





目录
一、概述
1.1、NoSQL优势
大数据量,可以通过廉价服务器存储大量的数据,轻松摆脱传统mysql单表存储量级限制。
高扩展性,NoSQL去掉了关系数据库的关系型特性,很容易横向扩展,摆脱了以往老是纵向扩展的诟病。
高性能,NoSQL通过简单的key-value方式获取数据,非常快速。还有NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多。[redis等]
灵活的数据模型,NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
高可用,NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如mongodb通过mongos、mongo分片就可以快速配置出高可用配置。
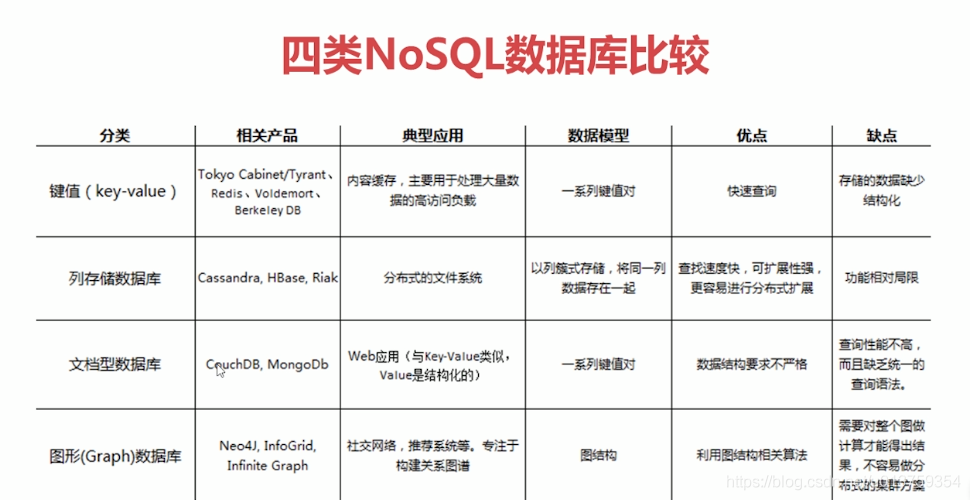
1.2、四类NoSQL对比
1.3、Redis概述
-
能干嘛?
1、内存存、储持久化 【数据库】
2、高速缓存 【缓存】
3、跨服务器发布订阅系统 【消息中间件MQ】
4、地图信息分析
5、计时器、计数器(浏览量)
-
为什么redis不用多线程?
**Redis是基于内存操作的,CPU不是Redis的性能瓶颈,其瓶颈是机器内存和网络带宽 **
-
为什么redis这么快?
1、redis是基于内存的,内存的读写速度非常快;
2、redis是单线程的,省去了很多上下文切换线程的时间;
3、redis使用多路复用技术,实现非阻塞IO。
-
什么是多路复用技术?
【传统处理IO】处理30个请求,第2个异常则后续全部阻塞
【多线程处理IO】处理30个请求,分身30个线程,一对一处理
【多路复用处理IO】处理30个请求,第2个异常则去执行其他正常的,不会造成阻塞
1.4、Docker安装配置Redis
1.4.1、安装配置
-
安装镜像
// 查看镜像 docker search redis // 拉取镜像 docker pull redis // 查看镜像 docker images -
配置文件
// 将配置文件redis.conf放到自定义目录/docker/redis目录下 // 修改启动默认配置 bind 127.0.0.1 // 注释掉这部分,用来限制redis只能本地访问 protected-mode no // 改为no, 默认yes表示开启保护模式,用来限制redis只能本地访问 daemonize no // 默认no,改为yes意为以守护进程方式启动,可后台运行,除非kill进程(可选) dir ./ //输入本地redis数据库存放文件夹(可选) appendonly yes // redis持久化(可选) databases 20 // 数据库个数,这里设置redis最多有20个数据库 -
启动redis容器
-
快速启动
docker run -itd --name myredis -p 6379:6379 redis -
指定配置文件启动
docker run \ -p 6379:6379 \ --name myredis \ -v /Users/yangmeng/docker/redis/redis.conf:/etc/redis/redis.conf \ -v /Users/yangmeng/docker/redis/data:/data \ -d redis\ redis-server /etc/redis/redis.conf-
参数说明
-p 6379:6379 // 端口映射,主机ip:容器ip --name myredis // 指定容器名称 -v /docker/redis/redis.conf:/etc/redis/redis.conf // 把本地redis.conf文件映射到容器 -v /opt/data/redis/data:/data // 挂载目录 -d redis // 后台运行 redis-server /etc/redis/redis.conf // 启动加载redis.conf
-
-
1.4.2、压力测试
redis自带压力测试,可以测试读写速度
-
进入redis容器
docker exec -it myredis /bin/bash -
压力测试
redis-benchmark -n 100000 -q
1.4.3、基本使用
-
进入容器
docker exec -it myredis /bin/bash -
连接访问redis
redis-cli -h localhost -p 6379 -
密码
config get requirepass # 获得密码 config set requirepass "123456" # 设置密码 auth 123456 # 登录
1.5、可视化客户端推荐
推荐一款免费、开源的可视化工具,支持
Windows、Linux和Mac,支持中英文切换,深色白色主题切换。
-
补充:在线版redis
redis提供了在线体验版, 可在线练习redis命令
1.6、redis.conf详解
说明
1gb => 1024*1024*1024 bytes #单位关系
units are case insensitive so 1GB 1Gb 1gB are all the same. #大小写不敏感
INCLUDES(配置文件)
include /path/to/other.conf #集成多个配置文件
NETWORK(网络)
bind 127.0.0.1 #可访问的ip
protected-mode yes #是否受保护
port 6379 #可访问的端口号
GENERAL(通用)
daemonize no # 以守护进程方式运行,默认为no改为yes
pidfile /var/run/redis_6379.pid # 如果上面改为yes,这里要指定进程文件
loglevel notice # 日志级别
logfile "" # 日志文件位置
databases 16 # 数据库数量,默认16个
always-show-logo yes # 是否总是显示开启时的logo
SNAPSHOTTING(快照(持久化))
save 900 1 # 900秒内有1次操作则进行持久化
save 300 10 # 300秒内有10次操作则进行持久化
save 60 10000 # 60秒内有10000次操作则进行持久化
stop-writes-on-bgsave-error yes # 持久化出错了,是否要继续工作
dbfilename dump.rdb # 是否压缩rdb文件(持久化会持久化在.rdb.aof)「会消耗内存」
rdbchecksum yes # 保存rdb文件时进行检查校验
dir ./ # 持久化rdb文件保存目录
REPLICATION (主从复制)
replicaof 127.0.0.1 6379 # 配置主节点的ip端口号
masterauth 123456 # 配置主节点的密码
SECURITY(安全)
requirepass 123456 # 设置密码
CLIENTS(限制)
maxclients 10000 # 最大连接客户端数
maxmemory <bytes> # 最大内存容量
maxmemory-policy noeviction # 内存达到上限后的处理策略
volatile-lru #从已设置过期时间的内存数据集中挑选最近最少使用的数据 淘汰;
volatile-ttl #从已设置过期时间的内存数据集中挑选即将过期的数据 淘汰;
volatile-random #从已设置过期时间的内存数据集中任意挑选数据 淘汰;
allkeys-lru #从内存数据集中挑选最近最少使用的数据 淘汰;
allkeys-random #从数据集中任意挑选数据 淘汰;
no-enviction #禁止驱逐数据。(默认淘汰策略。当redis内存数据达到maxmemory,在该策略下,直接返回OOM错误);
APPEND ONLY MODE (aof模式配置)
appendonly no # 默认是不开启aof模式,默认使用rdb
appendfilename "appendonly.aof" # 持久化文件名
appendfsync everysec # sync(同步)频率:每秒一次 「可能丢失这1s的数据」
# appendfsync always # 每次修改都会同步(消耗性能)
# appendfsync no # 不同步,操作系统自己同步,速度最快
二、Redis数据类型
-
key
setkeys *existsmoveexpirettlgettype -
String
【增】
setsetexsetnxmsetmsetnx【删】
del【改】
appendgetsetincrdecrincrbydecrbysetrange【查】
strlengetmgetgetrange -
List
【增】
lpushrpushlinsert【删】
lpopropplrem【改】
ltrimrpoplpush【查】
lrangelindexllen -
Set
【增】
sadd【删】
sremspop【改】
smove【查】
smemberssismembersrandmembersintersunionsdiff -
Hash
【增】
hsethsetnx【删】
hdel【改】
hsethincrby【查】
hgethgetallhkeyshvals -
Zset
【增】
zadd【删】
zrem【改】
【查】
zcardzrangezrangebyscorezrevrangezcount -
Geospatial
getaddgeoposgeodistgeoradiusgeoradiusbymembergeohash基于Zset,也可以使用Zset的一些方法(
zrangezrem) -
Hyperloglog
pfaddpdcountpfmerge -
Bitmaps
setbitgetbitbitcount
2.1、Redis-Key
setkeys *existsmoveexpirettlgettype
> set name yang
OK
> keys *
name
> exists name
1
127.0.0.1:6379> move name 1
1
127.0.0.1:6379> expire name 10
1
127.0.0.1:6379> ttl name
3
127.0.0.1:6379> ttl name
-2
127.0.0.1:6379> get name
null
127.0.0.1:6379> type name
string
2.2、五大基本数据类型
2.2.1、String
-
增
setsetexsetnxmsetmsetnx
> set name yang # 设置值(不存在新增,存在覆盖) OK > setex name 10 haha # 设置过期时间 OK > setnx name haha # 设置值(不存在新增,存在不覆盖) 1 > setnx name haha 0 > mset k1 v1 k2 v2 k3 v3 # 批量设置 OK > msetnx k1 v1 k4 v4 # msetnx原子性操作,要么都成功要么都失败 0 -
删
del
> del name aaa 1 -
改
appendgetset
> append name meng # 追加,没有则新增 8 > getset db redis # 先获取,再update null > get db redis > getset db mongodb redis > get db mongodbincrdecrincrbydecrby
> set views 0 OK > incr views # 自增 1 > incr views 2 > decr views # 自减 1 > incrby views 10 # 指定量增 11 > decrby views 5 # 指定量减 6setrange
> set title goodgoodstudy OK # 替换 setrange > setrange title 1 xx # 从指定位置开始逐一替换 13 > get title gxxdgoodstudy -
查
strlengetmgetgetrange
> strlen name # 获得值的长度 8 > get name # 获得值 yang1234 > mget k1 k2 k3 # 批量查询 v1 v2 v3 # 截取查询 getrange > getrange title 0 3 # 全闭区间 good > getrange title 0 -1 goodgoodstudy
2.2.2、List
栈、队列、阻塞队列
-
增
lpushrpushlinsert
> lpush name yang # 从左放入 1 > lpush name n1 n2 3 > rpush rname n1 n2 # 从右放入 2 > linsert listnew before hello2 hello6 # 增加值在某值前 3 > linsert listnew after hello2 hello8 # 增加值在某值后 4 > lrange listnew 0 -1 hello3 hello6 hello2 hello8 -
删
lpopropplrem
> lpop name # 左边删除1个 n2 > rpop name # 右边删除1个 yang > lrem rname 2 n2 # 删除指定值(指定删除个数) 1 > lrange rname 0 -1 n1 -
改
ltrimrpoplpush
> lpush list1 hello1 hello2 hello3 hello4 4 > ltrim list1 0 2 # 切片 OK > lrange list1 0 -1 hello4 hello3 hello2 > rpoplpush list1 listnew # 从列表右边移除一值,放入新列表中 hello2 > lrange list1 0 -1 hello4 hello3 > lrange listnew 0 -1 hello2 -
查
lrangelindexllen
> lrange name 0 -1 # 查询列表内容 n2 n1 yang > lindex rname 1 # 通过下标索引 n2 > llen rname # 查看列表长度 2
2.2.3、Set
-
增
> sadd myset hello woeld # 新增(可以直接新增多个) 1 -
删
> srem myset hello # 移除指定成员 1 > spop myset # 随机移除一个成员 hello2 > spop myset 2 # 随机移除多个成员 hello hello3 -
改
> smove myset myset2 hello # 指定一个值,移动到别的集合 1 -
查
> smembers myset # 查看所有成员 hello > sismember myset hello # 查看某成员是否在集合中 1 > scard myset # 查看成员个数 1 # 随机 > srandmember myset # 随机选出一个成员 hello2 > srandmember myset 2 # 随机选出指定个数成员 hello2 hello3 # 交并差 > sinter myset1 myset2 # 交集 3 > sunion myset1 myset2 # 并集 1 2 3 4 5 > sdiff myset1 myset2 # 差集 1 2
2.2.4、Hash
【String】 key: StringValue -------->「key-value」
【Hash】 key: dictValue -------->「字段:key-value」
-
增
> hset myhash k1 hello k2 hash # 新增(可设置多个值,存在则覆盖) 2 > hsetnx myhash k2 hashnew # 新增(存在则设置失败) 0 -
删
> hdel myhash k1 # 删除指定字段下的指定key-value 1 -
改
> hset myhash k3 5 1 > hincrby myhash k3 2 # 定量增 7 -
查
> hget myhash k1 # 查看指定字段的指定key的值 hello > hgetall myhash # 查看指定字段的所有key-value k1 hello k2 hash > hkeys myhash # 只获得key k1 k2 > hvals myhash # 只获得value hello hash
2.2.5、Zset
在set基础上,增加了一个score,set k1 v1 zset k1 score1 v1
-
增
> zadd salary 2000 p1 3000 p2 4000 p3 3 -
删
> zrem salary p2 #移除指定元素 1 -
改
-
查
> zcard salary # 查看有序集合成员数 2 > zrange salary 0 -1 # 查看所有(默认顺序) p1 p2 p3 > zrangebyscore salary -inf +inf # 查看所有(升序) p1 p2 p3 > zrevrange salary 0 -1 # 查看所有(降序) p3 p2 p1 > zrangebyscore salary -inf +inf withscores # 查看所有(升序、携带score) p1 2000 p2 3000 p3 4000 > zrangebyscore salary -inf 3000 withscores # 查看范围内(升序、携带score) p1 2000 p2 3000 > zcount salary 2000 4000 # 查看区间内成员数 2
2.3、三大特殊数据类型
2.3.1、Geospatial
-
getadd
【添加经纬度】getadd key 经度 维度 value …
> geoadd china:city 116.41667 39.91667 beijing 121.43333 34.50000 shanghai 114.31667 30.51667 wuhan 113.65000 34.76667 zhengzhou # 添加城市经纬度 4 -
geopos
【查看经纬度】
> geopos china:city wuhan # 查看经纬度 114.31666821241378784 30.51667020693319188 -
geodist
【计算距离】m:米 km:千米 mi:英里 ft:英尺
> geodist china:city wuhan beijing km # 计算两地距离(km) 1062.7024 -
georadius
【指定经纬度查询距离范围内成员】georadius key 经度 维度 距离 单位 [withdist/withcoord] [count num]
> georadius china:city 114.31 30.5166 2000 km # 查看指定位置2000km以内的城市 wuhan zhengzhou shanghai beijing > georadius china:city 114.31 30.5166 2000 km withdist # 查看指定位置2000km以内的城市(含距离) wuhan 0.6390 zhengzhou 476.7400 shanghai 801.3563 beijing 1062.8185 > georadius china:city 114.31 30.5166 2000 km withcoord # 查看指定位置2000km以内的城市(含位置) wuhan 114.31666821241378784 30.51667020693319188 zhengzhou 113.64999979734420776 34.76667012617188135 shanghai 121.4333304762840271 34.49999971716130887 beijing 116.41667157411575317 39.91667095273589183 > georadius china:city 114.31 30.5166 2000 km withcoord count 2 # 查看指定位置2000km以内的城市(含位置&取最近的2个) wuhan 114.31666821241378784 30.51667020693319188 zhengzhou 113.64999979734420776 34.76667012617188135 -
georadiusbymember
【指定value查询距离范围内成员】georadius key value 距离 单位 [withdist/withcoord] [count num]
> georadiusbymember china:city wuhan 2000 km withcoord count 2 # 查看指定值2000km以内的城市(含位置&取最近的2个) wuhan 114.31666821241378784 30.51667020693319188 zhengzhou 113.64999979734420776 34.76667012617188135 -
geohash
【指定value将其经纬度转为Geohash】
> geohash china:city beijing wuhan # 将指定value将其经纬度转为Geohash wx4g14s53n0 wt3m976u7r0 -
补充
GEO底层实现原理其实就是Zset,可以使用Zset的命令来操作geo
> zrange china:city 0 -1 wuhan zhengzhou shanghai beijing > zrem china:city shanghai 1
2.3.2、Hyperloglog
基于统计学算法实现,占用的内存是固定的,2^64个不同的元素,只需要12kb内存
可用于统计uv,但是会有0.81%的错误率
-
pfadd
> pfadd mykey a b c d e f g # 添加元素 1 > pfadd mykey2 f g h i j k l 1 -
pfcount
> pfcount mykey # 统计元素个数 7 -
pfmerge
> pfmerge mykey3 mykey mykey2 # mykey3 = mykey U mykey2 OK > pfcount mykey3 12
2.3.3、Bitmaps
位存储
用于存储只有两个选择项的值
-
setbit
> setbit daka 1 0 # 存值 0 > setbit daka 2 1 0 > setbit daka 3 1 0 > setbit daka 4 0 0 -
getbit
> getbit daka 2 # 查指定值 1 -
bitcount
> bitcount daka # 计数(唯1的求和) 2
三、Redis事务
redis的事务不保证原子性
3.1、基本事务操作
-
事务流程
> multi # 1、开启事务 OK > set k1 v1 # 2、命令入队 QUEUED > get k1 QUEUED > exec # 3、执行事务 OK v1 -
取消事务
在关闭事务之前,可以取消事务,队中命令则不会被执行
> multi # 1、开启事务 OK > set k1 v1 # 2、命令入队 QUEUED > discard # 3、执行事务 > OK -
异常
-
编译时异常
命令错误导致的异常
事务中所有命令都不会被执行(原子性)
> multi OK > set k1 v1 QUEUED > get # 命令错误导致的异常 QUEUED > get k1 QUEUED > exec ReplyError: EXECABORT Transaction discarded because of previous errors. # 全部失败 -
运行时异常
类似于java中0/1的异常
事务中其他命令可以正常被执行(非原子性)
> set k1 v1 OK > multi OK > set k2 v2 QUEUED > incr k1 # 运行异常(k1是字符串不能+1) QUEUED > get k2 QUEUED > exec OK (error) ERR value is not an integer or out of range # 抛出运行异常 "v2" # 其他命令照常执行
-
3.2、Redis乐观锁
-
乐观锁悲观锁
【悲观锁】
很悲观,认为任何时候都会出现问题,所以,无论什么时候都会加锁
【乐观锁】
不加锁,监控值,更新数据的时候判断一下在该事务期间是否有人修改过数据
-
测试乐观锁
使用watch监视,unwatch取消监视
- watch监视
> watch mymoney #监控 > OK > multi # 开启监听 OK > incrby mymoney 10 # 操作mymoney, 与此同时,另外一个连接执行incrby mymoney 10 QUEUED > get mymoney QUEUED > exec # 执行事务,则执行失败 (nil)-
unwatch取消监视
事务执行完就自动执行了unwatch,不用再输入unwatch
> watch mymoney #监控 > OK > unwatch mymoney #取消监控 > OK > multi # 开启监听 OK > incrby mymoney 10 # 操作mymoney, 与此同时,另外一个连接执行incrby mymoney 10 QUEUED > get mymoney QUEUED > exec # 执行事务,执行成功 (integer) 120 "120"
四、Jedis
Java操作redis
4.1、Jedis基本操作
import redis.clients.jedis.Jedis;
public class TestJedis {
public static void main(String[] args) {
// new jedis对象
Jedis jedis = new Jedis("127.0.0.1", 6379);
// ping
System.out.println(jedis.ping());
}
}
4.2、Jedis执行事务
public class TestRedis {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
// 开启事务
Transaction multi = jedis.multi();
try{
multi.set("k1", "v1");
int i = 1/0; // 故意让代码运行时异常
multi.exec(); // 执行事务
} catch (Exception e) {
multi.discard(); // 放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("k1"));
}
}
}
五、SpringBoot集成Redis
5.1、SpringBoot缓存原理
5.1.1、原理探究
-
SpringBoot缓存配置类
SpringBoot提供了10个配置类,其中SimpleCacheConfiguration是默认配置类
org.springframework.boot.autoconfigure.cache.GenericCacheConfiguration org.springframework.boot.autoconfigure.cache.JCacheCacheConfiguration org.springframework.boot.autoconfigure.cache.EhCacheCacheConfiguration org.springframework.boot.autoconfigure.cache.HazelcastCacheConfiguration org.springframework.boot.autoconfigure.cache.InfinispanCacheConfiguration org.springframework.boot.autoconfigure.cache.CouchbaseCacheConfiguration org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration org.springframework.boot.autoconfigure.cache.CaffeineCacheConfiguration org.springframework.boot.autoconfigure.cache.SimpleCacheConfiguration 【默认】 org.springframework.boot.autoconfigure.cache.NoOpCacheConfiguration -
SpringBoot各类缓存优先级
默认使用默认缓存,当导入其他依赖则默认缓存失效
导入多种依赖,则按照上面排序生效其中一个
// 源码 @ConditionalOnMissingBean({CacheManager.class}) @Conditional({CacheCondition.class}) class SimpleCacheConfiguration { SimpleCacheConfiguration() { }源码中,使用了注解@ConditionalOnMissingBean「判断当前需要注入Spring容器中的bean的实现类是否已经含有,有的话不注入,没有就注入(被覆盖)」 当注入其他缓存后,会在容器中注入对应缓存的CacheManager,此时,由于上述注解的原因,默认缓存则不再生效。 -
Cache结构
Cache结构是一个map: ConcurrentMap<Object, Object>
5.1.2、注解开发
-
配置debug
用于测试缓存是否生效
logging: level: com.ym.Demo.dao: debug -
开启缓存
需要在启动类上开启缓存
@EnableCaching //开启缓存 public class DemoApplication { ... } -
常用注解
-
@EnableCaching开启缓存功能,一般放在启动类上。
-
@CacheConfig
在类上使用,当该类有多个方法有同样的缓存操作时使用
-
@Cacheable用于
查询数据时,添加缓存 -
@CachePut
用于
新增数据时, 自动更新缓存 -
@CacheEvict用于
修改数据时,清空缓存 -
@Caching同一个方法上同时使用多种注解
-
5.1.3、注意事项
@Cacheable、**@CacheEvict**等缓存注解的方法1在同一类下被方法2调用,则方法2缓存不生效,若想缓存生效,可以再加一层Manager层,把方法1放入Manager层,用于对Service层通用能力的下沉。
5.2、SpringBoot快速集成Redis
-
导入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
添加配置
连接池参数要选择lettuce的(默认),不要配成jedis的,源码中jedis很多类不存在,因此是不生效的。
redis: host: port: password: max-active: 8 # 连接池最大连接数(使用负值表示没有限制) max-wait: -1 # 连接池最大阻塞等待时间(使用负值表示没有限制) max-idle: 8 # 连接池中的最大空闲连接 min-idle: 0 # 连接池中的最小空闲连接 timeout: 0 # # 连接超时时间(毫秒) -
直接使用
【缓存】直接使用SpringBoot的缓存注解即可
【操作】RedisTemplate || RedisUtils操作数据-
注意:实体类要实现Serializable(序列化)才能存入redis, 不然会报错
public class Table implements Serializable {}
-
5.3、编写Redis配置文件
5.3.1、配置文件解决核心问题
-
1、实现序列化后,redis工具中显示乱码
重写redisTemplate方法,使用fastjson进行序列化
-
2、设置默认过期时间
-
3、Redis挂掉后,报错且不走数据库
捕获Redis连接超时的异常,使Redis挂掉后,不影响正常访问
5.3.2、序列化问题源码分析
【结论】
1、默认使用的RedisTemplate设置的JDK序列化(序列化效果不好),可以自定义redisTemplate替换默认的
2、对象的两个泛型都是Object,需要强制转换为<String, Object>
3、由于String 是redis最常用的类型,所以单独提供了StringRedisTemplate
-
RedisAutoConfiguration源码
@Bean @ConditionalOnMissingBean( name = {"redisTemplate"} )// 可以自定义redisTemplate替换默认的 public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException { // 默认没有做而外的序列化(使用的RedisTemplate默认序列化),redis对象都是需要序列化的 // 两个泛型都是Object,需要强制转换为<String, Object> RedisTemplate<Object, Object> template = new RedisTemplate(); template.setConnectionFactory(redisConnectionFactory); return template; } @Bean @ConditionalOnMissingBean // 由于String 是redis最常用的类型,所以单独提供了StringRedisTemplate public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException { StringRedisTemplate template = new StringRedisTemplate(); template.setConnectionFactory(redisConnectionFactory); return template; } -
RedisTemplate源码
if (this.defaultSerializer == null) { // RedisTemplate默认配置了JDK序列化 this.defaultSerializer = new JdkSerializationRedisSerializer(...); }
5.2.3、Redis配置文件
-
使用fastjson序列化redis
public class FastJsonRedisSerializer<T> implements RedisSerializer<T> { private static final Charset DEFAULT_CHARSET = Charset.forName("UTF-8"); private Class<T> clazz; public FastJsonRedisSerializer(Class<T> clazz) { super(); this.clazz = clazz; } @Override public byte[] serialize(T t) throws SerializationException { if (null == t) { return new byte[0]; } return JSON.toJSONString(t, SerializerFeature.WriteClassName).getBytes(DEFAULT_CHARSET); } @Override public T deserialize(byte[] bytes) throws SerializationException { if (null == bytes || bytes.length <= 0) { return null; } String str = new String(bytes, DEFAULT_CHARSET); return (T) JSON.parseObject(str, clazz); } } -
Redis配置文件
@Slf4j @Configuration @EnableCaching @ConditionalOnClass(RedisOperations.class) @EnableConfigurationProperties(RedisProperties.class) public class RedisConfig extends CachingConfigurerSupport { // 【1】解决序列化问题 @Bean(name = "redisTemplate") @SuppressWarnings("unchecked") @ConditionalOnMissingBean(name = "redisTemplate") public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) { RedisTemplate<Object, Object> template = new RedisTemplate<>(); //使用fastjson序列化 FastJsonRedisSerializer fastJsonRedisSerializer = new FastJsonRedisSerializer(Object.class); // value值的序列化采用fastJsonRedisSerializer template.setValueSerializer(fastJsonRedisSerializer); template.setHashValueSerializer(fastJsonRedisSerializer); // key的序列化采用StringRedisSerializer template.setKeySerializer(new StringRedisSerializer()); template.setHashKeySerializer(new StringRedisSerializer()); template.setConnectionFactory(redisConnectionFactory); return template; } // 【2】设置key默认过期时间 @Bean public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) { return new RedisCacheManager(RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory), this.redisCacheConfiguration(1800), // 默认配置 this.initialCacheConfigurations()); // 指定key过期时间配置 } private Map<String, RedisCacheConfiguration> initialCacheConfigurations() { Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>(); return redisCacheConfigurationMap; } private RedisCacheConfiguration redisCacheConfiguration(Integer seconds) { Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig(); redisCacheConfiguration = redisCacheConfiguration.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)).entryTtl(Duration.ofSeconds(seconds)); return redisCacheConfiguration; } // 【3】配置redis挂掉后,捕获异常,不影响查询数据库 public CacheErrorHandler errorHandler() { CacheErrorHandler cacheErrorHandler = new CacheErrorHandler() { @Override public void handleCacheGetError(RuntimeException e, Cache cache, Object o) { RedisErrorException(e, o); } @Override public void handleCachePutError(RuntimeException e, Cache cache, Object o, Object o1) { RedisErrorException(e, o); } @Override public void handleCacheEvictError(RuntimeException e, Cache cache, Object o) { RedisErrorException(e, o); } @Override public void handleCacheClearError(RuntimeException e, Cache cache) { RedisErrorException(e, null); } }; return cacheErrorHandler; } protected void RedisErrorException(Exception exception,Object key){ log.error("redis异常:key=[{}], exception={}", key, exception.getMessage()); } }
六、Redis持久化
Redis是内存数据库,如果不将内存中数据保存到磁盘中,则断电即失,所以,Redis提供了持久化功能
6.1、RDB(Redis DataBase)
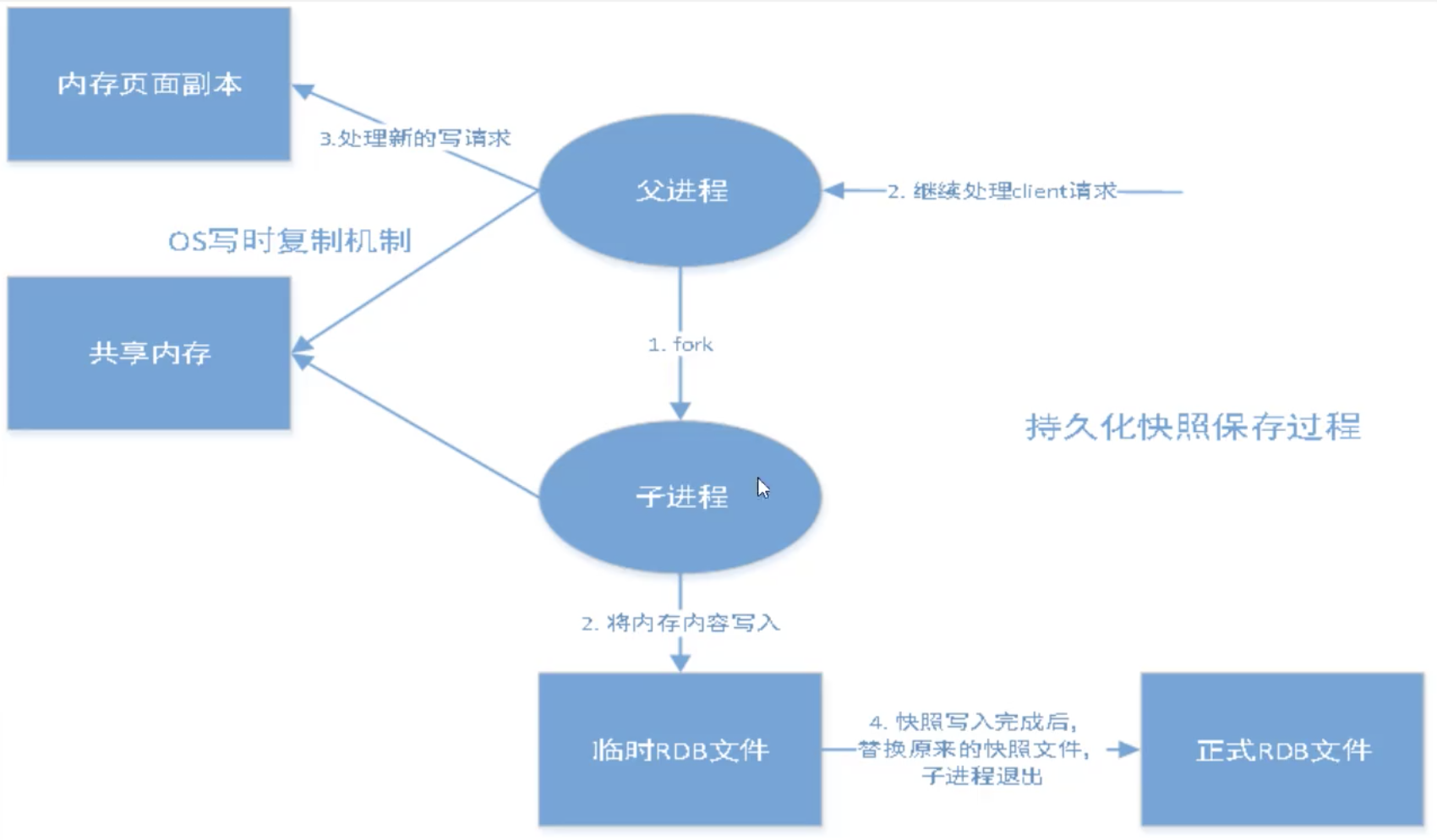
Redis会fork一个子进程,把操作存入临时文件,当满足触发机制,将临时文件替换正式文件。
主进程不进行任何的IO操作,确保了极高的性能
机制
当满足触发机制时,会生成备份文件dump.rdb
配置文件:SNAPSHOTTING(快照(持久化))
save 900 1 # 900秒内有1次操作则进行持久化
save 300 10 # 300秒内有10次操作则进行持久化
save 60 10000 # 60秒内有10000次操作则进行持久化
stop-writes-on-bgsave-error yes # 持久化出错了,是否要继续工作
dbfilename dump.rdb # 是否压缩rdb文件(持久化会持久化在.rdb.aof)「会消耗内存」
rdbchecksum yes # 保存rdb文件时进行检查校验
dir ./ # 持久化rdb文件保存目录
触发机制
- 满足save规则
- 执行flushall
- 退出redis
如何恢复rdb文件
-
查看rdb文件需要存储的位置(可自定义)
> config get dir 1) "dir" 2) "user/local/bin" -
把rdb文件放到上述位置,启动redis时会自动恢复其中的数据
优缺点
-
优点
1、由于采用子进程进行备份,主进程不进行任何IO操作,所以适合大规模数据备份、恢复(备份与恢复速度快)
-
缺点
1、需要一定时间间隔进行操作(save设置),redis意外宕机,会造成数据丢失(最后一次的临时rdb文件)。
2、fork进程时会占用一定的内存空间
6.2、AOF(Append Only File)
机制
将所有(除读取外)命令无限追加记录下来到appendonly.aof,恢复时,把这个文件中命令全部执行一遍。
配置文件:APPEND ONLY MODE (aof模式配置)
appendonly no # 默认是不开启aof模式,默认使用rdb
appendfilename "appendonly.aof" # 持久化文件名
appendfsync everysec # sync(同步)频率:每秒一次 「可能丢失这1s的数据」
# appendfsync always # 每次修改都会同步(消耗性能)
# appendfsync no # 不同步,操作系统自己同步,速度最快
auto-aof-rewrite-min-size 64mb # aof是无限追加,当文件大小到64mb,则会新fork一个进程对aof文件进行重写(优化)
修复aof文件
如果aof文件被篡改了,那redis将无法启动,可以使用redis提供的工具redis-check-aof进行修复
> redis-check-aof -- fix appendonly.aof
优缺点
-
优点
1、同步频率的设置可以更好地避免数据丢失
-
缺点
1、相对于rdb,aof文件更大(aof存储所有除读以外的命令)
2、aof数据恢复比较慢(因为要把所用命令执行一遍)
6.3、应用Tips

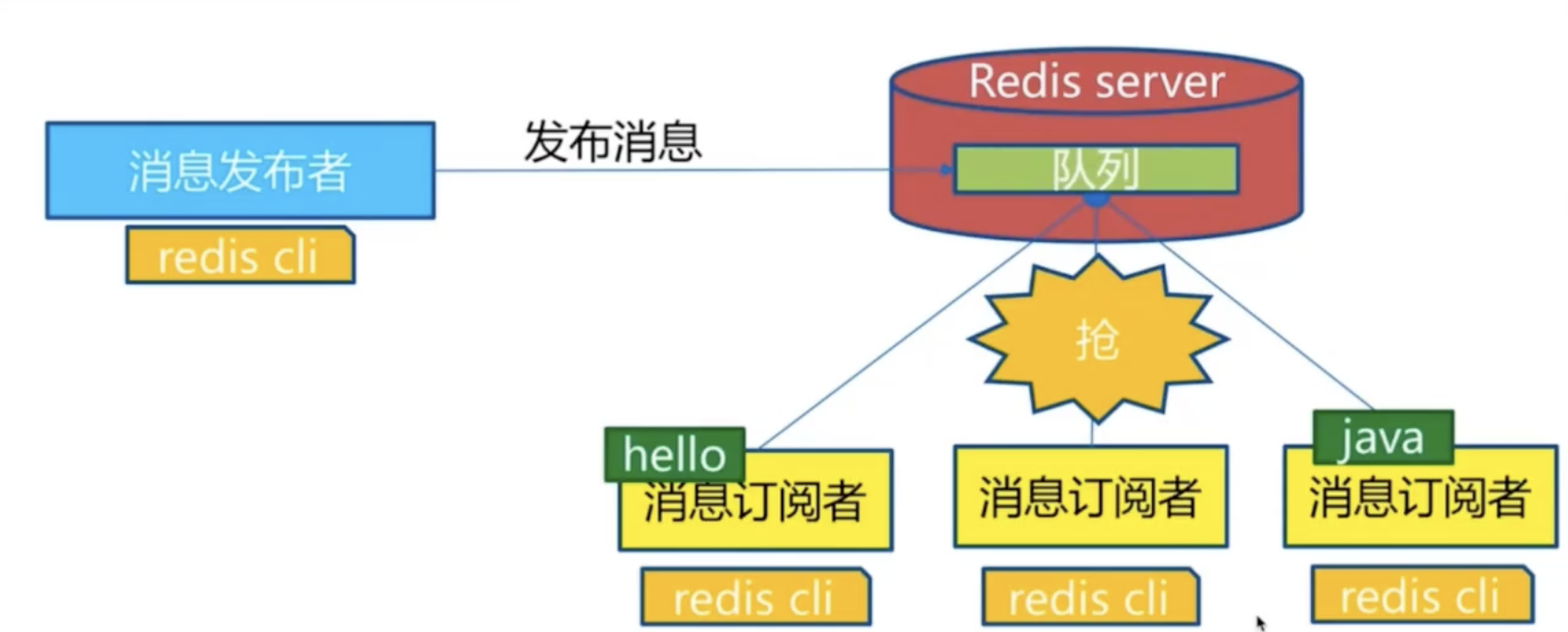
七、Redis消息订阅发布
redis发布订阅(pub/sub)是一种消息通信模式
7.1、基本使用
订阅
-
订阅指定单个/多个频道信息
SUBSCRIBE channel [channel ...] -
订阅一个或多个符合给定模式的频道
PSUBSCRIBE pattern [pattern ...]
发布
-
将消息发送到指定频道
PUBLISH channel message
退订
-
退订指定频道
UNSUBSCRIBE [channel [channel ...]] -
退订所有给定模式的频道
PUNSUBSCRIBE [pattern [pattern ...]]
查看订阅发布状态
-
查看订阅发布状态
PUBSUB subcommand [argument [argument ...]]
7.2、SpringBoot中使用
7.2.1、消息订阅代码
-
消息监听配置
@Configuration public class RedisSubConfig { @Bean public RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory, MessageListenerAdapter adapter) { RedisMessageListenerContainer container = new RedisMessageListenerContainer(); container.setConnectionFactory(connectionFactory); //订阅channel1:/topic/event/1 container.addMessageListener(adapter, new PatternTopic("/topic/event/1")); // 订阅channel2:/topic/event/2 container.addMessageListener(adapter, new PatternTopic("/topic/event/2")); return container; } @Bean public MessageListenerAdapter adapter(RedisMessageListener message) { //给messageListenerAdapter 传入一个消息接收的处理器,利用反射的方法调用“receiveMessage1” return new MessageListenerAdapter(message, "receiveMessage1");//onMessage:接收消息的方法名称 } @Bean public MessageListenerAdapter adapter(RedisMessageListener message) { //给messageListenerAdapter 传入一个消息接收的处理器,利用反射的方法调用“receiveMessage2” return new MessageListenerAdapter(message, "receiveMessage2");//onMessage:接收消息的方法名称 } } -
自定义消息处理器
@Component @AllArgsConstructor public class RedisMessageListener implements MessageListener { // 接收消息的方法1 @Override public void receiveMessage1(Message message) { System.out.println("receiveMessage1接收到的消息:"+message); } // 接收消息的方法2 @Override public void receiveMessage2(Message message) { System.out.println("receiveMessage2接收到的消息:"+message); } }
7.2.2、消息发布代码
//指定队列名
String channel = "/topic/event/" + eventId;
//把消息发送到指定队列指定队列名
redisTemplate.convertAndSend(channel, messageVO);
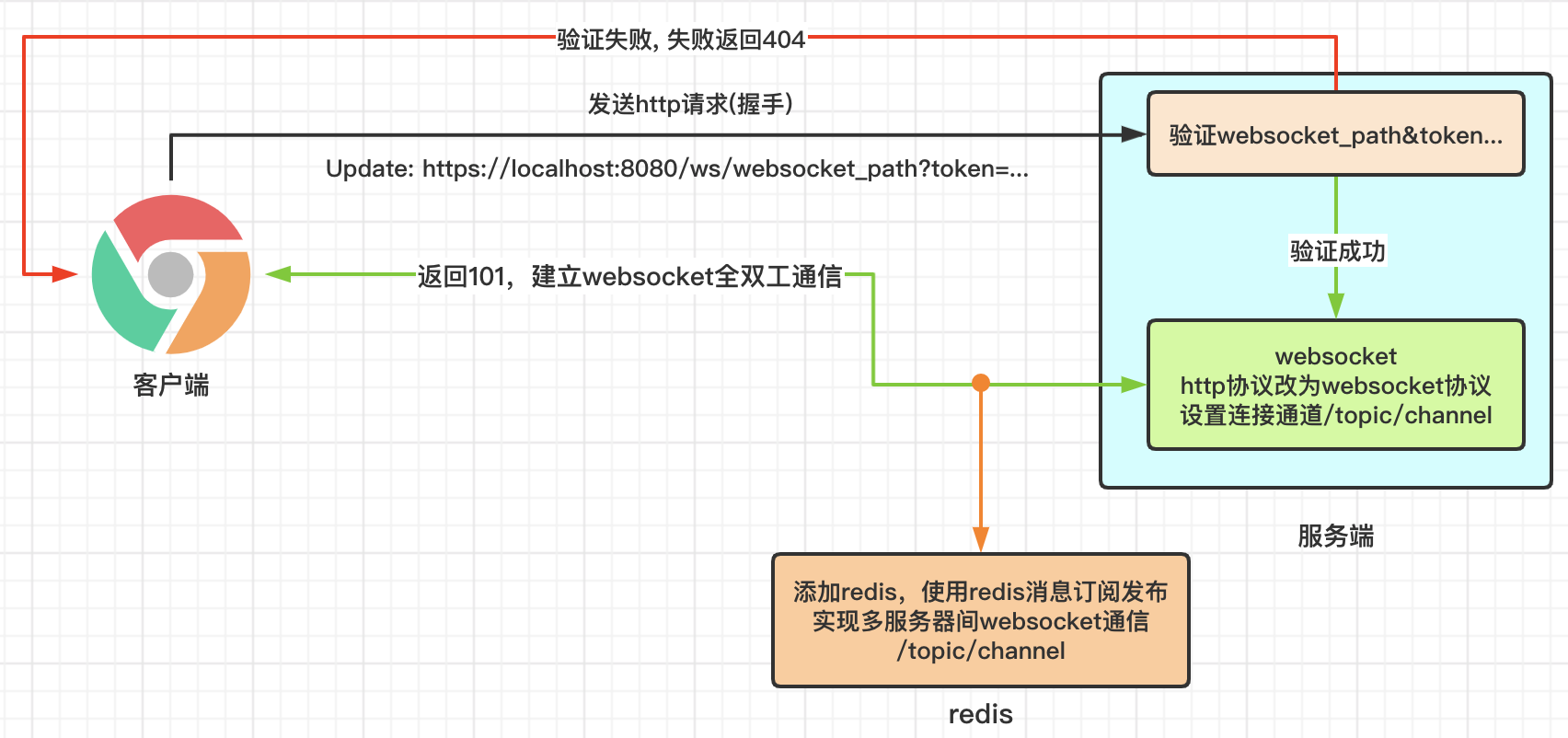
7.3、使用案例
- 使用redis实现websocket的多服务器之间消息通信
八、Redis集群
8.1、主从复制
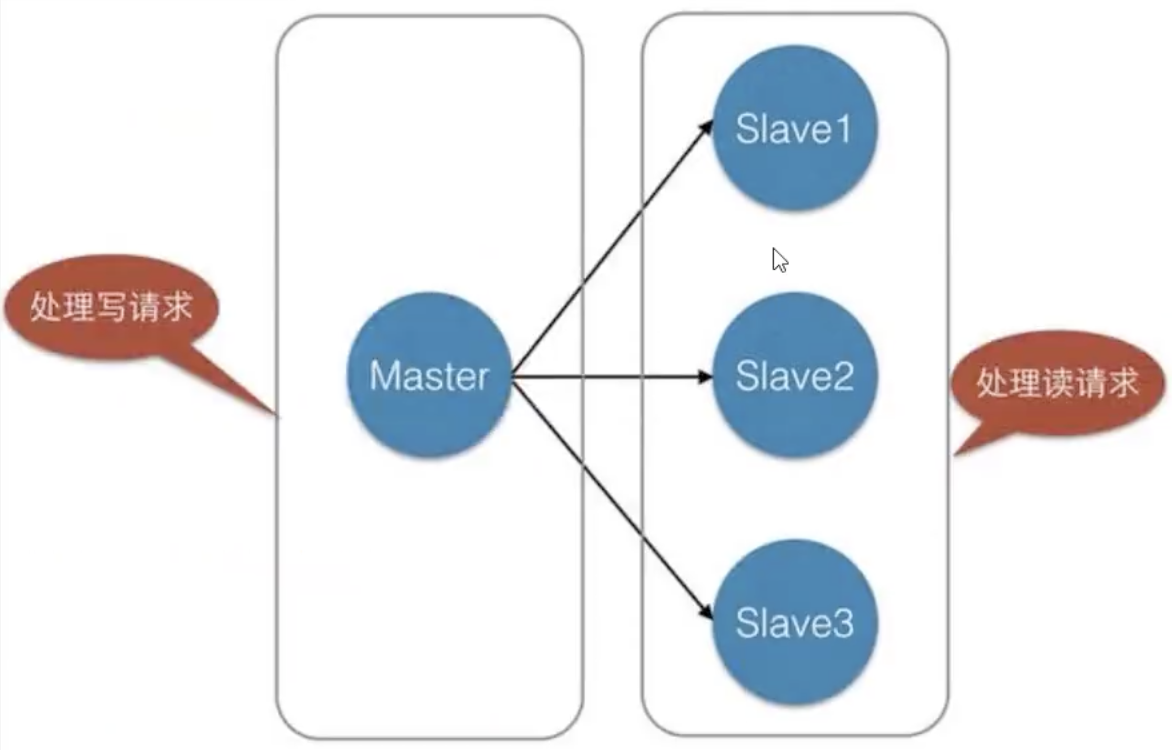
概述
将一台Redis服务器数据(master/leader),复制到其他Redis服务器(slave/follower)。
Redis最大使用内存不应超过20G,如果超过则要考虑使用集群
主从复制作用
- 数据冗余:实现了数据的热备份(运行状态下备份),是持久化之外的一种数据冗余方式
- 数据冗余的作用:可以实现更快速查询(避免一个查询需要去多个节点查询)
- 故障恢复:当其中一个节点出现问题,可以由其他节点提供服务,实现快速故障恢复
- 负载均衡:主从复制配合读写分离,通过子节点分担读负载,可大大提升Redis服务器并发量
- 高可用基石:主从复制是哨兵和集群能够实现的基础
8.2、集群搭建
8.2.1、命令搭建临时集群
使用命令搭建集群,只是临时的,子节点断开重连会恢复为主节点,主节点断开重连还是子节点的主节点
第一步:创建多个配置文件
为每一个节点创建一个配置文件,需要修改如下配置项(eg:redis80.conf)
port 6380 # 配置不同的端口号
daemnize yes # 开启后台运行
pidfile /var/run/redis_6380.pid # 配置不同的进程文件
logfile "6380.log" # 配置不同的日志文件名
dbfilename dump8380.rdb # 配置不同的备份文件名
第二步:启动不同的服务
使用不同的配置文件,启动不同的服务
redis-server redis80.conf # 以redis80.conf文件启动redis服务
ps -ef|grep redis # 查看服务启动情况
第三步:配置主从
只配从节点,不用配主节点(默认就是主节点)
-
配置子节点
> redis-cli -p 6380 # 连接redis > slaveof 127.0.0.1 6379 # 配置为子节点 > inof replication # 查看当前redis的信息(role:slave master_port:6379) -
在主节点查看子节点情况
> inof replication # 查看当前redis的信息 # role:master 「主节点」 # connection_slaves: 2 「两个子节点」 # slave0: ip=127.0.0.1,port=6380,state=online,offset=196,lag=1 「子节点情况」
8.2.2、搭建永久集群
直接在配置文件中的REPLICATION项配置上主节点信息,则以此配置文件启动时即为子节点,子节点断开重连依旧是子节点。
第一步:创建多个配置文件
为每一个节点创建一个配置文件,需要修改如下配置项(eg:redis80.conf)
port 6380 # 配置不同的端口号
daemnize yes # 开启后台运行
pidfile /var/run/redis_6380.pid # 配置不同的进程文件
logfile "6380.log" # 配置不同的日志文件名
dbfilename dump8380.rdb # 配置不同的备份文件名
replicaof 127.0.0.1 6379 # 配置主节点的ip端口号
masterauth 123456 # 配置主节点的密码
第二步:启动不同的服务
使用不同的配置文件,启动不同的服务
redis-server redis80.conf # 以redis80.conf文件启动redis服务
ps -ef|grep redis # 查看服务启动情况
启动完毕即为主从
> inof replication # 查看主/从redis的信息
8.3、哨兵模式
自动选举主节点
8.4.1、概述
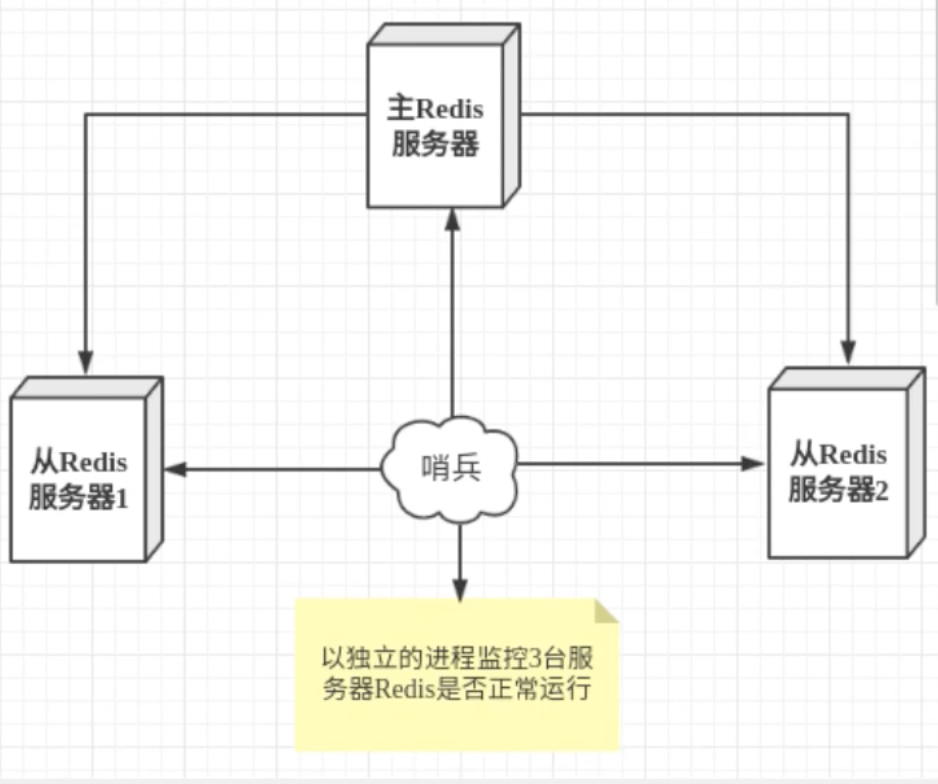
概述
-
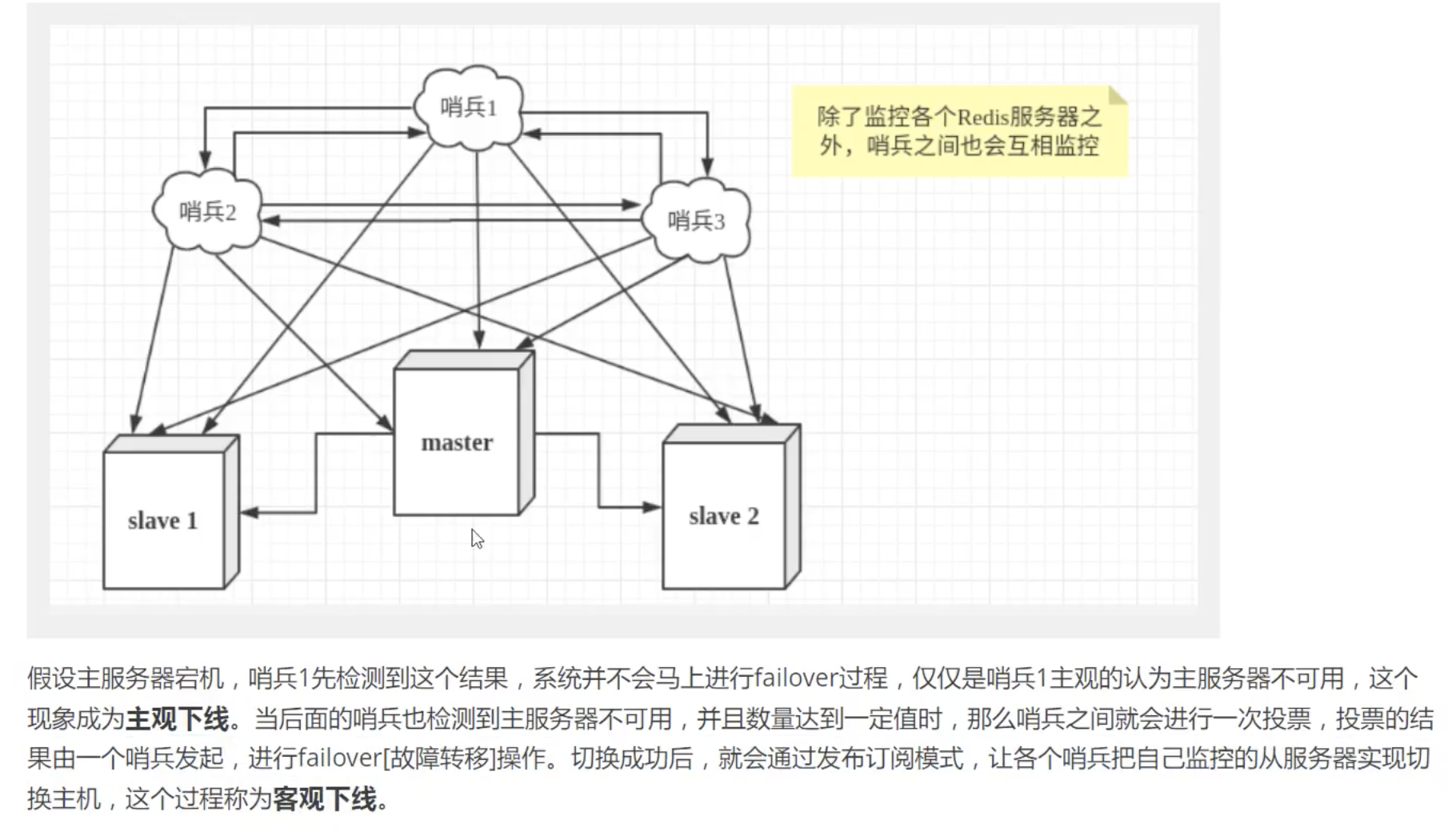
当服务器宕机后,需要手动(
slaveof no one)把从服务器切换为主服务器,需要人工干预,费时费力,还会造成一段时间内的服务不可用。 -
哨兵模式可以自动监控主机是否故障,如果故障,根据投票自动将从机换为主机,若之前的主机重连则会成为从机。
- 为防止哨兵挂掉,则使用多个哨兵进行互相监控,形成哨兵集群(加上redis集群进程,至少要6个进程)
优缺点
-
优点
- 具备所有主从复制的优点
- 主从自动切换,转移故障(高可用)
-
缺点
- 扩展比较麻烦
- 配置复杂
8.4.2、配置哨兵模式
简单配置
-
编写配置文件
# sentinel monitor 自动以哨兵名 要监控的ip 要监控的port 1(票数,用于投票) sentinel monitor myredis 127.0.0.1 6379 1 -
启动哨兵
redis-sentinel sentinel.conf
全部配置
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379(哨兵集群时配置此项)
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
#这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
#一个是事件的类型,
#一个是事件的描述。
#如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
8.4、集群的特性总结
- 数据的复制是单向的,只能由主节点到从节点,一个子节点只能有一个主节点
- Master以写为主,Slave以读为主(不能写),主机中所有数据都会自动被从机保存
- 主节点写数据,会自动同步到子节点(增量复制)
子节点挂掉- 恢复为子节点后仍能获得其断开期间主节点设置的值
- 子节点启动连到master,会发送一个同步命令,主节点会将所有数据传送到子节点(全量复制)
- 只要子节点连接到主节点,就一定会进行一次全量复制
- 恢复为子节点后仍能获得其断开期间主节点设置的值
主节点挂掉- 【普通模式】
- 子节点无操作,主机断开重连依旧是主机。
- 子节点手动执行
slaveof no one则可成为主节点,如果此时之前的主节点再恢复就只能是光杆司令的主机了。
- 【哨兵模式】哨兵模式可以自动监控主机是否故障,如果故障,根据投票自动将从机换为主机,若之前的主机重连则会成为从机。
- 【普通模式】
九、缓存穿透、击穿、雪崩
保证服务高可用
实战操作,后续补充
9.1、缓存穿透(数据库无数据)
当数据库不存在所查目标数据(因此缓存中也没有),当有大量请求穿过redis查询数据库,则会给数据库造成很大的压力,这时候则被称为换sun穿透
9.1.1、解决方案
-
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。
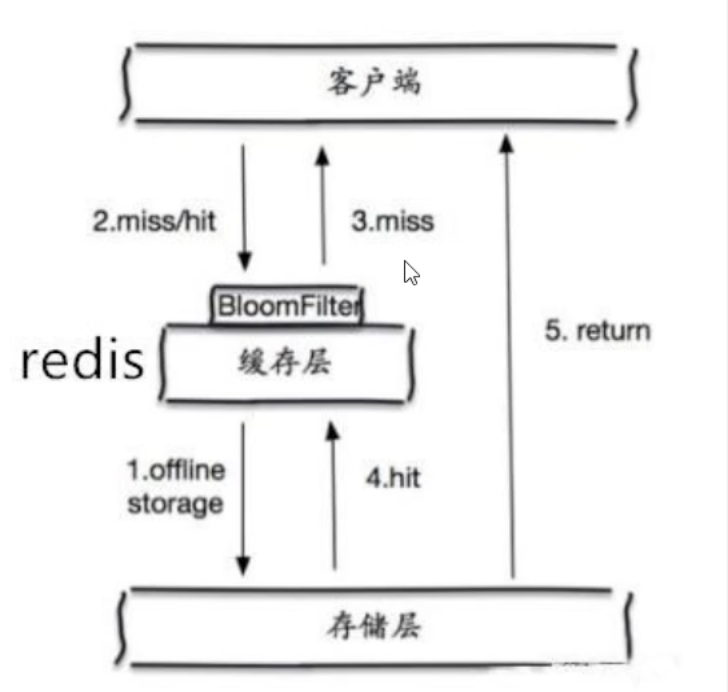
-
缓存空对象
当存储层未被命中,则将该对象在redis缓存为空值并设置过期时间,之后再查询则会从缓存中获取,保护了后端数据源。
- 缺点
- 缓存空值,造成存储空间浪费
- 当设置的过期时间没过,但是数据源已经更新,会导致数据不一致
- 缺点
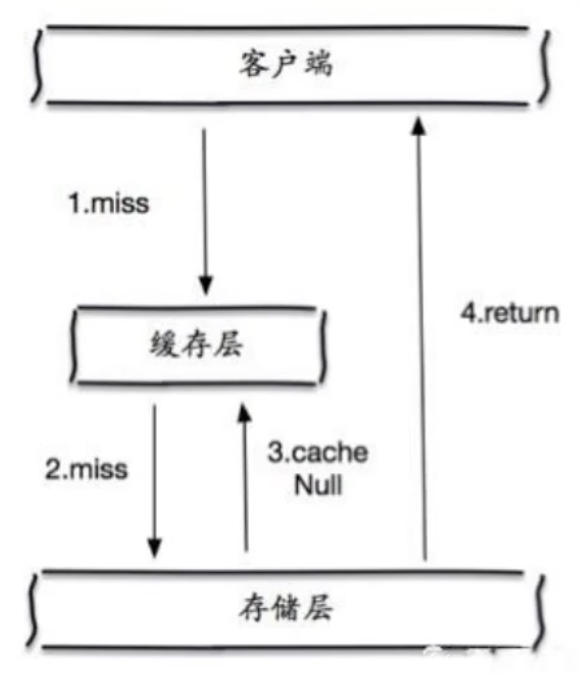
9.2、缓存击穿(某一缓存过期)
缓存中的一个非常热key,在不停地扛着高并发(大并发集中在一个点),当key过期的瞬间,高并发将穿破缓存,直接请求数据库,造成数据库宕机。「微博热搜宕机」
9.2.1、解决方案
-
设置热点数据永不过期
没有设置过期时间,所有则不会产生缓存击穿
- 缺陷:占用内存
-
加互斥锁
使用分布式锁,保证每个Key同时只有一个线程去查询后端服务,其他线程只能等待。
- 缺陷:将高并发转移到了分布式锁,因此对分布式锁考验很大
9.3、缓存雪崩(缓存集体失效)
在某一时间段,缓存集体失效(比如redis集群宕机),大量数据全部请求数据库,造成数据库宕机
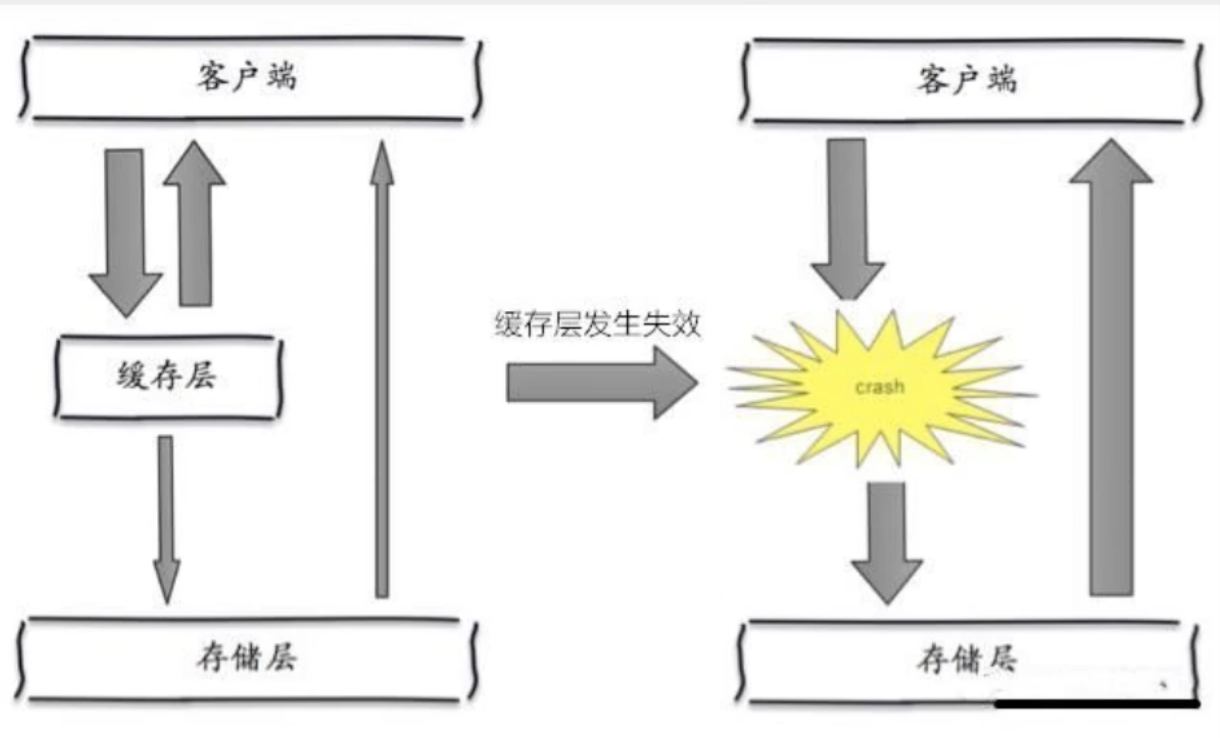
9.3.1、解决方案
-
redis高可用
搭建集群、异地多活
-
限流降级
缓存失效后,通过加锁或队列来控制数据库写缓存的线程数,或者停掉部分服务,保证核心服务可用
-
数据预热
在即将发生高并发时,预先把数据访问一遍,并设置不同的且够长的过期时间,让缓存失效时间在高并发后或尽量均匀
