




在Flink使用场景中,常常需要获取外部配置或规则数据后进行计算或规则匹配,同时当外部数据发生变化时,Flink中程序也要保持更新,有以下几种方式可以实现
在算子的open()方法中读取MySQL或其他存储介质,获取全量维表信息比如在算子RichMapFunction的open()方法中获取全部数据,然后在算子中进行使用,这种方法的缺点是如果外部数据更新了Flink是没法知道的,这就需要在开启一个定时任务定时从MySQL中获取最新的数据。
数据不需要存储,仅需要用到外部数据的时候去进行查询,可以保证查询到的数据是最新的,但是对于吞吐量较高的场景,可能与外部(比如MySQL)交互就变成了 Flink任务的瓶颈,虽然可以设置为异步I/O的形式进行交互优化,但优化程度一般有限。
需要设置过期时间或者定时更新数据,当数据到达过期时间后从新从外部获取,或者定时从外部捞取数据进行更新,不能在外部数据发生变动时,及时更新到Flink程序中。
预加载和本地缓存难以应对当外部数据发生变化时,数据实时在Flink中保持更新。
类似于全局性共享的数据,详见官方文档
https://flink.apache.org/2019/06/26/broadcast-state.html
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/stream/state/broadcast_state.html
广播变量创建后,它可以运行在集群中的任何function上,而不需要多次传递给集群节点,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降。我们可以把一个dataset或者不变的缓存对象(例如maplist集合对象等)数据集广播出去,然后不同的任务在节点上都能够获取到,并在每个节点上只会存在一份,而不是在每个并发线程中存在。
如果不使用broadcast,则在每个节点中的每个任务中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。广播变量,可以借助下图辅助理解。
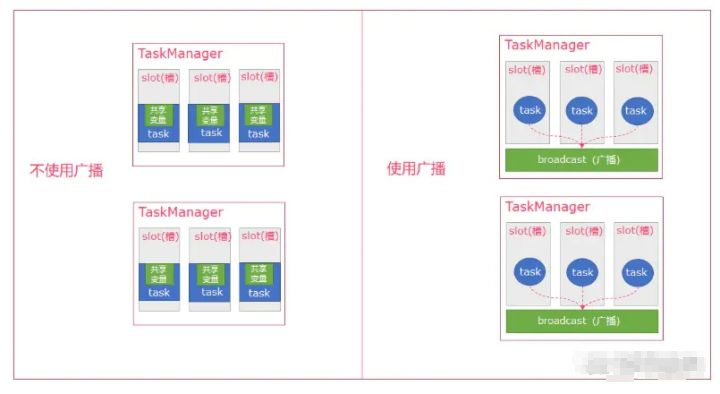
根据广播使用场景将广播的类型分为广播变量和广播流(其实广播原理是一样的)。
将广播的数据作为一个整体或对象广播,比如从MySQL中一次获取全部数据,然后广播出去,因为数据在MySql中,如果MySql中某条记录发生变动,Flink的souce是没法知道,也不会广播。所以只能在souce中定时从MySql中获取全部数据,然后广播更新。
示例数据格式:
kafka源流数据,只有itemid,没有ip和port{"host":"orcl", "itemid":"7875", "value":1}{"host":"orcl2", "itemid":"7876", "value":2}规则数据集在MySql,itemid关联ip和portitemid ip port7875 192.168.199.105 15217876 192.168.199.106 1526
自定义MySql source, 定时 从Mysql获取全部数据
@Overridepublic void run(SourceContext<HashMap<String, Tuple2<String, Integer>>> ctx) { try { while (isRunning) { HashMap<String, Tuple2<String, Integer>> output = new HashMap<>(); ResultSet resultSet = preparedStatement.executeQuery(); //每隔60s获取全部外部数据集 while (resultSet.next()) { String itemid = resultSet.getString("itemid"); String ip = resultSet.getString("ip"); int port = resultSet.getInt("port"); output.put(itemid, new Tuple2<>(ip, port)); } ctx.collect(output); Thread.sleep(1000 * 60); } } catch (Exception ex) { log.error("从Mysql获取配置异常...", ex); } }
广播代码实现:
public void processElement(Map<String,Object> value, ReadOnlyContext ctx, Collector<Map<String,Object>> out) throws Exception { //从广播中获取全量数据 ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(ruleStateDescriptor); //获取全部规则数据进行匹配
Map<String, Tuple2<String, Integer>> itemrules= broadcastState.get(null); //规则数据集为空跳过 if(itemrules==null) { return; } //事件流中的itemid Object itemidObj = value.get("itemid"); value kafka流中数据获取itemid if (itemidObj == null) { return; } Tuple2<String, Integer> itemruld = itemrules.get(itemidObj.toString()); if(itemruld!=null){ //匹配成功增加ip,port字段 value.put("ip", itemruld.f0); value.put("port", itemruld.f1); out.collect(value); }}@Overridepublic void processBroadcastElement(HashMap<String, Tuple2<String, Integer>> value, Context ctx, Collector<Map<String,Object>> out) throws Exception { //数据全部更新 BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx .getBroadcastState(ruleStateDescriptor); //每次更新全部规则数据 broadcastState.put(null, value); System.out.println("规则全部更新成功,更新item规则:" + value);}
执行结果:
//itemid=7875关联ip=192.168.199.104{host=orcl, itemid=7875, value=1, ip=192.168.199.104, port=1521}//手动将mysql中的ip=192.168.199.104改为ip=192.168.199.105,在source 休眠结束后将会更新数据规则更新成功,更新item规则:{7875=(192.168.199.105,1521), 7876=(192.168.199.106,1526)}//itemid=7875关联ip=192.168.199.105{host=orcl, itemid=7875, value=1, ip=192.168.199.105, port=1521}
这种方式和预加载很像,都是通过定时任务加载全部数据,只不过是方法的位置不同,一个是在自定义source中设置休眠时间,另外一个是在算子的open方法中设置定时任务,广播变量的方式同样无法做到数据修改后实时更新。
当数据来源于kafka时,Flink消费kafka获取流,将流数据存储在广播状态中,称之为广播流,不同于广播变量一次获取全部数据,广播流是kafka新增一条记录就将这条记录存储到广播中,那广播流如何实现外部数据的新增和更新?
kafka源流数据,只有itemid,没有ip和port{"host":"orcl", "itemid":"7875", "value":1}{"host":"orcl2", "itemid":"7876", "value":2}规则数据集在kafka,itemid关联ip和port{"itemid":"7875","ip":"192.168.199.104","port":1521}{"itemid":"7876","ip":"192.168.199.106","port":1526}
2.1 外部数据新增和修改记录
// 广播状态底层结构是Map结构//kafka中的数据,flink消费后存储到广播状态,在广播状态中以itemid为key进行存储{"itemid":"7875","ip":"192.168.199.104","port":1521}{"itemid":"7876","ip":"192.168.199.106","port":1526}//新增 往kafka写入新记录(key不相同),flink会持续消费kafka并将数据通过Map的put()方法存入广播状态//修改 往kafka写入新记录(key相同),put()方法覆盖之前的这条记录以达到更新的目的//比如需要更新itemid的ip和port值,要求往kafka中写入一条新数据,比如更新itemid 7875的ip和port{"itemid":"7875","ip":"192.168.199.105","port":1525}
2.2 删除记录
//kafka中的数据,flink消费后存储到广播状态,以itemid为key进行存储{"itemid":"7875","ip":"192.168.199.104","port":1521}{"itemid":"7876","ip":"192.168.199.106","port":1526}//如果需要删除某条记录,往kafka中写入带有key的数据和删除标记即可//比如删除itemid为7875的记录,要求往kafka中写入一条新数据,程序删除广播中itemid7875的记录{"itemid":"7875","isRemove":true}
由于消费kafka流是实时的,kafka的新记录会实时进行消费,根据新记录的内容对广播数据实时的进行新增,修改或删除
同时由于kafka中的数据是不可变的,当程序需要重启时,只需从头消费kafka即可,由于具有幂等性,最终的广播数据是不会变的。
示例代码
//Flink消费外部kafka规则数据作为流FlinkKafkaConsumer<ItemRuleEntiy> ruleKafkaConsumer = new FlinkKafkaConsumer<ItemRuleEntiy>("topic",new ItemRuleEntiyPojoSchema(),properties);DataStream<ItemRuleEntiy> ruleStream = env.addSource(ruleKafkaConsumer);
//广播方法@Overridepublic void processBroadcastElement(ItemRuleEntiy value, BroadcastProcessFunction<Map<String, Object>, ItemRuleEntiy, Map<String, Object>>.Context ctx, Collector<Map<String, Object>> out) throws Exception { BroadcastState<String, ItemRuleEntiy> broadcastState = ctx.getBroadcastState(ruleStateDescriptor); if (StringUtils.isNoneBlank(value.getItemid())) { System.out.println("获取到新的广播规则:" + value); //相比广播变量,这里每次只存一条规则,相同key则覆盖修改 broadcastState.put(value.getItemid(), value); 存放数据到广播 }}@Overridepublic void processElement(Map<String, Object> value, BroadcastProcessFunction<Map<String, Object>, ItemRuleEntiy, Map<String, Object>>.ReadOnlyContext ctx, Collector<Map<String, Object>> out) throws Exception { ReadOnlyBroadcastState<String, ItemRuleEntiy> broadcastState = ctx.getBroadcastState(ruleStateDescriptor); Object itemidObj = value.get("itemid"); 源kafka流中数据获取itemid if (itemidObj == null) { return; } // 根据item从广播数据中查找规则,能查到,则增加ip,port字段 ItemRuleEntiy itemRule = broadcastState.get(itemidObj.toString()); if (itemRule != null) { 从广播中捞取到数据时 value.put("ip", itemRule.getIp()); value.put("port", itemRule.getPort()); out.collect(value); }}
执行结果
// 所有广播规则数据:7875={itemid=7875, ip=192.168.199.104, port=1521}7876={itemid=7876, ip=192.168.199.106, port=1526}//itemid=7875关联ip=192.168.199.104({host=orcl, itemid=7875,value=1, ip=192.168.199.104, port=1521},7875)//kafka写入{itemid=7875, ip=192.168.199.105, port=1521}
获取到新的广播规则:{itemid=7875, ip=192.168.199.105, port=1521}
//itemid=7875关联ip=192.168.199.105
{host=orcl,itemid=7875, value=1, ip=192.168.199.105, port=1521},7875)
通过kafka广播流的方式最终实现了Flink与外部数据交互的实时更新,不仅是kafka,还有MQ,甚至文件格式都可以作为广播流,广播流要求数据不能从内部更改(无法作为流消息被实时消费),只能通过新增的方式进行修改和删除(新增记录中key相同的表示覆盖修改,带key和删除标记的表示删除)
相比表(mysql,oracle)只是结果的呈现,日志(kafka或其它队列)是一种带有时间维度(或先后顺序)信息的存储,可以说表是二维的,日志是三维的,通过日志可以复原每个时间点的表,但是表不能还原日志。
广播作为一种流(流明显带有时间特性),所以当不带时间维度的表作为流时,是没法形成真正意义上的流,只能通过定时获取表的全部数据作为伪流,流中每个时间点的数据也只能是全量表数据,同时定时也就没法做到实时获取。只有带时间维度的日志作为流时,才能做到实时获取,而且每次只获取最新的一条记录即可,不用每次获取全部数据。


