




在讨论了隔离问题并对低级数据结构进行了论述之后,上次探索行版本并观察了不同的操作如何改变元组标头字段。
现在,将研究如何从元组中获取一致的数据快照。
什么是数据快照?
数据页实际上可以包含同一行的多个版本。但是每个事务只能看到每一行的一个(或没有)版本,以便它们在特定时间点上构成数据的一致图(按ACID表示)。
PostgreSQL的隔离级别基于快照:每个事务都使用其自己的数据快照,该快照“包含”在创建快照之前提交的数据,并且不“包含”在该时刻尚未提交的数据。我们从这里:链接已经看到了,尽管最终的隔离看起来比标准要求的严格,但仍然存在异常。
在“读取已提交”隔离级别中,将在每个事务语句的开头创建一个快照。在执行语句时,此快照处于活动状态。在图中,快照创建的时刻(它由事务ID决定)以蓝色显示。
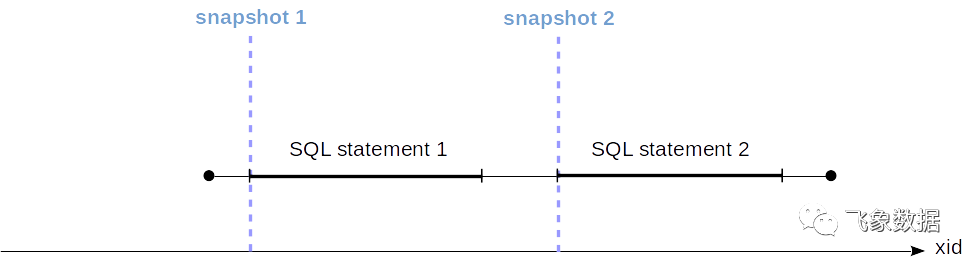
在“可重复读取”和“可序列化”级别上,快照在第一个事务语句的开头创建一次。这样的快照在事务结束之前一直保持活动状态。
快照中元组的可见性
可见性规则
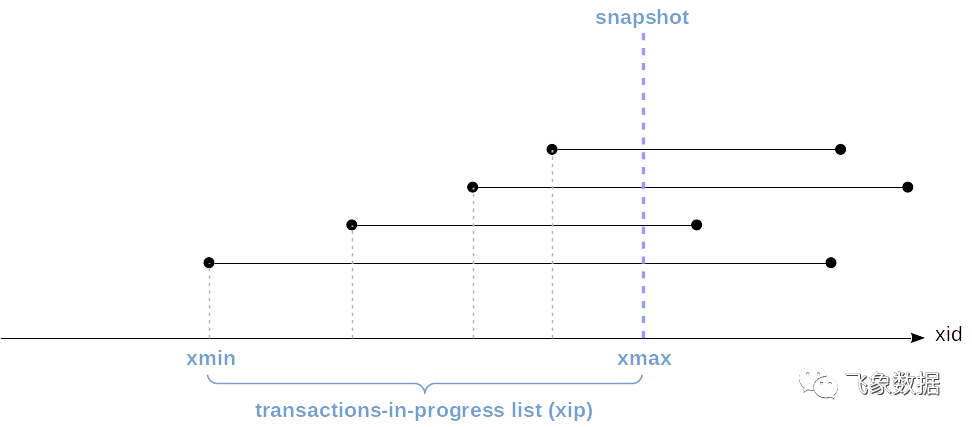
快照不是所有必要元组的物理副本。快照实际上由多个数字指定,并且快照中元组的可见性由规则确定。
元组在快照中是否可见取决于标头中的两个字段,即xmin和xmax,即创建和删除该元组的事务的ID。这样的间隔不会重叠,因此,每个快照中的一行表示一个以上的版本。
确切的可见性规则非常复杂,并考虑了许多不同的情况和极端情况。
您可以通过查看 src/backend/utils/time/tqual.c 轻松确保这一点(在版本 12 中,检查移至 src/backend/access/heap/heapam_visibility.c)
为简化起见,可以说一个元组是可见的,而在快照中,该xmin事务所做的更改是可见的,而该事务所做的更改xmax则不可见(换句话说,已经创建了元组,但是尚不清楚它是否已删除)。
关于事务,无论是创建快照的事务(它确实看到自己尚未提交的更改)还是在快照创建之前就提交了事务,其更改在快照中都是可见的。
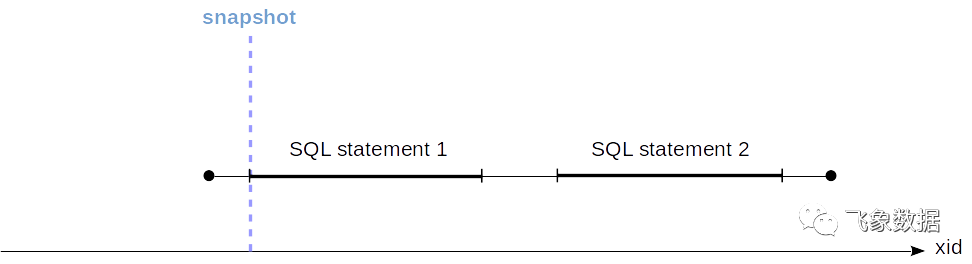
可以按段(从开始时间到提交时间)以图形方式表示事务:

这里:
事务2的更改是可见的,因为它是在创建快照之前完成的。
事务1的更改将不可见,因为它在创建快照时处于活动状态。
事务3的更改是在创建快照之后开始的(无论它是否完成),因此将不可见。
不幸的是,系统没有意识到事务的提交时间。仅知道其开始时间(由事务ID确定并在上图中用虚线标记),但是完成的事件未写入任何地方。
我们所能做的就是在创建快照时找出事务的当前状态。该信息在服务器的共享内存中的ProcArray结构中可用,该结构包含所有活动会话及其事务的列表。
但是将无法确定事后快照创建时某个事务是否处于活动状态。因此,快照必须存储所有当前活动事务的列表。
从上面得出结论,在PostgreSQL中,即使表页面中所有必要的元组都可用,也无法创建快照来显示在特定时间后一致的数据。经常会引起一个问题,为什么PostgreSQL缺乏追溯(或时间;或闪回)查询这就是原因之一。
有趣的是,这个功能最初是可用的,但后来从 DBMS 中删除了。您可以在Joseph M. Hellerstein的文章中了解这一点。
因此,快照由几个参数确定:
创建快照后,更确切地说,是下一个事务的ID,但在系统(snapshot.xmax)中不可用。
创建快照时(snapshot.xip)的活动(进行中)事务列表。
为了方便和优化,还存储了最早的活动事务的ID(snapshot.xmin)。该值具有重要意义,下面将进行讨论。
快照还存储了一些其他参数,但是这些参数对我们来说并不重要。
例子
为了了解快照如何确定可见性,让我们通过三个事务重现上面的示例。该表将具有三行,其中:
第一个是由在快照创建之前开始但在快照创建之后完成的事务添加的。
第二个是通过在快照创建之前开始并完成的事务添加的。
第三个是在创建快照后添加的。
=> TRUNCATE TABLE accounts;
第一个事物(尚未完成):
=> BEGIN;=> INSERT INTO accounts VALUES (1, '1001', 'alice', 1000.00);=> SELECT txid_current();txid_current-----------------3695(1 row)
第二个事物(在创建快照之前完成):
| => BEGIN;| => INSERT INTO accounts VALUES (2, '2001', 'bob', 100.00);| => SELECT txid_current();| txid_current| --------------| 3696| (1 row)| => COMMIT;
在另一个会话的事务中创建快照。
|| => BEGIN ISOLATION LEVEL REPEATABLE READ;|| => SELECT xmin, xmax, * FROM accounts;|| xmin | xmax | id | number | client | amount|| ------+------+----+--------+--------+--------|| 3696 | 0 | 2 | 2001 | bob | 100.00|| (1 row)=> COMMIT;
第三个事物(在创建快照后出现):
| => BEGIN;| => INSERT INTO accounts VALUES (3, '2002', 'bob', 900.00);| => SELECT txid_current();| txid_current| --------------| 3697| (1 row)| => COMMIT;
显然,在我们的快照中仍然仅可见一行:
|| => SELECT xmin, xmax, * FROM accounts;|| xmin | xmax | id | number | client | amount|| ------+------+----+--------+--------+--------|| 3696 | 0 | 2 | 2001 | bob | 100.00|| (1 row)
问题是Postgres如何理解这一点。
全部由快照确定。让我们看一下:
|| => SELECT txid_current_snapshot();|| txid_current_snapshot|| -----------------------|| 3695:3697:3695|| (1 row)
在这里snapshot.xmin,snapshot.xmax和snapshot.xip被列出,并用冒号分隔(snapshot.xip在这种情况下是一个数字,但通常是一个列表)。
根据上述规则,在快照中,那些由具有 ID为xid
的事务所做的更改必须是可见的,比如 snapshot.xmin <= xid < snapshot.xmax,除了那些在snapshot.xip列表上的。让我们看一下所有表行(在新快照中):
=> SELECT xmin, xmax, * FROM accounts ORDER BY id;xmin | xmax | id | number | client | amount------+------+----+--------+--------+---------3695 | 0 | 1 | 1001 | alice | 1000.003696 | 0 | 2 | 2001 | bob | 100.003697 | 0 | 3 | 2002 | bob | 900.00(3 rows)
第一行不可见:它是由活动事务列表(xip)上的事务创建的。
第二行可见:它是由快照范围内的事务创建的。
第三行不可见:它是由快照范围之外的事务创建的。
|| => COMMIT;
事物本身的变化
确定事务本身变更的可见性会使情况复杂化。在这种情况下,可能仅需要查看部分此类更改。例如:在任何隔离级别,在某个时间点打开的游标一定不能看到以后所做的更改。
为此,元组标头具有一个特殊字段(在cmin和cmax伪列中表示),该字段显示事务内部的订单号。cmin是用于插入的数字,cmax用于删除,但为了节省元组头中的空间,实际上是一个字段,而不是两个不同的字段。假定事务很少插入和删除同一行。
但是,如果发生这种情况,一个特殊的组合命令ID( combocid)插在同一字段中,以及后端处理记得实际cmin和cmax本combocid。但这是完全不同的。
这是一个简单的例子。开始一个事务并在表中添加一行:
=> BEGIN;=> SELECT txid_current();txid_current--------------3698(1 row)
INSERT INTO accounts(id, number, client, amount) VALUES (4, 3001, 'charlie', 100.00);
让我们输出表的内容以及cmin字段(但仅适用于事务添加的行,对于其他行则没有意义):
=> SELECT xmin, CASE WHEN xmin = 3698 THEN cmin END cmin, * FROM accounts;xmin | cmin | id | number | client | amount------+------+----+--------+---------+---------3695 | | 1 | 1001 | alice | 1000.003696 | | 2 | 2001 | bob | 100.003697 | | 3 | 2002 | bob | 900.003698 | 0 | 4 | 3001 | charlie | 100.00(4 rows)
现在,我们为查询打开一个游标,该查询返回表中的行数。
=> DECLARE c CURSOR FOR SELECT count(*) FROM accounts;
然后,我们添加另一行:
=> INSERT INTO accounts(id, number, client, amount) VALUES (5, 3002, 'charlie', 200.00);
查询返回4-打开游标后添加的行不会进入数据快照:
=> FETCH c;count-------4(1 row)
为什么?因为快照仅考虑cmin < 1。
=> SELECT xmin, CASE WHEN xmin = 3698 THEN cmin END cmin, * FROM accounts;xmin | cmin | id | number | client | amount------+------+----+--------+---------+---------3695 | | 1 | 1001 | alice | 1000.003696 | | 2 | 2001 | bob | 100.003697 | | 3 | 2002 | bob | 900.003698 | 0 | 4 | 3001 | charlie | 100.003698 | 1 | 5 | 3002 | charlie | 200.00(5 rows)=> ROLLBACK;
事件视界范围
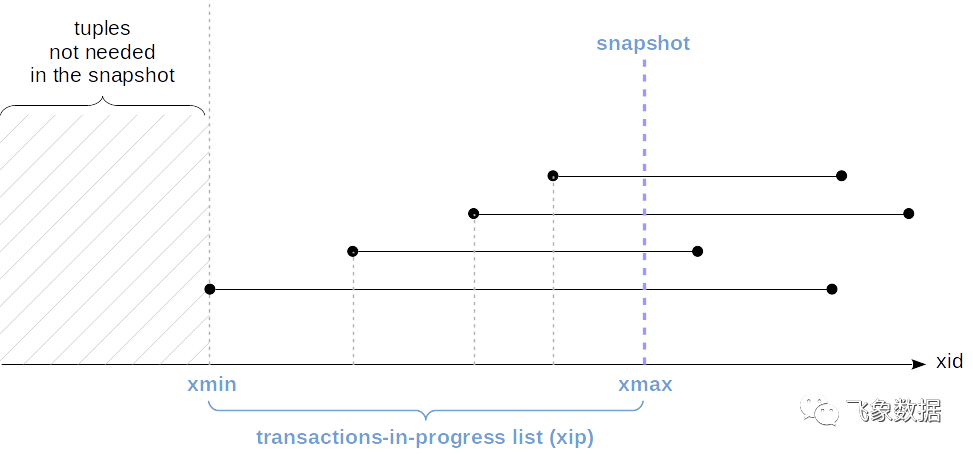
最早的活动事务的ID(snapshot.xmin)具有重要意义:它确定事务的“事件范围”。也就是说,超出其范围,该事务始终只能看到最新的行版本。
实际上,仅当尚未完成的事务创建了最新的(死)行版本时,才需要看到该行版本,因此尚不可见。但是,毫无疑问,所有“超出预期”的事物都已经完成。
您可以在系统目录中看到事务范围:
=> BEGIN;=> SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();backend_xmin--------------3699(1 row)
我们还可以在数据库级别定义范围。为此,我们需要获取所有活动快照并xmin在其中找到最旧的快照。它将定义范围,超过该范围,数据库中的无效元组将对任何事务都不可见。这样的元组可以被清除掉 -这就是为什么从实际的角度来看,视界范围的概念如此重要的原因。
如果某个事务长时间保存快照,那么它也将保存数据库范围。此外,即使事务本身不保存快照,仅存在未完成的事务也将保留视野。
这意味着无法清除数据库中的死元组。另外,“长时间”事务有可能根本不与其他事务相交,但是这并不重要,因为所有事务共享一个数据库范围。
现在,如果我们使一个段代表快照(从snapshot.xmin到snapshot.xmax)而不是事务,那么我们可以将情况可视化如下:

在此图中,最低的快照与未完成的事务有关,在其他快照中,快照snapshot.xmin不能大于事务ID。
在我们的示例中,事务是从“读取已提交”隔离级别开始的。即使它没有任何活动的数据快照,它仍将继续保持发展:
| => BEGIN;| => UPDATE accounts SET amount = amount + 1.00;| => COMMIT;
=> SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();backend_xmin--------------3699(1 row)
并且仅在事务完成之后,视界范围才向前移动,从而可以清除死元组:
=> COMMIT;=> SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();backend_xmin--------------3700(1 row)
如果所描述的情况确实导致问题,并且无法在应用程序级别解决,则从9.6版开始可以使用两个参数:
old_snapshot_threshold确定快照的最大生存期。这段时间过后,服务器将有资格清除死元组,并且如果“长时间播放”事务仍然需要它们,则将出现“快照太旧”错误。
idle_in_transaction_session_timeout确定空闲事务的最大生存期。经过这段时间后,事务中止。
快照导出
有时会出现这样的情况,其中必须保证多个并发事务才能看到相同的数据。一个示例是pg_dump实用程序,该实用程序可以在并行模式下工作:所有工作进程必须以相同状态查看数据库,以使备份副本保持一致。
当然,我们不能依靠这样的信念,即仅仅因为事务是“同时”开始的,它们就能看到相同的数据。为此,可以导出和导入快照。例如
该pg_export_snapshot函数返回快照ID,可以将其传递给另一个事务(使用DBMS外部的工具)。
=> BEGIN ISOLATION LEVEL REPEATABLE READ;=> SELECT count(*) FROM accounts; -- any querycount-------3(1 row)
=> SELECT pg_export_snapshot();pg_export_snapshot---------------------00000004-00000E7B-1(1 row)
另一个事务可以在执行第一个查询之前使用SET TRANSACTION SNAPSHOT命令导入快照。还应该在指定可重复读或可序列化隔离级别之前,因为在“读已提交”级别,语句将使用其自己的快照。
| => DELETE FROM accounts;| => BEGIN ISOLATION LEVEL REPEATABLE READ;| => SET TRANSACTION SNAPSHOT '00000004-00000E7B-1';
现在,第二个事务将与第一个事务的快照配合使用,因此,请参见三行(而不是零行):
| => SELECT count(*) FROM accounts;| count| -------| 3| (1 row)
导出快照的生存期与导出事务的生存期相同。
| => COMMIT;=> COMMIT;
未完待续。
