




 点亮 ⭐️ Star · 照亮开源之路
点亮 ⭐️ Star · 照亮开源之路GitHub:https://github.com/apache/incubator-seatunnel

什么是 Connector 如何接入数据源和目标 代码演示如何实现一个 Connector 目前支持的源和目标
什么是 Connector
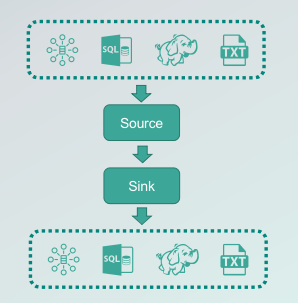
如何接入数据源和目标
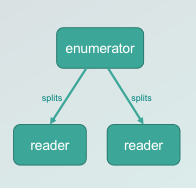
如何接入 Source
DS
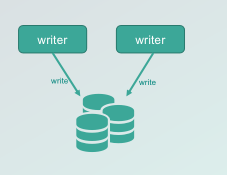
如何接入 Sink
DS
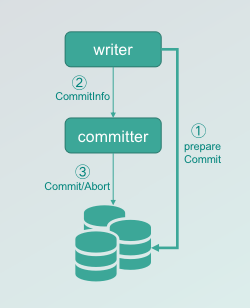
如何实现 Connector
DS
必要环境
SeaTunnel 工程结构
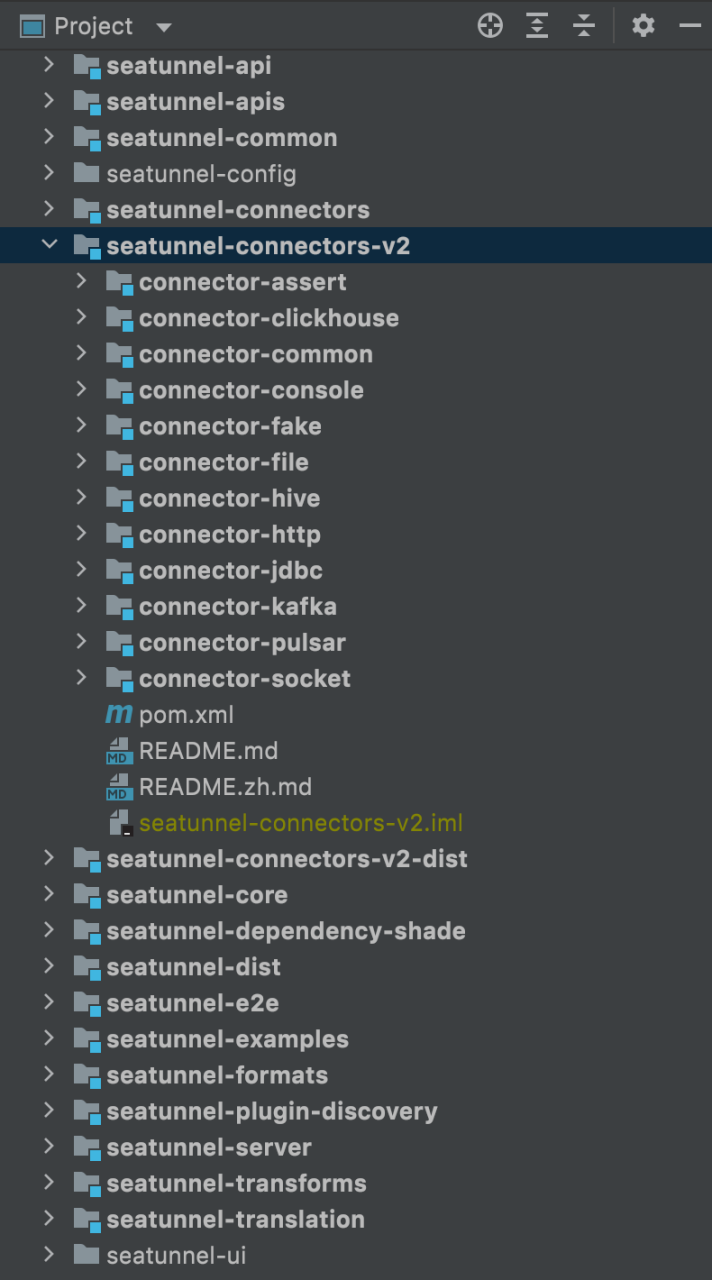
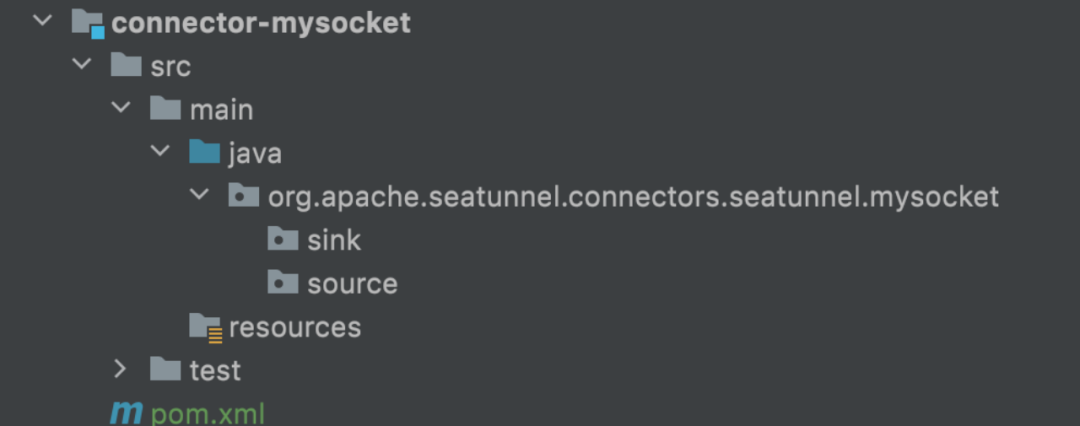
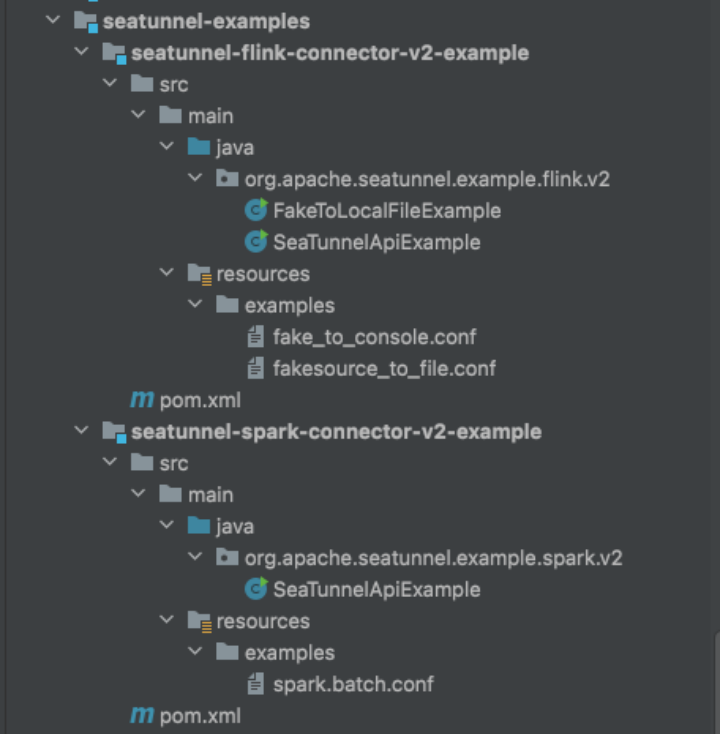
代码演示
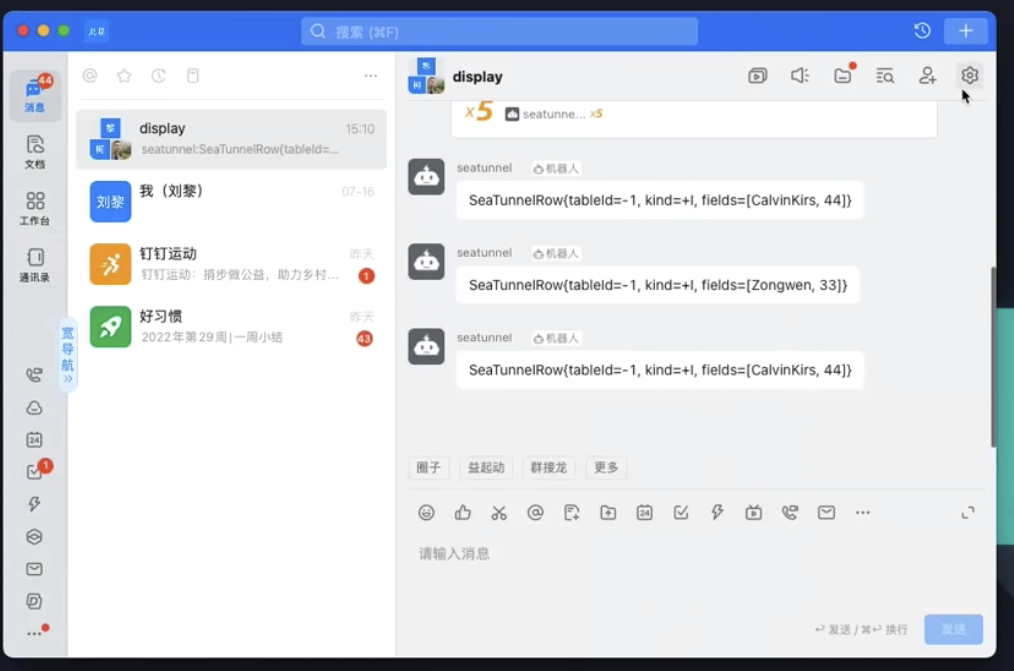
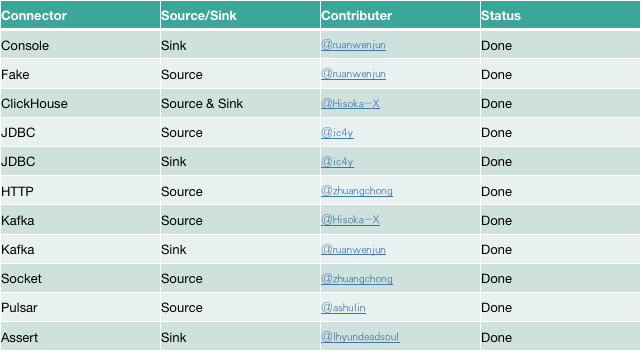
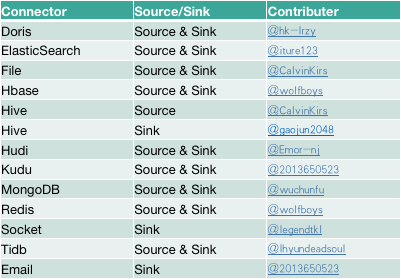
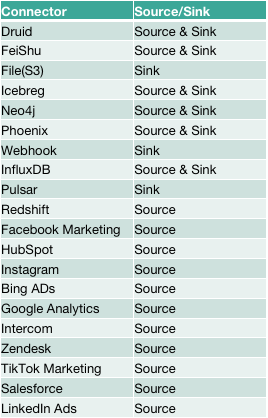
现阶段支持的新连接器
Apache SeaTunnel

// 保持联络 //
微信号 : Seatunnel
来,和社区一同成长!
往期推荐



点击阅读原文,报名成为讲师

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
RisingWave 产品月报|25 年 4 月
RisingWave中文开源社区
303次阅读
2025-05-08 10:04:55
内核探究|Apache Cloudberry™ PAX 行列混存方案技术解析
HashData
95次阅读
2025-04-16 10:33:54
开源之夏2025宣讲,来选心仪的项目吧!
海豚调度
51次阅读
2025-04-18 09:54:16
HTTP接口数据也能定时同步入湖?DolphinScheduler×SeaTunnel快速搞定!
海豚调度
50次阅读
2025-05-08 10:04:28
我用Coze+MCP快速验证了一个Doris用户的需求...AI可期,但还不是万能的!
一臻数据
49次阅读
2025-04-28 11:01:13
修改下内存配置,DolphinScheduler CPU飙升问题秒解决
海豚调度
49次阅读
2025-04-16 10:33:31
万字长文 | Apache SeaTunnel 分离集群模式部署 K8s 集群实践
SeaTunnel
43次阅读
2025-04-24 09:53:12
Flink HA 总结
伦少的博客
41次阅读
2025-04-29 09:53:41
任务运维、循环任务死锁.....DolphinScheduler任务配置经验分享
海豚调度
36次阅读
2025-04-30 12:18:11
欢迎 Apache SeaTunnel 社区新晋 Committer 王超
SeaTunnel
35次阅读
2025-04-18 09:54:14



