对于任何一个企业,用户增长和用户留存是一个永恒的话题。在企业运营中,大家都会关注自己花了很多代价获取的用户,在过了一段时间之后是否还在自己的企业进行消费,因此就有了留存分析的需求。今天我们就基于Kaggle的一个零售行业的公开数据集,无代码的方式做一下留存分析。
01
什么是Cohort Analysis?
我们首先来理解一下什么是Cohort Analysis。Cohort Analysis从字面意思来看,叫做人群分析。相对比较容易理解的解释就是对符合条件的一群人进行后续的分析。比如在移动互联网领域有对新增用户的次日留存分析、三日留存分析等等。游戏公司则可能对付费用户做月留存分析,电商用户对每个月有购买行为的用户分析月留存等等。
02
零售留存分析实战
下面我们就用Kaggle的一个数据集来做样例,看看如何实现人群分析中最常见的留存分析。
数据集简介
这个数据集来自于全球最有名的数据科学家社区Kaggle,最早的出处是加州大学欧文分校的课程作业,具体数据集地址为:https://archive.ics.uci.edu/ml/datasets/Online+Retail+II , 也可以到Kaggle去下载:
https://www.kaggle.com/code/mahmoudelfahl/cohort-analysis-customer-segmentation-with-rfm/data
整个数据集为xlsx格式,有23M,大约54万行。
数据加载和清理
首先我们从前面提到的下载地址中下载相关的数据集。如果大家自己有自己的生产环境数据,可以参照我对这个数据集的操作方法来根据自己的数据做留存分析。
Kaggle的这个零售数据集是xlxs格式,我们决定用快表格(QuickTable)进行数据处理和留存分析,第一步就是先把数据上传到系统中。首先在QuickTable中创建一个项目:
创建后进入项目,然后选择Upload File,
上传成功后,会先review数据,然后create.
现在数据上传成功,我们可以开始进行后续的数据查看和清洗工作了。
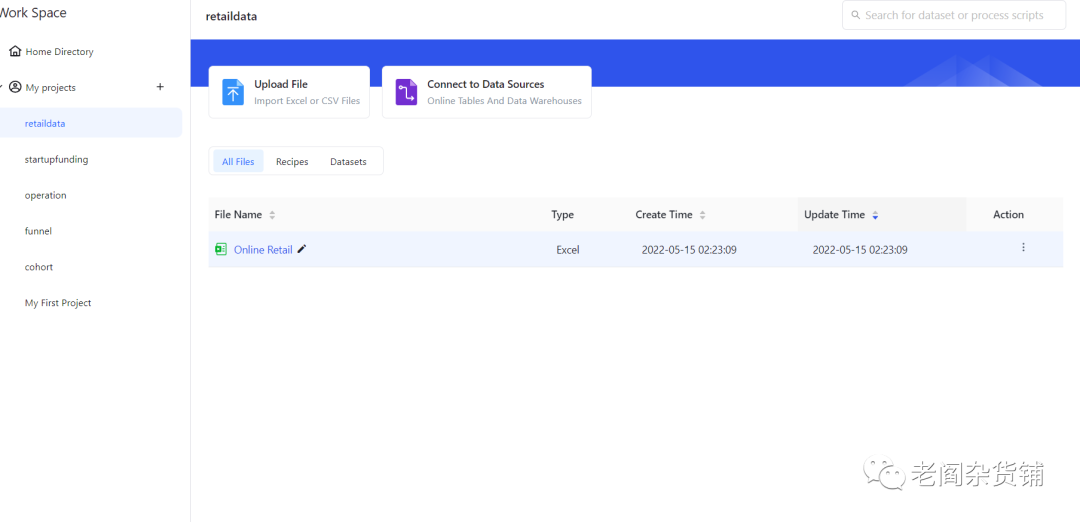
点击上传的数据集打开,我们就可以看到数据,如下图:
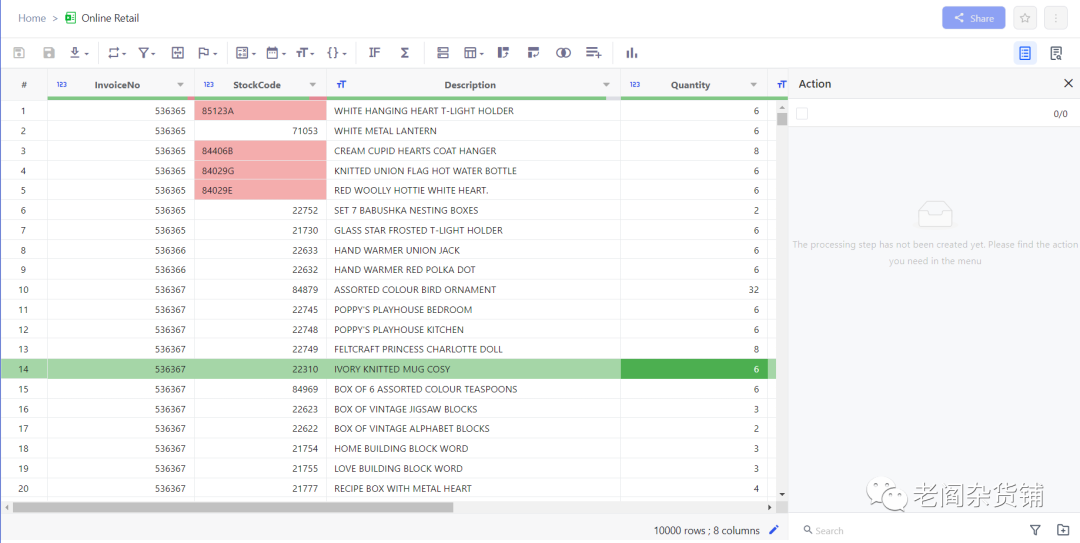
系统默认装载10000行,我们修改一下数据量,点击10000 rows旁边的笔,则打开采样规则,如下图:
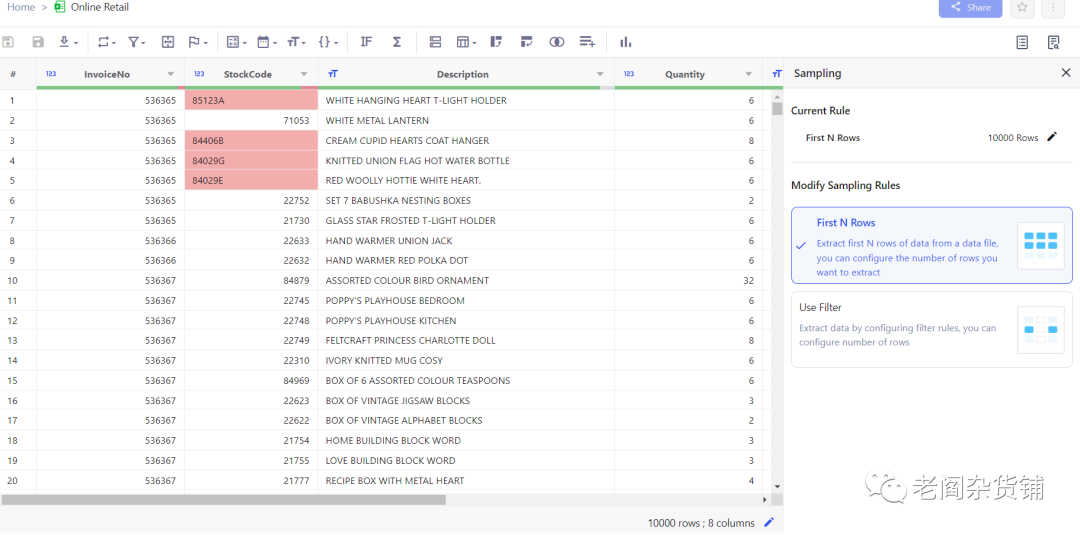
点击采样数量旁边的笔,设置1000000,这样可以最多装载100万行,这个数据集不到100万行,因此会全部装载。
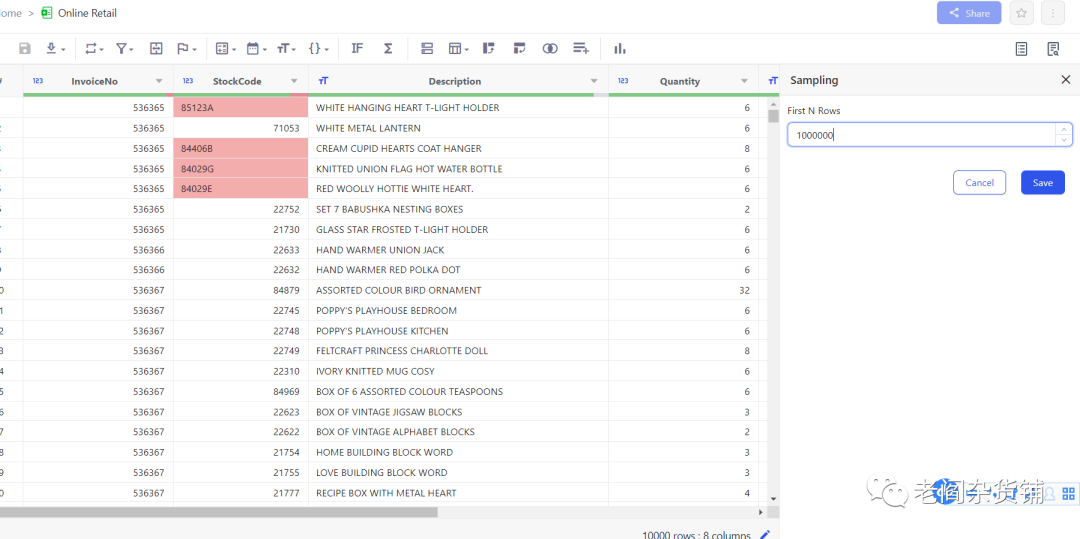
点击确认后,会重新装载数据,装载完成之后如下图:

这里可以看到装载了541909行数据。由于我们要做人群分析,我们先看看代表用户的CustomerId这个字段情况。点击CustomerID列,选择Overview,如下图:
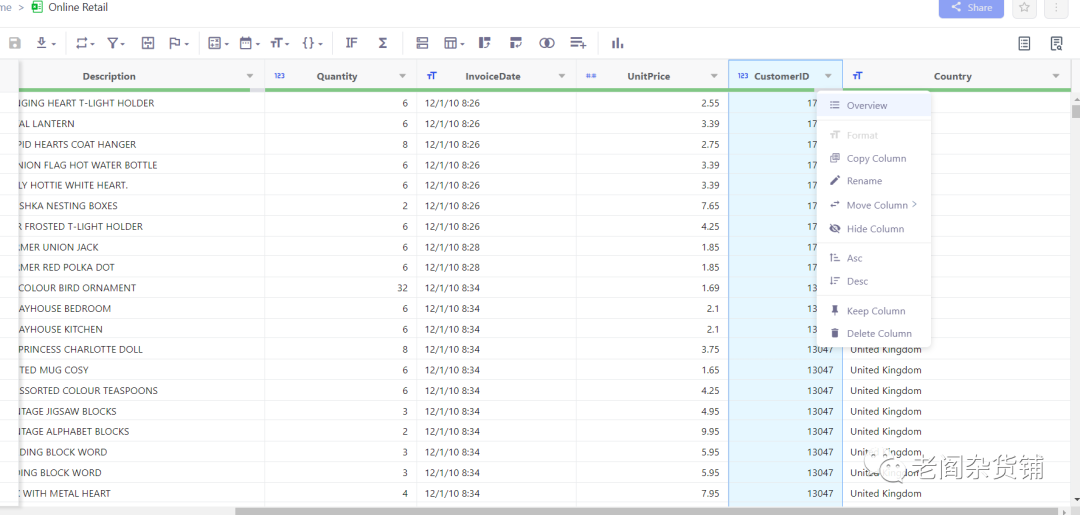
然后点击CustomerID的列概览框,可以看到列分布情况:
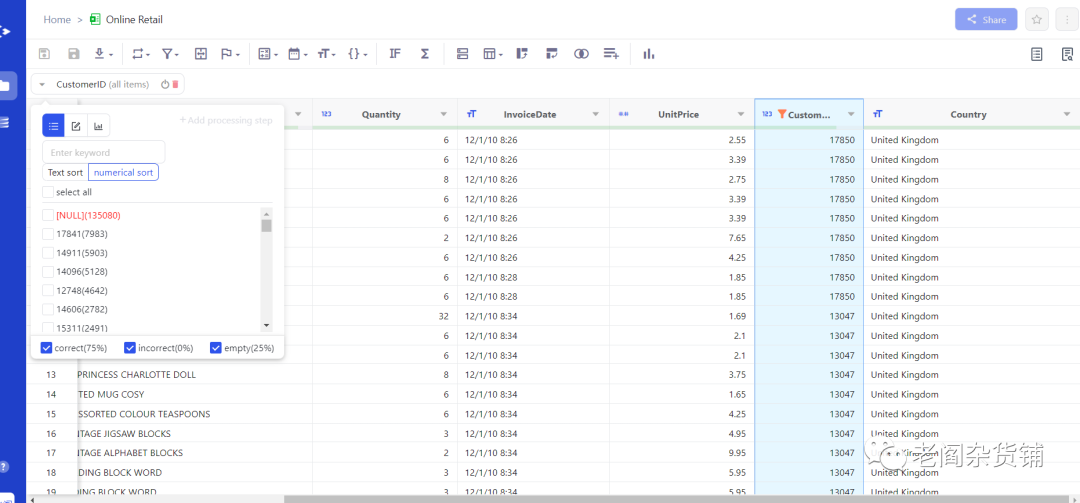
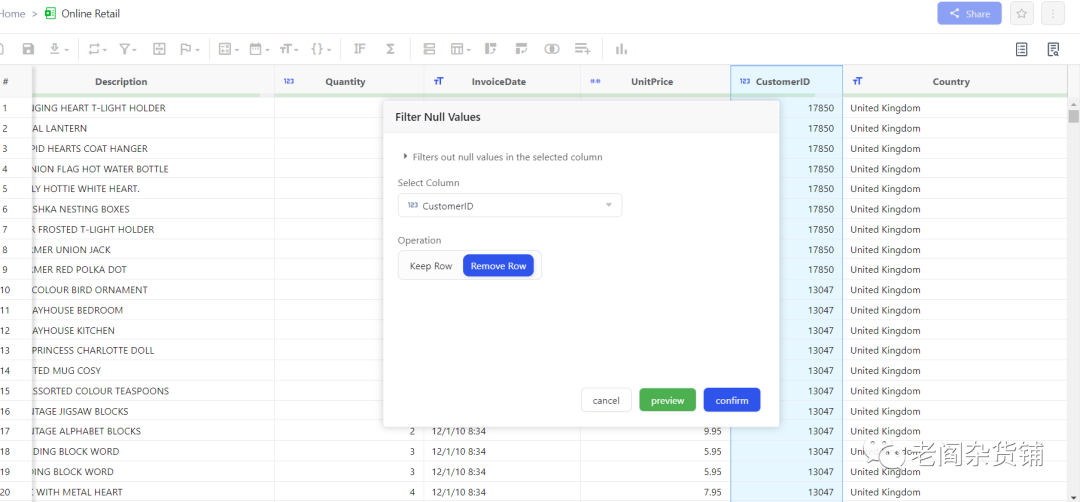
我们可以看到有135080行的CustomerId是空值,这种数据需要先清洗过滤掉。选择CustomerId列,然后选择菜单中的filters->null value filter,如下图:

则可以对这一列进行空值过滤
选择删除空值列,则所有CustomerId为空的行就会被删除。过滤后,可以看到剩下的行数为406829行,如下图:
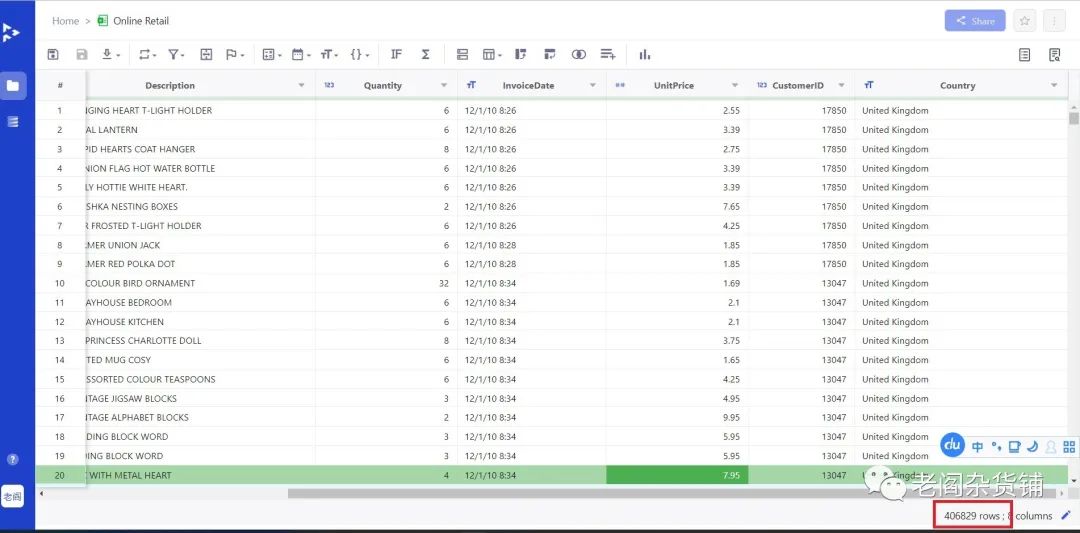
到现在,我们就完成了数据的简单清洗工作,我们可以点中每一列,看看这一列的数据概况和数据分布情况,就像我们写python程序的时候调用dataframe.info一样。只是这里不需要写代码,直接选中列就可以看到相关信息。
数据建模
在完成了我们初步的数据装载和清洗之后,我们要根据我们的目标进行数据建模。我们的目的是分析每个月有过购买行为的用户的月留存情况,也就是每个月有过购买行为的用户作为一个人群,去分析后续每个月还有购买行为的用户的数量以及占人群的比率。
基于这个目标,我们首先要能去找到每个月的有过购买行为的用户。原始数据中有一个字段是InvoiceData,是用户购买的日期。原始数据格式为月/日/年 小时:分钟。系统默认识别为文本类型,我们首先先对这个字段进行日期格式化处理。选中这一列,然后点击列头的TT,选择Data进行日期格式化:
系统会自动进行类型推断和转换,如下图:
点击确认,则这一列数据被转换为日期类型。
接下来,我们要新生成一列,从InvoiceDate中提取月,用来做后续的人群圈选。具体操作为, 选中InvoiceDate这一列,选择time format菜单,进行如下格式化操作:
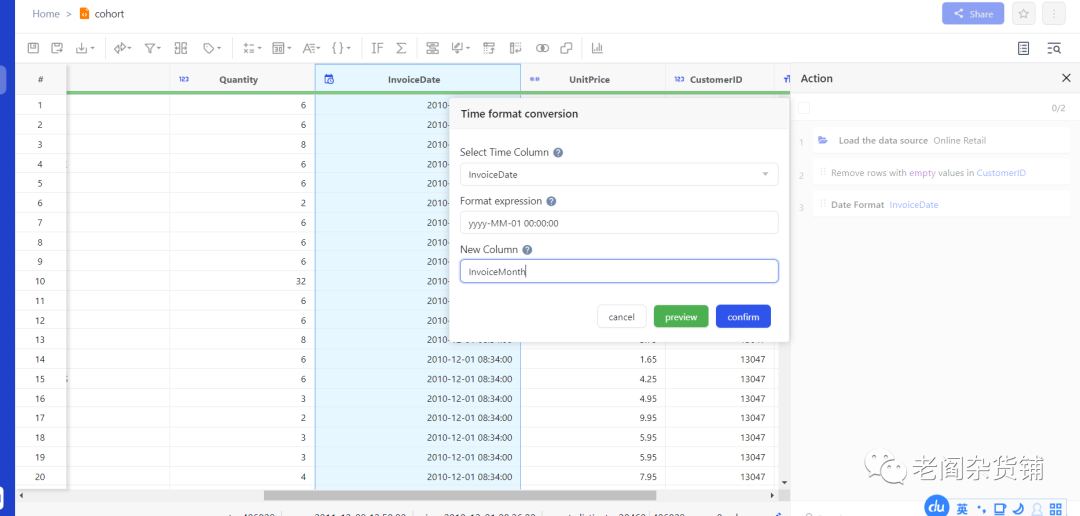
我们可以看到新生成一列InvoiceMonth列,为了确认是否正确,我们可以在这一列上选择列概览。
接下来,我们要用到一个比较高级的功能-窗口函数来计算每个客户的最早购买产品的月份,用来进行人群分群。具体的操作为:
1,选择窗口菜单的Min选项,如下图:
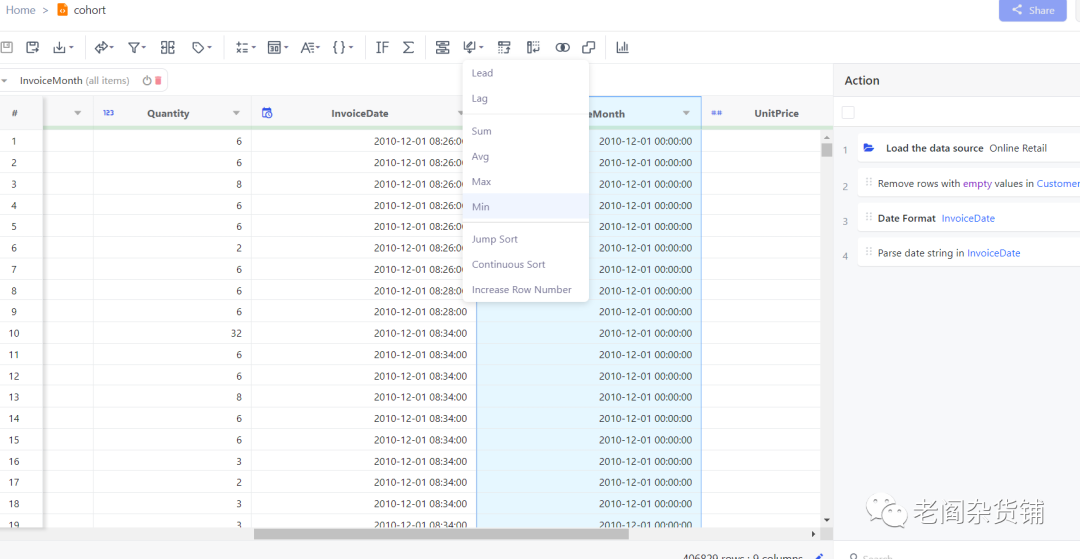
2,group by column中选择CustomerId, 然后sort column选择InvoiceMonth, column calcuation也选择InvoiceMonth,如下图:
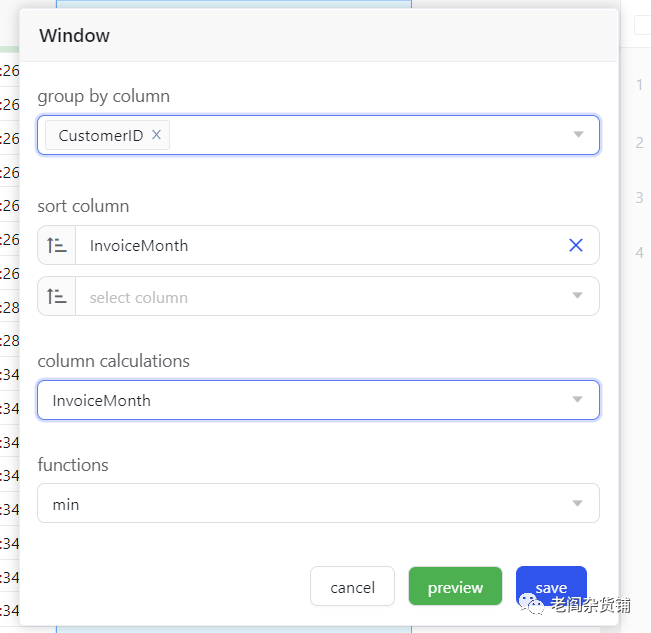
选择Save后,会生成新的一列,如下图:
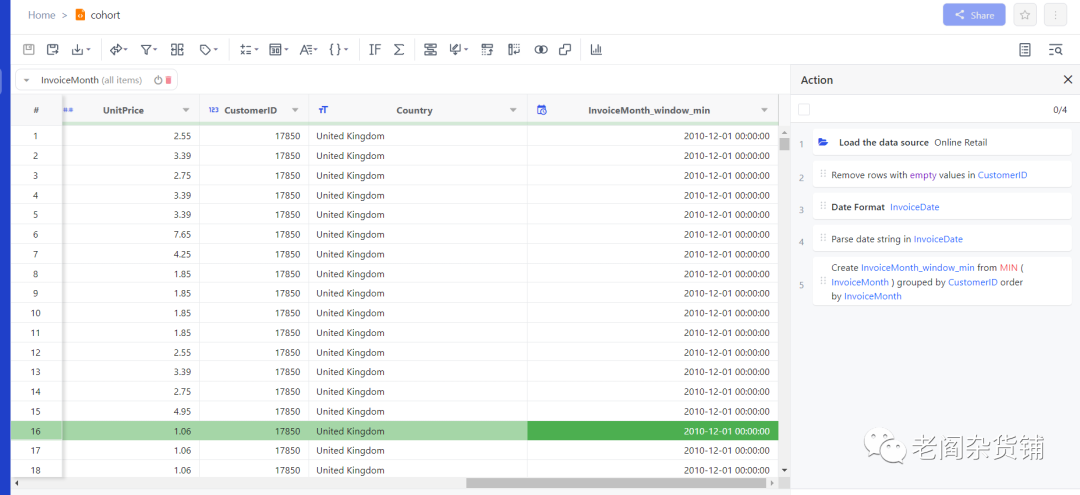
对生成的这新的一列InvoiceMonth_window_min改名,重命名为CohortMonth。
3,生成CohortIndex计算列。因为我们要计算从首次购买这个月的人在后续每个月的留存情况,因此我们需要计算InvoiceMonth和CohortMonth之间的差值。具体操作是选择time related calculation,然后选择interval,month,如下图:
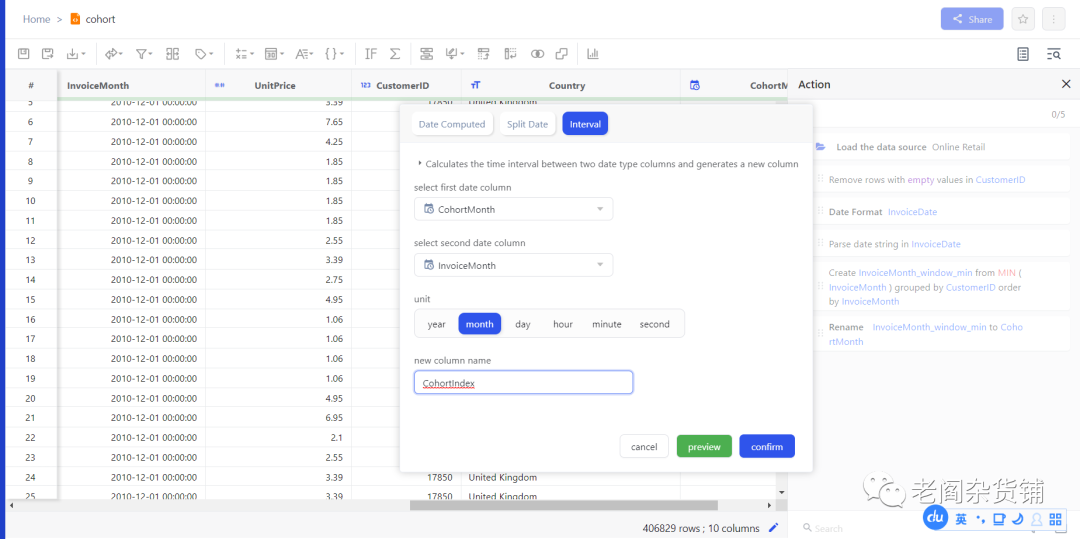
确认之后会生成新的叫做CohortIndex的列,如下图:
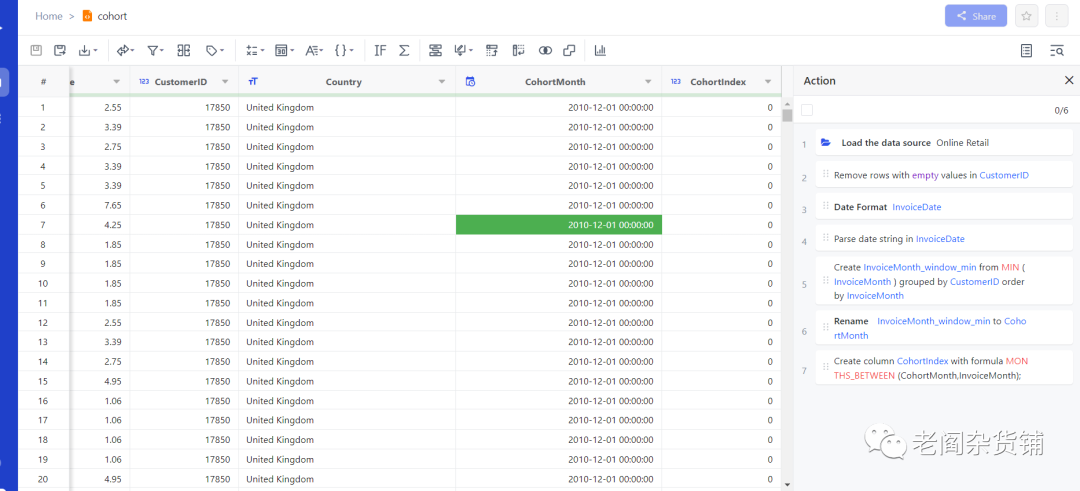
到这一步截止,我们用了7步工作完成了数据的清洗和建模,剩下我们将要进行留存计算。
留存计算
由于我们打算基于每月的活跃购买用户计算后边每个月的留存数据,因此我们以CohortMonth, CohortIndex为分组进行聚合操作,操作的方法是CustomerId的排重,如下图:
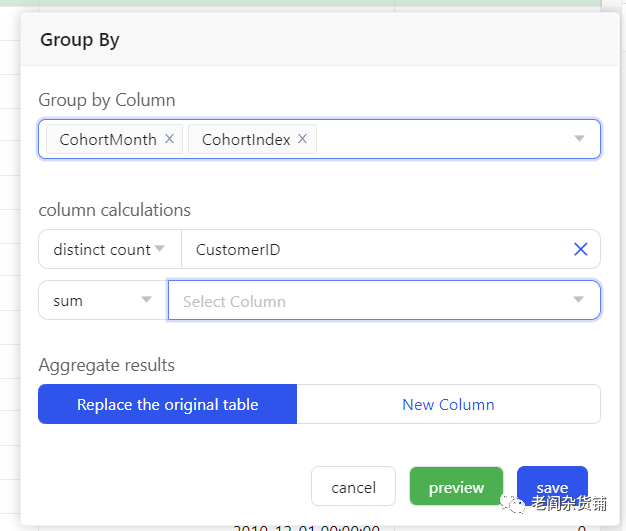
Save后,会生成留存计算结果,如下图:

我们可以看到这个数据的排列顺序并不是我们要求的,我们可以继续用窗口函数做一次按照CohortMonth和CohortIndex的排序:
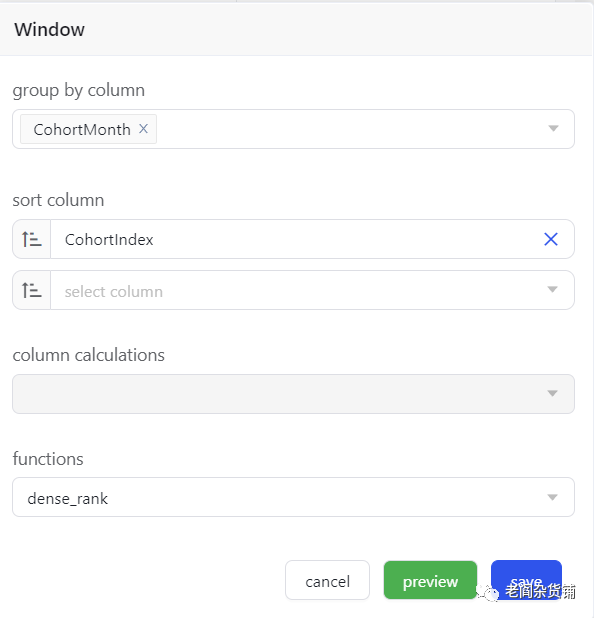
排序后结果如下:
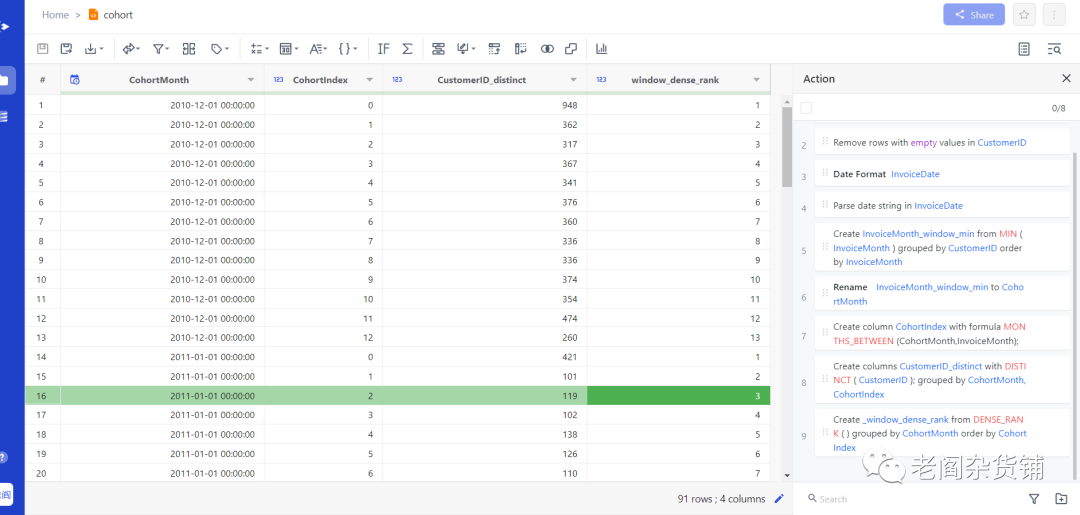
这样我们的基本的留存数据就计算出来了,我们可以基于这个数据做后续的热力图分析。
留存热力图
为了能更直观的展现留存数据,我们可以用热力图来进行数据展示。具体操作方法为选择chart->heatmap,如下图:
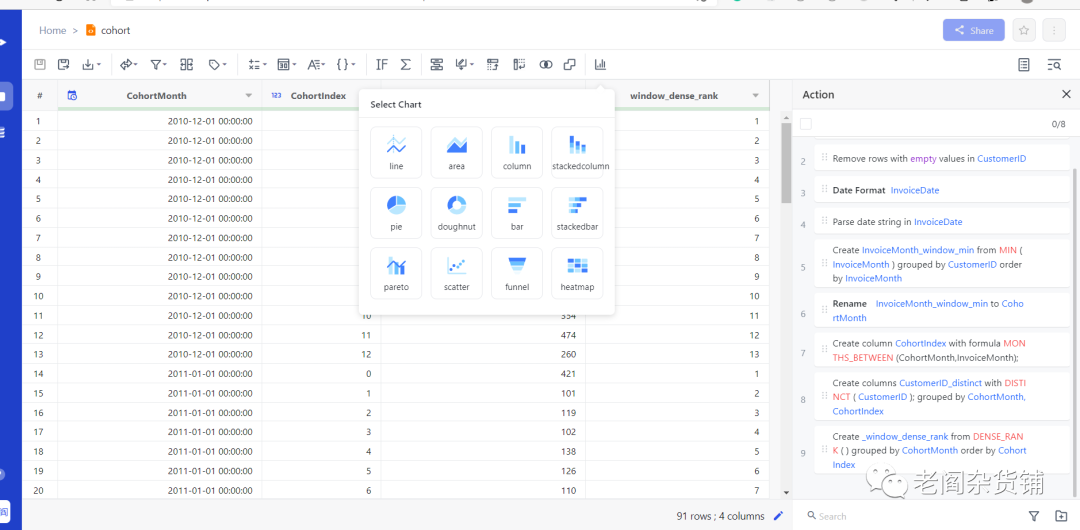
其中row选择CohortMonth, Column选择CohortIndex, Value选择CustomerID_distinct,然后在chart style里选择show value,图表如下图:
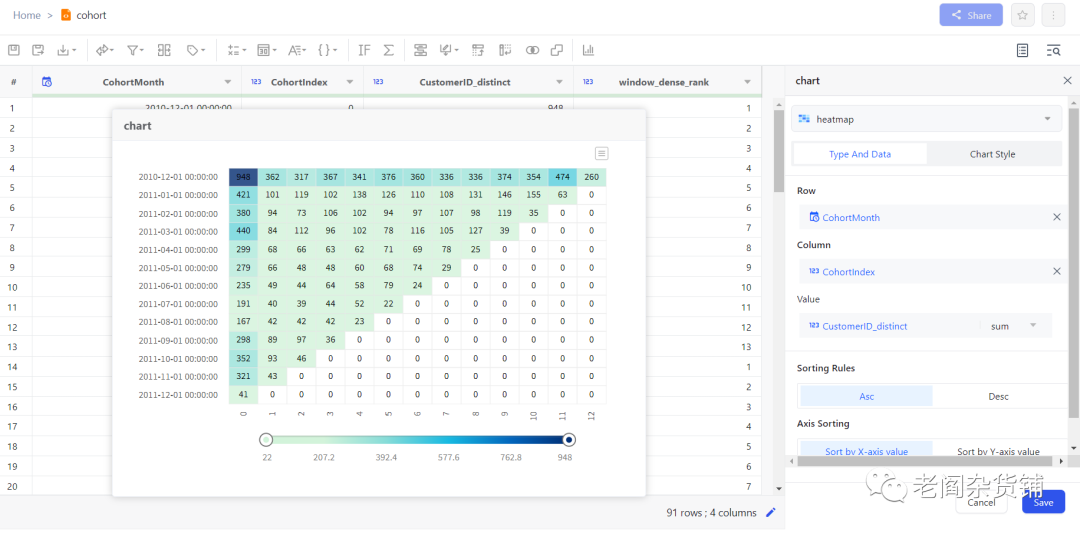
然后点击Save,则图表会被保留在处理步骤中,如下图:
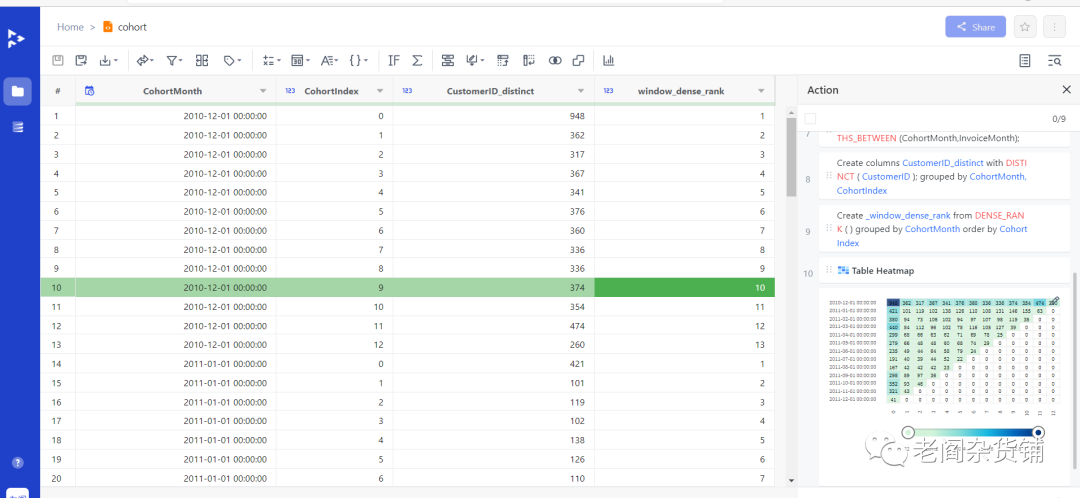
这样,通过10步操作,我们就完成了最常见的留存分析,并做了图表的可视化。
当然,我们还可以继续计算每个月的留存率,然后形成留存率的热力图,详细步骤我这里不做更多介绍,大家有兴趣可以找我来申请账户进行体验。
附录加彩蛋:
在做留存分析的时候,我们用到了一个非常重要的功能-Window,也就是窗口函数。窗口函数的作用主要是在一个分组中,进行Min(最小值), Max(最大值), Sum(汇总),Avg(平均值), Count(计数),以及排序等等操作的函数。Window函数属于SQL中比较新的用于统计分析的能力,目前在不同的数据仓库平台中的实现也不尽相同。QuickTable支持自动地把前面的操作步骤翻译为不同平台兼容的SQL,包括Snowflake, Databricks, Maxcompute等等。对于数据使用者来讲,大家可以避免去熟悉不同平台的SQL方言,专注于数据本身,由工具来帮大家解决底层技术的问题。如下图: