




基于基本的存储格式,Oracle 还提供了一些其他类型的索引,下面做一个简要介绍:
反转键值索引(Reverse Key Index)
反转键值索引是将索引字段值按字节为反转后再作为键值存储。 例如,索引字段的部分值分别如下:
ROW1: AAA ROW2:AAB ROW3:ABA ROW4:AAC
那么,普通索引的结构将可能是如下结构:
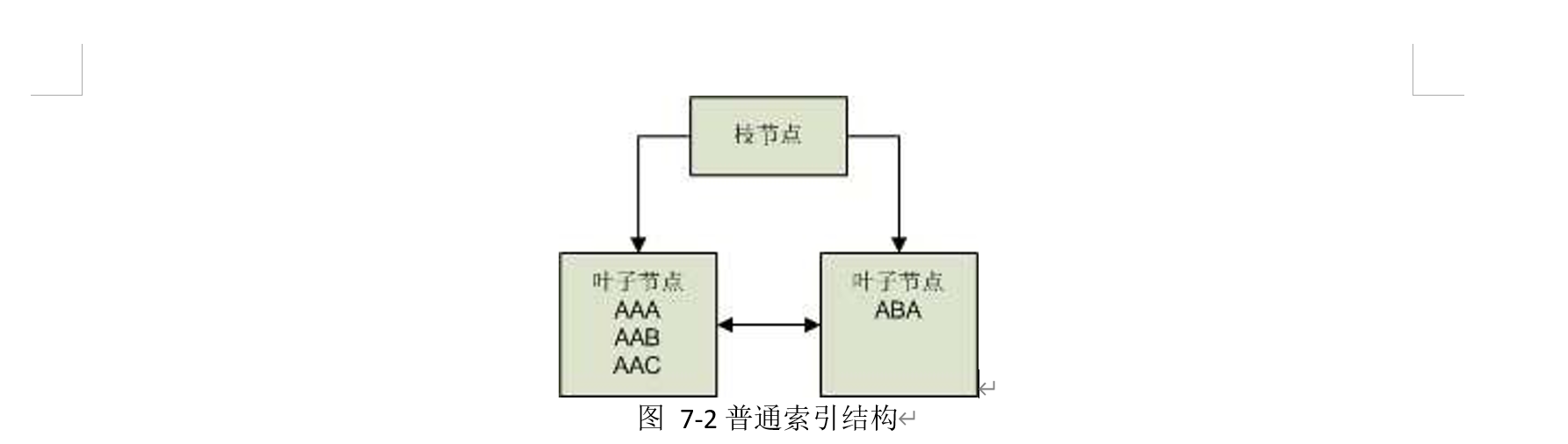
而创建为反转键值索引,它们的值需要反转后作为键值,即:
原始值 反转值
AAA AAA
AAB BAA
ABA ABA
AAC CAA
反转键值索引将可能变为如下结构:
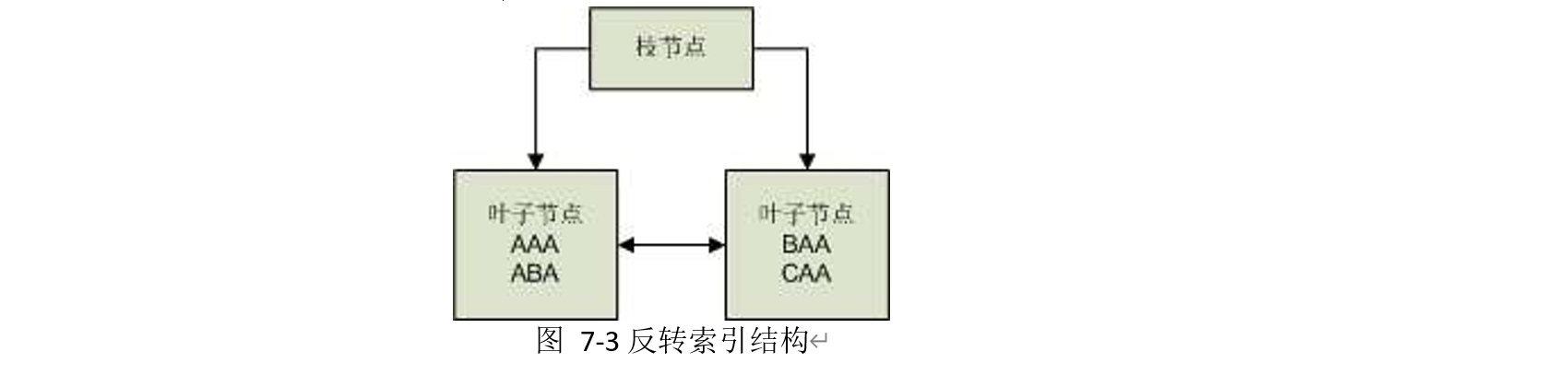
通常,创建反转键值索引的目的是减少数值递增或递减的索引字段导致的频繁索引分裂问题、 或者减少索引数据块在 RAC 环境中被争用。但这种索引存在诸多限制,例如无法进行范围扫描。
降序索引
普通索引存储时,会以键值按照升序进行存储。通过在创建索引时,为字段指定 DESC 关键字, 索引则按其降序存储键值。
函数索引(Function-Based Index,FBI)
函数索引不以字段的原始数值为键值,而是以一个表达式(包含允许的函数和一到多个字段) 值为键值。例如,我们希望不区分大小写来检索某个字符类型字段时,为了提高检索效率,可以在 字段创建一个函数索引:UPPER(COL)。检索时,将绑定变量值也变为大写:UPPER(COL) =
UPPER(:VAR)。
位图关联索引(Bitmap Join Index)
位图关联索引是一种特殊的位图索引。索引键值来源于建立的表,但是仅当映射的表记录的索 引字段值与键值匹配并且满足与一个到多个表的关联关系时,映射为 1,否则为 0。例如,在我们的示例表 T_OBJECTS 上,T_OBJECTS_IDX2 是一个建立在字段 STATUS 上的普通位图索引,
T_OBJECTS_IDX3 则是建立在字段 STATUS 上并与表 T_USERS 关联的位图关联索引。假如 T_OBJECTS
和 T_USERS 分别如下:


那么,在 T_OBJECTS_IDX2 键值为“INVALID”的索引记录上,未压缩的映射位为:00001100; 在 T_OBJECTS_IDX3 键值为“INVALID”的索引记录上,未压缩的映射位为:00000100————因为
T_OBJECTS 中 OWNER 为“NOBODY”的记录与 T_USERS 的 USERNAME 关联不上。
索引查找
除非是完全索引扫描或完全快速扫描,对索引进行查找时需要有一个访问条件(Access
Predication)。而我们现在知道,Oracle 的索引的基本数据结构是 B*Tree,对索引的查找就是从根节点开始,逐步匹配到满足访问条件的叶子节点的索引记录,再由过滤条件过滤掉不匹配的索引记 录。由于,叶子节点本身是一个按照键值顺序的双向链表,因此以这个过程进行检索,则每层枝节 点访问且仅访问一个节点,直到找到第一个满足访问条件的叶子节点,然后再由叶子节点上的双向 链表找到其它所有满足访问条件的叶子节点。如果还需要获取除索引字段和 ROWID 以外其它表字段,则再由索引记录中的 ROWID 访问表。
o 无需访问表的情况。
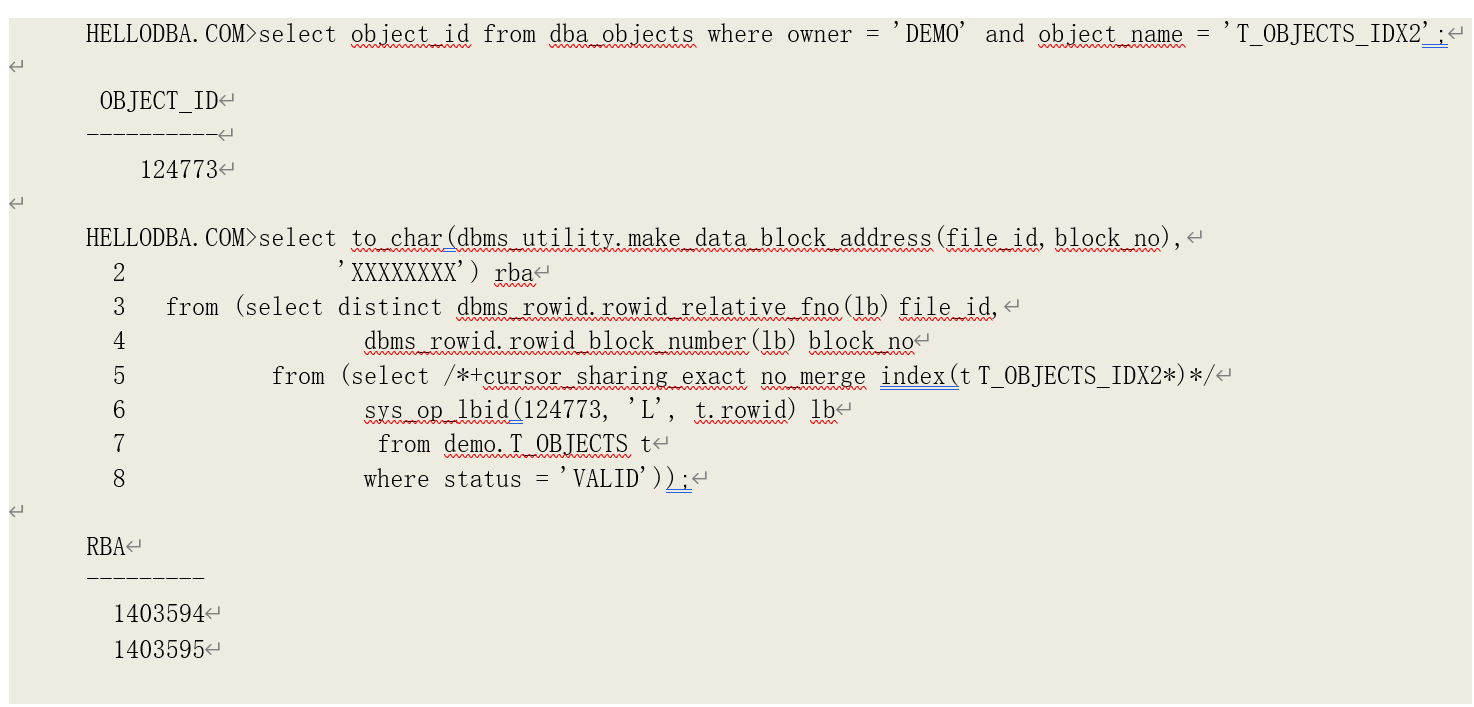
根据上述索引扫描的过程描述,我们可以得知索引数据块的访问次数等于:索引枝节点层数+ 满足访问条件的叶子节点数据块数。我们以以下查询为例,分析这种情况下索引范围扫描的逻辑读的来源:
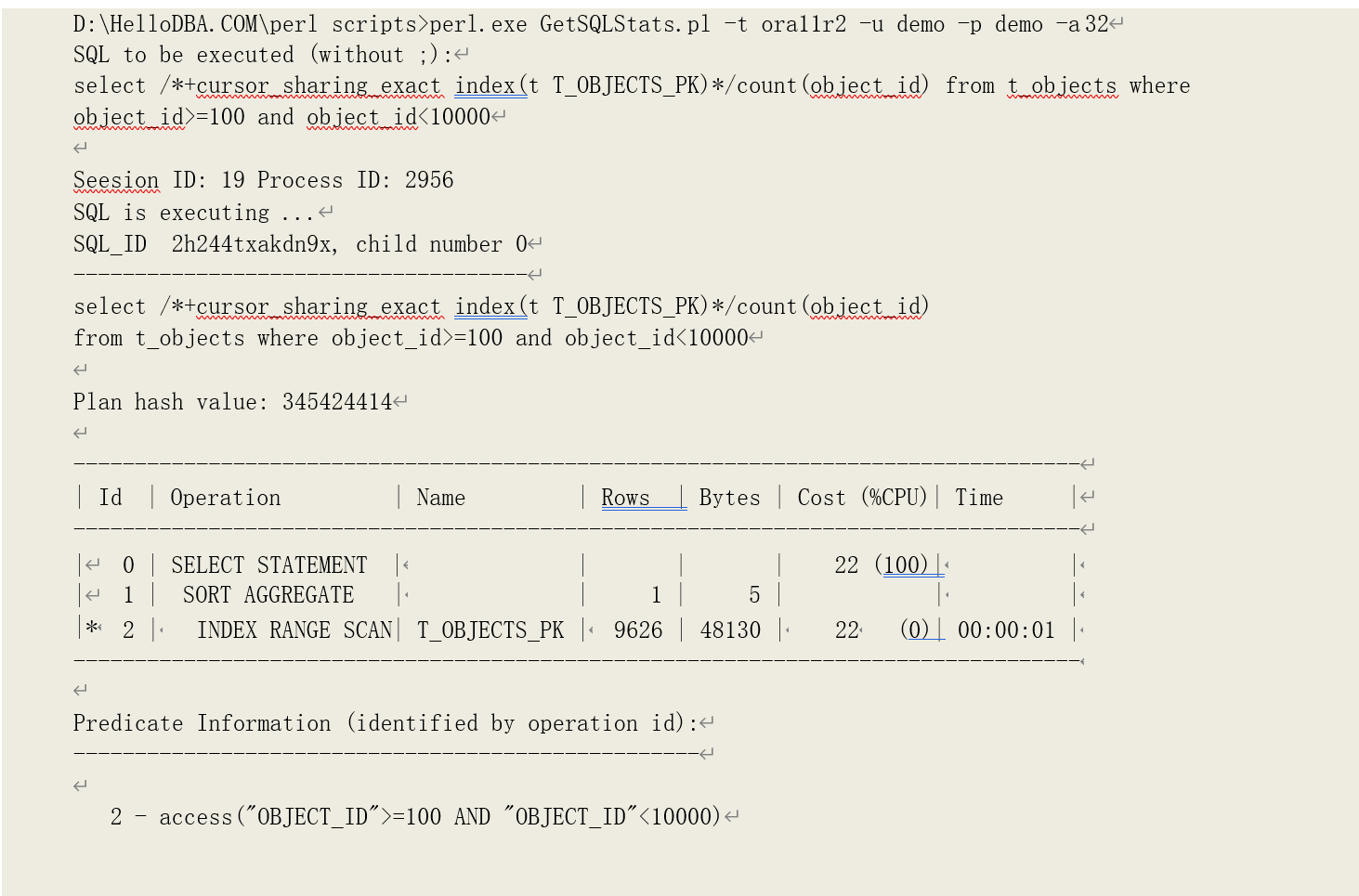

该查询是对索引 T_OBJECTS_PK 进行范围扫描,访问条件为"OBJECT_ID">=100 AND
“OBJECT_ID”<10000,总共产生了 18 次逻辑读。我们看下该索引的枝节点层数是多少:

枝节点层数为 1,即需要访问 1 个枝节点数据块。再通过 Oracle 的非公开函数 sys_op_lbid(前面章节有介绍)看看满足访问条件的索引记录存在那些叶子节点数据块当中:


可以看到,有 17 个叶子节点数据块。再加上一个枝节点,等于 18,即产生 18 次逻辑读。再看位图索引的情况:
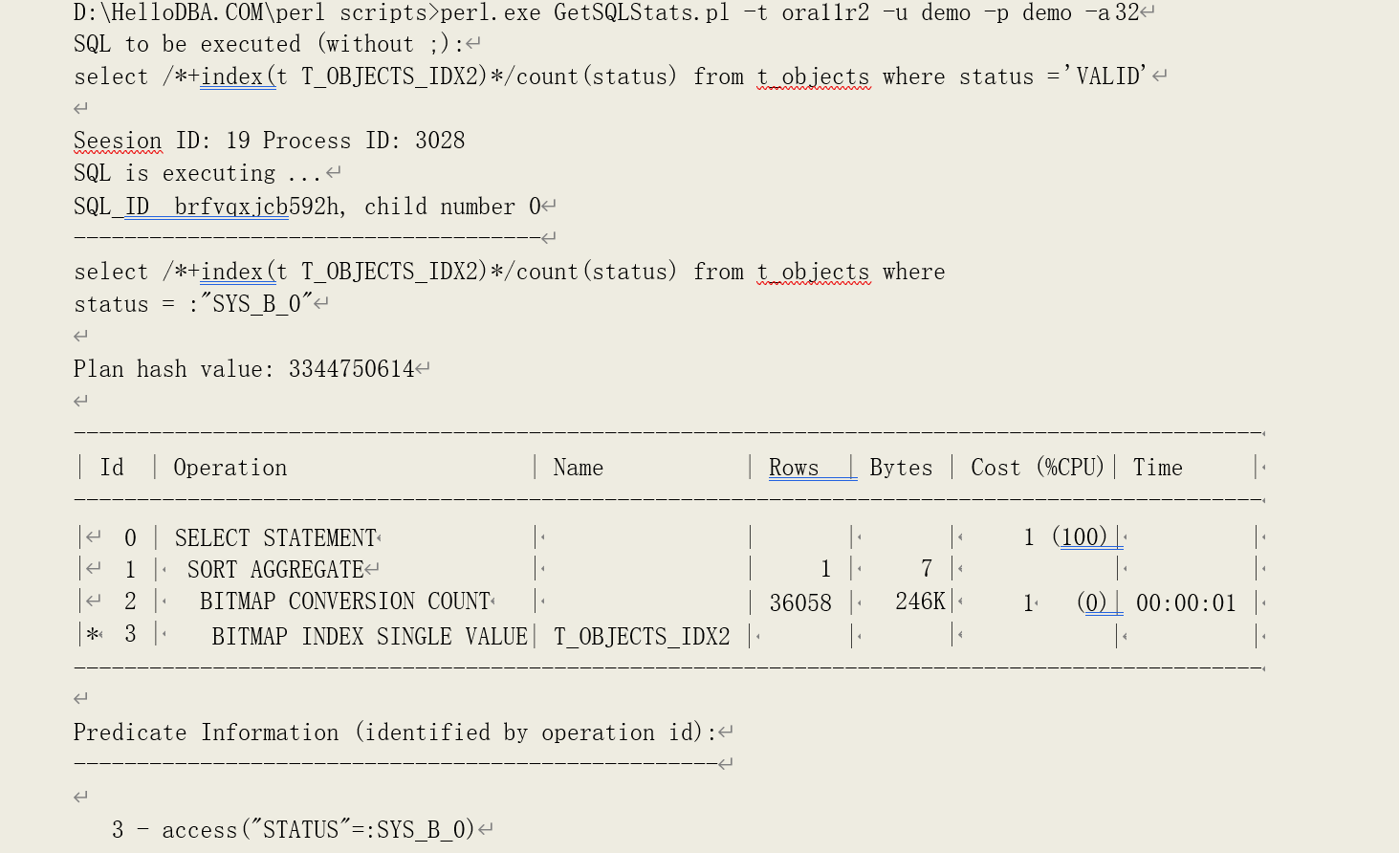

产生了 3 次逻辑读。


索引的枝节点层数为 1:
访问的叶子节点数为 2,加上一个枝节点,等于 3,即逻辑读次数。
提示:以一致性模式读取数据块到缓存中时,可以大致分为两个阶段:检查用于管理缓存数据块头 的哈希表、以确认当前数据块是否已经在缓存当中(如果不存在就需要从物理磁盘读入数据块内 容);Pin 住缓存数据块并读取缓存数据块的内容、根据具体情况决定是否做一致性回滚。由于枝节点通常很少被修改(一般发生在其下层节点分裂时),因此在大多数情况下,仅需要检查其是否 已经在缓存中,即不进行 pin 操作。相应的,这样的一致性读次数被统计为“consistent gets -
examination”。
o 由索引 ROWID 访问表
由索引读取到的 ROWID 再访问表时,如果连续的 ROWID 都指向同一个表数据块,那么这个数据块只需要读取一次以获取这些 ROWID 所指向的记录。但如果,后续的 ROWID 中还有记录指向该数据块,则它需要被再次读取。因此,由索引 ROWID 访问表所产生的逻辑读等于连续的 ROWID 所指向的表数据块位置的变换次数。
我们看以下示例:

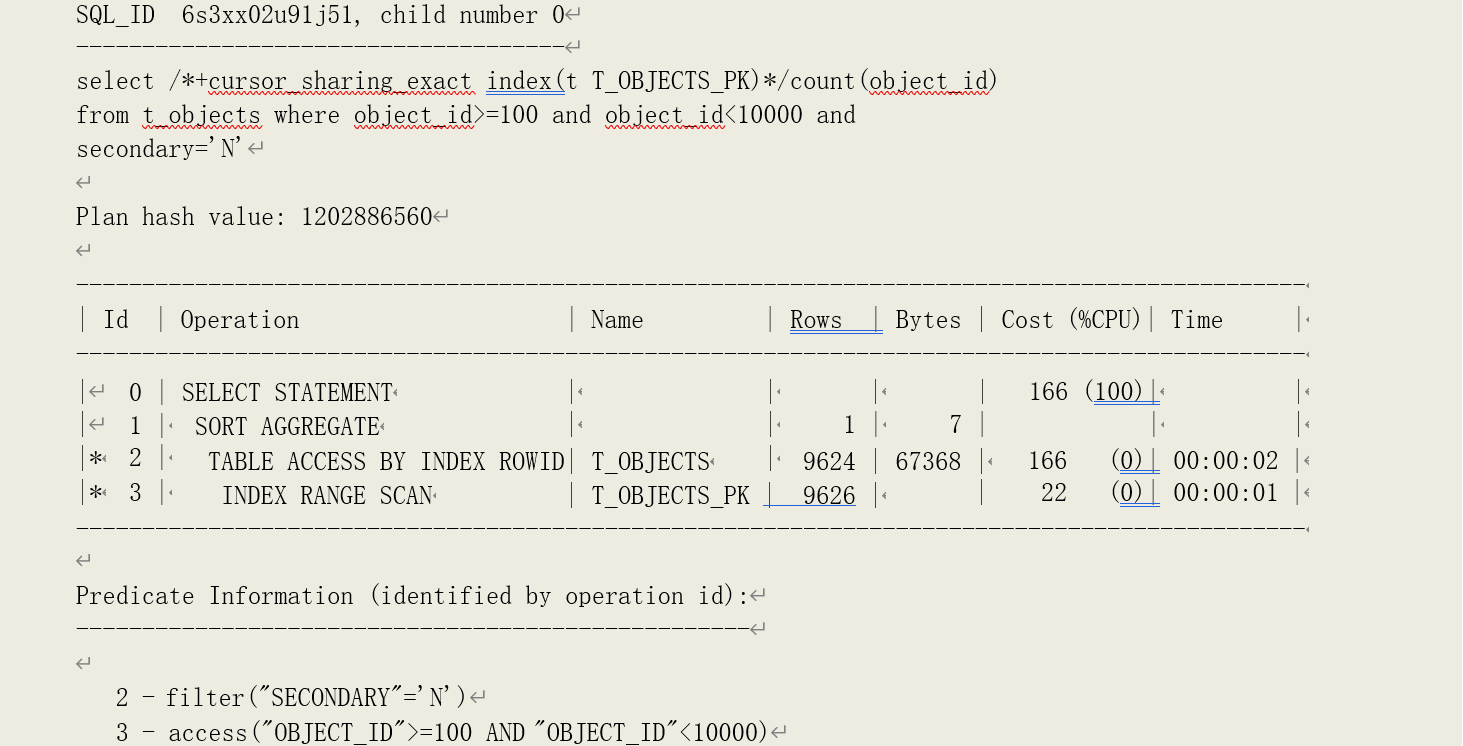

可以看到,该查询产生了 304 次逻辑读。其中,对索引的访问条件和前例相同,因此,有索引ROWID 访问表所产生的逻辑读次数为 304-18=286。我们再利用函数 sys_op_countchg(前面章节有介绍)来获取连续 ROWID 指向的数据块位置的变换次数:
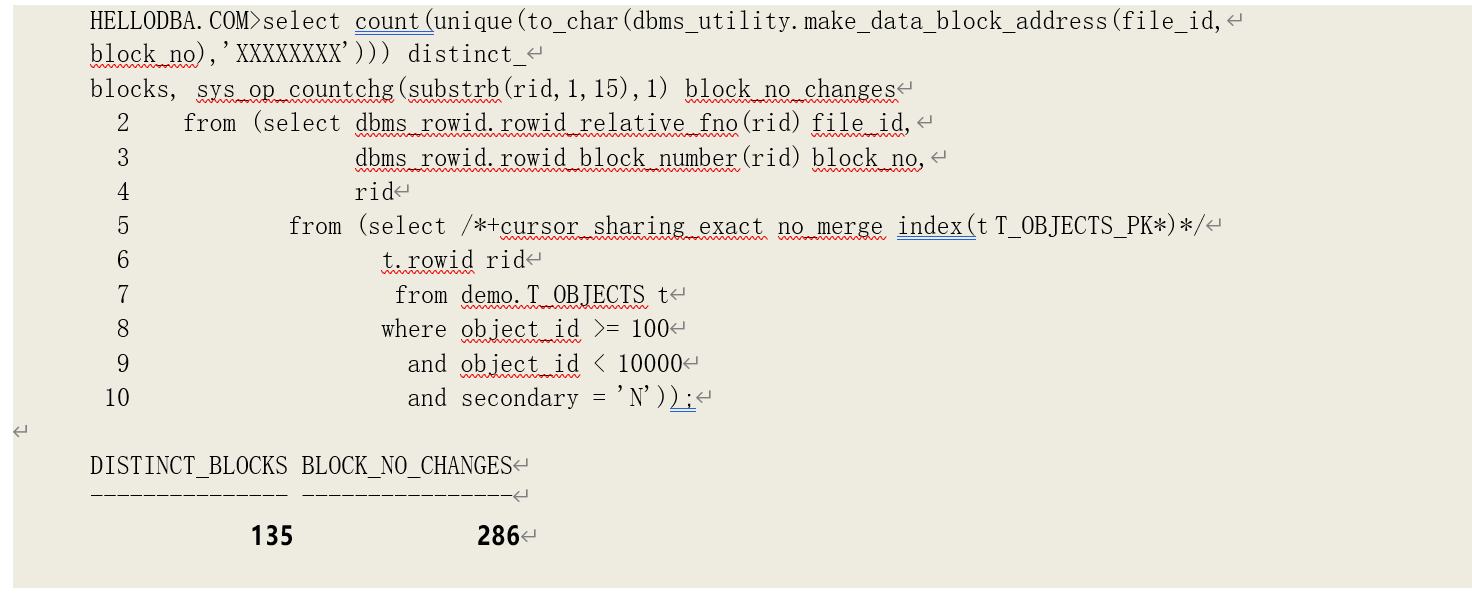
可以看到,尽管所有 ROWID 指向 135 块表数据块,但连续 ROWID 指向的数据块位置的变换次数为 286,即等于实际的逻辑读次数(304-18)。
全表扫描
全表扫描是一种多数据块读的操作,它会读取存储段(Segment)的高水位线(High Water
Mark)以下的所有已经被格式化的数据块。
提示:非分区表、非本地分区索引、(表或索引的)分区都会有独立的存储段。
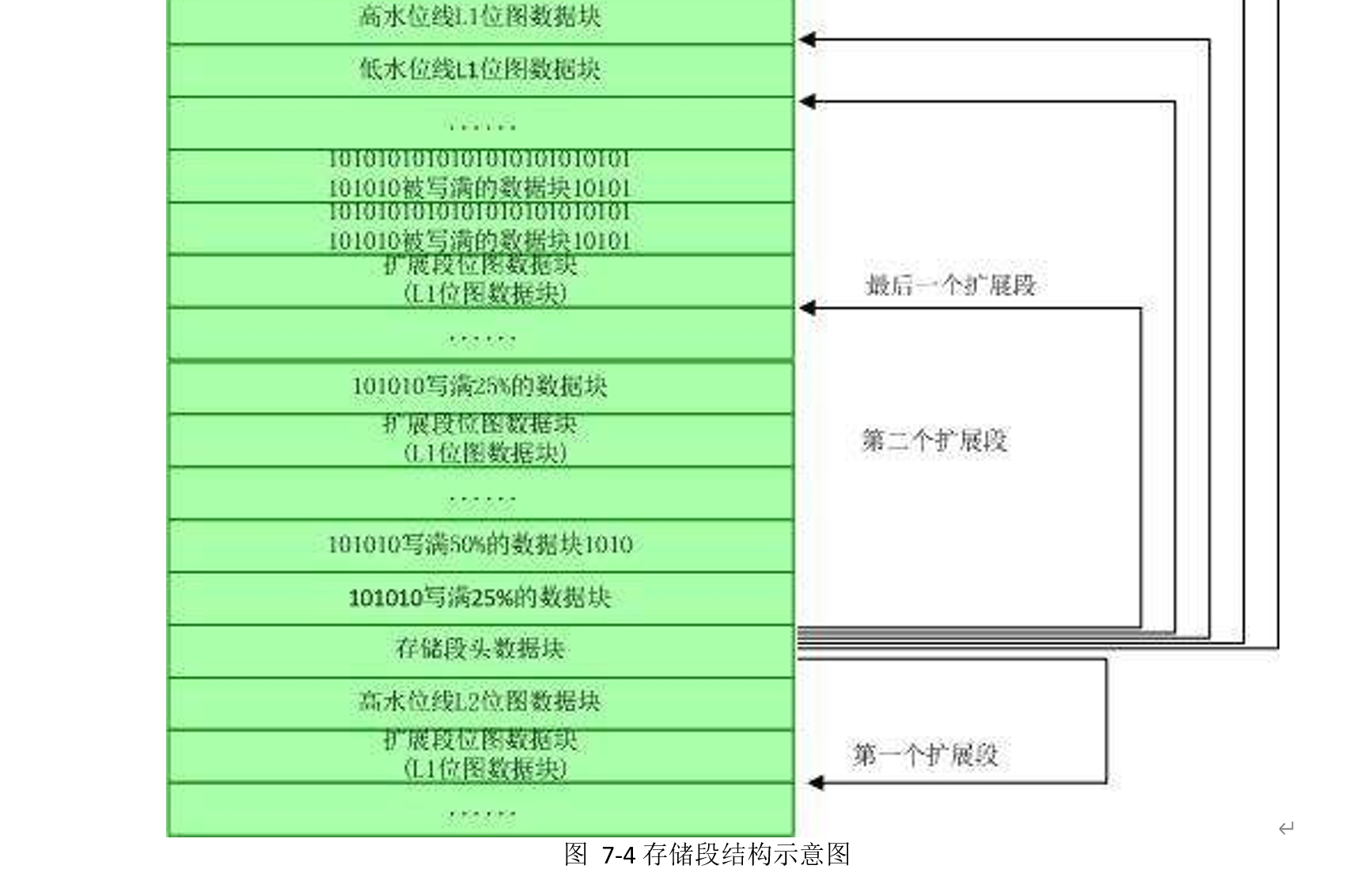
在 ASSM 管理方式下,整个数据逻辑结构可以视为一个以存储段头数据块为根节点的树状结构。每个存储段中存在三类数据块:
• 元数据块(Metadata Block),存储了存储段及扩展段的数据块使用情况及其它基本的存储信息,又可以分为:
o 存储段头数据块(Segment Header):存储了水位线信息、扩展段映射(Extent Map) 信息(包含了扩展段中第一个第一层位图数据块地址和第一个用户数据块的地址)、 指向各层最后一块位图数据块的地址以及指向第二层位图数据块的地址信息等———
—段头数据块同时还可以视为第一个第三层位图数据块;
o 第三层位图数据块:记录了指向第二层位图数据块的地址信息和其上级位图数据块地 址;
o 第二层位图数据块:记录了指向第一层位图数据块的地址信息和其上级位图数据块地 址;
o 第一层位图数据块:记录了数据块的使用情况(是否被格式化以及数据占用率)和其 上级位图数据块地址;
• 已经被格式化的数据块(Formatted Data Block);
• 未被格式化的数据块(Unformatted Data Block);
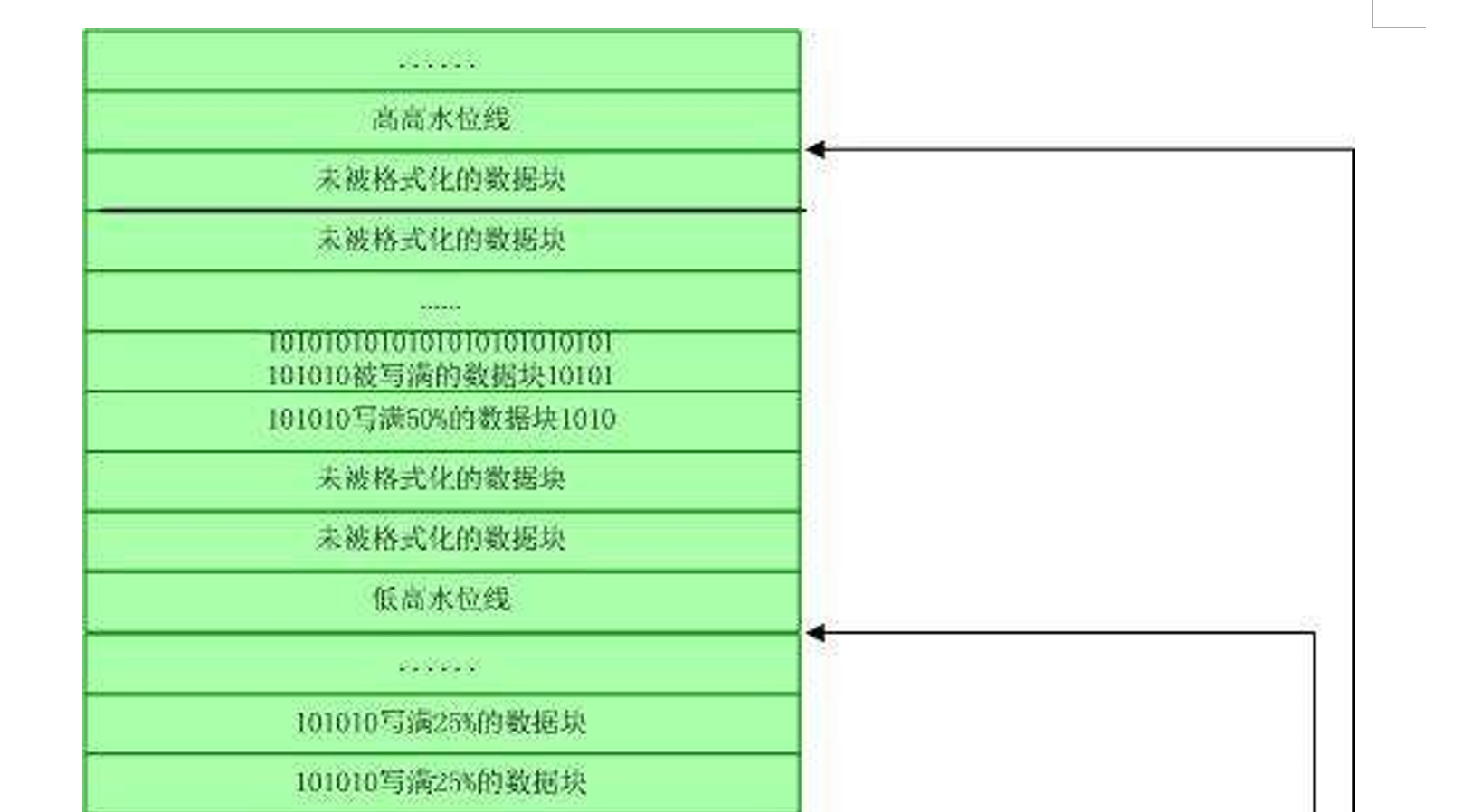
以下是一个存储段的存储示意图:
我们将段头数据块导出到文本,可以看到相关的存储信息:


从文本文件中,可以看到存储段高水位线及其以下的数据块数:
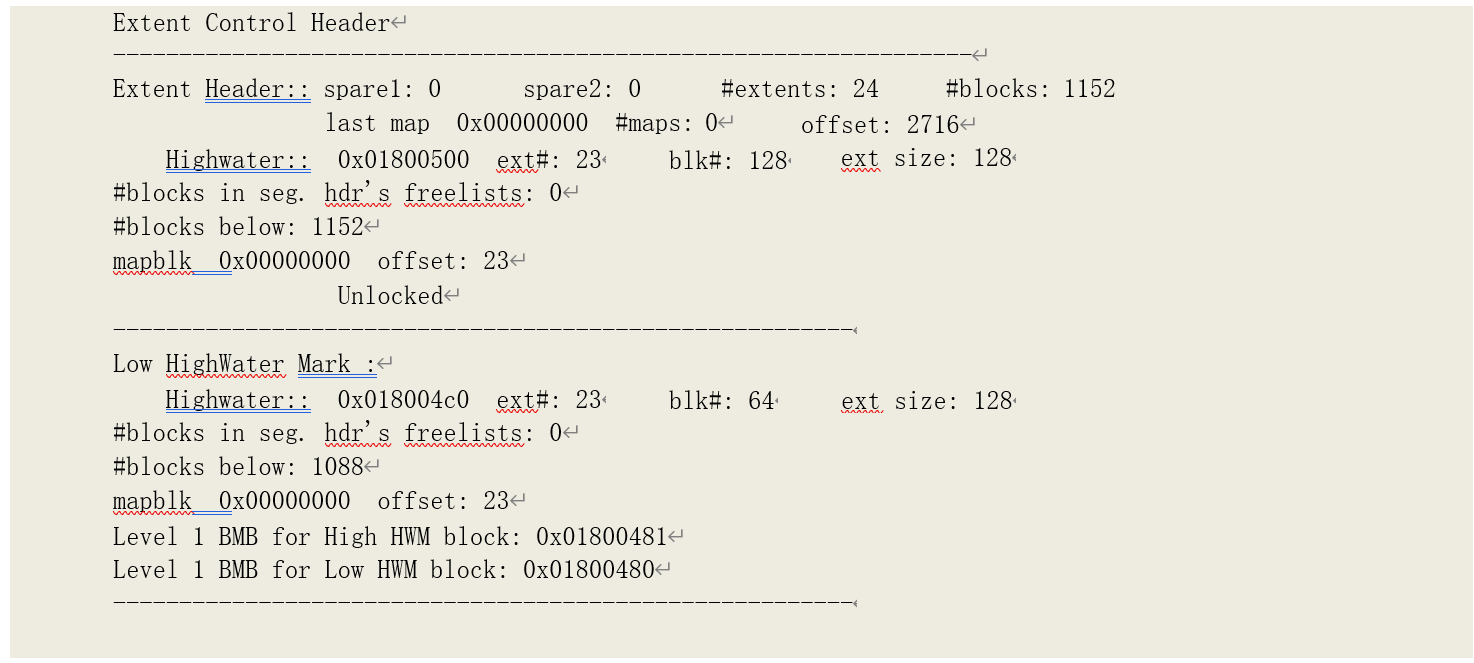
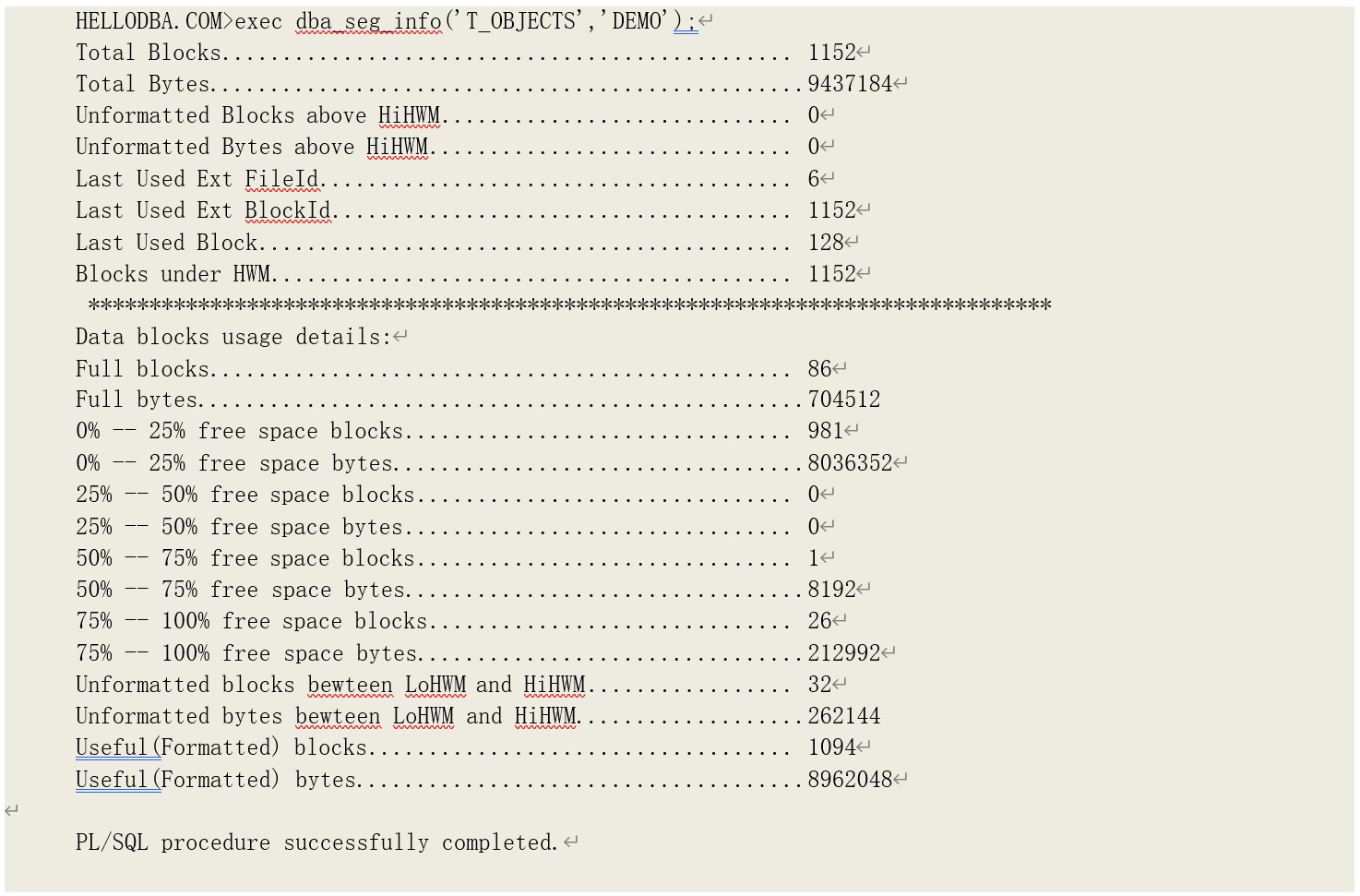
在我们的示例中,表 T_OBJECTS 的高水位线以下有 1152 块数据块。我们也可以通过系统包DBMS_SPACE 来获得相关信息。存储过程 DBA_SEG_INFO 就是我们利用该包编写的存储过程:
ASSM 管理方式下,有两条高水位线:高高水位线(High High Water Mark)和低高水位线(Low High Water Mark)。当存储段已分配的数据块中可用数据块无法容纳新插入的数据时,Oracle 需要
提高水位线。新的水位线即高高水位线,原水位线则成为低高水位线。新进入高高水位线以下的数 据块并不会立即被格式化,被格式化仅仅是用于管理数据块的位图块。数据块则是在第一次写入数 据时才格式化。因此,在低高水位线以下的数据块都是已经被格式化数据块;而低高水位线和高高 水位线之间的数据块则有已经格式化的数据块和未被格式化的数据块。
因此,要完成一次全表扫描,Oracle 需要读取和处理低高水位线以下的所有数据块、低高水位线与高高水位线之间已经被格式化的数据块。要获得处理低高水位线以下的所有数据块的位置,
Oracle 只需要到存储段头中所有低高水位线以下的扩展段中第一块数据块的位置;而要获得低高水位线与高高水位线之间已经被格式化的数据块的位置,则需要先读取用于管理低高水位线与高高水 位线之间数据块的第一层位图块,找到已经被格式化的数据块。在有些情况下,如表被移动
(Move)、数据以 Append 方式添加或者分配的扩展段比较小,低高水位线和高高水位线会处于同一位置,此时,Oracle 就会直接读取高水位线以下的所有数据块。
扫描过程分析
我们先在单一用户环境下,运行以下语句,看看 Oracle 读取了那些数据块、如何读取的:
从系统视图 vbh(包含了所有 Ping 在 SGA 所有缓存 buffer 中的数据块)可以看到之前对表
(t_objects)的读取导致了哪些数据块已经被缓存住,我们将对视图 vbh 写入了存储过程
dba_seg_buff 中。

然后执行对表(t_objects)的全表扫描:
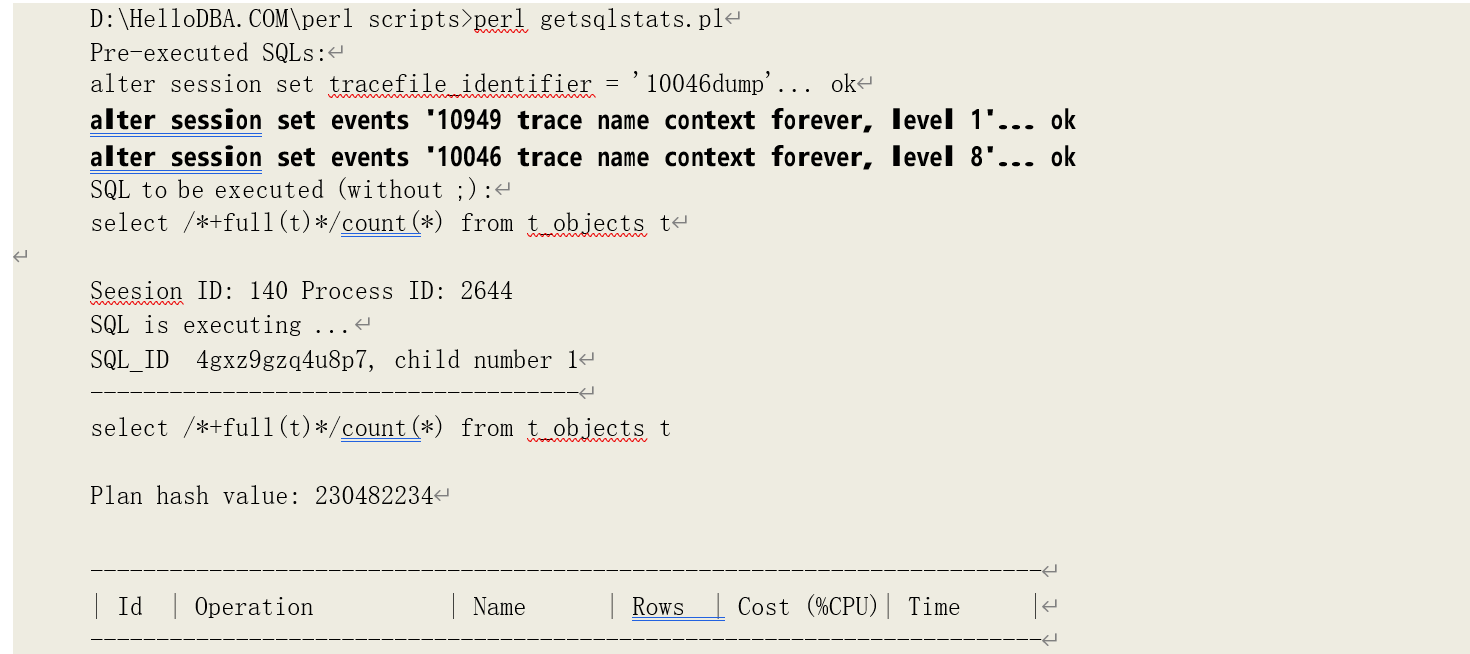
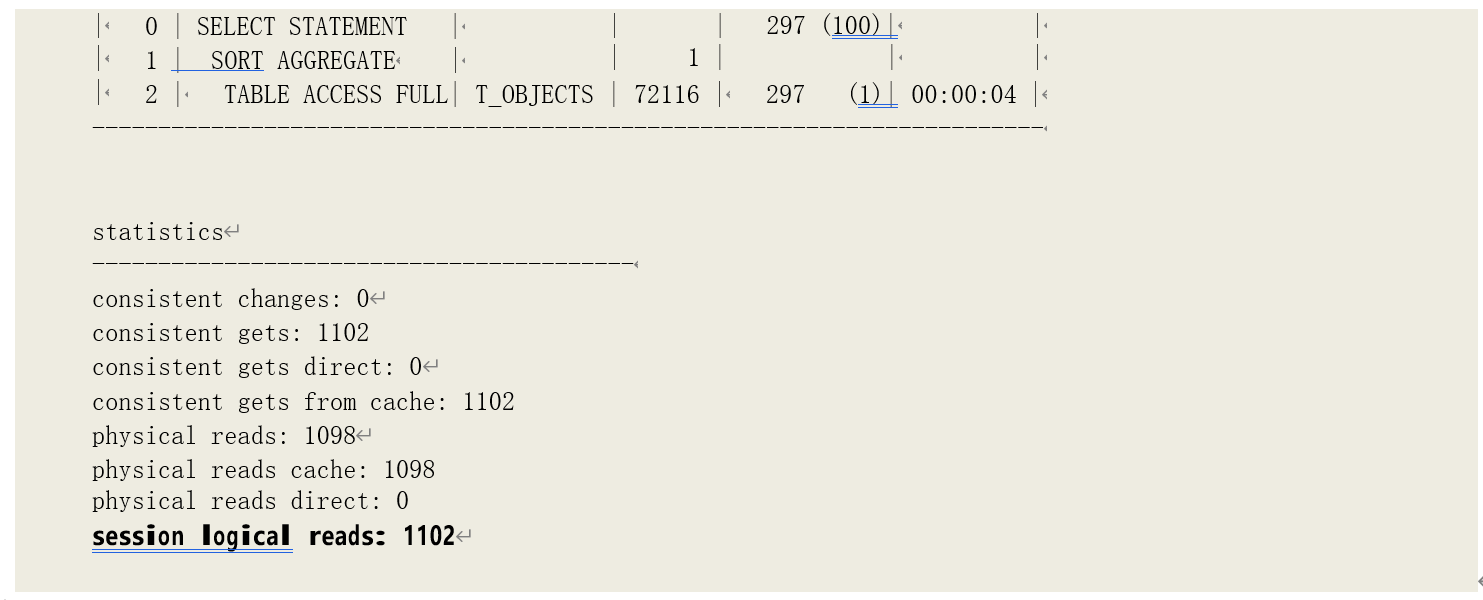
注意,我们在运行语句之前设置了事件 10949 关闭直接读自动调优特性,避免直接读取数据块。关于这一特性,我们会在物理读分析当中详细介绍。
可以看到,总共发生了 1102 次逻辑读。而通过之前我们获得存储信息可以看到,该表的存储
段中有 1094 块已经格式化的数据块。剩下的 8 次则是读取了存储段头等元数据块。为了进一步观察全表扫描时如何读取的数据块,我们可以打开系统对发生内存数据块被 pin 住的跟踪
(_trace_pin_time),Oracle 会记录并跟踪数据块 pin 的时间。该参数不能立即起效,需要修改
spfile 中的参数重启实例后起效————该参数属于非公开参数,在未得到 Oracle 的支持的情况下, 也不建议在生产环境中打开。
提示:通过 pin 次数来间接观察逻辑读次的方法有局限性。例如,进行某些操作时,如修改回滚数据块的内容(pin kcbwh5: kcbchg1),也需要 Pin 住一个缓存块,但是并不产生逻辑读;而在读取某些数据块时,如索引的支节点,可能不会进行 pin 操作,但是会产生逻辑读。

提示:通过 10200 事件可以跟踪到对用户数据块(非元数据块)的一致性读。在这里,我们为了同
时找出读取元数据块造成的逻辑读次数,使用了通过跟踪内存块 pin 的方法。
通过跟踪内容(在 11.0.2.1 中跟踪)可以清楚的看到对表 T_OBJECS 的全表扫描过程和读取的数据块(括号当中是我们增加的注释,不属于跟踪信息):

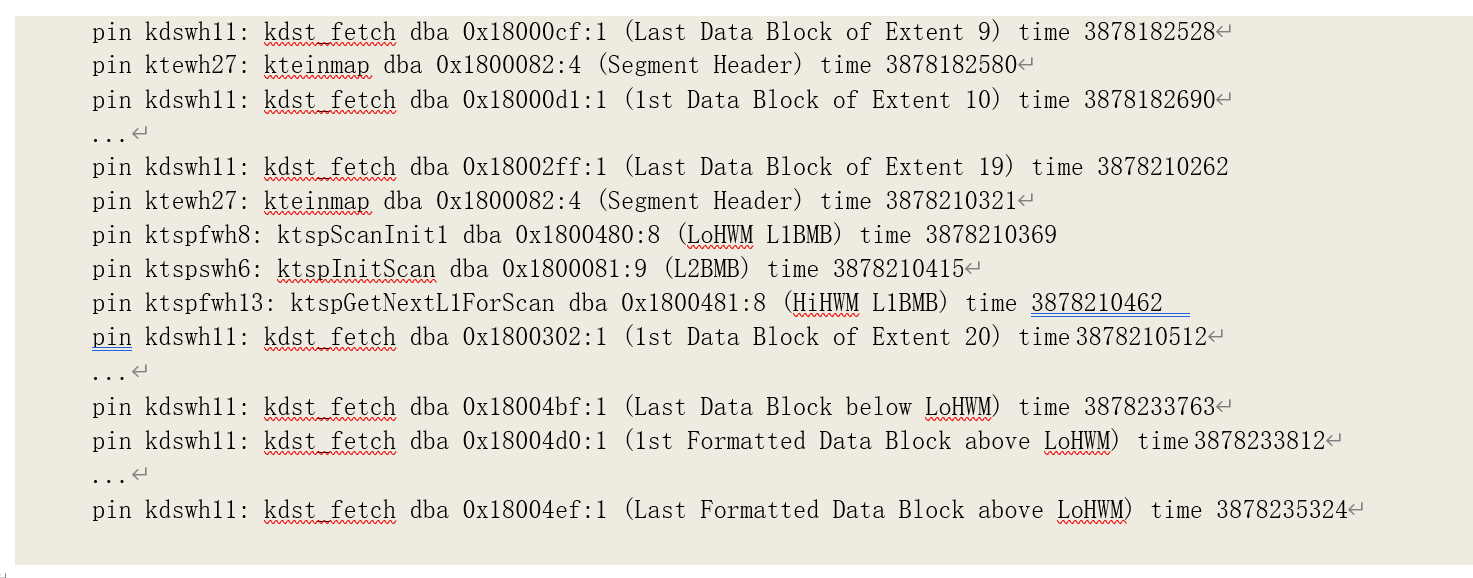
以上每条跟踪记录中记录了发生 pin 的内部函数名称、内存块映射的数据块地址(Data Block
Address,DBA)以及发生时间。其中的函数分属以下三个核心模块:
• kds - 核心数据层查找/扫描(Kernel Data layer Seek/Scan)
• ktein - 扩展段信息操作(extent information operations)
• ktsp - 空间使用管理(space usage management)
各个函数的作用如下:
• kteinicnt:扩展段数量统计;
• kteinpscan:读取扩展段映射表信息,为全表扫描做准备;
• kteinmap:获取部分扩展段映射表;
• ktspScanInit1:读取低高水位线的第一层位图块;
• ktspInitScan:读取第二层位图块(高水位线第一层位图块的上一层位图块);
• ktspGetNextL1ForScan:获取下一个第一层位图块(即高高水位线的第一层位图块);
• kdst_fetch:全表扫描读取数据;
记录中,dba 后面的 16 进制数字就是函数 pin 住内存块所映射的物理地址。通过导出其内容不难发现它们是存储段中哪个数据块。我们建立以下外表面,再将跟踪记录导入,可以更加容易分析各个数据块被读取的次数:
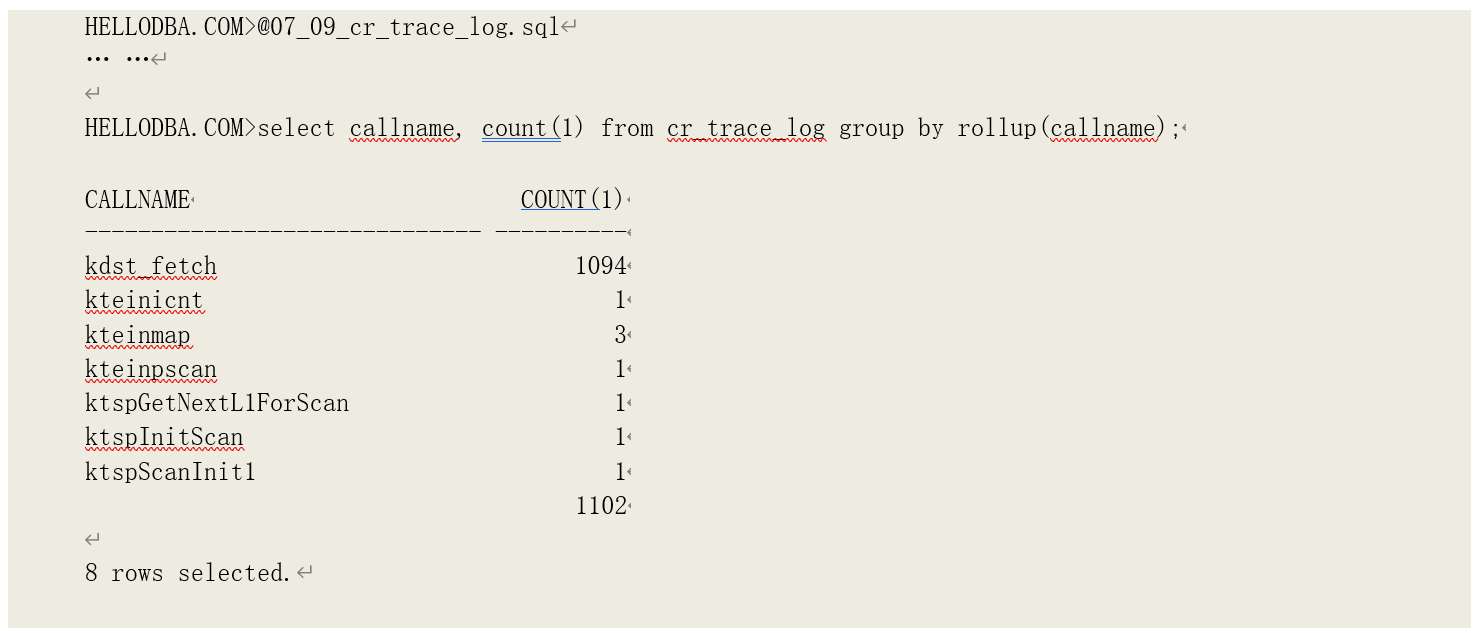
可以看到,总数与一致性读次数相符。
• 其中 kdst_fetch 调用了 1094 次,也正是存储段中已经被格式化的数据块数量;
• kteinicnt、kteinpscan 分别被调用了 1 次,获取用于全表扫描的存储段基本信息;
• kteinmap 被调用了 3 次,即每次读取 10 个扩展段映射信息;
• ktspScanInit1、ktspScanInit1、ktspGetNextL1ForScan 在读取最后一轮扩展段映射表(含有高水位线所在扩展段)时分别被调用了 1 次,用于获取高、低高水位线的第一层位图块,确认高、低高水位线之间哪些数据块已经被格式化;如果高、低高水位线的位置一致(由 kteinpscan 获知),则不会发生对这 3 个函数的调用。
由此可见,对于含有 n 块已格式化数据块的存储段,其时间复杂度为 O(n)。
但是,逻辑读所反映的是读取的数据块数,如果数据都是由缓存获取的话(未发生物理读,此时性能的影响主要来自于 CPU 的处理时间————这一点我们也可以从优化器在考虑缓存命中率时的 IO 代价计算公式看出),它可以独立的作为一个性能衡量指标。但是,而全表扫描是一个多数据块读的操作,在发生物理读时,是一次读取多个数据块。此时,逻辑读不能单独被作为衡量语 句性能的指标,我们还需要考虑物理读取的数据块数已经发出的物理读请求的次数————通过
10046 事件级别为 8 的跟踪,可以获取这些信息。以下就是我们对这次语句执行的 10046 事件跟踪内容(括号中是我们添加的注释,即该数据块所处位置和类型):
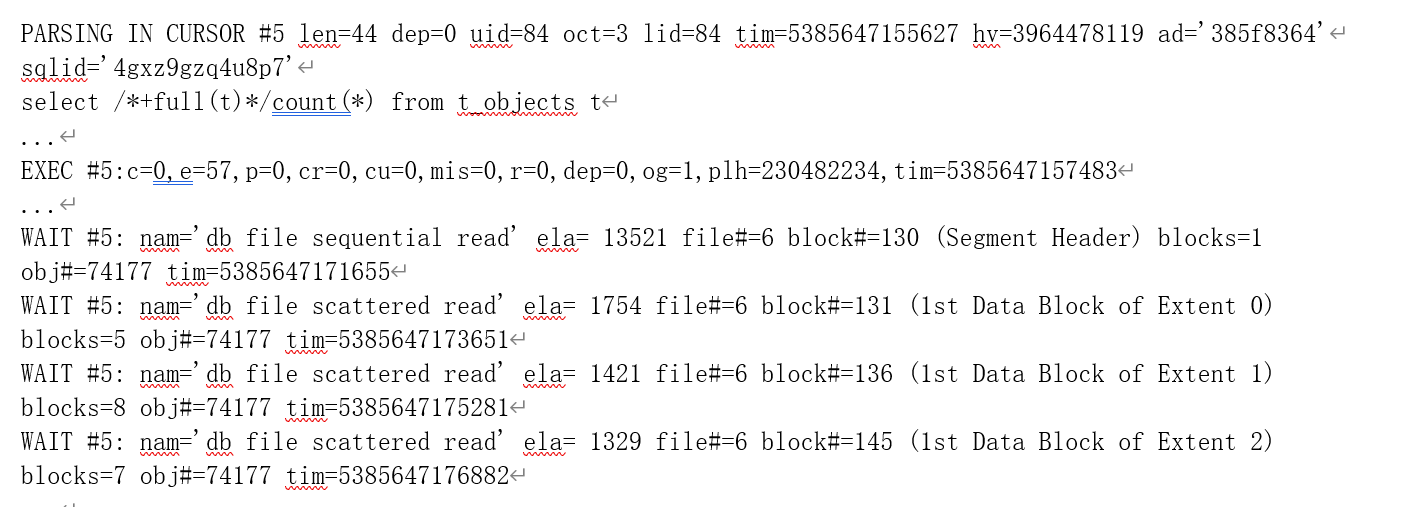
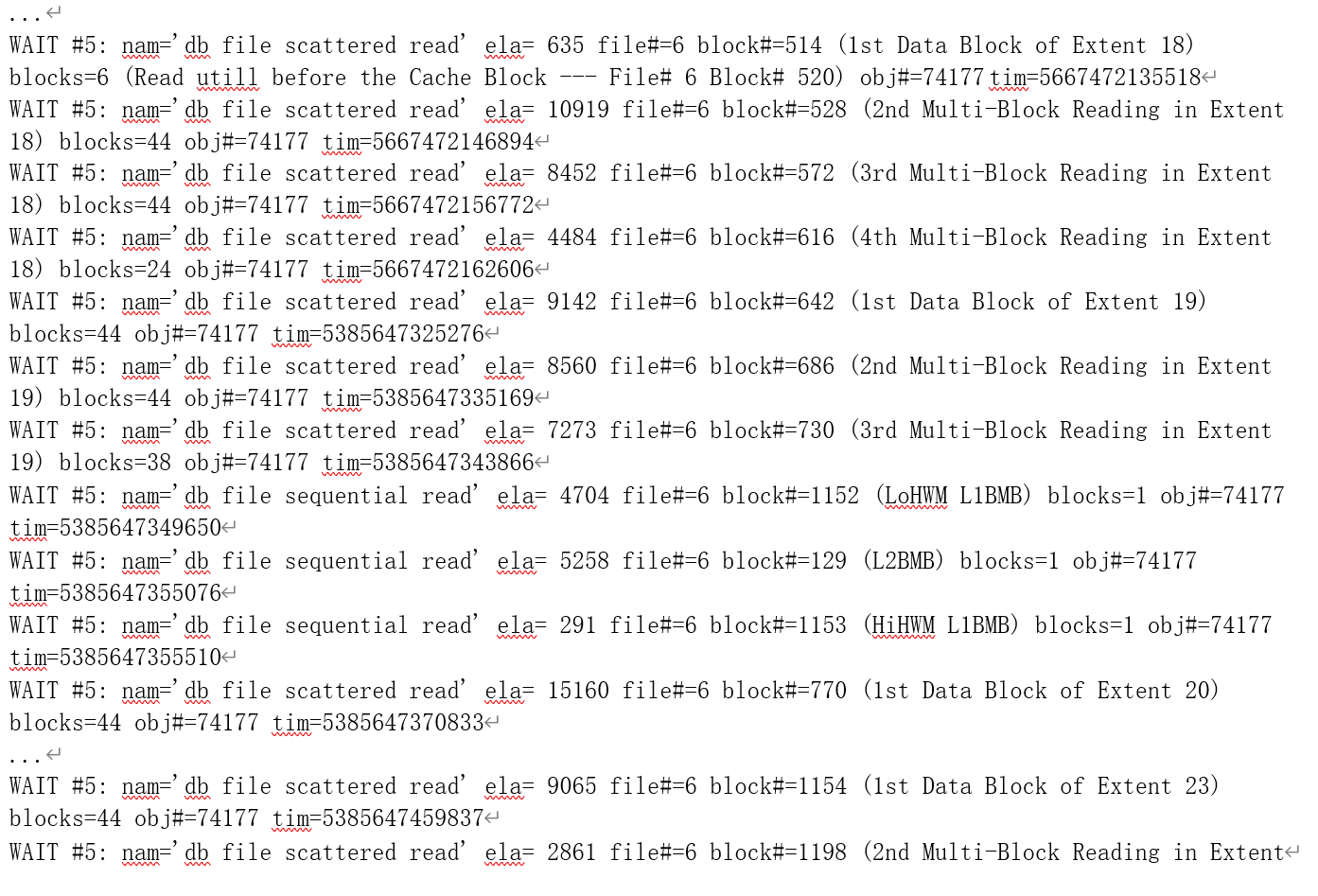

通过物理读相关等待事件(db file sequential read:数据文件序列读取,发生在从磁盘读取单个数据块到缓存当中时;db file scattered read:数据文件散列读取,发生在从磁盘读取多个数据块到缓存当中时)的文件编号参数(file#)、数据块编号参数(block#),我们不难与 pin 跟踪的数据块地址对应起来(已经读入缓存的数据块,如存储段头,再次读取时,则不会发生物理读了);
而通过对等待事件的数据块数参数(blocks)的累加,可以得出物理读取的数据块数为 1098
(同时 10046 中也记录了 p=1098,1094 块用户数据块和 4 块元数据块:0x1800081、0x1800082、
0x1800480、0x1800481),和运行统计数据中一致。对于多数据块读,一次读入缓存中的数量限制 受到三个因素的约束:
• 读取数据块所在扩展段的大小;
• 多数据块读参数(db_file_multiblock_read_count,这一参数受到操作系统平台所支持的最 大 IO 带宽以及数据块大小的限制);
• 缓存中的数据块————上述两个条件都不满足时,按照物理位置连续读取到被缓存的数据块之前;

在我们的这个例子当中,我们可以了解到:
- 从存储段头得知,前面 16 个扩展段的大小都是 8 个数据块。因此,对他们的多数块读的数据块数为(8-元数据块数);
- 后面 8 个扩展段的大小为 128 个数据块。因此,对第 16~17、19~22 个扩展段,每个扩展段请求读取了 3 次:
• 第一次读取跳过了元数据块,一次读取了 44 个数据块————即多数据块读参数的限制;
• 第二次也是读取了 44 个数据块;
• 第三次则读取到扩展段的尾部,读取了 38 块(128-44*2-2); - 第 18 个扩展段则请求读取了 4 次:
• 第一次读取跳过了元数据块,一次读取了 6 个数据块————至已经被缓存的数据块(第 6 个文件第 520 块)之前;
• 第二、三次都是读取了 44 个数据块;
• 第四次则读取到扩展段的尾部,读取了 24 块(128-6-8-44*2-2);
4. 最后一个扩展段也是请求读取了 3 次:
• 第一次读取跳过了元数据块,一次读取了 44 个数据块;
• 第二次读取了 18 个数据块,即低高水位线第一层位图块所映射的数据块范围(64- 44-2);
• 通过导出高高水位线第一层位图块,我们可以看到第三次读取是从第一块已经被格 式化的数据块开始,读到了最后一块被格式化的数据块。
客户端数组大小
前面的示例是在没有任何可能造成而外逻辑读的影响因素下执行的。我们现在引入影响因素之
————客户端数组大小(ARRAY SIZE)。数组大小在许多客户端接口中都可以设置,例如 JDBC、
OCI 等,而通过这些接口编写的客户端程序通常也可以对该参数进行设置,例如 SQLPlus、Perl 的Oracle DBI 接口。当该参数值小于一个数据块中实际含有的数据记录数时,就会导致 Oracle 会多次读取同一个数据块。例如,在 SQLPlus,ARRAYSIZE 的默认大小为 15————该数值通常小于数据块中实际含有的数据记录数。该参数设置的是服务进程每次读取、返回多少条数据记录给客户端, 我们在做 COUNT(*)时,语句获取的是数据记录统计结果,因此不会受到该参数的影响。当我们的语句是用于获取数据记录时,就可以看到该参数的影响(我们这里的数组大小是 32):
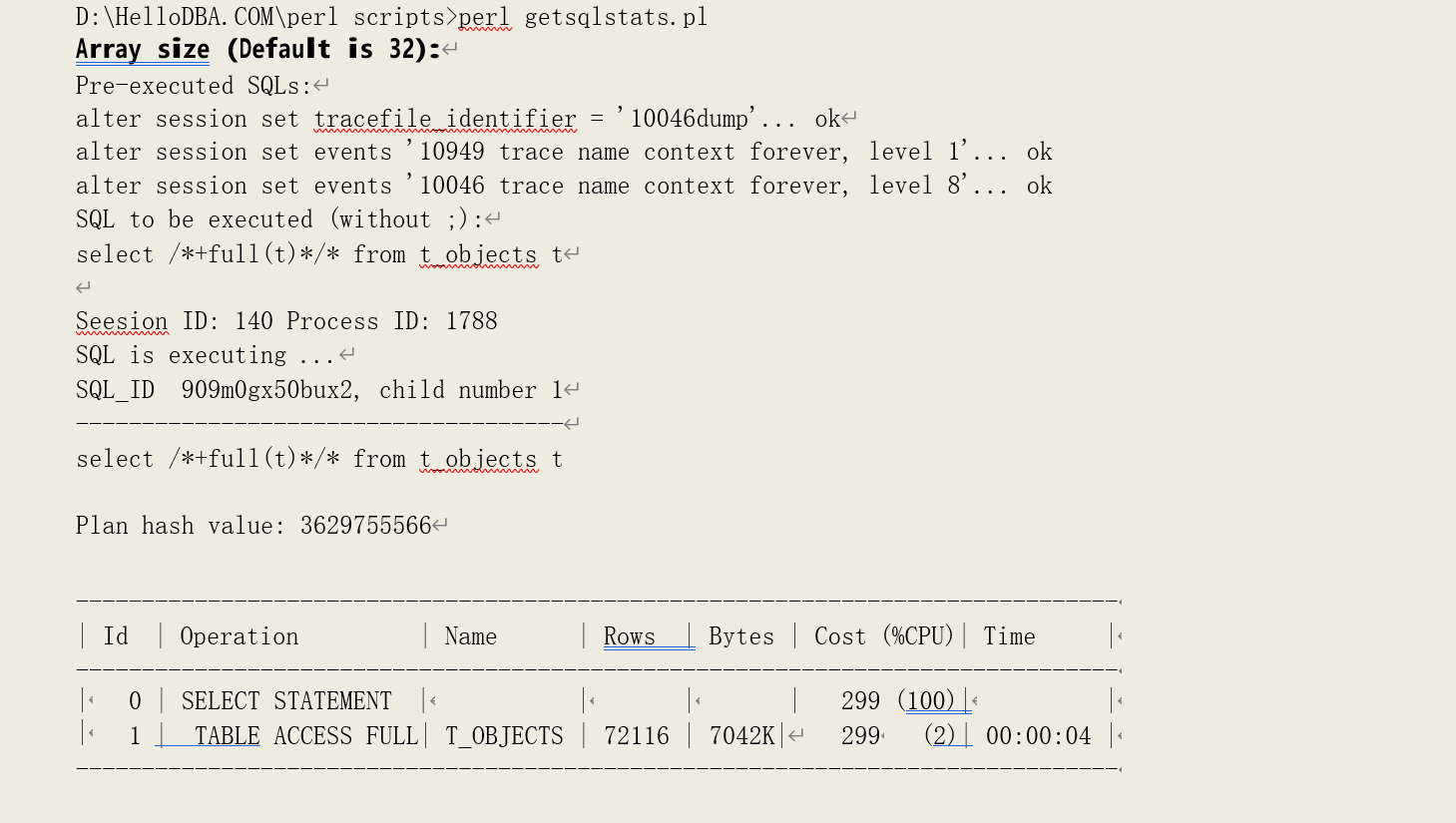
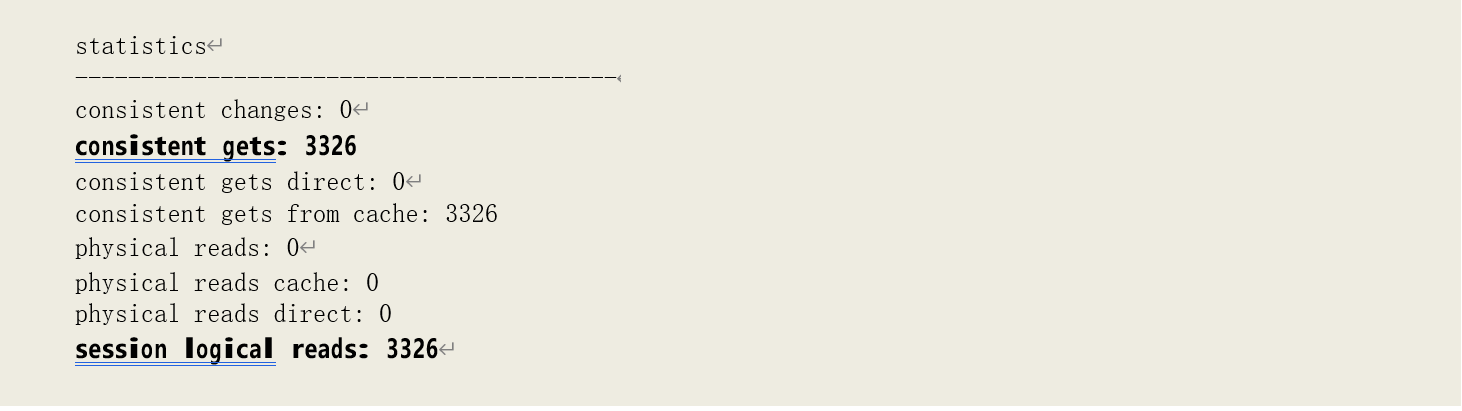
此时,逻辑读明显增大。Oracle 在扫描、处理数据时,一旦累积的符合条件的记录数达到数值大小时,便会将记录返回给客户端、指针向后移一位,然后再重新读取指针所指向的数据块,数据
块上的满足条件的记录数大于数组大小时,就会造成 Oracle 多次读取该数据块————这就是客户端数组设置所造成的额外逻辑读的原因。因此,我们也可以这样来大致估算出其造成的额外逻辑读的次数:(满足条件的记录数)/(数组大小)。在我们的例子中,该数字为:72116/32 = 2253, 再加上原有的逻辑读数,估算出总的逻辑读为 2253 + 1102 = 3355。这个数字与实际值很接近,但更大,原因就是在数组满时正好读到了数据块的最后一条记录————此时的逻辑读与数组无关。
而从 10046 的跟踪记录可以看到,每获取(Fetch)了 32 条记录(r=32)后,服务端就与客户端产生了一次交互:
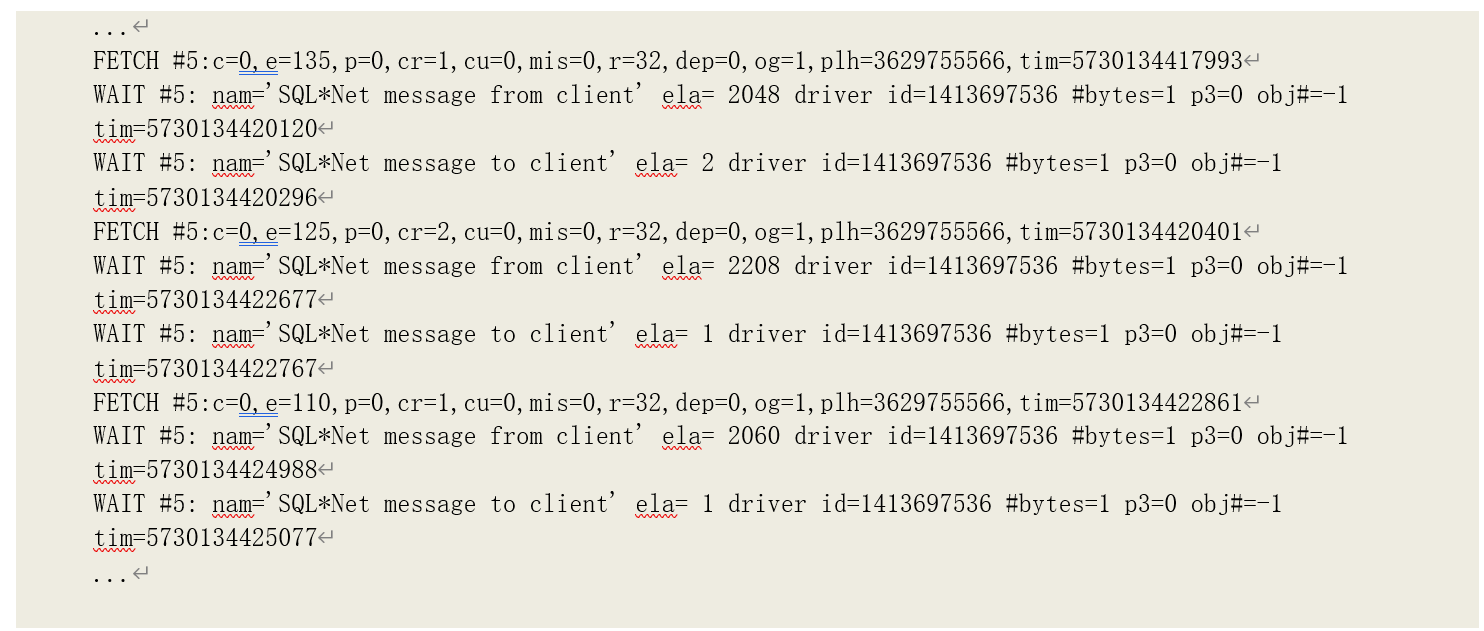
我们用以下过程准确计算出客户端数组设置造成的额外逻辑读:
计算结果为 2224,再加上扫描数据块的逻辑读 1102:2224+1102 = 3326,结果就和实际相吻合。
块清除
当事务修改数据块上的数据时,需要修改数据块头(如 ITL—————关注的事务条目, Interested Transaction List)和数据记录中的锁标识位,使被修改的数据记录通过这些标识位与当前事务以及相应的回滚信息关联起来。当事务提交或者其他事务访问这些数据块时,这些标识位需要被清除掉,这一行为称为块清除(Block CleanOut)。根据与完成清除工作的事务直接的关系已经事务执行清除工作的时机不同,清除操作可以分为:
提交块清除(Commit CleanOut)
更新事务本身完成,快速清除的数据块中相应事务链条目(ITL)中的标识(相应操作不会产生 额外的 Redo 记录————"_log_committime_block_cleanout"为设置时),但其它标识不会被清除。
• 被修改过的数据块可能在事务提交之前就被 DBWn 进程写入磁盘当中。事务提交时,不会对这些数据块执行提交清除工作;
• 对于还在 Buffer Cache 中的脏数据块,事务会选择小于 Buffer Cache 的 10%的数据块执行提交块清除;
延迟块清除(Delayed Block CleanOut)
由后续的其他(读写)事务在读取到数据块时来清除之前事务没有清除干净的所有标识。延迟 块清除会导致产生额外的 Redo 记录。根据其与事务本身的关系又分为即时块清除(Immediate Block CleanOut)和延期块清除(Deferred Block CleanOut):
• 即时块清除:本身作为一致性读或者当前读过程的一部分,根据读的模式不同,分为一致
性读即时块清除(immediate (CR) block cleanout)和当前模式读即时块清除(immediate (CURRENT) block cleanout);
o 一致性读即时块清除:一致性读在读取数据块内容时立即清除之前事务未清除干净的
标识;
o 当前模式读即时块清除:事务在读在当前数据块内容时立即清除之前事务未清除干净的标识————通常发生在当前模式读入被修改过的索引数据块时;
• 延期块清除:当前读过程额外做的工作,仅在当期模式读中出现(deferred (CURRENT)
block cleanout);
o 当期模式读延期块清除:事务在读在当前数据块内容时不会立即清除之前事务未清除 干净的标识,而是在读取完成后再清除;
在执行清除工作,以下根据清除类型不同,以下 1 个或多个标识会被清除:
- 更新清除 SCN(CleanOut SCN,CSC)————所有清除都会执行该操作;
- 修改 ITL————如果有多个事务标识需要被清除,则会清除相应的多个 ITL,可能包括以下标识位的改变:
o flag:–U- => C—,其中 U 表示事务已经提交但未做清除;C 表示事务已提交且完成了清除工作;
o lck:N => 0,其中 N 为事务锁住的记录数;
o Scn/Fsc: Fsc => Scn,且 fsc 的空闲空间数(Scn/Fsc 的前两个字节)被清 0。其中 FSC
(Free Space Credit)为清除完成后可以释放的空间大小;Scn 为提交 SCN(Commit
SCN)。例如,fsc 0x0020.ef7b7f0d => scn 0x0000.ef7b7f0d - 修改空间信息
o avsp(数据块可用空间,Available Space):如果之前事务的 Fsc 数大于 0,则将这些空闲空间累加到数据块的可用空间中,例如 avsp=0x1713 => avsp=0x1733 - 清除记录事务标识
o 表数据块的记录:lb: 0xI => 0x0
o 索引数据块的记录:lock: I => 0
I 为对应事务的 ITL 编号。
当发生一致性读即时块清除(immediate (CR) block cleanout)时,就会导致一致性读的增加。以下两种情形都会导致产生一致性读即时块清除操作:
• 一致性读所读取的数据块上存在活动事务(即未提交或回滚的事务)修改的数据。此时,
Oracle 需要先做延迟块清除、再回滚被修改的内容。在运行性能统计数据中由"cleanouts and rollbacks - consistent read gets"统计此类清除所造成的额外一致性读;
• 一致性读所读取的数据块存在未被之前事务清除(包括提交清除)的标识位。此时仅做清 除工作,在运行性能统计数据中由"cleanouts only - consistent read gets"统计此类清除所造成的额外一致性读;
由于第一种情形中的额外逻辑读不仅有延迟块清除所造成的,还有一致性回滚所造成的,我们 在下一节在分析这种情况。本节中,我们看下第二种情形的影响:
我们先看下会有多少个数据块在本例中需要做延迟块清除:


然后在一个会话中修改这些记录,并且在提交之前使它们被清出缓存、避免提交清除:

再执行一条全表扫描语句读取数据块:


可以看到,该查询语句执行过程中发生了延迟块清除。不仅逻辑读的数量增加(统计在 db block changes 中,3326+5=3331),而且导致了当前数据块内容的修改(db block changes: 5),同时还产生了 Redo 记录(redo size: 404)。
我们对会话设置了 10203(数据块清除跟踪事件)跟踪事件,可以从跟踪文件中找到这些块清除的记录:

•我们分别看下这两种情况造成的一致性回滚。
提示:10201 事件可以跟踪一致性回滚的记录。
o 存在未被提交/回滚的数据
要造成这样的情形,我们现在一个会话中修改表的数据,并保持事务不提交/回滚:

然后我们再执行全表扫描读取表的数据,并打开 10201 事件跟踪一致性回滚:
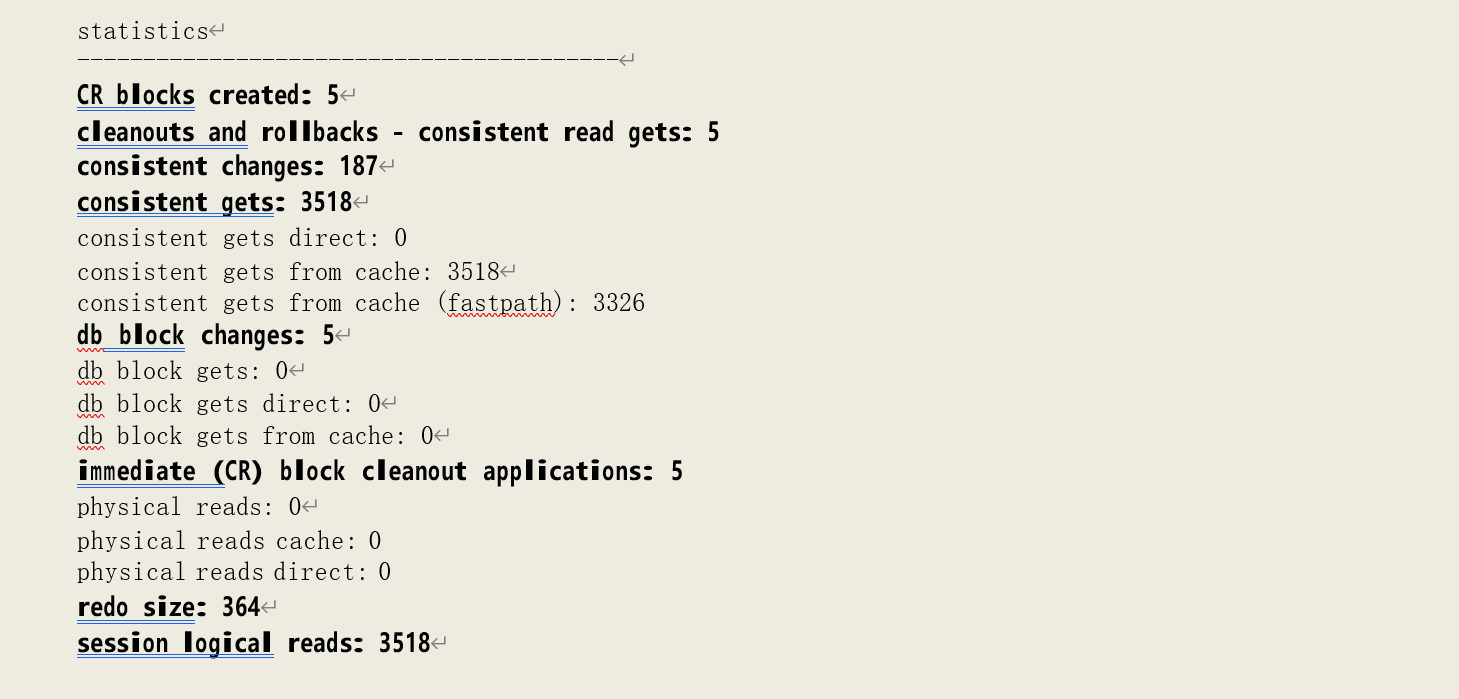
可以看到此时的逻辑读增加了 192 次,其中有 187 次一致性修改(consistent changes)和 5 次块清除(immediate (CR) block cleanout applications)。
我们通过 10201 的跟踪记录可以发现 187 次一致性修改的记录:
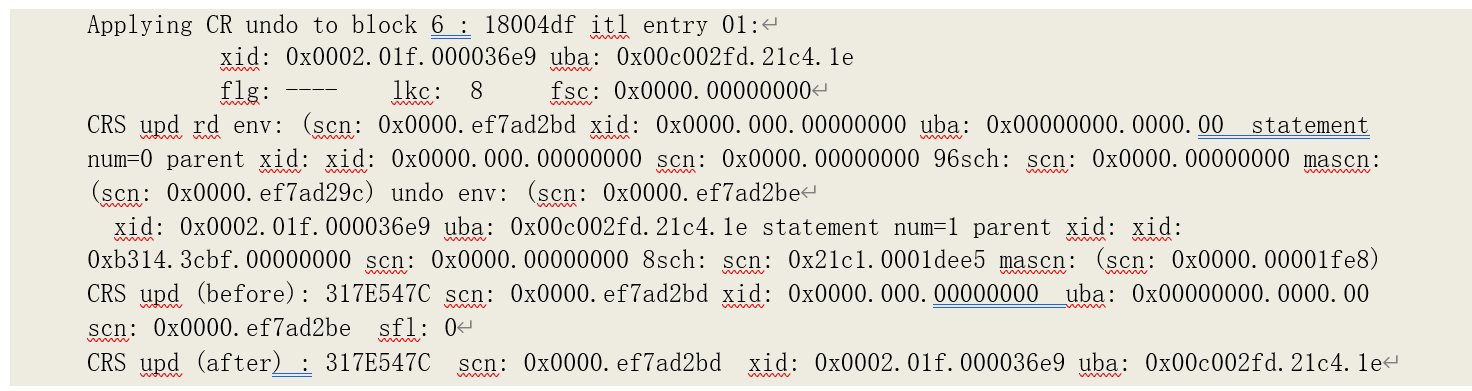
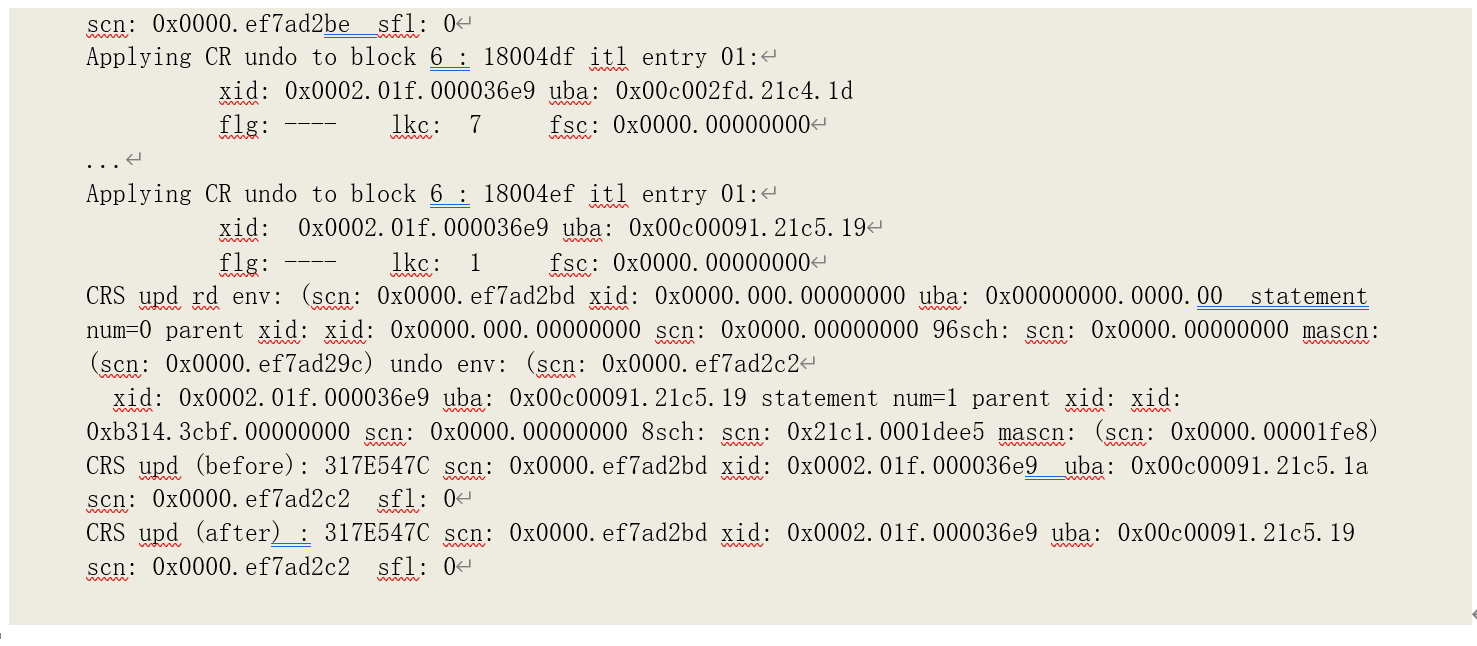
跟踪记录中总共有 187 次一致性回滚(Applying CR undo …),造成了统计数据中的 187 次一致性修改。
再由跟踪记录的块清除记录可以统计出 5 次块清除造成的逻辑读:

提示:进行一致性回滚时,Oracle 会从“当前”块拷贝一块新的内存块作为"CR"块,再对"CR"块进
行回滚操作,因此,统计数据中可以看到“CR blocks created: 5”。
o 数据块修改的提交时间在读取数据块的事务的开始之后
要造成该情形,我们先启动查询语句并暂停:
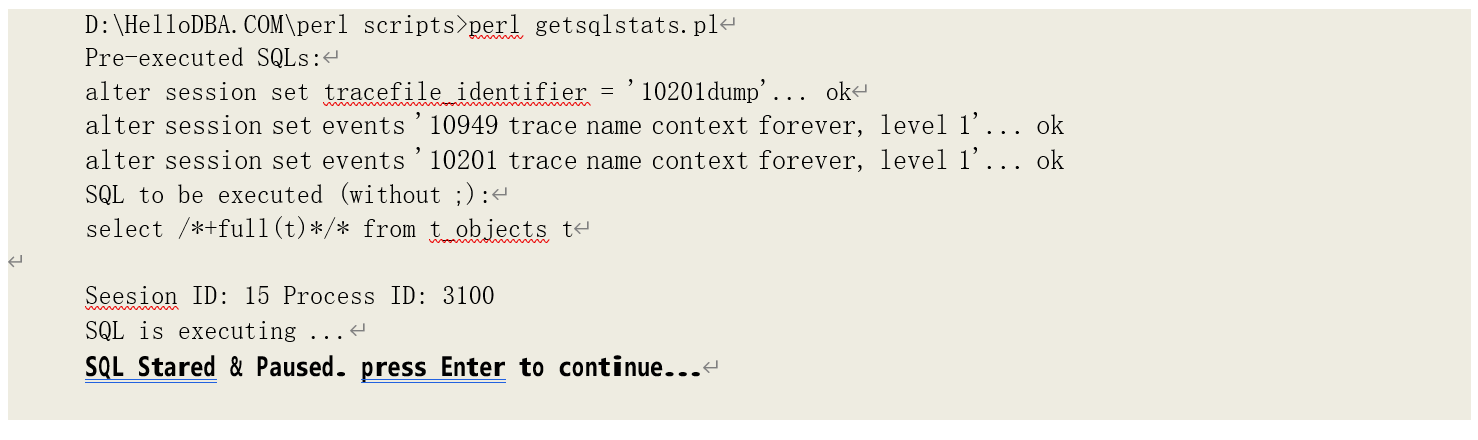
然后在其他会话中执行数据修改并提交:


再继续查询语句的处理:
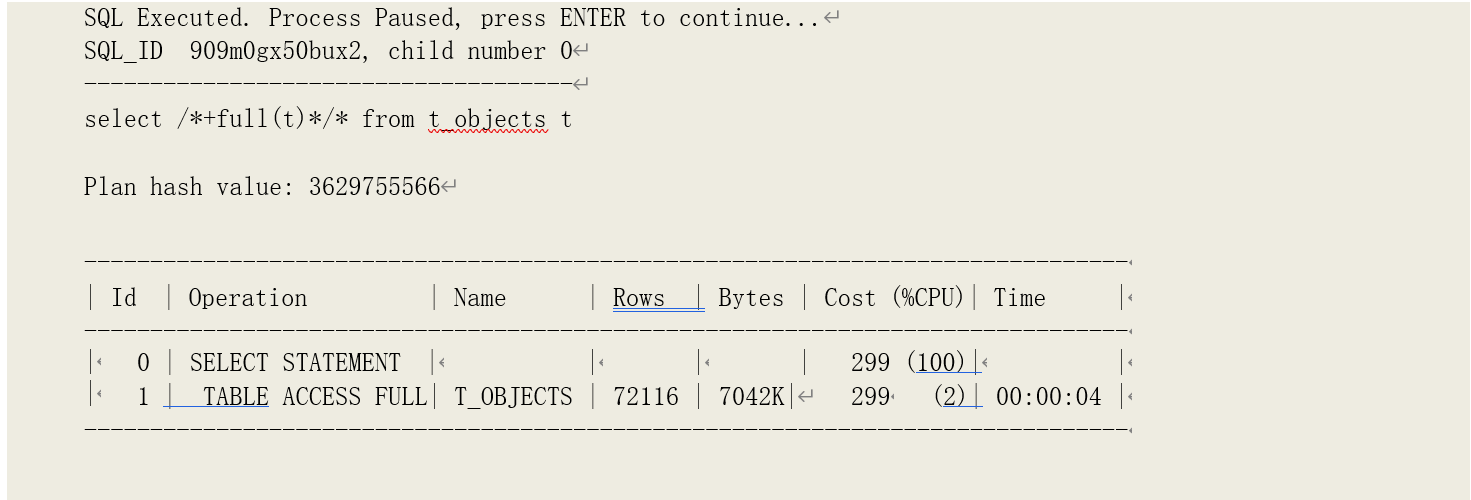
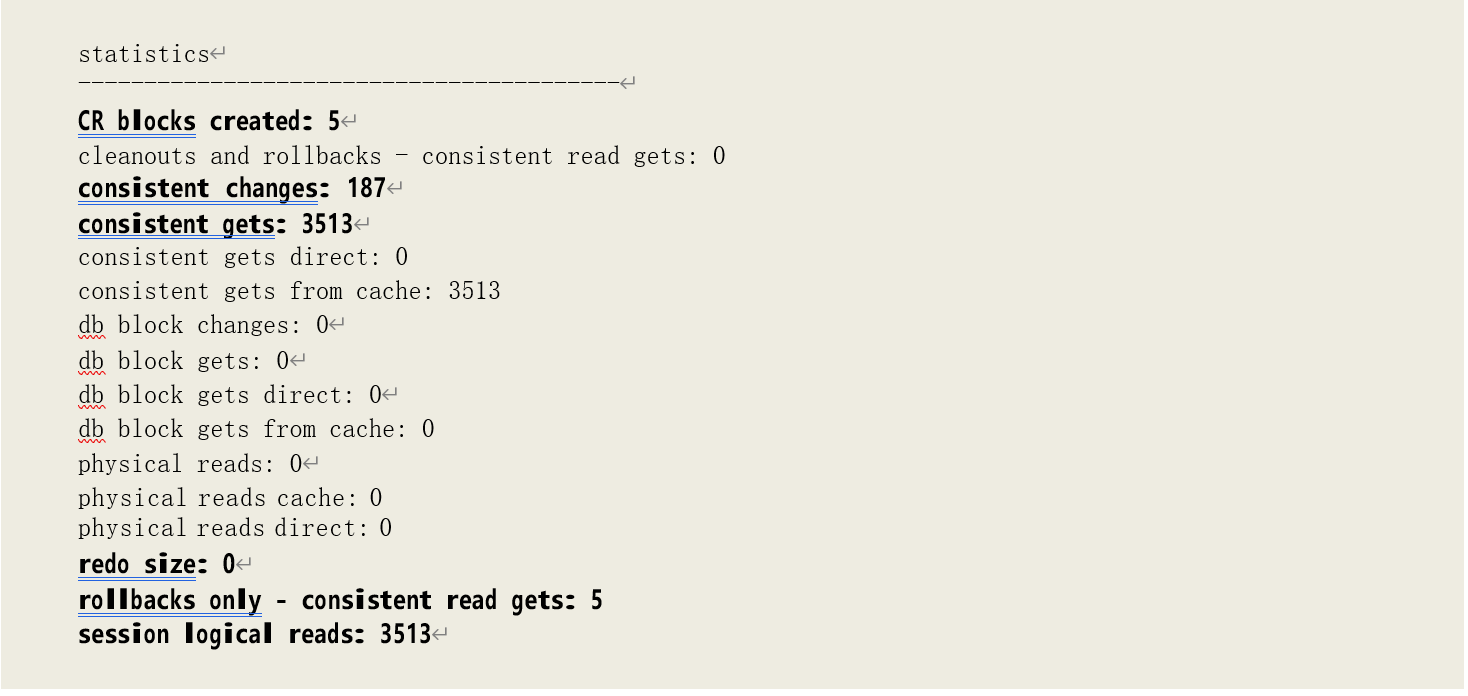
可以看到,这种情况下,增加的逻辑读次数等于一致性修改的次数:3326+187=3513。
提示:由于之前事务仅修改了 5 个数据块,远小于 10%的缓存块数,因此,在事务提交时完成了提交清除,一致性读事务也无需再做延迟块清除,仅作回滚操作。相应的,统计数据中可以看到“rollbacks only - consistent read gets: 5”。
