




原文地址:Oracle Partition and Performance of massive/concurrent Inserts
原文作者: Lazhar Felahi
对于客户,我必须检查分区是否可以提高大量并发插入的性能。
目标是通过 dbms_parallel_execute 包并行执行多个插入(我之前的博客“使用DBMS_PARALLEL_EXECUTE 并行化您的 Oracle 插入”解释了如何使用dbms_parallel_execute)。
这个想法是在 2 个表中插入超过 2000 万行:
- 一张未分区的表 –> DBI_FK_NOPART
- 以 HASH 分区的一张表 –> DBI_FK_PART
- 两个表具有相同的列、相同的索引但类型不同:
分区表上的所有索引都是全局的:
- 创建索引……按哈希(……)进行全局分区……。
- 未分区表上的所有索引都正常
- 创建索引…开…
--Table DBI_FK_PART --> PARTITIONED SQL> select TABLE_NAME,PARTITION_NAME from dba_tab_partitions where table_name = 'DBI_FK_PART'; TABLE_NAME PARTITION_NAME ------------------- -------------------------------------------------------------------------------------------------------------------------------- DBI_FK_PART SYS_P9797 DBI_FK_PART SYS_P9798 DBI_FK_PART SYS_P9799 DBI_FK_PART SYS_P9800 DBI_FK_PART SYS_P9801 DBI_FK_PART SYS_P9802 DBI_FK_PART SYS_P9803 DBI_FK_PART SYS_P9804 DBI_FK_PART SYS_P9805 DBI_FK_PART SYS_P9806 DBI_FK_PART SYS_P9807 TABLE_NAME PARTITION_NAME ------------------- -------------------------------------------------------------------------------------------------------------------------------- DBI_FK_PART SYS_P9808 DBI_FK_PART SYS_P9809 DBI_FK_PART SYS_P9810 DBI_FK_PART SYS_P9811 DBI_FK_PART SYS_P9812 DBI_FK_PART SYS_P9813 DBI_FK_PART SYS_P9814 DBI_FK_PART SYS_P9815 DBI_FK_PART SYS_P9816 DBI_FK_PART SYS_P9817 DBI_FK_PART SYS_P9818 TABLE_NAME PARTITION_NAME ------------------- -------------------------------------------------------------------------------------------------------------------------------- DBI_FK_PART SYS_P9819 DBI_FK_PART SYS_P9820 DBI_FK_PART SYS_P9821 DBI_FK_PART SYS_P9822 DBI_FK_PART SYS_P9823 DBI_FK_PART SYS_P9824 DBI_FK_PART SYS_P9825 DBI_FK_PART SYS_P9826 DBI_FK_PART SYS_P9827 DBI_FK_PART SYS_P9828 32 rows selected. --TABLE DBI_FK_NOPART --> NOT PARTITIONED SQL> select TABLE_NAME,PARTITION_NAME from dba_tab_partitions where table_name = 'DBI_FK_NOPART'; no rows selected SQL>复制
每个表有超过 12 亿行:
SQL> select count(*) from xxxx.dbi_fk_nopart; COUNT(*) ---------- 1241226011 1 row selected. SQL> select count(*) from xxxx.dbi_fk_part; COUNT(*) ---------- 1196189234 1 row selected.复制
让我们检查两个表的最大主键:
SQL> select max(pkey) from xxxx.dbi_fk_part; MAX(PKEY) ---------- 9950649803 1 row selected. SQL> select max(pkey) from xxxx.dbi_fk_nopart; MAX(PKEY) ---------- 9960649804 1 row selected. SQL>复制
让我们创建 2 个过程:
“test_insert_nopart” 插入到未分区的表中 “DBI_FK_NOPART”
“test_insert_part” 插入到分区“DBI_FK_PART”的表中
create or replace NONEDITIONABLE procedure test_insert_nopart is v_sql_stmt varchar2(32767); v_pkey number; l_chunk_id NUMBER; l_start_id NUMBER; l_end_id NUMBER; l_any_rows BOOLEAN; l_try NUMBER; l_status NUMBER; begin DBMS_OUTPUT.PUT_LINE('start : '||to_char(sysdate,'hh24:mi:ss')); begin DBMS_PARALLEL_EXECUTE.DROP_TASK(task_name => 'TASK_NAME'); exception when others then null; end; DBMS_PARALLEL_EXECUTE.CREATE_TASK(task_name => 'TASK_NAME'); --We create 3 chunks DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(task_name => 'TASK_NAME',sql_stmt =>'SELECT NUM_COL,NUM_COL+10 FROM TEST_TAB WHERE ROWNUM < 10001', by_rowid => false); SELECT max(pkey) into v_pkey FROM XXXX.DBI_FK_NOPART; --I will Insert 1000 rows for each chunks, each chunks will work with different session_id v_sql_stmt := 'declare s varchar2(16000); vstart_id number := :start_id; vend_id number:= :end_id; table_name varchar2(30); v_pkey number; begin EXECUTE IMMEDIATE ''SELECT max(pkey) FROM XXXX.DBI_FK_NOPART'' INTO v_pkey; for rec in 1..1000 loop s:=''INSERT /*TEST_INSERT_DBI_FK_NOPART*/ INTO XXXX.DBI_FK_NOPART ( pkey, boid, metabo, lastupdate, processid, rowcomment, created, createduser, replaced, replaceduser, archivetag, mdbid, itsforecast, betrag, itsopdetherkunft, itsopdethkerstprm, itsfckomppreisseq, clsfckomppreisseq, issummandendpreis, partitiontag, partitiondomain, fcvprodkomppkey, fckvprdankomppkey, session_id ) VALUES ( 1 +'||v_pkey||' , ''''8189b7c7-0c36-485b-8993-054dddd62708'''' , -695, sysdate, ''''B.3142'''' , NULL, SYSDATE, ''''XXXX_DEV_DBITEST'''' , SYSDATE, NULL, NULL, NULL, ''''8a9f1321-b3ec-46d5-b6c7-af1c7fb5167G'''' , 0, ''''ae03b3fc-b31c-433b-be0f-c8b0bdaa82fK'''' , NULL, ''''5849f308-215b-486b-95bd-cbd7afe8440H'''', -251, 0, 201905, ''''E'''', :start_id, :end_id, SYS_CONTEXT(''''USERENV'''',''''SESSIONID''''))''; execute immediate s using vstart_id, vend_id; commit; end loop; end;'; dbms_output.put_Line (v_sql_stmt); DBMS_PARALLEL_EXECUTE.RUN_TASK (task_name => 'TASK_NAME', sql_stmt =>v_sql_stmt, language_flag => DBMS_SQL.NATIVE, parallel_level => 4 ); DBMS_OUTPUT.PUT_LINE('end : '||to_char(sysdate,'hh24:mi:ss')); end; create or replace NONEDITIONABLE procedure test_insert_part is v_sql_stmt varchar2(32767); v_pkey number; l_chunk_id NUMBER; l_start_id NUMBER; l_end_id NUMBER; l_any_rows BOOLEAN; l_try NUMBER; l_status NUMBER; begin DBMS_OUTPUT.PUT_LINE('start : '||to_char(sysdate,'hh24:mi:ss')); begin DBMS_PARALLEL_EXECUTE.DROP_TASK(task_name => 'TASK_NAME'); exception when others then null; end; DBMS_PARALLEL_EXECUTE.CREATE_TASK(task_name => 'TASK_NAME'); --We create 3 chunks DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(task_name => 'TASK_NAME',sql_stmt =>'SELECT NUM_COL,NUM_COL+10 FROM TEST_TAB WHERE ROWNUM < 10001', by_rowid => false); SELECT max(pkey) into v_pkey FROM XXXX.DBI_FK_PART; --I will Insert 1000 rows for each chunks, each chunks will work with different session_id v_sql_stmt := 'declare s varchar2(16000); vstart_id number := :start_id; vend_id number:= :end_id; table_name varchar2(30); v_pkey number; begin EXECUTE IMMEDIATE ''SELECT max(pkey) FROM xxxx.DBI_FK_PART'' INTO v_pkey; for rec in 1..1000 loop s:=''INSERT /*TEST_INSERT_DBI_FK_PART*/ INTO xxxx.DBI_FK_PART ( pkey, boid, metabo, lastupdate, processid, rowcomment, created, createduser, replaced, replaceduser, archivetag, mdbid, itsforecast, betrag, itsopdetherkunft, itsopdethkerstprm, itsfckomppreisseq, clsfckomppreisseq, issummandendpreis, partitiontag, partitiondomain, fcvprodkomppkey, fckvprdankomppkey, session_id ) VALUES ( 1 +'||v_pkey||' , ''''8189b7c7-0c36-485b-8993-054dddd62708'''' , -695, sysdate, ''''B.3142'''' , NULL, SYSDATE, ''''xxxx_DBITEST'''' , SYSDATE, NULL, NULL, NULL, ''''8a9f1321-b3ec-46d5-b6c7-af1c7fb5167G'''' , 0, ''''ae03b3fc-b31c-433b-be0f-c8b0bdaa82fK'''' , NULL, ''''5849f308-215b-486b-95bd-cbd7afe8440H'''', -251, 0, 201905, ''''E'''', :start_id, :end_id, SYS_CONTEXT(''''USERENV'''',''''SESSIONID''''))''; execute immediate s using vstart_id, vend_id; commit; end loop; end;'; dbms_output.put_Line (v_sql_stmt); DBMS_PARALLEL_EXECUTE.RUN_TASK (task_name => 'TASK_NAME', sql_stmt =>v_sql_stmt, language_flag => DBMS_SQL.NATIVE, parallel_level => 4 ); DBMS_OUTPUT.PUT_LINE('end : '||to_char(sysdate,'hh24:mi:ss')); end;复制
现在让我们通过上面创建的过程在每个表中插入大约 2000 万行:
SQL> set timing on SQL> set autotrace on SQL> begin 2 test_insert_nopart; 3 end; 4 / PL/SQL procedure successfully completed. Elapsed: 00:06:30.34 SQL> begin 2 test_insert_part; 3 end; 4 5 / PL/SQL procedure successfully completed. Elapsed: 00:00:22.92 SQL> select max(pkey) from xxxx.dbi_fk_nopart; MAX(PKEY) ---------- 9980650809 SQL> select 9980650809 - 9960649804 from dual; 9980650809-9960649804 --------------------- 20001005 SQL> select max(pkey) from xxxx.dbi_fk_part; MAX(PKEY) ---------- 9980811483 SQL> select 9980811483 - 9950649803 from dual; 9980811483-9950649803 --------------------- 30161680复制
第一个结论:
- 在 06.30.34 分钟内已将大约 2000 万行插入到未分区“DBI_FK_NOPART”的表中
- 在 22 秒内已将大约 3000 万行插入到分区“DBI_FK_PART”的表中
与非分区表相比,在大表上执行大规模并发插入总是更快。
现在,让我们检查 OEM 图形以了解为什么插入 DBI_FK_PART 比 DBI_FK_NOPART 快 17 倍

在下午 03:40 到下午 3:46 之间,我们可以看到与 DBI_FK_NOPART 上的插入相关的峰值
在下午 03:49,我们可以看到与 DBI_FK_PART 相关的插入相关的非常小的峰值

如果我们只关注 INSERT 命令(第 1 行和第 4 行),则进入 DBI_FK_PART(表分区)的一个在 CPU(绿色)和 CONCURRENCY(紫色)上的等待比 DBI_FK_NOPART(表分区)中的 INSERT 更少,其中 I/O是事件最重要的。
让我们更详细地了解数据库正在等待两个 INSERT 的事件:
对于插入 DBI_FK_NOPART:
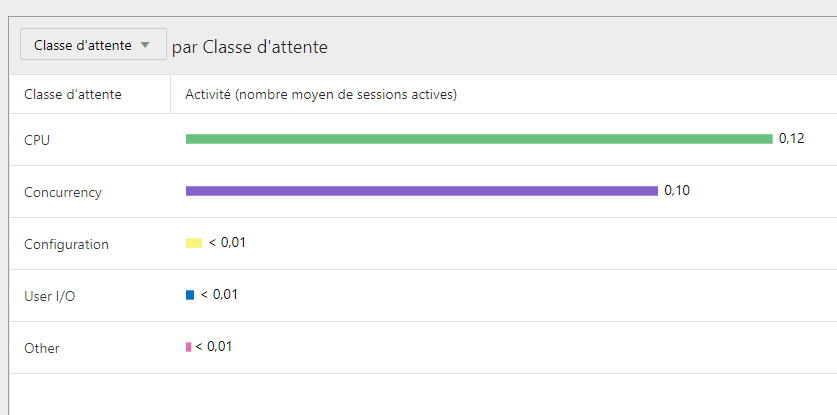
如果我们点击并发事件:

对于插入 DBI_FK_PART:

如果我们点击并发事件:

第二个结论
“db 文件顺序读取”事件似乎表明两个表之间的响应时间差异似乎是由于我们在每个表上创建的索引类型(分区表上的全局分区索引 VS 非分区表上的普通索引)。
由于可以在非分区表上创建全局分区索引,另一个“有趣的”测试(在本博客上没有完成)应该是用非分区表上的全局索引替换普通索引,并检查响应时间是否更快。
总而言之,如果我们有分区许可证,就性能而言,我们应该始终对在读取 (SELECT) 或写入 (INSERT) 中多次访问的大表进行分区。
