





此篇文章可能略长,如一次看不完,可以置顶,下次继续,主要是我太爱你们了,想把我知道的都告诉你,所以勿介意
远看忽忽悠悠,近看飘飘摇摇,在水中一出一冒,有人说是葫芦有人说是瓢,二人打赌江边瞧,原来是和尚洗澡。
上文书《春节大放送|MGR开篇》只讲了些皮毛,这次续篇,来给它洗个澡,神秘的面纱下到底是神还是妖。

下面咱们先说下这个组件给我们提供了哪些视图,方便我们日常运维和诊断问题。在performance_schema下包括以下视图,这些视图的功能从名字中可以基本了解个大概,具体详细的参数说明,可以参见官方文档,这里不一一赘述。
replication_group_members
replication_group_member_stats
replication_connection_configuration
replication_connection_status
replication_applier_configuration
replication_applier_status
replication_applier_status_by_coordinator
replication_applier_status_by_worker
日常诊断最常用的视图是replication_group_members,replication_group_member_stats,replication_applier_status_by_worker,第一个是成员信息,第二个是事务执行情况以及冲突检测和队列状态,第三个是线程执行的具体进度。接下来,从头到脚扒一扒MGR的独特之处。

集群的每一次成员变化(加/减)都会触发view change机制,即集群变化的一个mark,会写入binlog,那么在此点就是一个分隔点,如果是加入节点,那么该点之前的就通过recovery机制追以前数据,此点之后就通过applier补录新集群产生的数据,稍后介绍这两个的区别。
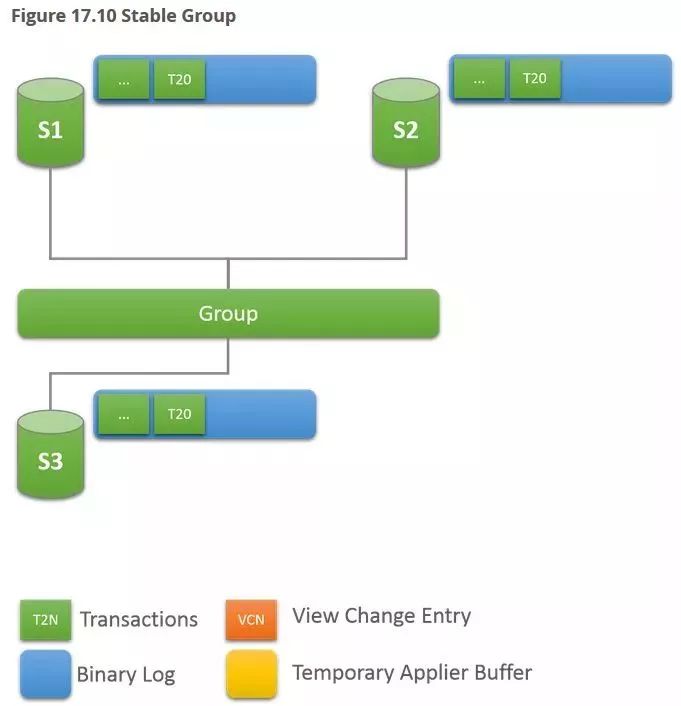
如下图所示,该集群有当前有3个节点S1,S2,S3。
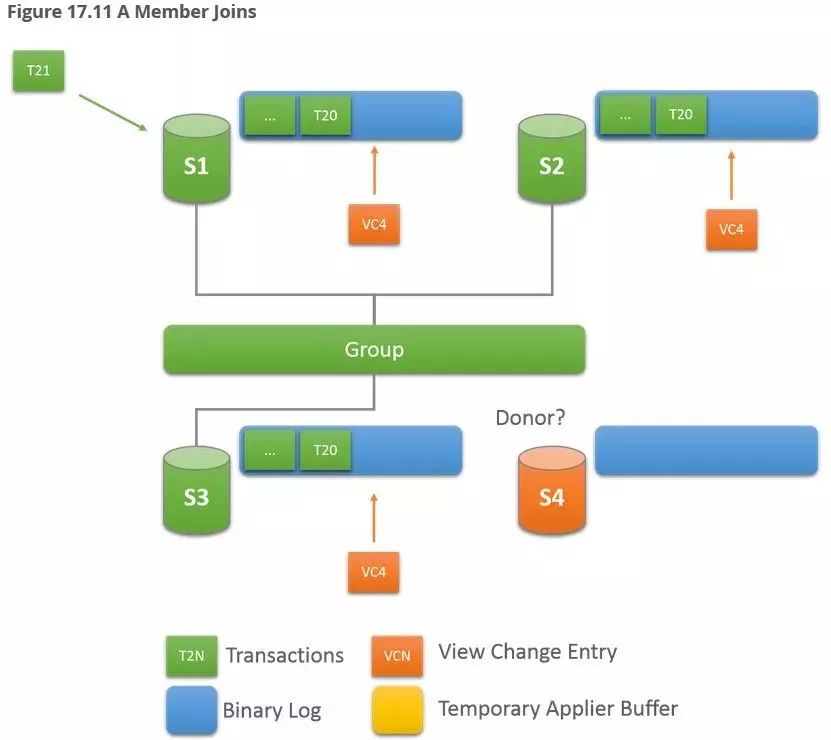
加入一个新节点S4,此刻产生了新的view change 4,写入binlog。
新加入的节点会选择一个节点(也就是donor节点)追缺少的数据,在追齐数据之前,该节点状态是 RECOVERING。
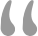
donor节点的选取与参数 group_replication_ip_whitelist,group_replication_group_seeds 有关,前者是ip白名单,后者是种子节点,系统会自动从种子列表中选择节点作为donor(其实系统也不是漫无目的的随便选,还是会根据applier的进度来判断该节点是否适合做数据拉取,这个话题先不展开了,有兴趣的可以自己试试),目前版本还不能手动指定(变通方式是通过修改参数),另外就是选取的时候如果当前选定的节点连接失败,会自动连接其余可用节点,直至达到retry设定的阈值。
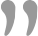
从下图可知,新加入的S4选择S2作为donor节点,拉取数据,细心的小伙伴应该已经产生了疑问,就是恢复过程中涉及到的两阶段,其中有没有隐藏些什么问题点需要我们强烈关注?
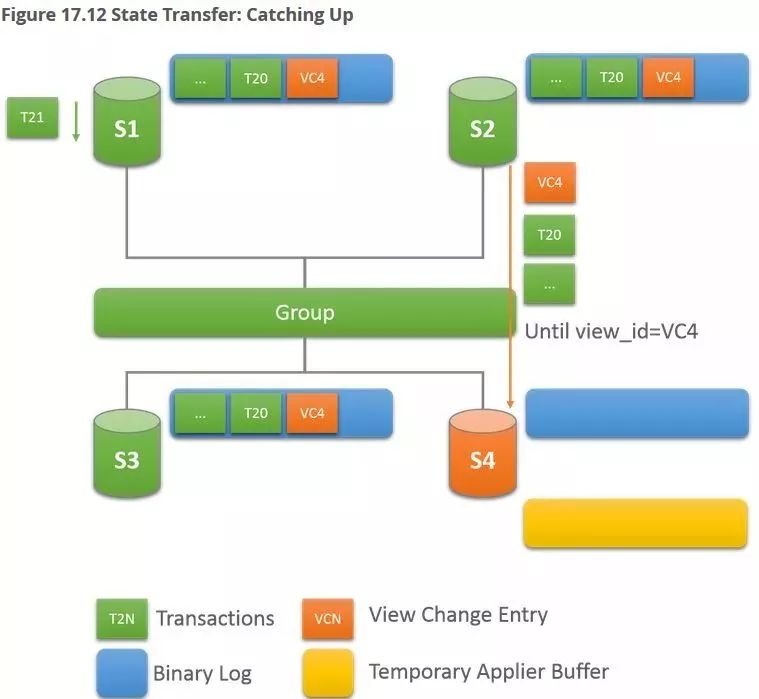
接下来聊聊这个恢复阶段。
一旦你开始用MGR,就发现目录中多了一些莫名的文件,如下图,其中一部分是recovery文件,另一部分是applier文件,这两部分文件就组成了恢复过程中涉及到的两阶段。

阶段一,节点初加入集群时会产生view change,这之前的数据通过传统的异步复制方式进行补录,该阶段的执行情况可以通过show slave命令观察,也可以通过之前提到的那几个视图进行观察。
举例show方式,命令如下
show slave status for channel 'group_replication_recovery';
内容部分我想不用我介绍,你比我都熟悉了,强大的小伙伴们

阶段二,终于追上你了,recovery线程这会终于可以休息了,recovery文件写完,不再更新,该换老大applier上场了,话说老大这会可能已经等了很久了(加入的新节点如果缺少很多数据,或者donor负载较高,恢复时间都会延长),而这之间,集群还在一直写数据,不会因为有新来的,就会停下来等他的,这就导致applier刚一出马,也有很重的活要做,于是开始写applier文件,但此前积攒的事务放哪里呢?
答:先写applier文件,然后等着线程开始再从头撸?


不行,这些数据还没消费,不能写文件,只能先放内存里保存着,就是所谓的temporary applier buffer,估计小伙伴们也注意到了,那这得用多少内存!

对,你说对了,就用这么多,内存使用量与view change后产生的binlog量相当,该何时加入新节点,我想你已经心中有数了。
关于这部分内容,在上个贴图,让你印象更深刻一些。
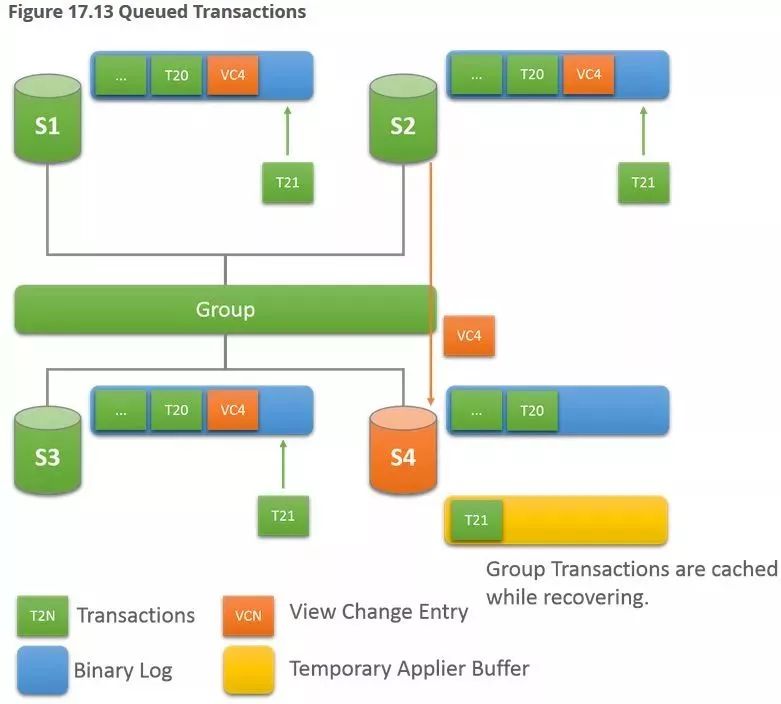
最终,加入节点状态变成ONLINE,完美,来张图纪念一下。
网络对MGR的打击是致命的,直戳小心脏
 ,当然这也不能全怪人家,你说你网络不好,你怪我喽。现在5G都已经on the way了,是不是咱就别吐槽了,心中有数就行了。
,当然这也不能全怪人家,你说你网络不好,你怪我喽。现在5G都已经on the way了,是不是咱就别吐槽了,心中有数就行了。
单主情况下,如果Primary节点与大多数Secondary节点网络不通,将直接阻塞事务,导致挂起,如果仅少数Secondary节点网络出现问题,不会阻塞业务,但有一个很明显的性能下降,经试验发现正常情况下能跑5000的tps,这种情况下,仅有50+的tps,下降到1%(关闭了流控,启用了100byte的压缩),网络恢复正常后,tps逐渐恢复至正常水平。
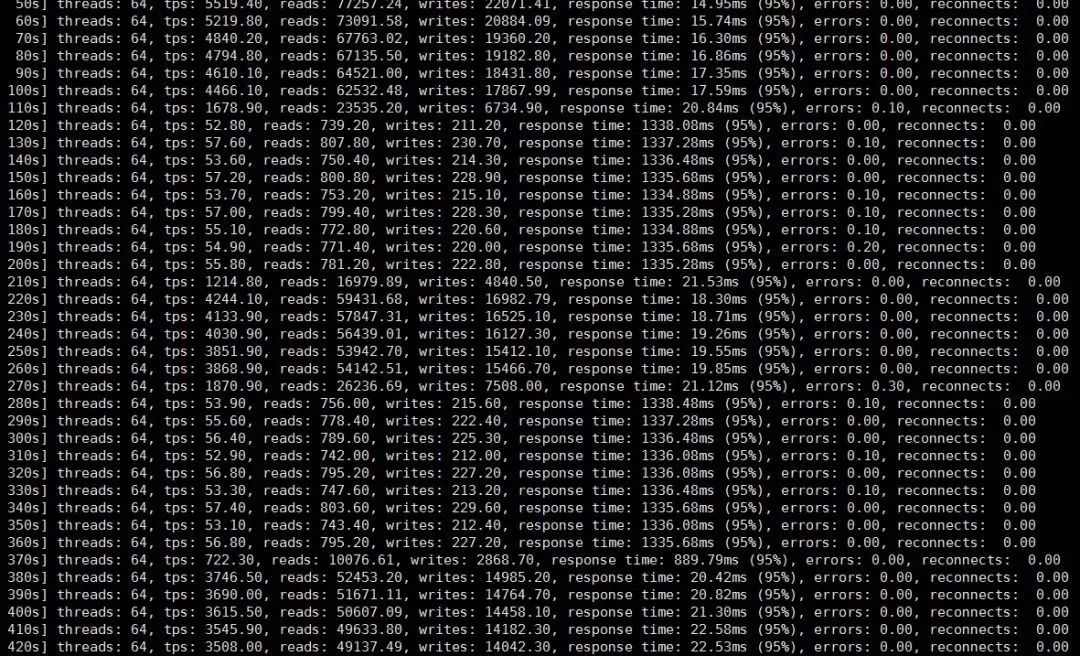
多主情况下,个别Primary节点出现网络故障后会挂起该节点事务,其余Primary节点依然继续业务操作(不包括DDL与DML这种冲突情况),从而避免脑裂的发生。
另外,既然这里提到性能了,就再提供一个链接(http://mysqlhighavailability.com/an-overview-of-the-group-replication-performance),可以从中得到你关心的性能情况,结论与其一致。
这部分说下很多小伙伴关心的DDL与DML问题,也是一个很现实的问题,单主情况下就不讨论了,多主情况下,先给一段官方的描述。
Note
If the group is deployed in single-primary mode, then this is not a problem, because all changes are performed through the same server, the primary.
Warning
MySQL DDL execution is not atomic or transactional. The server executes and commits without securing group agreement first. As such, you must route DDL and DML for the same object through the same server, while the DDL is executing and has not replicated everywhere yet.
——官网
以上的意思大家自己领悟哈,我解释不到位,就知道如果有DDL和DML操作相同对象,要在同一个节点,如果在不同节点操作,问题就大了(这个也很容易验证,后果就是不一致)。那么我们就不理解了,我用多主就是为了提高效率,这样不就又变成单主了么?我们日常运维过程中,对DDL使用最多的情况就是采用OSC方案,那么把这个方案放这里能满足我们的要求么?
在满怀希望的心情下,下边开始操作

tx_isolation:READ-COMMITTED
step1 Primary211持续load数据
step2 Primary210无操作,Primary212执行OSC
pt-online-schema-change --user=xx --socket=xx --alter "add COLUMN e bigint NOT NULL DEFAULT 0 " D=mgrtest,t=t --execute
情况一 innodb_autoinc_lock_mode=1 (默认值)
命令执行失败,如下图所示
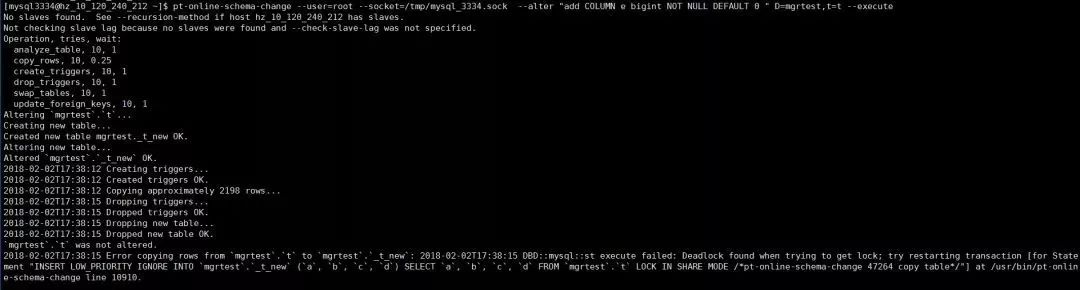
TABLE LOCK table TABLE LOCK table `mgrtest`.`_t_new` trx id 10471081 trx id 10471081 lock mode AUTO-INC waiting
....
INSERT LOW_PRIORITY IGNORE INTO `mgrtest`.`_t_new` (`a`, `b`, `c`, `d`) SELECT `a`, `b`,`c`, `d` FROM `mgrtest`.`t` LOCK IN SHARE MODE *pt-online-schema-change 47264 copy table*/
2018-02-02T09:38:12.542869Z 48 [Note] InnoDB: *** (2) HOLDS THE LOCK(S):
TABLE LOCK table `mgrtest`.`_t_new``mgrtest`.`_t_new` trx id 10471076 trx id 10471076 lock mode AUTO-INC
OSC在默认自增锁模式下,因bulk insert 的执行与event 的insert 执行会造成死锁,即不能在不同节点对相同对象同时执行DDL与DML。
情况二 innodb_autoinc_lock_mode=2 (不加锁)
Primary212 OSC命令执行成功,但数据发生不一致
Primary211持续load成功,没有被阻塞
Primary212/primary210停止复制
关于这部分内容,就不展开分析了,内容有点多,结论是最终集群发生数据不一致。
所以呢,我们要老老实实、认认真真的阅读官方文档,不要你做的不要去做,除非你已经认识到并能接收这个risk(官方文档用语)。
这部分理解起来就很简单多了,官方描述也很清晰,也是大家认为的那样(哪样啊 )。
)。
流控就是控制queue大小,涉及参数
group_replication_flow_control_mode
group_replication_flow_control_applier_threshold
group_replication_flow_control_certifier_threshold
我们可以控制queue大小和关闭流控,如果达到阈值,会截流。
压缩参数默认1MB,如小事务很多,建议调小。
事务大小参数比较关键,如果事务过大(like tpcc),将导致集群挂起,参数group_replication_transaction_size_limit默认值0,即无限制,我们需要根据业务需求,设置合理值,其实innodb已经有参数max_binlog_cache_size做了一层保护,不过鉴于重要程度,还是需要根据业务设置合理的值。
好了,唠叨的差不多了,重要关键部位都撸完了,估计小伙伴们也能了解个七七八八了,如有需求,再续写第三季了,最后别忘了点赞和关注哦。

网易乐得DBA组负责网易乐得电商、网易邮箱、网易技术部数据库日常运维
负责数据库私有云平台的开发和维护
负责数据库及数据库中间件的开发和测试等
分享最前沿实用数据库干货
关注网易乐得DBA
精深数据库神功

