




到目前为止,我们已经讨论了查询执行阶段、统计信息和两种基本的数据访问方法:顺序扫描和索引扫描。
列表中的下一项是 join 连接方法。本文将提醒您有哪些逻辑连接类型,然后讨论三种物理连接方法之一,即嵌套循环连接。此外,我们将查看PostgreSQL 14 中引入的行记忆功能。
join 连接
join 连接是 SQL 的主要特性,是实现其强大功能和敏捷性的基础。行集(无论是直接从表中提取还是作为操作的结果形成)总是成对连接在一起。有几种类型的连接。
- 内联接。一个 INNER JOIN(或通常只是 JOIN )是两个集合的子集,包括两个原始集合中与连接条件匹配的所有行对。连接条件是将第一行集合中的列与第二行集合中的列联系在一起。所有涉及的列都包含所谓的连接键。
如果连接条件是等式运算符(通常是这种情况),则连接称为equijoin。
两个集合的笛卡尔积(或 a CROSS JOIN)包括来自这两个集合的行对的所有可能组合。这是具有 TRUE 条件的内部联接的特定情况。
- 外连接。(LEFT OUTER JOIN 或 LEFT JOIN )用左集中的行补充内连接的结果,这些行在右集中没有对应的对(缺少的右集列的内容设置为 NULL)。
RIGHT JOIN 工作原理相同,只是 join 顺序颠倒了。
FULL JOIN 是 LEFT JOIN 和 RIGHT JOIN 结合起来。它包括两个集合中缺少的行,以及INNER JOIN结果。
- 半连接和反连接。semijoin 类似于常规的内部连接,但有两个关键区别。首先,它仅包括第一组中在第二组中具有匹配对的行。其次,它只包含第一个集合中的行一次,即使一行恰好在第二个集合中有多个匹配项。
反连接仅包括第一组中在第二组中没有匹配对的那些行。
SQL 不提供显式半连接或反连接操作,但可以使用一些表达式(例如EXISTS 和 NOT EXISTS)来获得等效的结果。
以上都是逻辑运算。例如,您可以将内部联接表示为仅保留满足联接条件的行的笛卡尔积。然而,在硬件方面,有一些方法可以更有效地执行内部连接。
PostgreSQL 提供了几种连接方法:
- 嵌套循环join
- 哈希join
- 合并join
连接方法是在 SQL 中执行连接操作的算法。它们通常具有针对特定连接类型量身定制的各种类型。例如,使用嵌套循环模式的内连接将在具有嵌套循环节点的计划中表示,但使用相同模式的左外连接将在计划中看起来像嵌套循环左连接节点。
不同的方法在不同的条件下发挥作用,计划者的工作是在成本方面选择最好的方法。
嵌套循环join
嵌套循环算法基于两个循环:外循环内的内循环。外部循环搜索第一个(外部)集合的所有行。对于每个这样的行,内部循环在第二个(内部)集合中搜索匹配的行。一旦发现满足加入条件的 pair,节点立即将其返回给父节点,然后继续扫描。
内循环的循环次数与外循环的行数一样多。因此,算法效率取决于几个因素:
- 外集基数。
- 存在从内部集合中获取行的有效访问方法。
- 从内部集合中提取的重复行数。
让我们看一些例子。
笛卡尔积
嵌套循环连接是计算笛卡尔积的最有效方法,无论两组中的行数如何。
EXPLAIN SELECT * FROM aircrafts_data a1 CROSS JOIN aircrafts_data a2 WHERE a2.range > 5000; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=0.00..2.78 rows=45 width=144) −> Seq Scan on aircrafts_data a1 outer set (cost=0.00..1.09 rows=9 width=72) −> Materialize (cost=0.00..1.14 rows=5 width=72) inner set −> Seq Scan on aircrafts_data a2 (cost=0.00..1.11 rows=5 width=72) Filter: (range > 5000) (7 rows)复制
嵌套循环节点是执行算法的地方。它总是有两个孩子:上面的一个是外部集合,下面的一个是内部集合。
在这种情况下,内部集由 Materialize 节点表示。被调用时,节点将其子节点的输出存储在 RAM 中( 存储上限是work_mem,然后开始溢出到磁盘),然后返回它。在进一步调用时,节点从内存中返回数据,避免额外的表扫描。
内连接查询可能会生成类似的计划:
EXPLAIN SELECT * FROM tickets t JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no WHERE t.ticket_no = '0005432000284'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=0.99..25.05 rows=3 width=136) −> Index Scan using tickets_pkey on tickets t (cost=0.43..8.45 rows=1 width=104) Index Cond: (ticket_no = '0005432000284'::bpchar) −> Index Scan using ticket_flights_pkey on ticket_flights tf (cost=0.56..16.57 rows=3 width=32) Index Cond: (ticket_no = '0005432000284'::bpchar) (7 rows)复制
规划器实现等价并将 tf.ticket_no = t.ticket_no 条件替换为tf.ticket_no = constant,实质上将内连接转换为笛卡尔积。
基数估计。两个集合的笛卡尔积的基数等于两个集合的基数的乘积:3 = 1 × 3。
费用估算。连接的启动成本等于其子节点的启动成本之和。
在这种情况下,连接的总成本等于以下各项的总和:
- 每行的外部集合的行提取成本。
- 对于每一行,内部集合的一次性行提取成本(因为外部集合的基数等于 1)。
- 每个输出行的处理成本。
SELECT 0.43 + 0.56 AS startup_cost, round(( 8.45 + 16.58 + 3 * current_setting('cpu_tuple_cost')::real )::numeric, 2) AS total_cost; startup_cost | total_cost −−−−−−−−−−−−−−+−−−−−−−−−−−− 0.99 | 25.06 (1 row)复制
不精确是由于舍入误差。计划器的计算以浮点值执行,为了计划的可读性,浮点值向下舍入到小数点后两位,而我使用向下舍入的值作为输入。
让我们回到前面的例子。
EXPLAIN SELECT * FROM aircrafts_data a1 CROSS JOIN aircrafts_data a2 WHERE a2.range > 5000; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=0.00..2.78 rows=45 width=144) −> Seq Scan on aircrafts_data a1 (cost=0.00..1.09 rows=9 width=72) −> Materialize (cost=0.00..1.14 rows=5 width=72) −> Seq Scan on aircrafts_data a2 (cost=0.00..1.11 rows=5 width=72) Filter: (range > 5000) (7 rows)复制
这个计划有一个 Materialize 节点,它将行存储在内存中,并在重复请求时更快地返回它们。
一般来说,总 join 成本包括:
- 每行的外部集合的行提取成本。
- 对于每一行(在此期间完成物化),内部集的一次性行获取成本。
- (N-1) 乘以重复内部集合行获取成本的成本,对于每一行(其中 N 是外部集合中的行数)。
- 每个输出行的处理成本。
在这个例子中,在第一次获取内部行之后,物化帮助我们节省了进一步的获取成本。初始 Materialize 调用的成本在计划中,进一步调用的成本不在计划中。它的计算超出了本文的范围,所以当我说在这种情况下连续 Materialize 节点调用的成本为 0.0125 时,请相信我。
因此,此示例的总连接成本如下所示:
SELECT 0.00 + 0.00 AS startup_cost, round(( 1.09 + 1.14 + 8 * 0.0125 + 45 * current_setting('cpu_tuple_cost')::real )::numeric, 2) AS total_cost; startup_cost | total_cost −−−−−−−−−−−−−−+−−−−−−−−−−−− 0.00 | 2.78 (1 row)复制
参数化join
让我们看一个更常见的例子,它不是简单地简化为笛卡尔积。
CREATE INDEX ON tickets(book_ref); EXPLAIN SELECT * FROM tickets t JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no WHERE t.book_ref = '03A76D'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=0.99..45.67 rows=6 width=136) −> Index Scan using tickets_book_ref_idx on tickets t (cost=0.43..12.46 rows=2 width=104) Index Cond: (book_ref = '03A76D'::bpchar) −> Index Scan using ticket_flights_pkey on ticket_flights tf (cost=0.56..16.57 rows=3 width=32) Index Cond: (ticket_no = t.ticket_no) (7 rows)复制
在这里,嵌套循环搜索外部集(票),并为每个外部行搜索内部集(航班),将票号t.ticket_no 作为参数传递下来。在内部循环上调用索引扫描节点时,会使用条件 ticket_no = constant 调用它 。
基数估计。规划器估计 t.book_ref = ‘03A76D’ 过滤器将返回外部集合中的两行 (rows=2),这两行中的每一行在内部集合中平均有三个匹配项 (rows=3)。
连接选择性是连接后保留的笛卡尔积行的分数。这必须排除正在连接的列中具有 NULL 的任何行,因为 NULL 的过滤条件始终为 false。
基数估计为笛卡尔积基数(即两组基数的乘积)乘以选择性。
在这种情况下,外部集的基数估计是两行。至于内部集,没有过滤器(除了连接条件本身)适用于它,因此它的基数等于ticket_flights表的基数。
因为这两个表是使用外键连接的,所以子表的每一行在父表中只有一个匹配对。选择性计算考虑了这一点。在这种情况下,选择性等于外键引用的表大小的倒数。
因此,估计值(假设 ticket_no 行不包含任何 NULL)是:
SELECT round(2 tf.reltuples (1.0 / t.reltuples)) AS rows FROM pg_class t, pg_class tf WHERE t.relname = 'tickets' AND tf.relname = 'ticket_flights'; rows −−−−−− 6 (1 row)复制
自然地,可以在没有外键的情况下连接表。在这种情况下,连接选择性将等于连接条件的选择性。
因此,等值连接(假设数据分布均匀)的“通用”选择性计算公式如下所示:
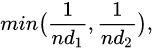
其中 nd1 和 nd2 是第一组和第二组中不同连接键值的数量。
distinct values 统计显示,tickets 表中的所有门票编号都是唯一的(这并不奇怪,ticket_no主键也是如此),但在ticket_flights每个门票中大约有四个匹配行:
SELECT t.n_distinct, tf.n_distinct FROM pg_stats t, pg_stats tf WHERE t.tablename = 'tickets' AND t.attname = 'ticket_no' AND tf.tablename = 'ticket_flights' AND tf.attname = 'ticket_no'; n_distinct | n_distinct −−−−−−−−−−−−+−−−−−−−−−−−− −1 | −0.3054527 (1 row)复制
估计值与外键匹配:
SELECT round(2 tf.reltuples least(1.0/t.reltuples, 1.0/tf.reltuples/0.3054527) ) AS rows FROM pg_class t, pg_class tf WHERE t.relname = 'tickets' AND tf.relname = 'ticket_flights'; rows −−−−−− 6 (1 row)复制
如果此统计信息可用于两个表的连接键,则计划程序会使用最常见的值列表来补充通用公式计算。这为规划者提供了对 MCV 列表中行的相对精确的选择性评估。其余行的选择性仍然被计算为好像它们的值是均匀分布的。直方图不用于提高选择性评估质量。
一般来说,没有外键的连接的选择性最终可能比有定义的外键的连接更差。对于复合键尤其如此。
让我们使用 EXPLAIN ANALYZE 命令检查计划中的实际行数和内部循环调用的数量:
EXPLAIN (analyze, timing off, summary off) SELECT * FROM tickets t JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no WHERE t.book_ref = '03A76D'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=0.99..45.67 rows=6 width=136) (actual rows=8 loops=1) −> Index Scan using tickets_book_ref_idx on tickets t (cost=0.43..12.46 rows=2 width=104) (actual rows=2 loops=1) Index Cond: (book_ref = '03A76D'::bpchar) −> Index Scan using ticket_flights_pkey on ticket_flights tf (cost=0.56..16.57 rows=3 width=32) (actual rows=4 loops=2) Index Cond: (ticket_no = t.ticket_no) (8 rows)复制
正如预期的那样,外部集合包含两行(实际行=2)。内部索引扫描节点被调用两次(循环=2)并且每次平均返回四行(实际行=4)。总计为八行(实际行=8)。
我关闭了每步计时主要是为了保持输出的可读性,但值得注意的是,计时功能可能会在某些平台上大大减慢执行速度。但是,如果我们要重新打开计时,我们会看到计时是平均的,就像行数一样。从那里,您可以将时间乘以循环计数以获得完整的估计。
费用估算。成本计算与前面的示例没有太大区别。这是我们的执行计划:
EXPLAIN SELECT * FROM tickets t JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no WHERE t.book_ref = '03A76D'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=0.99..45.67 rows=6 width=136) −> Index Scan using tickets_book_ref_idx on tickets t (cost=0.43..12.46 rows=2 width=104) Index Cond: (book_ref = '03A76D'::bpchar) −> Index Scan using ticket_flights_pkey on ticket_flights tf (cost=0.56..16.57 rows=3 width=32) Index Cond: (ticket_no = t.ticket_no) (7 rows)复制
内部集的重复扫描成本与初始扫描成本相同。结果:
SELECT 0.43 + 0.56 AS startup_cost, round(( 12.46 + 2 * 16.58 + 6 * current_setting('cpu_tuple_cost')::real )::numeric, 2) AS total_cost; startup_cost | total_cost −−−−−−−−−−−−−−+−−−−−−−−−−−− 0.99 | 45.68 (1 row)复制
行缓存(记忆)
如果您使用相同的参数重复扫描内部集合行并且(因此)每次都获得相同的结果,那么缓存这些行以加快访问速度可能是个好主意。
随着 Memoize 节点的引入,这在 PostgreSQL 14 中成为可能。Memoize 节点在某些方面类似于 Materialize 节点,但它是专门为参数化连接量身定制的,并且在底层要复杂得多:
- Materialize 只是简单地实现其子节点的每一行,而 Memoize 为每个参数值存储单独的行实例。
- 当达到其最大存储容量时,Materialize 会卸载磁盘上的任何额外数据,但 Memoize 不会(因为这会使缓存的任何好处无效)。
下面是一个带有记忆节点的计划:
EXPLAIN SELECT * FROM flights f JOIN aircrafts_data a ON f.aircraft_code = a.aircraft_code WHERE f.flight_no = 'PG0003'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=5.44..387.10 rows=113 width=135) −> Bitmap Heap Scan on flights f (cost=5.30..382.22 rows=113 width=63) Recheck Cond: (flight_no = 'PG0003'::bpchar) −> Bitmap Index Scan on flights_flight_no_scheduled_depart... (cost=0.00..5.27 rows=113 width=0) Index Cond: (flight_no = 'PG0003'::bpchar) −> Memoize (cost=0.15..0.27 rows=1 width=72) Cache Key: f.aircraft_code −> Index Scan using aircrafts_pkey on aircrafts_data a (cost=0.14..0.26 rows=1 width=72) Index Cond: (aircraft_code = f.aircraft_code) (12 rows)复制
首先,规划器分配 work_mem × hash_mem_multiplier 进程内存用于缓存目的。第二个参数hash_mem_multiplier(默认为 1.0)提示节点使用哈希表搜索行(在这种情况下使用开放寻址)。参数(或一组参数)用作缓存键。
除此之外,所有键都放在一个列表中。列表的一端存储“冷”键(一段时间未使用),另一端存储“热”键(最近使用)。
每当调用 Memoize 节点时,它都会检查与传递的参数值对应的行是否已被缓存。如果是,Memoize 将它们返回给父节点(嵌套循环)而不调用子节点。它还将缓存键放入键列表的热端。
如果需要的行还没有被缓存,Memoize 从子节点请求行,缓存它们并向上传递。新的缓存键也被放入列表的热端。
随着缓存填满,分配的内存可能会用完。发生这种情况时,Memoize 会从列表中删除最冷的项目以释放空间。该算法与缓冲区高速缓存中使用的算法不同,但服务于相同的目标。
如果一个参数匹配的行太多以至于即使删除了所有其他条目也无法放入缓存中,则根本不会缓存该参数的行。缓存部分输出没有意义,因为下次参数出现时,Memoize 仍然必须调用其子节点才能获得完整输出。
这里的基数和成本估算与我们之前看到的相似。
这里值得注意的一点是,计划中的 Memoize 节点成本只是其子节点的成本加上cpu_tuple_cost并没有太大意义。
我们想要该节点的唯一原因是降低成本。Materialize 节点也有同样的不确定性:“真正的”节点成本是重复扫描成本,它没有在计划中列出。
Memoize 节点的重复扫描成本取决于可用内存量和访问缓存的方式。它还很大程度上取决于预期的不同参数值的数量,这决定了内部集合扫描的数量。有了所有这些变量,您可以尝试计算在缓存中找到给定行的概率以及从缓存中逐出给定行的概率。第一个值降低成本估算,另一个值增加它。
这个计算的细节与本文的主题无关。
现在,让我们使用我们最喜欢的EXPLAIN ANALYZE命令来检查一个带有 Memoize 节点的计划是如何执行的。
此示例查询选择与特定飞行路径和特定飞机类型匹配的所有航班,因此所有 Memoize 调用的缓存键将相同。所需的行不会在初始调用时被缓存(未命中:1),但对于所有重复调用(命中:112),它将在那里。缓存本身总共占用了一千字节的内存。
EXPLAIN (analyze, costs off, timing off, summary off) SELECT * FROM flights f JOIN aircrafts_data a ON f.aircraft_code = a.aircraft_code WHERE f.flight_no = 'PG0003'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (actual rows=113 loops=1) −> Bitmap Heap Scan on flights f (actual rows=113 loops=1) Recheck Cond: (flight_no = 'PG0003'::bpchar) Heap Blocks: exact=2 −> Bitmap Index Scan on flights_flight_no_scheduled_depart... (actual rows=113 loops=1) Index Cond: (flight_no = 'PG0003'::bpchar) −> Memoize (actual rows=1 loops=113) Cache Key: f.aircraft_code Hits: 112 Misses: 1 Evictions: 0 Overflows: 0 Memory Usage: 1kB −> Index Scan using aircrafts_pkey on aircrafts_data a (actual rows=1 loops=1) Index Cond: (aircraft_code = f.aircraft_code) (15 rows)复制
请注意两个零值:驱逐和溢出。前一个是从缓存中逐出的次数,后一个是内存溢出的次数,其中给定参数值的完整输出大于分配的内存大小,因此无法缓存。
高 Evictions 和 Overflows 值表明分配的缓存大小不足。当可能的参数值的数量估计不正确时,通常会发生这种情况。在这种情况下,使用 Memoize 节点可能会变得非常昂贵。作为最后的手段,您可以通过将enable_memoize参数设置为off来禁用缓存。
外连接
您可以使用嵌套循环执行左外连接:
EXPLAIN SELECT * FROM ticket_flights tf LEFT JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no AND bp.flight_id = tf.flight_id WHERE tf.ticket_no = '0005434026720'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop Left Join (cost=1.12..33.35 rows=3 width=57) Join Filter: ((bp.ticket_no = tf.ticket_no) AND (bp.flight_id = tf.flight_id)) −> Index Scan using ticket_flights_pkey on ticket_flights tf (cost=0.56..16.57 rows=3 width=32) Index Cond: (ticket_no = '0005434026720'::bpchar) −> Materialize (cost=0.56..16.62 rows=3 width=25) −> Index Scan using boarding_passes_pkey on boarding_passe... (cost=0.56..16.61 rows=3 width=25) Index Cond: (ticket_no = '0005434026720'::bpchar) (10 rows)复制
注意 Nested Loop Left Join 节点。对于这个特定的查询,规划器选择了一个非参数化的过滤连接:这意味着每个循环都会对内部行集进行相同的扫描(这就是它“隐藏”在 Materialize 节点后面的原因),并且输出在连接处被过滤过滤节点。
外连接的基数估计与内连接的计算方法相同,但结果是计算结果与外集的基数之间的较大值。换句话说,外连接可以有更多的行,但绝不会比更大的连接集少。
外连接的成本估算计算与内连接的完全一样。
但是请记住,规划器可能会为内部连接选择与外部连接不同的计划。即使在这个例子中,如果我们强制规划器使用嵌套循环连接,我们会注意到连接过滤器节点的不同,因为外部连接必须检查票号匹配以获得正确的结果,只要没有对在外集。这将略微增加总体成本。
SET enable_mergejoin = off; EXPLAIN SELECT * FROM ticket_flights tf JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no AND bp.flight_id = tf.flight_id WHERE tf.ticket_no = '0005434026720'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop (cost=1.12..33.33 rows=3 width=57) Join Filter: (tf.flight_id = bp.flight_id) −> Index Scan using ticket_flights_pkey on ticket_flights tf (cost=0.56..16.57 rows=3 width=32) Index Cond: (ticket_no = '0005434026720'::bpchar) −> Materialize (cost=0.56..16.62 rows=3 width=25) −> Index Scan using boarding_passes_pkey on boarding_passe... (cost=0.56..16.61 rows=3 width=25) Index Cond: (ticket_no = '0005434026720'::bpchar) (9 rows) RESET enable_mergejoin;复制
右连接与嵌套循环不兼容,因为嵌套循环算法区分内部集和外部集。外部集被完全扫描,但如果使用索引扫描访问内部集,则仅返回与连接过滤器匹配的行。因此,某些行可能保持未扫描状态。
出于同样的原因,完全连接也是不兼容的。
反连接和半连接
反连接和半连接在某种意义上是相似的,对于第一个(外部)集合的每一行,两种算法都希望在第二个(内部)集合中只找到一个匹配项。
反连接返回第一组中没有在第二组中匹配的所有行。换句话说,算法从外部集合中取出一行并在内部集合中搜索匹配项,一旦找到匹配项,算法就会停止搜索并跳转到外部集合的下一行。
反连接对于计算NOT EXISTS谓词很有用。示例:查找所有没有定义座位模式的飞机模型:
EXPLAIN SELECT * FROM aircrafts a WHERE NOT EXISTS ( SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code ); QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop Anti Join (cost=0.28..4.65 rows=1 width=40) −> Seq Scan on aircrafts_data ml (cost=0.00..1.09 rows=9 widt... −> Index Only Scan using seats_pkey on seats s (cost=0.28..5.55 rows=149 width=4) Index Cond: (aircraft_code = ml.aircraft_code) (5 rows)复制
Nested Loop Anti Join 节点是执行 antijoin 的地方。
当然,这不是反连接的唯一用途。此等效查询还将生成一个带有反连接节点的计划:
EXPLAIN SELECT a.* FROM aircrafts a LEFT JOIN seats s ON a.aircraft_code = s.aircraft_code WHERE s.aircraft_code IS NULL;复制
半连接返回第一组中与第二组匹配的所有行(这里也不搜索重复匹配,因为它们不会以任何方式影响结果)。
半连接用于计算EXISTS谓词。让我们找到所有具有定义座位模式的飞机:
EXPLAIN SELECT * FROM aircrafts a WHERE EXISTS ( SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code ); QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop Semi Join (cost=0.28..6.67 rows=9 width=40) −> Seq Scan on aircrafts_data ml (cost=0.00..1.09 rows=9 widt... −> Index Only Scan using seats_pkey on seats s (cost=0.28..5.55 rows=149 width=4) Index Cond: (aircraft_code = ml.aircraft_code) (5 rows)复制
Nested Loop Semi Join 是节点。
在这个计划(以及上面的 anitjoin 计划)中,seats表有一个常规的行数估计(行数=149),而我们知道我们只需要从中获取一行。执行查询时,循环将在获取行后停止,当然。
EXPLAIN (analyze, costs off, timing off, summary off) SELECT * FROM aircrafts a WHERE EXISTS ( SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code ); QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop Semi Join (actual rows=9 loops=1) −> Seq Scan on aircrafts_data ml (actual rows=9 loops=1) −> Index Only Scan using seats_pkey on seats s (actual rows=1 loops=9) Index Cond: (aircraft_code = ml.aircraft_code) Heap Fetches: 0 (6 rows)复制
半连接基数估计照常计算,除了内部集基数设置为 1。至于 anitjoin 选择性,估计也照常计算,然后从 1 中减去。
反连接和半连接的成本估计是根据以下事实计算的:对于大多数外部集合行,只扫描一小部分内部集合行。
非等值连接
嵌套循环连接算法可以使用任何连接条件连接行集。
自然,如果内集是基表,表有索引,索引的算子类包含连接条件算子,那么内集的行可以非常高效地访问。
除此之外,任何两组行都可以通过过滤连接条件连接为笛卡尔积,这里的条件可以是任意的。这是一个示例:查找彼此相邻的机场对。
CREATE EXTENSION earthdistance CASCADE; EXPLAIN (costs off) SELECT * FROM airports a1 JOIN airports a2 ON a1.airport_code != a2.airport_code AND a1.coordinates <@> a2.coordinates < 100; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop Join Filter: ((ml.airport_code <> ml_1.airport_code) AND ((ml.coordinates <@> ml_1.coordinates) < '100'::double precisi... −> Seq Scan on airports_data ml −> Materialize −> Seq Scan on airports_data ml_1 (6 rows)复制
并联模式
嵌套循环连接可以在并行模式下运行。
并行化在外部集级别完成,并允许多个工作进程同时扫描外部集。每个工作人员从外部集合中获取一行,然后自行依次扫描内部集合。
下面是一个多连接查询示例,用于查找拥有特定航班机票的所有乘客:
EXPLAIN (costs off) SELECT t.passenger_name FROM tickets t JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no JOIN flights f ON f.flight_id = tf.flight_id WHERE f.flight_id = 12345; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Nested Loop −> Index Only Scan using flights_flight_id_status_idx on fligh... Index Cond: (flight_id = 12345) −> Gather Workers Planned: 2 −> Nested Loop −> Parallel Seq Scan on ticket_flights tf Filter: (flight_id = 12345) −> Index Scan using tickets_pkey on tickets t Index Cond: (ticket_no = tf.ticket_no) (10 rows)复制
像往常一样,顶级嵌套循环连接按顺序运行。外部集合包含使用唯一键获取的表中的单行flights,因此即使内部集合中有大量行,嵌套循环也很有效。
内部集合以并行模式收集。每个工作人员获取自己的行,通过嵌套循环中,从 ticket_flights 与 tickets 的连接进行获取。
未完待续。
原文标题:Queries in PostgreSQL: 5. Nested loop
原文作者:Egor Rogov
原文地址:https://postgrespro.com/blog/pgsql/5969618



