




了解了排序算法后,我们再来看排序操作的运行性能。由前面的算法描述我们知道,是否进行内存排序是由工作区大小和排序数据大小决定的:而排序数据大小小于工作区大小则能进行内存排 序。内存中的排序数据也需要以数据块为单位组织,因此排序工作区还需要包括数据块头和排序算 法本身所需的数据结构。因此,我们可能无法精确计算出内存排序所需要的工作区大小,但是我们 可以用经验值来估算。我的一个估算方法是:由系统函数 sys_op_opnsize(前面章节有介绍)得到排序数据大小,然后再除以经验系数 0.8,例如:
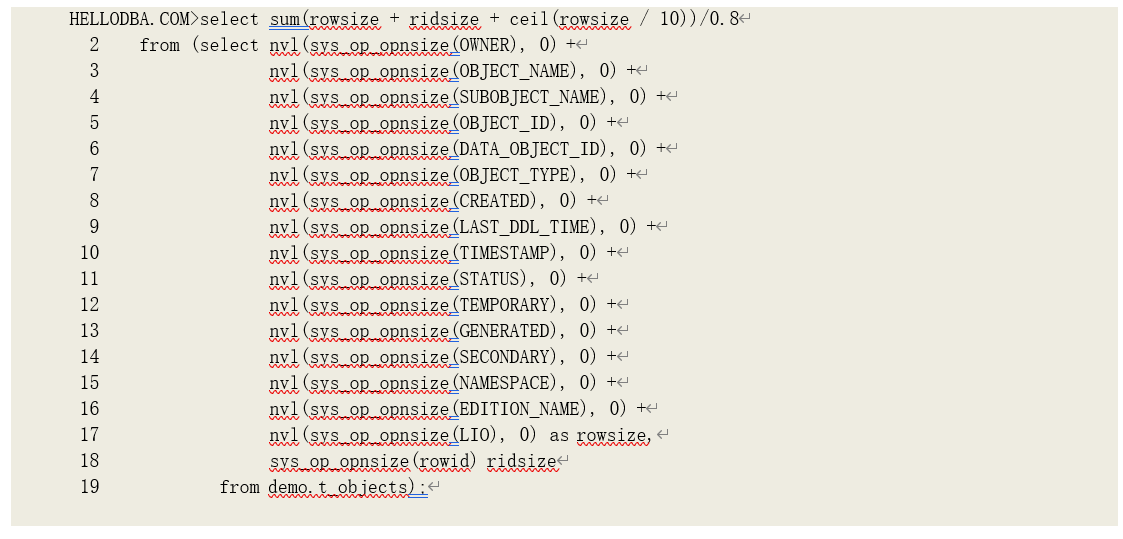

排序示例
我们以一个多次传递模式下的排序过程作为示例,详细分析其运行性能。为了造成多次传递我特地修改了会话参数“_smm_max_size”等于 1024k:
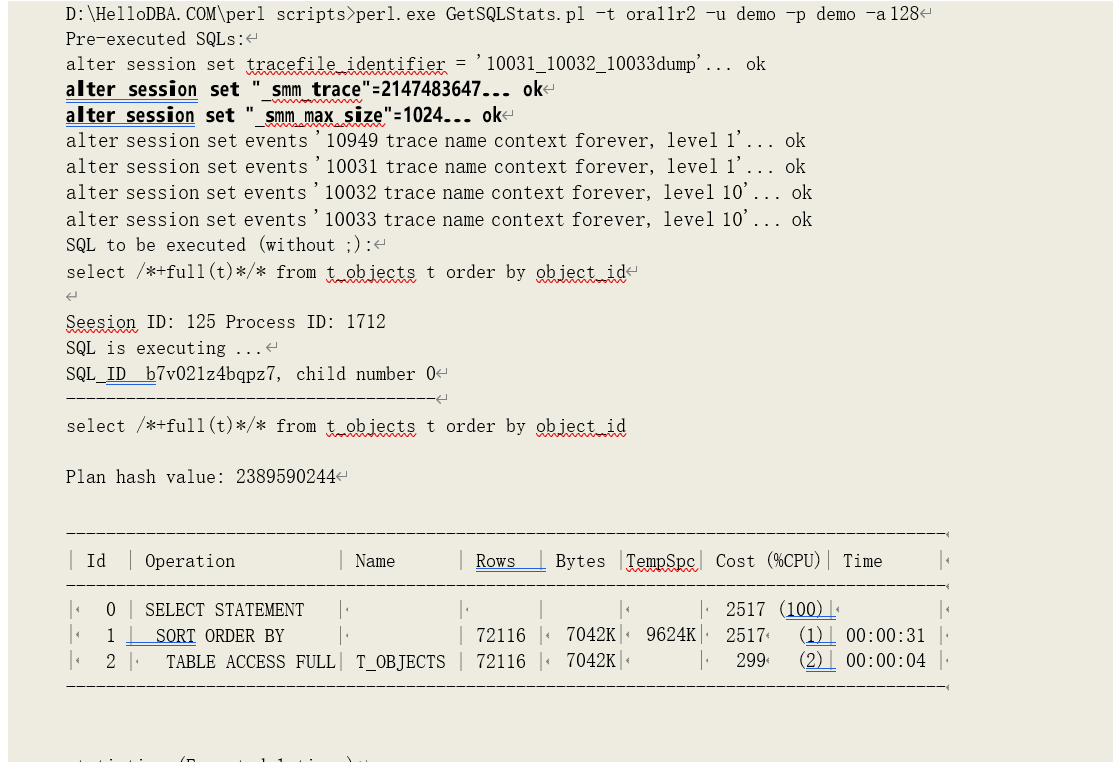
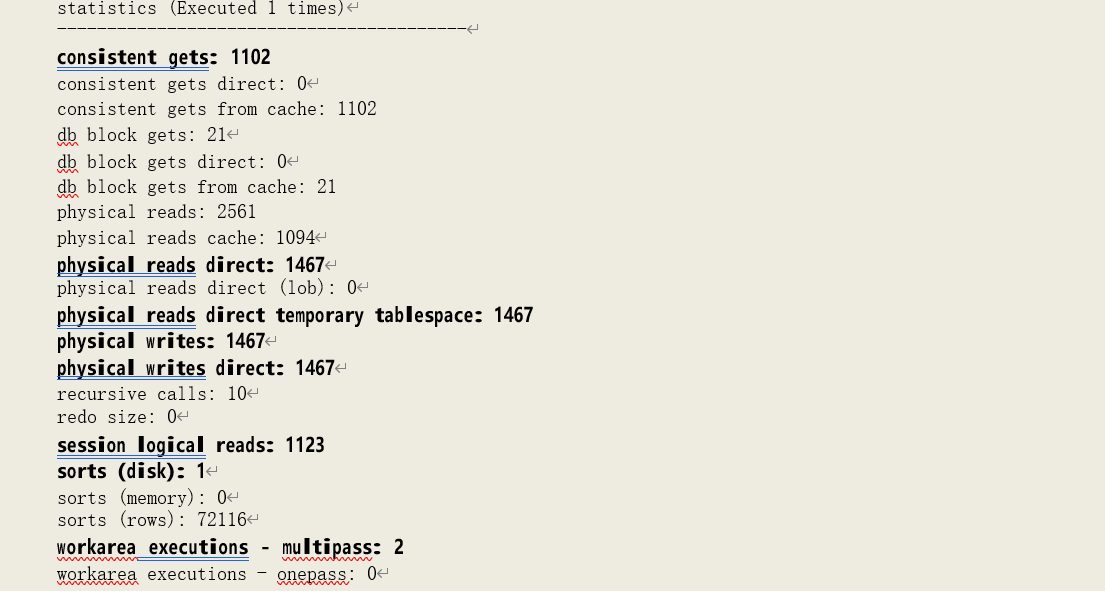

从运行统计数据中可以看到。临时磁盘读写的数据块数为 1467(提示:直接读写临时磁盘的次数并未统计到逻辑读当中),SQL 产生了一次磁盘排序(sorts (disk): 1),而由统计数据“workarea executions - multipass: 2”可以知道其为多次传递模式的排序。为了深度分析该排序过程,我还在会话中打开了多个跟踪事件:
• _smm_trace:SQL 内存管理的跟踪,即工作区管理和分配的跟踪,2147483647 为最大级别, 显示所有跟踪信息;
• 10031:跟踪排序过程的调试信息
o 级别 1:跟踪相关内部函数的调用和返回信息;
o 级别 2:导出系统的工作区的内存堆(heap)信息;
o 级别 4:新旧排序算法的使用;
• 10032:导出排序的运行统计数据,10 为最大级别;
• 10033:导出排序的中间合并的运行统计数据,10 为最大级别。
我们在跟踪文件内容的起始部分开始分析:
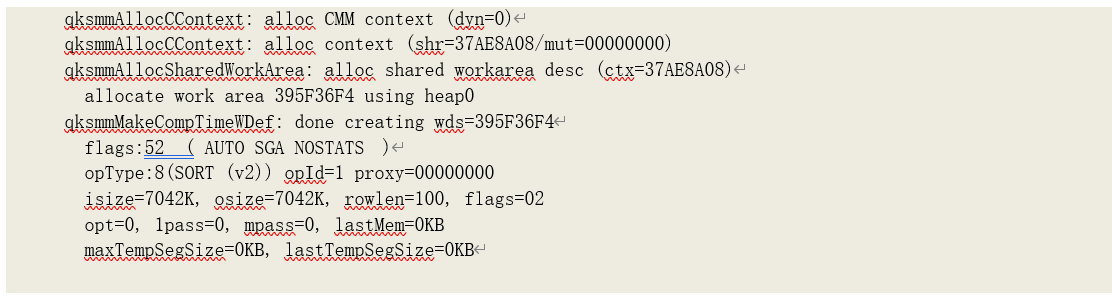
由于该语句是在数据库启动后第一次运行,因此缓存中找不到当前游标的以往运行的工作区数 据,需要为其创建新的工作区。首先由其统计数据计算出工作区的上下文(Context)数据。
• isize 为输入数据大小,由执行计划中其子操作的输出数据大小(BYTES)得到;
• osize 为输出数据大小,由执行计划中其操作的输出数据大小(BYTES)得到;
• rowlen 为数据记录平均长度,由输入数据大小除以其子操作的输入数据记录数(Cardinality) 得到
其执行计划的相关统计数据为:
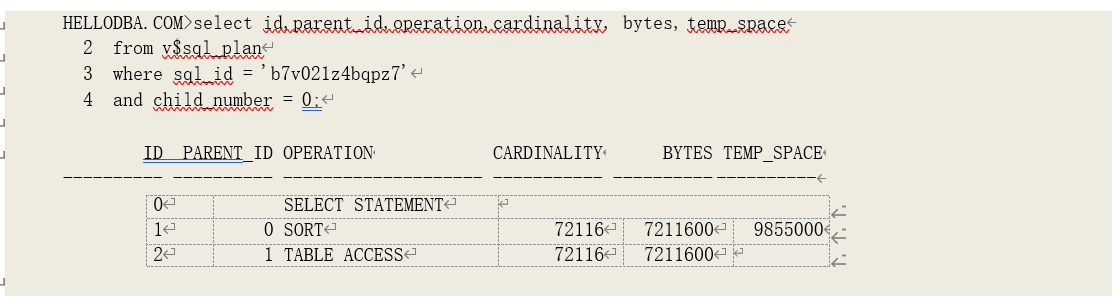
此,isize=7211600/1024=7042k,osize=7211600/1024=7042k,rowlen=7211600/72116=100
并且,此时初始化排序操作运行统计数据,优化模式运行次数(opt)、一次传递模式运行次数
(1pass)、多次传递运行次数(mapss)、最后一次运行的最终分配内存大小(lastMem)、曾经
分配的最大临时磁盘空间大小(maxTempSegSize)和最后一次运行分配的临时磁盘空间大小
(lastTempSegSize)为 0。
提示:如果当前游标曾经分配过工作区,我们则可以由缓存中获取工作区的上下文(Context)数据:

得到上下文数据后,开始初始化工作区:
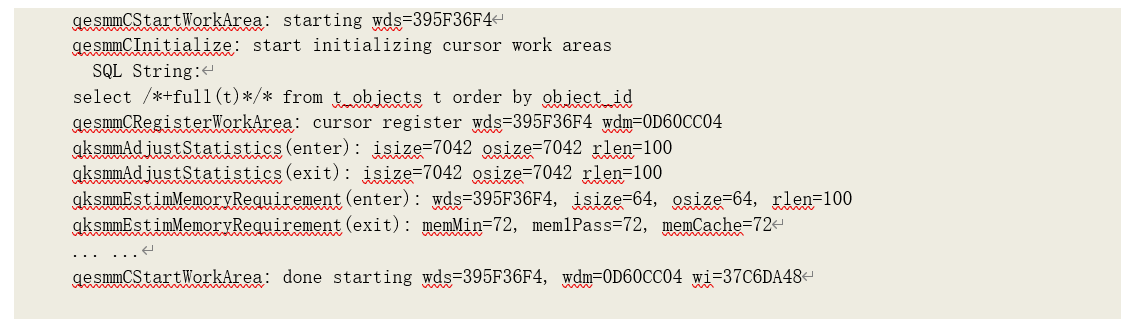
在初始化工作区时,估计输入的数据大小设为最小:GREAST(64k, 2rlen),即 64k 或者平均记录长度的 2 倍大小当中的最大值,并以此计算所需的工作区大小:641.125=72K。
分配工作区后,开始处理输入数据。当分配的工作区空间已满、且仍有输入数据数据时,需要
调整工作区大小:

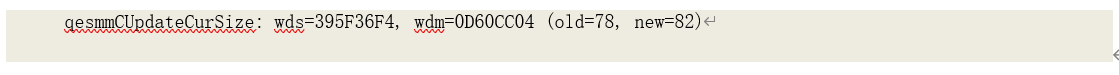
当前操作运行统计数据(Operation statistics)中,curSize 记录了当前分配的工作区大小和曾经分配的最大工作区大小。
在修改工作区请求大小之前,还要根据当前的 PGA 使用情况决定 PGA 可用空间限制是否能接受该请求大小(qesmmCComputeCursorBound),高并发环境中,该限制大小可能会小于单个会话 的工作区最大限制(_smm_max_size)。
因为当前是缓存模式运行,工作区大小的调整基本上是原有大小乘以系数 1.2 左右。因为此时并不需要进行临时磁盘的直接读写,因此读写槽大小(rsz/wsz)等于数据块大小(8k)。dwn 应该是直接写槽数(Direct Write slot Number)。
在缓存模式下,工作区大小的调整都是按照上述方式进行的,直到计算得出所需内存大小超出
系统限制(_smm_max_size,1024k):

此时,由于请求的工作区大小(1206K)大于系统限制(1024k),因此系统仅允许分配 1024k
内存。并且内存中已排序的数据需要准备被写入磁盘,因而需要为工作注册临时段
(qesmmCRegisterTempSeg)。运行模式由优化模式转为一次传递模式,准备进入初始化运行阶段, 需要计算一次传递模式所需内存(1pass),计算过程如下:
Input_Left_Szie = New_Estim_size = Sorted_Data_Size * Factor = 1206k Runs_Left = (sqrt(Runs_Done^2 + 2Input_Left_Szie/SSize) - Runs_Done)/ 2
= (sqrt(0^2 + 21206/248) - 0)/ 2
= 1.559
≈ 2
One_Pass_Mem = 2*(Runs_Done + Runs_Left)Read_Slot_Size + 22Write_Slot_Size
= 2(0+2)248+22*248
= 1984
其中,New_Estim_size 即由已排序数据估算的剩余输入数据大小(cmy,可能是 Cache mode Memory Yields 的缩写),即 1206k;由于目前还未产生初始化运行结果,因此已经执行的初始化运
行次数(Runs_Done,即跟踪记录中的 nru)为 0;SSize 为读写槽的大小,此时设为最大
(“_smm_auto_max_io_size”,248k),即跟踪记录中的 S;Runs_Left 为计算所得的剩余初始化运行次数,即跟踪记录中的 nrulft;One_Pass_Mem 为一次传递模式所需内存大小,即跟踪记录中的 1pass。
此时,由于计算出的一次传递模式所需内存大小超出了系统最大值(“_smm_max_size”,
1024k)的限制,因此需要调整读写槽的大小为系统设置的最小值(“_smm_auto_min_io_size”,
56k)后重新计算:
此时,由于请求的工作区大小(1206K)大于系统限制(1024k),因此系统仅允许分配 1024k
内存。并且内存中已排序的数据需要准备被写入磁盘,因而需要为工作注册临时段
(qesmmCRegisterTempSeg)。运行模式由优化模式转为一次传递模式,准备进入初始化运行阶段, 需要计算一次传递模式所需内存(1pass),计算过程如下:
Input_Left_Szie = New_Estim_size = Sorted_Data_Size * Factor = 1206k Runs_Left = (sqrt(Runs_Done^2 + 2Input_Left_Szie/SSize) - Runs_Done)/ 2
= (sqrt(0^2 + 21206/248) - 0)/ 2
= 1.559
≈ 2
One_Pass_Mem = 2*(Runs_Done + Runs_Left)Read_Slot_Size + 22Write_Slot_Size
= 2(0+2)248+22*248
= 1984
其中,New_Estim_size 即由已排序数据估算的剩余输入数据大小(cmy,可能是 Cache mode Memory Yields 的缩写),即 1206k;由于目前还未产生初始化运行结果,因此已经执行的初始化运
行次数(Runs_Done,即跟踪记录中的 nru)为 0;SSize 为读写槽的大小,此时设为最大
(“_smm_auto_max_io_size”,248k),即跟踪记录中的 S;Runs_Left 为计算所得的剩余初始化运行次数,即跟踪记录中的 nrulft;One_Pass_Mem 为一次传递模式所需内存大小,即跟踪记录中的 1pass。
此时,由于计算出的一次传递模式所需内存大小超出了系统最大值(“_smm_max_size”,
1024k)的限制,因此需要调整读写槽的大小为系统设置的最小值(“_smm_auto_min_io_size”,
56k)后重新计算:

重新计算过程及结果如下:
Input_Left_Szie = 1206k
Runs_Left = (sqrt(Runs_Done^2 + 2Input_Left_Szie/SSize) - Runs_Done)/ 2
= (sqrt(0^2 + 21206/56) - 0)/ 2
= 3.281
≈ 4
One_Pass_Mem = 2*(Runs_Done + Runs_Left)Read_Slot_Size + 22Write_Slot_Size
= 2(0+4)56+22*56
= 672
此时计算的结果未超出限制,因此可以请求为工作区分配 672k 空间,并将内存中已排序数据写入磁盘(即第一初始化运行的结果)。
当工作区再次被输入数据占满时,要重新计算所需内存大小:

至此,已经完成排序的数据大小(kbs)为 1054k,新估计的排序数据大小为 1468k,因此缓存模式下对新进入排序区的数据排序所需内存(cache)为 1468-1054=414k,也即剩余的排序数据大小。而已经完成的初始化次数(nru)为 1,当前的读写槽(S)为 56k,因此剩余的排序次数和一次传递模式所需内存大小为:
Runs_Left = (sqrt(Runs_Done^2 + 2Input_Left_Szie/SSize) - Runs_Done)/ 2
= (sqrt(1^2 + 2414/56) - 1)/ 2
= 1.549
≈ 2
One_Pass_Mem = 2*(Runs_Done + Runs_Left)Read_Slot_Size + 22Write_Slot_Size
= 2(1+2)56+22*56
= 560
按照这种方式调整工作区大小,直到所有输入数据被处理完成:

然后进入了合并阶段。

进入该阶段后,读槽大小被重新调整为最大(S=253952,即 248k),写槽大小不变(rsz=248
wsz=56)。此时已无剩余输入数据,因此剩余初始化运行次数无需再计算(nrulft),为 0。总共完成了 16 次初始化运行。而该阶段,一次传递模式所需内存大小的计算调整为:
One_Pass_Mem = 2*(Runs_Done)Read_Slot_Size
= 216*248
= 7936
计算出的结果超出了系统限制(1024k),因此,需要调整读槽大小为系统最小值(56k)再重新计算:

调整后的计算结果为:21656=1792,仍然大小系统限制。但因为读槽已经为最小值,因此不再重新计算,而是采用了系统限制大小(1024k)为新的工作区大小:

此时,会将收集到的实际运行统计数据,如最终估算输入数据大小(isize)、最终估算输出数据大小(osize)和估算的平均记录长度(rlen),以及据此计算得出的工作区相关数据,如一次传递模式所需内存(mem1Pass)大小、缓存模式所需内存(10017)大小和此次运行中分配的最大工 作区大小(curSize)写入共享内存当中。工作区相关数据计算如下:
memCache = isize1.125
= 89041.125
= 10017
mem1Pass = sqrt(2Input_Real_SizeRead_Slot_Size)+2Write_Slot_NumberWrite_Slot_Size
= sqrt(2890456)+2256
= 998.623 + 224
= 1222.623
≈ 1222
memMin = 2Min_Read_Slot_NumberRead_Slot_Size+2Write_Slot_NumberWrite_Slot_Size
= 2256+2256
= 448
执行至此,10032 事件记录下了目前的工作区参数设置:

sort_area_size 即为最终分配的工作区大小(1024k);sort_multiblock_read_count 由读槽大小除以数据块大小计算所得每次直接读临时文件的数据块数;max intermediate merge width 为中间合并(除最终一次合并外的所有合并)的最大宽度;此外,还有一个数值————最终合并(该次合 并的结果无需在写入磁盘,直接输出客户端或作为其父操作的数据源)的最大宽度(max final merge width)也会影响后续的合并过程。这些数值的计算方式如下:
sort_multiblock_read_count = Read_Slot_Size/Blksize
= 56/8
= 7
max intermediate merge width = (sort_area_size/Read_Slot_Size - 2Write_Slot_Number)/2
= (1024/56 - 22)/2
= 7.1428571428571428571428571428571
≈ 7
max final merge width = sort_area_size/Read_Slot_Size/2
= 1024/56/2
= 9.1428571428571428571428571428571
≈ 9
根据上述数据,可以计算出合并次数:以此排序总共产生了 16 次初始化运行(initial runs), 大于最终合并的最大宽度限制,合并次数计算如下:
runs = initial_runs - fin_merge_width = 16 - 9 =7
i = floor(runs/int_merge_width) = floor(7/7) = 1 m = int_merge_widthi = 71 = 7
r = runs - m + i = 7 - 7 + 1 = 1
int_merges = 1 + i = 1 + 1 =2
merges = int_merges + 1 = 2 + 1 =3
中间合并的读槽数为:
Read_Slot_Number = (initial_runs + int_merges - fin_merge_width)/int_merges
= (16+2-9)/2
= 9/2
因此,第一次合并了 4 组数据:


由于数据被重新组织,合并后的数据块数并不一定等于读入的数据块数。合并后的数据集再次成为后续合并的数据源。
每次合并前,仍然需要重新计算工作区大小:

在这里,已经合并了 4 次初始化运行数据集,并产生了一个新的中间运行(intermediate run) 数据集,因此还需合并 16-4+1=13 个数据集。而读槽大小再次被重新调整为最大(248k),因此计算得一次传递模式所需内存大小为:
One_Pass_Mem = 2*(Runs_Done)Read_Slot_Size
= 213*248
= 6448
计算结果超出限制,需调整读槽大小再次计算,过程略。直到最终合并完成

运行统计数据和工作区相关数据被再次更新,并写入内存。我们此时可以通过视图
V$SQL_WORKAREA 查询到这些数据:
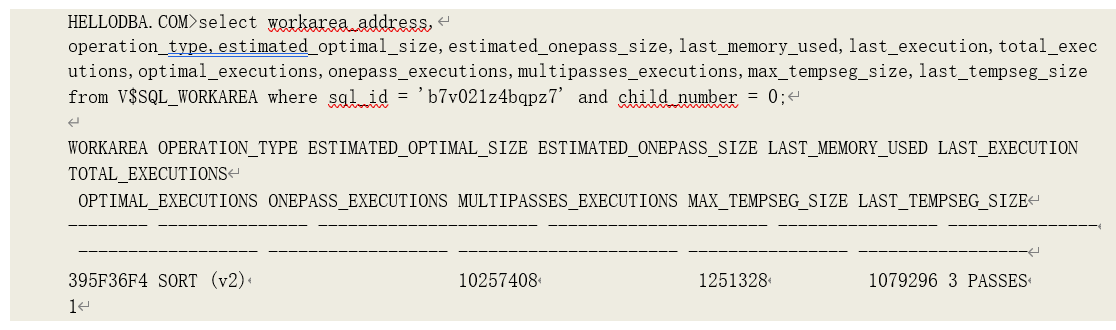
而 10032 事件也会在跟踪记录中记录下相关数据:
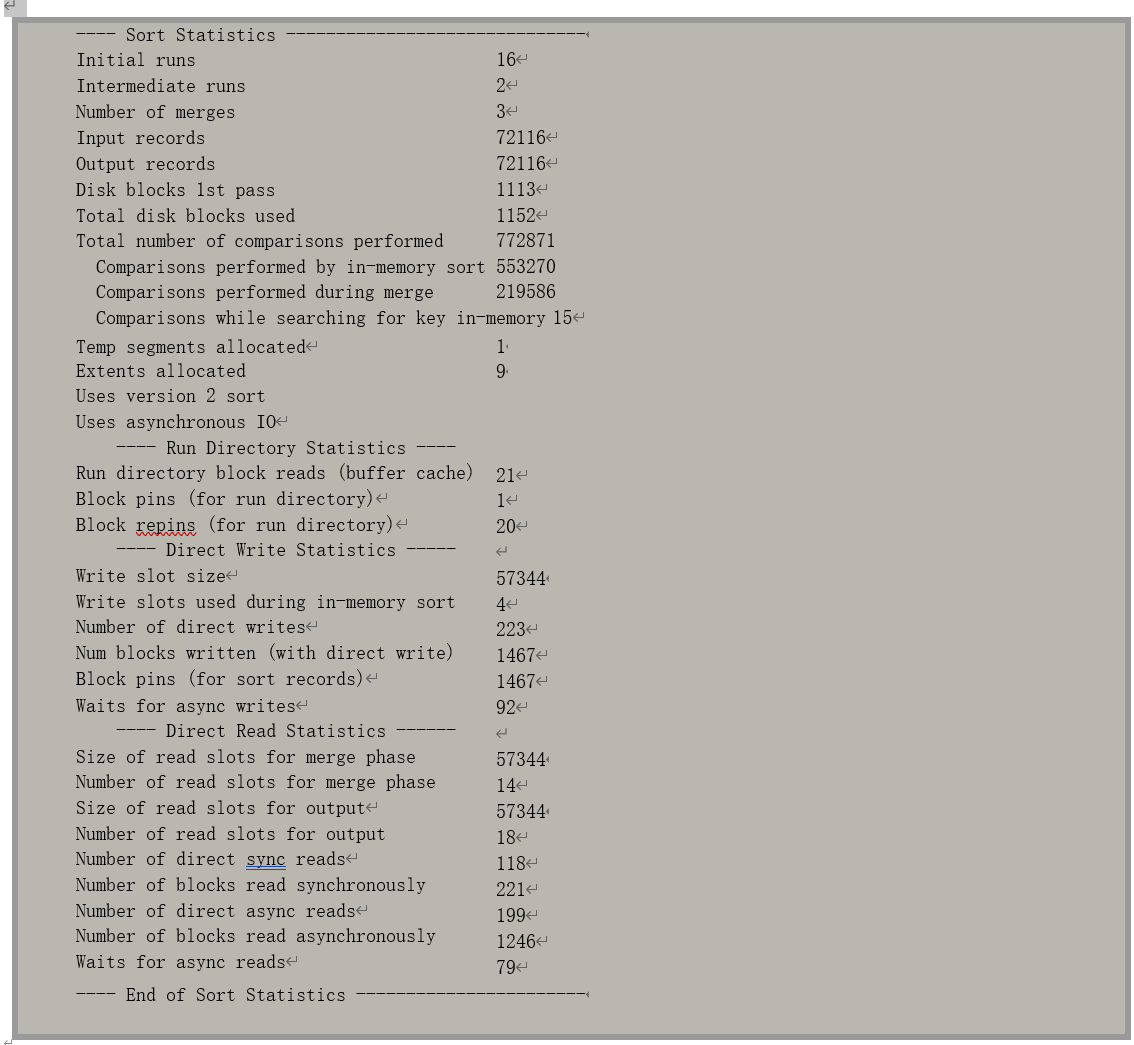
这些数据从名字不难看出代表含义:
• Initial runs:初始化运行次数;
• Intermediate runs:中间运行(合并)次数;
• Number of merges:合并次数;
• Input records:输入记录数;
• Output records:输出记录数;
• Disk blocks 1st pass:第一次传递需要写入磁盘的数据块数,即输出数据大小(osz=8904k) 除以数据块大小,8904/8=1113;
• Total disk blocks used:实际总共使用的临时磁盘数据块数,因为存在重用,并一定会等于读、写数据块数;
• Total number of comparisons performed:数据比较次数;
• Temp segments allocated:分配的临时段数;
• Extents allocated:分配的扩展段数;
• Uses version 2 sort:采用的排序算法;
• Uses asynchronous IO:使用了异步 IO;
• Run Directory Statistics:运行目录统计数据。运行目录数据块是用于存储和修改工作区统计数据的临时数据块,也即排序数据块(Sort Block),由于这些统计数据是系统共享的,因此相应数据块需要以当前模式读入缓存,因而产生相应的逻辑读(db block gets);
• Write slot size:写槽大小;
• Write slots used during in-memory sort :排序过程中使用的写槽数;
• Number of direct writes:写的次数,与写入临时磁盘的数据块数和写槽大小相关,但每次写的数据大小并不一定等于写槽大小;
• Num blocks written (with direct write):总共写入临时磁盘的数据块数,这里与运行统计数据中的物理写(Physical Writes)一致;
• Waits for async writes:异步写导致的等待次数;
• Size of read slots for merge phase:合并阶段(即中间合并)的读槽大小;
• Number of read slots for merge phase:合并阶段(即中间合并)的读槽数量;
• Size of read slots for output:用于输出(即最终合并)的读槽大小;
• Number of read slots for output:用于输出(即最终合并)的读槽数量;
• Number of direct sync reads:直接同步读的次数;
• Number of blocks read synchronously:直接同步读的数据块数;
• Number of direct async reads:直接异步读的次数;
• Number of blocks read asynchronously:直接异步读的数据块数;直接同步读的数据块数加上直接异步读的数据块数(221+1246=1467)即为物理直接读取临时磁盘的数据块数,和统 计数据(physical reads direct temporary tablespace)中一致;
• Waits for async reads:异步读导致的等待次数;
提示:读写磁盘的统计过程可以设置 10046 事件的级别为 8 进行跟踪。
最后,释放资源,关闭游标。

通过这一过程分析,我们可以知道:Oracle 采用了这一新的工作区管理方法后,可以使得每次排序操作(或其他需要工作区的操作)在运行过程中,根据实际数据临时调整分配内存大小,使得最终占用的内存与每次运行的实际数据大小相符(按照 Oracle 的估计,这种管理方法下,最多分配的工作区大小为理想状态下所需大小的 1.7 倍)。在提高了 PGA 的利用率的同时,还能最大限度的提高相关操作的性能。
