




逻辑读所代表的是语句需要访问的数据块次数。而所读取的数据块,可能来自于已经缓存在Buffer Cache 中的内存块,也可能来自于物理磁盘。当在缓存中找不到所要读取的数据块时,则需要发出系统发出磁盘读请求、从物理磁盘读取数据块。而根据物理读取的数据块是否进入缓存,又 可以分为物理读人缓存(physical reads cache)和物理直接读(physical reads direct)。当发生物理读人缓存的操作时,需要从共享缓存中找到一个可用的内存块,然后将物理数据块中的内容写入内 存块。下次再次读取该数据块时,则很可能直接命中缓存,而无需再从磁盘读取。当发生物理直接 读时,Oracle 不会检查缓存中是否存在该数据块,而是直接总物理磁盘中读取,并且读取到数据块内容也不会被写入缓存,而是直接交给用户服务进程处理。
从上述描述中,我们可以知道两点信息:
除了一些特殊情况外,如对象被初次读取,语句物理读人缓存次数通常是无法预测的,因为 它和每次运行时对象的缓存命中率相关;
对于缓存命中率很低的语句或操作,例如对大表的全表扫描,发生物理读的几率较高,因而 直接读比读入缓存的效率高————因为直接读没有查找、拷贝和读取缓存的过程。
我们下面分别分析造成物理直接读(physical reads direct)和物理读人缓存(physical reads
cache)的情况。
物理直接读
发生物理直接读时,通常是满足了特定条件。在 10g 中,发生物理直接读的情形主要有以下一些情况。
读取大对象存储段数据
我们创建表时,如果存在大二进制类型(Large Of Binary,包括 CLOB、NCLOB 和 BLOB)字段时, 可以指定是否其存储在与其表所在存储段(ENABLE STORAGE IN ROW)或者另外一个存储段上
(DISABLE STORAGE IN ROW)。即使指定了 ENABLE STORAGE IN ROW,当写人的 LOG 数据大小超过一定限制时(例如,在 10g 中,数据块大小为 8192 字节时,LOB 字段最大运行存储在表数据块的大小为 3964 字节),Oracle 也会将其写入另外的存储段中。Oracle 读取 LOB 存储段中数据是以直接读取的方式读取的。
我们以两种存在 LOB 字段的表为例:

当查询 T_SQLPLANS 时,可以从统计数据块看直接读取了 LOB 存储段的数据块:
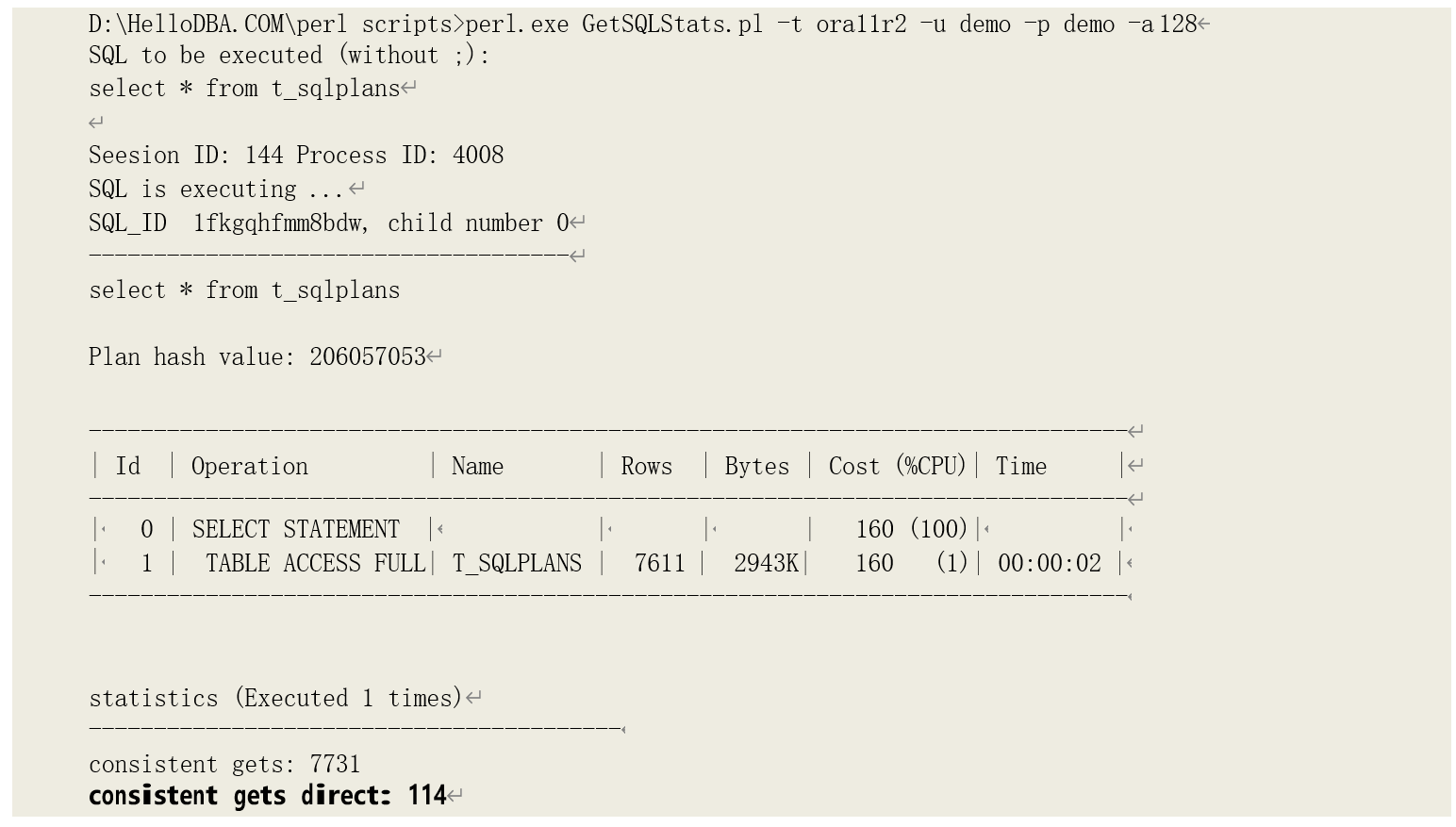

对 LOB 存储段的读取和对表存储进行全表扫描时的读取方式类似:读取高水位线以下的已经被格式化的数据块。我们同样可以通过 DBMS_SPACE 包查看其数据块分配和使用情况:
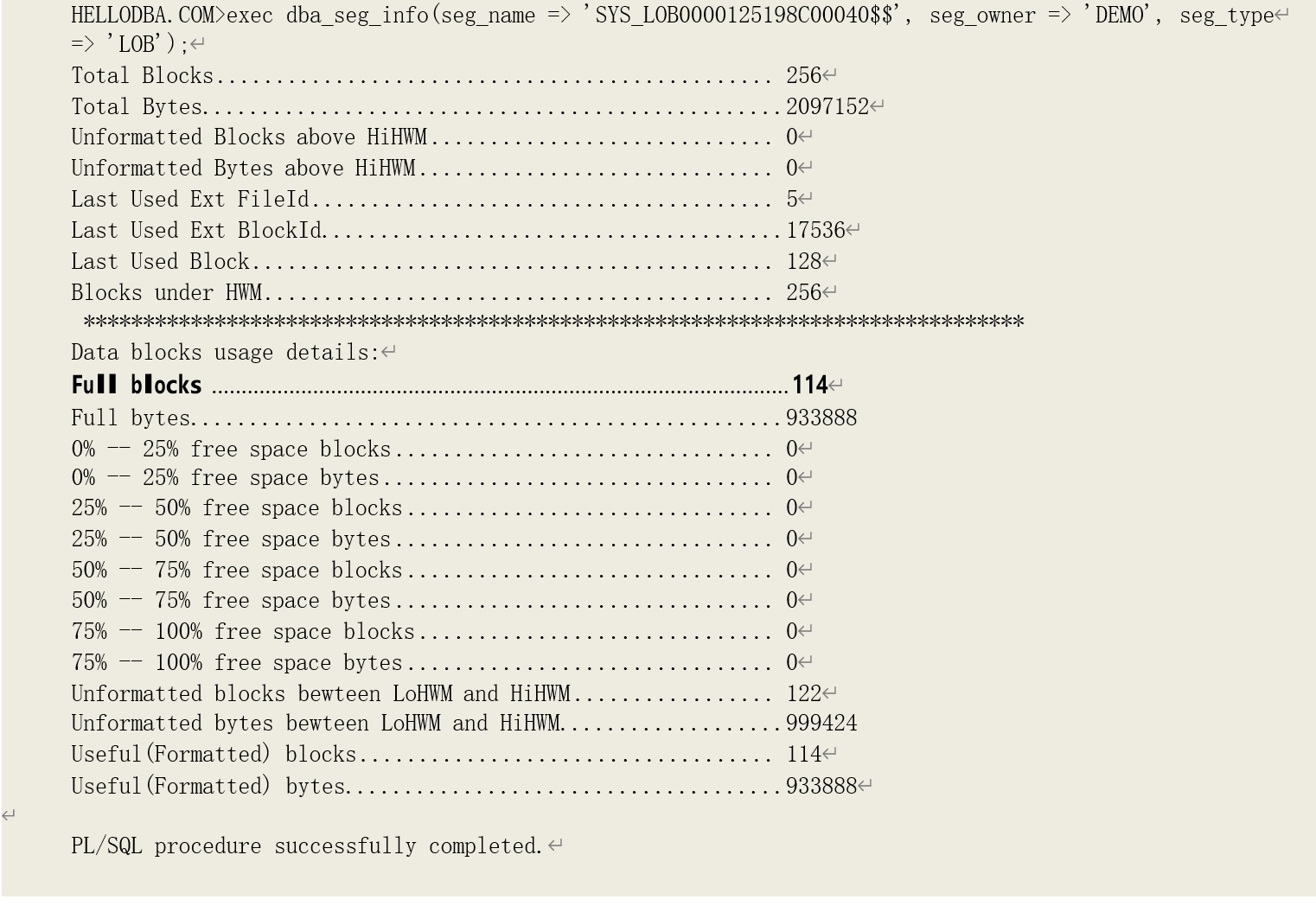
可以看到,高水位线以下被格式化的数据块有 114 块,与性能统计数据中直接读取 LOB 存储的数据块次数一致。
而当我们查询 T_STATTAB,则没有发生直接读取 LOB 数据块的情况:

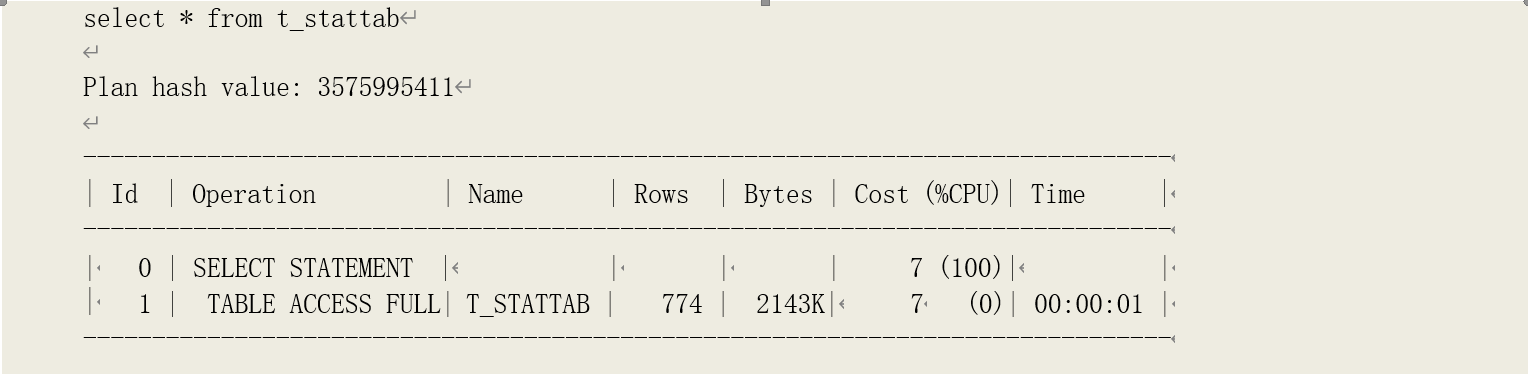

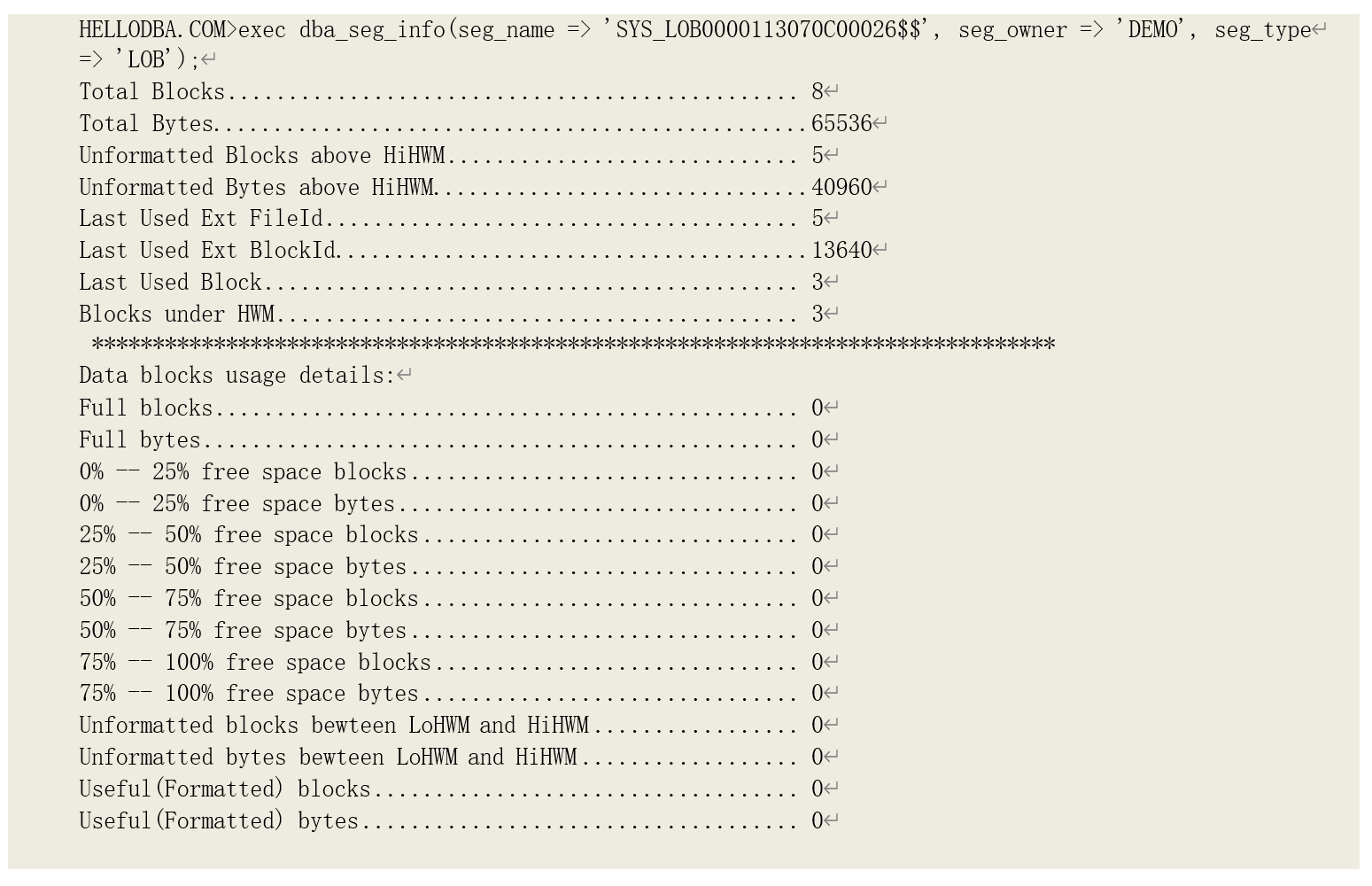
再通过 DBMS_SPACE,可以发现其存储段中没有格式化的数据块,说明其数据目前都存储在表的存储段当中:
读取临时数据块
在进行某些操作时,如排序、哈希关联,Oracle 需要一定的工作区放置输入数据以完成操作。当工作区无法一次容纳下需要输入的所有数据时,Oracle 需要将部分数据先写入临时磁盘、在其它步骤中再次读入以完成对所有数据的操作。而对临时数据的读取,就是以直接读取的方式进行的。 当工作区能够一次容纳下需要输入的所有数据以完成操作时,该操作就是在优化模式(Optimal
Mode)下进行的,因为该模式下所有数据都直接在缓存中处理的,因此也称为缓存模式(Cache
Mode);如果需要一次写入、读取临时磁盘过程来完成操作时,该操作就是在一次传递模式
(One-pass Mode)下进行的;如果需要多次次写入、读取临时磁盘过程来完成操作时,该操作就
是在多次传递模式(Multi-pass Mode)下进行的,这种模式下,允许系统分配给该操作最小的内存, 因此也称为最小化模式(Minimal Mode)。
在 9i 之前版本,工作区大小是由系统参数(如 sort_area_szie、sort_area_retain_szie、
hash_area_size)指定的,每次运行时根据参数设置分配固定大小的工作区。并且可能还需要 DBA
根据情况对它们进行调整,使得其能满足大多数操作的需要,提高系统整体性能。从 9i 开始,
Oracle 引入了对 PGA 的自动管理模式,并且使得工作区的大小在运行过程中能根据需要在一个较大范围内进行自我调节,从而使得处理输入数据大小不同的操作在运行时能获得最理想的工作区大小。这一技术就成为可调节的内存分配(Adaptive Memory Allocation)技术。要深入分析相关操作的运
行性能,我们就必须要了解这项技术。
o 可调节的内存分配
进行某些 SQL 操作,如排序、哈希关联时,Oracle 进程需要一定的工作区域对输入数据进行处理,使得最终输出数据满足操作要求。例如,在进行哈希关联时,需要在工作区中创建哈希表,由 哈希表对构建数据集和探测数据集进行关联。但是,在操作实际运行之前,是无法知道每次运行实 际会输入多少数据。在 9i 之前,只能根据参数设置为其分配一块空间(例如,64k)。但实际需要的空间大小可能远小于这一空间大小,造成内存的浪费;也可能远大于该空间大小,造成大量的临 时磁盘读写、使得相关语句性能极为糟糕。
可调节的内存分配技术使得操作在其不同阶段、根据不同影响因素,都能其调整工作区的大小。而工作区大小的调整,也可能意味着操作的工作模式的改变。例如,从优化模式转变为一次传递模 式。
以排序操作为例,整个过程分为两个阶段:输入阶段和合并阶段。合并阶段不是必须的,而是根据输入阶段是否有数据被写如临时磁盘而决定是否执行的。在每个阶段过程中,还会有一些事件 触发进程进一步调整工作区的分配大小。
o 排序操作
排序操作过程分为两个阶段:输入阶段和合并阶段。合并阶段不是必须的,而是根据输入阶段是否有数据被写如临时磁盘而决定是否执行的。在每个阶段过程中,还会有一些事件触发进程进一 步调整工作区的分配大小。
输入阶段
在输入阶段,会分别执行初始化(Initialization)、数据处理执行(Execution)和重新配置
(Reconfigure)三个动作。
在进行初始化时,完成以下工作:
1、查找当前游标是否已经在 Library Cache 中,并查找其排序操作曾经分配的工作区,如果可以找到,则获取工作区的上下文(Context)数据以及该操作的运行统计数据(我们可以通过视图
V$SQL_WORKAREA 查询)。这些数据包括:
• 分配的工作区地址(WORKAREA_ADDRESS);
• 优化模式所需内存的估算大小(ESTIMATED_OPTIMAL_SIZE);
• 各种模式下的运行次数
(OPTIMAL_EXECUTIONS/ONEPASS_EXECUTIONS/MULTIPASSES_EXECUTIONS);
• 最后一次运行所使用的工作区大小(LAST_MEMORY_USED);
• 最大分配的临时磁盘空间大小(MAX_TEMPSEG_SIZE)和最后一次运行分配的临时磁盘空间 大小(LAST_TEMPSEG_SIZE);
• 输入数据大小(Input Size,ISize)、输出数据大小(Output Size,OSize)以及数据记录长度(Row Length,rlen)则可以由这些数据计算得出:
ISize = OSize = ESTIMATED_OPTIMAL_SIZE;
rlen = FLOOR(ESTIMATED_OPTIMAL_SIZE/Cardinality);
2、如果未找到曾经分配的工作区及相关数据,则由系统创建一块工作区,并查找对象统计数据(由视图 dba_tab_statistics 可查询)和执行计划数据(由视图可查询)以初始化工作区相关数据
(即分配游标上下文————Context):获取的对象统计数据和执行计划数据包括但不限于数据记 录平均长度(AVG_ROW_LEN)、输入数据记录数(Cardinality)以及输入数据字节数(BYTES)。初始化的参数:
• 包括估计的输入数据大小(Input Size,ISize)、估计的输出数据大小(Output Size,
OSize),它们由执行计划中的输入数据字节数得来,即 ISize = OSize = BYTES;
• 数据记录长度(Row Length,rlen),由表统计数据中平均记录长度得来,即 rlen = AVG_ROW_LEN;
• 设置以下参数值为 0:各种模式下的运行次数(opt/1pass/mpass),最后一次运行分配的内存大小(lastMem),曾经分配的最大临时磁盘空间(maxTempSegSize)和最后一次运行分配的临时磁盘空间大小(lastTempSegSize);
3、初始化工作区,包括以下工作:
• 将当前游标注册到工作区;
• 调整运行时统计数据,设置估计的输入、输出数据大小(ISize、OSize)为最小:
GREAST(64k, 2rlen);
• 设置 IO 槽大小(IO Slot Size,SSize,或者说 IO 缓冲大小)为最大(IO 槽大小的最大、最小值限制由隐含参数“_smm_auto_min_io_size”和“_smm_auto_max_io_size”设置)
• 由统计数据估算各种模式所需内存大小(memMin、mem1Pass 和 memCache),此时都被
设置为最小值,为输入数据大小的 1.125 倍。假如 2rlen < 64k, 则 ISize = 64k,那么memMin = mem1Pass = memCache = 64*1.125 = 72k
• 分配最小空间给工作区
初始化完成后,就开始执行输入数据的处理,最初的执行是以优化模式执行的。
• 如果输入数据小于最小输入数据大小,则一次执行可以完成操作,并输出结果;
• 如果实际输入数据大小超出当前的估计数据大小或者需要使用的内存大小超出了系统限制 的单个会话的工作区最大值(工作区最大大小限制由隐含参数“_smm_max_size”设置) 时,则会进行重新配置(Reconfigure)相关参数并调整工作区大小。
在重新配置过程中,根据排序所处阶段不同,采用不同的调整策略:
• 在内存排序阶段,即可分配内存足够、未产生读写临时磁盘之前,当已分配工作区全部被占用、仍然有数据输入时:调整方法为在估计输入数据大小的基础上乘以一个系数(一个大于 1 小于 2 的数字,如 1.2),然后基于该数据再次计算所需工作区大小,并请求分配, 如请求分配内存大小未超出系统限制(“_smm_max_size”),则分配所需内存,并继续以优化模式处理输入数据;否则,进入初始化运行(Initial Run)阶段,
• 初始化运行(Initial Run)阶段,即内存排序后的数据需要被写入磁盘后再次读入输入数据, 当已分配工作区全部被占用、仍然有数据输入时:调整方法为在估计输入数据大小的基础
上乘以一个系数(一个大于 1 小于 2 的数字,如 1.2),然后基于该数据再次计算缓存模式所需工作区大小(缓存模式所需工作区大小=新的估算大小-已排序数据大小);并且还要
计算一次传递模式(One-pass Mode)所需内存,如果该值大于系统限制
(“_smm_max_size”),则需要调整 IO 槽大小(为最小值,_smm_auto_min_io_size)重新计算一次传递模式所需内存,如果再次计算结果仍然大于系统限制,则一次传递模式所
需内存采用系统限制值;最终工作区大小采用缓存模式和一次传递模式所需内存的最小值; 一次传递模式(One-pass Mode)所需内存计算方法如下:
o 先由新估计的输入数据大小(已经排序的数据则已写入磁盘)得出还需要处理的数据 大小:
Input_Left_Szie = New_Estim_size = Sorted_Data_Size * Factor
其中,New_Estim_size 为新估计的数据数据大小,Sorted_Data_Size 为以排序的数据大小,Factor 约等于 1.2
o 再由以下公式计算出剩余的内存排序次数:
Runs_Left = (sqrt(Runs_Done^2 + 2Input_Left_Szie/SSize) - Runs_Done)/ 2
其中,Runs_Done 为已经完成的内存排序(即初始化运行,Initial Runs)次数,SSize
为 IO 槽大小;
o 最后由已经完成的内存排序次数和剩余的内存排序次数得出一次传递模式所需内存的 大小:
One_Pass_Mem = 2(Runs_Done + Runs_Left)Read_Slot_Size + 2Write_Slot_Number*Write_Slot_Size
提示:在非内存排序模式下,读入数据和写入临时磁盘数据是可以同时进行的,因此,异步 IO 能极大减少排序操作的响应时间。异步 IO 下,一次传递模式所需内存计算需要乘以 2,并且保留 2 个写槽(Write Slot,Write_Slot_Number)。
异步 IO 模式下。由于一次传递是同时读写数据,因此工作区需要保留 2 个 IO 槽用于写入数据到临时磁盘,因此,留给读入数据的内存会被在优化模式下更小。
所有输入数据都完成内存排序并写入磁盘后,进入合并(Merge)阶段。进入该阶段后,IO 槽大小重新调整为最大设置(“_smm_auto_max_io_size”),并据此计算一次传递模式所需内存大小。同样,如果计算结果大于系统限制,则需要调整 IO 槽大小(为最小值,
_smm_auto_min_io_size)重新计算。并最终采用计算的一次传递模式所需内存大小为排序工作区大 小。由于此时计算的是最终排序(Final Merge)所需内存,而最终排序是无需再将数据写入临时磁盘、而是直接输出给客户端,并且此时已没有未处理的数据。因此,计算公式调整为以下公式:
One_Pass_Mem = 2*(Runs_Done)*Read_Slot_Size
而进入合并阶段后,需要依据初始化运行(Initial Runs)次数和运行参数计算出合并次数,运行参数的计算如下:
• sort_area_size 为合并阶段计算所得的工作区大小;
• sort_multiblock_read_count 为每次读写临时磁盘的数据块数:
sort_multiblock_read_count = SSize/Blksize
其中,SSize 为 IO 槽大小,blksiz 为数据块大小
• max intermediate merge width 为除最终合并以外的中间合并(intermediate merge,或者称中间运行,intermediate run)的最大合并宽度
max intermediate merge width = sort_area_size/SSize/2 - write slots number
由于中间合并的结果仍然需要被写入临时磁盘,因此留给读入数据的内存大小需要减去预 留给写数据的内存大小,在异步 IO 模式下,写槽数(write slots number)为 2;
• max final merge width 为最终合并宽度,最终合并结果可以被直接输出给客户的,无需写入磁盘,因此计算公式为:
max final merge width = sort_area_size/SSize/2
在进行合并时,需要遵循以下几个原则:
- 为保证各个读入槽的读取数据时间相对平衡,每次合并时读取相近大小的数据集,由 小到大进行合并;
- 中间合并的结果也作为后续合并的数据集;
- 根据原则 1,最终合并的数据集为最大的数据集,并且在多次传递模式(Multi-pass
Mode)下,其合并的数据集个数等于最终合并宽度;
按照以上 3 个原则,我们可以给出以下伪代码计算合并次数:

以上过程即为可调节的内存分配管理模式下的排序的内存分配过程。
提示:在默认情况下,排序区最大限制(“_smm_max_size”)由系统设置,为 PGA 大小
(“pga_aggregate_target”)的 20%。
在进一步分析排序操作的性能之前,我们先简单地了解 Oracle 的排序算法。目前(10gR2 及以后版本),在 Oracle 中存在两种版本的排序算法,我们下面对它们做一个简单描述。
排序算法(版本 1,V1)
我们知道,在进行 SQL 查询时,排序操作是在特定的内存中完成的,也就是排序工作区。初次进入排序区的数据是无序的,Oracle 要选择一项合适的算法对这些无序数据进行排序。
在 10g 之前,工作区是固定分配的(sort_area_size 设置)。除非在会话中重新设置,所有会话都只能分配相同大小的排序区。因此,这就决定了排序区大小通常不能太大。而也就成为 Oracle 选择排序算法的重要因素————空间复杂度小并且稳定。而在所有已知排序算法中,空间复杂度最小的算法为插入排序、选择排序和堆排序,复杂度为 O(1),但是选择排序和堆排序都具有不稳性, 因此最终选择插入排序。
插入排序的实现也比较简单:
-
将数据逐个从无序数据集中取出,放入有序数据集中的合适位置;
-
有序数据集以特定数据结构组织,如链表、阵列等;在 Oracle 中,则是平衡二叉树。
但是,插入排序的效率并不理想,其时间复杂度为 O(n^2),这使得在进行排序时,CPU 的消耗也会比较高。我们称这一算法为版本 1 的算法。
排序算法(版本 2,V2)
在 10g 以后,对私有内存的管理发生了很大的变化。不仅 PGA 本身能灵活伸展,工作区的管理和分配也变得非常灵活。例如,在默认情况下,2G PGA 允许会话的工作区大小从 204k 到 40M 之间伸缩。如此灵活的工作空间,使得 Oracle 选择效率更高的排序算法成为可能。在 10gR2 开始,
Oracle 引入了新的排序算法。
我们知道,在所有基于比较的排序算法中,效率最高的当属快速排序了(时间复杂度为 O(n Log
n))。但是,快速排序无论是在时间效率还是空间效率方面,都属于一种不稳定的排序算法。因此, 为了弥补它这方面的不足,很多研究人员会将它与其他一些排序算法(通常是一些非基于比较的排 序算法)结合起来,在降低算法的不稳定性的同时,又提高其效率。
在 Oracle 10g 中,也同样是引入了快速排序的改进算法,而与其混合的算法则是所有算法中时间复杂度最低的基数排序算法。
基数排序是一种非基于比较的排序算法,它是另外一种排序算法————桶排序的改进算法, 对数据的排序键值有一定要求:
- 它首先要求所有数据排序键值具有相同长度,如果长度不同,则按照最长数据位数进行左 补 0 对齐;
- 为获得稳定性,它还要求知道当前排序键值最大、最小值,从而确定“桶”的范围。
基数排序算法的基本思想如下:
- 从左向右(或从右向左),逐个针对键值中的每位数进行排序;
- 按照当前排序的数字位构造出一批“桶”,按照大小顺序、每个桶盛放一定大小范围的数 据,每条数据则由前排序的数字位放入相应的桶当中;
- 所有数据都放入桶中后,当前一轮排序完成,键值排序位递进一位,并以该位数据再对每 个桶中的数据再次进行排序;
- 如此递归,直到完成最后一个数据位的排序;
- 将所有桶的数据拼接到一起。
基数排序是一种稳定(已知键值范围情况下)的排序算法,它的时间复杂度为 O(n*k),其中 k 为排序键值的位数,也是影响其效率的关键因素。例如,与快速排序向比较,如果 k<Log(n),则其效率比快速排序高。
因此,Oracle 在混合这两种算法时,充分利用各自的优势来弥补对方的不足:
• 利用基数排序来提高算法的稳定性;
• 利用快速排序来减少基数排序中的匹配位数;
在解释 Oracle 如何做到相互弥补之前,先看下快速排序是如何实现的:
- 从数据中找一个轴心数,依据这个轴心数将数据集分为 3 个分区:小于轴心数的数据放左边、相等的放中间、大于的放右边(有些实现方法分 2 个分区,将等于的放在左边或右边);
- 递归地对左、右分区进行划分,直到分区中的数据只剩 1 个;
不难理解,快速排序的不稳定性在于其轴心数的选择:在最坏情况下(总是选到最大、最小 值),时间复杂度会达到 O(n^2)。为了降低不稳定性,Oracle 的改进算法在选择轴心数时,会先对数据进行采样,选择采样数据中的中间值为轴心数。另外一项降低不稳定性的举措则是:不直接对 左、右分区进行快速排序,而是对它们进行基数排序————因为在做第一次分区时,已经扫描过
每一条数据,因此基数排序所需的先决条件在扫描完成后都可以满足。特别指出的是:键值数据是 以字节形式存储的,即每位字节的范围是在 0~255 之间。也即是说,在基数排序过程中,我们只需要构造 256 个桶。
除此以外,在快速排序的分区过程中,还完成了另外一件重要的事:找到每个分区中最左边的
相同字节数。如果分区中所有数据最左边的部分字节(假定为 m 位)是相同的,那么在进行基数排序过程中,这 m 位数据就可以被跳过,即其实际复杂度就可以降为 O(n*(k-m))。同样,基数排序过程中,对桶中的数据再次递归排序时,不是调用基数排序方法,而是调用快速排序方法,以再次 减少位数。
如此,两种方法相互递归调用,使得整体算法的不稳定性和时间复杂度都被降低。在 Oracle 中, 这一新算法被称为版本 2 的算法。
我用 Perl 脚本(07_10_OracleNewSort.pl)模拟了版本 2 算法的排序过程,有兴趣的读者可以运行和查看代码。
在 10g、11g 中,默认下会采用版本 2 的算法进行排序。
合并排序
无论是采用版本 1 还是版本 2 的排序算法,排序操作都是在排序工作区中完成的。当排序工作区大小足够大、能容纳下所有数据完成排序过程是,称其为优化(Optimal)排序,也可以说内存排序;相反,如果排序工作区大小不足,无法一次完成对所有数据的排序,则每次能将部分数据进 行排序,并将已排序数据写入临时磁盘空间,当所有数据都已分组排序写入临时磁盘后(这一过程 也称为初始化运行,Initial run),再将已排序的分组数据读入工作区进行合并排序,这样的排序过程也成为磁盘排序。对于磁盘排序,仅作一次合并就称为一次传递排序(One-Pass);需要进行多次排序则成为多次传递排序(Multi-Pass)。
进行合并排序时,可以同时合并两组或者多组已排序数据,合并的数据组数即为合并宽度
(Merge Width),它由工作区大小和每次读取的数据块数共同决定。在排序合并过程中,对临时磁盘数据的读取就是直接读。
