




在上一篇文章中,我们了解了关于搜索技术、以文搜图,以及 CLIP 模型的基础知识。本篇我们将花上 5 分钟时间,对这些基础知识进行一次动手实践,快速构建一个「以文搜图」的搜索服务原型。
Notebook 链接👇
https://github.com/towhee-io/examples/blob/main/image/text_image_search/1_build_text_image_search_engine.ipynb
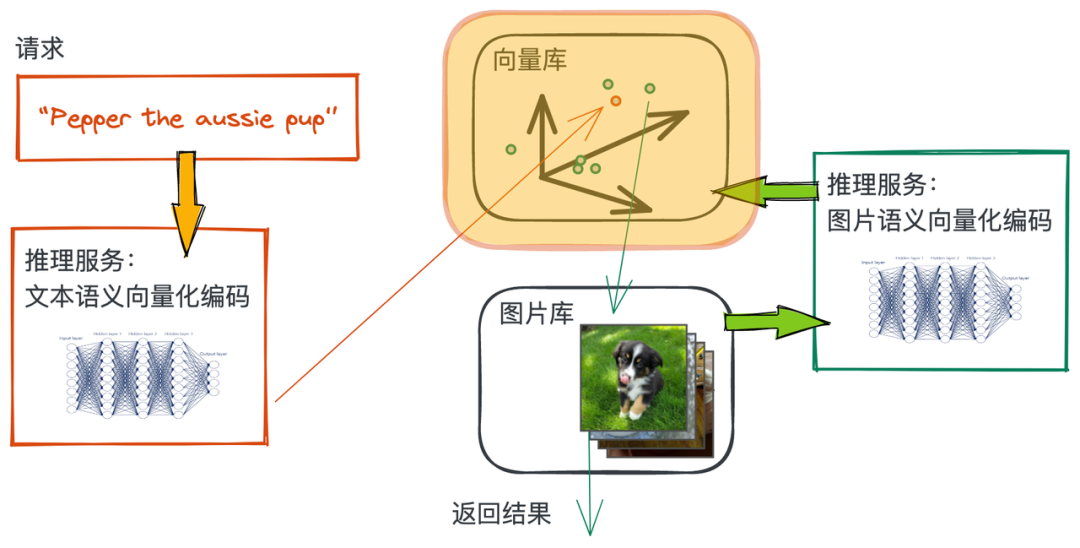
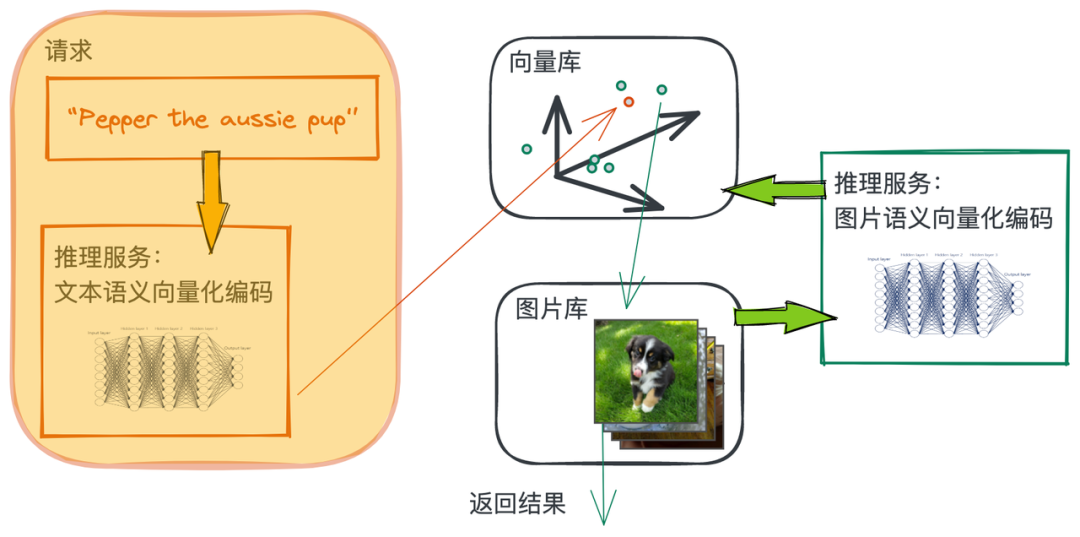
这里我们选取 “搜萌宠” 这个小例子:面对成千上万的萌宠,帮助用户在海量的图片中快速找到心仪的那只猫咪或修勾~

一个宠物的小型图片库。 一个能将宠物图片的语义特征编码成向量的数据处理流水线。 一个能将查询文本的语义特征编码成向量的数据处理流水线。 一个可以支撑向量近邻搜索的向量数据库。 一段能将上述所有内容串起来的 python 脚本程序。
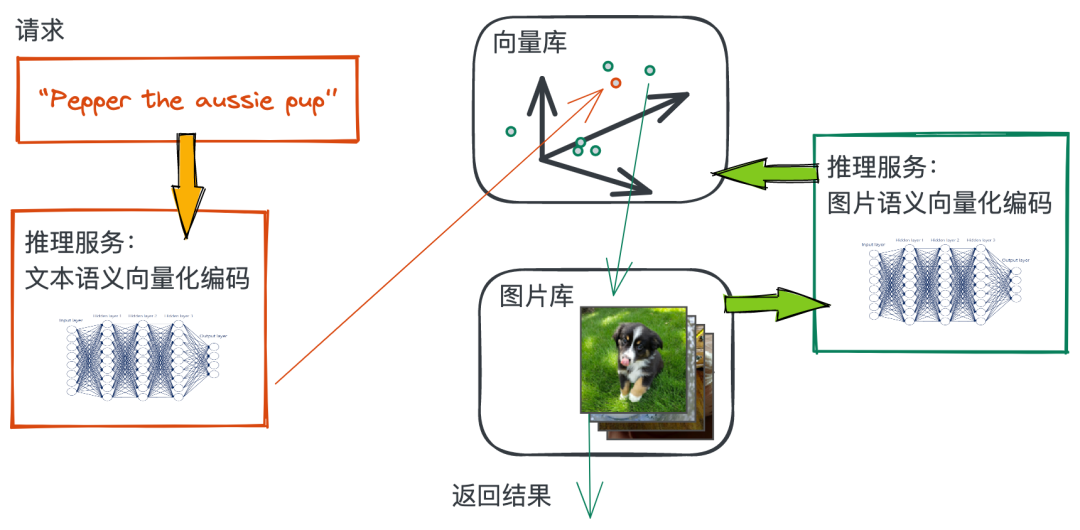
接下来,我们会陆续完成这张图的关键组件,开始干活~
安装基础工具包
我们用到了以下工具:
Towhee 用于构建模型推理流水线的框架,对于新手非常友好。 Faiss 高效的向量近邻搜索库。 Gradio 轻量级的机器学习 Demo 构建工具。
创建一个 conda 环境
conda create -n lovely_pet_retrieval python=3.9conda activate lovely_pet_retrieval
安装依赖
pip install towhee gradioconda install -c pytorch faiss-cpu
准备图片库的数据
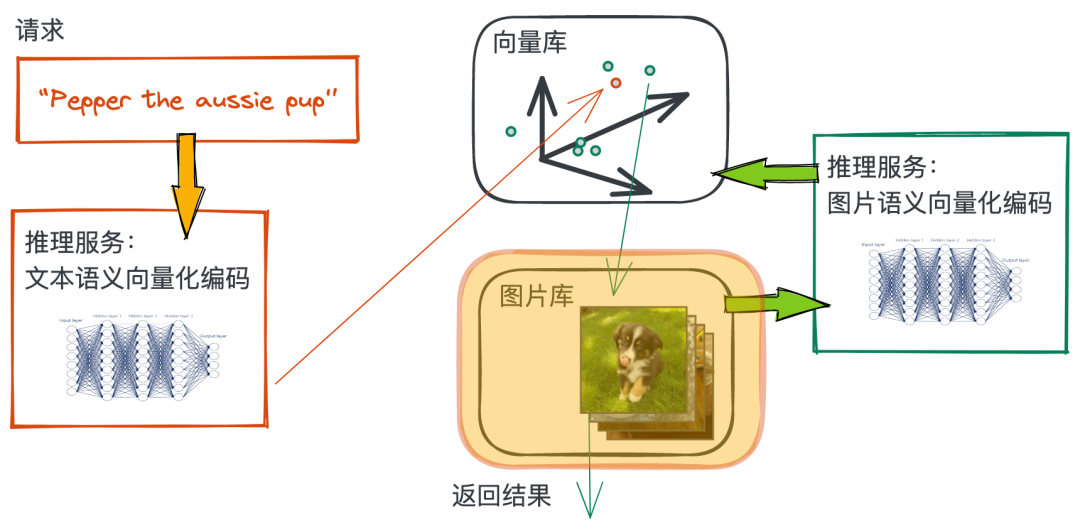
我们选取 ImageNet 数据集的子集作为本文所使用的 “小型宠物图片库”。首先,下载数据集并解压:
curl -L -O https://github.com/towhee-io/examples/releases/download/data/pet_small.zipunzip -q -o pet_small.zip
数据集的组织如下:
img: 包含 2500 张猫狗宠物图片 info.csv:包含 2500 张图片的基础信息,如图像的编号(id)、图片文件名(file_name)、以及类别(label)。
import pandas as pddf = pd.read_csv('info.csv')df.head()
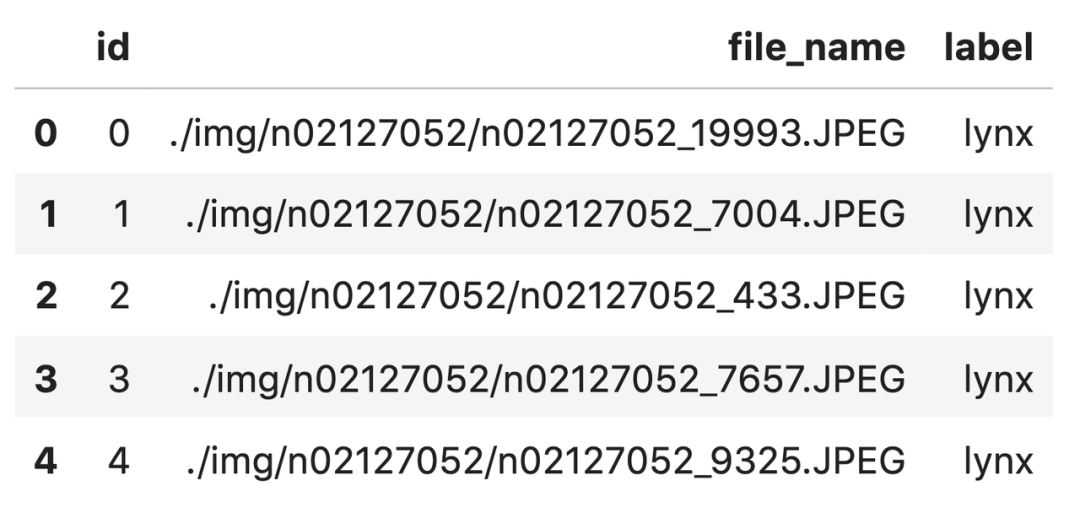
到这里,我们已经完成了关于图片库的准备工作 。
将图片的特征编码成向量
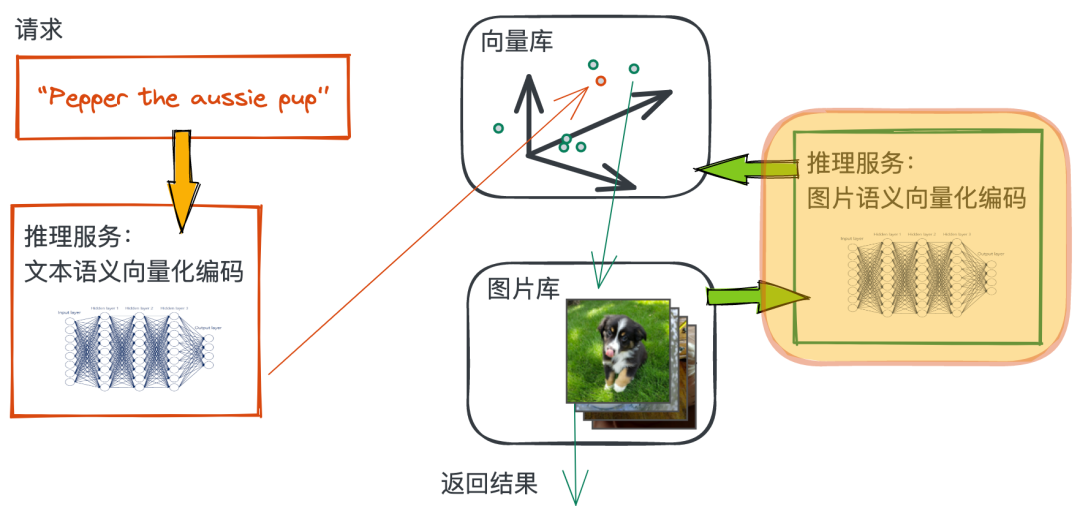
我们通过 Towhee 调用 CLIP 模型推理来生成图像的 Embedding 向量:
import towheeimg_vectors = (towhee.read_csv('info.csv').image_decode['file_name', 'img']().image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32', modality='image').tensor_normalize['vec','vec']() # normalize vector.select['file_name', 'vec']())
这里对代码做一些简要的说明:
read_csv('info.csv')
读取了三列数据到data collection,对应的 schema 为 (id,file_name,label)。image_decode['file_name', 'img']()
通过每行的file_name
读取图片文件,解码并将图片数据放入img
列。image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32',modality='image')
用clip_vit_b32
将img
列的每个图像的语义特征编码成向量,向量放到vec
列。tensor_normalize['vec','vec']()
将vec
列的向量数据做归一化处理。select['file_name', 'vec']()
选中file_name
和vec
两列作为最终结果。
创建向量库的索引
我们使用 Faiss 对图像的 Embedding 向量构建索引:
img_vectors.to_faiss['file_name', 'vec'](findex='./index.bin')
img_vectors 包含两列数据,分别是file_name
,vec
。Faiss 对其中的vec
列构建索引,并将每行的file_name
与vec
相关联。在向量搜索的过程中,file_name
信息会随结果返回。这一步可能会花上一些时间。
查询文本的向量化
查询文本的向量化过程与图像语义的向量化类似:
req = (towhee.dc['text'](['a samoyed lying down']).image_text_embedding.clip['text', 'vec'](model_name='clip_vit_b32', modality='text').tensor_normalize['vec', 'vec']().select['text','vec']())
这里对代码做一些简要的说明:
dc['text'](['a samoyed lying down'])
创建了一个data collection,包含一行一列,列名为text
,内容为 'a samoyed lying down'。image_text_embedding.clip['text', 'vec'](model_name='clip_vit_b32',modality='text')
用clip_vit_b32
将文本 'query here' 编码成向量,向量放到vec
列。注意,这里我们使用同样的模型(model_name='clip_vit_b32'
),但选择了文本模态(modality='text'
)。这样可以保证图片和文本的语义向量存在于相同的向量空间。tensor_normalize['vec','vec']()
将vec
列的向量数据做归一化处理。select['vec']()
选中text
,vec
列作为最终结果。
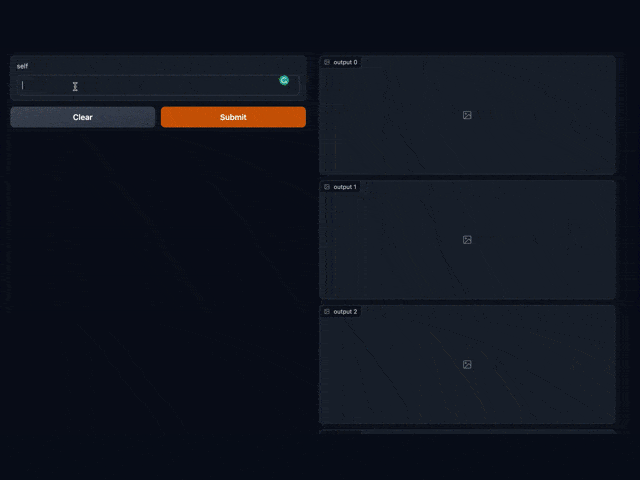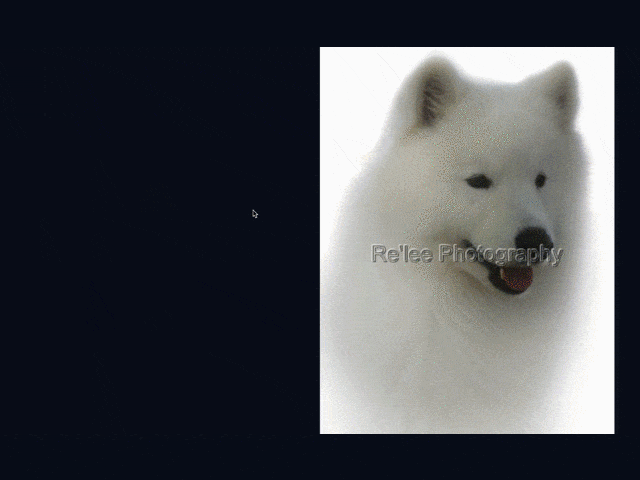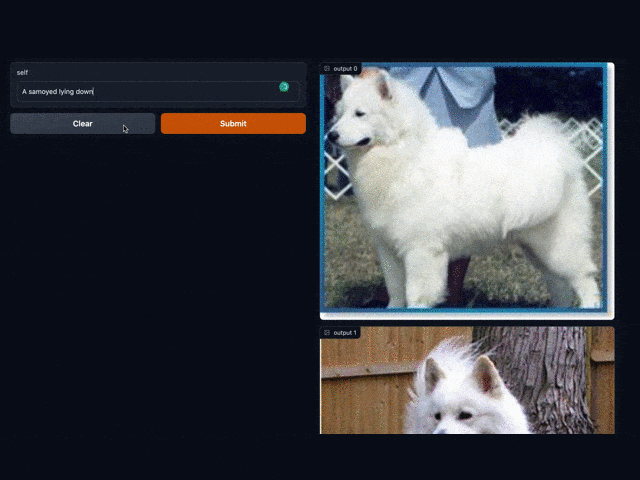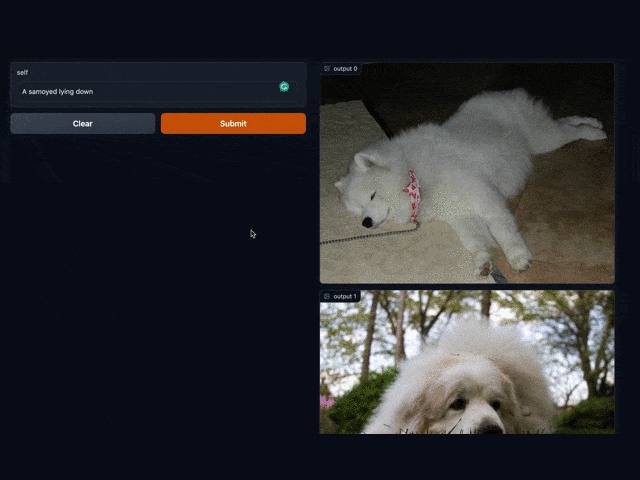
查询
我们首先定义一个根据查询结果读取图片的函数read_images
,用于支持召回后对原始图片的访问。
import cv2from towhee.types import Imagedef read_images(anns_results):imgs = []for i in anns_results:path = i.keyimgs.append(Image(cv2.imread(path), 'BGR'))return imgs
接下来是查询的流水线:
results = (req.faiss_search['vec', 'results'](findex='./index.bin').runas_op['results', 'result_imgs'](func=read_images).select['text', 'result_imgs']())results.show()
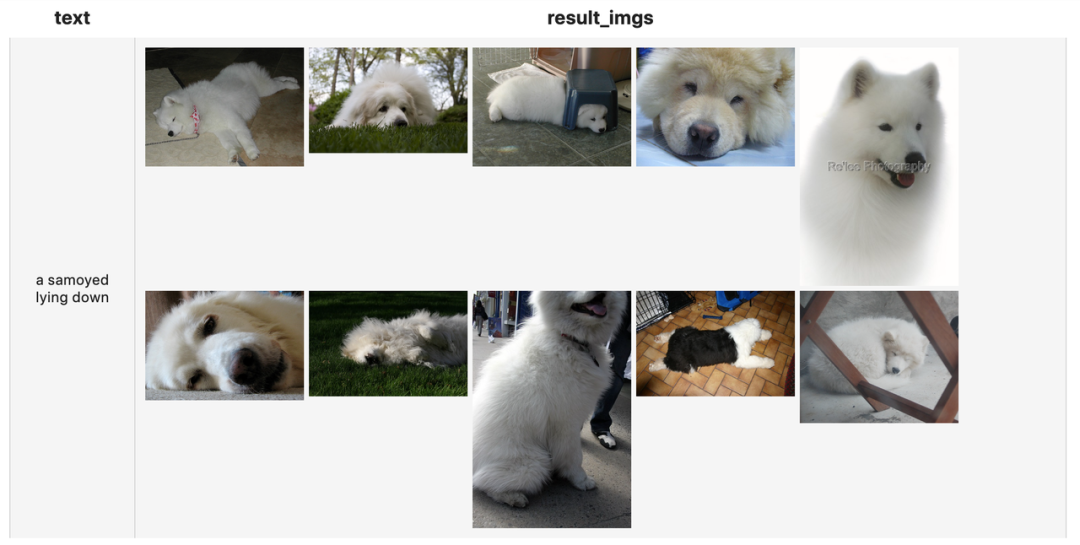
faiss_search['vec', 'results'](findex='./index.bin', k = 5)
使用文本对应的Embedding 向量对图片的向量索引index.bin
进行查询,找到与文本语义最接近的 5 张图片,并返回这 5 张图片所对应的文件名results
。runas_op['results', 'result_imgs'](func=read_images)
其中的 read_images 是我们定义的图片读取函数,我们使用runas_op
将这个函数构造为 Towhee 推理流水线上的一个算子节点。这个算子根据输入的文件名读取图片。select['text', 'result_imgs']()
选取text
和result_imgs
两列作为结果。
到这一步,我们以文搜图的完整流程就走完了,接下来,我们使用 Grado,将上面的代码包装成一个 demo。
使用 Gradio 打造 demo
首先,我们使用 Towhee 将查询过程组织成一个函数:
search_function = (towhee.dummy_input().image_text_embedding.clip(model_name='clip_vit_b32', modality='text').tensor_normalize().faiss_search(findex='./index.bin').runas_op(func=lambda results: [x.key for x in results]).as_function())
然后,创建基于 Gradio 创建 demo 程序:
import gradiointerface = gradio.Interface(search_function,gradio.inputs.Textbox(lines=1),[gradio.outputs.Image(type="file", label=None) for _ in range(5)])interface.launch(inline=True, share=True)
Gradio 为我们提供了一个 Web UI,点击 URL 进行访问(或直接与 notebook 下方出现的界面进行交互):
点击这个 URL 链接,就会跳转到我们「以文搜图」的交互界面,输入你想要的文字,即可呈现出与文字对应的图片。例如,我们输入 "puppy Corgi" (柯基小奶狗) 即可得到:
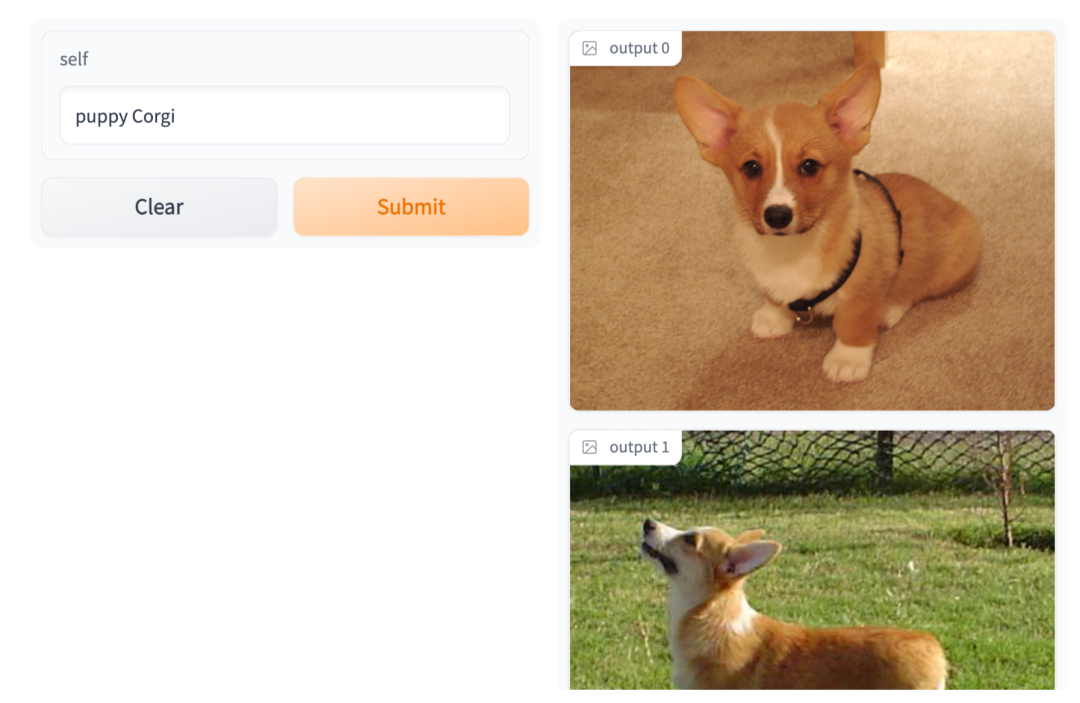
可以看到 CLIP 对于文本和图像的语义编码还是很细致的,像 “小奶狗” 这样的概念也被包含在了图片与文本的 Embedding 向量中。
总结
在本篇文章中,我们构建了一个以文搜图的服务原型(尽管非常小,但五脏俱全),并使用 Gradio 创建了可交互的 demo 程序。
在今天的这个原型中,我们用到了 2500 张图片,并用 Faiss 库对向量构建索引。但在真实的生产环境中,向量底库的数据量一般在千万级到十亿级,仅使用 Faiss 库难以满足大规模向量搜索所需要的性能、可扩展性、可靠性。在下一篇中,我们将进入进阶内容:学习使用 Milvus 向量数据库进行大规模向量的存储、索引、查询。敬请期待!
更多项目更新及详细内容请关注我们的项目( https://github.com/towhee-io/towhee ) ,您的关注是我们用爱发电的强大动力,欢迎 star, fork, slack 三连 :)
作者简介
编辑简介

