




Table of Contents
一. 数据源介绍
数据源:
一个啤酒的数据源,为了方便演示,数据只有20行。
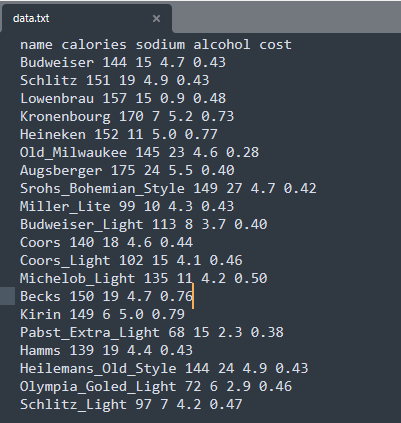
- name 啤酒的名称
- calories 啤酒的卡路里
- sodium 纳元素含量
- alcohol 酒精含量
- cost 价格
二. 使用DBSCAN进行聚类
代码:
import pandas as pd
from sklearn.cluster import DBSCAN
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
# 读取数据源
beer = pd.read_csv('E:/file/data.txt', sep=' ')
X = beer[["calories","sodium","alcohol","cost"]]
# 训练数据源
db = DBSCAN(eps=10, min_samples=2).fit(X)
# 加上标签
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
# 画图
colors = np.array(['red', 'green', 'blue', 'yellow'])
pd.scatter_matrix(X, c=colors[beer.cluster_db], figsize=(10,10), s=100)
plt.show()
# 验证模型效果
score_scaled = metrics.silhouette_score(X,beer.cluster_db)
print("使用DBSCAN的模型效果:")
print(score_scaled)
测试记录:
使用DBSCAN的模型效果:
0.49530955296776086
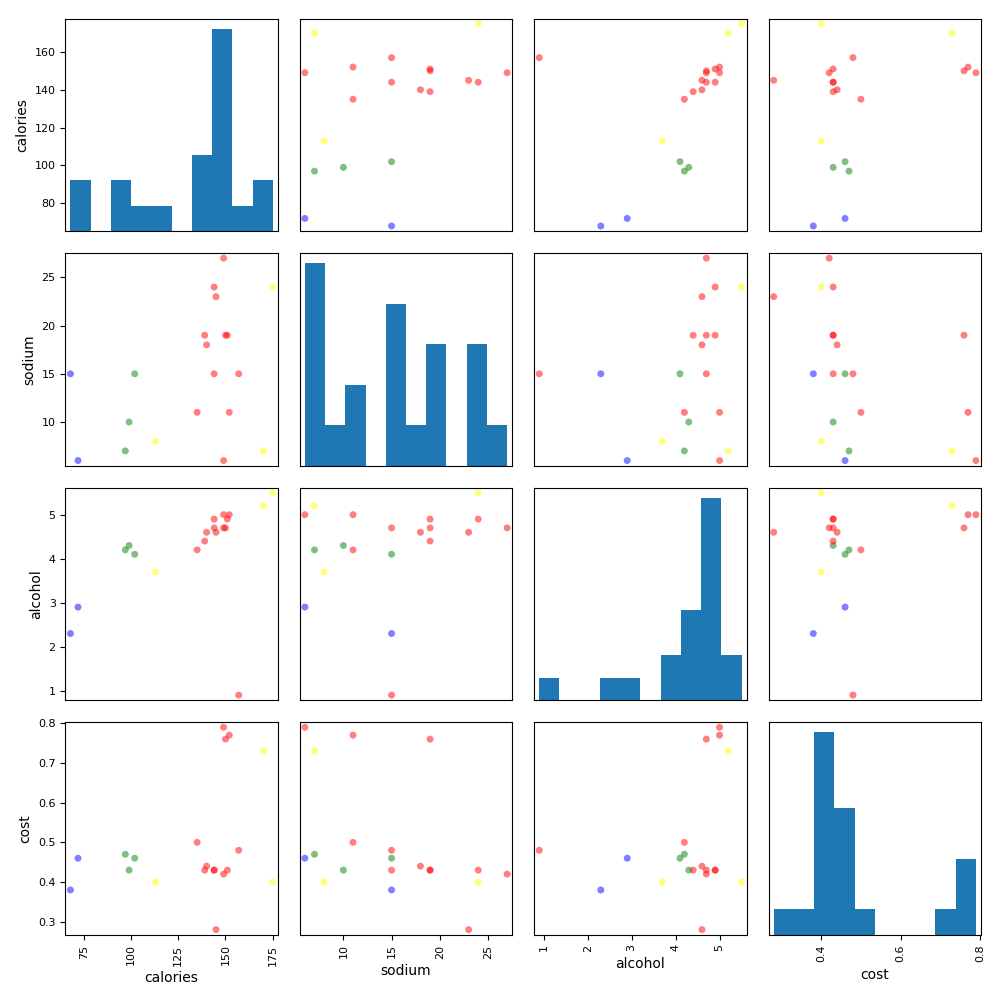
分析:
从评分及可视化效果来看,聚类效果不理想,不如K-Means效果。
对于样本集复杂的使用DBSCAN。
对于样本集简单的直接使用K-Means即可。
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
