




作者:MiguelAraújo 译:徐轶韬
MySQL开发团队很高兴宣布MySQL Shell AdminAPI的新8.0维护版本– 8.0.23!除了一些错误修复和较小更改之外,还包括有关监视/故障排除 和性能的一些重要增强。
MySQL Shell AdminAPI
集群诊断
DBA的主要任务包括检查群集的运行方式以及当群集不能100%运行正常时,执行故障排除。AdminAPI将监视信息汇总在以下位置,使得DBA的操作变得非常容易:
<Cluster>.status([options])
在此版本中,我们扩展了status()
命令以提供诊断错误相关的更多信息。
让我们通过一些示例深入研究这些扩展内容。“一张图片胜过千言万语!”
集群成员被驱逐出集群
在8.0.23之前的版本中,每当将集群成员从集群中驱逐出去时,仅简单地显示为(MISSING)
。但是导致成员退出有很多原因,例如组复制被停止,成员崩溃或某些复制错误导致等等。
在组复制报告里提供的实例成员角色功能上,使用extended
选项Cluster.status()具
有价值。但是,它没有提供有关问题原因的任何其他信息。
由于以上这些原因,我们将Cluster.status()的默认输出中包括下面的信息
:
当相应的实例状态不是ONLINE时的memberState。此信息直接来自
performance_schema.replication_group_members
。
每个实例都有一个新的instanceErrors字段,显示可以检测到的非在线实例的诊断信息
以下示例显示了在实例上手动停止了组复制的命令输出:
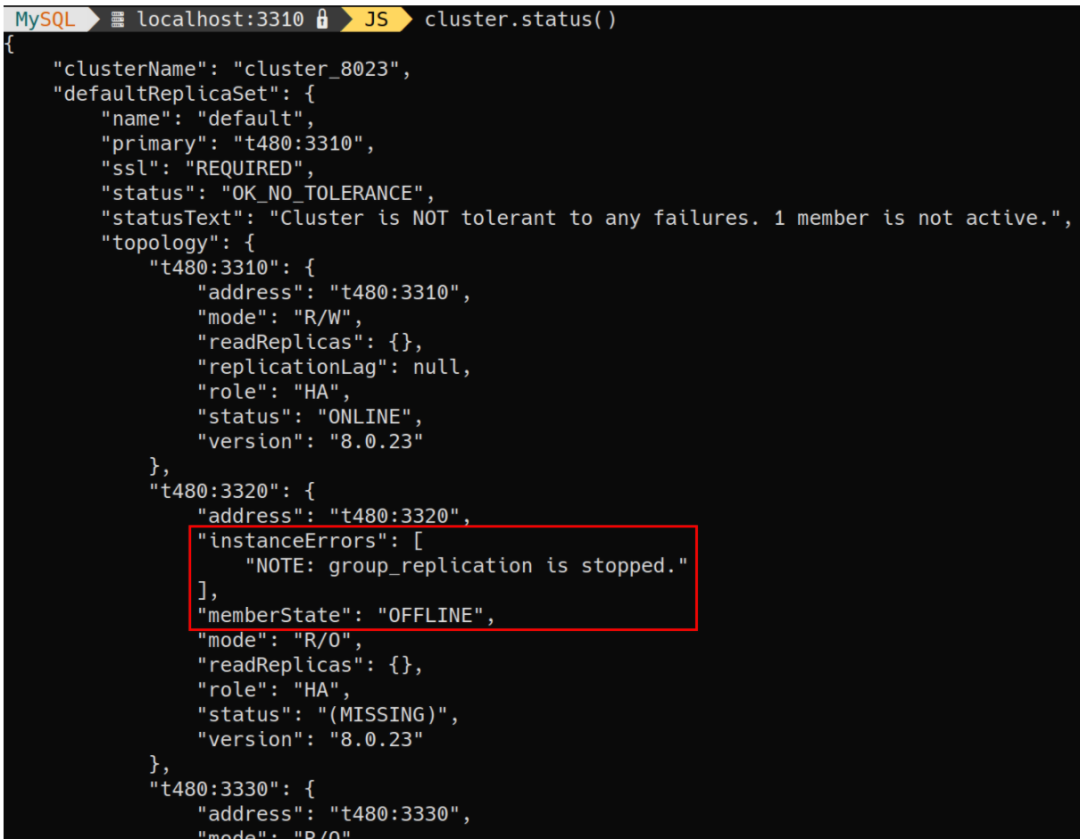
信息取决于实例是否可访问。
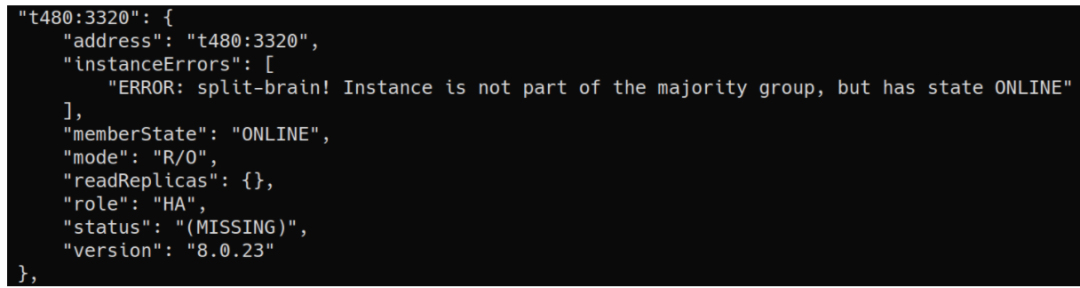
脑裂
只要实例不属于多数组,但它报告自己存在ONLINE
且可到达,就可以检测到脑列:
回放错误
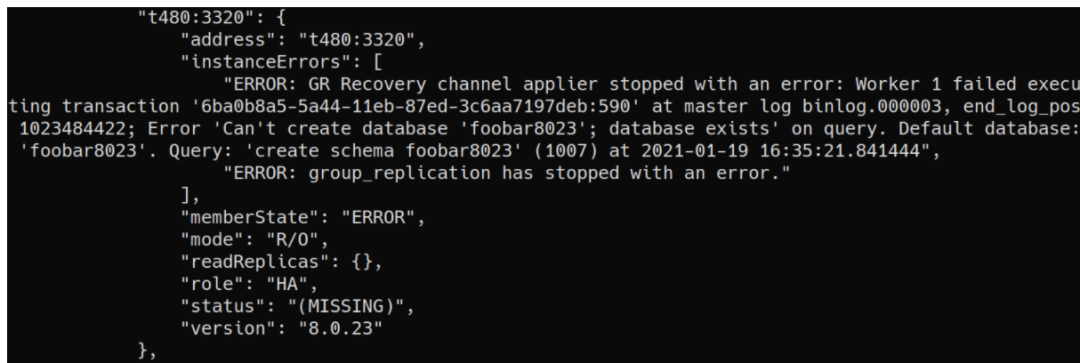
如果发生复制错误,该成员可能会停留在RECOVERING
一段时间,直到最终失败并消失 (MISSING)
。诊断实际情况的唯一方法是检查错误日志。
这对用户是非常不友好的,因此我们还包括检查用来验证成员进入ERROR
状态的原因:
其他诊断
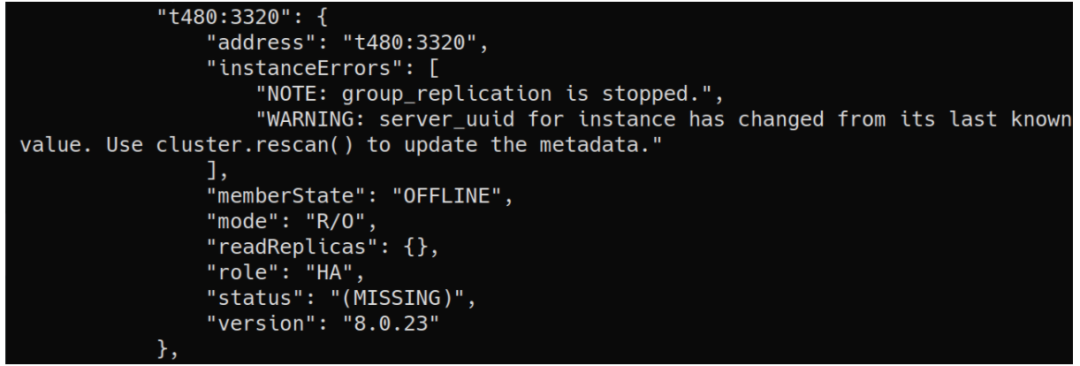
某些特定场景,例如从备份恢复集群成员,即使该成员运行在相同的host:port上,也可能需要对server_uuid进行更改,这样它就可以自动重新加入集群。但是,由于server_uuid被用作实例的唯一标识符,AdminAPI不会理解该实例已重新联接,并将其标记为(MISSING)。
类似地,属于组复制组但不属于元数据的实例现在会在Cluster.status()中标识并报告。
诊断总结
在新的字段instanceErrors中检测并识别了以下问题:
次要成员(
super_read_only
禁用)恢复通道错误
回放通道错误
组复制的成员,但不是元数据的成员
可连接的离线成员(GR插件已停止)
脑裂
成员
server_uuid
与元数据中记录的内容不匹配
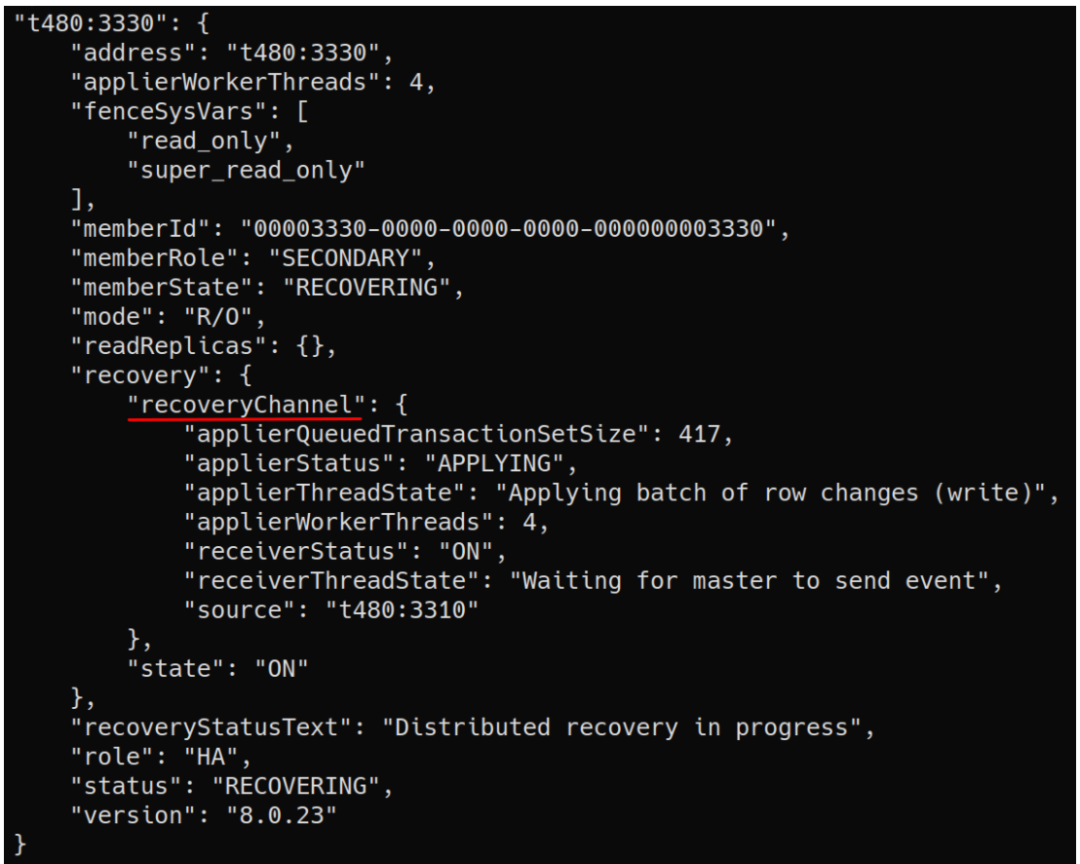
复制信息
与ReplicaSet.status()中提供的信息类似,我们在新的恢复字段中包含了成员执行增量恢复时恢复通道的信息。
注意:仅当扩展的值> 0时,此信息才可用
多线程复制回放
MySQL InnoDB Cluster和InnoDB ReplicaSet使用不同的复制机制,分别是组复制和异步复制。然而,尽管这两种复制协议在数据传播方面是不同的,但都依赖于异步机制来处理和应用binlog更改。从在主节点上提交事务到在从节点上提交事务的时间间隔通常称为复制延迟。
也就是说,任何一种技术都可能遭受复制延迟的困扰。MySQL DBA在生产环境中必须面对的问题之一。
幸运的是,自MySQL 5.7以来,在这方面进行了许多改进。例如,在MySQL 8中,基于每个事务的WRITESET,引入了一种跟踪独立事务的新机制。通过评估哪些事务不具有相互依赖性,并且可以对二进制日志并行执行回放,该机制极大地提高了应用程序的吞吐量。
尽管这些改进在一段时间内是可用的,但为了克服复制延迟问题,需要调整设置,并且在此版本之前,复制应用程序默认使用单线程应用程序。
考虑到许多常见的工作负载具有大量同时发生的小事务,并且大多数现代服务器都具有较高的处理能力,复制中的并行化肯定会有很大的不同!
由于这些原因,InnoDB Cluster和InnoDB ReplicaSet现在默认支持并启用并行复制回放。
必要设定
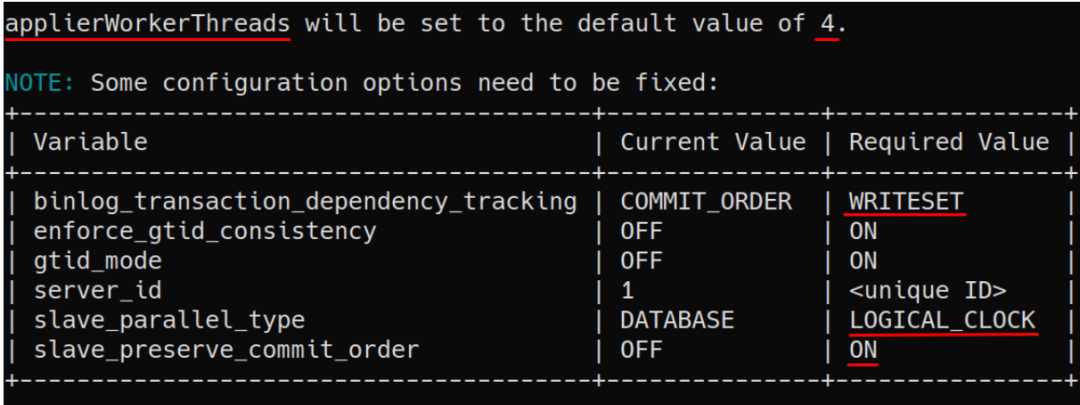
InnoDB Cluster和ReplicaSet要求MySQL服务器具有适当的设置才能运行。为了默认启用并行复制回放,我们将设置扩展包括以下内容:
transaction_write_set_extraction=XXHASH64
(对InnoDB Cluster要求,但对InnoDB ReplicaSet没有要求)slave_parallel_type=LOGICAL_CLOCKbinlog_transaction_dependency_tracking=WRITESETslave_preserve_commit_order=ON
关于如何检查和配置实例以准备使用InnoDB Cluster ReplicaSet的方式没有任何变化,仅将命令扩展为可以自动检查并启用上面列出的设置:
通过以下方法检查要求:
dba.checkInstanceConfiguration()使用以下步骤配置实例:
dba.configureInstance() dba.configureReplicaSetInstance()
下面是一个使用dba.configureInstance()来为InnoDB集群配置实例的示例:
回放线程
多线程复制依赖于多个执行任务的线程。线程的数量可以根据用户的用例进行配置和调整。我们认为4是一个适合典型部署和工作负载的合理数字,因此我们将其设置为默认值。
当为InnoDB Cluster/ReplicaSet配置实例时,可以更改这个默认值。一个名为applierWorkerThreads的新选项被添加到dba.configureInstance() dba.configureReplicaSetInstance()。
例如:
mysql-js> dba.configureInstance("clusteradmin@t480:3330", {applierWorkerThreads: 2, restart: true})复制
而且,与任何其他设置一样,您可以使用.options()命令查看Cluster/ReplicaSet的设置。
调整回放线程的数量
如果需要为正在运行的Cluster / ReplicaSet调整线程数,则可以根据dba.configureInstance() / dba.configureReplicaSetInstance()进行
。与配置实例准备时类似,用户可以更改线程号的当前值:
例如:
mysql-js> dba.configureInstance("clusteradmin@t480:3320", {applierWorkerThreads: 16})复制
注意:请注意,即使您可以更改在线成员的设置,也不会立即生效,但需要重新实例化(停止并启动GR)。
Cluster / ReplicaSet升级会受到影响吗?
当您升级运行早于8.0.23的MySQL服务器和MySQL Shell版本的Cluster或ReplicaSet时,可能不需要在实例上启用多线程复制,因为这些设置不是必需的。
MySQL Shell在运行.status()
命令时会检测到该错误,并相应地指导您进行更改并利用此功能。

修复了一些明显的错误
BUG#26649039 –Shell无法识别具有新UUID的成员重新加入
如果将集群成员从集群中删除,然后使用例如MEB从备份中还原,无论何时实例自动或通过Cluster.rejoinInstance()实例重新加入群集,都会被标记为(MISSING)
。
这是因为AdminAPI使用server_uuidas作为实例的唯一标识符,并且由于server_uuidas可能在备份恢复后发生更改,AdminAPI将不认为该实例是同一实例。
此问题已通过Cluster.status()
诊断程序修复,即重新加入实例后添加了新检查,当通过UUID在元数据上找不到该实例时,将使用其主机和端口对其进行搜索,元数据将根据用于重新加入操作的选项进行更新。
BUG#31757737 – INNODB集群操作应自动连接到主数据库
如果Shell程序的活动会话是与集群的次要成员建立的,则InnoDB 集群操作(例如Cluster.addInstance()
或Cluster.rejoinInstance()
将失败。但是,考虑到Shell能够知道哪个成员是主要成员,并且所有集群成员必须具有相同的cluster-admin凭据,这些命令应该不会失败,并且应该自动使用主要成员的连接。
这正是解决该错误的方法。现在,无论从哪个成员来获取集群的对象,都将在正确的成员上执行操作。
BUG#27882663 – CLUSTER.STATUS()未显示不在元数据中的活动GR成员
cluster .status()操作没有显示不属于元数据的集群成员的信息。这些信息只有在使用Cluster.rescan()时才能看到。如果不显示组复制组中的所有成员,即使元数据中没有出现,也会隐藏集群(非InnoDB集群管理)中实例的意外/不希望的参与。
这与Cluster.status()中的改进一起得到了修复,方法是列出参与集群的成员(即使没有在元数据中注册),并向用户指示将这些成员包含到元数据中的步骤。
BUG#32112864 - REBOOTCLUSTERFROMCOMPLETEOUTAGE()不排除选项“REMOVEINSTANCES”列表中的实例
dba.rebootClusterFromCompleteOutage()需要在MySQL Shell上激活会话:
获取在元数据中注册的集群成员。
确定哪个集群成员具有GTID超集。
如果活动会话不是针对具有GTID超级集的成员,则该命令将中止并向用户指示具有GTID超集的实例。
但是,GTID超集检查是使用Shell可以访问的所有实例(在群集的元数据中注册)完成的。
如果实例具有不同的GTID集,并且用户希望将其从群集中明确删除,则该操作将被阻止,因为命令行管理程序无法确定哪个实例具有GTID超集。根据不同的观点,可以将不同的实例视为最新实例。
另外,用户应该可以通过选择一个特定的实例来重新启动集群,即使它不是最新的,只要它们表明不打算使用命令的选项/提示重新加入其他实例即可。
修补程序通过确保如果用户显式设置removeInstances
变量或对有关实例重新加入的提示回答“No”来解决此问题,必须从GTID超集验证中排除这些实例。
BUG#31428813 – DBA.UPGRADEMETADATA()失败,并出现错误:“ UNKNOWN COLUMN ‘MYSQL.ROUTER’ IN ‘FIELD LIST’
如果在sql_mode中使用ANSI_QUOTES,则使用dba.upgradeMetadata()升级元数据模式会失败。
这是由特定查询导致的,该查询将数据插入元数据架构的路由器表中,该表使用双引号将字符串引起来。当将sql_mode设置为使用ANSI_QUOTES时,MySQL将"
视为标识符引号而不是字符串引号,从而在运行该查询时导致错误。
这个补丁通过确保upgrade metadata命令准备AdminAPI使用的会话来修复这个问题,AdminAPI除了其他完整性检查外,它确保该会话使用的sql_mode使用默认值,以避免用户集不兼容的设置。
BUG#32152133 –替换 MASTER/START SLAVE 术语
与MySQL Server一样,复制相关功能中已弃用的术语已更新,同时在必要时保持向后兼容性。
专门处理了以下MySQL复制命令:
CHANGE MASTER TOSTART SLAVE UNTIL MASTER_LOG_POS, MASTER_LOG_FILE
替换成新的:
CHANGE REPLICATION SOURCE TOSTART REPLICA UNTIL SOURCE_LOG_POS, SOURCE_LOG_FILE
及其参数:
MASTER_HOSTMASTER_PORTMASTER_*
新的参数:
SOURCE_HOSTSOURCE_PORTSOURCE_*
您可以在MySQL术语更新博客文章中了解有关常规更改的信息。
立即尝试并向我们发送您的反馈意见
可从以下链接下载MySQL Shell 8.0.23 GA:
MySQL社区下载网站:https : //dev.mysql.com/downloads/shell/
MySQL Shell也可以在GitHub上找到:https: //github.com/mysql/mysql-shell
与往常一样,我们渴望听听社区的反馈!您也可以通过 Slack的#shell 和 #mysql_innodb_cluster与我们 联系:https : //mysqlcommunity.slack.com/
MySQL Shell的文档可以在https://dev.mysql.com/doc/mysql-shell/8.0/en/中找到 ,InnoDB Cluster和InnoDB ReplicaSet的正式文档可以在《AdminAPI用户指南》中找到。
更改和错误修复的完整列表可以在8.0.23 Shell 发行说明中找到。
感谢您关注“MySQL解决方案工程师!”

