




哈希关联也是一个需要有特定工作区内存来完成的操作,它同样利用了可调节的内存分配技术, 当可用内存不足时(无法满足优化模式运行的需要),也会产生直接读写临时磁盘。
我们前面提到,哈希管理算法主要有三种:经典算法、Grace 算法和混合算法。Oracle 采用的是混合算法,过程大致如下:
• 先用哈希函数对左数据集(也称为构建数据集)的关联字段进行哈希计算、按哈希值分区, 将部分或全部分区载入内存,并且基于内存中的数据记录创建哈希表;
• 然后逐条扫描右数据集(也称为探测数据集)的数据记录,用相同的哈希函数获取其关联 字段的哈希值,并与内存中的哈希表进行匹配。
在哈希关联过程中,数据的读写是以多数据块(Multiple Blocks)的方式进行的,每次读取的数据块都需要分配一个内存槽(Slot),也称为一个簇(Cluster)。整个过程可以分为 3 个阶段:构建(Build)阶段、探测关联(Probe Join)阶段和探测(Probe)阶段。其中,构建阶段还包括相关
数据(如分区数)的初始化过程。而探测(Probe)阶段在优化模式(Optimal Mode)下不会出现。在构建阶段,要完成对构建表的分区(Partition,也称为 Fanout)和矢量图(Bitmap Victor,每
个分区一个)的创建。要完成这两项任务,需要逐条扫描探测数据集中的记录,通过一个哈希函数
(我们称 HashFunc1)对其管理字段计算以决定其所属分区,并且由另外一个哈希函数(我们称
HashFunc2)获取其在位矢量图上的相应位置。并且,
• 对于需要写入磁盘的分区,如果是同步 IO,则需要为每个分区分配 1 个读槽(Read Slot), 数据满了就写入相应分区;如果是异步 IO,则还需要分配 1 个写槽(Write Slot),使得读写能同时进行;
• 而对于需要保留在内存中进行第一次哈希管理匹配的分区,则根据工作区的可用大小清理, 将其全部或者部分簇保留在内存当中;
• 在这一阶段,同时还需要有部分内存用于存储其他数据(如位矢量图)。
在探测关联阶段,则需要创建哈希表,将驻留在内存中的分区上的数据建立哈希键值(Key-
Value)映射关系。每个哈希键对应一个分组(Bucket),并由链表指针关联到所有该哈希值的数据 记录管理起来。然后扫描探测数据集,在扫描过程中,同样用 HashFunc1 决定其所在分区,同时用
HashFunc2 获取其矢量图位,并与相应分区的位矢量图匹配,如果匹配不上,则数据被直接丢弃, 如果能匹配到,则由相应构建分区是否在内存中决定是将其写入磁盘还是与内存中的哈希表匹配。 同样,对于需要写入磁盘的分区,需要分配相应的内存槽用于读写。
而探测阶段则可以视为一个递归过程。如果磁盘上还有剩余分区未被匹配,则选择一对分区进行哈希管理,将其中较小分区作为构建数据集读入内存创建哈希表、较大分区作为探测数据集被逐 条扫描、并与哈希表进行匹配。而如果工作区无法容纳下某个构建分区,则需要对这一对分区重复 着三个阶段,将其划分为子分区后进行探测关联。这种情况的出现,也表明该哈希操作是在多次传 递模式(Multi-Pass Mode)下完成的。
哈希关联过程示意
为了更加清晰的理解哈希关联过程,我们用以下一系列示意图来描述一个简单示例:
(过程中产生的哈希值是由 Perl 脚本 Hash.pl 生成的)
假设构建数据集中有 24 条记录,探测数据集中有 40 条记录。而在初始化阶段,计算得到的分区数为 4,并且保留 2 个分区(第 2、3 分区)在内存中用于第一次探测关联;还计算得到位矢量图的位数为 16,即哈希表的键值数(或者说 Bucket 数)。
构建阶段
扫描构建数据集,并且根据哈希函数 HashFunc1 将每条数据读入相应分区的内存槽当中,同时还由哈希函数 HashFunc2 获取其位矢量图的位置,并将其所在分区的位矢量图的相应位置 1。关联字段值为 Null 的被直接丢弃。

在上图中,构建数据集的第一条的关联字段值为 18,通过哈希函数 HashFunc1 得到其所属分区为第一个分区,因此被读取内存槽 Slot 2 当中;有哈希函数 HashFunc2 得到其哈希值为 4,因此将分区 1 的位矢量图的第 4 位置 1。最终得到的 4 个分区的位矢量图为:

探测关联阶段
进入探测管理阶段后,将第 2、3 分区的数据全部读入内存并创建哈希表。

该哈希表有 16 个分组,有些分组下没有数据、而有些分组有多条数据,以下是对该哈希表的一个数据统计:

以下是哈希关联跟踪信息中的记录:

创建哈希表后,开始扫描探测表。同样,需要用哈希函数 HashFunc1 决定每条探测记录所属分区,用哈希函数 HashFunc2 得到其位矢量图的位置、并与相应分区的位矢量图进行匹配过滤。未被过滤的数据则根据其所属分区决定是写入磁盘还是与哈希表进行关联匹配。

上图中,第一条记录的 HashFunc1 的值为 1,属于第 1 个分区,其 HashFunc2 的值为 15,相应的构建分区的位矢量图中第 15 位为 1,因此这条记录要被读入内存槽 Slot 1,准备被写入磁盘Parition 1;第三条记录属于第 3 个分区,其哈希值为 7,相应构建分区的位矢量图第 7 位为 0,因此被过滤、丢弃;而第六条记录同样属于第 3 个分区,但未被位矢量图过滤,并且通过哈希表找到了匹配记录,因此被直接输出。
探测阶段
所有探测数据被扫描后,尚在内存中未匹配数据都被写入磁盘,进入探测阶段:

从中选出一对分区(假定选定分区 0)进行探测,选择其中较小分区作为构建分区、并创建哈希表(哈希分组的数量可能会根据内存情况重新调整)。在这里,原构建分区 0 的大小大于原探测分区 0,因此,他们的角色发生了转换(Role Reversed):

另外一个较大分区作为探测分区,逐条扫描记录,与哈希表进行匹配:

分区 0 探测完成后,再重复对分区 1 进行探测。运行过程中的工作区大小动态调整
和排序过程类型,在哈希关联过程中同样会根据估算的构建数据集的大小、当前可用工作区的
限制等条件,动态调整工作区的大小,使得整个过程在最合理的工作区大小范围内获得最佳的性能。相关数据计算,和系统参数设置、是否采用异步 IO 以及构建数据记录长度等因素相关。以下的计
算是我们在 11gR2 的环境中得到一些近似计算方法。
分区数(Fanout)和内存槽大小(Slot Size,SS)
对于一定大小的构建数据集(Input Size,ISize),决定所需内存大小(M)的主要因素就是分区数和内存槽大小。在初始化过程中,最重要的工作就是估算出最合适的分区数和内存槽大小,使 得在可用内存下获得最大性能。
对于 Fanout 和 SS 的计算,是基于一次传递模式的假定前提下的。因为即使计算数据错误,一次传递模式可以平滑地向其他两种模式转换。估算过程为:先取内存槽大小 SS 的最大值(由系统参数“_smm_auto_max_io_size”决定,SAMAXIO),并由公式计算出分区数 Fanout。然后再由内存槽大小 SS 和分区数 Fanout 计算出所需工作区大小 MReq。如果计算出所需工作区大小小于当前的最大工作区大小(参数_SMM_MAX_SIZE 为关键决定因素,SMMAX)的限制,则采用当前的内存槽大小 SS 和分区数 Fanout 对构建数据集进行划分;否则,调整内存槽大小 SS 和分区数 Fanout 重新计算。调整的原则如下:
• 如果内存槽大小 SS 大于最小设置值(由系统参数“_smm_auto_min_io_size”决定,
SAMINIO),则将内存槽大小减少一半,并再用公式计算出分区数。新的内存槽大小计算 方法如下:
SS[new] = (SS[old] + BLKSIZE)/2 - BLKSIZE
• 否则,分区数减半:Fanout[new] = Fanout[old]/2
从前面的过程描述可以看出,构建阶段和探测关联阶段所需的内存可能是不同的。而分区数的 计算是基于构建阶段所需内存等于探测相当的前提下。11gR2 下,我们观察到的计算方法为:
Fanout = GREATEST(8, SQRT(4*ISize/SS+1)+1)
计算所得的 Fanout 必须为 2 的幂数。而在分区数调整过程中,减少分区数时,优化模式下,
Fanout 最小为 8;一次传递模式下,Fanout 最小为 2。此外,在减少分区数时,还需要保证一个分区占用的内存槽数量小于分区数,即,
(ISize/Fanout)/SS < Fanout
=>
SQRT(ISize/SS) < Fanout
优化模式和一次传递模式下执行操作所需的内存大小是不同的,相应的,由内存槽大小和分区数计算所需工作区大小的方法也是不同的。因此,在计算所需工作区大小之前,还需要由输入数据 大小和工作区最大限制来估计是在哪一种模式下运行:如果 ISize*FCal < SMMAX,则由优化模式和
内存需求来估算,否则,由一次传递模式的内存需求来估算。11gR2 下,我们观察到的计算方法为:
• 一次传递模式:
MReq = (BSN+1)SSFCal
• 优化模式:
MReq = (CEIL(ISize/SS)+Fanout)SSFCal
其中,
• Fcal 为调整系数,保证计算所得内存中有足够空间用于控制管理信息。它的计算与构建数据集的数据记录长度(Row Length,RLen)有关。
FCal ≈ 1.053+8.43/RLen
• BSN 为构建阶段分配的内存槽数,
BSN = Fanout3/2
并且,
o 如果 SMMAX < MBLimit,则 BSN = GREATEST(Fanout+4, TRUNC(ISize/FCal/SS));
o 如果 SMMAX > MCache,则 BSN ≈ ISize/(SS+8)
o MBLimit 为构建阶段最少驻留一个分区在内存中所需的的内存大小。
MBLimit ≈ Fanout3/2SSFBuild + VTotal
FBuild 为构建阶段保证足够空间用于控制信息的系数,11gR2 中,FBuild≈
1+7.08/RLen
VTotal 为位矢量图所需空间 VTotal,VTotal = 0.05Fanout3/2SSFBuild,并且为
2 的幂数。
o MCache 为以最大内存槽大小 SMAXIO 计算得到缓存模式所需的内存大小:
MCache ≈ (CEIL((GREATEST(TRUNC(ISize)-
3SSAdj,0))/SSAdj)+FanoutMax+4)SSAdjFmax
Fmax 为最大缓存模式下的计算系数,Fmax ≈ (1.016+7/RLen)
SSAdj 为由最大内存槽大小调整后的内存槽大小,SSAdj ≈ (63SMAXIO-8)/64
FanoutMax 为由最大内存槽大小计算得到的分区数,FanoutMax = GREATEST(8, SQRT(4I/S+1)+1)
• 如果该语句游标存在曾经分配过的工作区上下文(由视图 V$SQL_WORKAREA 可以查询), 则数据记录长度的由上下文数据中获取,否则,由统计数据计算得来:
RLen = SACL + COLN2 + 12
其中,SACL 为语句中构建表的所有被选择字段、关联字段的平均长度综合;COLN 为这些字段的字段数量,12 应该是 ROWID 的长度。
此外,输入数据大小(ISize)同样也是从曾经分配过的工作区上下文获取,否则,由统计数据 和执行计划数据计算得来:
ISize = Card * RLen /1024
其中,Card 为执行计划中,构建数据集的记录数(Cardinality)。
构建数据集分区
进入构建阶段后,需要由计算所得数据来为操作分配实际工作区。在构建阶段,要分配 BSN 个内存槽用于读、写构建数据和保留 1 到多个分区数据,还需要分配位矢量图空间和其它管理数据空间,其计算大致如下:
MBuild ≈ SBNSSFBuild + VTotal
其中,SBN、FBuild 和 VTotal 计算和上面相同。要注意的是,位矢量图是为每个分区创建的, 因此,每个分区的位矢量图空间为:
VPart = VTotal/Fanout
哈希关联过程分析示例
我们通过以下示例来分析一个一次传递的哈希关联过程。在示例中,修改了最大内存槽限制为
2048K,并且用提示将大表作为构建表,以下是工作区自我调节(或者说 SQL 内存管理,SQL Memory Manage,SMM)的其他相关参数,以及语句的运行性能统计:

修改参数值,并运行语句,对其进行 10104 事件跟踪:
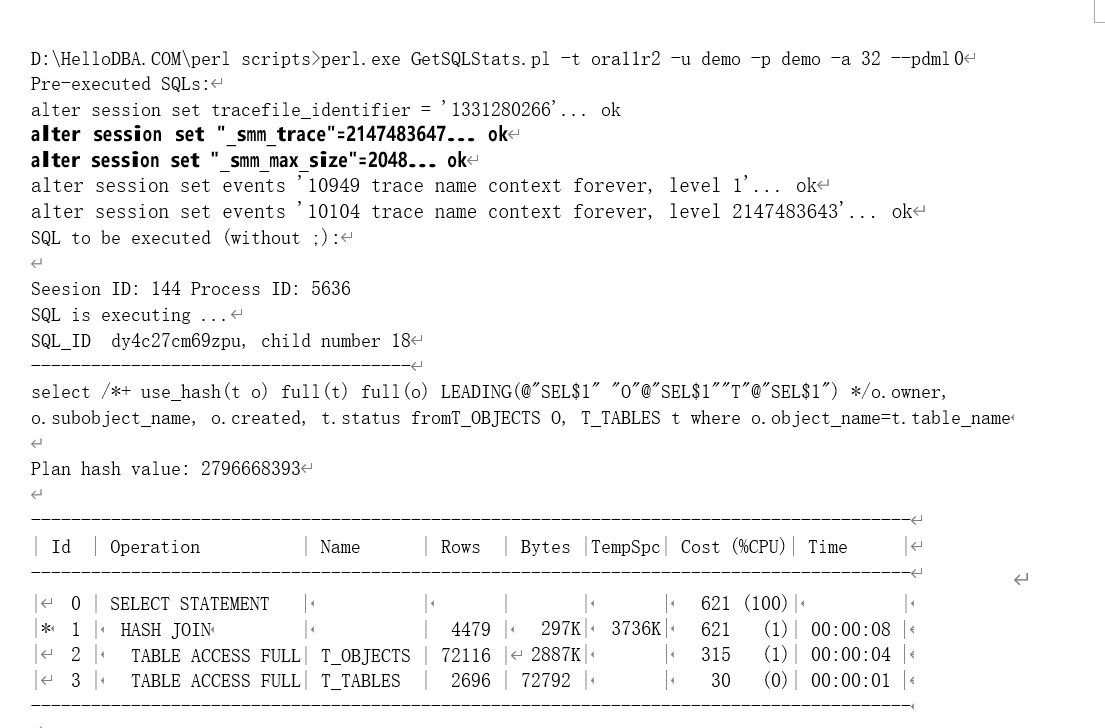

通过设置 10104 事件,可以获得哈希关联的过程跟踪信息。


首先获取到统计信息,这里是第一次运行该语句,因此,从对象统计数据和执行计划数据中计 算出输入数据大小。这里构建表为 T_OBJECTS,查询字段和关联字段为’OWNER’、
‘SUBOBJECT_NAME’、‘CREATED’、‘OBJECT_NAME’,字段总的平均长度为 41,字段数为 4,因此
RLen=41+42+12=61;执行计划中的构建数据集的记录数为 72116。最终得到输入数据大小 ISize =
7211661/1024=4295K。
由统计数据以及最小内存槽大小 SMINIO 和最大内存槽大小 SMAXIO 计算得到三种模式所需的内存:
FanoutMax = GREATEST(8,SQRT(1+4ISize/SMAXIO)) = GREATEST(8,SQRT(1+44295/248)+1) = 9.38297045 ≈ 8 = 2^3
SSAdj = (63SMAXIO-8)/64 = (63248-8)/64 = 244
=>
MMin = 8SMINIO = 856 = 448
M1pass ≈ 2FanoutMaxSSAdjFmax = 28244(1.016+7/61) = 4414.464
MCache ≈ (CEIL((GREATEST(TRUNC(ISize)-3SSAdj,0))/SSAdj)+FanoutMax+4)SSAdjFmax = (CEIL((GREATEST(TRUNC(4295)-3244))/244)+8+4)244(1.016+7/61) = 7449.408
然后计算分区数和内存槽大小,先由最大内存槽大小(SMAXIO,248)计算得到分区数,
Fanout = GREATEST(8, SQRT(4ISize/SS+1)+1) = GREATEST(8, SQRT(44295/248+1)+1) = 9.38297045 ≈ 8 = 2^3
由于 ISizeFCal = 4295(1.053+8.43/61) = 5116.19 > SMMAX = 2048,因此采用一次传递模式下的计算方式计算所需内存。
先要计算得到 BSN
VTotal = 0.05Fanout3/2SSFBuild = 0.0583/2248(1+7.08/61) = 166.07055737704918032786885245902 ≈ 128 = 2^7
MBLimit ≈ Fanout3/2SSFBuild + VTotal = 83/2248(1+7.08/61) + 128 = 3449.411 > SMMAX
因而,
BSN = GREATEST(Fanout+4, TRUNC(ISize/FCal/SS)) = GREATEST(8+4,
TRUNC(4295/(1.053+8.43/61)/248)) = 14
再得到所需内存大小:
MReq = (BSN+1)SSFCal = (14+1)248(1.053+8.43/61) = 4431.252 > SMMAX
因此,要调整内存槽大小重新计算:
SS[new] = 120
Fanout = GREATEST(8, SQRT(4ISize/SS+1)+1) = GREATEST(8, SQRT(44295/120+1)+1) = 13.0069 ≈
8 = 2^3
VTotal = 0.05Fanout3/2SSFBuild = 0.0583/2120(1+7.08/61) = 80.357 ≈ 64 = 2^6 MBLimit ≈ Fanout3/2SSFBuild + VTotal = 83/2120(1+7.08/61) + 64 = 1671.134 < SMMAX BSN = Fanout3/2 = 83/2 = 12
MReq = (BSN+1)SSFCal = (12+1)120(1.053+8.43/64) = 1848.161 < SMMAX
分区数最终为 8,构建阶段内存槽数为 12,内存槽大小为 120。

构建阶段分配的内存大小为:
MBuild ≈ SBNSSFBuild + VTotal = 12120(1+7.08/64) + 64 = 1663.3
其中位矢量图的大小为 64K,则每个分区的位矢量图大小为: VPart = VTotal/Fanout=64/8=8K

以上是初始化完成后的第的相关数据。
• “Original hash-area size”为构建阶段分配的内存大小,即 MBuild;
• “Memory for slot table 为”构建阶段内存槽的总共大小:SSSBN = 12012*1024=1474560
• “Calculated overhead for partitions and row/slot managers”为用于位矢量图及其它管理信息数据的大小,等于分配的总的内存大小减去内存槽总的大小:1708564-1474560=234004;
• “Hash-join fanout”和“Number of partitions”为分区数;
• “Number of slots”为构建阶段分配的内存槽数;
• “Multiblock IO”为直接读写临时空间的数据块数,SS/BLKSIZE = 120/8 = 15;
• “Cluster (slot) size(KB)”为内存槽大小;
• “Minimum number of bytes per block”为每个数据用于存放用户数据的大小,等于数据块大小减去块头大小(32 字节);
• “Bit vector memory allocation(KB)”为总共分配的位矢量图的大小,即 VTatol;
• “Per partition bit vector length(KB)”为每个分区的位矢量图大小,即 VPart;
• “Maximum possible row length”为数据记录可能的最大长度,由对象统计数据中每个字段的最大长度设置之和得到;
• “Estimated build size (KB)”为估算到的构建数据集的大小,单位应该是 MB,即ISize/1024=TRUNC(4295/1024)=4;
• “Estimated Build Row Length (includes overhead)”为数据记录平均长度;


进入构建阶段,将数据分区。从写临时磁盘的记录可以看到,仅最后一个分区的数据未被写入 磁盘。构建数据全部扫描完成后,进入了探测关联阶段,

数据扫描完成后,根据扫描获取到的实际统计数据更新操作统计数据。同时由新的统计数据计 算出新的内存需求大小、进入下一阶段:探测关联阶段。
可以看到,更新后的总的构建数据集大小为 3486KB、数据记录长度为 50 字节。新的统计数据也是包含了关联记录的控制信息:数据记录长度为实际长度加上字段数乘以 1 再加 ROWID 长度
(12)。3486KB 为记录长度未作取整时的总的大小,而在内存估算和更新工作区上下文数据时, 总的长度为数据记录长度取整后的大小、即 3520K。在我们的示例中,实际值为:

由实际的构建数据集的大小,我们可以估算出每个分区占用的内存槽数:
ISize[new]/Fanout/SS/(8160/8192) = 3486/8/120/(8160/8192) = 3.645,取整后为 4。继续看跟踪记录:

进入探测关联阶段之后,用于其他 7 个分区的读写内存槽中的数据也被写入磁盘,被释放的内存将被用于创建第一个哈希表。


仅最后一个分区的 4 个内存槽被驻留在内存当中。rows 为该分区中的数据记录数。clusters 应该为该分区的总的簇数(即槽数),slots 为该分区主流在内存中的槽数,kept 表示该分区在构建阶段后是否被保留。
通常来说,在构建阶段,需要有 1 个内存槽用于存放额外的管理数据,而在同步 IO 模式下, 每个分区要分配 1 个内存槽用于读写,那么剩余用于存放第一次哈希关联分区数据的内存就剩下
SBN-1-Fanout = 12-1-8=3。从前面的实际构建数据大小计算得到平均每个分区的内存槽数为 4。因此, 剩余内存正好容纳下一个分区(3 加上本身用于读写的内存槽等于 4)。





从这个过程分析可以看到,完成一次哈希关联操作,并不是使用一个固定的工作区大小,而是根据构建数据集和构建分区大小以及当前可用内存、相关内存大小限制等条件,动态的分配和释放 内存空间。这样,即保证了当前操作能获得最佳的性能,同时还尽可能的将多余空间释放给其它需 要工作区的操作。



