




1. 摘要
前一篇文章介绍了现代数据栈,接着继续介绍现代数据栈更多细节。
一年前,一些人已经预测 dbt 有一天会比 Spark 更大[1],而 2021 年证明了他们是正确的:dbt 变得非常受欢迎,有传言说 dbt-labs 可能会再次以 60 亿美元的估值筹集资金。按照这个速度,他们很快就会赶上 Databricks,后者在 2021 年 9 月达到 380 亿美元的估值。尽管如此,今年 Spark 最让我印象深刻的是,几乎所有关于现代数据栈的博客文章都没有 Spark,它是围绕 2 个关键组件构建的:
• 大规模并行 SQL 引擎(BigQuery、Redshift、Snowflake)
• 和... dbt
上游:无代码提取/加载工具(Fivetran、Stitch、Airbyte)。下游:BI 工具(Tableau、Looker、Power BI、Metabase)和反向 ETL 工具,用于将数据导出到专门的数据库(客户数据平台等)。
2. 现代数据栈
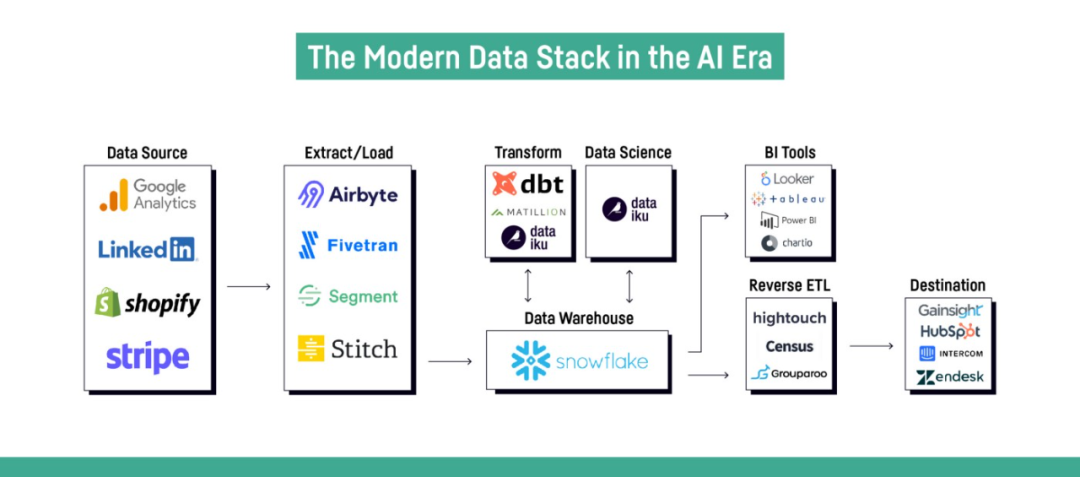
我只需要在 Google 图片中输入“现代数据栈”即可注意到数据市场中的所有公司都在提出他们自己的技术列表来组成这个栈,因为他们通常会尝试将自己包含在列表中。但我也注意到,这个现代数据栈通常是在完全没有 Spark 的情况下构建的,并且 Databricks 生态系统大多被视为它的完整替代品。当然,Databricks 完全意识到这一点,并且像许多其他人一样,尝试加入可以放在栈中心的 SQL 引擎的小圈子:他们在 12 月发布了与 dbt Core 以及 Databricks SQL 的完全集成[2]。
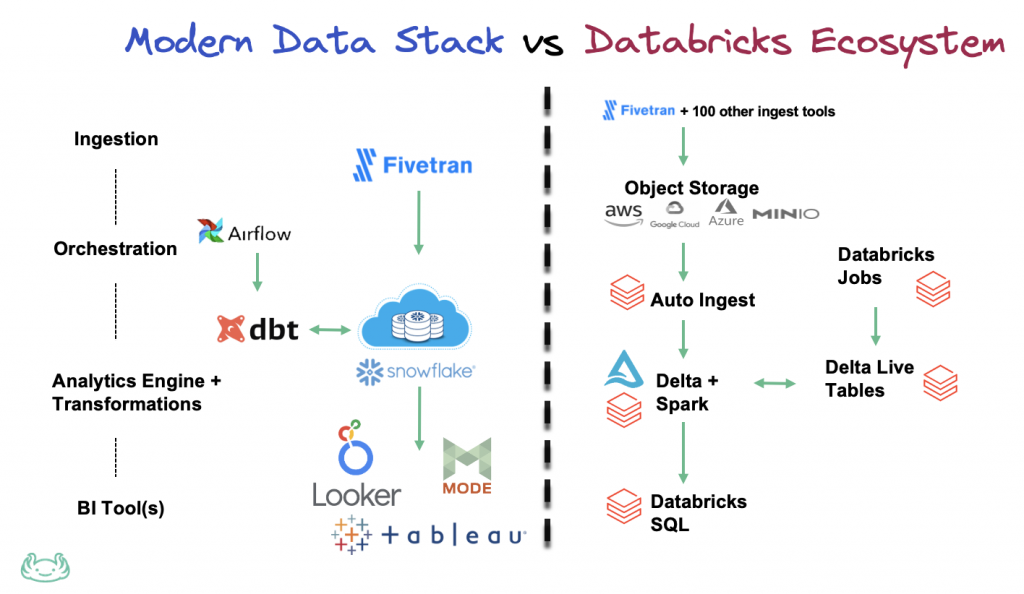
最近我回复了另一家公司的某个人,他询问是否值得将 Spark 添加到他们的现代数据栈中。由于我的团队目前同时使用 pySpark、BigQuery 和(一点点)dbt,我自己对这个问题思考了很多。所以我用一长串促进我当前思考的利弊来回答他们,我在这里分享:
基础架构:BigQuery 完全由 Google 管理,完全托管。相比之下 Spark 的掌握要复杂得多,即使这往往变得更容易(Spark-serverless 在 GCP 上提供预览版,并且即将在 Databricks 和 Databricks SQL 上推出)。
学习曲线:在 BigQuery(只有 SQL)上找到或培养熟练的人比 Spark 更容易。我的建议:在 Scala、Java 或 .Net 中更喜欢 pySpark 而不是 Spark。例如 Python 更易于访问,并且已经被 Airflow 使用。我认为在 Spark 中使用 Python 以外的其他语言的唯一正当理由是:“使用 RDD 做非常高级的事情”和“重用某些公司已经用 Java 编写的代码,而无需重新实现它”。
代码组织:dbt 展示了组织 SQL 转换管道的正确方式(从 2014 年到 2017 年,我开发了一个工具,它与 dbt 做同样的事情,但用于 Apache Hive)。据我所知,目前还没有工具可以为 pySpark 做同样的事情(dbt 确实支持 spark-sql,但没有完整的 pySpark),这就是为什么我们开发了一个内部工具,我希望有一天能开源它。
表现力:我喜欢 SQL,甚至比 BigQuery 更喜欢,但我不能只用 SQL 完成我需要的所有事情。此外我认为使用 Jinja 模板不是正确的解决方案:正如 Maxime Beauchemin 在他的博客文章中所说的那样,这将导致大量的模板化 SQL 和 YAML。就个人而言我认为这与第一个调度程序中的错误相同:config-as-code 有很多限制,Airflow 通过证明 code-as-config(感谢 Python)工作得更好来扭转局面。是的JINJA 确实解决了 config-as-code 的一些僵化问题,但我仍然觉得 JINJA 相当繁重和冗长,可读性不强,并且单元测试 JINJA 代码似乎相当乏味。
SQL 的限制:与 Maxime Beauchemin 一样,我相信(至少,我希望)当 BigQuery、Snowflake 或 Redshift 提供类似于 pySpark 中提供的 DataFrame API 时,情况会变得更好。Snowflake 实际上已经这样做了:他们最近发布了 Snowpark,其 DataFrame API[3] 从 Spark 的 API 借鉴而来。我最近开始为 BigQuery 做一个 DataFrame API[4] 的 POC,以展示用这样的东西可以做更多的事情(我承认,其中一些已经可以用 JINJA 宏完成,但在某种程度上我觉得不太优雅并且很难维护)。我将在下一篇文章中详细讨论这个 POC。
UDF:SQL 的另一个重要限制:使用 UDF 比使用 SQL 代码更容易实现某些逻辑。在 BigQuery 中,UDF 必须使用 SQL 或 Javascript (!!!) 编写。Snowflake 允许使用 Java。去告诉只知道 Python 的数据工程师/分析师/科学家编写 Javascript UDF……PySpark 允许我们用 Python 编写 UDF,期待 BigQuery 支持。

Extract-Load (E/L):我对大量似乎使用自定义 Airflow 运算符而不是 Spark 来执行 E/L 任务的人感到非常惊讶。我认为这是 Spark 的最大优势之一:它支持大量连接器[5]可以读取/写入所有内容和任何内容。它还可以对 json 和 xml 执行自动模式检测,而不会让人头疼。而且,正如 Ari Bajo 指出[6],最好使用中心状态 (Spark) 并使用 O(n) 连接器,而不是为每个源-目标对编写 O(n²) 连接器。Spark 可以做到这一切,而且我认为它的运行成本比 Fivetran 便宜得多(尽管我必须说开源工具 Airbyte 可能是一个不错的选择)。Spark 的设置成本可能更高,但一旦付费,复制和添加新的源/目标不会花费很长时间。另一个优点:Spark 可以同时进行 ETL 和反向 ETL。确实,它确实需要非开发人员可以使用图形界面的开发人员。但我也有一种感觉,一个非开发人员使用 GUI 将无法调查和解决潜在问题(但我可能错了)。
实时:在我的团队中,我们开始将 pySpark 用于简单的实时案例(将原始数据提取到 BigQuery 中),但我不太了解该主题,无法将其与其他替代方案(例如 lambda 函数)进行比较。我们会注意到,由于它的微批处理模式,Spark 让我们可以很容易地获得完全一次的保证。

3. 总结
总结一下,我认为这些考虑大部分都围绕着一个中心点,那就是 SQL 最大的优点,但也是它最大的弱点:简单。正是由于 SQL 的简单性,BigQuery 和 Snowflake 等平台非常易于使用,并且采用如此广泛,同时降低了供应商锁定的风险。相反,这种简单性也是它最大的缺点,因为 SQL 的限制很快就会达到,开发最佳实践更难应用,也不太普及。多亏了 dbt 和 JINJA,其中一些不利因素可以得到缓解,但我相信行业将不得不走得更远,使用 DataFrames 或其他类似的 API,以帮助数据技术人员编写更通用和更高级的转换,并更好地解决不断增长的对数据的需求。

在我的团队中,主要挑战之一是我们倾向于在 pySpark 和 BigQuery 之间交替使用,以从每种工具的最佳表现中受益。这使得数据血缘更加困难,因为 dbt 只让我们可视化 BigQuery 部分,而我们内部的“dbt for pySpark”工具只让我们看到 pySpark 部分。从长远来看,我希望 BigQuery 能够添加与 pySpark 相比缺少的功能(DataFrame API 和 Python UDF),这将使我们有朝一日能够将当前的 pySpark 转换迁移到 BigQuery。pySpark 唯一保留的东西是 E/L 和实时数据处理。
引用链接
[1]
一些人已经预测 dbt 有一天会比 Spark 更大: [https://medium.com/datamindedbe/why-dbt-will-one-day-be-bigger-than-spark-2225cadbdad0](https://medium.com/datamindedbe/why-dbt-will-one-day-be-bigger-than-spark-2225cadbdad0)[2]
完全集成: [https://docs.databricks.com/dev-tools/dbt.html](https://docs.databricks.com/dev-tools/dbt.html)[3]
DataFrame API: [https://docs.snowflake.com/en/developer-guide/snowpark/reference/scala/com/snowflake/snowpark/DataFrame.html](https://docs.snowflake.com/en/developer-guide/snowpark/reference/scala/com/snowflake/snowpark/DataFrame.html)[4]
DataFrame API: [https://medium.com/r?url=https%3A%2F%2Fgithub.com%2FFurcyPin%2Fbigquery-frame](https://medium.com/r?url=https%3A%2F%2Fgithub.com%2FFurcyPin%2Fbigquery-frame)[5]
大量连接器: [https://spark-packages.org/?q=tags%3A%22Data%20Sources%22](https://spark-packages.org/?q=tags%3A%22Data%20Sources%22)[6]
正如 Ari Bajo 指出: [https://airbyte.io/blog/airflow-etl-pipelines](https://airbyte.io/blog/airflow-etl-pipelines)
