




原文链接:https://www.percona.com/blog/mydumper-stream-implementation/
作者:David Ducos
您可能知道mysqldump 是单线程的,而 STDOUT 是其默认输出。由于 MyDumper 是多线程的,它必须写入不同的文件。由于 0.11.3 版本于 2021 年 11 月发布之后,我们可以在 MyDumper 中流式传输我们的备份。我们思考了几个月,直到我们确定了实现它的最简单方法,并且我们还必须添加对压缩的支持。所以,在修复了几个错误之后,我们现在认为它已经足够稳定了,我们可以解释它是如何工作的。
如果 MyDumper 是多线程的,您如何进行流式传输?
接收流对于 myloader 来说不是问题,它一次接收一个文件并将其发送到一个线程来处理它。但是mydumper 中的每个工作线程都连接到数据库,并且一旦读取数据,就应该将其发送到流中,这可能会导致与正在从数据库读取数据的其他工作线程发生冲突。为了避免这个问题,我们最终得到了最简单的解决方案:mydumper 将进行备份并将其存储在您配置的本地文件系统中,文件名将入队以由弹出一个 Stream Thread 处理一次文件并通过管道传输到标准输出。我们研究了在转储文件时发送文件块的替代方案,但我们实现的方式更简单并提高了整体性能。
实施细节
这是我们如何实现它的高级图表:
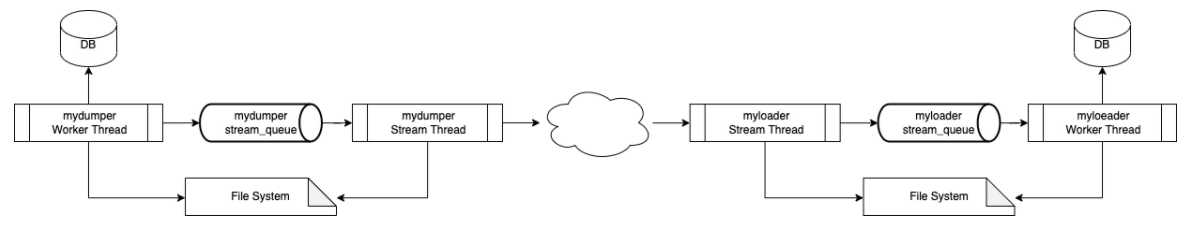
当 mydumper 工作线程处理作业时,它会连接到数据库并将输出存储到文件中。这没有改变,使用流,我们将文件名推送到 mydumper stream_queue。
mydumper Stream Thread 正在从 mydumper stream_queue 中弹出文件名,它将文件头发送到 stdout,然后打开文件并发送其内容。
然后,myloader Stream Thread 接收并检测标题,它将使用标题中的文件名创建新文件并将内容存储在其中。
关闭文件后,它会将文件名排入 myloader 的 stream_queue 中。 myloader 工作线程将获取该文件并根据文件的类型对其进行处理。
默认情况下,文件会被删除,但如果要保留它们,可以使用 –no-delete 选项。
标头只是简单地将 - 添加到文件名,因此您可以使用 myloader 或 mysql 客户端导入数据库。这是一个例子:
-- sbtest-schema-create.sql CREATE DATABASE /*!32312 IF NOT EXISTS*/ `sbtest` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */; -- sbtest.sbtest1-schema.sql /*!40101 SET NAMES binary*/; /*!40014 SET FOREIGN_KEY_CHECKS=0*/; /*!40103 SET TIME_ZONE='+00:00' */; CREATE TABLE `sbtest1` ( `id` int NOT NULL AUTO_INCREMENT, `k` int NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', `pad2` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=100010 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; -- sbtest.sbtest1.00000.sql /*!40101 SET NAMES binary*/; /*!40014 SET FOREIGN_KEY_CHECKS=0*/; /*!40103 SET TIME_ZONE='+00:00' */; INSERT INTO `sbtest1` VALUES(1,49929,"83868641912-28773972837-60736120486-75162659906-27563526494-20381887404-41576422241-93426793964-56405065102-33518432330","67847967377-48000963322-62604785301-91415491898-96926520291","") …复制
简单用例
线程写入单个文件以避免冲突,从而提高性能。但是,拥有数千个文件来备份几个表是不可管理的。因此,最简单的用例是将所有内容发送到单个文件:
mydumper -B <SCHEMA_NAME> -h <FROM> > filename.sql复制
然后您可以使用以下方法简单地导入它:
myloader --stream -o -h <TO_SERVER> < filename.sql复制
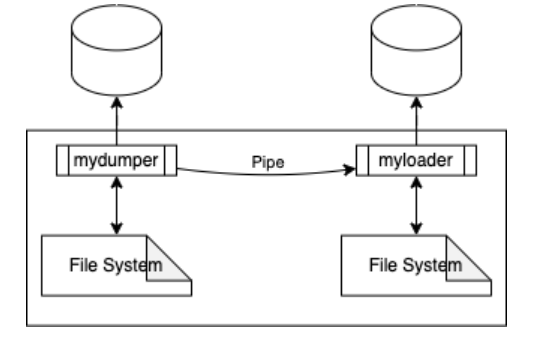
现在您可以从 mydumper 进程通过管道传输到 myloader,可以执行以下操作:
Shell mydumper -B <SCHEMA_NAME> -h <FROM> | myloader --stream -o -h <TO> 1 mydumper -B <SCHEMA_NAME> -h <FROM> | myloader --stream -o -h <TO>复制
或者您可以使用 nc 通过网络发送流:
mydumper -B <SCHEMA_NAME> -h <FROM_SERVER> | nc <MYDUMPER_SERVER> <ANY_PORT> nc -l <MYDUMPER_SERVER> <ANY_PORT> | myloader --stream -o -h <TO_SERVER>复制
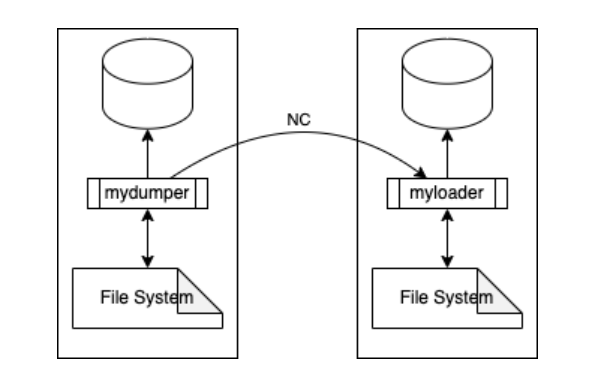
此实现使用 mydumper 和 myloader 上的备份目录作为缓冲区,您必须考虑到这一点,因为默认情况下它将创建一个运行它的目录。
您需要考虑的另一件事是 mydumper 和 myloader 将写入磁盘,整个备份将在处理时写入两个文件系统,并使用具有足够磁盘空间的文件系统。
最后,您可以保持 myloader 运行并发送多个 mydumper 备份。首先,您需要运行:
nc -k -l <MYDUMPER_SERVER> <ANY_PORT> | myloader --stream -o -h <TO_SERVER>复制
然后执行:
mydumper -B <SCHEMA_NAME_1> -h <FROM_SERVER> | nc <MYDUMPER_SERVER> <ANY_PORT> mydumper -B <SCHEMA_NAME_2> -h <FROM_SERVER> | nc <MYDUMPER_SERVER> <ANY_PORT> mydumper -B <SCHEMA_NAME_3> -h <FROM_SERVER> | nc <MYDUMPER_SERVER> <ANY_PORT> mydumper -B <SCHEMA_NAME_4> -h <FROM_SERVER> | nc -N <MYDUMPER_SERVER> <ANY_PORT>复制
某些版本的 nc 有以下两个选项:
-
k 当一个连接完成时,监听另一个。需要-l。
-
N shutdown(2) 输入 EOF 后的网络套接字。一些服务器需要这个来完成他们的工作。
如果您正在刷新一些测试环境并且只需要不同数据库上的几个表,或者如果您使用仅适用于某些表的 where 子句,这将非常有用。
注意事项
通常,当您将数据发送到 STDOUT 时,您不会遇到转储服务器上的磁盘空间使用问题。如果您使用的是 MyDumper,情况则会不一样。文件将存储在 mydumper 服务器上,直到它们被传输到接收服务器。例如,如果您有一个 10TB 的数据库,与磁盘带宽相比,网络带宽非常低,您最终可能会填满临时保存文件的磁盘。
结论
我们专注于实施以加快进出口流程。与其他软件或实现相反,我们将文件系统用作缓冲区,从而导致更高的磁盘利用率。



