




上次我们讨论了数据的一致性,从用户的角度分析了事务隔离级别之间的差异,并指出了了解这些的重要性。现在我们开始探索PostgreSQL如何实现快照隔离和多版本并发。
在本文中,我们将了解数据是如何在文件和页面中进行物理布局的。这使我们脱离了孤立的讨论,但这样的离题对于理解接下来的内容是必要的。我们需要弄清楚数据在底层存储是如何组织的。
1. Relations
如果你查看表和索引的内部,可以发现它们是以类似的方式组织的。两者都是数据库对象,其中包含一些由行组成的数据。
毫无疑问,表是由行组成的,但是对于索引来说,这不太明显。但是,想象一下B树:它由包含索引值和对其他节点或表行的引用的节点组成。可以将这些节点视为索引行,实际上,它们就是索引行。
实际上,还有一些其他对象以类似的方式组织:序列(本质上是单行表)和物化视图(本质上是记住查询的表)。还有常规视图,它们本身不存储数据,但在所有其他意义上都类似于表。
PostgreSQL中的所有这些对象称为Relation。这个词非常不恰当,因为它是关系理论中的术语。你可以在Relation和表(视图)之间绘制相似之处,但是当然不能在Relation和索引之间绘制相似之处。但这恰好发生了:PostgreSQL的学术渊源得以体现。在我看来,首先调用的是表和视图,其余的随着时间的推移而膨胀。
为简单起见,我们将进一步讨论表和索引,但是其他关系的组织方式完全相同。
2. Forks 和 文件
通常,每个Relation对应几个forks。fork可以有几种类型,每种类型都包含特定类型的数据。
如果有一个fork,它首先由唯一的文件表示。文件名是一个数字标识符,可以附加与fork名称对应的结尾。
文件逐渐增长,当其大小达到1 GB时,将创建一个相同fork的新文件(此类文件有时称为段)。段的序号附加在文件名的末尾。
文件大小的1 GB限制在历史上是为了支持不同的文件系统而产生的,其中一些文件系统无法处理较大的文件。您可以在编译PostgreSQL(./configure--with segsize
)时更改此限制。
因此,磁盘上的多个文件可以对应一个Relation。例如,对于一张小表,将有三个文件。
属于一个表空间和一个数据库的所有对象文件将存储在一个目录中。您需要记住这一点,因为文件系统通常无法很好地处理目录中的大量文件。
请注意,文件依次被划分为pages(或blocks),通常按8KB划分。我们将进一步讨论pages的内部结构。
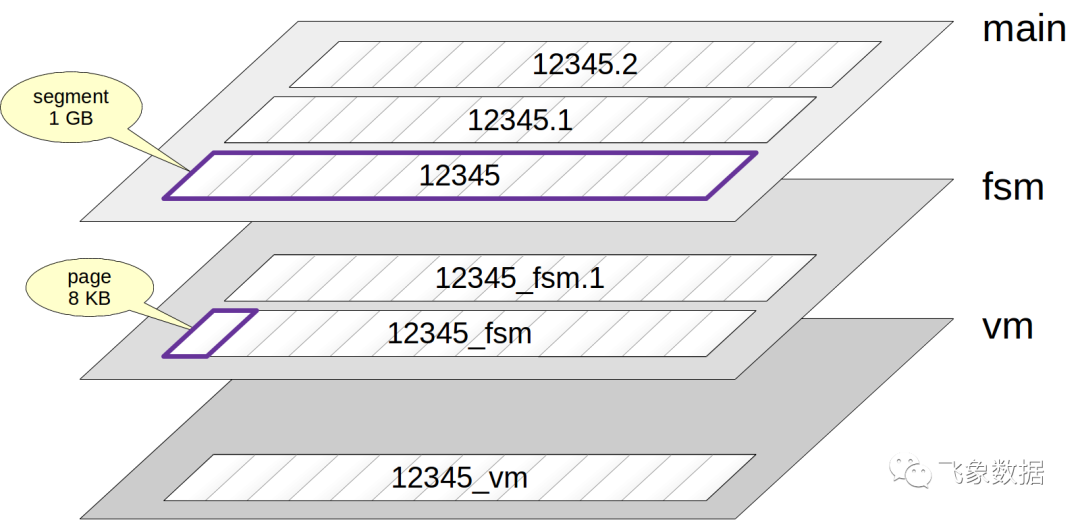
现在让我们看看fork的类型。
main fork是数据本身:就是表和索引行。main fork可用于任何关系(不包含数据的视图除外)。
main fork的文件名由唯一的数字标识符组成。例如,这是我们上次创建的表的路径:
=> SELECT pg_relation_filepath('accounts');pg_relation_filepath----------------------base/41493/41496(1 row)复制
这些标识符来自哪里?目录«base»对应于«pg_default»表空间。后面子目录,对应于数据库,和文件的位置:
=> SELECT oid FROM pg_database WHERE datname = 'test';oid-------41493(1 row)=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';relfilenode-------------41496(1 row)复制
路径是相对的,从数据目录(PGDATA)开始指定。此外,PostgreSQL中的几乎所有路径都是从PGDATA开始指定的。有鉴于此,您可以安全地将PGDATA移动到不同的位置—没有任何限制(除了可能需要在LD_LIBRARY_PATH中设置库的路径)。
查看文件系统:
postgres$ ls -l --time-style=+ var/lib/postgresql/11/main/base/41493/41496-rw------- 1 postgres postgres 8192 var/lib/postgresql/11/main/base/41493/41496复制
initialization fork仅对未记录日志的表(使用指定的UNLOGGED创建)及其索引可用。像这样的对象与常规对象没有任何不同,只是它们的操作不记录预写日志。因此,使用它们的速度更快,但在发生故障时无法以一致状态恢复数据。因此,在恢复过程中,PostgreSQL只需删除这些对象的所有fork,并写入initialization fork来代替main fork。这将导致一个空对象。
“accounts”表是记录预写日志的表,因此它没有initialization fork。但是为了试验,我们可以设置UNLOGGED:
=> ALTER TABLE accounts SET UNLOGGED;=> SELECT pg_relation_filepath('accounts');pg_relation_filepath----------------------base/41493/41507(1 row)复制
这个示例说明动态打开和关闭日志的可能性与将数据重写为不同名称的文件有关。
initialization fork与main fork名称相同,但后缀为“_init”:
postgres$ ls -l --time-style=+ var/lib/postgresql/11/main/base/41493/41507_init-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init复制
free space map(fsm)是一个fork,用于跟踪页面内部空闲空间的可用性。这个空间在不断变化:当添加新版本的行时,它会减少,而在vacuuming时,它会增加。在插入新版本行的过程中使用fsm,可以快速找到合适的页面,以便添加数据。
fsm的名称具有“_fsm”后缀。但该文件不会立即出现,而是在需要时才出现。要做到这一点,最简单的方法是vacuum 表(到时候我们会解释原因):
=> VACUUM accounts;postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm复制
visibility map(vm)是一个fork,其中仅包含最新行版本的page,用一个bit标记。粗略地说,这意味着当事务尝试从这样的page读取一行时,可以在不检查其可见性的情况下显示该行。在下一篇文章中,我们将详细讨论这是如何发生的。
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm复制
3. Pages
如前面所述,文件在逻辑上划分为多个pages。
page大小通常为8 KB。大小可以在某些限制内更改(16 KB或32 KB),但只能在编译过程中更改(./configure--with blocksize
)。编译完成并运行的实例只能处理相同大小的页面(16 KB或32 KB)。
无论文件属于哪个fork,服务器都以非常相似的方式使用它们。Pages 首先被读入缓冲区缓存,在那里进程可以读取和更改Pages;然后,根据需要,将它们刷回磁盘。
每个page 都有内部分区,通常包含以下分区:
0 +-----------------------------------+| header |24 +-----------------------------------+| array of pointers to row versions |lower +-----------------------------------+| free space |upper +-----------------------------------+| row versions |special +-----------------------------------+| special space |pagesize +-----------------------------------+复制
您可以使用pageinspect扩展pageinspect轻松了解这些分区的大小:
=> CREATE EXTENSION pageinspect;=> SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));lower | upper | special | pagesize-------+-------+---------+----------40 | 8016 | 8192 | 8192(1 row)复制
表中的第一个page(0)里的header。除了其他区域的大小之外,header还具有关于page的不同信息,但我们对此不感兴趣。
页面底部有special space,在这种情况下为空白。它仅用于索引,甚至不用于所有索引。«At the bottom»反映了图片中的内容;说«in high addresses»可能更准确。
在special space之后,将找到row versions,即我们存储在表中的数据以及一些内部信息。
page顶部,紧随header之后:指向page中可用行版本的指针数组(array of pointers to row versions)。
行版本和指针之间可以留有Free space(此可用空间在可用空间映射中保持跟踪)。请注意,page内没有内存碎片-所有可用空间都由一个连续区域表示。
3.1 指针
为什么需要指向行版本的指针?问题是索引行必须以某种方式引用表中的行版本。很明显,引用必须包含文件编号、文件中的page以及行版本的一些指示。我们可以使用从page开始的偏移量作为指示器,但这很不方便。我们将无法在page内移动行版本,因为它会破坏可用的引用。这将导致页面内部空间的碎片化和其他麻烦的后果。因此,索引引用指针编号,指针引用page中行版本的当前位置。这是间接寻址。
每个指针正好占用四个字节,并包含:
对行版本的引用
此行版本的大小
确定行版本状态的几个字节
3.2 数据格式
磁盘上的数据格式与缓存中的数据表现完全相同。page“按原样”读入缓冲区缓存,无需进行任何转换。因此,来自一个平台的数据文件与其他平台不兼容。
例如,在X86体系结构中,字节顺序是从最低有效字节到最高有效字节(little-endian),z/Architecture 使用逆序(big-endian),而在ARM中,可以交换顺序。
许多体系结构提供了机器字边界上的数据对齐。例如,在32位x86系统上,整数(类型“integer”,占用4字节)将在4字节字的边界上对齐,方式与双精度数字(类型“double precision”,占用8字节)相同。在64位系统上,双精度数字将在8字节字的边界上对齐。这是另一个不兼容的原因。
由于对齐,表行的大小取决于字段顺序。通常,这种影响不是很明显,但有时可能会导致大小的显着增长。例如,如果对类型为“ char(1)”和“ integer”的字段进行交叉,则通常浪费它们之间的3个字节。有关更多详细信息,请查看Nikolay Shaplov的演示文稿“ Tuple internals”。
4. 行版本 和 TOAST
下次我们将讨论行版本的内部结构细节。此时,我们只需要知道每个版本必须完全放入一个page:PostgreSQL无法将行“扩展”到下一个page。而是改为使用超大属性存储技术(TOAST)。名称本身暗示可以将一行切成多个片。
TOAST暗示了几种策略。在将长属性值分解成小的toast chunks之后,我们可以将它们传递到单独的内部表中。另一种选择是压缩值,以使行版本适合常规page。我们可以同时做这两个事情:首先压缩,然后分解并传输。
对于每个主表,如果需要,可以创建一个单独的TOAST表,一个用于所有属性(以及其上的索引)。潜在长属性也决定了这一需求。例如,如果一个表有一个类型为“numeric”或“text”的列,即使不使用长值,也会立即创建TOAST表。
由于TOAST表本质上是一个常规表,因此它具有相同的forks。这会使对应于表的文件数量增加一倍。
初始策略由列数据类型定义。可以使用psql中的\d+
命令查看它们,但是由于它还会输出很多其他信息,因此我们将查询系统目录:
=> SELECT attname, atttypid::regtype, CASE attstorageWHEN 'p' THEN 'plain'WHEN 'e' THEN 'external'WHEN 'm' THEN 'main'WHEN 'x' THEN 'extended'END AS storageFROM pg_attributeWHERE attrelid = 'accounts'::regclass AND attnum > 0;attname | atttypid | storage---------+----------+----------id | integer | plainnumber | text | extendedclient | text | extendedamount | numeric | main(4 rows)复制
这些策略的名称表示:
plain — TOAST未使用(用于已知为短数据类型,例如«integer»)
extended — 压缩和存储都可以在单独的TOAST表中进行
external — 长值不压缩就存储在TOAST表中。
main — 长值首先被压缩,并且如果压缩无济于事,则进入TOAST表。
一般来说,算法如下所示。PostgreSQL的目标是让一个page至少有四行。因此,如果行大小超过页面的四分之一,则需要考虑header(常规8K页面为2040字节),TOAST必须应用于部分值。我们遵循下面描述的顺序,并在行不超过阈值时立即停止:
首先,我们使用“external”和“extended”策略从最长的属性到最短的属性进行检查。“Extended”属性被压缩(如果有效),如果值本身超过page的四分之一,它将立即进入TOAST表。“External”属性的处理方式相同,但不会压缩。
如果在第一次传递之后,行版本还不适合page,我们将使用“external”和“extended”策略将其余属性传输到TOAST表。
如果这也没有帮助,我们尝试使用“main”策略压缩属性,但将它们保留在表page中。
只有在该行不够短的情况下,“main”属性才能进入TOAST表。
有时,更改某些列的策略可能很有用。例如,如果事先知道无法压缩列中的数据,则可以为其设置“external”策略,这样可以避免不必要的压缩尝试,从而节省时间。这样做如下:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;复制
重新运行查询,我们得到:
attname | atttypid | storage---------+----------+----------id | integer | plainnumber | text | externalclient | text | extendedamount | numeric | main复制
TOAST表和索引位于单独的pg_toast模式中,因此通常不可见。对于临时表,"pg_toast_tempN"模式的使用类似于通常的"pg_tempN"。
当然,如果你喜欢,没有人会阻止你侦查这个过程的内部机制。假设,在"accounts"表中有三个可能很长的属性,因此,必须有一个TOAST表。这里是:
=> SELECT relnamespace::regnamespace, relnameFROM pg_class WHERE oid = (SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts');relnamespace | relname--------------+----------------pg_toast | pg_toast_33953(1 row)=> \d+ pg_toast.pg_toast_33953TOAST table "pg_toast.pg_toast_33953"Column | Type | Storage------------+---------+---------chunk_id | oid | plainchunk_seq | integer | plainchunk_data | bytea | plain复制
将“plain”策略应用于切成toasts 是合理的:没有第二级的toasts 。
PostgreSQL更好地隐藏索引,但是也不难找到:
=> SELECT indexrelid::regclass FROM pg_indexWHERE indrelid = (SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953');indexrelid-------------------------------pg_toast.pg_toast_33953_index(1 row)=> \d pg_toast.pg_toast_33953_indexUnlogged index "pg_toast.pg_toast_33953_index"Column | Type | Key? | Definition-----------+---------+------+------------chunk_id | oid | yes | chunk_idchunk_seq | integer | yes | chunk_seqprimary key, btree, for table "pg_toast.pg_toast_33953"复制
"client"列使用"extended"策略:它的值将被压缩。让我们检查:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1;=> SELECT * FROM pg_toast.pg_toast_33953;chunk_id | chunk_seq | chunk_data----------+-----------+------------(0 rows)复制
在TOAST表中什么也没有:重复字符被压缩得很好,压缩后的值适合通常的表页。
现在让客户端名称由随机字符组成:
=> UPDATE accounts SET client = (SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000))WHERE id = 1RETURNING left(client,10) || '...' || right(client,10);?column?-------------------------TCKGKZZSLI...RHQIOLWRRX(1 row)复制
这样的序列不能被压缩,它进入到TOAST表:
=> SELECT chunk_id,chunk_seq,length(chunk_data),left(encode(chunk_data,'escape')::text, 10) ||'...' ||right(encode(chunk_data,'escape')::text, 10)FROM pg_toast.pg_toast_33953;chunk_id | chunk_seq | length | ?column?----------+-----------+--------+-------------------------34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX(2 rows)复制
我们可以看到数据被分解为2000字节的chunks。
当访问长值时,PostgreSQL会为应用程序自动透明地恢复原始值并将其返回给客户端。
当然,压缩和分解然后再还原非常耗费资源。因此,将大量数据存储在PostgreSQL中并不是最好的主意,特别是如果它们经常使用且使用情况不需要事务逻辑(例如:原始会计凭证的扫描)时尤其如此。一个更有益的替代方法是使用文件名存储在DBMS中的文件系统上存储此类数据。
TOAST表仅用于访问长值。此外,TOAST表支持它自己的多版本转换并发:除非数据更新达到一个长值,否则新的行版本将引用TOAST表中的相同值,从而节省了空间。
请注意,TOAST仅适用于表,不适用于索引。这对要索引的键的大小施加了限制。
