




创业公司利用大数据和人工智能开发更具创新性的商业模式,这一说法并不新鲜。因此,大数据和人工智能问题在高管和技术论坛上无处不在。但他们经常在如此高的层次上讨论,以至于人们最终错过了这类公司构建模块的细节。
在这篇博文中,我将介绍现代公司最有价值的组成部分之一:实时处理数据的能力,这使得零售、媒体和娱乐以及金融等行业能够进行数据驱动的决策。例如:
-
行为和购买分析可以实现更具针对性的即时产品和建议,为客户提供更个性化的体验。
-
潜在客户跟踪促使销售团队专注于最高效的营销渠道,而不是花时间在性能较差的渠道上。
-
支出模式分析使金融机构能够在欺诈发生之前发现欺诈,有效防止损失。
但是,如果你工作的公司不是在实时数据时代呢?首先,你并不孤单。许多公司仍在批处理作业中处理数据,这可能意味着分析数据延迟1、7…30天。这种情况发生在各种规模的公司身上,但这并不意味着如果该公司打算更进一步,就没有低挂果实。
有人可能认为,一家公司需要大量的工程工作来组装实时分析管道,包括现代化事务系统和建立事件流平台,但情况并非总是如此。例如,变更数据捕获(也称CDC)为数据的移动带来了一种无痛的方法,尤其是从事务性数据库到数据湖。稍后我将演示它是如何工作的。
什么是变更数据捕获?
根据定义,变更数据捕获是一种数据集成方法,它基于对企业数据源所做变更的识别、捕获和交付(来源:维基百科)。它解决了与在企业内安全、可靠、快速、一致地移动数据相关的问题。大多数变更数据捕获产品的一个常见特征是对源数据库的影响较小,尤其是那些依赖于日志扫描机制的数据库。
变更数据捕获有多种用途:
-
事务性数据库更改触发的最小工作量数据流。
-
实时数据库复制以支持数据仓库或云迁移。
-
实时分析支持数据从事务环境传输到分析环境,延迟非常低。
-
实现数据库迁移,零停机时间。
-
用于调试和审计目的的时间旅行日志记录。
有许多更改数据捕获解决方案。Debezium可能是最流行的开源解决方案,经常与Apache Kafka一起使用以支持事件流。HVR已有十多年的历史,目前仍在积极开发中。它可以部署在领先的云提供商中,但我不会说它是一个云原生解决方案,因为它需要彻底的设置。另一方面,Arcion和Strim是具有云和自托管部署模型的较新技术。
在这一点上,我想您可能想知道更改数据捕获是如何工作的,所以让我们来看一些实际操作的东西。
使用Arcion更改数据捕获的实践指南
为了便于说明,假设一家零售公司在其交易环境中有大量发.票数据,并且没有利用这些数据做出明智的决策。他们的目标是投资于数据分析,但其内部数据中心不支持此类额外的工作负载,因此他们决定从雪花开始评估更合适的云解决方案。考虑到他们仍在评估云产品,他们希望以尽可能少的开发工作释放分析能力。实时数据库复制非常适合此用例。
我需要一些零售发.票来演示它是如何工作的,Kaggle上有两个免费的零售数据集示例。我将使用在线零售II UCI,因为它将很好地满足我们的目的,并允许我们轻松地使用原始数据将数据的一对一副本创建到我们在雪花中创建的数据湖中。这将有效地为我们的数据湖创建一个青铜层方法。
MySQL将用作源代码。它是一种广泛使用但易于设置的关系数据库,因此大多数人将遵循我所做的,并且可能能够将这些步骤复制到其他数据库中。
由于Smowflake在市场上的巨大影响力,它将被用作目标数据仓库。《财富》500强中有近一半的人使用它(来源:Snowflake Fast Facts 2022 Report),而且,读者也可以将这些步骤复制到其他数据仓库中。
我还将使用Arcion,因为它提供了云本机部署选项以及OLTP和数据仓库连接器支持,从而实现了一个简单的设置过程。
MySQL安装程序
1、创建源数据库
CREATE DATABASE arcion_cdc_demo;
USE arcion_cdc_demo;
2、创建源表
CREATE TABLE IF NOT EXISTS transactions (
transaction_id BIGINT NOT NULL AUTO_INCREMENT,
invoice VARCHAR(55) NOT NULL,
stock_code VARCHAR(55) NOT NULL,
description VARCHAR(255),
quantity DECIMAL(9,3) NOT NULL,
invoice_date DATETIME NOT NULL,
price DECIMAL(10,2) NOT NULL,
customer_id DECIMAL(9,1),
country VARCHAR(255),
PRIMARY KEY (transaction_id)
);
3、为复制事务创建用户
CREATE USER `cdc-replication-agent`@`%`
IDENTIFIED WITH mysql_native_password BY `<password>`;
4、仅授予用户所需的最低权限
GRANT REPLICATION SLAVE, REPLICATION CLIENT
ON *.*
TO `cdc-replication-agent`@`%`;
GRANT SELECT
ON arcion_cdc_demo.transactions
TO `cdc-replication-agent`@`%`;
5、允许外部网络访问MySQL(默认端口3306)
这一步取决于承载MySQL服务器的基础设施,详细说明不在本文的讨论范围内。如果出于任何原因不允许外部网络访问,请考虑在MySQL网络中设置Arcion的Replicant代理,而不是使用Arcion Cloud。
6、将数据加载到源表中
INTO TABLE transactions
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
IGNORE 1 ROWS
(invoice, stock_code, description, quantity, invoice_date, price, @customer_id, country)
SET customer_id = NULLIF(@customer_id, '');
7、将二进制日志格式设置为ROW
您还需要确保MySQL实例二进制日志格式(binlog_format)设置为ROW,以支持带有Arcion的CDC。这可以通过多种方式完成,具体取决于实例的部署方式和位置。下面是一个在Amazon RDS上运行MySQL的示例。
SnowFlake设置
1、创建目标数据库
CREATE DATABASE demo;
USE demo;
2、创建目标模式
CREATE SCHEMA arcion_cdc;
USE demo.arcion_cdc;
3、创建目标表
CREATE TABLE IF NOT EXISTS transactions (
transaction_id NUMBER,
invoice VARCHAR(55),
stock_code VARCHAR(55),
description VARCHAR(255),
quantity NUMBER(9,3),
invoice_date TIMESTAMP_NTZ(9),
price NUMBER(10,2),
customer_id NUMBER(9,1),
country VARCHAR(255)
);
4、为复制事务创建角色和用户
CREATE ROLE dataeditor;
CREATE USER cdcreplicationagent
PASSWORD = '<password>';
GRANT ROLE dataeditor
TO USER cdcreplicationagent;
ALTER USER IF EXISTS cdcreplicationagent SET DEFAULT_WAREHOUSE = COMPUTE_WH;
ALTER USER IF EXISTS cdcreplicationagent SET DEFAULT_ROLE = dataeditor;
5、授予角色所需的权限
GRANT DELETE, INSERT, SELECT, UPDATE
ON TABLE demo.arcion_cdc.transactions
TO ROLE dataeditor;
GRANT ALL PRIVILEGES ON WAREHOUSE COMPUTER_WH TO ROLE dataeditor;
GRANT CREATE DATABASE ON ACCOUNT TO ROLE dataeditor;
Arcion Cloud CDC设置
创建了数据源和目标后,我们现在将登录到Arcion Cloud以设置复制管道,从而启用CDC。你可以注册并登录Arcion。
一旦登录到Arcion云,我们将登陆复制屏幕。在这里,我们将单击屏幕中间的New Replication按钮。
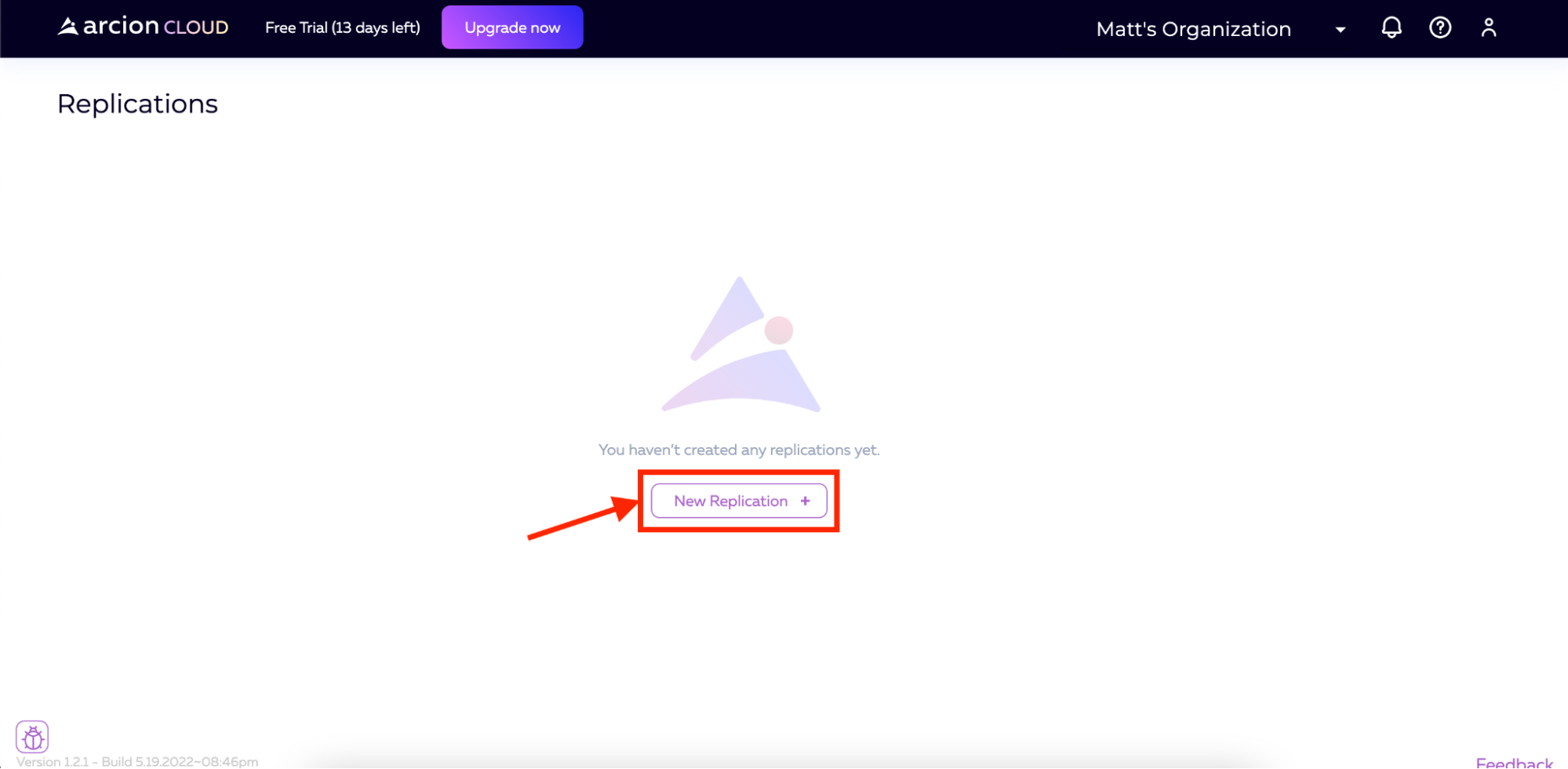
接下来,我们将选择复制模式和写入模式。有几个选项可以满足您的需要。对于复制模式,Arcion支持:
-
快照(初始负载)
-
完整(快照+CDC)
-
对于写入模式,Arcion支持:
-
更换
-
截断
出于我们在这里的目的,我们将选择复制模式为完全,写入模式为截断。您还将看到,我将复制命名为“MySQL to Snowflake”。
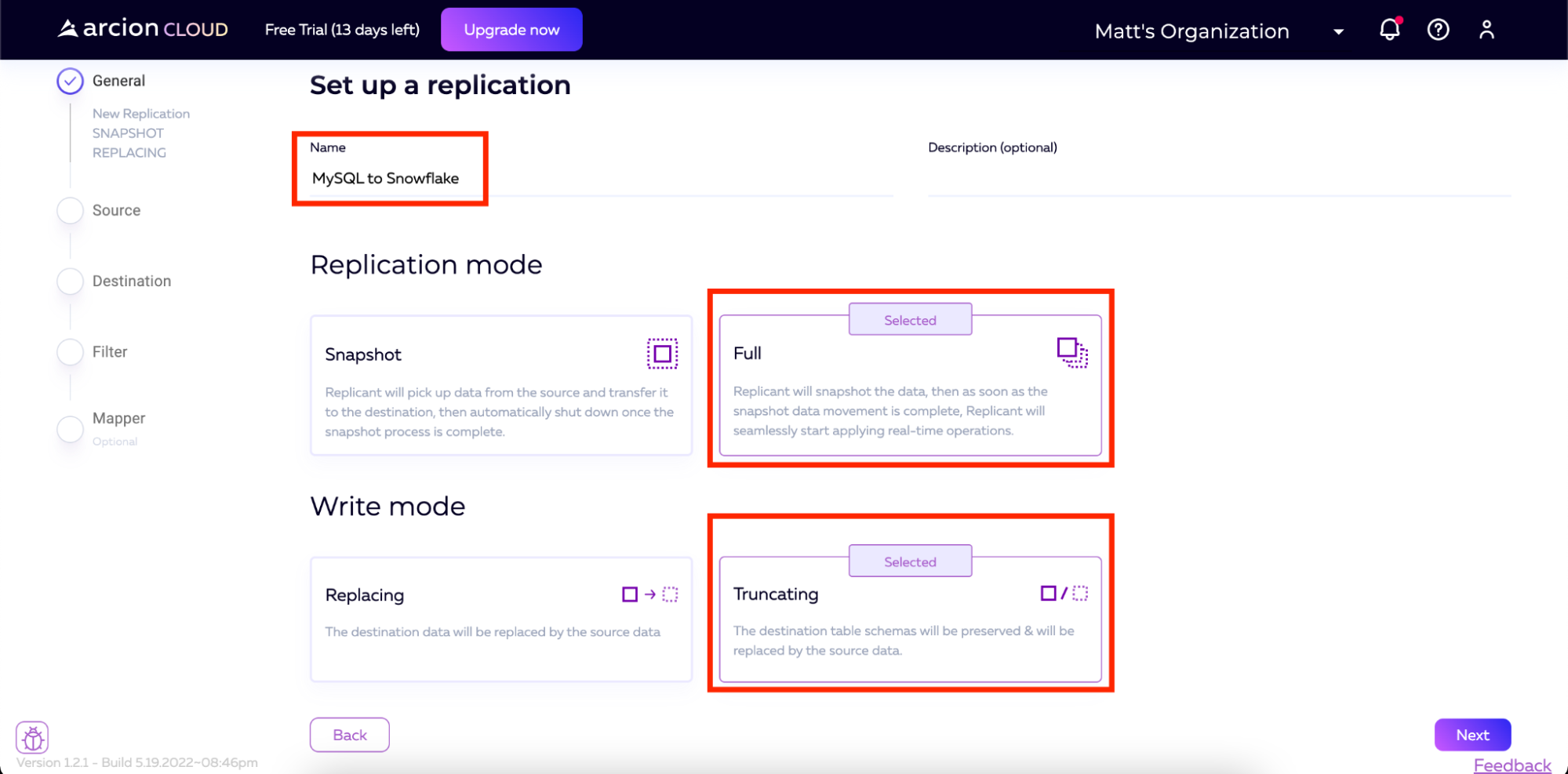
填充名称并选择复制和写入模式后,单击屏幕底部的下一步。
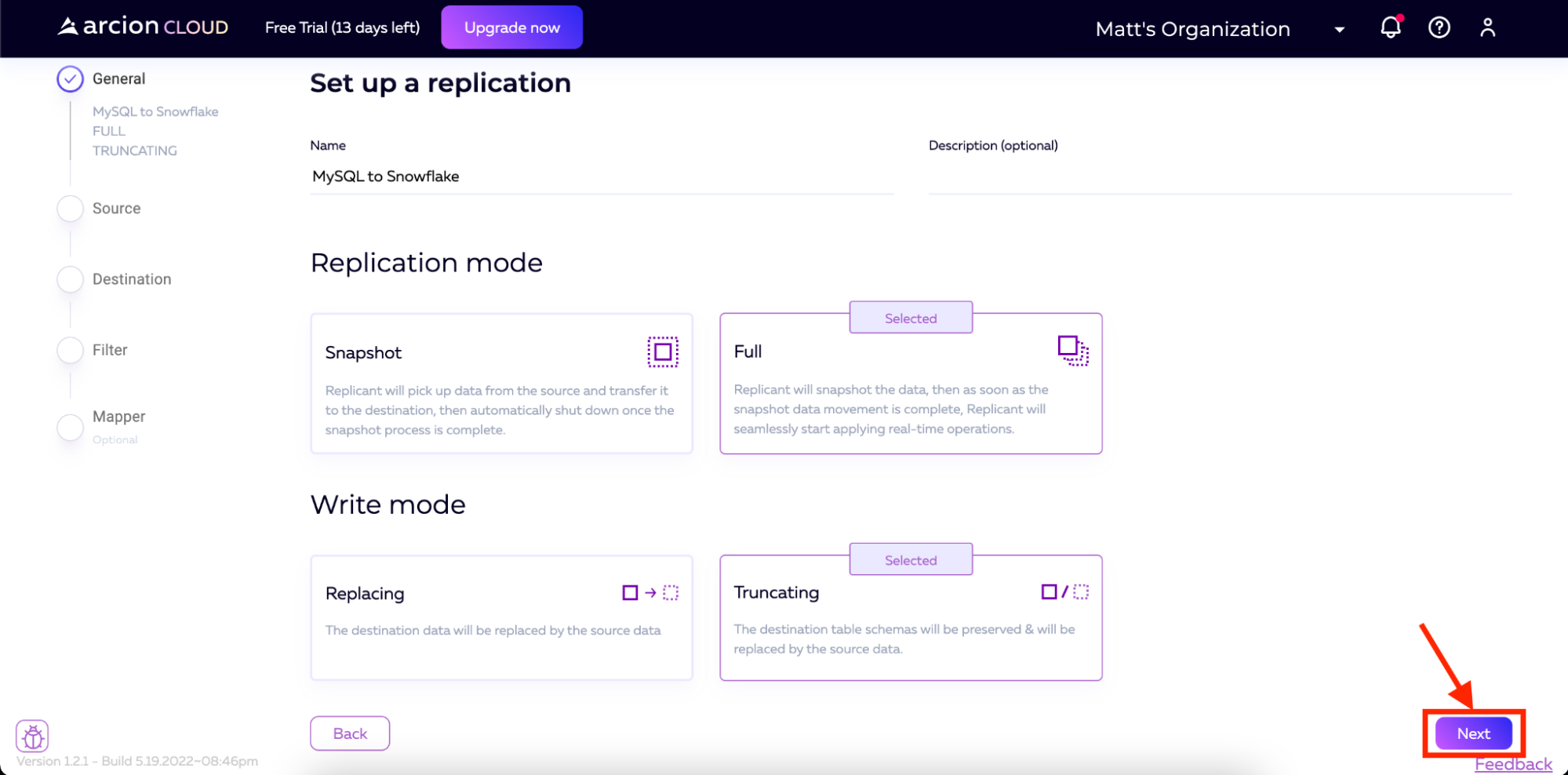
然后我们进入源代码屏幕。从这里,我们将单击创建新按钮。
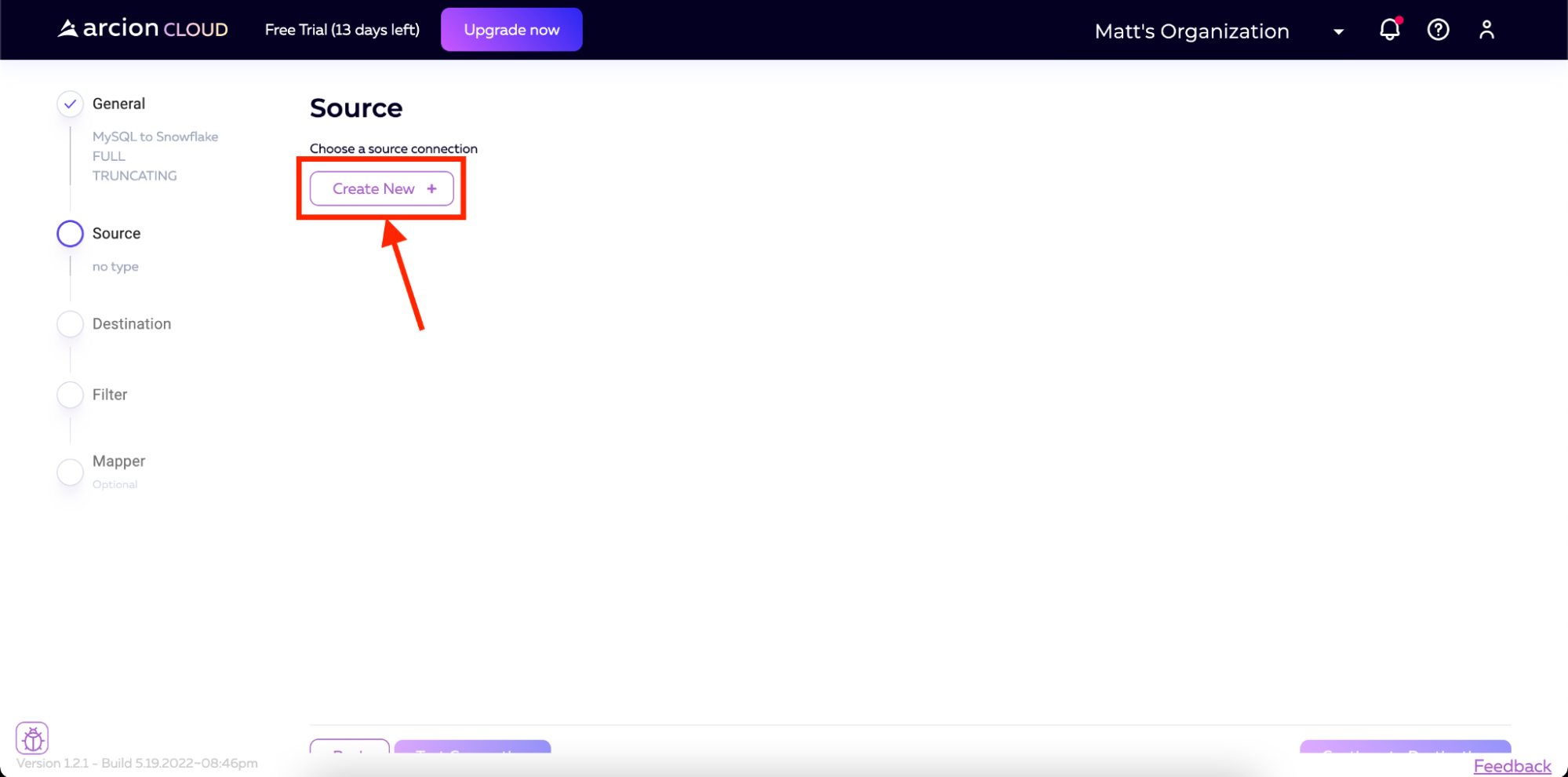
然后我们将选择MySQL作为源代码。
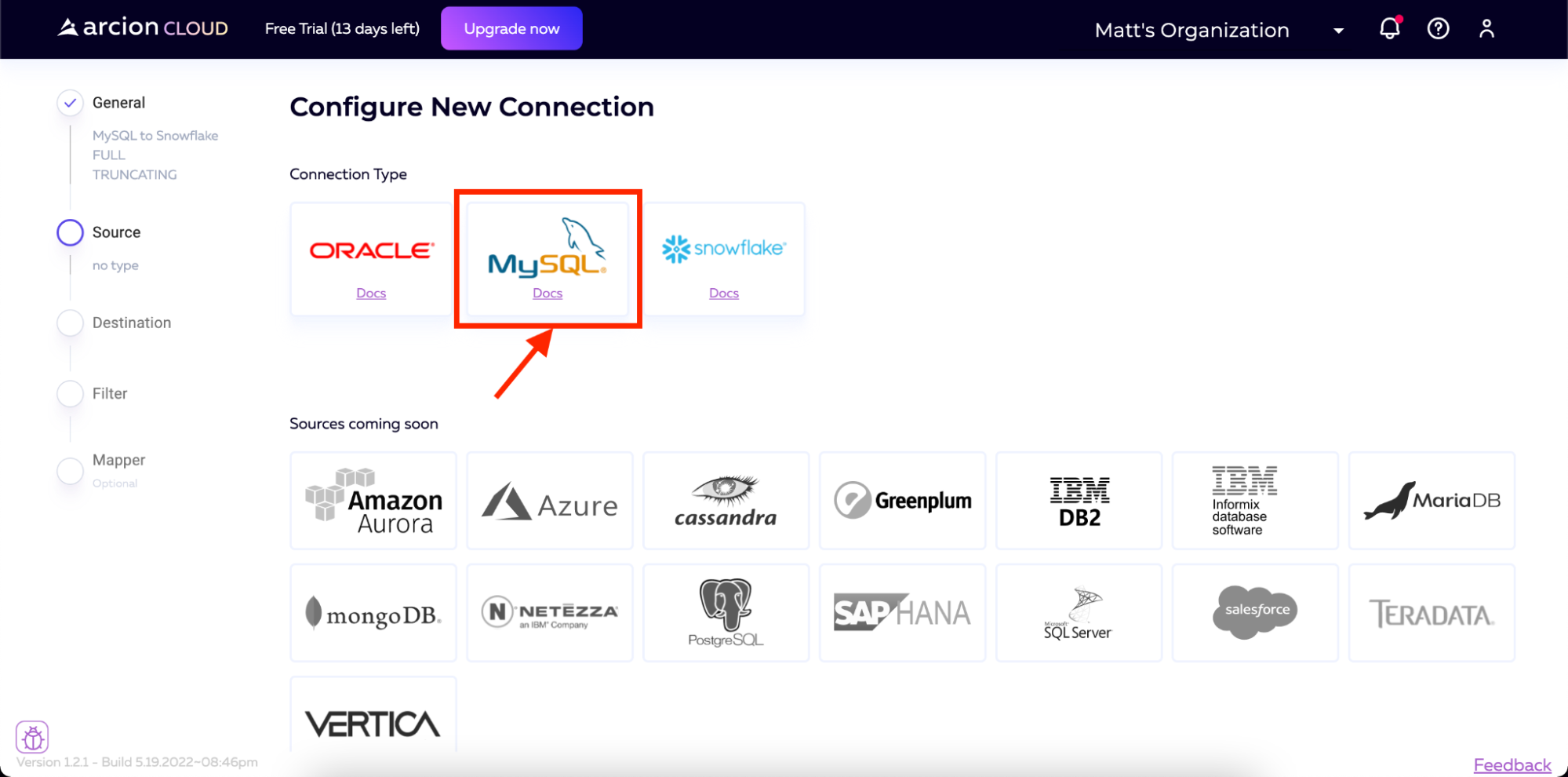
然后滚动到页面底部,单击继续。

现在,我们可以添加MySQL实例的详细信息。这些详细信息包括:
-
连接名称
-
主机
-
端口
-
用户名
-
密码
所有其他字段都将默认。对于用户名和密码,我们将使用在前面针对MySQL实例运行的脚本中创建的用户。
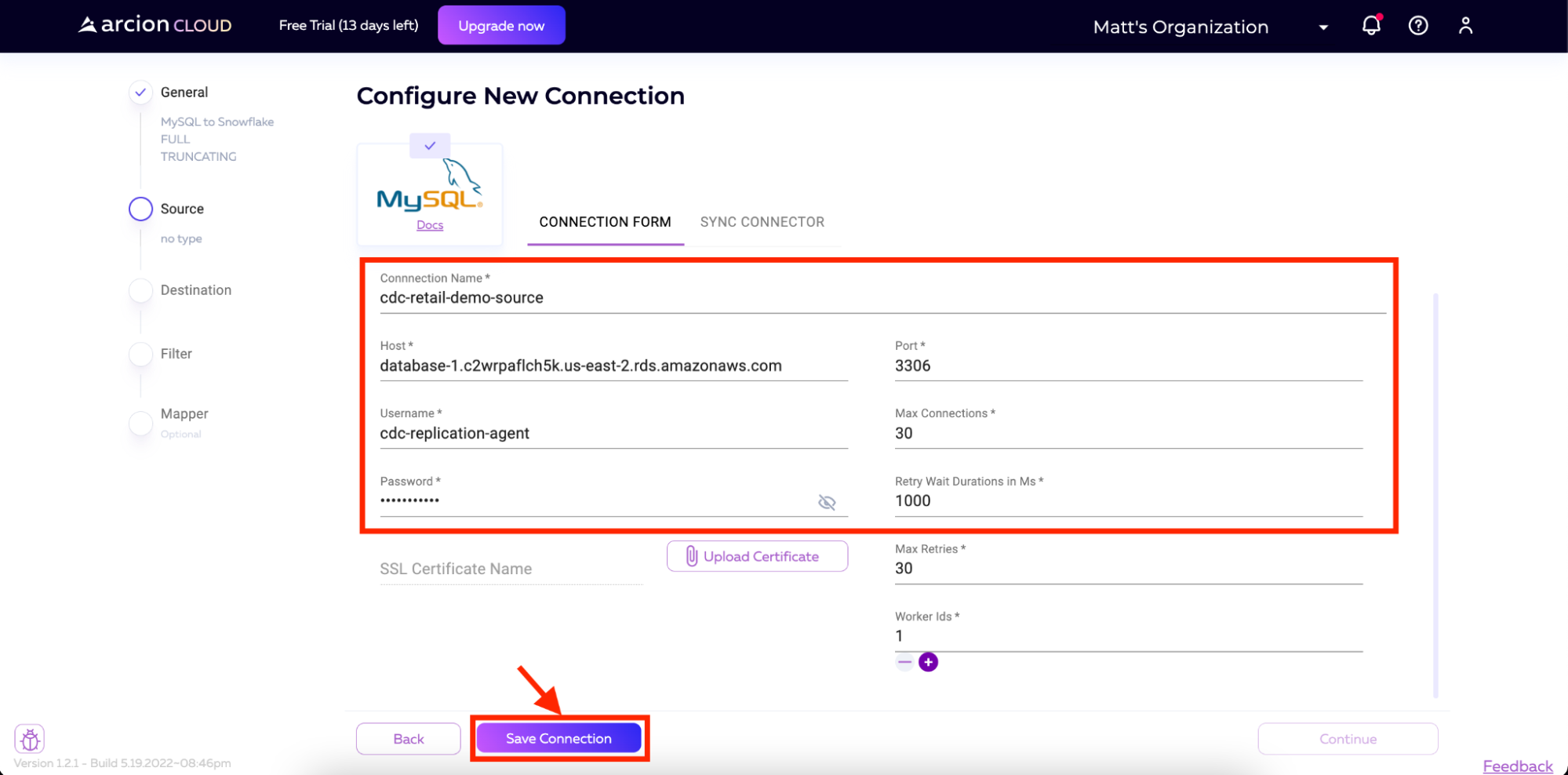
一旦连接被保存,我们将希望从数据库中提取模式。在下一页中,我们将被提示单击Sync Connector按钮。点击按钮,Arcion Cloud将连接到我们的MySQL实例并下拉模式。
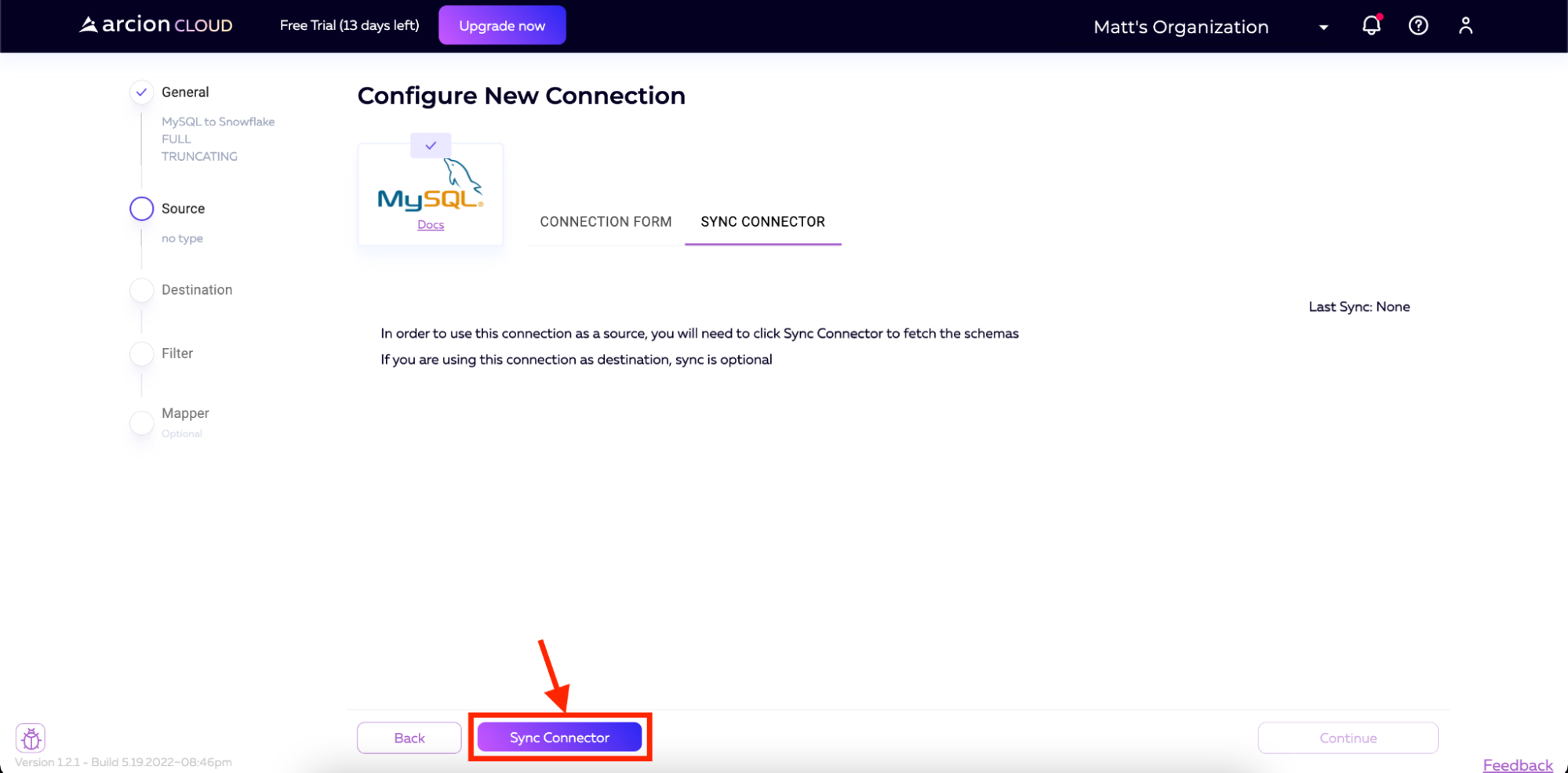
一旦完成,Arcion Cloud中的UI将显示检索到的模式。然后,我们将单击屏幕右下角的“继续”进入下一步。

我们现在已经正确配置了数据源。这将显示在下一个屏幕以及测试连接按钮上。为了确保一切正常工作,我们将单击测试连接按钮。
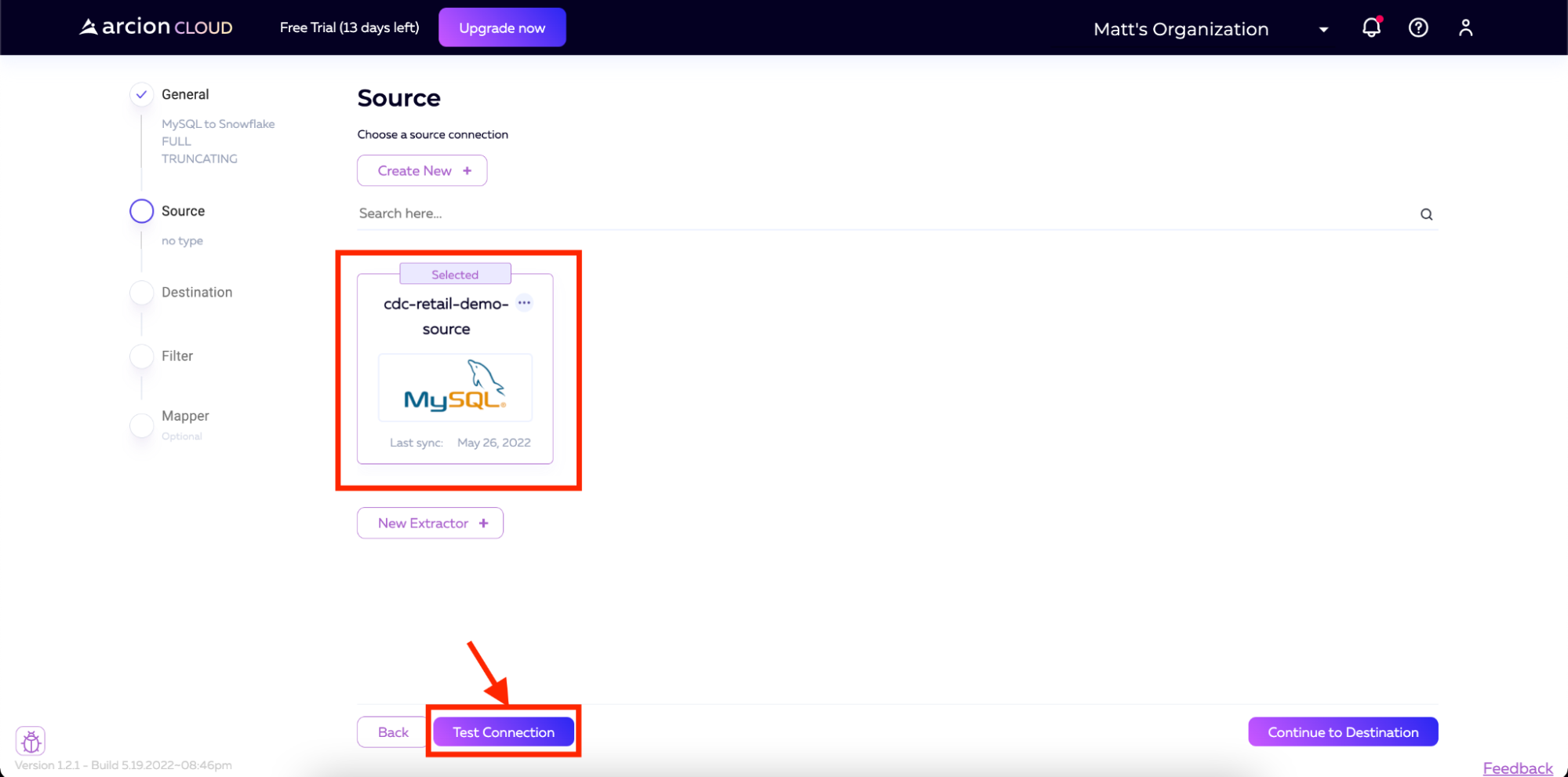
一旦测试运行完毕,结果应该是这样的。您可以单击“完成”按钮退出。
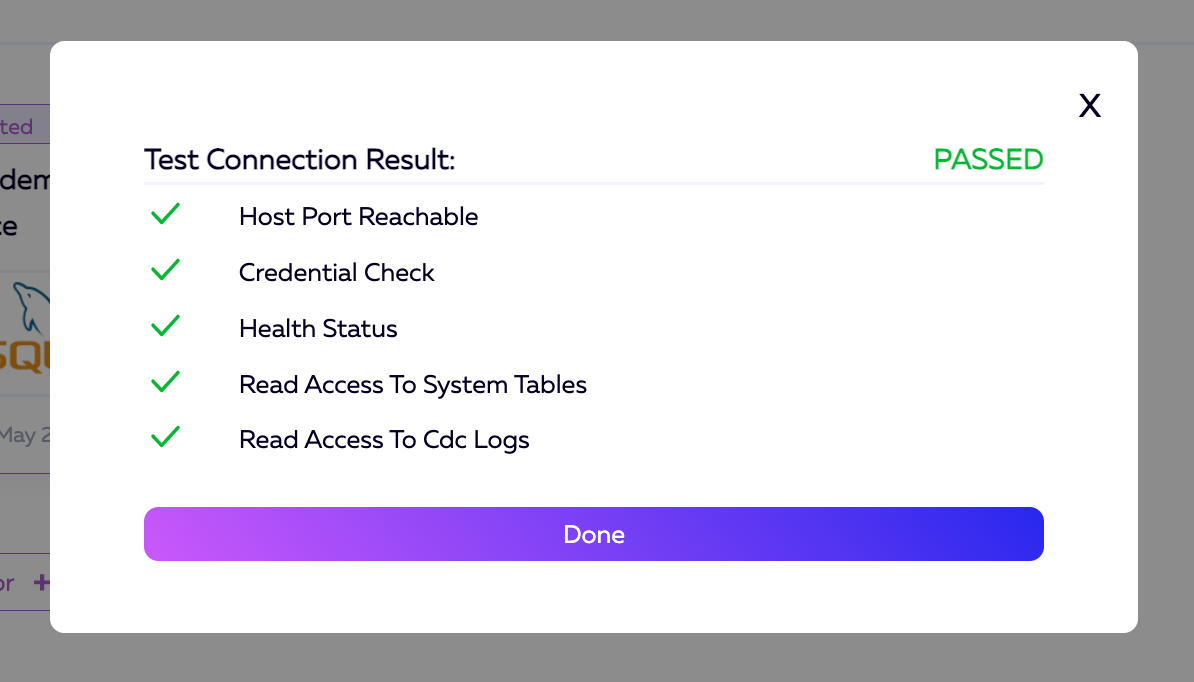
测试成功后,我们现在可以单击屏幕右下角的“继续到目标”,转到设置目标的步骤。
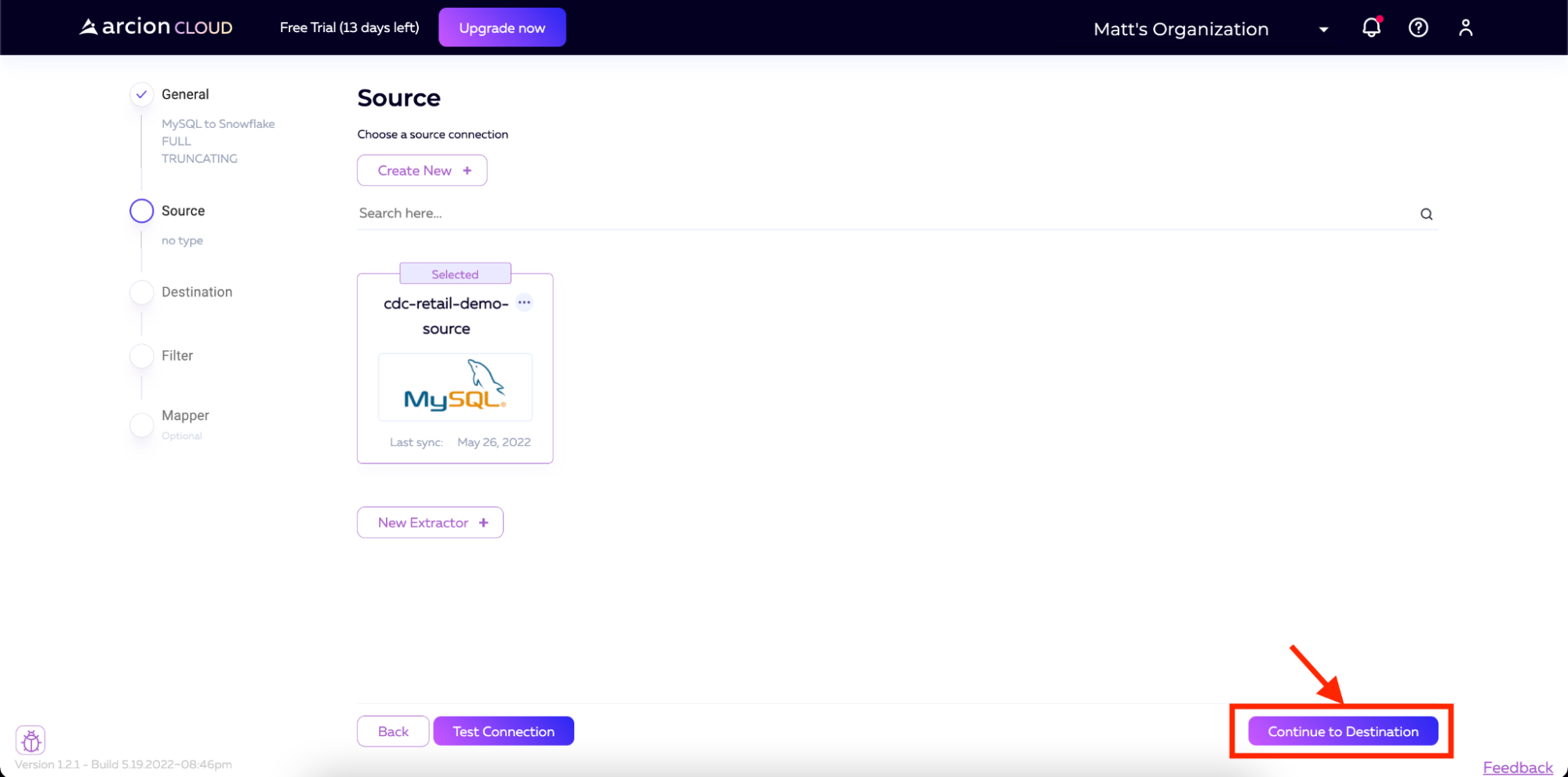
在目标屏幕上,我们将单击新建连接以开始设置Snowflake 连接器。
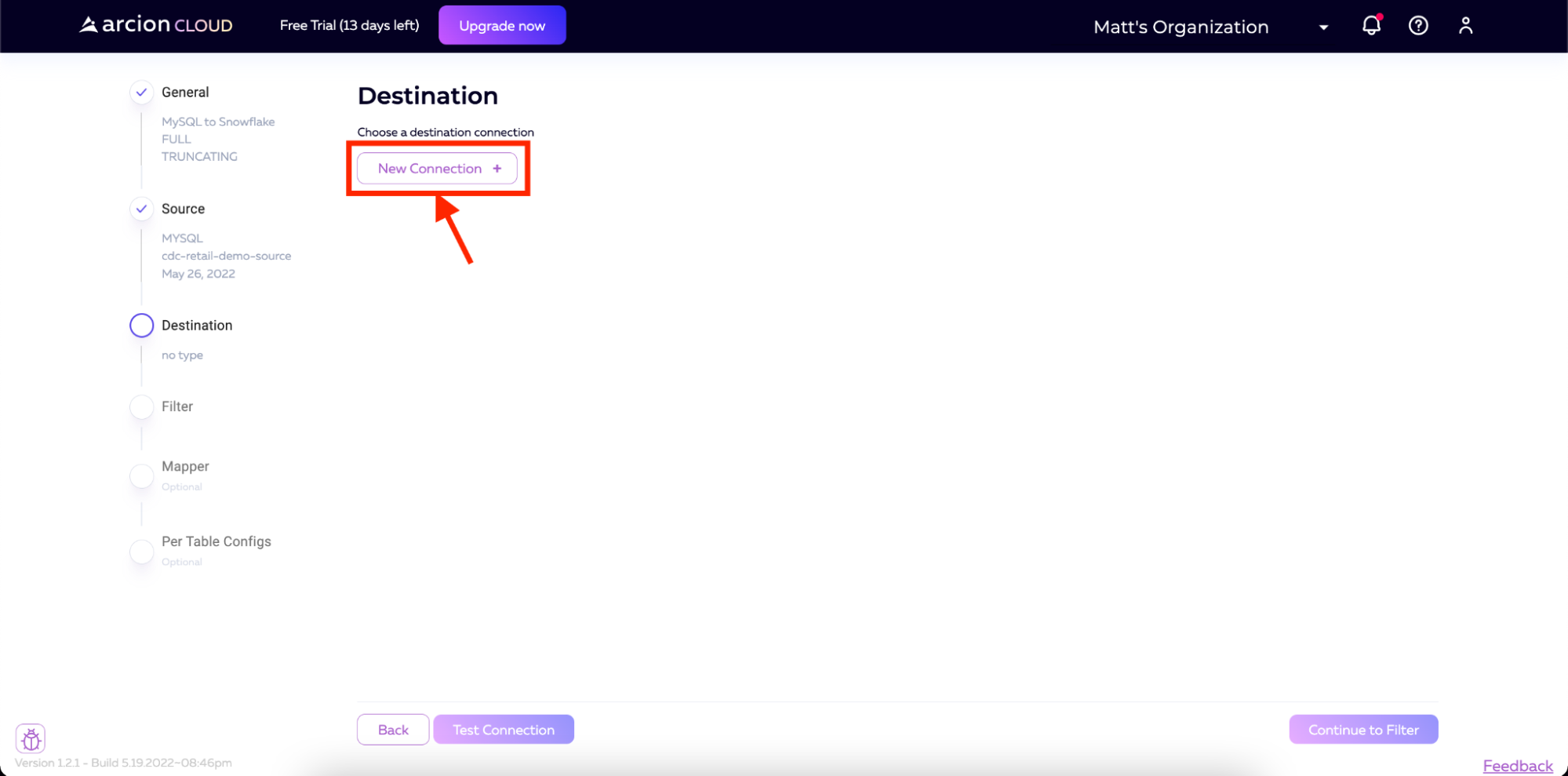
然后,选择Snowflake作为连接类型,然后单击Continue。

在下一个屏幕上,输入您的连接详细信息。这些详细信息包括:
-
连接名称
-
主机
-
接口
-
用户名
-
密码
所有其他字段都将默认。对于用户名和密码,我们将使用在前面针对雪花实例运行的脚本中创建的用户。
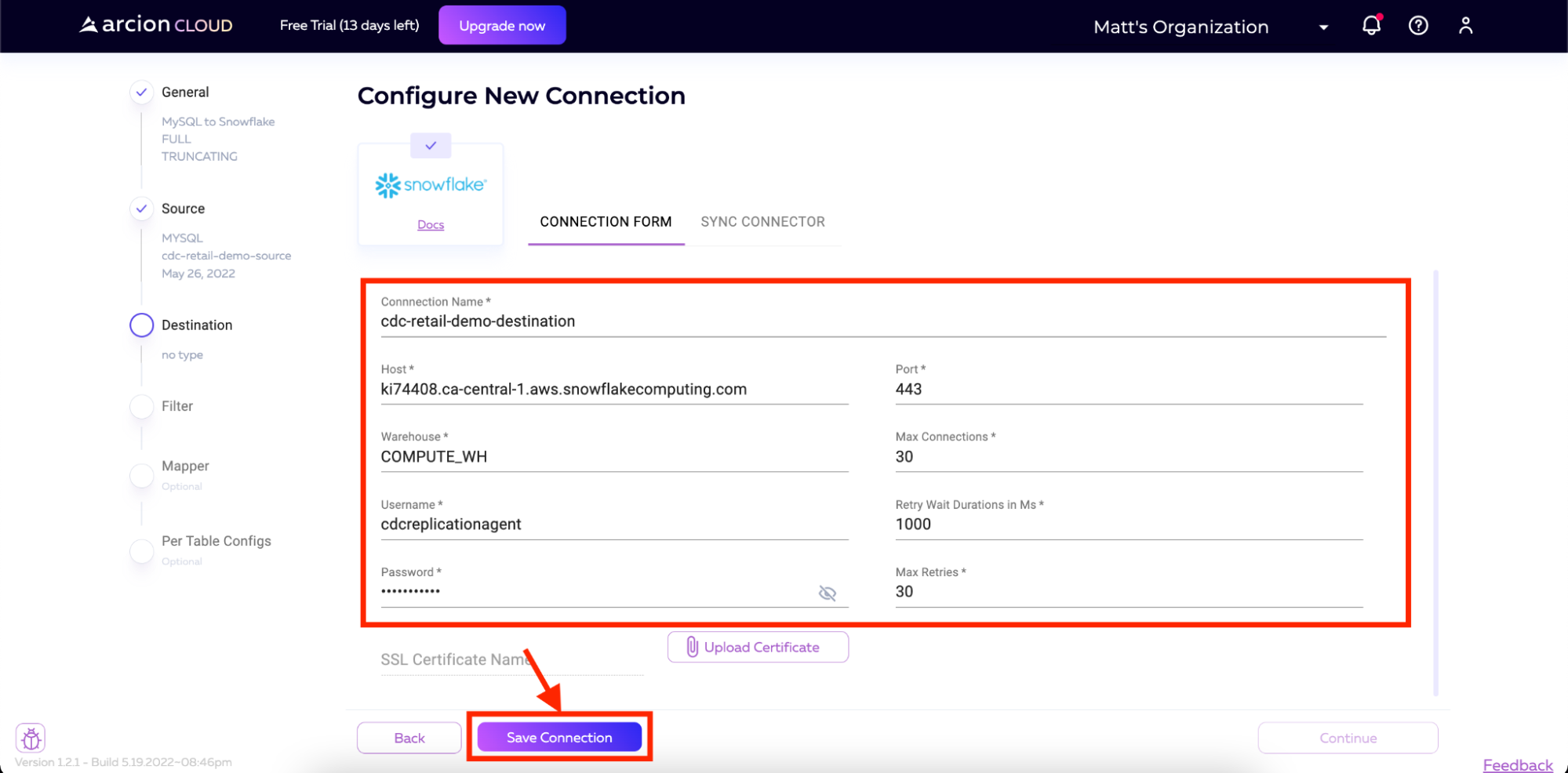
在下一个屏幕上,我们将同步连接器。单击同步连接器并等待过程完成。
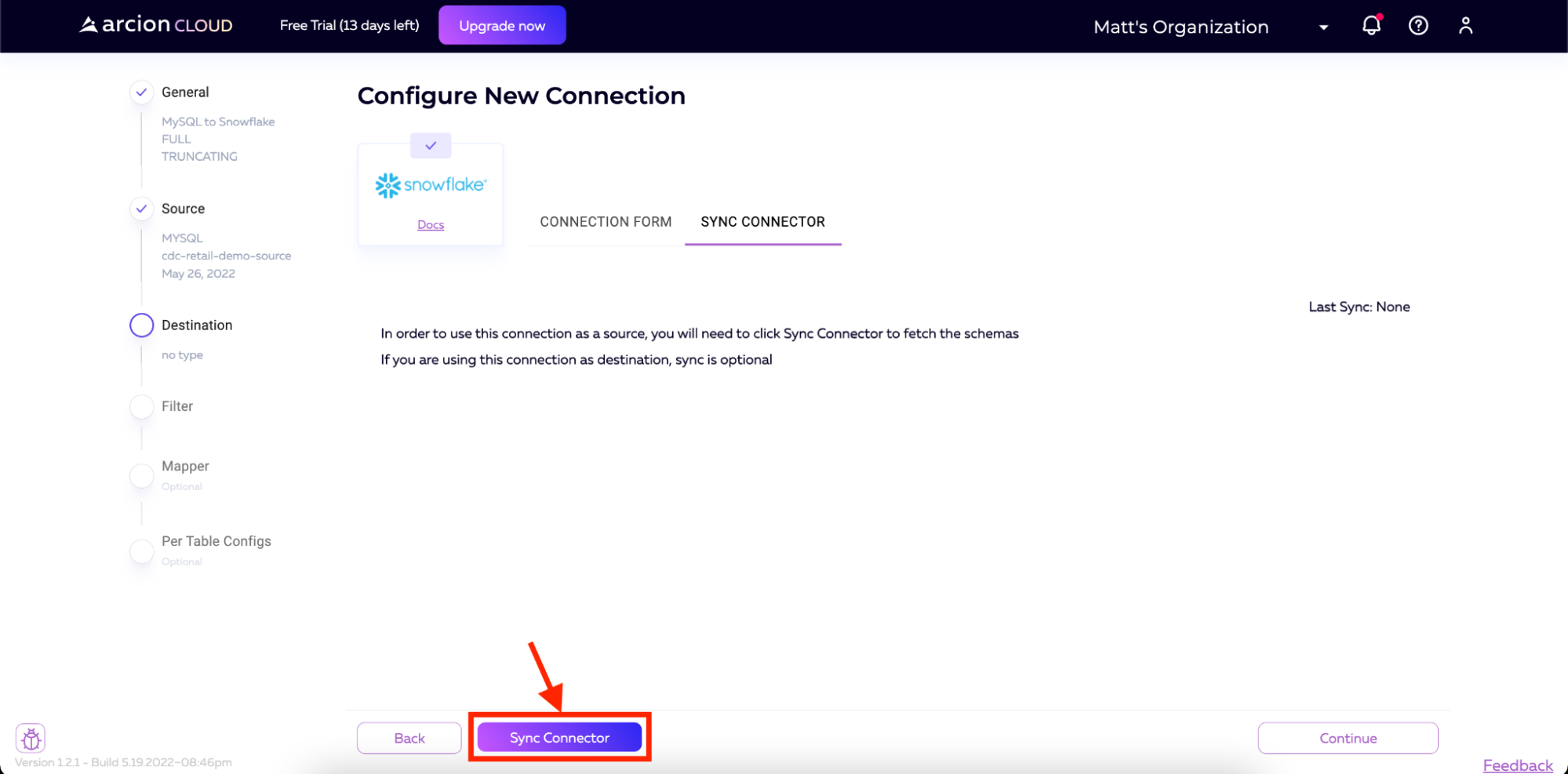
完成后,您将看到模式加载到屏幕上。然后,我们可以单击屏幕右下角的“继续”。
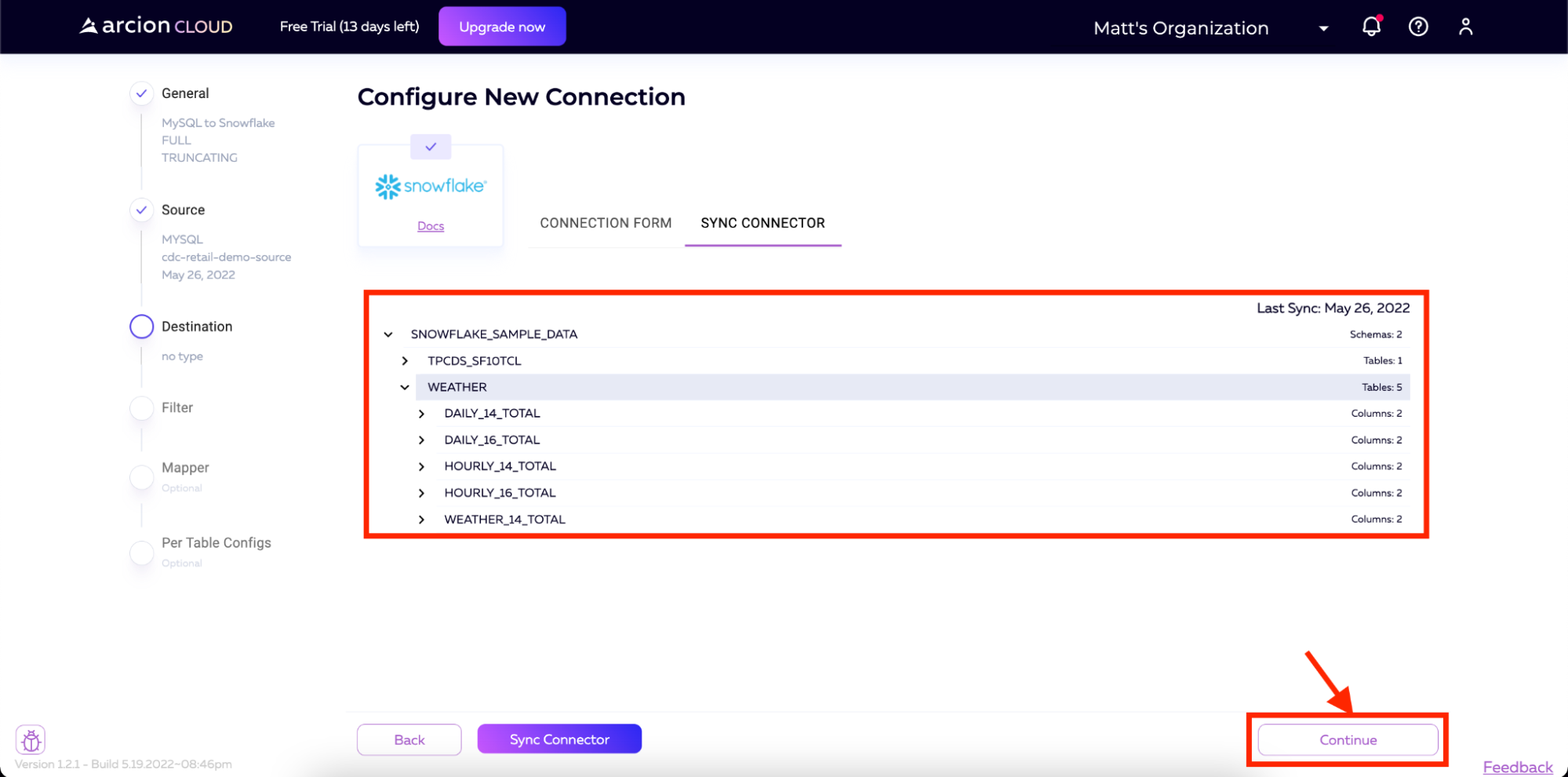
我们使用Snowflake配置连接的最后一步是测试连接。我们将单击测试连接按钮,等待结果返回到Arcion Cloud。
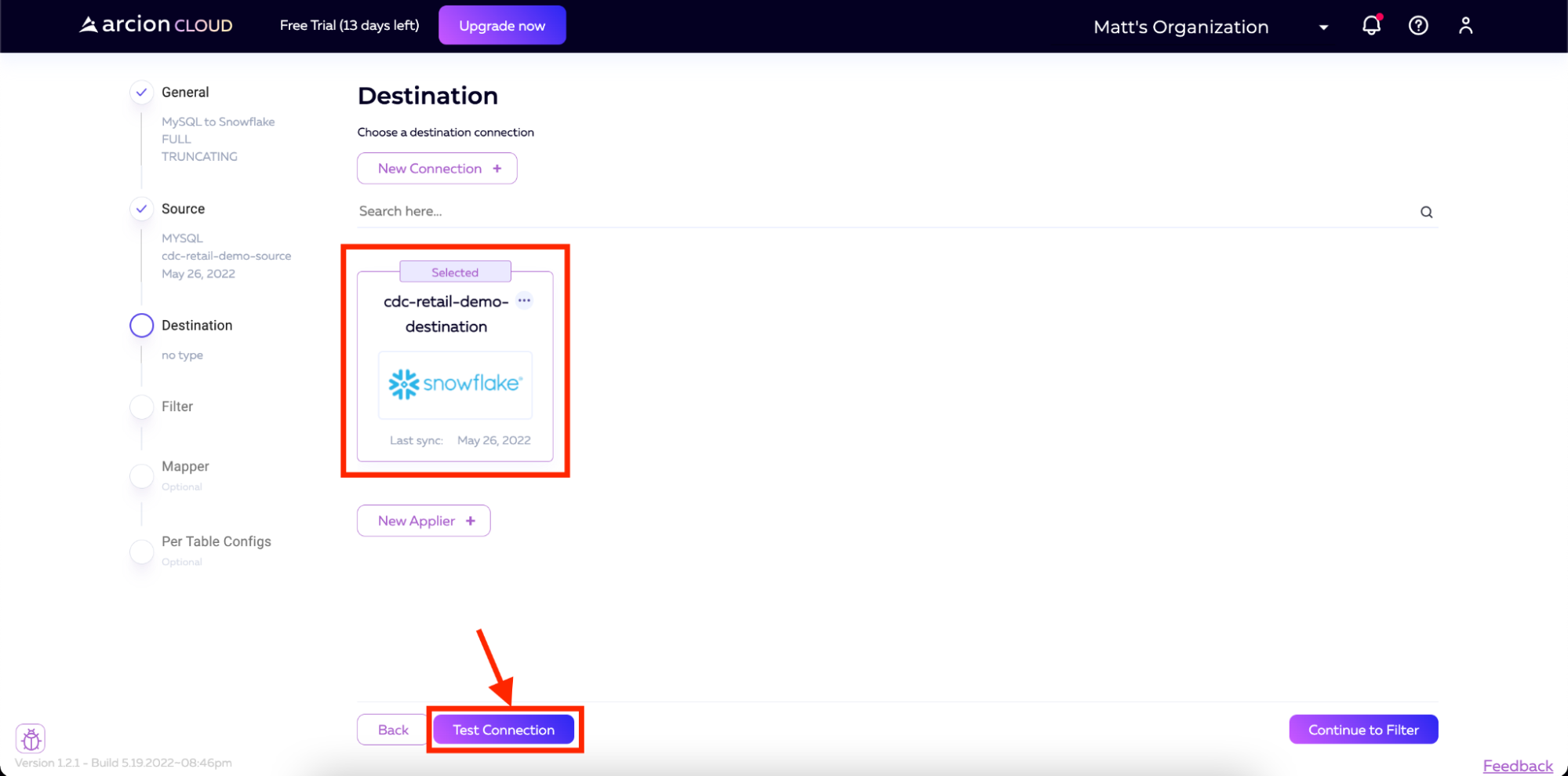
您应该看到,所有测试都已通过,以确保Arcion能够访问创建连接所需的一切。
注意:如果主机端口不可访问,请确保您的Snowflake连接的URL上没有包含“https://”。这可能会导致该检查出错。
现在,我们可以单击Continue to Filter开始管道的过滤器配置。
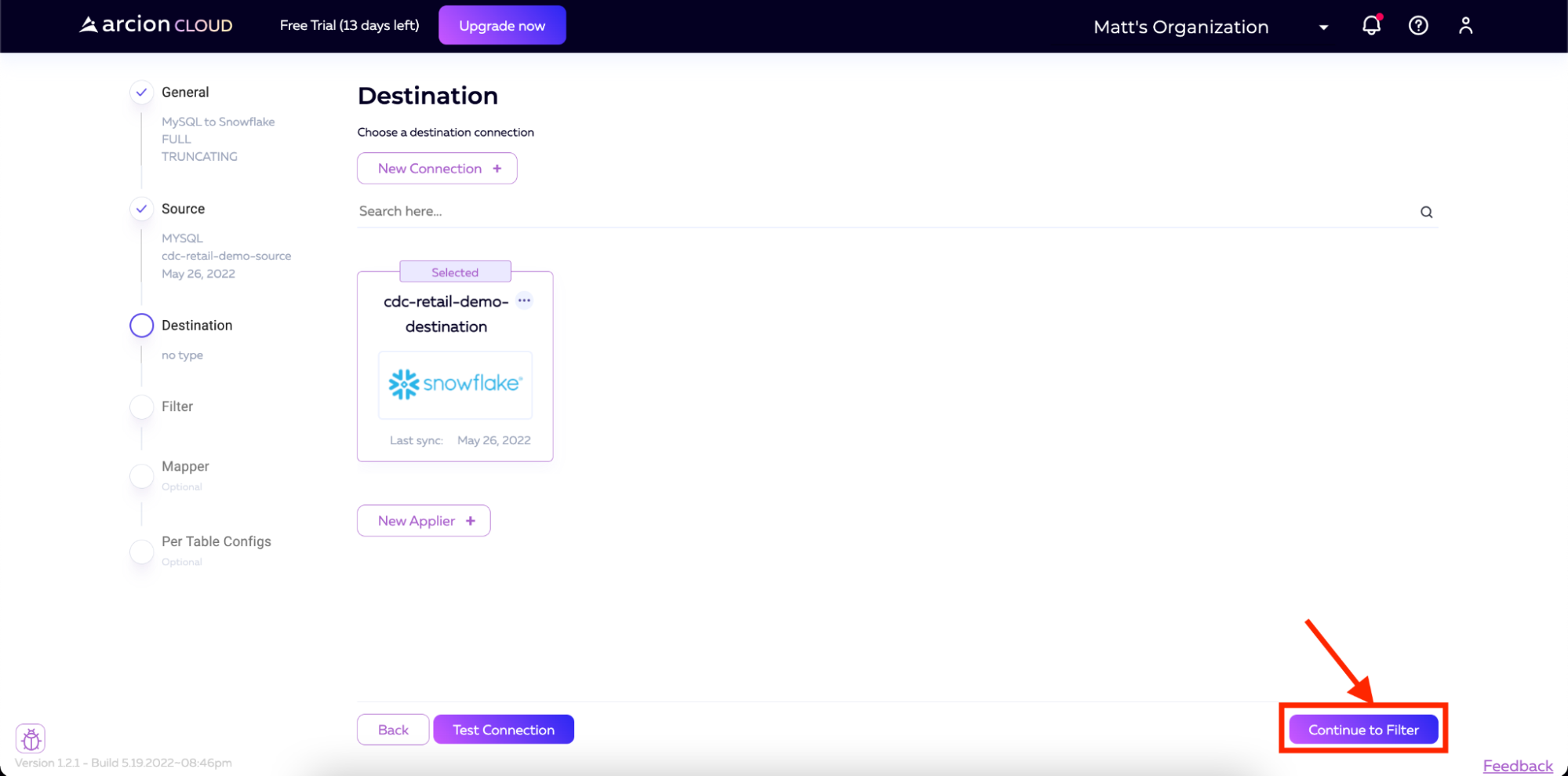
在Filters屏幕上,我们将选中Select All复选框,以便将所有表和列从源复制到目标。
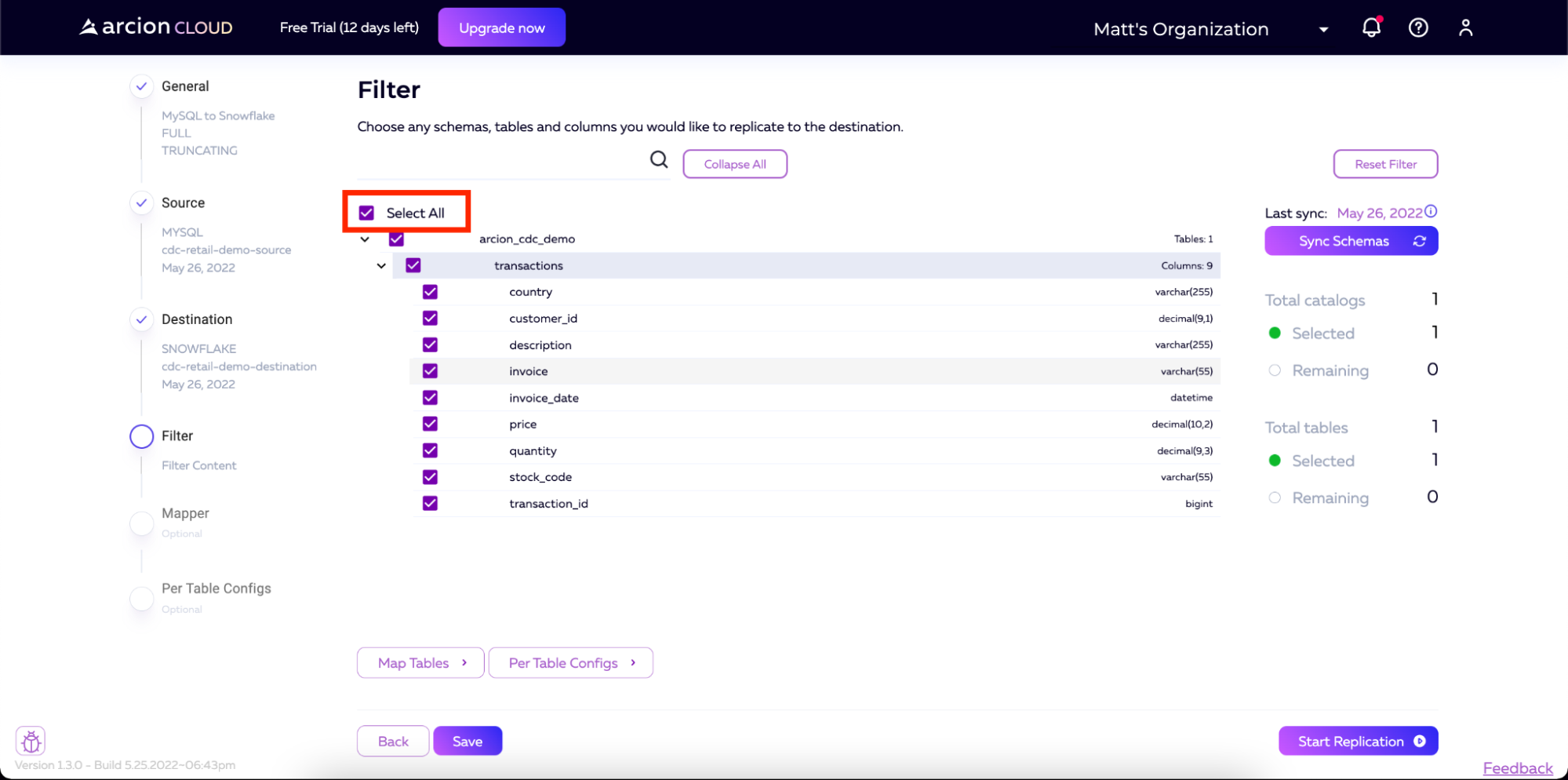
也可以选择单击映射表和每个表配置(Applier Configuration Docs、Extractor Configuration Docs)按钮来添加进一步的配置。出于我们的目的,我们将这些保留为默认值。之后,您将单击开始复制。
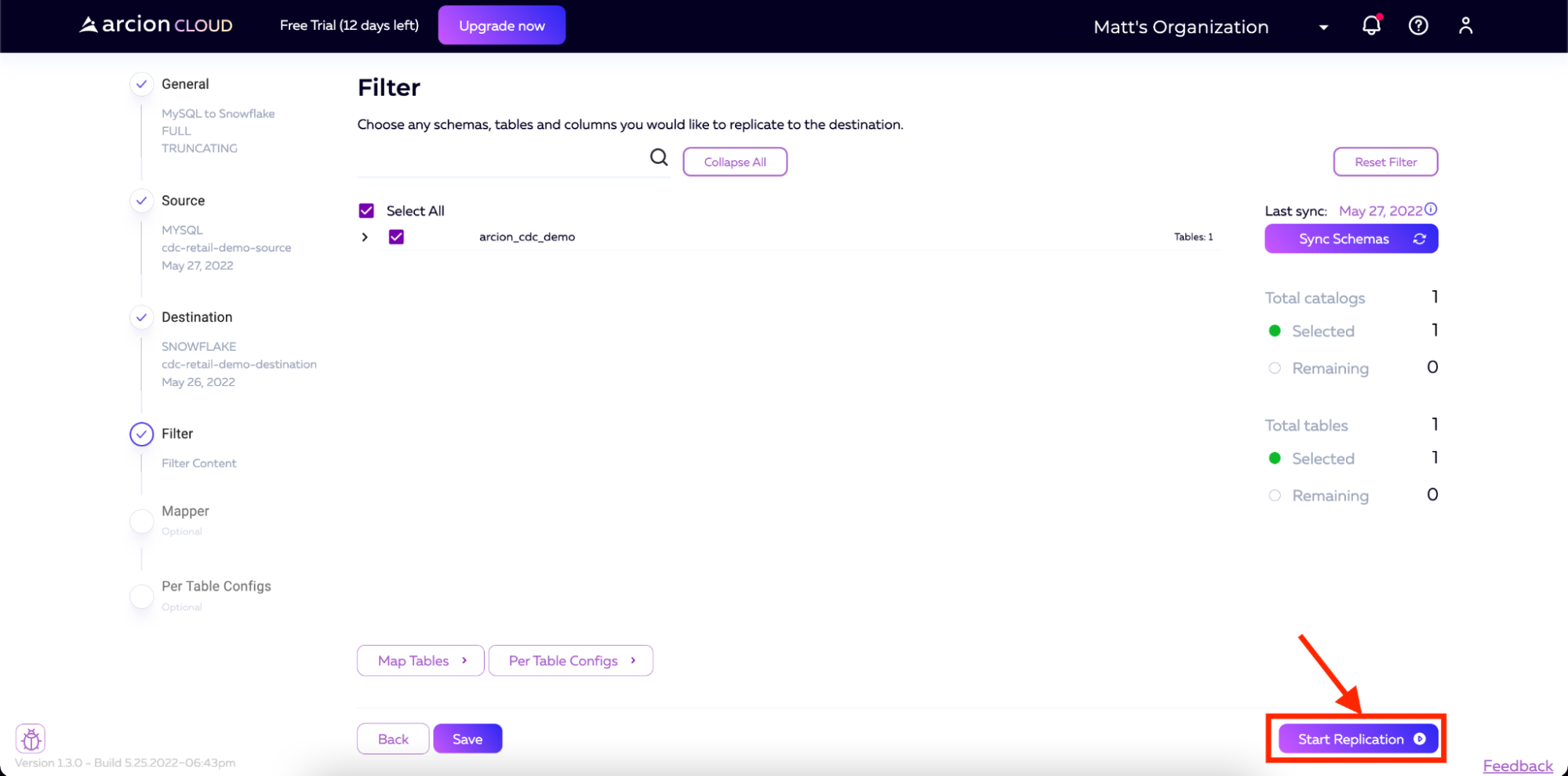
然后将开始复制。
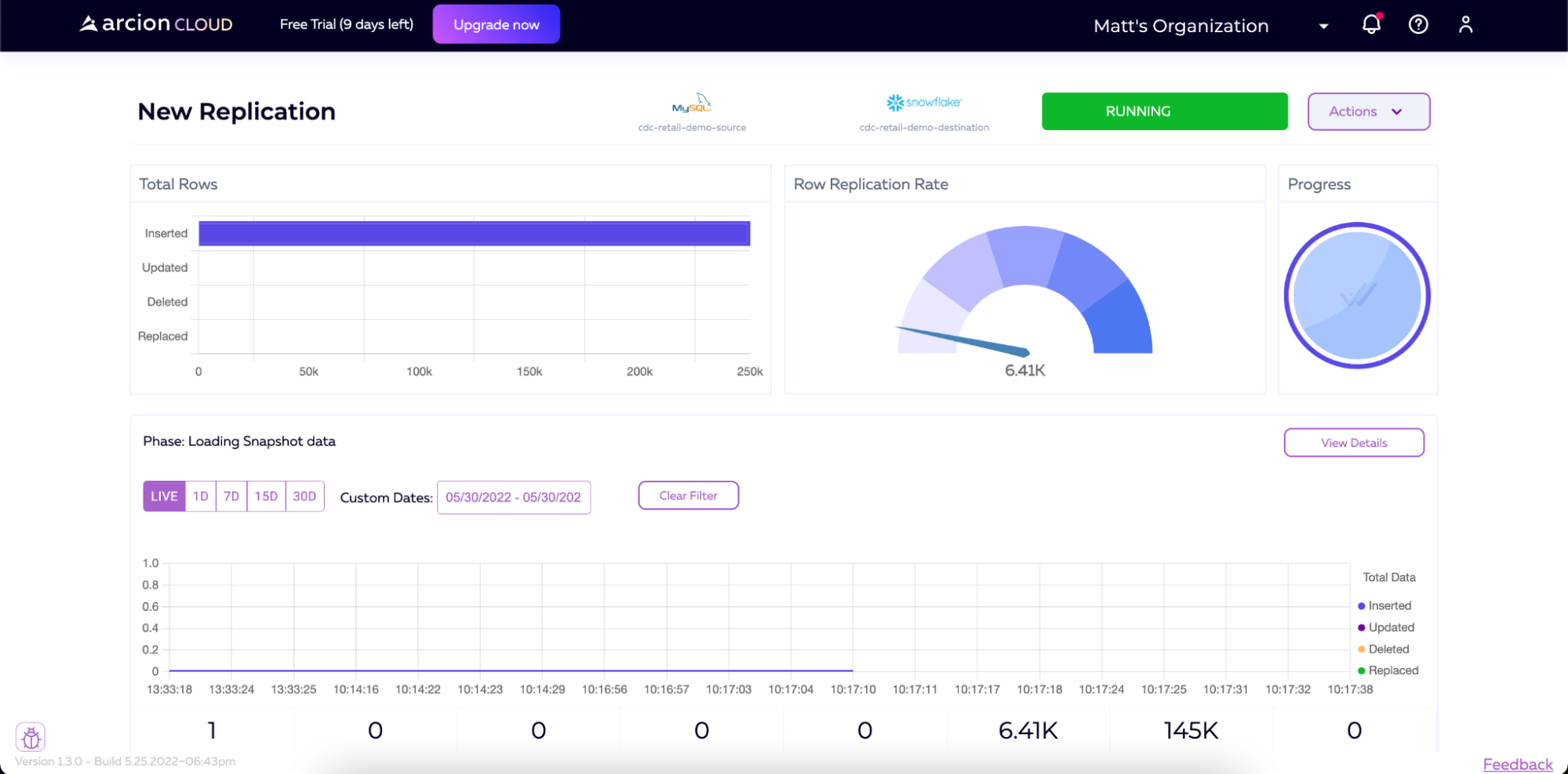
加载初始数据后,管道将继续运行,监视更改,并将这些更改应用到目标。空闲管道仍将在屏幕右上角显示RUNNING,但在将新数据写入源之前,将显示0的行复制速率。您还将注意到,管道的阶段描述现在将显示更改数据捕获,而不是加载快照数据。
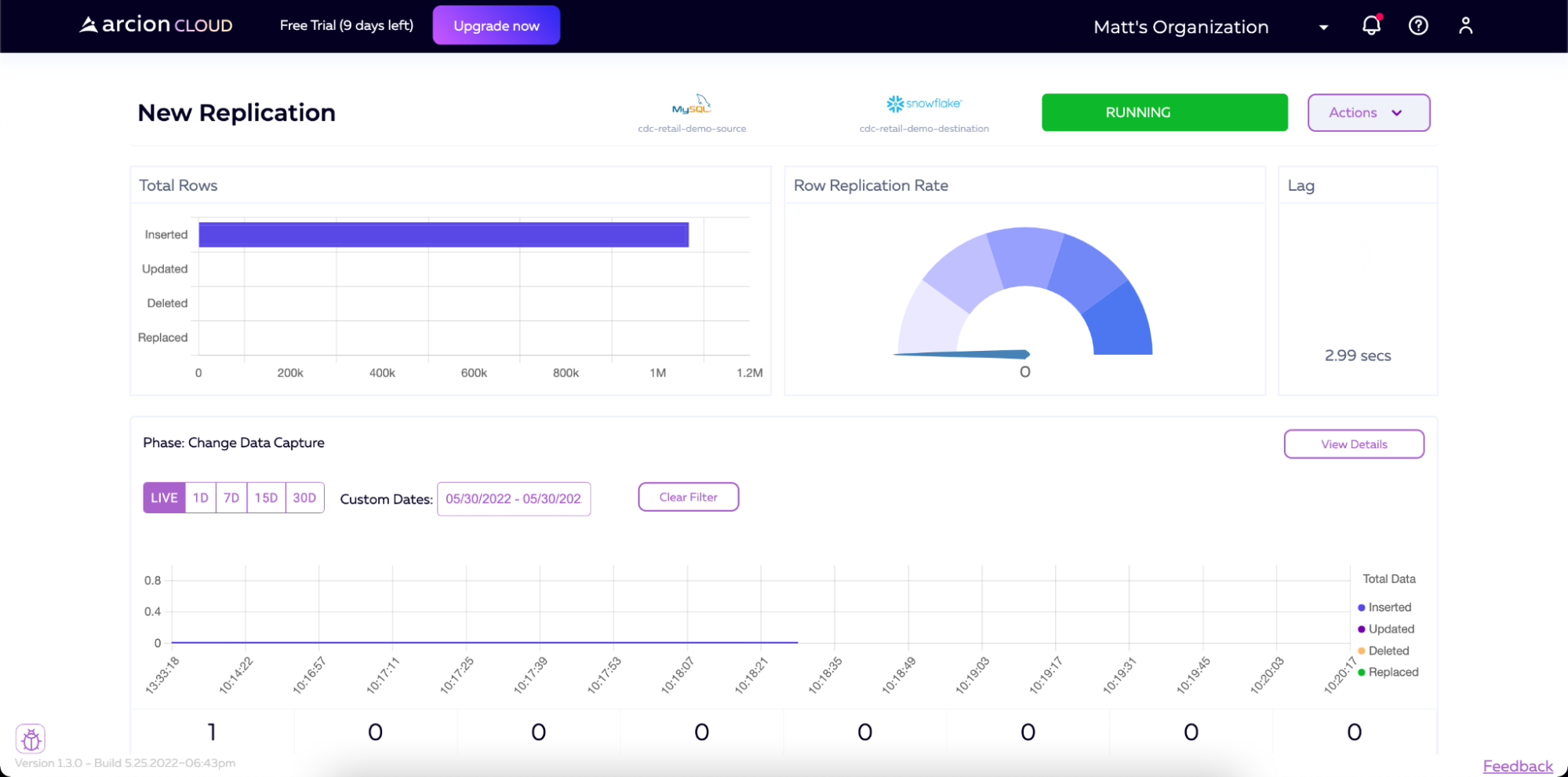
如果我们开始向MySQL实例添加数据(例如,再次运行加载脚本),我们将看到Arcion检测到这一点,然后将该数据实时同步到Snowflake。
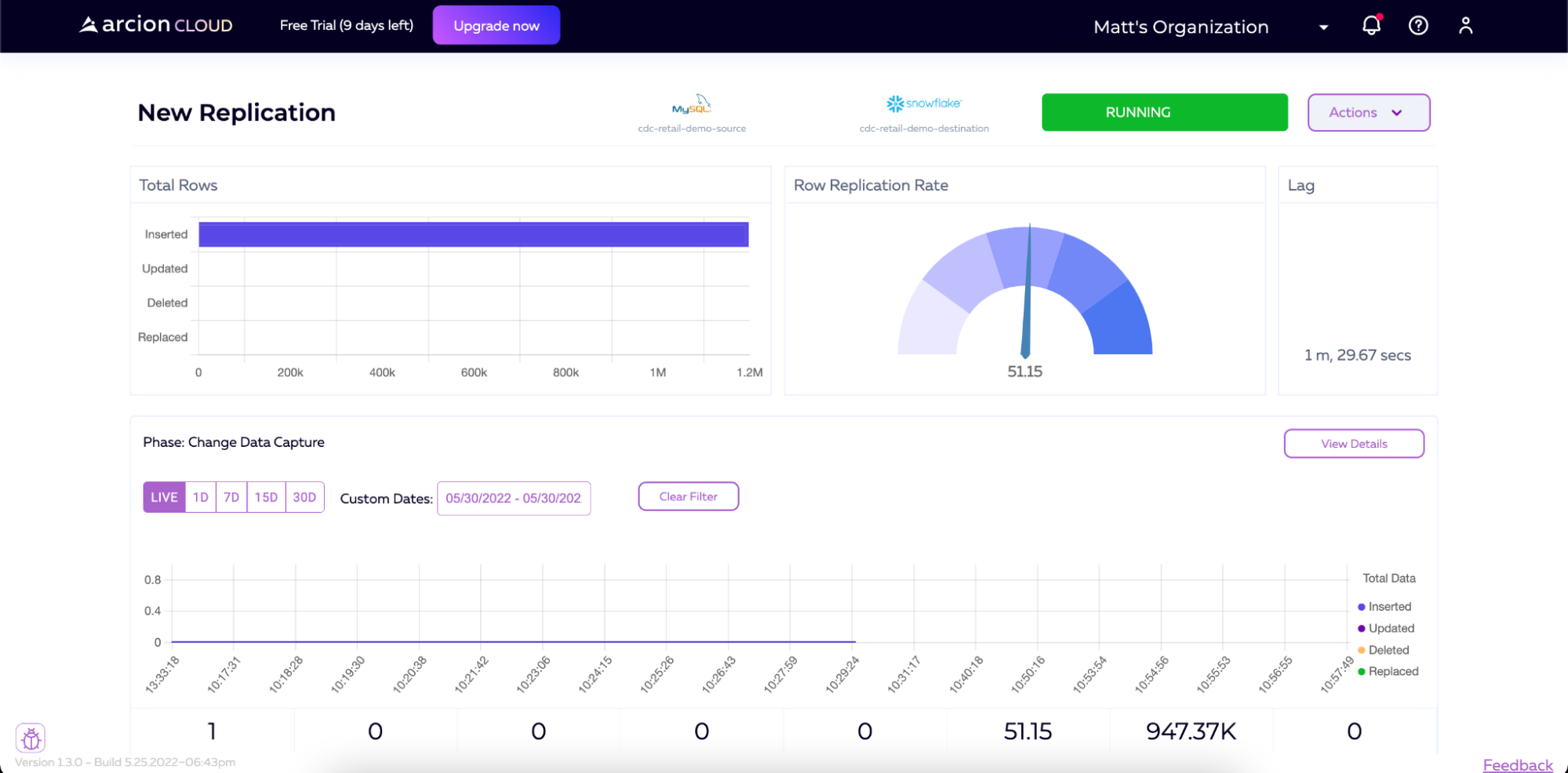
接下来是什么?
有了这一点,我们已经成功地与Arcion建立了支持CDC的数据管道。我们来自MySQL的初始数据已经同步到Snowflake,未来的数据将实时转移到Snowflake。
这种实时数据移动到Snowflake的性质可以为许多用例提供动力,这些用例需要即时访问与一个或多个数据源或主数据库同步的数据。对于零售企业来说,近即时库存和供应链管理、更好的客户体验和产品推荐现在可以通过此管道和即时同步到Snowflake的数据来实现。这项新功能只需点击几下即可解锁。
原文标题:Change Data Capture to Accelerate Real-Time Analytics
原文作者:Michael Bogan
原文链接:https://dzone.com/articles/change-data-capture-to-accelerate-real-time-analyt
