




postresql使用分享–01
1,pg事务的特点
1.1 事务中锁的处理
事务是所有关系型数据库系统的基础概念。事务最重要的一点是它将多个步骤捆绑成了一个单一的、要么全完成要么全不完成的操作。
mysql\oracle中事务:
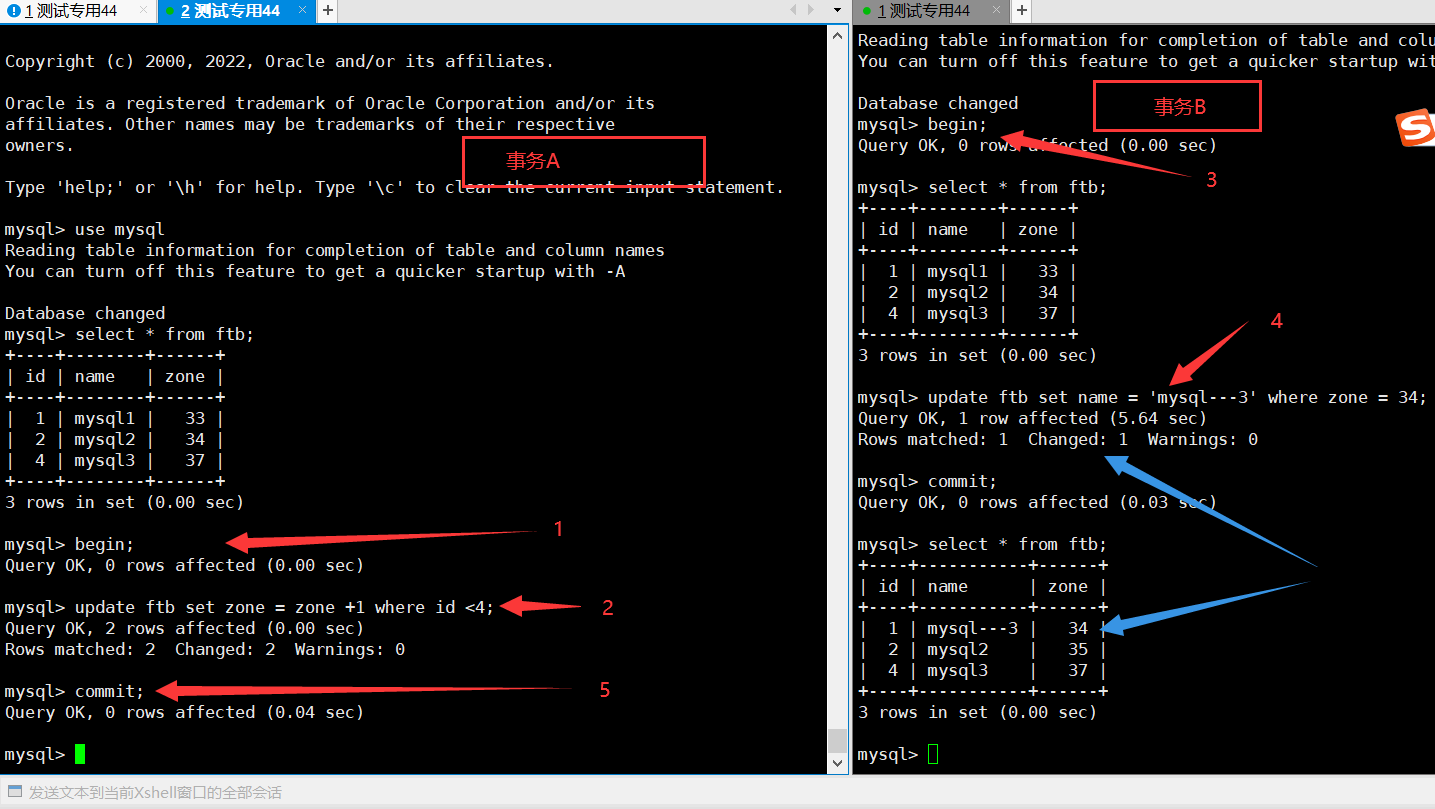
PG中的同类型数据处理:
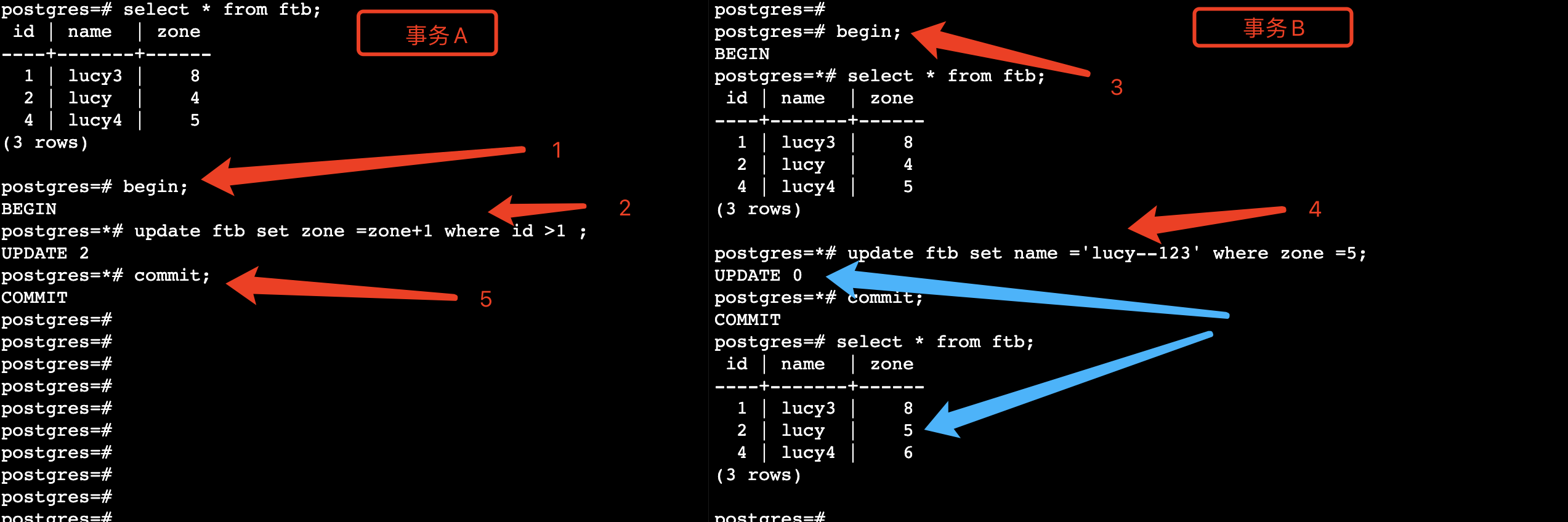
结论:在mysql(oracle)中,一个事务中锁被释放的时候,会对数据进行一个renew,然后进行操作;
PG中,一个事务中的锁被释放后,不会renew数据,只会对原来锁住的记录进行更改,如果此时数据已经被更改,那么该更新会失效。
注意点:该事务(被锁住)中更新的条件是另外一个事务(锁住他)的更新内容。
1.2 事务中错误的异常处理
mysql:
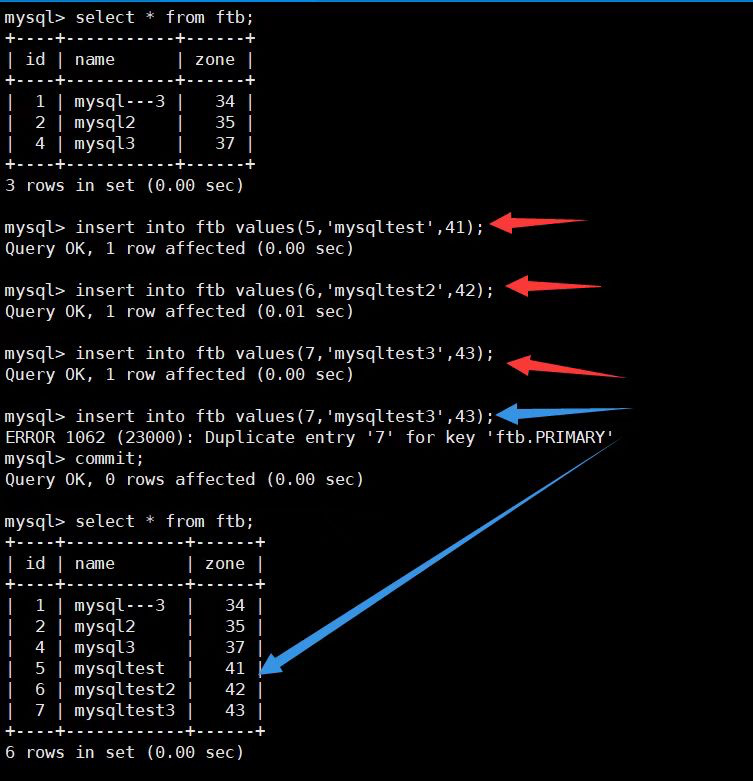
postgresql:
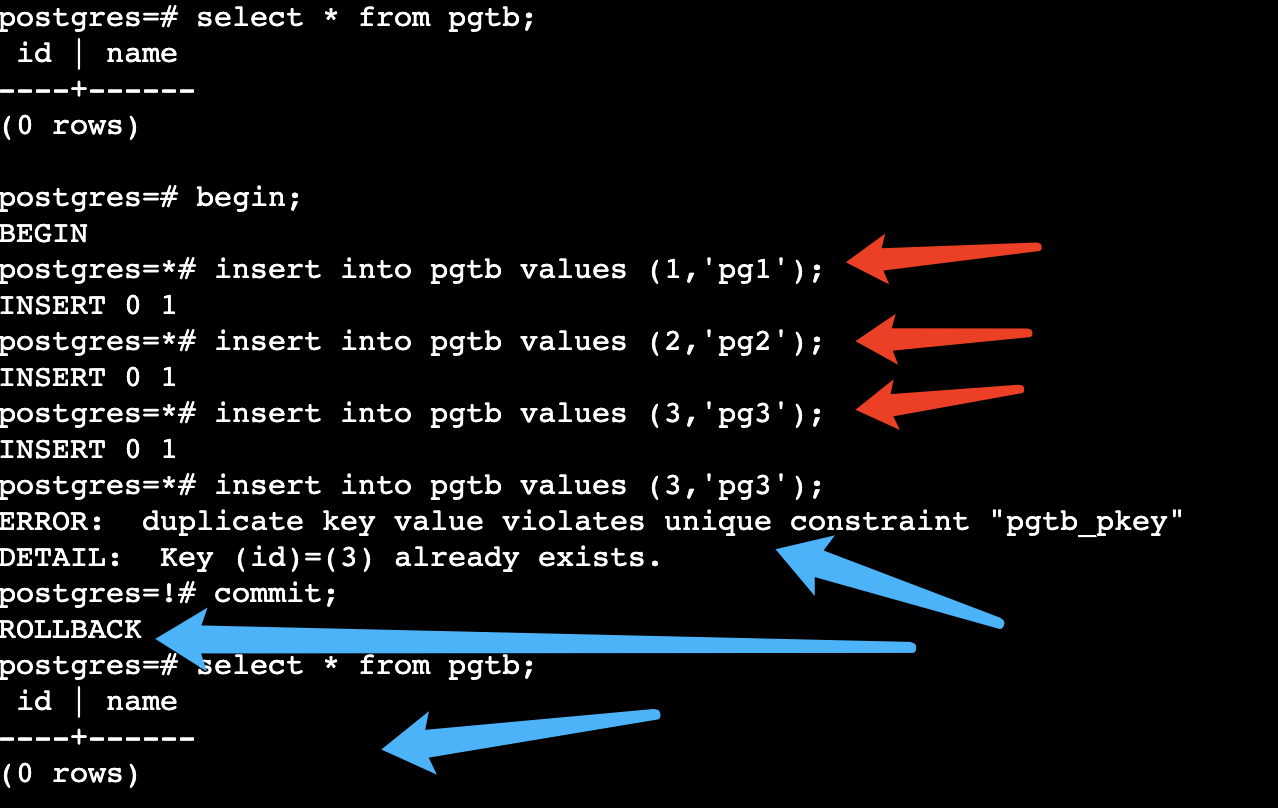
如何避免这样的事情发生可以通过savepoint来避免—但是需要小心使用,能不使用就不使用(一个事务中savepoint不能超过64 ,否则会影响数据库性能–遇到过类似的问题 造成数据库卡顿 )
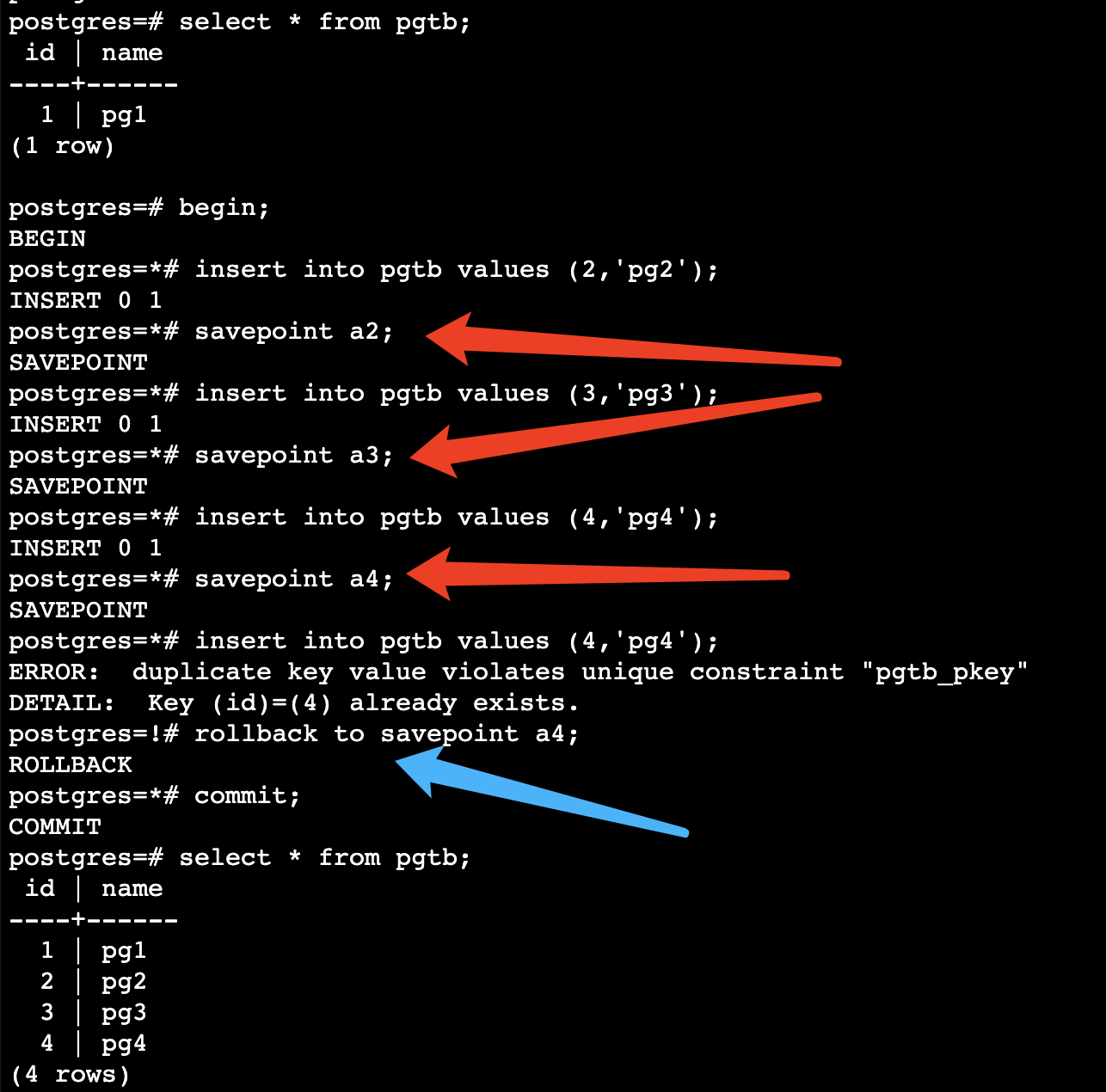
结论:在mysql(oracle)中,一个事务里面如果出现某个错误,提交事务的时候 只有该语句失败,其他执行成功的语句不会回滚;
在pg中,一个事务里面如果出现某个错误,提交的时候,整个事务会提交不会报任何错误,但是会隐式回滚。
1.3 insert、update
类似mysql upsert方式的 insert
testuse=# select * from t2;
name | age
------+-----
lucy | 17
emmy | 18
luck | 12
(3 rows)
testuse=# insert into t2 values('luck',7) on CONFLICT (name) do nothing;
INSERT 0 0
testuse=# insert into t2 values('luck',7) on CONFLICT (name) do update set age=excluded.age+1;
INSERT 0 1
testuse=# select * from t2;
name | age
------+-----
lucy | 17
emmy | 18
luck | 8
(3 rows)
testuse=# insert into t2 values('luck',20),('emmy',22) on CONFLICT (name) do update set age=excluded.age+1 where t2.name !='luck';
INSERT 0 1
testuse=# select * from t2;
name | age
------+-----
lucy | 17
luck | 8
emmy | 23
(3 rows)
Update 的表与表 连接方式
testuse=# select * from t2;
name | age
------+-----
emmy | 23
lucy | 18
luck | 9
(3 rows)
testuse=# select * from t2_sex;
uid | sex
-----+-----
1 | 1
2 | 1
3 | 0
(3 rows)
testuse=# select * from t2_uid;
id | name
----+------
1 | lucy
2 | luck
3 | emmy
(3 rows)
testuse=# update t2 t set age=t.age+1 from t2_uid i,t2_sex a where t.name=i.name and i.id=a.uid and i.id<3 and a.sex=1;
UPDATE 2
testuse=# select * from t2;
name | age
------+-----
emmy | 23
lucy | 19
luck | 10
(3 rows)
2,postgesql 分区表、继承表
2.1 继承
父表上的所有检查约束和非空约束都将自动被它的后代所继承,除非显式地指定了
NO INHERIT子句。其他类型的约束(唯一、主键和外键约束)则不会被继承
2.1.1 创建继承表
在创建的时候指定继承
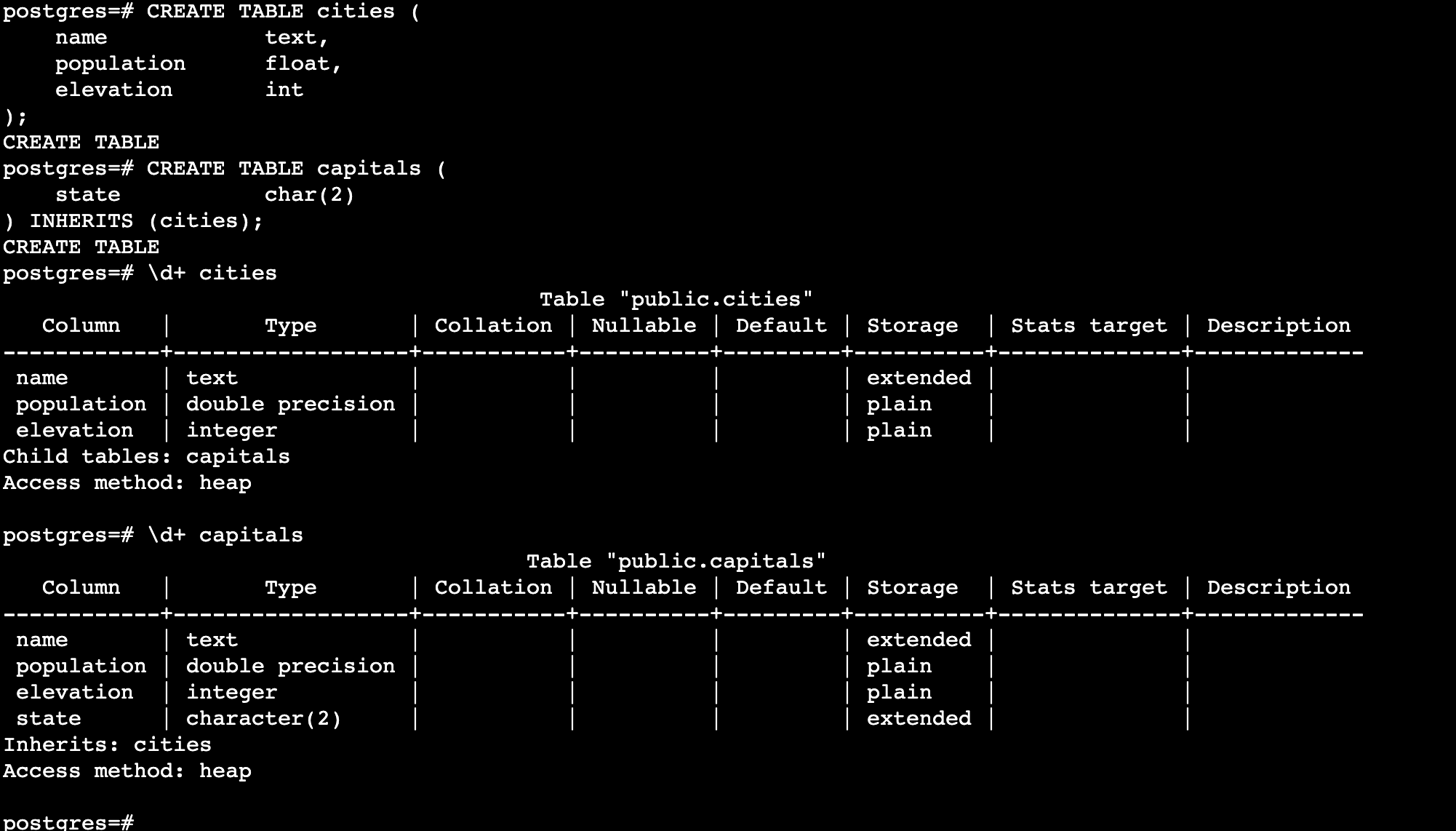
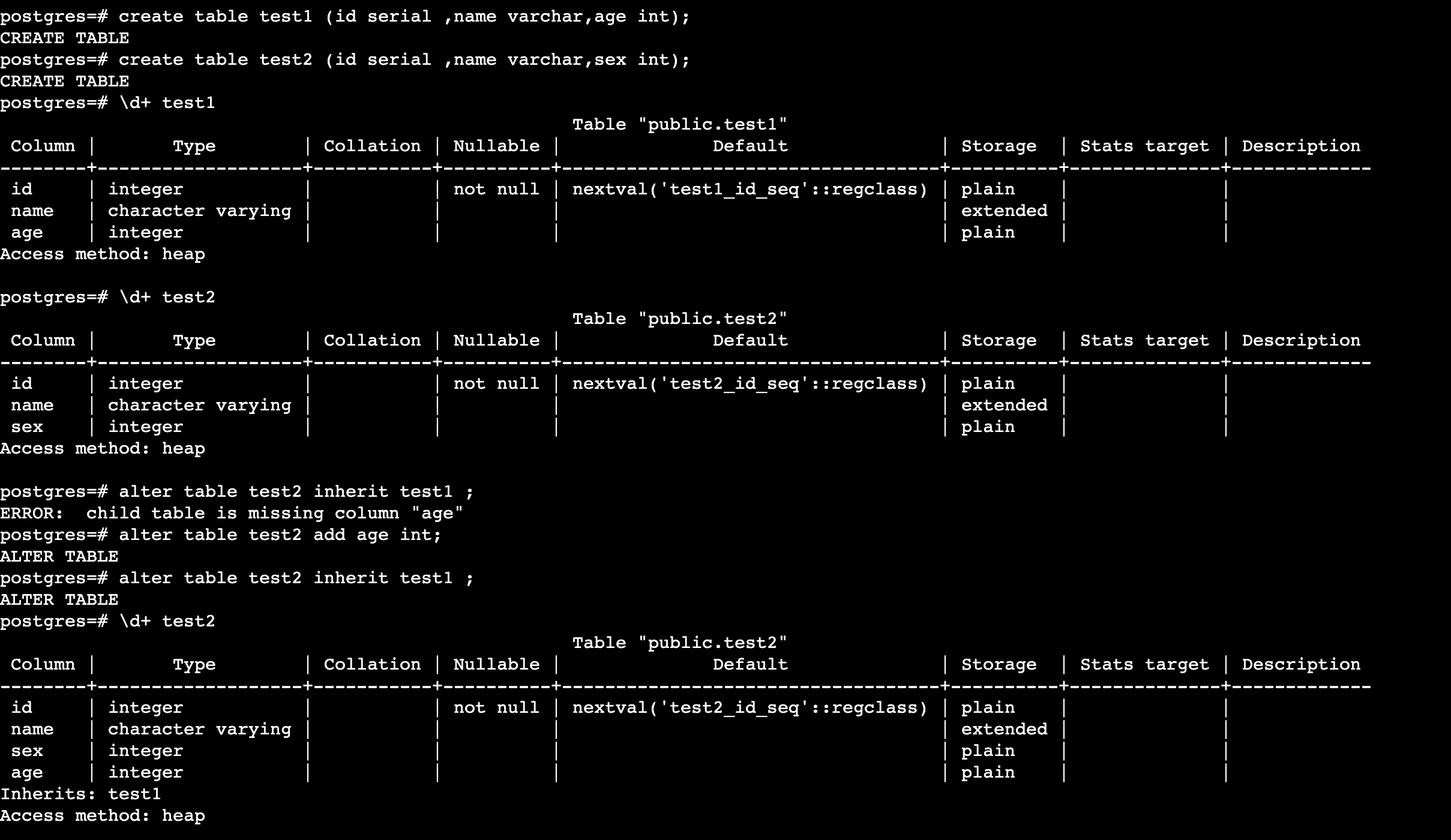
也可以先有的表进行继承,但是这样的话继承者(子表)需要包含被继承者(父表)所有的列:
order insert 触发器
Order_202201 create_time
Order_202202
Order_202203
2.1.2 父表、继承表 数据查询与操作
继承关系,父表和继承表中可能都会有数据,如果只希望查询父表的数据,则在表名前面加上 only(select、update、delete),也可以在父表添加check或者非空约束的时候也可以加。
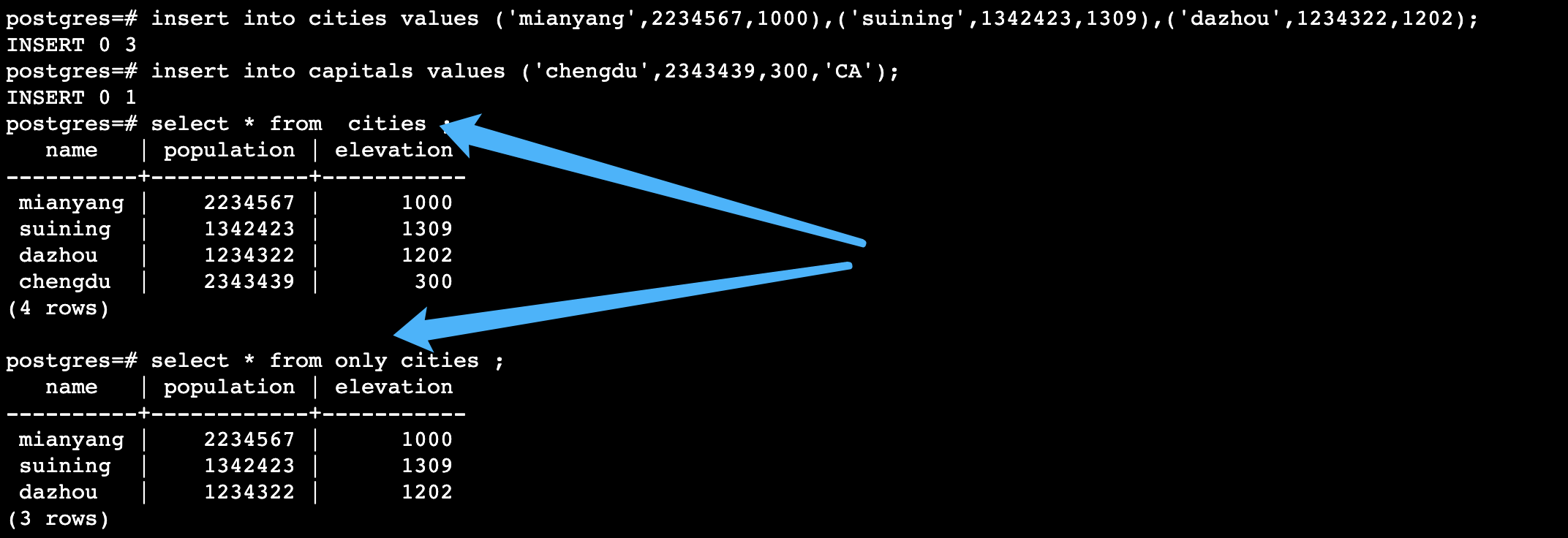
(继承表对于一般的insert,不会自动触发到相关的字表,需要自己定义相关规则或者触发器来进行数据分发)
非空约束:
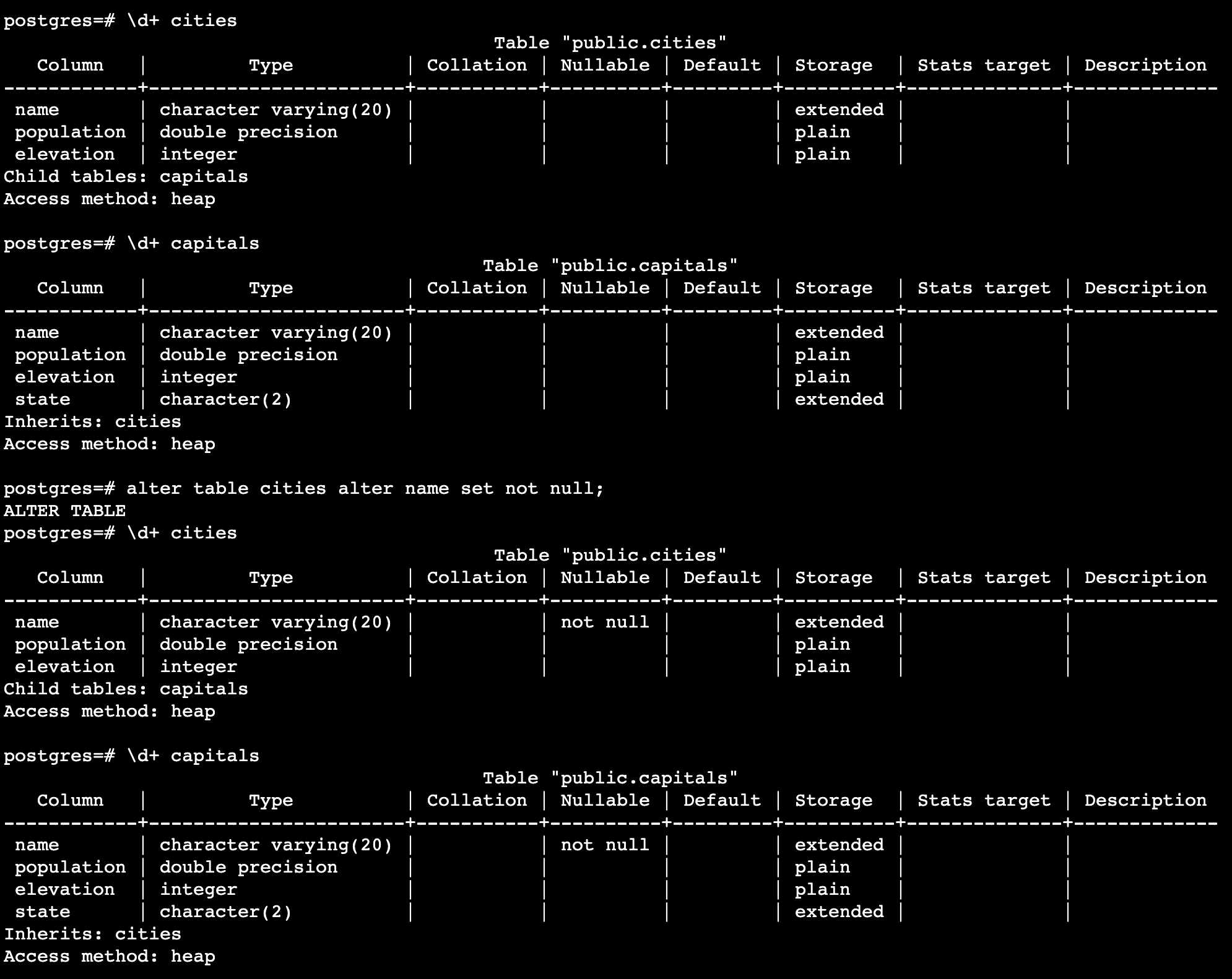

check约束:

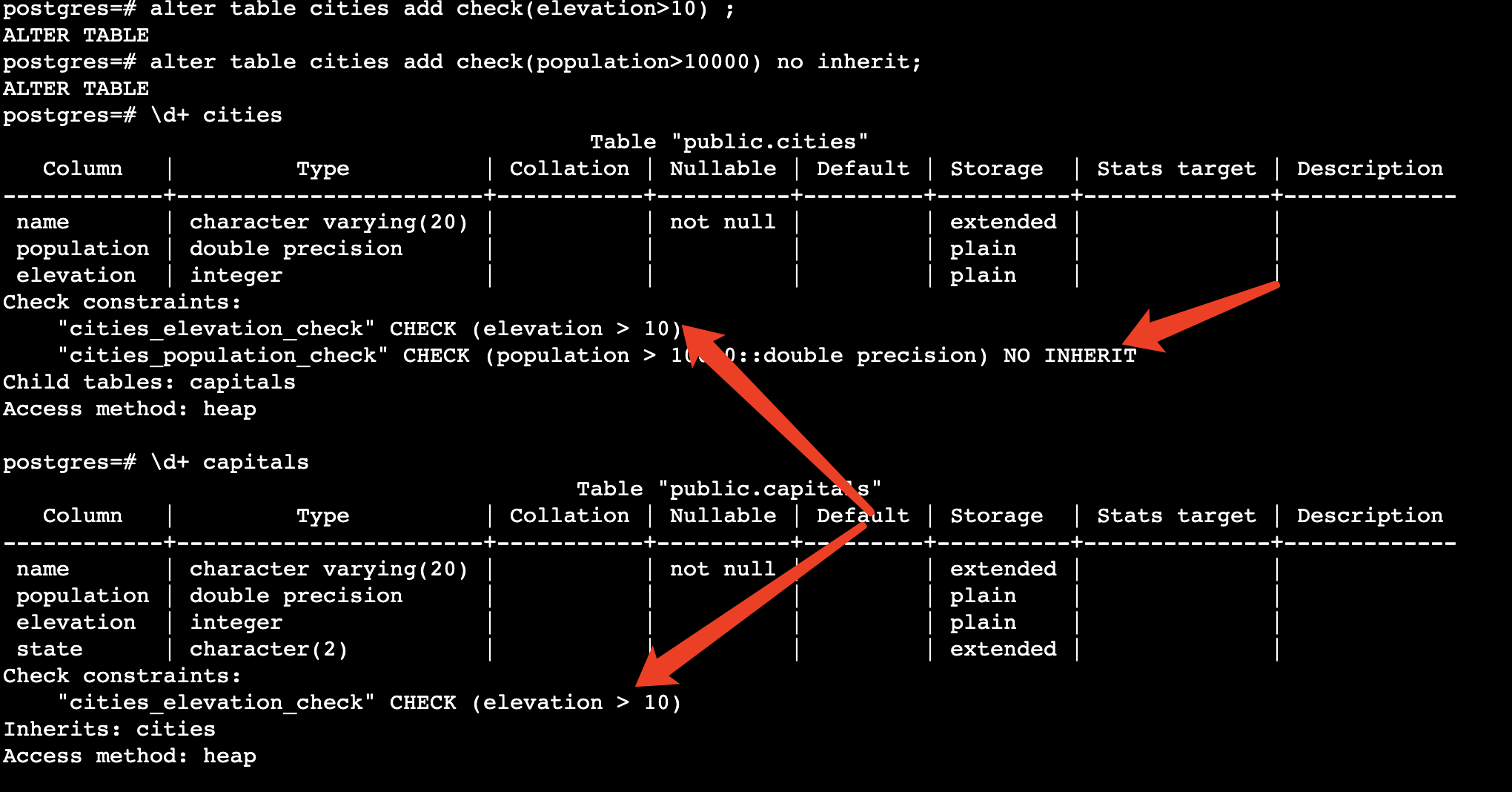
2.1.3 父表与继承表 数据表权限问题
继承的查询仅在附表上执行访问权限检查。例如,在cities表上授予UPDATE权限也隐含着通过cities访问时在capitals表中更新行的权限。这保留了数据(也)在父表中的样子。但是如果没有额外的授权,则不能直接更新capitals表。
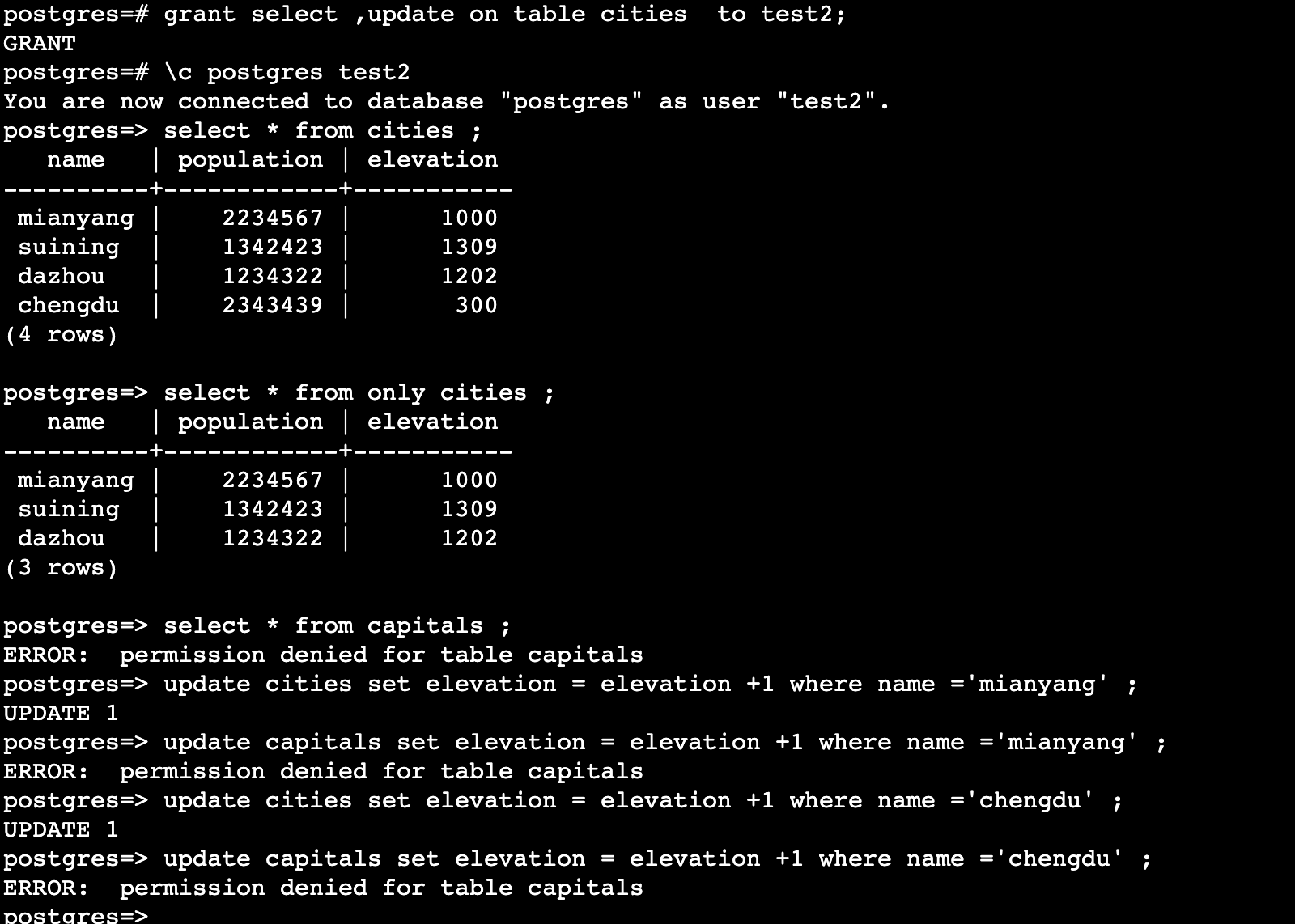
在早期(V10之前的版本)的表分区一般是通过 继承表+触发器 实现。
2.1.4 继承表的注意事项
下面的提醒适用于用继承实现的分区:
-
没有自动的方法啊验证所有的
CHECK约束之间是否互斥。编写代码来产生子表以及创建和修改相关对象比手写命令要更加安全。 -
索引和外键约束适用于单个表而不是其继承子级。
注意并非所有的SQL命令都能工作在继承层次上。用于数据查询、数据修改或模式修改(例如SELECT、UPDATE、DELETE、大部分ALTER TABLE的变体,但INSERT或ALTER TABLE ... RENAME不在此列)的命令会默认将子表包含在内并且支持ONLY记号来排除子表。负责数据库维护和调整的命令(如REINDEX、VACUUM)只工作在独立的、物理的表上并且不支持在继承层次上的递归。 继承特性的一个严肃的限制是索引(包括唯一约束)和外键约束值应用在单个表上而非它们的继承子女。在外键约束的引用端和被引用端都是这样。因此,按照上面的例子: 如果我们声明cities.name为UNIQUE或者PRIMARY KEY,这将不会阻止capitals表中拥有和cities中城市同名的行。而且这些重复的行将会默认显示在cities的查询中。事实上,capitals在默认情况下是根本不能拥有唯一约束的,并且因此能够包含多个同名的行。我们可以为capitals增加一个唯一约束,但这无法阻止相对于cities的重复。 相似地,如果我们指定cities.name REFERENCES某个其他表,该约束不会自动地传播到capitals。在此种情况下,我们可以变通地在capitals上手工创建一个相同的REFERENCES约束。 指定另一个表的列REFERENCES cities(name)将允许其他表包含城市名称,但不会包含首府名称。这对于这个例子不是一个好的变通方案。 -
这里展示的模式假定行的键列值从不改变,或者说改变不足以让行移动到另一个分区。由于
CHECK约束的存在,尝试那样做的UPDATE将会失败。如果需要处理那种情况,可以在子表上放置适当的更新触发器,但是那会使对结构的管理更加复杂。 -
如果使用手工的
VACUUM或者ANALYZE命令,不要忘记需要在每个子表上单独运行它们。这样的命令:ANALYZE 主表;将只会处理主表。
-
带有
ON CONFLICT子句的INSERT语句不太可能按照预期工作,因为只有在指定的目标关系而不是其子关系上发生唯一违背时才会采取ON CONFLICT行动。 -
将会需要触发器或者规则将行路由到想要的子表中,除非应用明确地知道分区的模式。编写触发器可能会很复杂,并且会比声明式分区在内部执行的元组路由慢很多。
2.2 表分区
指将逻辑上的一个大表分成一些小的物理上的片,Postgresql V10首次引入了“声明式分区”功能,在此之前只能通过继承表方式实现
2.2.1表分区的一些定义和分区方式
简单来说,使用分表表就是提高性能
当一个表非常大时,划分所带来的好处是非常值得的。一个表何种情况下会从划分获益取决于应用,一个经验法则是当表的尺寸超过了数据库服务器物理内存时,划分会为表带来好处。
-
分区表: 使用分区方法将一个大表拆成多个分片的表;
无法把一个常规表转换成分区表,反之亦然。
**语法:**create table tablename (…)
PARTITION BY {range|list|hash} (column_name|(expression))
-
分区: 这些小的分片就叫分区;
分区可以有自己的与其他分区不同的索引、约束以及默认值;
可以把一个包含数据的常规表或者分区表作为分区加入到另一个分区表,或者从分区表中移走一个分区并且把它变成一个独立的表。
**语法:**create table tablename
PARTITION of parent_table for values partition_bound_spec
默认分区:create table tablename PARTITION of parent_table DEFAULT;
-
子分区:每个分区还可以定义自己的分区
**语法:**create table tablename
PARTITION of parent_table for values partition_bound_spec
PARTITION BY {range|list|hash} (column_name|(expression))
分区不能有除其所属分区表之外的父表,一个常规表也不能从分区表继承使得后者成为其父表。这意味着分区表及其分区不会参与到与常规表的继承关系中。
表分区三要素:
- 分区方法
- 分区键
- 分区边界
PostgreSQL对下列分区形式提供了内建支持:
-
范围划分
表被根据一个关键列或一组列划分为“范围”,不同的分区的范围之间没有重叠。例如,我们可以根据日期范围划分,或者根据特定业务对象的标识符划分。
-
列表划分
通过显式地列出每一个分区中出现的键值来划分表。
-
哈希分区
通过为每个分区指定模数和余数来对表进行分区。每个分区所持有的行都满足:分区键的值除以为其指定的模数将产生为其指定的余数。
2.2.2 继承表与分区表的一些差异
由于分区表及其分区组成的分区层次仍然是一种继承层次,继承的普通规则也适用,不过有一些例外,尤其是:
- 分区表的
CHECK约束和NOT NULL约束总是会被其所有的分区所继承。不允许在分区表上创建标记为NO INHERIT的CHECK约束。 - 只要分区表中不存在分区,则支持使用
ONLY仅在分区表上增加或者删除约束。一旦分区存在,那样做就会导致错误,因为当分区存在时是不支持仅在分区表上增加或删除约束的。不过,分区本身上的约束可以被增加和删除。 - 由于分区表并不直接拥有任何数据,尝试在分区表上使用
TRUNCATEONLY将总是返回错误。 - 分区不能有在父表中不存在的列。在使用
CREATE TABLE创建分区时不能指定列,在事后使用ALTER TABLE时也不能为分区增加列。只有当表的列正好匹配父表时,才能使用ALTER TABLE ... ATTACH PARTITION将它作为分区加入。 - 如果
NOT NULL约束在父表中存在,那么就不能删除分区的列上的对应的NOT NULL约束。 - 继承表的唯一约束、主键和外键均不会被子表继承,分区表都可以。
2.2.3 例子
比如我们正在为一个某大型商品公司构建数据库,该公司每天测量最高温度以及每个区域的商品销售情况。
我们知道大部分查询只会访问上周的、上月的或者上季度的数据,因为这个表的主要用途是为管理层准备在线报告。为了减少需要被存放的旧数据量,我们决定只保留最近3年的数据。在每个月的开始我们将去除掉最早的那个月的数据。
要在这种情况下使用声明式分区,可采用下面的步骤:
- 1,通过指定
PARTITION BY子句把measurement表创建为分区表,该子句包括分区方法(这个例子中是RANGE)以及用作分区键的列列表。
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-
2,创建分区。每个分区的定义必须指定对应于父表的分区方法和分区键的边界。注意,如果指定的边界使得新分区的值会与已有分区中的值重叠,则会导致错误。向父表中插入无法映射到任何现有分区的数据将会导致错误,这种情况下应该手工增加一个合适的分区。(范围:左闭右开)
CREATE TABLE measurement_y2022m01 PARTITION OF measurement FOR VALUES FROM ('2022-01-01') TO ('2022-02-01'); CREATE TABLE measurement_y2022m02 PARTITION OF measurement FOR VALUES FROM ('2022-02-01') TO ('2022-03-01'); CREATE TABLE measurement_y2022m03 PARTITION OF measurement FOR VALUES FROM ('2022-03-01') TO ('2022-04-01'); CREATE TABLE measurement_y2022m04 PARTITION OF measurement FOR VALUES FROM ('2022-04-01') TO ('2022-05-01'); CREATE TABLE measurement_y2022m05 PARTITION OF measurement FOR VALUES FROM ('2022-05-01') TO ('2022-06-01'); CREATE TABLE measurement_y2022m06 PARTITION OF measurement FOR VALUES FROM ('2022-06-01') TO ('2022-07-01'); CREATE TABLE measurement_y2022m07 PARTITION OF measurement FOR VALUES FROM ('2022-07-01') TO ('2022-08-01'); CREATE TABLE measurement_y2022m08 PARTITION OF measurement FOR VALUES FROM ('2022-08-01') TO ('2022-09-01'); CREATE TABLE measurement_y2022m09 PARTITION OF measurement FOR VALUES FROM ('2022-09-01') TO ('2022-10-01'); CREATE TABLE measurement_y2022m10 PARTITION OF measurement FOR VALUES FROM ('2022-10-01') TO ('2022-11-01'); CREATE TABLE measurement_y2022m11 PARTITION OF measurement FOR VALUES FROM ('2022-11-01') TO ('2022-12-01'); CREATE TABLE measurement_y2022m12 PARTITION OF measurement FOR VALUES FROM ('2022-12-01') TO ('2023-01-01');为了实现子分区,在创建分区的命令中指定
PARTITION BY子句,例如:CREATE TABLE measurement_y2023m01 PARTITION OF measurement FOR VALUES FROM ('2023-01-01') TO ('2023-02-01') PARTITION BY RANGE (peaktemp);
确保enable_partition_pruning配置参数在postgresql.conf中没有被禁用。如果被禁用,查询将不会按照想要的方式被优化。
-
3,分区维护
我们在定义出来分区表时候,一般不是保持静态不变的,一般会随着需求,移除旧分区 添加新分区。
删除分区:
3.1 直接删除分区
DROP TABLE measurement_y2022m02;
另一种通常更好的选项是把分区从分区表中移除,但是保留它作为一个独立的表:
ALTER TABLE measurement DETACH PARTITION measurement_y2022m02;
3.2 加分区
类似地,我们可以增加一个新分区来处理新数据。我们可以在分区表中创建一个空分区,就像上面创建的初始分区那样:
CREATE TABLE measurement_y2023m02 PARTITION OF measurement
FOR VALUES FROM ('2023-02-01') TO ('2023-03-01')
TABLESPACE fasttablespace;
**降低锁影响** 另外一种选择是,有时候在分区结构之外创建新表更加方便,然后将它作为一个合适的分区。这允许先对数据进行装载、检查和转换,然后再让它们出现在分区表中:
CREATE TABLE measurement_y2023m02
(LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS)
TABLESPACE fasttablespace;
ALTER TABLE measurement_y2023m02 ADD CONSTRAINT y2023m02
CHECK ( logdate >= DATE '2023-02-01' AND logdate < DATE '2023-03-01' );
\copy measurement_y2023m02 from 'measurement_y2023m02'
-− possibly some other data preparation work
ALTER TABLE measurement ATTACH PARTITION measurement_y2023m02
FOR VALUES FROM ('2023-02-01') TO ('2023-03-01' );
在运行ATTACH PARTITION命令之前,推荐在要被挂接的表上创建一个CHECK约束来匹配期望的分区约束。 这样,系统将能够跳过扫描,否则需要验证隐式分区约束。 没有CHECK约束,将扫描表以验证分区约束,同时对该分区持有ACCESS EXCLUSIVE锁定,并在父表上持有SHARE UPDATE EXCLUSIVE(V12版本及之后)锁。 在完成ATTACH PARTITION后,可能需要删除冗余CHECK约束。
3.3 分区表上加索引
如上所述,可以在分区的表上创建索引,并自动将其应用于整个层次结构。 这非常便利,因为不仅现有分区将变为索引,而且将来创建的任何分区都将变为索引。 一个限制是,在创建这样一个分区索引时,不可能同时使用CONCURRENTLY限定符。 为了克服长时间锁,可以对分区表使用CREATE INDEX ON ONLY ;这样的索引被标记为无效,并且分区不会自动应用该索引。 分区上的索引可以使用CONCURRENTLY分别的创建。 然后使用ALTER INDEX .. ATTACH PARTITIONattached到父索引。 一旦所有分区的索引附加到父索引,父索引将自动标记为有效。 例如:
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales);
CREATE INDEX measurement_usls_200602_idx
ON measurement_y2006m02 (unitsales);
ALTER INDEX measurement_usls_idx
ATTACH PARTITION measurement_usls_200602_idx;
...
该技术也可以与UNIQUE 和PRIMARY KEY 约束一起试用; 当创建约束时隐式创建索引。例如:
ALTER TABLE ONLY measurement ADD UNIQUE (city_id, logdate);
ALTER TABLE measurement_y2006m02 ADD UNIQUE (city_id, logdate);
ALTER INDEX measurement_city_id_logdate_key
ATTACH PARTITION measurement_y2006m02_city_id_logdate_key;
...
另外的例子:
列表分区示例:
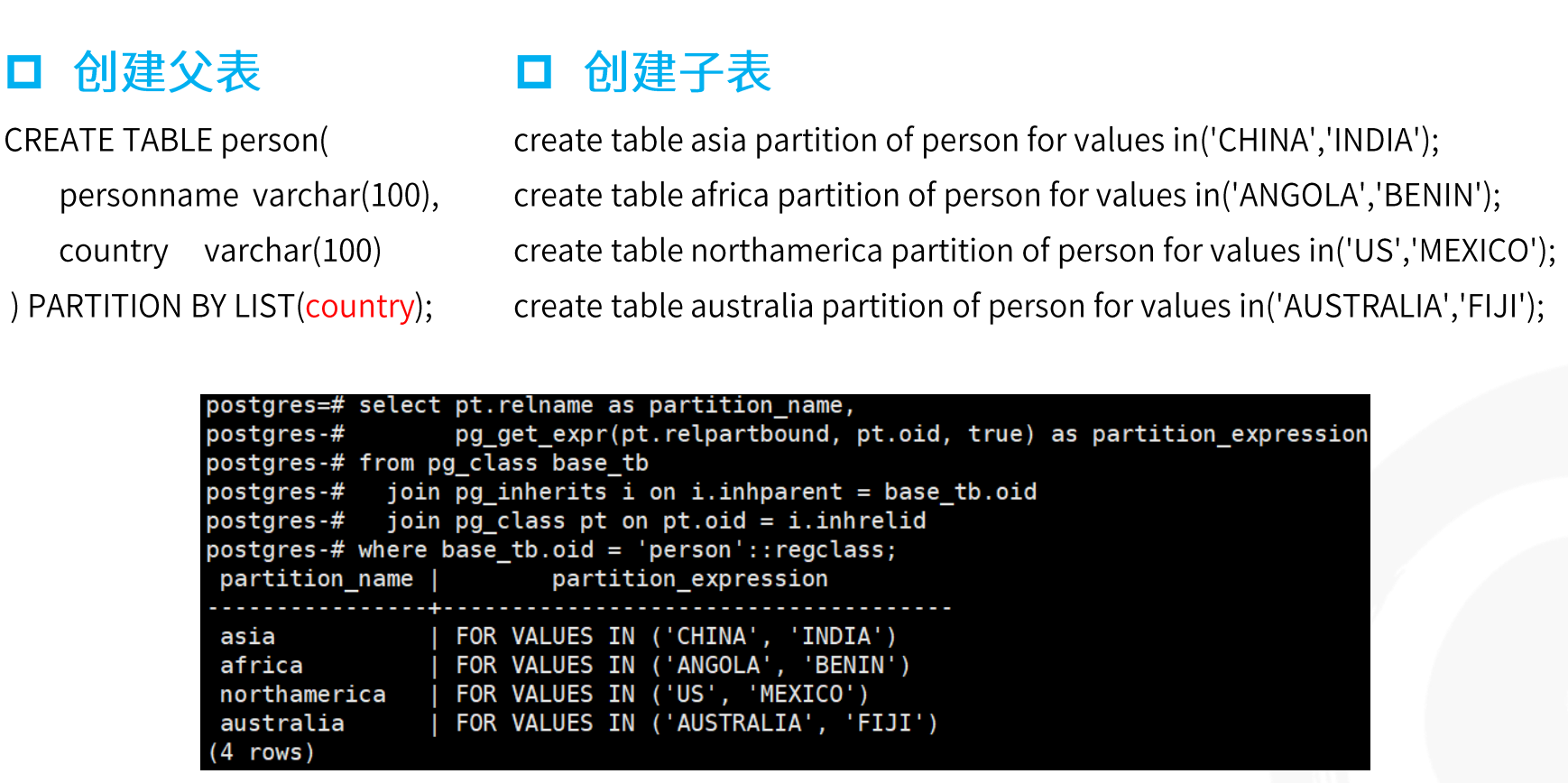
哈希分区示例:

2.2.4 使用分区表的限制
- 没有办法创建跨越所有分区的排除约束,只可能单个约束每个叶子分区。
- 分区表上的惟一约束(也就是主键)必须包括所有分区键列。存在此限制是因为PostgreSQL只能每个分区中分别强制实施唯一性。
BEFORE ROW触发器无法更改哪个分区是新行的最终目标。- 不允许在同一个分区树中混杂临时关系和持久关系。因此,如果分区表是持久的,则其分区也必须是持久的,反之亦然。在使用临时关系时,分区数的所有成员都必须来自于同一个会话。
虽然内建的声明式分区适合于大部分常见的用例,但还是有一些场景需要更加灵活的方法。分区可以使用表继承来实现,这能够带来一些声明式分区不支持的特性,例如:
- 对声明式分区来说,分区必须具有和分区表正好相同的列集合,而在表继承中,子表可以有父表中没有出现过的额外列。
- 表继承允许多继承。
- 声明式分区仅支持范围、列表以及哈希分区,而表继承允许数据按照用户的选择来划分(不过注意,如果约束排除不能有效地剪枝子表,查询性能可能会很差)。
- 在使用声明式分区时,一些操作比使用表继承时要求更长的持锁时间。例如,从分区表移除分区要求在父表上取得一个
ACCESS EXCLUSIVE锁,而在常规继承的情况下一个SHARE UPDATE EXCLUSIVE锁就足够了。
2.2.5 分区表的进化
PG V12:
-
新增特性:
1, 允许外键引用分区表
2, 允许分区边界是任何表达式:PG12之前版本只允许将简单常量作为分区边界
3,alter table attach partition 执行时降低了锁要求
4,新增3个分区查询函数:
pg_partition_ancestors:显示上层分区名称
pg_partition_root :显示根父表名称
pg_partition_tree :显示各级分区表层级关系信息
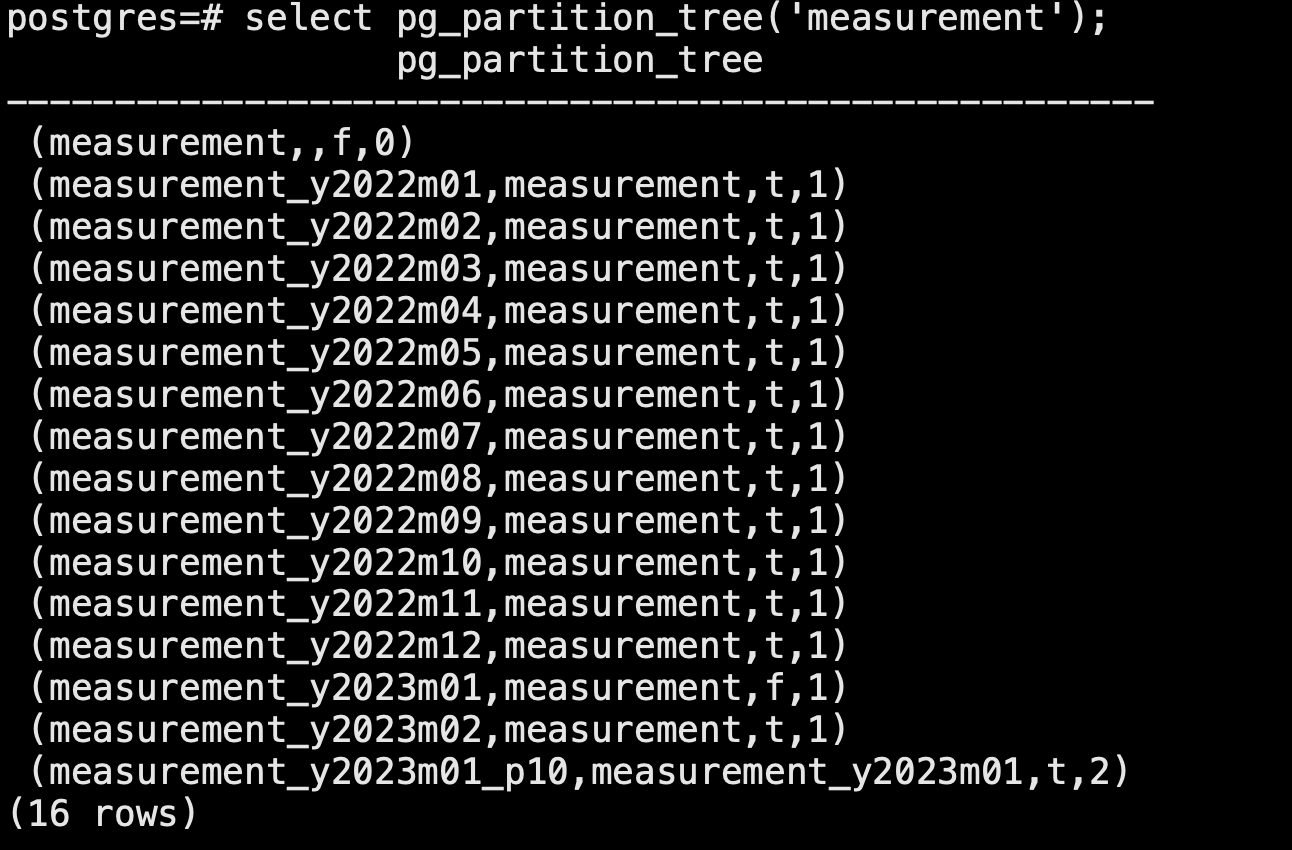

-
性能提升:
分区表DML性能大幅提升
分区表数据导入性能提升
-
分区挂接增强:
PG 12 之前:在父表和被连接分区上都要加上 Access Exclusive排它锁
PG 12:在被连接分区和默认分区(如果存在)上才加上 Access Exclusive排它锁,父表只需加上Shared update Exclusive共享锁
PG V13:
- 逻辑复制支持分区表
- before insert trigger
1,允许设置行级别的before insert trigger
2,不能改变分区键的值
-
分区表智能join增强
-
分区键可以使用表的完整行
PG V14
- 分区表支持reindex操作
- 卸载分区支持concurrently
3,pg常用函数
3.1 字符串函数
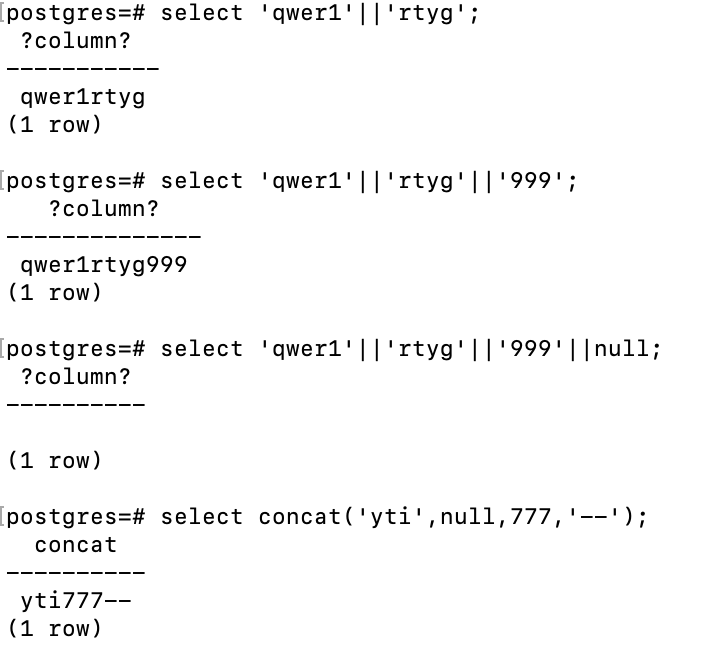
字符串链接
|| 和 concat、concat_ws函数:
示例:

字符串处理
-
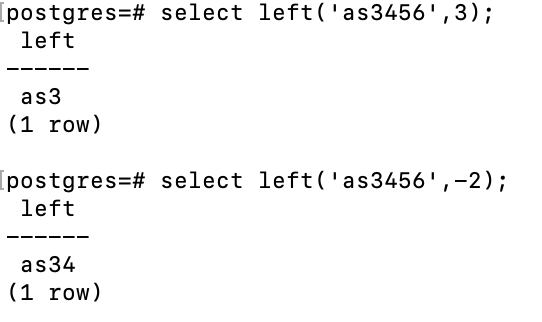
1,left(str text,n int) 返回字符串中的前n个字符,当n为负数时,将返回除了最后|n|个字符之外的所有字符。
-
2, right(str text,n int) 返回字符串中的最后n个字符,当n为负数时,将返回除了最前面|n|个字符之外的所有字符。

- 3,length(string) string中的字符个数

- 4,substr(
string,from[,count]) 提取字符串

- 5,replace(string text, from text, to text) 将string中出现的所有子串from替换为子串to

- 6,position(
stringinstring)

- 7,split_part(
stringtext,delimitertext,fieldint) 按*delimiter划分string*并返回给定域(从1开始计算)

-
8,regexp_split_to_array(
stringtext,patterntext) 使用一个POSIX正则表达式作为分隔符划分*string*。

-
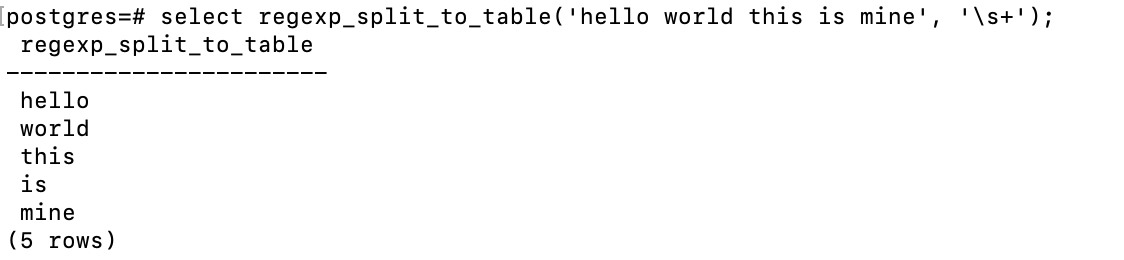
9,regexp_split_to_table(
stringtext,patterntext) 使用一个POSIX正则表达式作为分隔符划分*string*。
-
10,regexp_replace(
stringtext,patterntext,replacementtext) 替换匹配一个POSIX正则表达式的子串(只替换第一个匹配的值)。

3.2 聚集函数
聚集函数从一个输入值的集合计算出一个单一值。
3.2.1 通用聚集函数
| 函数 | 描述 |
|---|---|
| cont(*/expression) | 输入的行数/*expression*值非空的输入行的数目 |
max(expression) |
所有非空输入值中*expression*的最大值 |
min(expression) |
所有非空输入值中*expression*的最小值 |
avg(expression) |
所有非空输入值的平均值 |
sum(expression) |
所有非空输入值的*expression*的和 |
string_agg(expression, delimiter) |
非空输入值连接成一个串,用定界符分隔 |
array_agg(expression) |
输入值(包括空)被连接到一个数组 |
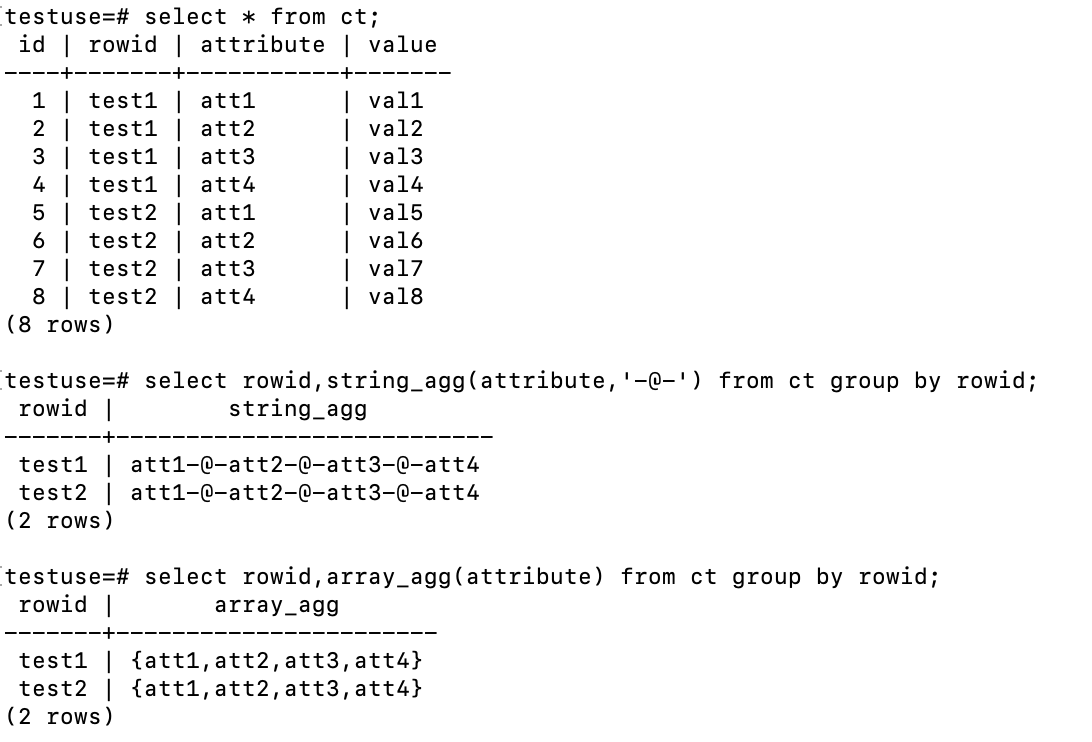
3.2.2 统计型聚集函数
| 函数 | 描述 |
|---|---|
corr(Y, X) |
相关系数 |
covar_pop(Y, X) |
总体协方差 |
covar_sam(Y, X) |
样本协方差 |
regr_avgx(Y, X) |
自变量的平均值 (sum(*X*)/*N*) |
regr_avgy(Y,X) |
因变量的平均值 (sum(*Y*)/*N*) |
regr_count(Y,X) |
两个表达式都不为空的输入行的数目 |
regr_intercept(Y,X) |
由(X, Y)对决定的最小二乘拟合的线性方程的 y截距 |
regr_r2(Y,X) |
相关系数的平方 |
regr_slope(Y,X) |
由(X, Y)对决定的最小二乘拟合的线性方程的斜率 |
regr_sxx(Y,X) |
sum(*X*^2) - sum(*X*)^2/*N*(自变量的“平方和”) |
regr_sxy(Y,X) |
sum(*X***Y*) - sum(*X*) * sum(*Y*)/*N*(自变量乘以因变量的“积之合”) |
regr_syy(Y,X) |
sum(*Y*^2) - sum(*Y*)^2/*N*(因变量的“平方和”) |
stddev(expression) |
stddev_samp的历史别名 |
stddev_pop(expression) |
输入值的总体标准偏差 |
stddev_samp(expression) |
输入值的样本标准偏差 |
variance(expression) |
var_samp的历史别名 |
var_pop(expression) |
输入值的总体方差(总体标准偏差的平方) |
var_samp(expression) |
输入值的样本方差(样本标准偏差的平方) |
3.3 窗口函数
聚合函数将结果集进行计算并且通常返回一行。窗口函数也是基于结果集的运算。与聚合函数不同的是,窗口函数并不会将结果集进行分组合并输出一行;而是将计算的结果合并到基于结果集运算的列上。
语法
function_name ([expression [, expression ...]]) [FILTER (WHERE filter_clause)]
OVER (window_definition)
window_definition:
[existing_window_name]
[PARTITION BY expression [, ...]]
[ORDER BY expression [ASC | DESC | USING operator] [NULLS {FIRST | LAST }] [, ...]]
[frame_clause]
- OVER:表示窗口函数的关键字
- PARTITION BY:对查询返回的结果集进行分组,之后窗口函数处理分组的数据。
- ORDER BY:设定结果集的分组数据排序
| 函数 | 描述 |
|---|---|
row_number() |
当前行在其分区中的行号,从1计 |
rank() |
带间隙的当前行排名; 与该行的第一个同等行的row_number相同 |
dense_rank() |
不带间隙的当前行排名; 这个函数计数同等组 |
percent_rank() |
当前行的相对排名: (rank- 1) / (总行数 - 1) |
cume_dist() |
累积分布:(在当前行之前或者平级的分区行数) / 分区行总数 |
ntile(num_buckets integer) |
从1到参数值的整数范围,尽可能等分分区 |
lag(value anyelement [, offset integer [, default anyelement ]]) |
返回*value,它在分区内当前行的之前offset个位置的行上计算;如果没有这样的行,返回default替代(必须和value类型相同)。offset和default都是根据当前行计算的结果。如果忽略它们,则offset默认是1,default*默认是空值 |
lead(value anyelement [, offset integer [, default anyelement ]]) |
返回*value,它在分区内当前行的之后offset个位置的行上计算;如果没有这样的行,返回default替代(必须和value类型相同)。offset和default都是根据当前行计算的结果。如果忽略它们,则offset默认是1,default*默认是空值 |
first_value(value any) |
返回在窗口帧中第一行上计算的*value* |
last_value(value any) |
返回在窗口帧中最后一行上计算的*value* |
nth_value(value any, nth integer) |
返回在窗口帧中第*nth行(行从1计数)上计算的value*;没有这样的行则返回空值 |
注意first_value、last_value和nth_value只考虑“窗口帧”内的行,它默认情况下包含从分区的开始行直到当前行的最后一个同等行。
部分示例
测试数据:

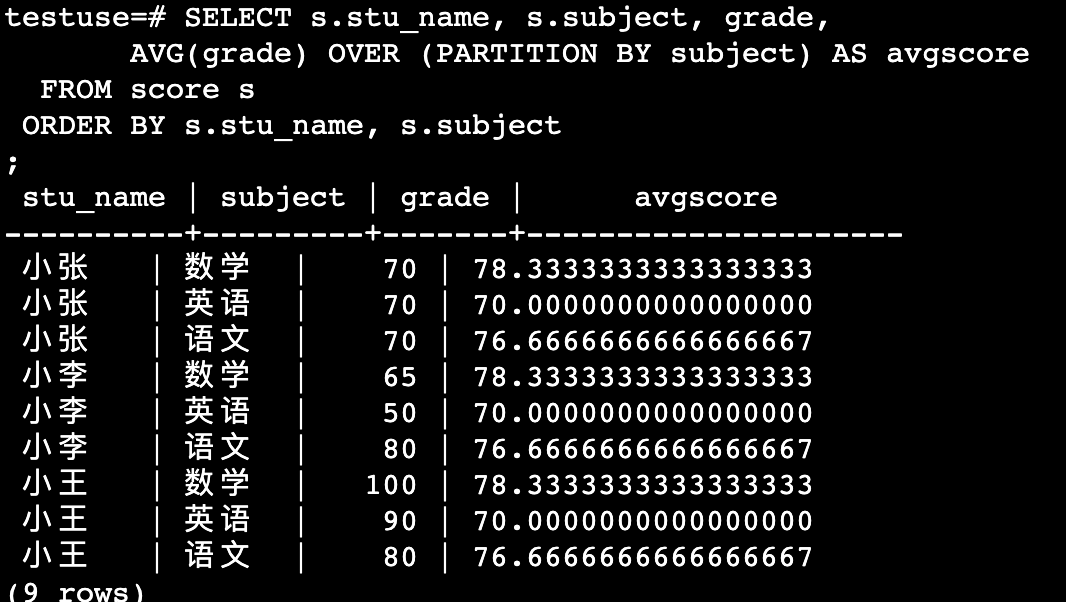
avg() OVER() / sum() over()
聚合函数后接 over属性的窗口函数表示在一个查询结果集上应用聚合函数。
SELECT s.stu_name, s.subject, grade,
AVG(grade) OVER (PARTITION BY subject) AS avgscore
FROM score s
ORDER BY s.stu_name, s.subject
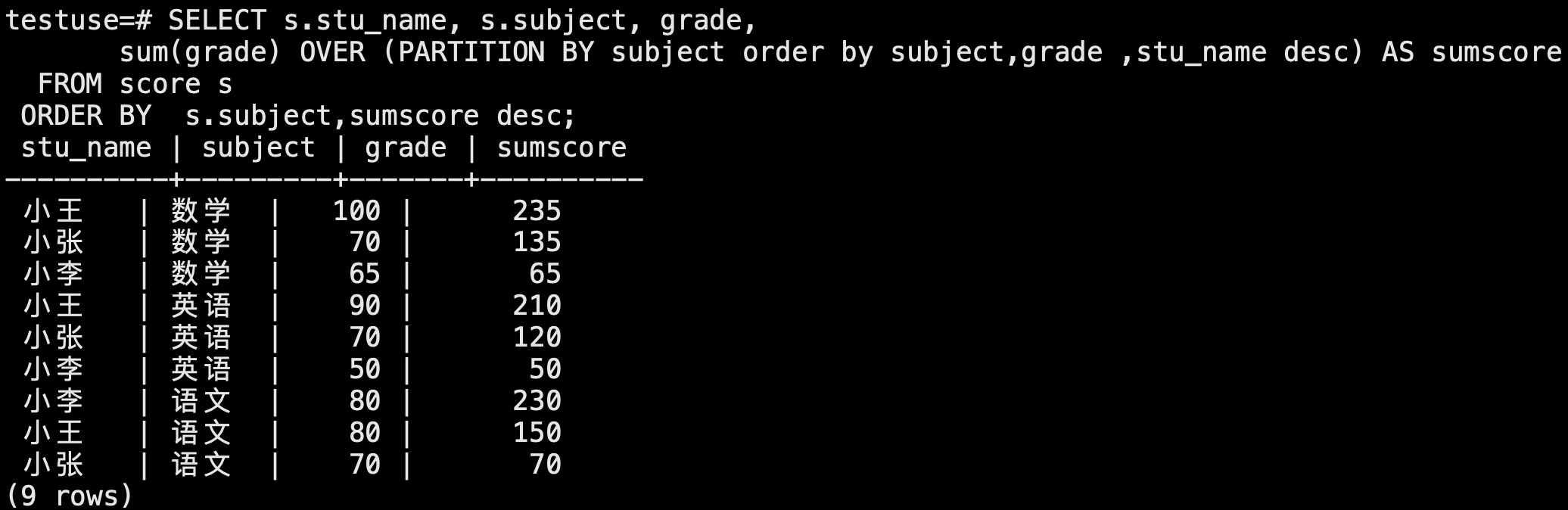
SELECT s.stu_name, s.subject, grade,
sum(grade) OVER (PARTITION BY subject order by subject,grade ,stu_name desc) AS sumscore
FROM score s
ORDER BY s.subject,sumscore desc;
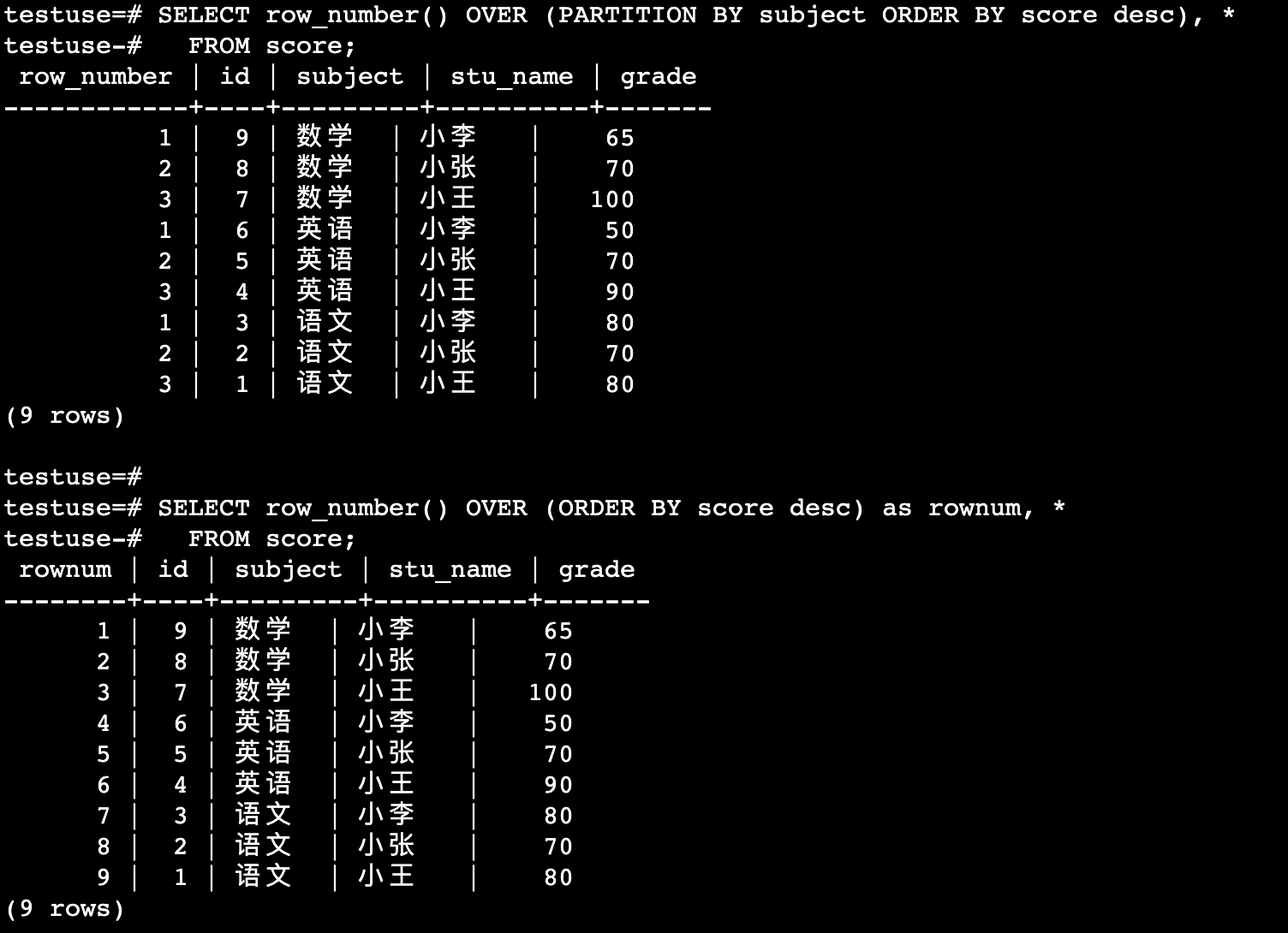
row_number()
对结果集分组后的数据标注行号,从 1 开始
SELECT row_number() OVER (PARTITION BY subject ORDER BY score desc), *
FROM score;
SELECT row_number() OVER (ORDER BY score desc) as rownum, *
FROM score;
rank()
当组内某行字段值相同时,行号重复并且行号产生间隙
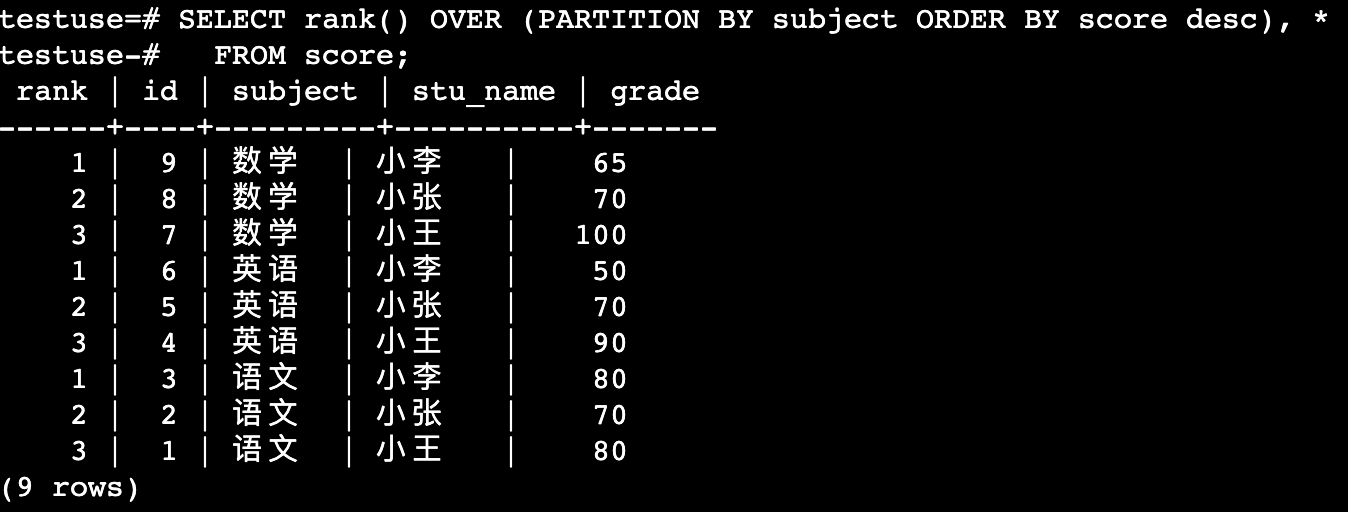
SELECT rank() OVER (PARTITION BY subject ORDER BY score desc), *
FROM score;
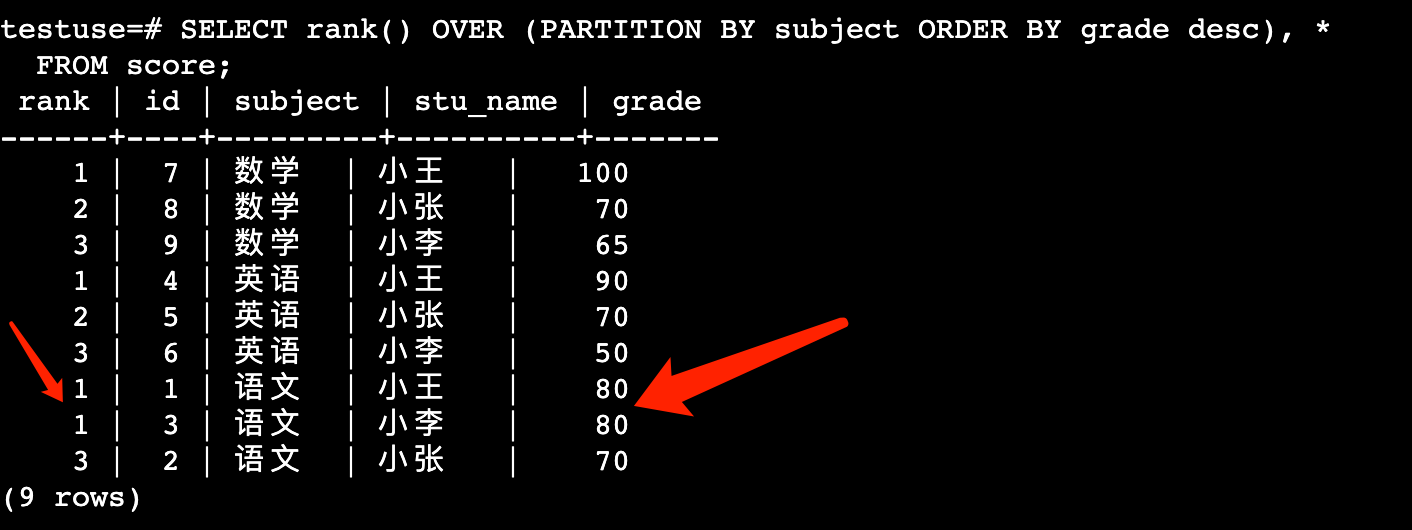
SELECT rank() OVER (PARTITION BY subject ORDER BY grade desc), *
FROM score;
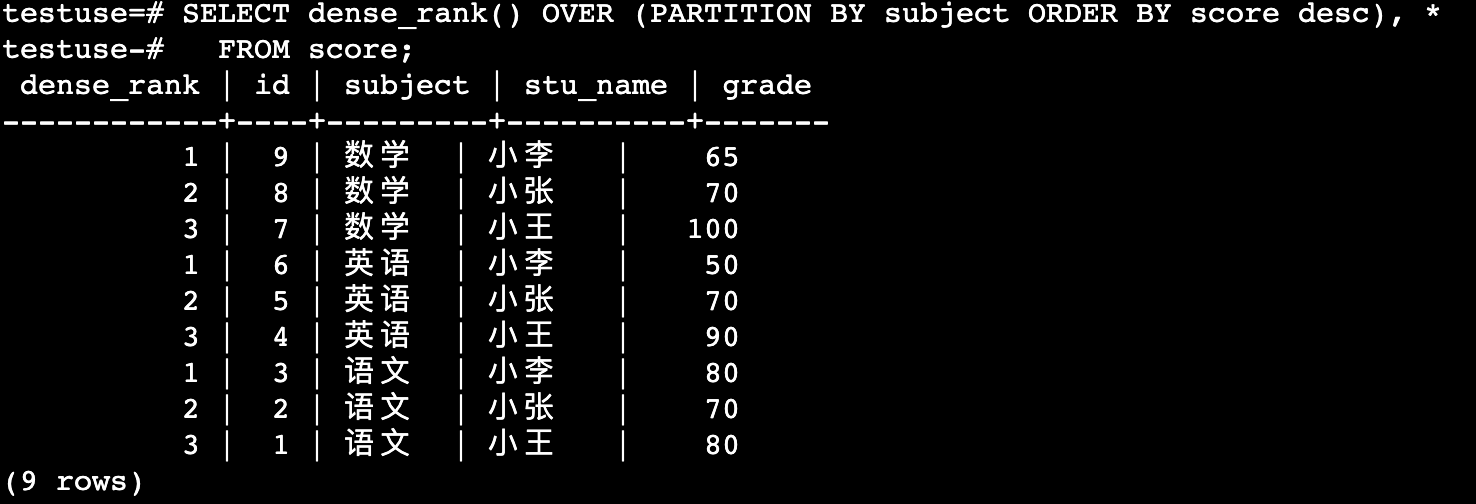
dense_rank()
当组内某行字段值相同时,虽然行号重复,但行号不产生间隙
SELECT dense_rank() OVER (PARTITION BY subject ORDER BY score desc), *
FROM score;
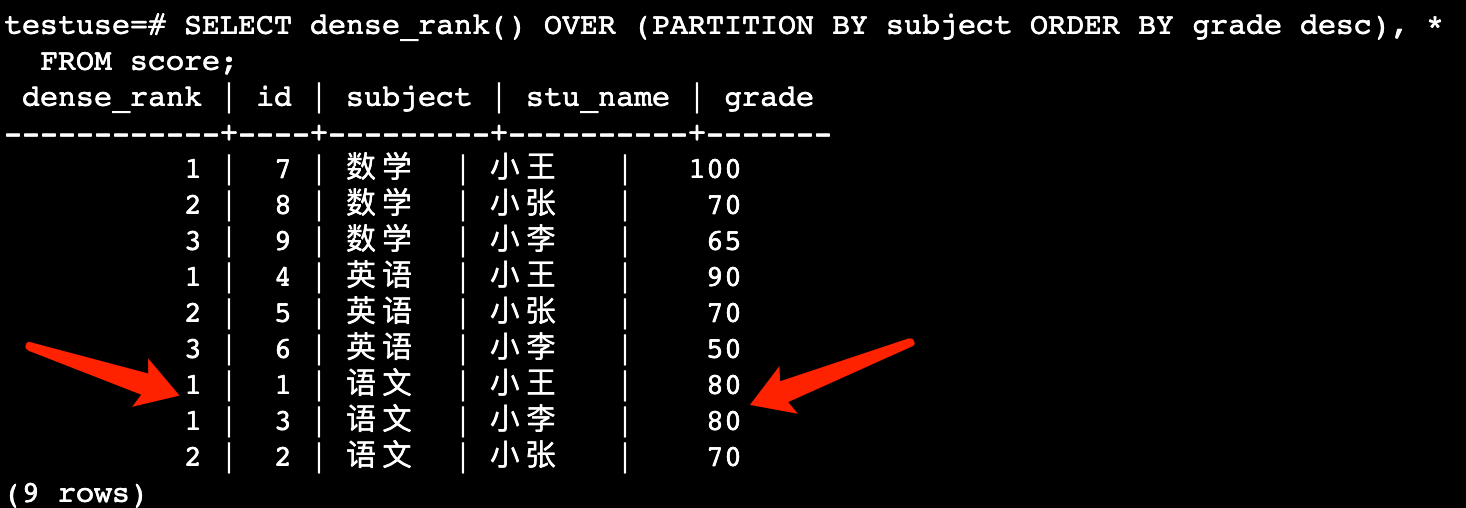
SELECT dense_rank() OVER (PARTITION BY subject ORDER BY grade desc), *
FROM score;
3.4 时间函数
几个表示时间的函数
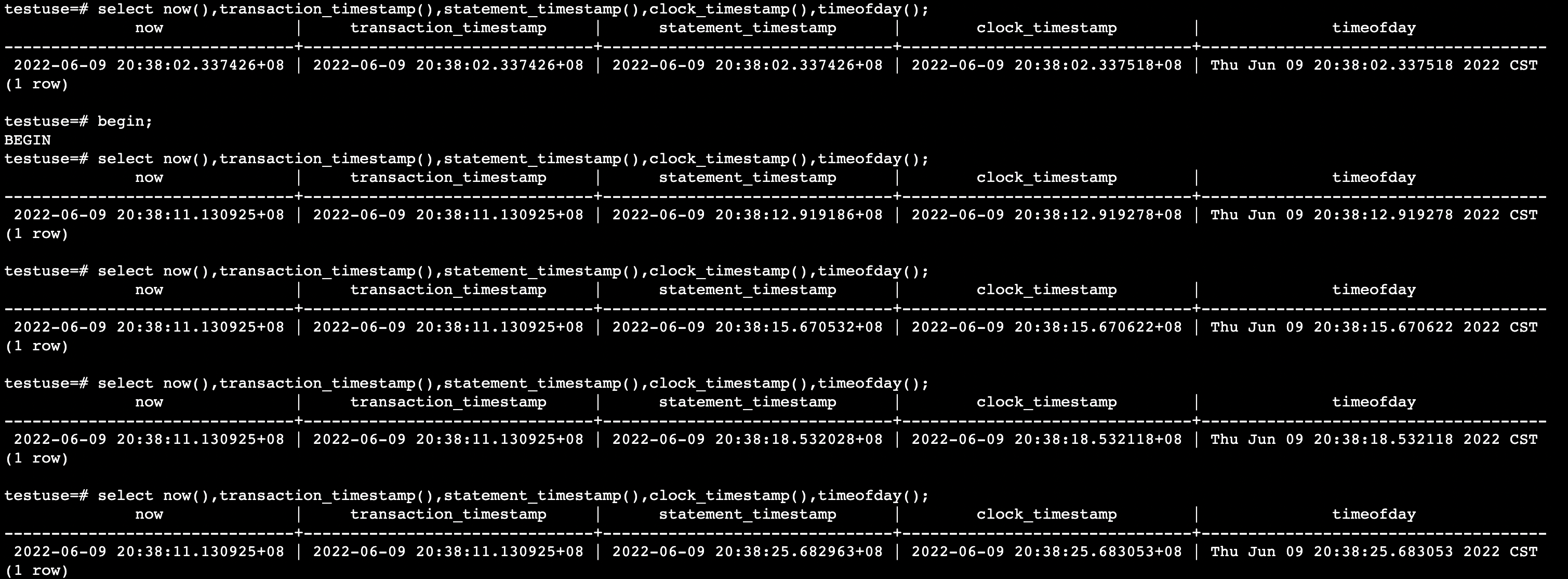
now() transaction_timestamp() statement_timestamp() clock_timestamp() timeofday()
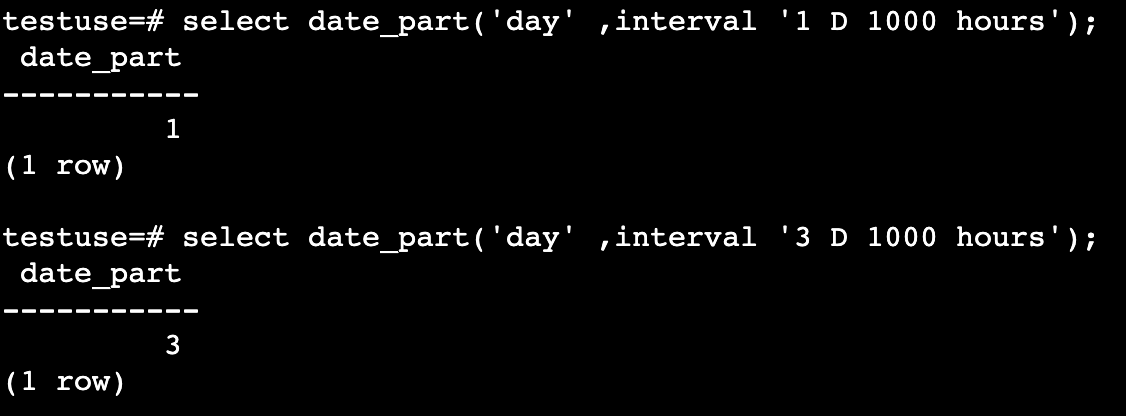
date_part
date_part(text, timestamp/interval)
获得子域(等价于extract);

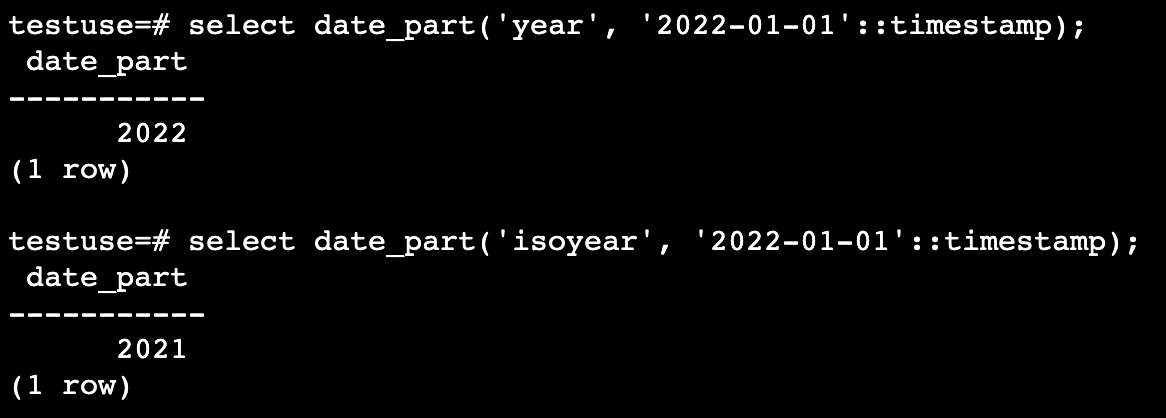
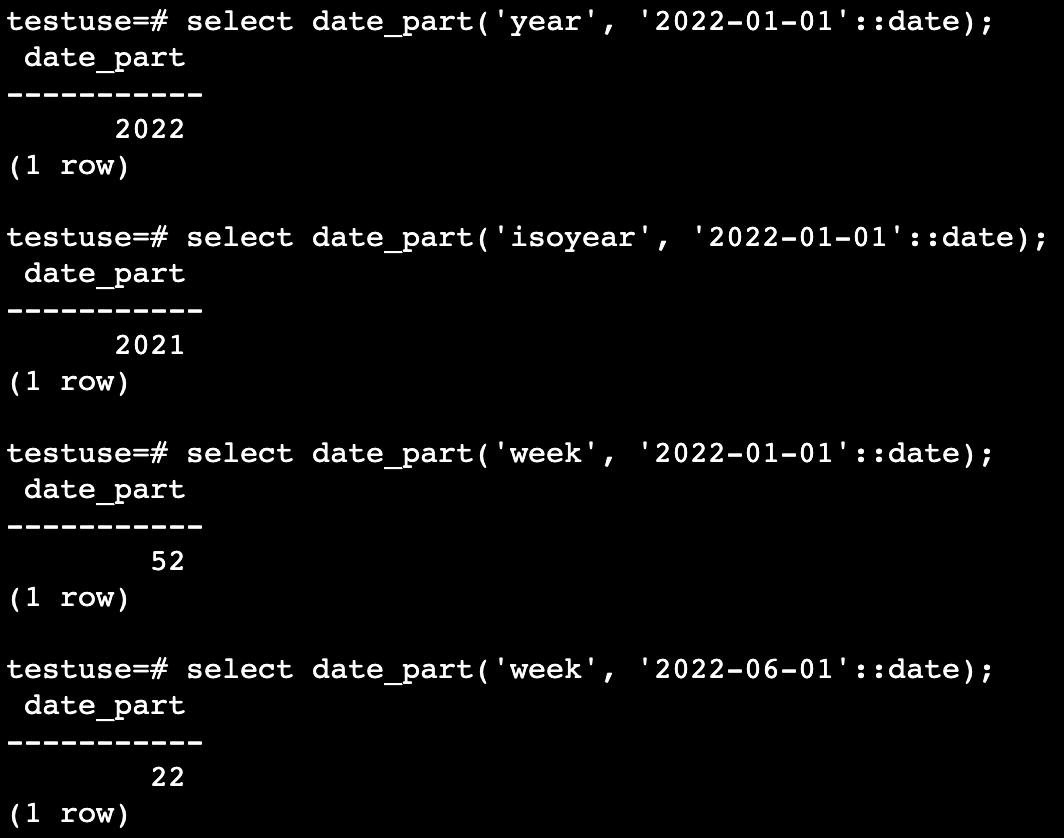
注意 year 和 isoyear
testuse=# select date_part('year', '2022-01-01'::timestamp);
date_part
-----------
2022
(1 row)
testuse=# select date_part('isoyear', '2022-01-01'::timestamp);
date_part
-----------
2021
(1 row)
date_trunc
date_trunc(field, source [, time_zone ])
*source是类型timestamp或interval的值表达式(类型date和 time的值都分别被自动转换成timestamp, timestamp with time zone,或者interval)。field*选择对输入值选用什么样的精度进行截断。返回的值是timestamp, timestamp with time zone,类型或者所有小于选定的 精度的域都设置为零(或者一,对于日期和月份)的interval。
*field*的有效值是∶
microseconds
milliseconds
second
minute
hour
day
week
month
quarter
year
isoyear
decade
century
millennium
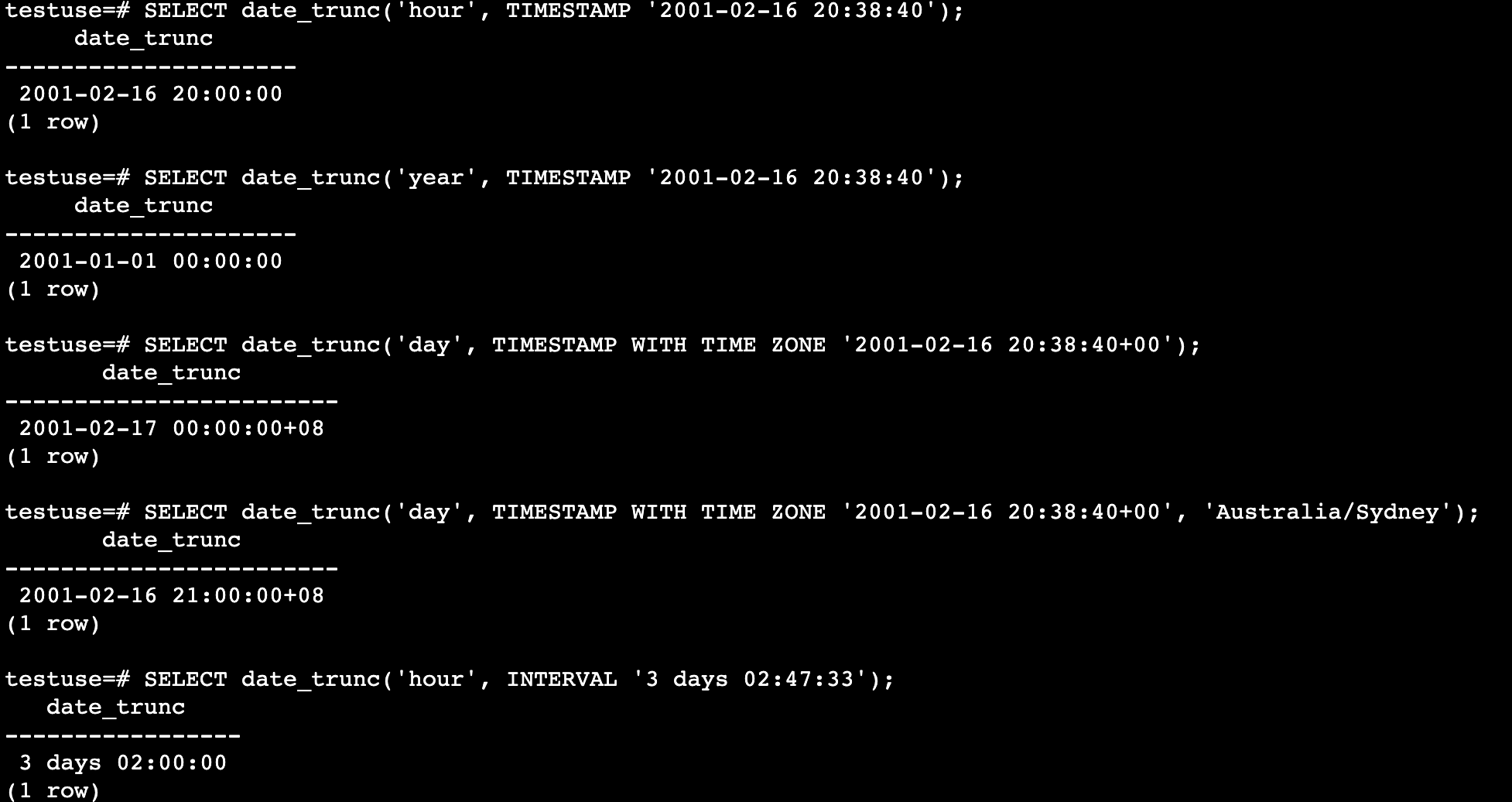
延时执行
pg_sleep(seconds)
pg_sleep_for(interval)
pg_sleep_until(timestamp with time zone)
示例:
SELECT pg_sleep(1.5);
SELECT pg_sleep_for('5 minutes');
SELECT pg_sleep_until('tomorrow 03:00');
pg_sleep_until并不保证能刚好在指定的时刻被唤醒,但它不会 在比指定时刻早的时候醒来。
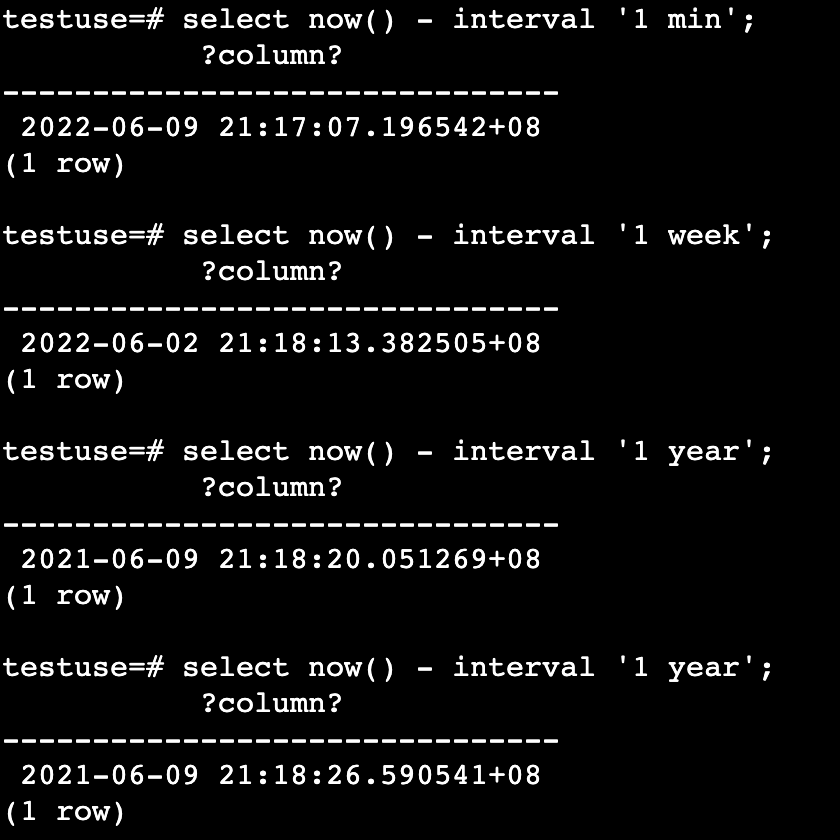
时间的计算
testuse=# select now() - interval '1 min';
testuse=# select now() - interval '1 week';
testuse=# select now() - interval '1 year';
testuse=# select now() - interval '1 year';
| Abbreviation | Meaning |
|---|---|
| Y | Years |
| M | Months (in the date part) |
| W | Weeks |
| D | Days |
| H | Hours |
| M | Minutes (in the time part) |
| S | Seconds |
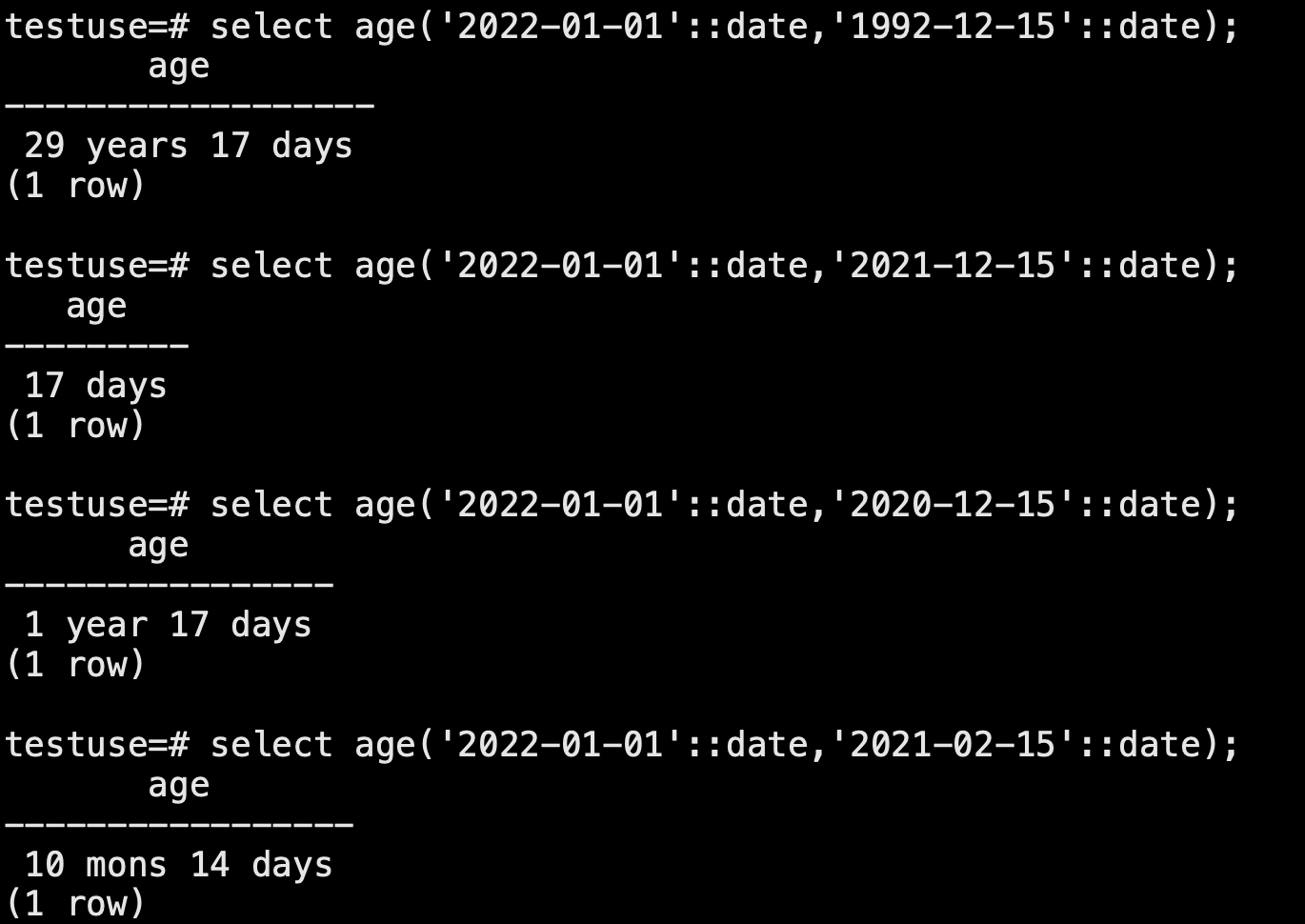
时间差
age(timestamp,timestamp) 或者时间直接相减
testuse=# select age(now(), timestamp '1987-01-01');
age
----------------------------------------
35 years 5 mons 8 days 21:20:11.979961
(1 row)
testuse=# select now()-'1987-01-01'::timestamp;
?column?
----------------------------
12943 days 21:20:33.405887
(1 row)
```
