




平台建设背景
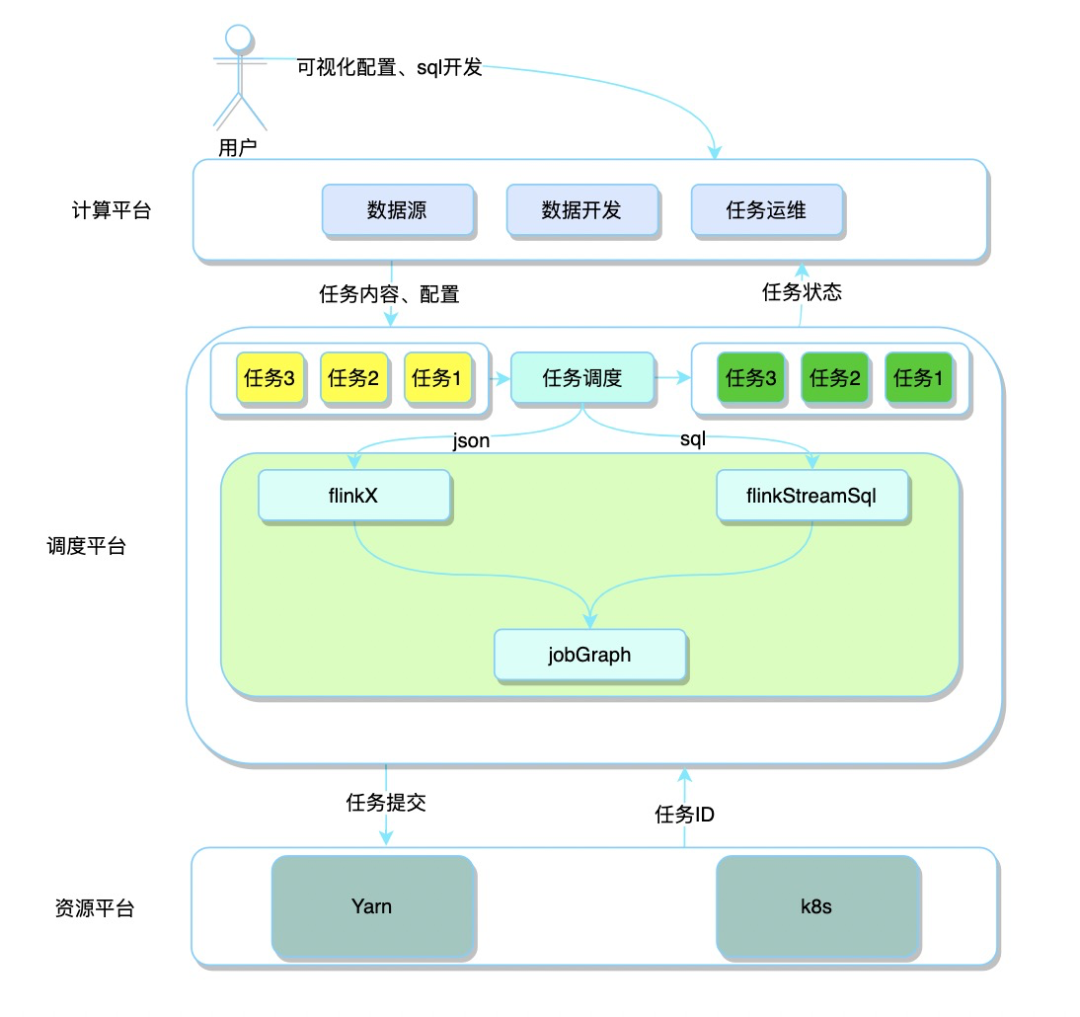
平台总体架构
01
计算平台
02
调度平台
数据同步任务:接收到上层传过来的json后,进入到FlinkX框架中,根据数据源端和写出目标端的不同生成对应的DataStream,最后转换成JobGraph。
数据计算任务:接收到上层传过来的sql后,进入到FlinkStreamSql框架中,解析sql、注册成表、生成transformation,最后转换成JobGraph。
调度平台将得到的JobGraph提交到对应的资源平台,完成任务的提交。
03
资源平台
数据同步和数据计算
01
FlinkX
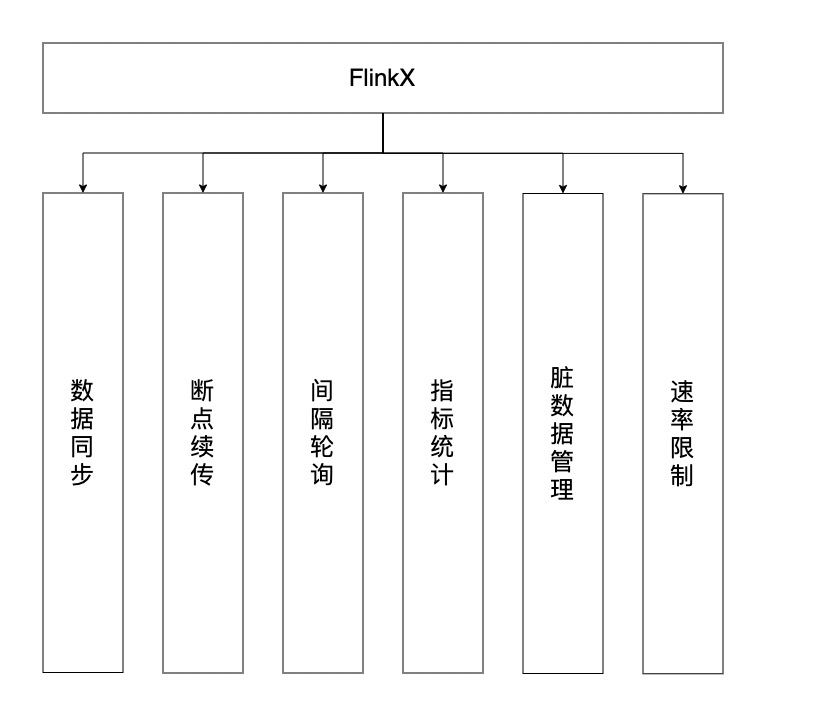
作为数据处理的第一步,也是最基础的一步,我们看看FlinkX是如何在Flink的基础上做二次开发,使用用户只需要关注同步任务的json脚本和一些配置,无需关心调用Flink的细节,并支持下图中的功能。


1)解析参数,如:并行度、savepoint路径、程序的入口jar包(平常写的Flink demo)、Flink-conf.yml中的配置等。
比如:在两个并行度读取mysql时,通过配置的分片字段(比如自增主键id)。
该方法主要做以下几件事
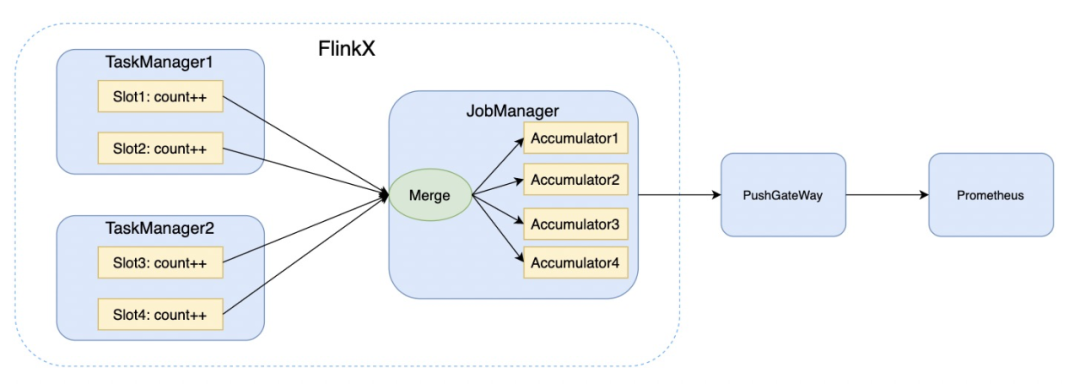
初始化累加器,记录读入、写出的条数、字节数
初始化自定义的Metric
开启限速器
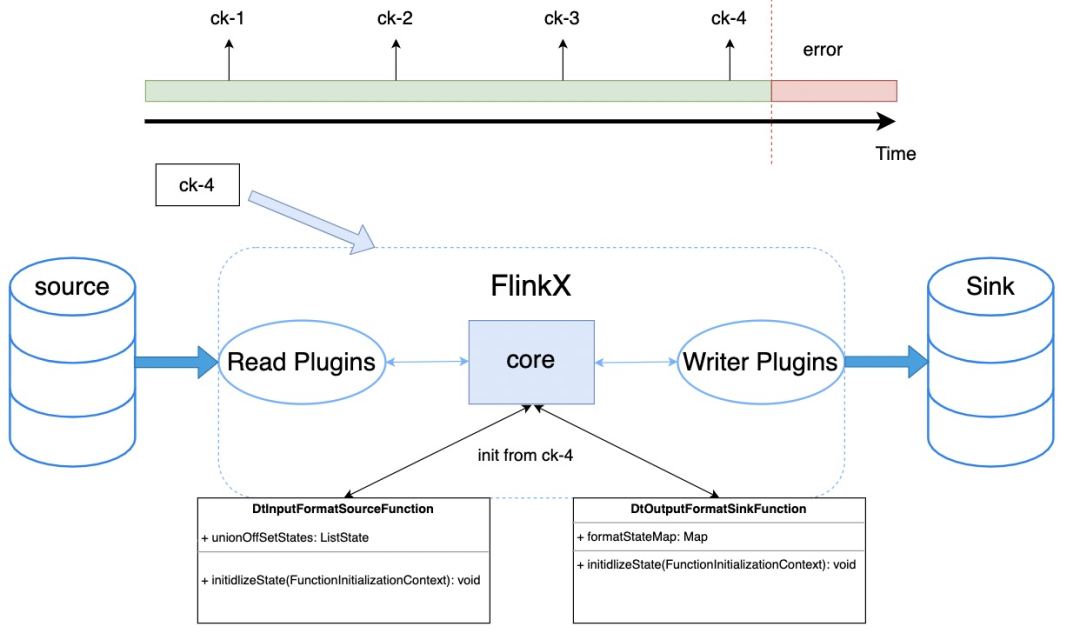
初始化状态
打开读取数据源的连接(根据数据源的不同,每个插件各自实现)
4、FlinkX的特性
累加器是从用户函数和操作中,分布式地统计或者聚合信息。每个并行实例创建并更新自己的Accumulator对象, 然后合并收集不同并行实例,在作业结束时由系统合并,并可将结果推动到普罗米修斯中,如图:
我们知道FlinkX是一个支持离线和实时同步的框架,这里以mysql数据源为例,看看是如何实现的。
离线任务:
在DtInputFormatSourceFunction的run方法中会调用InputFormat的open方法读取数据记录到resultSet中,之后再调用reachedEnd方法的判断resultSet的数据是否读取完,如果读取完,就走后续的close流程。
实时任务:
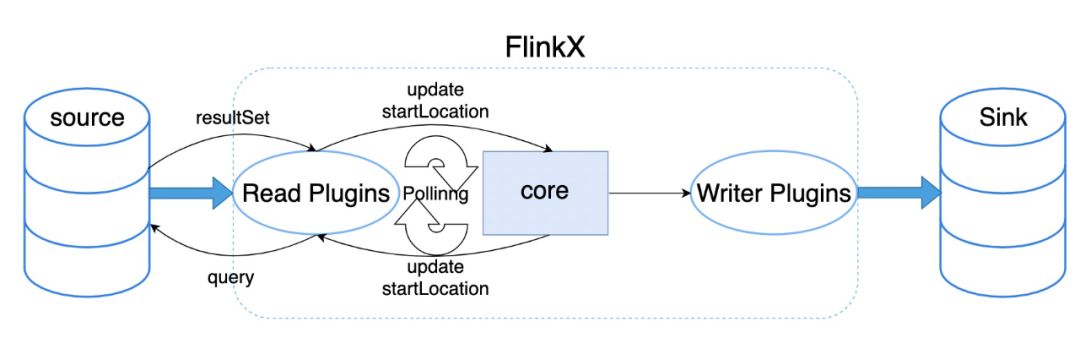
open方法和离线一致,在reachedEnd时判断是否是轮询任务,如果是则会进入到间隔轮询的分支中,将上一次轮询读取到的最大的一个增量字段值,作为本次轮询开始位置进行下一次轮询,轮询流程图如下:
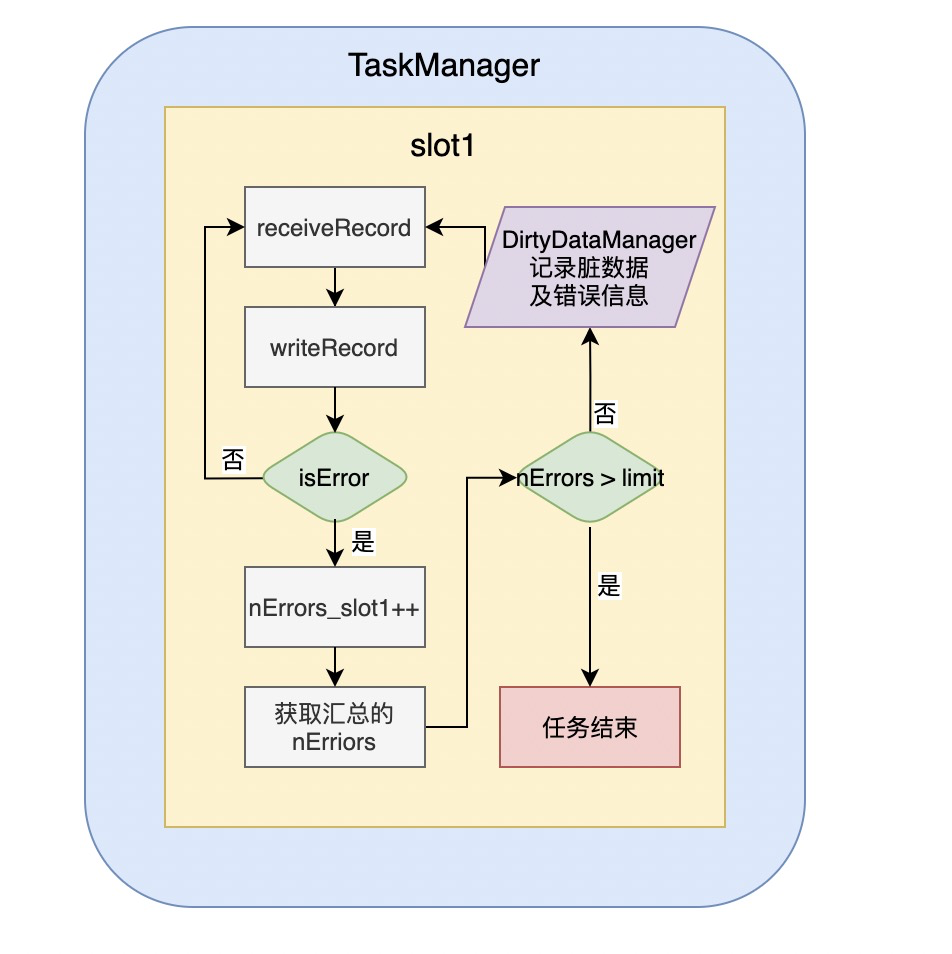
是把写入数据源时出错的数据记录下来,并把错误原因分类,然后写入配置的脏数据表。
错误原因目前有:类型转换错误、空指针、主键冲突和其它错误四类。
错误控制是基于Flink的累加器,运行过程中记录出错的记录数,然后在单独的线程里定时判断错误的记录数是否已经超出配置的最大值,如果超出,则抛出异常使任务失败。这样可以对数据精确度要求不同的任务,做不同的错误控制,控制流程图如下:
4)限速器
对于一些上游数据产生过快的任务,会对下游数据库造成较大的压力,故而需要在源端做一些速率控制,FlinkX使用的是令牌桶限流方式控制速率,如下图。当源端产生数据的速率达到某个阈值时,就不会在读取新的数据,在BaseRichInputFormat的open阶段也初始化了限速器。

以上就是FlinkX数据同步的基本原理,但是数据业务场景中数据同步只是第一步,由于FlinkX目前的版本中只有ETL中的EL,并不具备对数据的转换和计算的能力,故而需要将产生的数据流入到下游的FlinkStreamSql。
02
FlinkStreamSql
基于Flink,对其实时sql进行扩展,主要扩展了流与维表的join,并支持原生Flink SQL所有的语法,目前FlinkStreamSql source端只能对接kafka,所以默认上游数据来源都是kafka。
我们看看FlinkStreamSql 又是如何在Flink基础之上做到用户只需要关注业务sql代码,屏蔽底层是如何调用Flink api。整体流程和上面介绍的FlinkX基本类似,不同点在Client端,这里主要包括sql解析、注册表、执行sql 三个部分,所以这里重点介绍这部分。
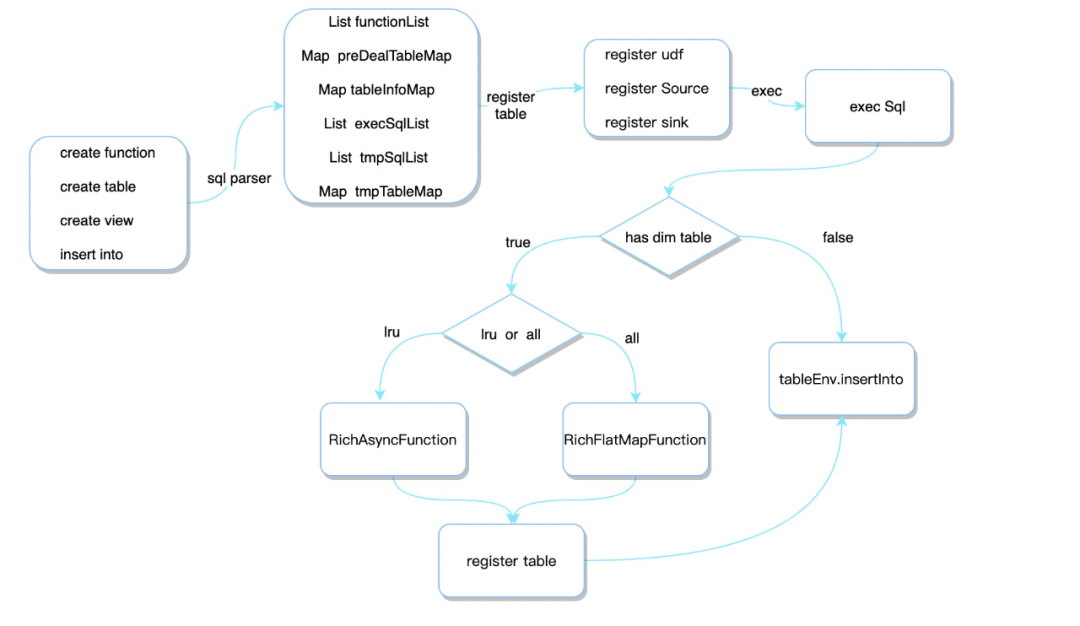
1、解析SQL
全量维表:将上游数据作为输入,使用RichFlatMapFunction作为查询算子,初始化时将数据全表捞到内存中,然后和输入数据组拼得到打宽后的数据,然后重新注册一张大表,供后续sql使用。
异步维表:将上游数据作为输入,使用RichAsyncFunction作为查询算子,并将查询得到的数据使用LRU缓存,然后和输入数据组拼得到打宽后的数据,然后重新注册一张大表,供后续sql使用。
任务运维
01
任务运行信息
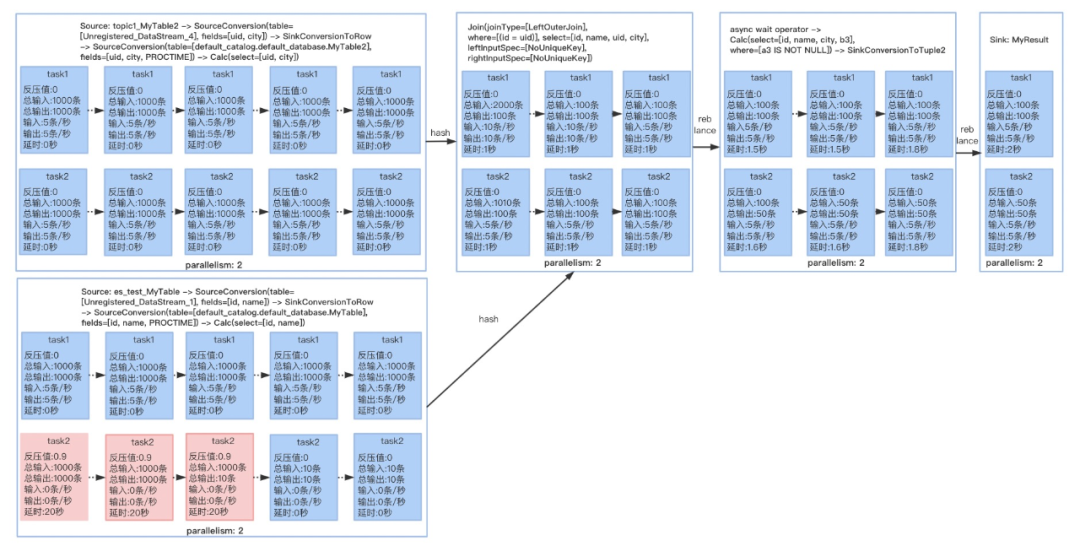
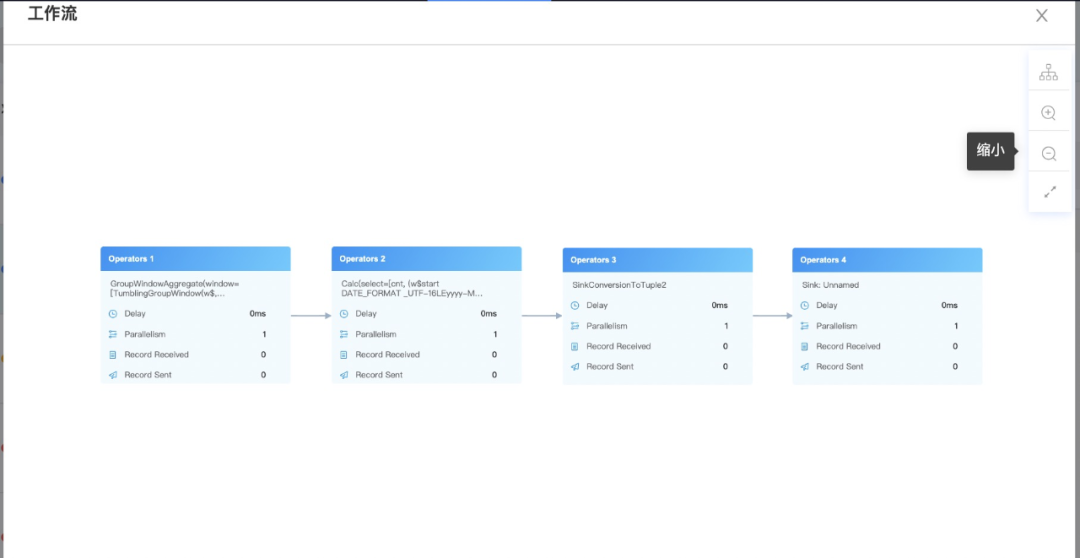
我们知道FlinkStreamSql是基于Flinksql封装的,所以在提交任务运行时最终还是走的Flinksql的解析、验证、逻辑计划、逻辑计划优化、物理计划,最后将任务运行起来,也就得到了我们经常看见的DAG图:
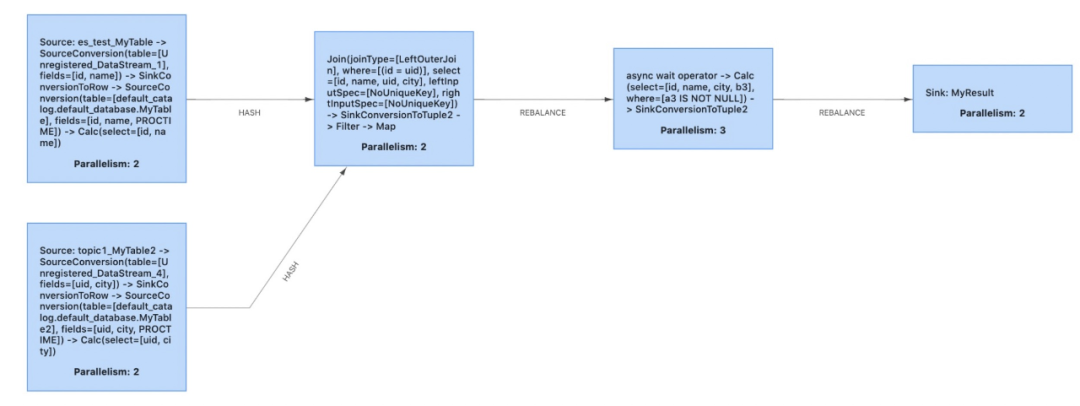
所以我们在原来生成DAG图的方式上进行了一定的改造,这样就能直观的看到子DAG图中每个Operator和每个并行度里面发生了什么事情,有了详细的DAG图后其他的一些监控维度就能直观的展示,比如:数据输入输出、延时、反压、数据倾斜,在出现问题时就能具体定位到,如下图的反压:
使用案例
01
实时同步mysql新增数据
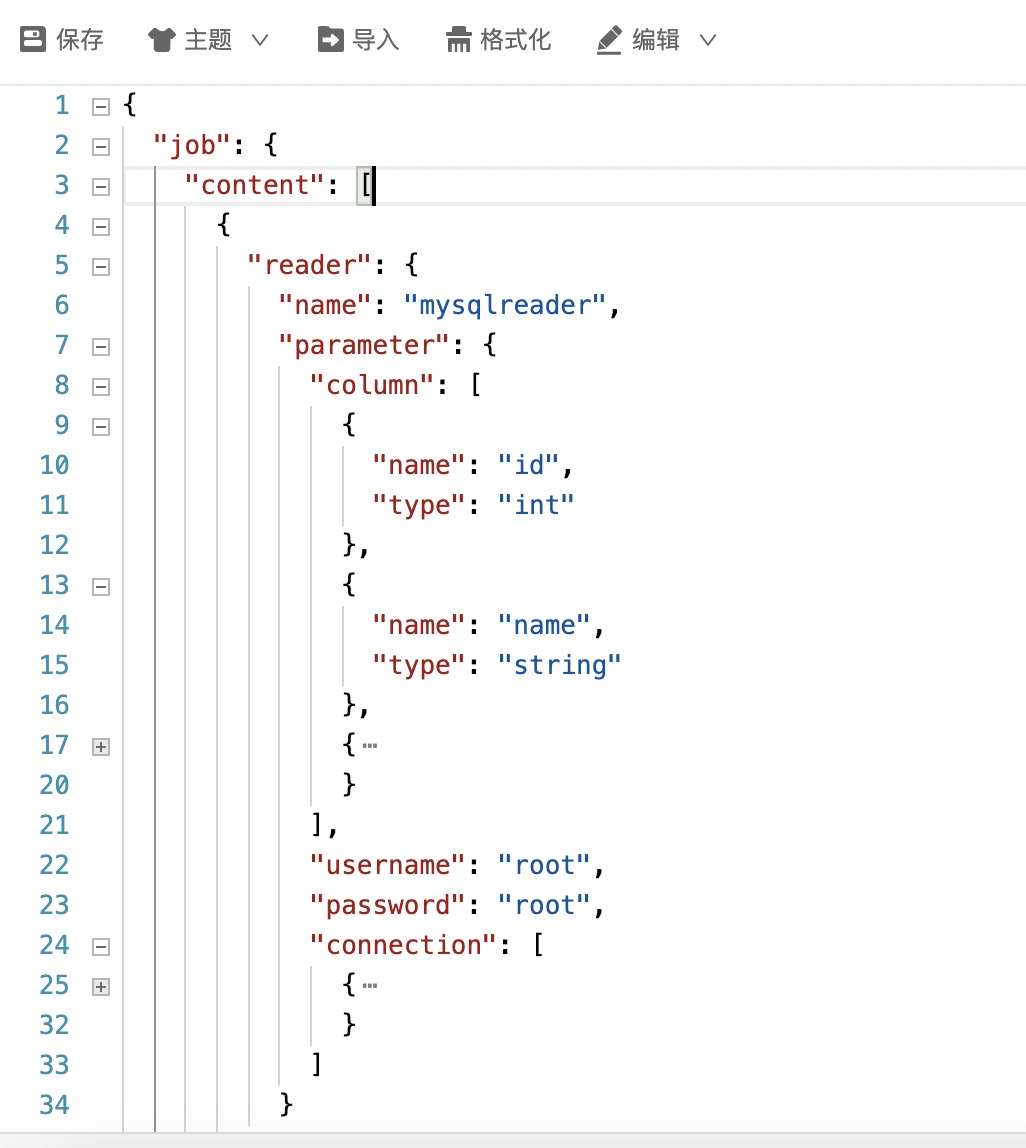
02
实时计算每分钟新增用户数

03
运行信息
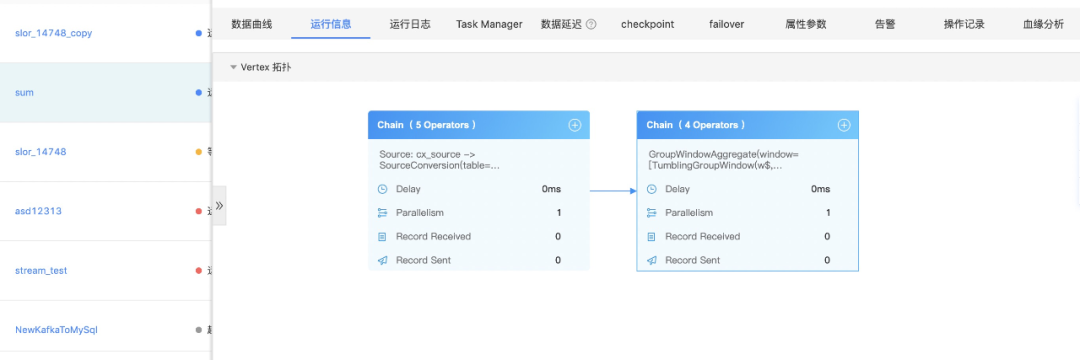
整体DAG,可以直观的显示上面提到的多项指标
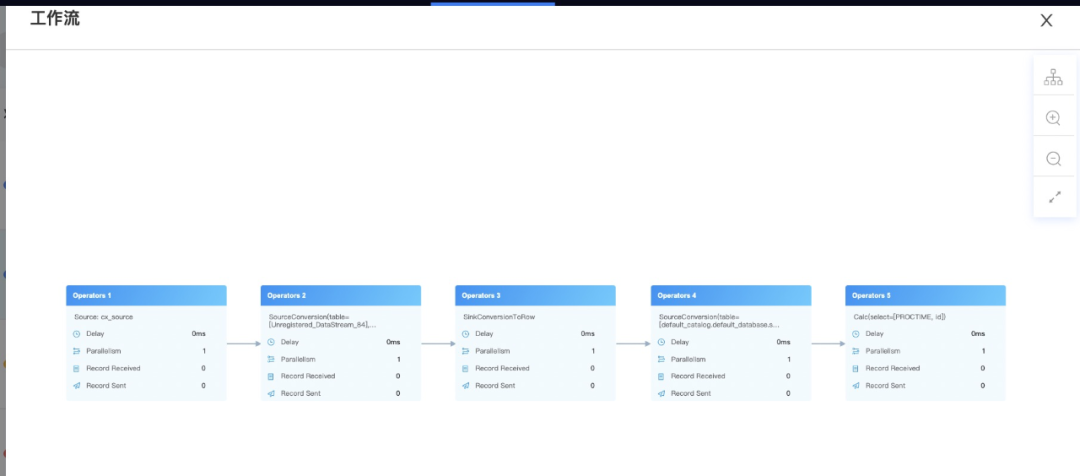
解析后的详细DAG图,可以看到子DAG内部的多项指标

本文作者
吹雪
数栈大数据高级工程师
FlinkX-Oracle Logminer模块介绍丨直播回顾
Flink提交流程&如何debug和跟踪流程(on yarn)丨直播回顾
Flink jm、tm启动过程和资源分配丨直播回顾
如何自定义Flink LookupTable 丨直播回顾

更多技术交流方式
想面对面的进行技术交流吗?想及时参与直播活动吗?可扫码加入钉钉群“袋鼠云开源框架技术交流群”(群号:30537511)

Gitee开源项目地址:
点击“阅读原文”,一键到达FlinkX开源项目!
