




1. 问题现象和原因概述
我行Hadoop集群生产环境的HBase在今年七八月份出现了一些请求响应缓慢以及数据不一致的现象,经分析发现问题的主要原因有两个方面:
1) 网卡打满导致请求响应缓慢:
通过查看问题发生时段集群服务器的网络流量情况,发现大量的RegionServer所在的服务器出现了网卡打满现象。随着我行大数据业务的快速发展,Hadoop集群所面临的数据读写压力也在不断增长,千兆网卡在应对大批量的数据通信请求时容易被打满,这种情况下就会大大影响数据的传输速度,进而产生请求响应缓慢的问题。
2) RegionServer进程JVM的负载过高:
随着业务的发展,我行HBase集群所承载的数据量也在不断增长,各个RegionServer中都维护了大量的Region,经常会出现单个RegionServer中包含一千多个Region的情况,大量的Region所对应的memstore就会占用较大的内存空间,同时也会出现频繁的memstore flush以及HFile的compaction操作,而磁盘刷写和compaction的执行也会加大磁盘写入的压力进而导致较高的IO wait,在这样的运行状态下HBase就非常容易出现请求响应缓慢,甚至产生较大的FullGC。
需要说明的是,当RegionServer出现长时间的GC后,其与Zookeeper的连接将超时断开,也就会导致RegionServer发生异常宕机,这种情况下随着Region的迁移而发生region not online的情况,甚至出现数据不一致,当出现数据不一致的时候就需要运维工程师进行手工数据修复才能恢复相关数据的访问;同时,由于Region的迁移还会导致其他的RegionServer需要负载更多的Region,这就使得整个集群的运行处于非常不稳定的状态。
如下是一次RegionServer发生Full GC的日志信息,一共持续了280秒:
[GC****-**-**T**:**:**.***+0800: 431365.526: [ParNew (promotion failed)Desired survivor size 107347968 bytes, new threshold 1 (max 6)- age 1: 215136792 bytes, 215136792 total: 1887488K->1887488K(1887488K), 273.7583160 secs]****-**-**T**:**:**.***+0800: 431639.284: [CMS: 15603284K->3621907K(20971520K), 7.1009550 secs] 17192808K->3621907K(22859008K), [CMS Perm : 47243K->47243K(78876K)], 280.8595860 secs] [Times: user=3044.83 sys=66.01, real=280.88 secs]****-**-**T**:**:**.***+0800: 431650.802: [GC****-**-**T**:**:**.***+0800: 431650.802: [ParNewDesired survivor size 107347968 bytes, new threshold 1 (max 6)- age 1: 215580568 bytes, 215580568 total: 1677824K->209664K(1887488K), 2.4204620 secs] 5299731K->4589910K(22859008K), 2.4206460 secs] [Times: user=35.54 sys=0.09, real=2.42 secs]Heap par new generation total 1887488K, used 1681569K [0x000000027ae00000, 0x00000002fae00000, 0x00000002fae00000) eden space 1677824K, 87% used [0x000000027ae00000, 0x00000002d4b68718, 0x00000002e1480000) from space 209664K, 100% used [0x00000002e1480000, 0x00000002ee140000, 0x00000002ee140000) to space 209664K, 0% used [0x00000002ee140000, 0x00000002ee140000, 0x00000002fae00000) concurrent mark-sweep generation total 20971520K, used 4380246K [0x00000002fae00000, 0x00000007fae00000, 0x00000007fae00000) concurrent-mark-sweep perm gen total 78876K, used 47458K [0x00000007fae00000, 0x00000007ffb07000, 0x0000000800000000)
长时间的JVM停顿使得RegionServer与Zookeeper的连接超时,进而导致了RegionServer的异常宕机:
INFO org.apache.hadoop.hbase.regionserver.HRegionServer: stopping server ***,***,1597296398937; zookeeper connection closed.INFO org.apache.hadoop.hbase.regionserver.HRegionServer: regionserver60020 exitingERROR org.apache.hadoop.hbase.regionserver.HRegionServerCommandLine: Region server exitingjava.lang.RuntimeException: HRegionServer Aborted at org.apache.hadoop.hbase.regionserver.HRegionServerCommandLine.start(HRegionServerCommandLine.java:66) at org.apache.hadoop.hbase.regionserver.HRegionServerCommandLine.run(HRegionServerCommandLine.java:85) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126) at org.apache.hadoop.hbase.regionserver.HRegionServer.main(HRegionServer.java:2493)INFO org.apache.hadoop.hbase.regionserver.ShutdownHook: Shutdown hook starting; hbase.shutdown.hook=true; fsShutdownHook=org.apache.hadoop.fs.FileSystem$Cache$ClientFinalizer@c678e87
2. HBase架构和概念
HBase 是一种面向列的分布式数据库,是Google BigTable的开源实现,适用于大数据量的存储(可支持上百亿行的数据),以及高并发地随机读写,针对rowkey的查询速度可达到毫秒级,其底层存储基于多副本的HDFS,数据可靠性较高,在我行的大数据业务中应用广泛。
HBase采用Master/Slave架构搭建集群,主要由HMaster、RegionServer、ZooKeeper集群这些组件构成,HBase的架构如下图所示:
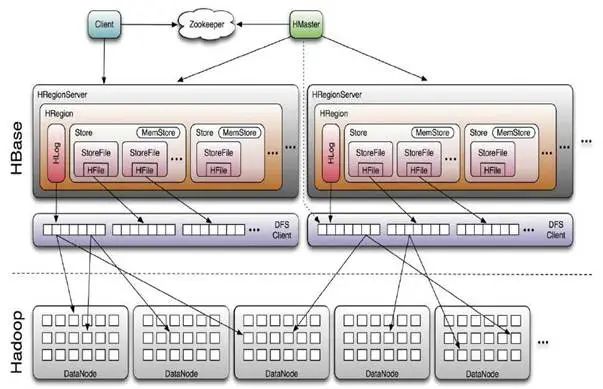
HBase Master : 负责监控所有RegionServer的状态,以及负责进行Region 的分配,DDL(创建,删除 table)等操作。
Zookeeper : 负责记录HBase中的元数据信息,探测和记录HBase集群中的服务状态信息。如果zookeeper发现服务器宕机, 它会通知Hbase的master节点负责维护集群状态。
Region Server : 负责处理数据的读写请求,客户端请求数据时直接和 Region Server 交互。
HRegion:HBase表在行的方向上分割为多个HRegion,HRegion是HBase中分布式存储和负载均衡的最小单元,不同的HRegion可以分别在不同的HRegionServer上,当HRegion的大小达到一定阀值时就会分裂成两个新的HRegion。
Store:每个region由1个以上Store组成,每个Store对应表的一个列族;一个Store由一个MemStore和多个StoreFile组成。
MemStore: 当RegionServer处理数据写入或者更新时,会先将数据写入到MemStore,当Memstore的数据量达到一定数值后会将数据刷写到磁盘,保存为一个新的StoreFile。
StoreFile:一个列族中的数据保存在一个或多个StoreFile中,每次MemStore flush到磁盘上会形成一个StoreFile文件,对应HDFS中的数据文件HFile。
3. Region数对HBase的影响分析
3.1 HBase flush
3.1.1 HBase flush的触发条件
HBase在数据写入时会先将数据写到内存中的MemStore,然后再将数据刷写到磁盘的中。
RegionServer在启动时会初始化一个MemStoreFlusher(实现了FlushRequester接口)线程,该线程不断从flushQueue队列中取出相关的flushrequest并执行相应的flush操作:
public void run() { while (!server.isStopped()) { FlushQueueEntry fqe = null; try { wakeupPending.set(false); // allow someone to wake us up again fqe = flushQueue.poll(threadWakeFrequency, TimeUnit.MILLISECONDS); ... FlushRegionEntry fre = (FlushRegionEntry) fqe; if (!flushRegion(fre)) { break; } } ...
HBase发生MemStore刷写的触发条件主要有如下几种场景:
1.MemStore级flush
当一个 MemStore 大小达到阈值 hbase.hregion.memstore.flush.size(默认128M)时,会触发 MemStore 的刷写。
/* * @param size * @return True if size is over the flush threshold */ private boolean isFlushSize(final long size) { return size > this.memstoreFlushSize; } ... flush = isFlushSize(size); ... if (flush) { // Request a cache flush. Do it outside update lock. requestFlush(); }
2.Region级flush
当一个Region中所有MemStore的大小之和达到hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier(默认128MB * 2),则会触发该 MemStore的磁盘刷写操作;
每当有数据更新操作时(例如put、delete)均会检查当前Region是否满足内存数据的flush条件:
this.blockingMemStoreSize = this.memstoreFlushSize * conf.getLong("hbase.hregion.memstore.block.multiplier", 2); ... if (this.memstoreSize.get() > this.blockingMemStoreSize) { requestFlush(); ...
其中requestFlush操作即将flush请求加入到RegionServer的flushQueue队列中:
public void requestFlush(HRegion r) { synchronized (regionsInQueue) { if (!regionsInQueue.containsKey(r)) { // This entry has no delay so it will be added at the top of the flush // queue. It'll come out near immediately. FlushRegionEntry fqe = new FlushRegionEntry(r); this.regionsInQueue.put(r, fqe); this.flushQueue.add(fqe); } } }...
3.RegionServer级flush
当一个RegionServer中所有MemStore的大小总和达到 hbase.regionserver.global.memstore.upperLimit * HBASE_HEAPSIZE(默认值0.4 * 堆空间大小,也即RegionServer 级flush的高水位)时,会从该RegionServer中的MemStore最大的Region开始,触发该RegionServer中所有Region的Flush,并持续检查当前memstore内存是否高于高水位,来阻塞整个RegionServer的更新请求。
直到该RegionServer的MemStore大小回落到前面的高水位内存值的hbase.regionserver.global.memstore.lowerLimit倍时(默认0.35*堆大小,低水位)才解除更新阻塞。
/** * Check if the regionserver's memstore memory usage is greater than the * limit. If so, flush regions with the biggest memstores until we're down * to the lower limit. This method blocks callers until we're down to a safe * amount of memstore consumption. */ public void reclaimMemStoreMemory() { TraceScope scope = Trace.startSpan("MemStoreFluser.reclaimMemStoreMemory"); if (isAboveHighWaterMark()) { if (Trace.isTracing()) { scope.getSpan().addTimelineAnnotation("Force Flush. We're above high water mark."); } long start = System.currentTimeMillis(); synchronized (this.blockSignal) { boolean blocked = false; long startTime = 0; while (isAboveHighWaterMark() && !server.isStopped()) { if (!blocked) { startTime = EnvironmentEdgeManager.currentTimeMillis(); LOG.info("Blocking updates on " + server.toString() + ": the global memstore size " + StringUtils.humanReadableInt(server.getRegionServerAccounting().getGlobalMemstoreSize()) + " is >= than blocking " + StringUtils.humanReadableInt(globalMemStoreLimit) + " size"); } blocked = true; wakeupFlushThread(); try { // we should be able to wait forever, but we've seen a bug where // we miss a notify, so put a 5 second bound on it at least. blockSignal.wait(5 * 1000); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); }
4.RegionServer定期Flush MemStore
周期为hbase.regionserver.optionalcacheflushinterval
(默认值1小时)。为了避免所有Region同时Flush,定期刷新会有随机的延时。
protected void chore() { for (HRegion r : this.server.onlineRegions.values()) { if (r == null) continue; if (r.shouldFlush()) { FlushRequester requester = server.getFlushRequester(); if (requester != null) { long randomDelay = rand.nextInt(RANGE_OF_DELAY) + MIN_DELAY_TIME; LOG.info(getName() + " requesting flush for region " + r.getRegionNameAsString() + " after a delay of " + randomDelay); //Throttle the flushes by putting a delay. If we don't throttle, and there //is a balanced write-load on the regions in a table, we might end up //overwhelming the filesystem with too many flushes at once. requester.requestDelayedFlush(r, randomDelay); } } ...
3.1.2 HBase flush的影响分析
大部分Memstore Flush操作都不会对数据读写产生太大影响,比如MemStore级别的flush、Region 级别的flush,然而如果触发RegionServer级别的flush,则会阻塞所有该 RegionServer 上的更新操作。
每次Memstore Flush都会为每个列族创建一个HFile,频繁的Flush就会创建大量的HFile,并且会使得HBase在检索的时候需要读取大量的HFile,较多的磁盘IO操作会降低数据的读性能。
另外,每个Region中的一个列族对应一个MemStore,并且每个HBase表至少包含一个的列族,则每个Region会对应一个或多个MemStore。HBase中的一个MemStore默认大小为128 MB,当RegionServer中所维护的Region数较多的时候整个内存空间就比较紧张,每个MemStore可分配到的内存也会大幅减少,此时写入很小的数据量就会可能出现磁盘刷写,而频繁的磁盘写入也会对集群服务器带来较大的性能压力。
3.2 HBase Compaction
3.2.1 HBase Compaction的产生
Memstore 刷写到磁盘会生成HFile文件,随着HFile文件积累的越来越多就需要通过compact操作来合并这些HFile。
HBase的Compaction的触发主要有三种情况:Memstore flush、后台线程周期性执行和手工触发。
1)HBase每次发生Memstore flush后都会判断是否要进行compaction,如果满足条件则会触发compation操作:
private boolean flushRegion(final HRegion region, final boolean emergencyFlush) { synchronized (this.regionsInQueue) { FlushRegionEntry fqe = this.regionsInQueue.remove(region); if (fqe != null && emergencyFlush) { // Need to remove from region from delay queue. When NOT an // emergencyFlush, then item was removed via a flushQueue.poll. flushQueue.remove(fqe); } } lock.readLock().lock(); try { boolean shouldCompact = region.flushcache().isCompactionNeeded(); // We just want to check the size boolean shouldSplit = region.checkSplit() != null; if (shouldSplit) { this.server.compactSplitThread.requestSplit(region); } else if (shouldCompact) { server.compactSplitThread.requestSystemCompaction( region, Thread.currentThread().getName()); } ...
2)后台线程 CompactionChecker 会定期检查是否需要执行compaction,检查周期为hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier, hbase.server.thread.wakefrequency 默认值 10000 即 10s,hbase.server.compactchecker.interval.multiplier 默认值1000。
3)手动触发的场景主要是系统管理员根据需要通过HBase Shell、HBase的API等方式来自主执行compact操作,例如禁用自动Major compaction,改为在业务低峰期定期触发。
HBase compaction相关的配置参数:
1)hbase.hstore.compactionthreshold:一个列族下的HFile数量超过该值就会触发Minor Compaction。
2)hbase.hstore.compaction.max:一次Minor Compaction最多合并的HFile文件数量,避免一次合并太多的文件对regionserver 性能产生太大影响。
3)hbase.hstore.blockingStoreFiles:一个列族下HFile数量达到该值就会阻塞写入,直到Compaction完成,应适当调大该值避免阻塞写入的发生。
4)hbase.hregion.majorcompaction:默认7天,Major Compaction持续时间长、计算资源消耗大,建议在业务低峰期进行HBase Major Compaction。
5)hbase.hstore.compaction.max.size : minor compaction时HFile大小超过这个值则不会被选中,防止过大的HFile被选中合并后出现较长时间的compaction
3.2.2 HBase Compaction对HBase性能的影响
RegionServer因内存紧张会导致频繁的磁盘刷写,因而会在磁盘上产生非常多的HFile小文件,当小文件过多的时候HBase为了保障查询性能就会不断地触发Compaction操作。
大量的HFile合并操作的执行会给集群服务器带来较大的带宽压力和磁盘IO压力,进而影响数据的读写性能。
4. HBase Split
Split是HBase的一个重要功能,HBase 通过把数据分配到一定数量的Region中来达到负载均衡的目的,当Region管理的数据量较大时可以通过手动或自动的方式来触发HBase Split从而将一个 Region 分裂成两个新的子 Region。
HBase 运行中有3种情况会触发Region Split的执行:
1)每次执行了Memstore flush 操作后会判断是否需要执行Split,由于flush的数据会写入到一个 HFile中,如果产生较大的HFile则会触发Split。
2)HStore 执行完Compact 操作之后可能会产生较大的HFile,此时会判断是否需要执行 Split。
3)系统管理员通过手工执行split 命令时来触发 Split。
HBase Split的过程如下图所示:
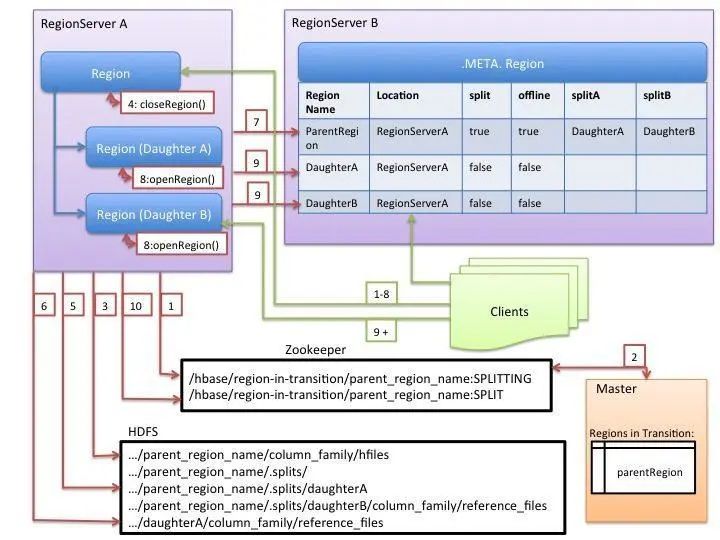
HBase Split的过程描述如下:
1)在ZK节点 hbase/region-in-transition/region-name 下创建一个 znode,并设置状态为SPLITTING
2)RegionServer 在父 Region 的数据目录下创建一个名为 .splits 的目录,RegionServer 关闭父 Region,强制将数据 flush 到磁盘,并将这个 Region 标记为 offline 的状态,客户端需要进行一些重试,直到新的 Region 上线。
3)RegionServer 在 .splits 目录下创建 daughterA 和 daughterB 子目录
4)RegionServer 启用两个子 Region,并正式提供对外服务,并将 daughterA 和 daughterB 添加到 .META 表中,并设置为 online 状态,这样就可以从 .META 找到这些子 Region,并可以对子 Region 进行访问了。
5)RegionServr 修改ZK节点 hbase/region-in-transition/region-name 的状态为SPLIT,从而完成split过程。
目前我行的HBase版本较低,split的中间态是存储在内存中的,一旦在split过程中发生RegionServer宕机就可能会出现RIT,这种情况下就需要使用hbck 工具进行手工数据修复,因此尽量减少split以及保持RegionServer的运行稳定对于hbase的数据一致性至关重要。
5. 当前的解决方案
根据以上分析我行HBase的问题主要在于基础设置问题以及每个RegionServer管理的region数过多导致服务异常的问题,所以接下来就是针对性地解决以上问题。
我们从八月中旬开始制定问题解决方案,经过与开发和运维的同事、以及星环的工程师反复沟通和商议,第一期解决方案主要如下:
1)大批量的数据归档和迁移操作避开业务高峰期,并且后续计划将集群服务器升级为万兆网卡并接入万兆网络环境;
2)扩容RegionServer的堆内存,缓解JVM压力;
3)设置minor compaction的最大值(hbase.hstore.compaction.max.size),避免minor compaction过程过于缓慢,减轻regionserver的处理压力;
4)关闭majorcompaction自动执行,将major compaction 放在业务低峰期定时执行;
5)系统负责人设置或者减小HBase表的TTL值,使得已过期的数据能够得到定期清理,避免无效数据占用大量的Region;
6)调大Region的最大值hbase.hregion.max.filesize,避免频繁的region分裂;
7)针对线上region数较多的表,在维护窗口对数据表进行在线的region合并;
8)部分表进行重建,并设置合理的分区数;
9)将一些不适用HBase的业务场景迁移至其他组件。
6. HBase相关工作建议
通过上述一系列的改造和优化,最近几个月以来我行的HBase运行已经比较平稳了,接下来在我们的开发和运维工作需要吸取之前的经验教训,争取在有力支撑我行大数据业务快速开展的同时还能够提供稳定的运行环境,下面是我总结的一些HBase在表设计和运维工作中一些注意事项,希望能带给大家一些启示,其中很多措施正在实施或者已经实施完成:
1) 建表时注意设置合理的TTL,并且通过评估数据量来配置合理的分区数;
2) 每张表尽量设计较少的column family数量,以减少memstore数和减轻regionserver的运行压力;
3) 实时监控每个regionserver管理的region数,并增加相应的预警功能;
从目前生产环境的运行情况来看,当单个regionserver所负载的region数超过800个时则会处于非常不稳定的状态。
4) 通过实时采集HBase的性能指标(包括:请求数、连接数、平均执行时间和慢操作数等)来辅助分析HBase集群的运行状态和问题;
5) HBase在出现hang或者宕机的情况下,注意巡检HBase的数据一致性,避免影响业务数据的访问;
6) 监控RegionServer的 JVM 使用率,当JVM负载过高的情况下考虑适当调大RegionServer的堆内存。
作者简介:焦媛,2011年加入民生银行,目前主要负责Hadoop平台的运行维护和相关工具的研发,以及HDFS和Spark相关产品的技术支持工作。

