




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!


某核心系统业务部分业务迁移到国产数据库OceanBase,但是历史数据仍然需要迁移到Oracle数据库,对数据实时性要求不高,只需要清理前完成1个月的数据迁移即可 。
DataX
1.1 DataX简介
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具,致力于实现包括:关系型数据库(MySQL、Oracle等)、HDFS、Hive、HBase、ODPS、FTP等各种异构数据源之间稳定高效的数据同步功能。

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。
将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中,比较简洁。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
datax的使用
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json复制
{
"job": {
"setting": {
"speed": {
"channel": 100,
"bytes":0
},
"errorLimit": {
"record":"",
"percentage":
}
},
"content": [
{
"reader": {
"name": "oceanbasev10reader",
"parameter": {
"username": "",
"password": "",
"column": [
"*"
],
"connection": [
{
"jdbcUrl":[ ""],
"querySql": [
"select * from ${readTb} PARTITION(${readpartition}) "
]
}
],
"batchSize": 1024
}
},
"writer": {
"name": "oraclewriter",
"parameter": {
"where": "",
"column": ["*"],
"preSql": [],
"connection": [
{
"jdbcUrl": "",
"table": ["${writeTb}"]
}
],
"username": "",
"password": ""
}
}
}
]
}
}复制
channel表示任务并发数。 record: 出错记录数超过record设置的条数时,任务标记为失败. percentage: 当出错记录数超过percentage百分数时,任务标记为失败. bytes表示每秒字节数,默认为0(不限速)。
python /home/admin/tools/datax3/bin/datax.py
/home/admin/ob_ss/ob_to_ora_ss_tbcs5.json -p"-DreadTb=table1
-Dreadpartition=partition1 -DwriteTb=table1 "复制
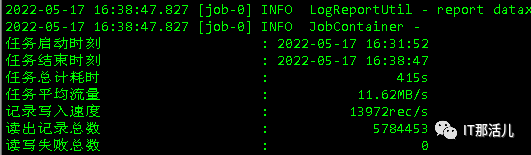
#!/bin/bash
v_table_list='/home/admin/ob_ss/source_table.lst'
v_exec_command='/home/admin/tools/datax3/bin/datax.py'
v_path_json='/home/admin/ob_ss/ob_to_ora_ss_tbcs5.json'
v_path_log='/home/admin/ob_ss/log/'
#从table_name.txt获取表名、分区
for table_name in `cat $v_table_list`
Do
v_source_table_name1=`echo $table_name|awk -F ":" '{print $1}'`
v_source_table_partition=`echo $table_name|awk -F ":" '{print $2}'`
v_target_table_name=`echo $table_name|awk -F ":" '{print $1}'|awk -F "." '{print $2}'`
$v_exec_command --loglevel=info -p "\
-DreadTb=${v_source_table_name1} \
-Dreadpartition=${v_source_table_partition} \
-DwriteTb=${v_target_table_name} \
" $v_path_json >> "$v_path_log"$v_source_table_name1"_"$v_source_table_partition".log复制
DataX的并发参数
Json配置文件读写数据有两种模式:
一种是table模式; 一种是querySql模式.

遇到的问题
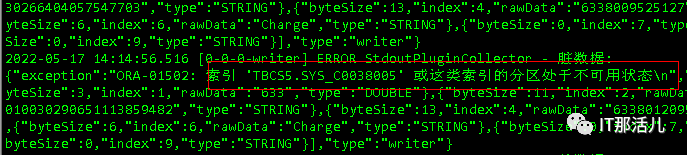
原因:TBCS.SYS_C0038005是全局索引,当在json的preSql设置”alter table ** truncate partition **” 时导致索引失效。 解决办法:rebuild重建索引,preSql设置” truncate table **”.
文章结语:dataX的总体使用相对比较简单,作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的 Reader 插件,以及向目标端写入数据的 Writer 插件,只要有相应的读写插件理论上 DataX 框架可以支持任意数据源类型的数据同步工作。

本文作者:张振浩(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【纯干货】Oracle 19C RU 19.27 发布,如何快速升级和安装?
Lucifer三思而后行
721次阅读
2025-04-18 14:18:38
Oracle RAC 一键安装翻车?手把手教你如何排错!
Lucifer三思而后行
640次阅读
2025-04-15 17:24:06
Oracle数据库一键巡检并生成HTML结果,免费脚本速来下载!
陈举超
558次阅读
2025-04-20 10:07:02
【ORACLE】你以为的真的是你以为的么?--ORA-38104: Columns referenced in the ON Clause cannot be updated
DarkAthena
505次阅读
2025-04-22 00:13:51
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
498次阅读
2025-04-17 17:02:24
【ORACLE】记录一些ORACLE的merge into语句的BUG
DarkAthena
492次阅读
2025-04-22 00:20:37
一页概览:Oracle GoldenGate
甲骨文云技术
473次阅读
2025-04-30 12:17:56
火焰图--分析复杂SQL执行计划的利器
听见风的声音
424次阅读
2025-04-17 09:30:30
3月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
377次阅读
2025-04-15 14:48:05
OR+DBLINK的关联SQL优化思路
布衣
366次阅读
2025-05-05 19:28:36


