





上篇文章《从5.6到8.0看MySQL写Redo进化史》介绍了Buffer Pool中多种链表的管理,相信大家对这些链表有了初步的认识,同时也有一些关于刷新脏页的疑问,本文就继续介绍InnoDB的脏页刷新策略——Checkpoint机制及Redo Log刷盘规则。
Checkpoint机制
在介绍checkpoint机制前先了解两个概念:
脏页(Dirty Page)
如果一个数据页在内存中修改了,但是还没有刷新到磁盘。这个数据页就称为脏页
日志顺序号(Log Sequence Number)
LSN表示重做日志的序号,8字节的数字,特点是单调递增型,代表每个重做日志的编号,也就意味着每个日志都有一个LSN与其对应。另外LSN的增长是使用字节偏移量来表示,就是重做日志每增加多少个字节,LSN就增加多少字节,所以LSN也是事务写入到重做日志的字节总量。
LSN不仅仅记录在重做日志中,它存在于多个对象中,表示的含义各不相同:重做日志(redo log)、页(page)、检查点(checkpoint)。在每个Page上都有对应的这个页第一次修改的LSN号和最新一次修改的LSN号(通过系统视图 information_schema.INNODB_BUFFER_PAGE_LRU 可以看到)。
每个页头部有一个值FIL_PAGE_LSN,该变量用于记录页的LSN,表示该页最后刷新时LSN的大小。因为重做日志记录的是每个页的日志,因此页中的LSN用来判断页是否需要进行恢复操作。例如,页P1的LSN为1000,而数据库启动时,InnoDB检测到写入重做日志中该P1页LSN为1300,并且该事务已经提交,那么数据库需要进行恢复操作,将重做日志应用到P1页中。同样的,对于重做日志中LSN小于P1页的LSN,则不需要进行重做,因为P1页中的LSN表示页已经被刷新到该位置。
Checkpoint(检查点)也通过LSN的形式来保存,其表示页已经刷新到磁盘的LSN位置,当数据库重启时,仅需从检查点开始进行恢复操作。若检查点的LSN与重做日志相同(但一般不会遇见检查点LSN与重做日志LSN相同,一般重做日志LSN比检查点LSN大,具体后面说),表示所有页都已经刷新到磁盘,不需要进行恢复操作了。用Redo Log LSN减去Checkpoint LSN就是需要恢复的数据。
Checkpoint解决的问题:
缩短数据库恢复时间
当数据库发生宕机时,数据库不需要重做所有的Redo Log,因为Checkpoint之前的页都已经刷新回磁盘。数据库只需对Redo Log LSN – Checkpoint LSN的重做日志进行恢复,大大缩短了恢复的时间。
确保缓冲池有空闲页
当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
确保重做日志有空间
当前事务数据库系统对重做日志的设计都是循环使用的,并不会让其无限增大。重做日志可以被重用的部分是指这些重做日志已经不再被需要,即数据页已经被持久化到磁盘上了。当数据库发生宕机时,数据库恢复操作不需要这部分的重做日志,因此这部分就可以被覆盖重用。如果重做日志写入过快或其他原因,为了避免数据丢失,那么当重做日志到达某个水平线之时就必须强制Checkpoint,最小也需要保持重做日志的剩余空间保持在这个水平线。
Checkpoint工作机制
在InnoDB存储引擎内部,有两种Checkpoint,分别为:Sharp Checkpoint,Fuzzy Checkpoint。Sharp Checkpoint发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,即参数innodb_fast_shutdown=1。但是若数据库在运行时也使用Sharp Checkpoint,那么数据库的可用性就会受到很大的影响,因为一次刷新太多脏页可能会导致数据库被hang住。故在InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页(通过各种复杂的条件计算出脏页刷新数),而不是刷新所有的脏页回磁盘。
在InnoDB存储引擎中可能发生如下几种情况的Fuzzy Checkpoint:
Master Thread Checkpoint
FLUSH_LRU_LIST Checkpoint
Async/Sync Flush Checkpoint
Dirty Page too much Checkpoint。
Master Thread Checkpoint
Master线程以大概每1秒或10秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,此时InnoDB存储引擎可以进行其他的操作,用户查询线程不会阻塞。Master线程每次刷新的脏页数比较少,可以通过调整如下参数来控制:
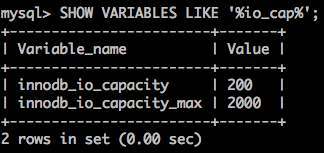
innodb_io_capacity表示磁盘IO的吞吐量,默认值为200。Master线程每次刷新到磁盘页的数量受该值的控制。当使用了SSD磁盘,或者磁盘做了RAID,存储设备拥有更高IO速度时,可以将该值调大,增加Master线程每次刷新脏页的数量,直到匹配磁盘IO的吞吐量。
FLUSH_LRU_LIST Checkpoint
在InnoDB 1.1.x版本之前,因为InnoDB存储引擎需要保证LRU列表中需要有差不多100个空闲页可供使用,需要检查LRU列表中是否有足够的可用空间操作发生在用户查询线程中,显然这会阻塞用户的查询操作。倘若没有100个可用空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除。如果这些页中有脏页,那么需要进行Checkpoint,并且会从FLUSH链表中把这个脏页信息移除,防止重复刷新。因为这些脏页是来自LRU列表的,因此称为FLUSH_LRU_LIST Checkpoint。
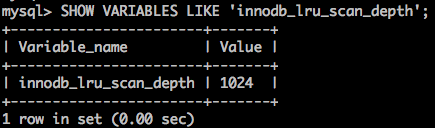
而从MySQL 5.6版本,也就是InnoDB 1.2.x版本开始,这个检查被放在了一个单独的Page Cleaner线程中进行,并且用户可以通过innodb_lru_scan_depth参数控制LRU列表中可用页的数量,也就是每次LRU链表扫描的深度,该值默认为1024。
此情况下触发,默认扫描1024个LRU冷端数据页,将脏页写入磁盘(有10个就刷10,有100个就刷100个)。
Async/Sync Flush Checkpoint
在重做日志文件不可用的情况,需要强制将一些页刷新回磁盘,而此时脏页是从脏页列表中选取的。为什么会出现不可用呢?因为除了重做日志缓冲在事务提交时需要刷新到磁盘外,其它一些LSN信息都是异步地刷新到持久存储上的。因为即使发生宕机,都可以通过重做日志文件进行恢复。因此存在其它位置的LSN和重做日志LSN产生一定的距离。而这些距离,在实际的应用中可能会非常大。若将已经写入到重做日志的LSN记为redo_lsn,将已经刷新回磁盘最新页的LSN记为checkpoint_lsn,则可以定义:checkpoint_age = redo_lsn – checkpoint_lsn,即未刷新重做日志大小。再定义以下变量:
async_water_mark = 75% * total_redo_log_file_size 到达重做日志75%触发异步刷新脏页
sync_water_mark = 90% * total_redo_log_file_size 到达重做日志90%触发同步刷新脏页
若每个重做日志文件的大小为1GB,并且定义了两个重做日志文件,则重做日志文件的总大小为2GB。那么async_water_mark = 1.5GB,sync_water_mark = 1.8GB。则:
当checkpoint_age < async_water_mark时,不需要刷新任何脏页到磁盘;
当async_water_mark < checkpoint_age < sync_water_mark时触发Async Flush,从缓冲池的Flush列表中刷新足够的脏页回磁盘,使得刷新后满足checkpoint_age < async_water_mark。
当checkpoint_age > sync_water_mark时,MySQL会停止事务的更新,此时Redo Log也会停止写入,必须等到刷足够的脏页时,才能允许事务再次提交。这种情况一般很少发生,除非设置的重做日志文件太小,并且在进行类似LOAD DATA的BULK INSERT操作。此时触发Sync Flush操作,从Flush列表中刷新足够的脏页回磁盘,使得刷新后满足checkpoint_age < async_water_mark。
可见,Async/Sync Flush Checkpoint是为了保证重做日志的循环使用的可用性。在InnoDB 1.2.x版本之前,Async Flush Checkpoint会阻塞发现问题的用户查询线程,而Sync Flush Checkpoint会阻塞所有的用户查询线程,并且等待脏页刷新完成。从InnoDB 1.2.x版本开始——也就是MySQL 5.6版本,这部分的刷新操作同样放入到了单独的Page Cleaner Thread中,故不会阻塞用户查询线程。
Dirty Page too much Checkpoint
最后,如果脏页的数量太多,也会导致InnoDB存储引擎强制进行Checkpoint,其目的总的来说还是为了保证缓冲池中有足够可用的页。由参数innodb_max_dirty_pages_pct控制:

innodb_max_dirty_pages_pct值为75表示,当缓冲池中脏页的数量占据75%时,强制进行Checkpoint,刷新一部分脏页到磁盘。在InnoDB 1.0.x版本之前,该参数默认值为90,之后的版本都为75。当然这个机制跟上面说的checkpoint_age机制是不相同的,两者并行。
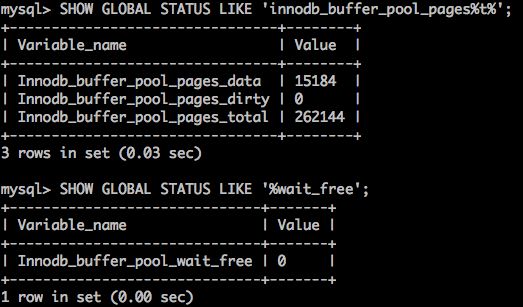
Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total表示脏页在Buffer中的占比。Innodb_buffer_pool_wait_free如果大于0,说明Buffer Pool Free List中暂无可用空闲页,数据库出现性能负载。
故障恢复机制
当MySQL Crash的时候,由于Checkpoint LSN表示已经刷新到磁盘页上的日志,因此在恢复过程中仅需恢复Checkpoint之后的日志部分。比如当数据库Checkpoint LSN为1000时发生宕机,重做日志刷新到的位置为1300,恢复操作仅恢复 1300 – 1000 这部分重做日志到Buffer Pool中。
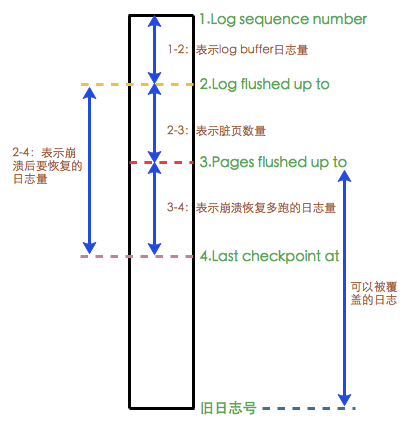
InnoDB的一条事务日志共经历4个阶段:
创建阶段:当前最新LSN,创建一条Redo日志,此时在Buffer Pool中,记为LSN1。
日志刷盘:记录日志持久化到磁盘上重做日志文件的LSN,记为LSN2。
数据刷盘:脏页数据刷新到磁盘数据文件的LSN,记为LSN3。
写Checkpoint:最近一次检查点对应的LSN,脏页数据刷新到磁盘数据文件时最老的LSN。此检查点之前的脏数据都已经刷新到磁盘,同时也是崩溃恢复时指定的起点,记为LSN4。
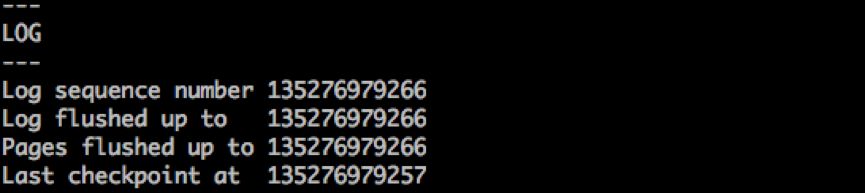
上图是在show engine innodb status中查看的数据库当前的相关LSN值,下图是各个LSN值之间的关系。
Redo Log刷盘规则
log buffer中未刷到磁盘的日志称为脏日志(dirty log)。默认情况下事务每次提交的时候都会刷事务日志到磁盘中,这是因为变量 innodb_flush_log_at_trx_commit 的值为1。但是innodb不仅仅只会在有commit动作后才会刷日志到磁盘,这只是innodb存储引擎刷日志的规则之一。
刷日志到磁盘有以下几种规则:
发出commit动作时。commit发出后是否刷日志由变量 innodb_flush_log_at_trx_commit 控制。
每秒刷一次。这个刷日志的频率由变量 innodb_flush_log_at_timeout 值决定,默认是1秒。要注意,这个刷日志频率和commit动作无关。
当log buffer中已经使用的内存超过一半时。
当有checkpoint时,checkpoint在一定程度上代表了刷到磁盘时日志所处的LSN位置。
总结
本篇内容大致介绍了Checkpoint解决的问题,Checkpoint工作机制,故障恢复机制以及Redo刷盘规则。通过知识储备这两篇文章的介绍,相信大家对Buffer Pool中的链表,LRU算法,Checkpoint机制以及Redo刷盘策略有了一定的了解,下篇文章会通过对比MySQL 5.7与8.0两个版本,详细介绍8.0中并行写Redo的机制。
网易开源中间件Cetus的github地址
https://github.com/Lede-Inc/cetus/blob/master/doc/cetus-quick-try.md 欢迎加star关注
社群
技术专家在线及时反馈
Cetus开源qq群号 521824702
Cetus开源微信群2
欢迎分享

网易乐得DBA组负责网易乐得电商、网易邮箱、网易技术部数据库日常运维,负责数据库私有云平台的开发和维护,负责数据库及数据库中间件的开发和测试等,分享最前沿实用数据库干货,关注网易乐得DBA,精修数据库功底。

