




即将发布的 Postgres 14 版本的第一个 beta 版本于昨天:https://www.postgresql.org/about/news/postgresql-14-beta-1-released-2213/发布。在本文中,我们将首先了解测试版中的内容,重点介绍一项主要的性能改进,以及引起我们注意的三项监控改进。
在我们开始之前,我想强调一下 Postgres 一个重要的独特方面总是让我印象深刻:与大多数其他开源数据库系统相比,Postgres 不是一个公司的项目,而是许多人一起工作的一个新版本,年复一年。这包括所有试用 beta 版本并向 Postgres 项目报告错误的人:https://www.postgresql.org/developer/beta/。我们希望这篇文章能激发您进行自己的测试和基准测试。
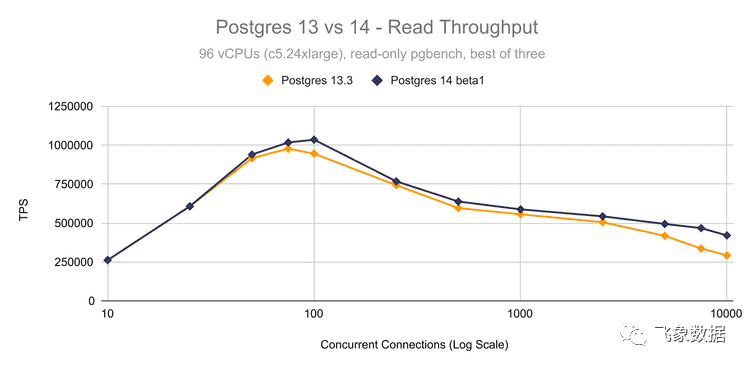
现在,我个人对Postgres 14 中更好的连接扩展感到最兴奋。对于这篇文章,我们运行了一个详细的基准测试,比较 Postgres 13.3 和 14 beta1(注意连接数是对数比例):
Postgres 14 中改进的活跃和空闲连接释放
Postgres 14 为我们这些需要大量数据库连接的人带来了重大改进。Postgres 连接模型依赖于进程而不是线程。这有一些重要的好处,但它也有大量连接数的开销。在这个新版本中,扩展活动和空闲连接的能力得到了显着改善,对于要求最苛刻的应用程序来说,这将是一项重大改进。
对于我们的测试,我们使用了两个 96 vCore AWS 实例 (c5.24xlarge),一个运行 Postgres 13.3,一个运行 Postgres 14 beta1。两者都使用 Ubuntu 20.04,具有默认系统设置,但 Postgres 连接限制已增加到 11,000 个连接。
我们使用pgbench:https://www.postgresql.org/docs/current/pgbench.html来测试活动连接的连接扩展。首先,我们使用 pgbench 比例因子 200 初始化数据库:
# Postgres 13.3$ pgbench -i -s 200...done in 127.71 s (drop tables 0.02 s, create tables 0.02 s, client-side generate 81.74 s, vacuum 2.63 s, primary keys 43.30 s).# Postgres 14 beta1$ pgbench -i -s 200...done in 77.33 s (drop tables 0.02 s, create tables 0.02 s, client-side generate 48.19 s, vacuum 2.70 s, primary keys 26.40 s).复制
在这里我们已经可以看到 Postgres 14 在初始数据加载方面做得更好。
我们现在启动具有一组不同活动连接的只读 pgbench,显示 5,000 个并发连接作为非常活跃的工作负载的示例:
# Postgres 13.3$ pgbench -S -c 5000 -j 96 -M prepared -T30...tps = 417847.658491 (excluding connections establishing)# Postgres 14 beta1$ pgbench -S -c 5000 -j 96 -M prepared -T30...tps = 495108.316805 (without initial connection time)复制
如您所见,Postgres 14 在 5000 个活动连接时的吞吐量大约高出 20%。在 10,000 个活动连接时,改进比 Postgres 13 提高 50%,并且在连接数较低时,您还可以看到持续的改进。
请注意,当连接数超过 CPU 数时,您通常会看到明显的 TPS 下降,这很可能是由于 CPU 调度开销,而不是 Postgres 本身的限制。现在,大多数工作负载实际上并没有这么多活动连接,而是有大量空闲连接。
这项工作的原作者Andres Freund:https://twitter.com/andresfreundtec 对单个活动查询的吞吐量进行了基准测试,同时还运行了 10,000 个空闲连接。查询从 15,000 TPS 增加到近 35,000 TPS - 这比 Postgres 13 中的要好 2 倍以上。您可以在Andres Freund 介绍这些改进的原始帖子:https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/improving-postgres-connection-scalability-snapshots/ba-p/1806462#fn:1
中找到所有详细信息。
使用 pg_backend_memory_contexts 深入研究内存使用
你有没有好奇过为什么某个 Postgres 连接会占用更多的内存?使用新pg_backend_memory_contexts
视图,您可以仔细查看为给定 Postgres 进程分配的确切内容。
首先,我们可以计算当前连接总共使用了多少内存:
SELECT pg_size_pretty(SUM(used_bytes)) FROM pg_backend_memory_contexts;pg_size_pretty----------------939 kB(1 row)复制
现在,让我们深入一点。当我们按内存使用量查询前 5 个条目时,您会注意到实际上有很多详细信息:
SELECT * FROM pg_backend_memory_contexts ORDER BY used_bytes DESC LIMIT 5;name | ident | parent | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes-------------------------+-------+------------------+-------+-------------+---------------+------------+-------------+------------CacheMemoryContext | | TopMemoryContext | 1 | 524288 | 7 | 64176 | 0 | 460112Timezones | | TopMemoryContext | 1 | 104120 | 2 | 2616 | 0 | 101504TopMemoryContext | | | 0 | 68704 | 5 | 13952 | 12 | 54752WAL record construction | | TopMemoryContext | 1 | 49768 | 2 | 6360 | 0 | 43408MessageContext | | TopMemoryContext | 1 | 65536 | 4 | 22824 | 0 | 42712(5 rows)复制
Postgres 中的内存上下文是一个内存区域,用于分配以支持查询计划或查询执行等活动。一旦 Postgres 在一个上下文中完成工作,整个上下文就可以被释放,从而简化内存处理。通过使用内存上下文,Postgres 源代码实际上避免free
了大部分手动调用(即使它是用 C 编写的),而是依靠内存上下文来分组清理内存。这里的顶级内存上下文,CacheMemoryContext 用于 Postgres 中的许多长寿命缓存。
我们可以通过对新表运行查询,然后再次查询视图来说明将附加表加载到连接中的影响:
SELECT * FROM test3;SELECT * FROM pg_backend_memory_contexts ORDER BY used_bytes DESC LIMIT 5;name | ident | parent | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes-------------------------+-------+------------------+-------+-------------+---------------+------------+-------------+------------CacheMemoryContext | | TopMemoryContext | 1 | 524288 | 7 | 61680 | 1 | 462608...复制
正如您所看到的,新视图表明,即使在查询完成后,只需在此连接上查询表将保留大约 2kb 的内存。这种表信息的缓存是为了加快未来的查询速度,但有时会导致具有许多不同模式的多租户数据库的内存使用量惊人。您现在可以通过这个新的监控视图轻松说明此类问题。
如果您想访问当前进程以外的进程的此信息,您可以使用新pg_log_backend_memory_contexts
函数,该函数将导致指定进程将其自己的内存消耗输出到 Postgres 日志:
SELECT pg_log_backend_memory_contexts(10377);LOG: logging memory contexts of PID 10377STATEMENT: SELECT pg_log_backend_memory_contexts(pg_backend_pid());LOG: level: 0; TopMemoryContext: 80800 total in 6 blocks; 14432 free (5 chunks); 66368 usedLOG: level: 1; pgstat TabStatusArray lookup hash table: 8192 total in 1 blocks; 1408 free (0 chunks); 6784 usedLOG: level: 1; TopTransactionContext: 8192 total in 1 blocks; 7720 free (1 chunks); 472 usedLOG: level: 1; RowDescriptionContext: 8192 total in 1 blocks; 6880 free (0 chunks); 1312 usedLOG: level: 1; MessageContext: 16384 total in 2 blocks; 5152 free (0 chunks); 11232 usedLOG: level: 1; Operator class cache: 8192 total in 1 blocks; 512 free (0 chunks); 7680 usedLOG: level: 1; smgr relation table: 16384 total in 2 blocks; 4544 free (3 chunks); 11840 usedLOG: level: 1; TransactionAbortContext: 32768 total in 1 blocks; 32504 free (0 chunks); 264 used...LOG: level: 1; ErrorContext: 8192 total in 1 blocks; 7928 free (3 chunks); 264 usedLOG: Grand total: 1651920 bytes in 201 blocks; 622360 free (88 chunks); 1029560 used复制
使用 pg_stat_wal 跟踪 WAL
基于 Postgres 13 中的 WAL 监控功能,新版本为 WAL 信息带来了一个新的服务器范围的摘要视图,称为pg_stat_wal
.
您可以使用它来更轻松地监控 WAL 写入随着时间的推移:
SELECT * FROM pg_stat_wal;-[ RECORD 1 ]----+------------------------------wal_records | 3334645wal_fpi | 8480wal_bytes | 282414530wal_buffers_full | 799wal_write | 429769wal_sync | 428912wal_write_time | 0wal_sync_time | 0stats_reset | 2021-05-21 07:33:22.941452+00复制
使用这个新视图,我们可以获得摘要信息,例如有多少整页图像 (FPI) 写入 WAL,这可以让您了解 Postgres 何时由于检查点而生成了大量 WAL 记录。其次,您可以使用新的wal_buffers_full
计数器快速查看设置何时wal_buffers
设置得太低,这可能会导致不必要的 I/O,可以通过将 wal_buffers 提高到更高的值来防止。
您还可以通过启用可选track_wal_io_timing
设置来获取有关 WAL 写入的 I/O 影响的更多详细信息,然后为您提供 WAL 写入的确切 I/O 时间,并将 WAL 文件同步到磁盘。请注意,此设置可能会产生明显的开销,因此除非需要,否则最好将其关闭(默认设置)。
使用内置 Postgres query_id 监控查询
在TimescaleDB:https://www.timescale.com/state-of-postgres-results/#top-three最近在 2021 年 3 月和 2021 年 4 月进行的一项调查中,该pg_stat_statements
扩展被命名为接受调查的用户群与 Postgres 一起使用的三大扩展之一。pg_stat_statements
与 Postgres 捆绑在一起,并且在 Postgres 14 中,扩展的重要功能之一被合并到核心 Postgres 中:
的计算query_id
,它唯一地标识一个查询,同时忽略常量值。因此,如果您再次运行相同的查询,它将具有相同的query_id
,使您能够识别数据库上的工作负载模式。以前,此信息仅可pg_stat_statements
用于 显示有关已完成执行的查询的汇总统计信息,但现在可用于pg_stat_activity
以及在日志文件中。
首先,我们必须启用新compute_query_id
设置并随后重新启动 Postgres:
ALTER SYSTEM SET compute_query_id = 'on';复制
如果您使用pg_stat_statements
查询 ID,将通过默认compute_query_id
设置自动计算auto
.
启用查询 ID 后,我们可以在pg_stat_activity
pgbench 运行期间进行查看,并了解为什么这与仅查看查询文本相比更有帮助:
SELECT query, query_id FROM pg_stat_activity WHERE backend_type = 'client backend' LIMIT 5;query | query_id------------------------------------------------------------------------+--------------------UPDATE pgbench_tellers SET tbalance = tbalance + -4416 WHERE tid = 3; | 885704527939071629UPDATE pgbench_tellers SET tbalance = tbalance + -2979 WHERE tid = 10; | 885704527939071629UPDATE pgbench_tellers SET tbalance = tbalance + 2560 WHERE tid = 6; | 885704527939071629UPDATE pgbench_tellers SET tbalance = tbalance + -65 WHERE tid = 7; | 885704527939071629UPDATE pgbench_tellers SET tbalance = tbalance + -136 WHERE tid = 9; | 885704527939071629(5 rows)复制
从应用程序的角度来看,所有这些查询都是相同的,但它们的文本略有不同,因此很难在工作负载中找到模式。然而,使用查询 ID,我们可以清楚地识别某些类型的查询的数量,并更轻松地评估性能问题。例如,我们可以按查询 ID 分组,看看是什么让数据库保持繁忙:
SELECT COUNT(*), state, query_id FROM pg_stat_activity WHERE backend_type = 'client backend' GROUP BY 2, 3;count | state | query_id-------+--------+----------------------40 | active | 8857045279390716299 | active | 76605088309618619801 | active | -78103156035625529721 | active | -3907106720789821134(4 rows)复制
当您在自己的系统上运行此程序时,您可能会发现查询 ID 与此处显示的不同。这是因为查询 ID 依赖于 Postgres 查询的内部表示,它可能依赖于体系结构,并且还考虑表的内部 ID 而不是它们的名称。
查询 ID 信息也可以log_line_prefix
通过新的 %Q 选项获得,从而更容易获得链接到查询的 auto_explain 输出:
2021-05-21 08:18:02.949 UTC [7176] [user=postgres,db=postgres,app=pgbench,query=885704527939071629] LOG: duration: 59.827 ms plan:Query Text: UPDATE pgbench_tellers SET tbalance = tbalance + -1902 WHERE tid = 6;Update on pgbench_tellers (cost=4.14..8.16 rows=0 width=0) (actual time=59.825..59.826 rows=0 loops=1)-> Bitmap Heap Scan on pgbench_tellers (cost=4.14..8.16 rows=1 width=10) (actual time=0.009..0.011 rows=1 loops=1)Recheck Cond: (tid = 6)Heap Blocks: exact=1-> Bitmap Index Scan on pgbench_tellers_pkey (cost=0.00..4.14 rows=1 width=0) (actual time=0.003..0.004 rows=1 loops=1)Index Cond: (tid = 6)复制
想要链接auto_explain
and pg_stat_statements
,等不及 Postgres 14 了?
我们构建了自己的开源查询指纹机制:https://pganalyze.com/blog/pg-query-2-0-postgres-query-parser#fingerprints-in-pg_query-a-better-way-to-check-if-two-queries-are-identical,该机制根据查询的文本唯一地标识查询。这在 pganalyze 中用于将 EXPLAIN 计划与查询匹配,您也可以在您自己的脚本中使用它,以及任何 Postgres 版本。
Postgres 14 版本中还有 200 多项其他改进!
这些只是新 Postgres 版本中的许多改进中的一部分。您可以在发行说明中找到有关新功能的更多信息,例如:
新的预定义角色
pg_read_all_data
/pg_write_all_data
授予全局读取或写入权限如果客户端断开连接,自动取消长时间运行的查询
当可移动索引条目的数量微不足道时,Vacuum 现在会跳过索引清理
每个索引信息现在包含在 autovacuum 日志输出中
现在可以使用非阻塞方式分离分区
ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY
还有很多。现在是帮助测试的时候了!
从官方软件包存储库下载 beta1https://www.postgresql.org/download/ ,或从源代码构建它。从现在开始的几个月内,我们都可以为使 Postgres 14 成为稳定版本做出贡献。
结论
在 pganalyze,我们对 Postgres 14 感到很兴奋,希望这篇文章也能引起您的兴趣!Postgres 再次展示了有多少小的改进使它成为一个稳定、值得信赖的数据库,由社区构建,为社区服务。
