




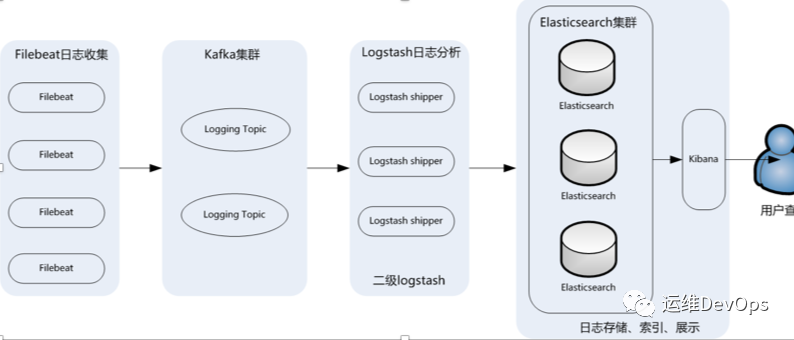
Elasticsearch 是一个搜索和分析引擎 Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,将数据发送到Elasticsearch等存储库中 Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化
mkdir data/elasticsearch复制
cd data/elasticsearchtouch docker-compose.yml复制
version: '3'services:elasticsearch: # 服务名称image: registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch:7.15.2 # 使用的镜像container_name: elasticsearch # 容器名称restart: always # 失败自动重启策略environment:- node.name=elk3 # 节点名称,集群模式下每个节点名称唯一- network.publish_host=192.168.120.131 # 用于集群内各机器间通信,对外使用,其他机器访问本机器的es服务,一般为本机宿主机IP- network.host=0.0.0.0 # 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,即本机- discovery.seed_hosts=192.168.120.129,192.168.120.130,192.168.120.131 # es7.0之后新增的写法,写入候选主节点的设备地址,在开启服务后,如果master挂了,哪些可以被投票选为主节点- cluster.initial_master_nodes=192.168.120.129,192.168.120.130,192.168.120.131 # es7.0之后新增的配置,初始化一个新的集群时需要此配置来选举master- cluster.name=es-cluster # 集群名称,相同名称为一个集群, 三个es节点须一致# - http.cors.enabled=true # 是否支持跨域,是:true 这里设置不起作用,但是可以将此文件映射到宿主机进行修改,然后重启,解决跨域# - http.cors.allow-origin="*" # 表示支持所有域名 这里设置不起作用,但是可以将此文件映射到宿主机进行修改,然后重启,解决跨域- bootstrap.memory_lock=true # 内存交换的选项,官网建议为true- "ES_JAVA_OPTS=-Xms512m -Xmx512m" # 设置内存,如内存不足,可以尝试调低点ulimits: # 栈内存的上限memlock:soft: -1 # 不限制hard: -1 # 不限制volumes:- /data/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml # 将容器中es的配置文件映射到本地,本地必须提前先有该文件,设置跨域, 否则head插件无法连接该节点- esdata:/usr/share/elasticsearch/data # 存放数据的文件, 注意:这里的esdata为 顶级volumes下的一项。ports:- 9200:9200 # http端口,可以直接浏览器访问- 9300:9300 # es集群之间相互访问的端口,jar之间就是通过此端口进行tcp协议通信,遵循tcp协议。volumes:esdata:driver: local # 会生成一个对应的目录和文件,如何查看,下面有说明。复制
#注意,三台机器都要创建cd data/elasticsearchtouch elasticsearch.yml#也可以先随意启动一台elastic,然后通过docker cp usr/share/elasticsearch/config/elasticsearch.yml拷贝出来即可复制
#直接修改配置文件, 进入sysctl.conf文件添加一行(解决容器内存权限过小问题)vi etc/sysctl.confvm.max_map_count=262144 # 添加此行sysctl -p #保存后执行此命令立即生效复制
cd data/elasticsearchdocker-compose up -d复制
network.host: 0.0.0.0http.cors.enabled: true #是否支持跨域http.cors.allow-origin: "*" #表示支持所有域名复制
docker restart elasticsearch复制
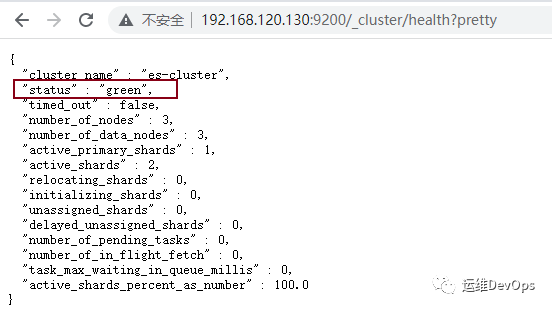
http://192.168.120.130:9200/_cluster/health?pretty复制
curl -X PUT "localhost:9200/index1?pretty" #创建索引index1curl -X DELETE "localhost:9200/index1?pretty" #删除索引index1curl -X GET "localhost:9200/_cat/indices?v" #查询所有索引curl -X GET http://localhost:9200/_cat/nodes?v #获取集群节点列表curl -X GET "localhost:9200/_cluster/health?pretty" #查看集群状态curl -X GET http://localhost:9200/index_name/_settings?pretty #查看索引的副本数以及分片数(number_of_shards:分片数,number_of_replicas: 副本数)curl -X PUT http://localhost:9200/index_name/_settings -H 'content-Type:application/json' -d '{"number_of_replicas":0}' #修改索引的副本数复制
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -v data/elk/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -e "discovery.type=single-node" registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch:7.15.2复制
curl -X PUT “192.168.10.36:9200/_settings” -H ‘Content-Type: application/json’ -d'{“number_of_replicas”:0}’复制
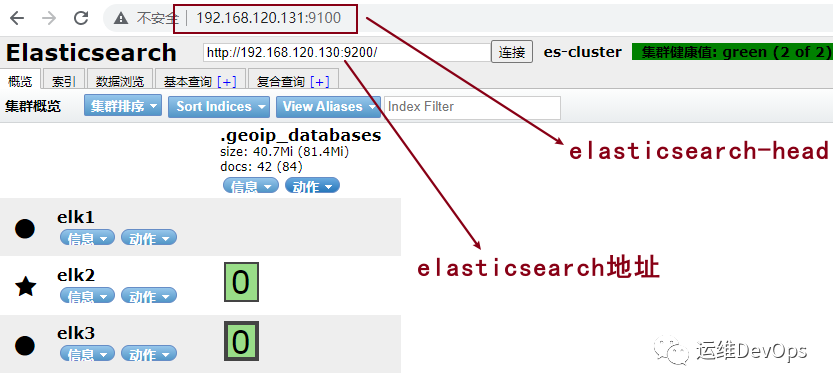
#注:安装在一个节点就可以docker pull mobz/elasticsearch-head:5或docker pull registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch-head:5#运行docker run -d -p 9100:9100 --name elasticsearch-head registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch-head:5复制
http.cors.enabled: truehttp.cors.allow-origin: "*"复制
mkdir data/kibana/config复制
cd /data/kibana/configtouch kibana.yml复制
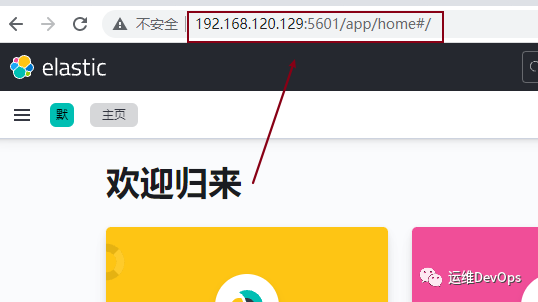
#访问kibana的地址server.publicBaseUrl: "http://192.168.120.129:5601"#Kibana的映射端口server.port: 5601#网关地址server.host: "0.0.0.0"#Kibana实例对外展示的名称server.name: "kibana"#Elasticsearch的集群地址,也就是说所有的集群IPelasticsearch.hosts: ["http://192.168.120.129:9200","http://192.168.120.130:9200","http://192.168.120.131:9200"]#设置页面语言,中文使用zh-CN,英文使用eni18n.locale: "zh-CN"xpack.monitoring.ui.container.elasticsearch.enabled: true复制
docker run -d --name kibana --network=elasticsearch_default -p 5601:5601 -v data/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml -v etc/localtime:/etc/localtime --privileged=true registry.cn-hangzhou.aliyuncs.com/workimage/kibana:7.15.2#指定网络名elasticsearch_default,与elasticsearch运行在同一个网络上复制
tar -xf kafka_2.12-3.0.0.tgz -C /data //解压到指定目录cd /dataln -s kafka_2.12-3.0.0 kafka //创建一个软连接复制
dataDir=/data/zookeeper/datadataLogDir=/data/zookeeper/logsclientPort=2181maxClientCnxns=0admin.enableServer=falsetickTime=2000initLimit=20syncLimit=10server.1=192.168.120.129:2888:3888server.2=192.168.120.130:2888:3888server.3=192.168.120.131:2888:3888#注意:server的值要和后面的id对应参数含义:dataDir:zk数据存放目录dataLogDir:zk日志存放目录clientPort: 客户端连接zk服务端口maxClientCnxns:设置0表示不限制并发连接数tickTime:zk服务器之间或客户端与服务器之间心跳间隔initLimit:允许follower(相对于leader而言的“客户端”)连接并同步到leader的初始化连接时间,它是以tickTime的倍数来表示的syncLimit:Leader与Follower之间发送消息时,请求和应答时间长度,如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃server:2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。复制
mkdir -p /data/zookeeper/{data,log}复制
broker.id=1listeners=PLAINTEXT://192.168.120.129:9092num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600log.dirs=/data/kafka/logsnum.partitions=6num.recovery.threads.per.data.dir=1offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1log.retention.hours=168log.segment.bytes=1073741824log.retention.check.interval.ms=300000zookeeper.connect=192.168.120.129:2181,192.168.120.130:2181,192.168.120.131:2181zookeeper.connection.timeout.ms=18000group.initial.rebalance.delay.ms=0auto.create.topics.enable=truedelete.topics.enable=true参数含义:broker.id:每个server需要单独配置broker id,如果不配置系统会自动配置,例如129机器配置为1,那么130可配置为2,131可配置为3listeners:监听地址,每台机器配置自己的IP地址num.network.threads:接收和发送网络信息的线程数num.io.threads:服务器用于处理请求的线程数,其中可能包括磁盘I/Osocket.send.buffer.bytes:套接字服务器使用的发送缓冲区(SO_SNDBUF)socket.receive.buffer.bytes: 套接字服务器使用的接收缓冲区(SO_RCVBUF)socket.request.max.bytes: 套接字服务器将接受的请求的最大大小(防止OOM)log.dirs: 日志文件目录num.partitions: partition数量num.recovery.threads.per.data.dir: 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1offsets.topic.replication.factor: 偏移量话题的复制因子,为了保证有效的复制log.retention.hours: 日志文件删除之前保留的时间(单位小时),默认168log.segment.bytes: 单个日志文件的大小,默认1073741824log.retention.check.interval.ms: 检查日志段以查看是否可以根据保留策略删除它们的时间间隔zookeeper.connect: ZK主机地址,如果zookeeper是集群则以逗号隔开zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间auto.create.topics.enable:当有producer向一个不存在的topic中写入消息时,是否自动创建该topicdelete.topics.enable:kafka提供了删除topic的功能,但默认并不会直接将topic数据物理删除。如果要从物理上删除(删除topic后,数据文件也一并删除),则需要将此项设置为true复制
mkdir -p /data/kafka/logs复制
echo 1 > /data/zookeeper/data/myid #192.168.120.129echo 2 > /data/zookeeper/data/myid #192.168.120.130echo 3 > /data/zookeeper/data/myid #192.168.120.131复制
#首先启动zookeeper,三台机器都执行cd /data/kafkanohup bin/zookeeper-sever-start.sh config/zookeeper.properties &#启动后可以查看到端口2181如下:[root@elk1 kafka]# netstat -lntup |grep 2181tcp6 0 0 :::2181 :::* LISTEN 20653/java复制
#启动kafka,三台机器都执行cd /data/kafkanohup bin/kafka-server-start.sh config/server.properties &#启动后可以看到监听端口9092在运行:[root@elk3 kafka]# netstat -lntup | grep 9092tcp6 0 0 192.168.120.131:9092 :::* LISTEN 22209/java复制
#创建testtopic,在任意一个节点执行命令如下:cd /data/kafka/bin./kafka-console-producer.sh --bootstrap-server 192.168.120.129:9092 --topic testtopic复制

cd /data/kafka/bin./kafka-console-consumer.sh --bootstrap-server 192.168.120.130:9092 --topic testtopic --from-beginning#注意:上图中消费地址用的是192.168.120.130,因为kafka是一个集群,因此用哪个地址都可以,也可以用192.168.120.129/131#--from-beginning:表示从最开始的时候开始消费复制
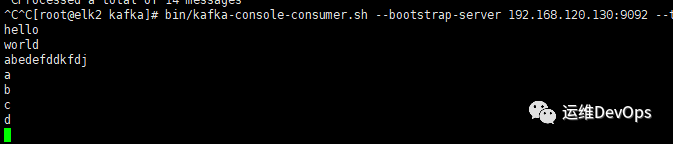
#创建一个topic:./kafka-topics.sh --create --bootstrap-server 192.168.120.129:9092 --replication-factor 2 --partitions 3 --topic mytopic#--replication-factor:指定创建这个topic的副本数#--partitions:指定该topic的分区数#--topic:指定topic的名称#列出现有topic./kafka-topics.sh --bootstrap-server 192.168.120.131:9092 --list#查看topic详细信息./kafka-topics.sh --bootstrap-server 192.168.120.131:9092 --describe --topic mystopic#删除topic./kafka-topics.sh --bootstrap-server 192.168.120.131:9092 --delete --topic mystopic复制
docker pull registry.cn-hangzhou.aliyuncs.com/workimage/logstash:7.15.2复制
mkdir -p /data/logstash/conf.dtouch /data/logstash/logstash.yml复制
path.config: /usr/share/logstash/conf.d/*.confpath.logs: /var/log/logstash#注意:这个文件是要挂载到内部的,因此路径要是内部的路径才对复制
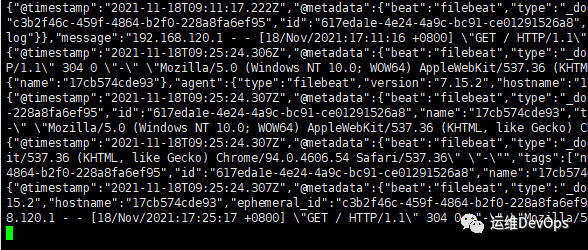
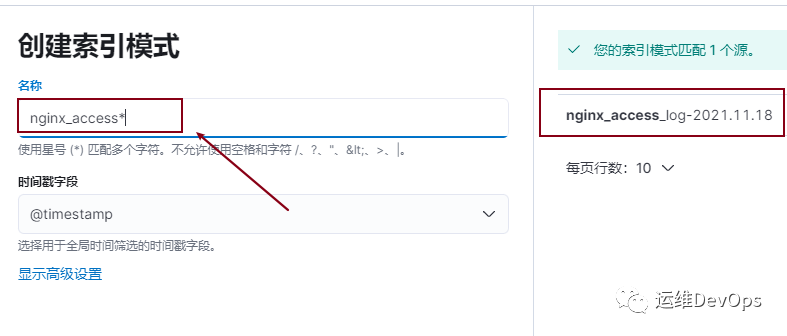
#注意:如果没有此配置文件,logstash容器起不来vim log.conf#内容如下:input {kafka{bootstrap_servers => "192.168.120.129:9092,192.168.120.130:9092,192.168.120.131:9092"group_id => "nginx_access_log"topics => ["nginx_access_log"]codec => json { charset => "UTF-8" }type => "nginx_access"}}output{elasticsearch {hosts => ["192.168.120.129:9200","192.168.120.130:9200","192.168.120.131:9200"]index => "nginx_access_log-%{+YYYY.MM.dd}"}stdout { codec => json }}参数说明:#group_id: 指定消费组,如果不指定,默认为logstash#topic:消费主题,和filebeat中的定义的要一一对应#codec: 转换为json格式,并指定编码#type:定义类型,如果有多个kafka,可以区分#hosts: 指定elasticsearch地址#index: 设置索引,此索引设置后kibana中可以看到#stout: 输入到elasticsearch中的类型为json#input: 输入内容#output:输出内容#filter: 过滤插件,再次没有使用复制
docker run -d --net=elasticsearch_default \-p 5044:5044 -p 5045:5045 --name logstash \-v /data/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml \-v /data/logstash/conf.d/:/usr/share/logstash/conf.d/ \registry.cn-hangzhou.aliyuncs.com/workimage/logstash:7.15.2复制
#要采集哪个机器的日志,就要在这机器上运行filebeatdocker pull registry.cn-hangzhou.aliyuncs.com/workimage/filebeat:7.15.2复制
mkdir -p /data/filebeat/log复制
vim /data/filebeat/filebeat.yml#filebeat自身日志配置logging.level: infologging.to_files: truelogging.files:path: /var/log/filebeatname: filebeatkeepfiles: 7permissions: 0644# 日志输入配置(可配置多个)filebeat.inputs:- type: log #定义采集nginx的access日志enabled: truepaths:- /var/log/nginx/access.logtags: ["nginx-access"]fields:kafka_topic: nginx_access_log #自定义字段,用来区分的multiline:pattern: ^[[:alnum:]] #^[[:alnum:]] 匹配任意数字字母开头negate: truematch: aftermultiline.max_lines: 5000processors:- drop_fields:fields: ["beat","input","source","offset"]#日志输出配置output.kafka:enabled: truehosts: ["192.168.120.129:9092","192.168.120.130:9092","192.168.120.131:9092"]topic: '%{[fields.kafka_topic]}'partition.round_robin:reachable_only: truerequired_acks: 1compression: gzipmax_message_bytes: 1000000#multiline:此参数功能是可以将日志全部发送到kafka而不发生截断,注意其中的pattern后面的正则表达式,要根据实际需要编写,否则可能出现无法匹配到合适的日志文件,导致无法采集,进而无法生成索引复制
docker run -d --name filebeat \-v /data/filebeat/log:/var/log/filebeat \-v /data/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \-v /var/log/nginx:/var/log/nginx \-v /etc/localtime:/etc/localtime \registry.cn-hangzhou.aliyuncs.com/workimage/filebeat:7.15.2复制
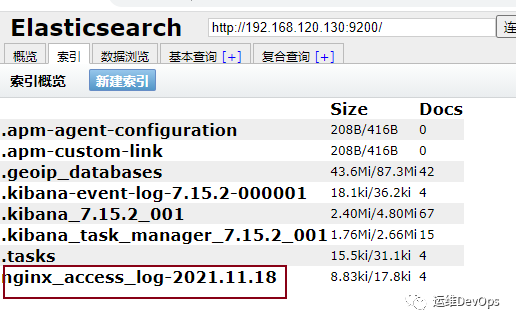
./kafka-console-consumer.sh --bootstrap-server 192.168.120.129:9092 --topic nginx_access_log --from-beginning复制
文章转载自运维DevOps,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
阿里云 Elasticsearch Serverless 检索增强型 8.17 版来袭!
阿里云大数据AI技术
380次阅读
2025-04-18 10:24:15
AI 乱写代码怎么破?使用 Context7 MCP Server 让 AI 写出靠谱代码!
Se7en的架构笔记
135次阅读
2025-04-29 09:53:31
利用 EDB Postgres AI - WarehousePG 替换 Greenplum 实现数据仓库现代化
新智锦绣
69次阅读
2025-04-18 17:28:36
阿里云 Elasticsearch Serverless 检索增强型8.17版免费邀测!
阿里云大数据AI技术
68次阅读
2025-04-15 13:18:15
可观测性方案怎么选?SelectDB vs Elasticsearch vs ClickHouse
SelectDB
63次阅读
2025-05-09 16:48:09
还在用 ELK?你已经 Out 了
GreptimeDB
44次阅读
2025-04-18 17:28:41
PGD4K 正式版发布!同时支持 Kubernetes 和 Openshift 平台
新智锦绣
39次阅读
2025-04-25 10:10:43
炸裂!又一个AI大模型的新方向,彻底爆了!!
铭毅天下Elasticsearch
33次阅读
2025-04-16 10:33:42
「码」上行动,抢滩AI搜索C位!
新智锦绣
26次阅读
2025-04-23 14:33:57
Elasticsearch 稀疏向量嵌入:概述与实现
新智锦绣
25次阅读
2025-04-24 09:53:04
