




最近遇到一个问题看到AWR显示的TOP事件是这样的
resmgr:cpu quantum 这就比较头疼了,CPU处理不过来。拿了一下出问题前半个小时的AWR。看到比较严重的是这样的。

SQL处理一下大概长这个样子:
SELECT * FROM (
select
若干的sum
(
SELECT 一个配置 FROM 其他数据库的表 WHERE 关联条件 ----都是状态和没写区别不大 问题1
)
(SELECT MAX(一个列) FROM 多个表 WHERE 关联条件 没有过滤条件 ----都是状态和没写区别不大 要取全表中这个列最大的一行记录的一个字段) 问题2
FROM 多个表 WHERE 关联条件 没有过滤条件 ----都是状态和没写区别不大 问题3
AND EXISTS ( 多个表 WHERE 关联条件 没有过滤条件 ----都是状态和没写区别不大) 问题4
AND 条件1 and 条件2 GROUP BY 好几列 ----没有时间 问题5
order by m.created_date desc --但是要求按照时间倒序排列 问题6
) TMP WHERE ROWNUM <=:3 ) WHERE ROW_ID > :4 ---框架自带
我把SQL转义为上面的形式。原文太长也复杂不太可读。
结合问题可以看到平均执行一次要12分钟(开发反馈大约20分钟根据后台监测)。也就是说这个SQL由于带来SUM group by比较典型的报表。不管最后是10行还是100行都是报表。按照行政区统计人口,全中国也不到40行数据。
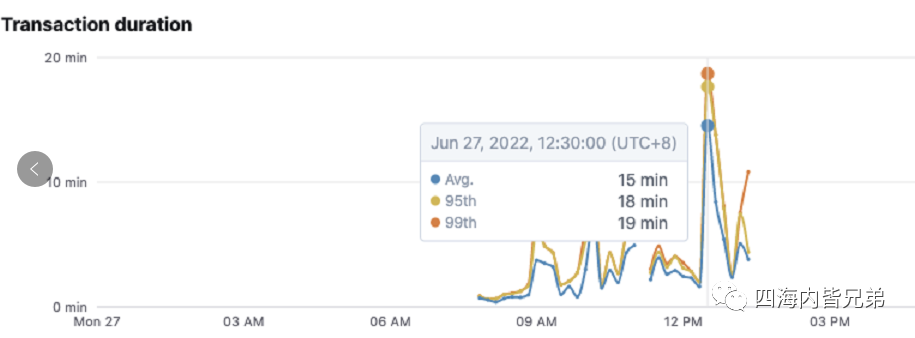
就我上面提到的这些问题一一进行改进。
问题1.我发现是读取静态配置,那么完全不需要去跨库关联。写成case when。直接把4-5个配型信息静态写在SQL中
问题2 由于全表排序非常要命,内存放不下,要到磁盘,磁盘也放不下就是大问题了。改成标量子查询 AND ROWNUM = 1 虽然我觉得标量子查询是不建议的,这种就是设计上没想好。但是这样总比全表排序好
问题5 过滤条件中缺索引。结合问题6补索引和时间联合索引,即使按照时间排序也不会产生排序动作。
问题6 既然要看最新的,那么不会去看几年以前,看一个月够不够?(最后达成说看三个月,这里很关键,很多时候实现要考虑合理性。一定要侵入业务,而且让业务服从逻辑)由于带上时间
问题3 既然外部有限制,那么子查询也带上时间
问题4 通过逻辑发现,有的表可以不用关联。既然外部有限制,那么子查询也带上时间。
这些修改可谓刀刀见肉,尤其6 可以带动3和4.这里要说明,必须压不合理诉求。问题1是看数据样本分析出来的。问题2是典型的不合理。
修改之后我们先看看真实运行情况如何。看到只有4次物理读还是可以的。
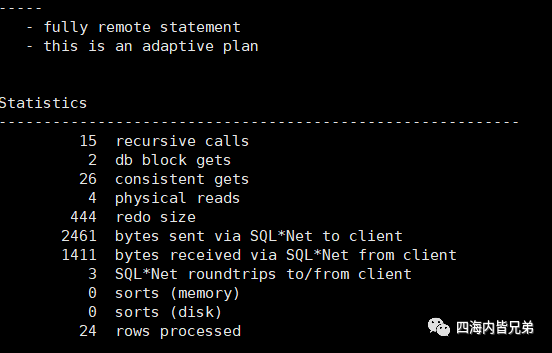
然后再执行看一下。这下心里踏实了,也就是说这个场景可以全部基于内存使用。(谁说Oracle MySQL PG就比redis的慢?)
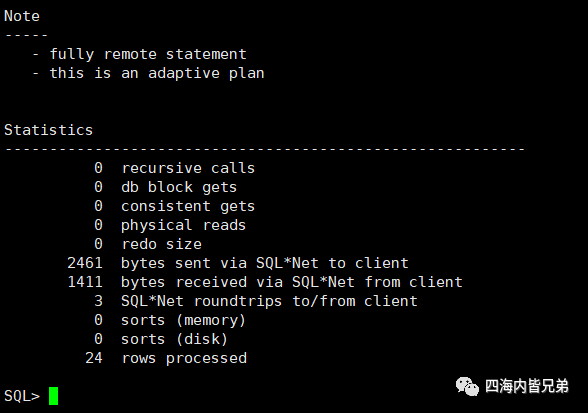
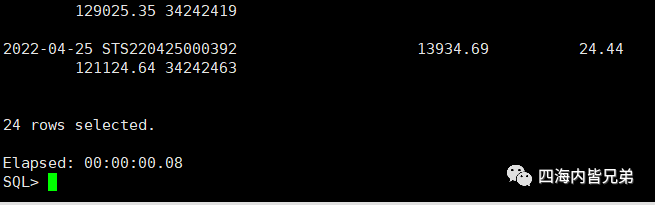
压测以后开发反馈,看不到耗时(因为这个最低粒度是1秒) 这里讲个笑话,问一个胖子你多重?他说200斤。表示质疑看上去不止嘛。他说其实我也不知道我有多重,关键那个秤200就到头了。
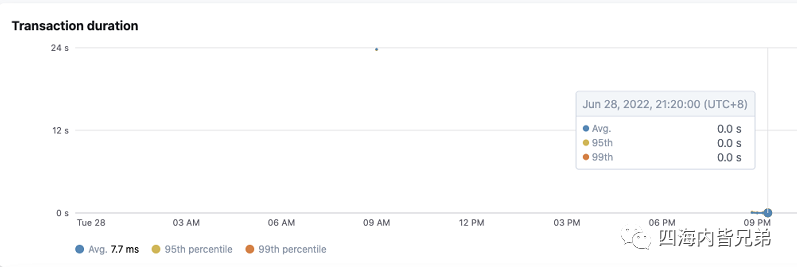
那么来看看数据库层面的精细度。可以看出来压测了73万多次,每次都是小于10毫秒的。这里也发现了一个有趣的现象,为什么我改了一个场景(压测这个场景数据库会出现4个不同的SQL)

原因是这样的。
上面两个是调用下面两个的。所以等于一个执行,就执行量两次。
那么为什么被调用的的也会出现两个呢?这就是问题6后面有个框架自带的注释。为了分页他先在最外层包了一层select count(1) from (select * from t 。。。。。。)所以一般执行一句SQL带动了两句。
然后再被调用一下就是4句。
所以我想本来就是出报表的场景(不是一般的点查,SQL写的这样复杂了)点一下,后台还运行4次,那么压力可想而知。如果10个人点,其实就是40的并发。
回过来计算:以第一行的执行效率计算执行738753次累计用时1072.51秒 那么单次执行 1072510(ms)/738753=1.4ms 即使4个加在一起也不到7ms。
原来执行20分钟(没出结果) 20分钟 1200秒VS 7ms 这个算下来已经10几万倍的性能提升了。这个如果去掉调用,去掉框架自带分页,而是采用数据库的分页,那么就是几十万倍的提升了。
当然后面可能还要考虑网络和前端渲染的问题,不过那不是我们能操心和控制的了的了。作为开发人员做到这样就可以了,付出有回报。
谁说出报表就应该慢?谁说不能毫秒出报表?这才是一个数据库应有的样子嘛。
好好写,在线交易也能秒出,不必要花费巨大代价到hadoop等。天下武功,唯快不破。再快快的过这里1ms吗?

