




前沿
读完这篇文章,你可以知道
为什么自动混合精度(Automatic Mixed Precision)可以帮助你减少神经网络的GPU内存占用
什么场景使用Automatic Mixed Precision(AMP )
如何在Pytorch和Horovod中使用混合精度
使用场景
首先如果使用AMP推荐使用Volta结构的GPU,配合Tensorcore使用(目前只有V100,A100,和TITAN V支持Tensorcore),非Volta结构的GPU如P100在特定网络上也可以获得AMP的增益(Apex #issue 76)。(N家就是卖卡卖卡
其次在小batch场景下混合精度并不能带来速度提升,甚至会更慢。因为小batch下的计算已经很快了,速度瓶颈在CPU和GPU间传送数据,而混合精度需要进行FP16与FP32的转换,会消耗更多时间。
历史背景
目前Pytorch比较流行的混合精度工具是Baidu和NVIDIA合作的Apex,不过Pytorch从1.6开始已经内置了AMP模块。
目前Pytorch的AMP有两种版本:pytorch1.5之前使用的NVIDIA的第三方包apex.amp,在pytorch 1.6以后自带了torch.cuda.amp
自动混合精度介绍
1. 简述
简单来说,自动混合精度(Auto Mixed Precision,AMP)是一种在模型训练中同时使用16位浮点数和32位浮点数的技术,它使用FP16,即半精度浮点数存储weights和gradients,从而达到减少GPU内存占用的目的,同时也起到加速模型训练的效果。
除了混合精度外,也看到采用时间换空间的方案来节省显存,比如DTR和Sublinear。旷世的MegEngine采用DTR(Dynamic Tensor Recomputation)方式来减少显存占用。DTR采用时间换空间的方式,来减少动态图训练中的显存占用。其在forward时,清除一部分计算结果,在backward从后计算梯度时再根据checkpoint去重新即时计算需要用到的forward结果。
自动混合精度的优点和缺点:
优点:
减少显存占用
加快训练和推断的计算,能带来多一倍速的体验
缺点:
溢出错误 (Overflow and underflow)
舍入误差
2. FP32和FP16
首先简单介绍下FP32,FP16,溢出错误和舍入错误。
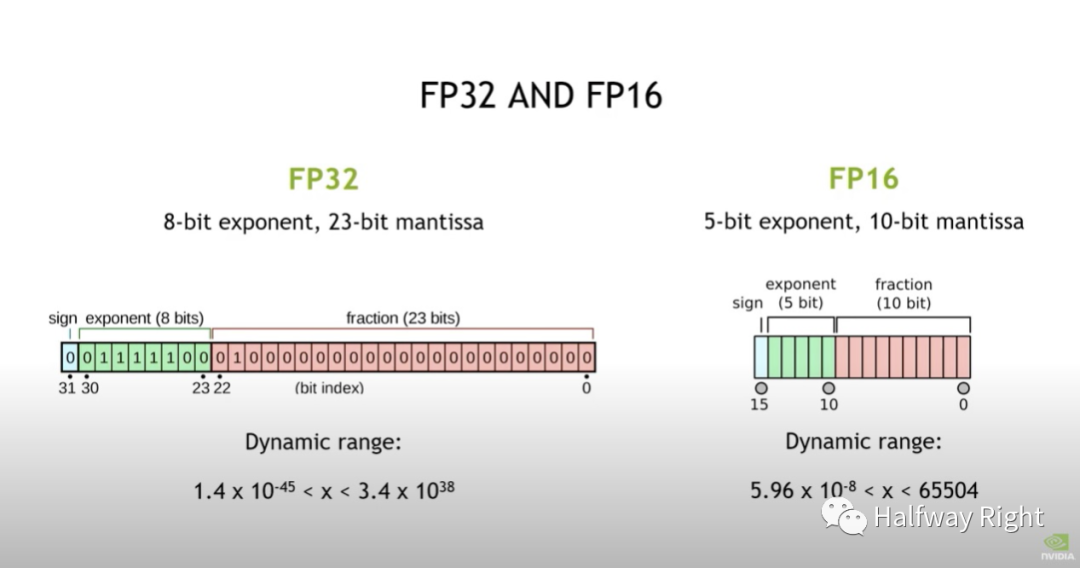
FP32:FP32有更广的数值表示范围(精度大),如图所示FP32有1个bit的符号位,8个exponent位置,23个fraction位置。
FP16:相比之下FP16的数值表示范围较窄(精度小),只有5个exponent位置和10个fraction位置,数值的有效表示范围是-65504到66504,精度相对小了很多,但是可以减少一半的存储空间。
关于符号位,exponent位,fraction位是做什么的,包括如何计算得到这个表示范围的可以维基百科搜下
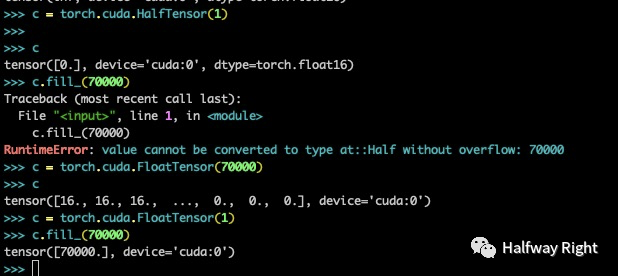
如下图所示,FP16无法表示70000 (因为大于66504)
3. underflow/overflow error
在实际数值计算中,由于计算机计算精度和存储有限,会有溢出误差和舍入误差两种误差。
溢出错误(underflow/overflow error):
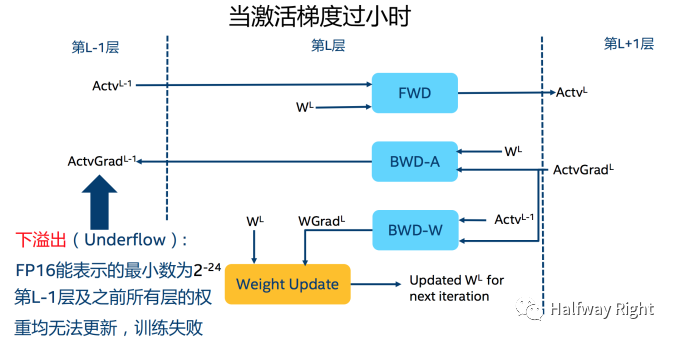
由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出(overflow,就是比数据类型的数值表示范围更大的数)和下溢出(underflow,就是比数据类型的数值表示范围更小的数),溢出之后训练就会出现"NaN"的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况,可以参考reference论文中的实验数据。
4. round-off error
舍入误差(round-off error)指的计算机运算得到的近似值和数学理论精确值之间的差异。在深度学习训练中,如果weights和gradient的计算小于当前区间内的最小间隔时,该次梯度更新可能会失败。

5. AMP的原理
从FP16的范围可以看出,用FP16代替原FP32神经网络计算的最大问题就是精度损失。
为了消除上面两个FP16的问题,自动混合精度使用了以下两种方法:
维护一份weights的FP32拷贝。在FWD和BWD过程中,weights,gradients和activations都使用FP16,这个FP32的weights拷贝是在更新weights的时候使用的,另外loss也是FP32的。(因为accumulation容易产生overflow,影响模型性能)
为啥weights需要这个FP32的copy?
一是,小于-24级别的weight gradient乘以学习率,会变成0,从而影响模型的accuracy。
二是,weight value 相比于 weight update的比例非常大,造成weight update变成0,详细看论文,不是很懂。
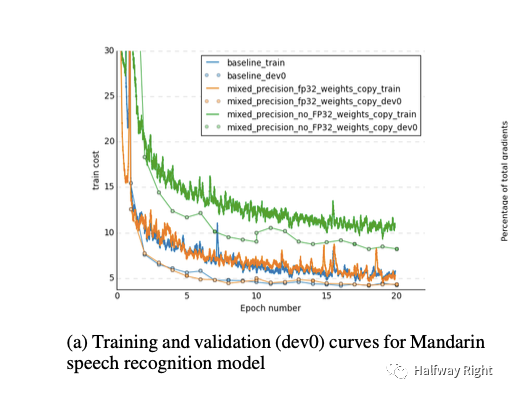
这个图说明了使用这个方法可以达到和用FP32一样的效果,不用的话accuracy loss损失80%。
增加了weights FP32的copy不是增加了内存吗?
虽然保存了weights的FP32 copy增加了一倍存储,但是对总的memory usage影响很小。因为memory usage主要消耗在activation上(activation of each layer会被存储下来用于back propagation pass)。现在activation是FP16,所以整体memory consumption是一半。
loss scaling (损失函数放大)
得到FP32的loss后,放大并保存为FP16格式,进行反向传播,更新时转为FP32缩放回来。下图可以看到,很多激活值比较小,无法用FP16表示。因此在前向传播后对loss进行扩大(固定值或动态值),这样在反响传播时所有的值也都扩大了相同的倍数,这样可以把那些数值小的loss向右shift(变大)。最后在更新FP32的权重之前又unscale回去。
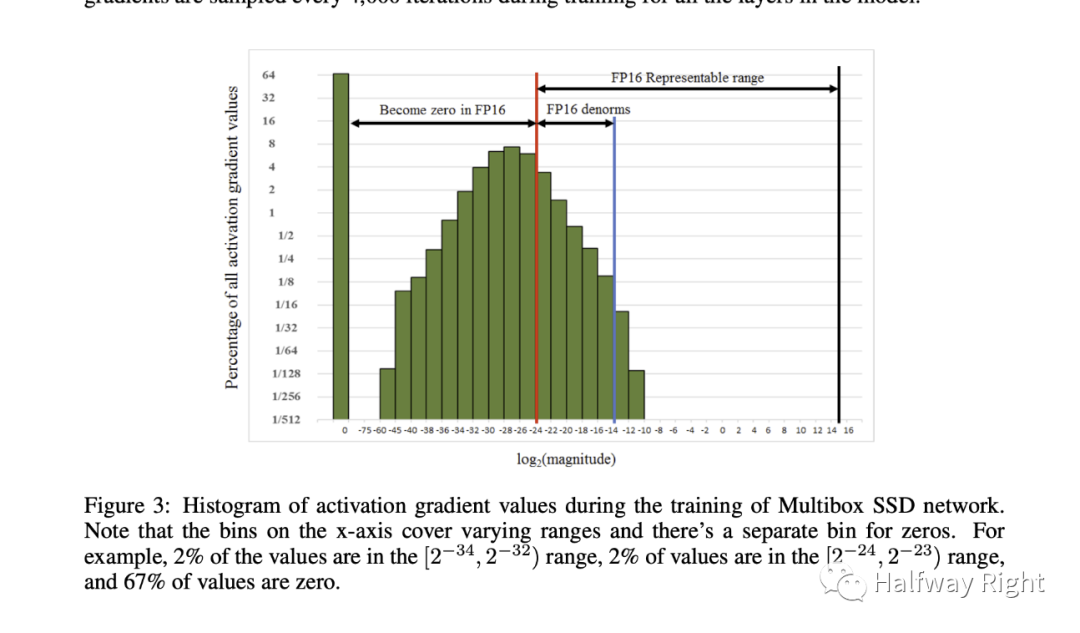
如果不使用loss scale,可以看到黄色那个曲线,activation gradients都很小,做了乘法运算以后underflow,造成loss发散。

Arithmetic Precision (算数运算精度)
大型神经网络的算数运算主要是vector dot-product, reduction和point-wise operation这三类,如果我们在这上面做FP16的算数运算优化,可以减少GPU中的内存占用。
对于vector dot-product运算,经过实验,我们发现将FP16的矩阵相乘后和FP32的矩阵进行加法运算(理解就是FP16 dot-product结果转成FP32),写入内存时再转回FP16可以获得和单精度运算同样的accuracy。所以Tensorcore加持的GPU在Arithmetic opertation层面通过这个优化点减少了内存占用和加快了计算速度。
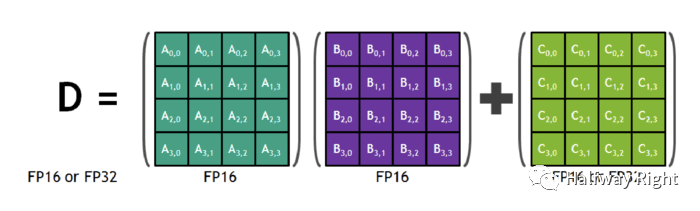
对于large reduction的计算应该使用FP32。这个操作往往发生在batch normalization layer (累加统计量)和softmax layer。这个阶段,AMP从内存中读写FP16的数值,进行FP32位的reduction操作。这个内存读写操作不会减缓训练过程,因为这些layer是受限于memory-bandwidth而不是算数运算。
对于point-wise operation运算,比如非线性(non-linearities)和element-wise矩阵乘法,这些也是memory bandwidth limited,不受FP16或者FP32的影响,所以FP16和FP32都可以使用。
参数 | 精度 | 作用 | 是否有FP32 copy | 原因 |
weights | FP16 | 在FWD和BWD的时候使用,节省了一半storage和bandwidth | 是 | 在optimizer那一步会用到更新weight gradient上,防止accumulation overflow。 |
activation | FP16 | 同上 | 否 | / |
gradients | FP16 | 同上 | 否 | / |
自动混合精度的实现
单机下的AMP实现
python 1.6及以上版本主要使用两个接口: autocast和gradscaler
from torch.cuda.amp import autocast as autocast
model=Net().cuda()
optimizer=optim.SGD(model.parameters(),...)
scaler = GradScaler() #训练前实例化一个GradScaler对象
for epoch in epochs:
for input,target in data:
optimizer.zero_grad()
with autocast(): #前后开启autocast
output=model(input)
loss = loss_fn(output,targt)
scaler.scale(loss).backward() #为了梯度放大
#scaler.step() 首先把梯度值unscale回来,如果梯度值不是inf或NaN,则调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新。
scaler.step(optimizer)
scaler.update() #准备着,看是否要增大scaler可以使用autocast的context managers语义(如上),也可以使用decorators语义。当进入autocast上下文后,在这之后的cuda ops会把tensor的数据类型转换为半精度浮点型,从而在不损失训练精度的情况下加快运算。而不需要手动调用.half(),框架会自动完成转换。不过,autocast上下文只能包含网络的前向过程(包括loss的计算),不能包含反向传播,因为BP的op会使用和前向op相同的类型。
参考:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html#introduction
分布式下的AMP实现
在分布式环境下这样使用with autocast()这个上下文管理器会失效,因为autocast是使用的local thread,而分布式环境下,backend会spawn不同的线程在不同的设备上运行FWD,所以需要使用autocast decorator装饰model的forward函数或者在forward里使用autocast。
MyModel(nn.Module):
@autocast()
def forward(self, input):
...
# 或者如下
MyModel(nn.Module):
def forward(self, input):
with autocast():
...参考:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html#introduction
Horovod的Mixed Precision
此外,Horovod也内置了compression algorithm,在ring allreduce期间会将梯度从FP32 compress到FP16,从而减少网络带宽。
运算过程:
计算某个worker上的gradient
compress每个worker上的gradient (在sum之前divide the gradient by the number of workers 解决overflow的问题)
做allreduce操作,并且average所有worker上的梯度。
decompress所有allreduced gradients.
更新参数。
作用:
主要减少allreduce了过程中的network utilization
减少 arithmetic computation on GPU
实现:
DistributedOptimizer(compression=hvd.Compression.fp16,...)此外之前Horovod-Pytorch简介那篇文章里的那个bus error目前解决了,其实是Docker容器内存过小造成的,通过加大容器内存可以解决。
reference:
Horovod Gradient Compression #2025 (https://github.com/horovod/horovod/issues/2025)
Add support for gradient_predivide_factor and averaging in Horovod backend. #1949(https://github.com/horovod/horovod/pull/1949)
Optionally average gradients before allreduce #1699(https://github.com/horovod/horovod/issues/1699)
实验记录
bath_size: 256
Dataset: MNIST
model: resnet18
GPU: P100
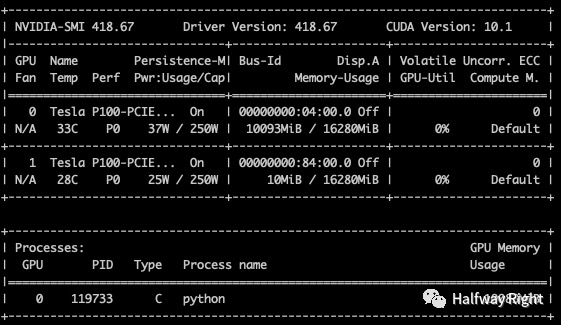
未使用AMP
GPU使用9.85GB,训练耗时:234s (3.9 min)
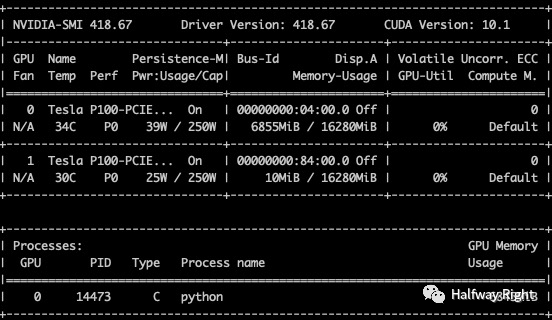
使用AMP
GPU使用6.68GB,训练耗时: 287s (4.8min)
总结:
在P100上的实验大概减少约30% GPU显存,多增加20%时间。V100上的实验还没跑,后续再做详细的性能测试。
Reference
MIXED PRECISION TRAINING: https://arxiv.org/pdf/1710.03740.pdf
https://pytorch.org/docs/stable/notes/amp_examples.html#amp-examples
https://www.youtube.com/watch?v=b5dAmcBKxHg
封面图片:Ciao, Salut
