




目录
3.1. RAC 架构概述
3.2. 11 件加强RAC 环境的事情
Applies to:
Purpose
Scope
Details
1. 在您的环境中应用最新的 Patchset Update (PSU)
2. 确保 UDP 缓冲区大小合适
3. 在所有版本 10.2 和 11.1 集群上将 DIAGWAIT 的值设置为 13
4. 在 Linux 环境中实施 HugePage
5. 实施 OS Watcher 和(或) Cluster Health Monitor
6. 按照最佳实践配置 OS 设置
7. 确保在 AIX 平台上应用合适的 APARS 以避免出现过量分页/交换问题
8. 应用 NUMA 补丁
9. 增加 Windows 非交互式 Desktop Heap
10. 运行 RACcheck 实用程序
11. 使用 slewing 选项实施 NTP
3.3 RAC 日常运维管理的内容
3.4. RACcheck 工具的使用
3.5. RAC 补丁管理方面建议
安装注意事项
补丁安装注意事项
3.6. RAC 常见问题解答
Applies to:
Purpose
Scope
Details
问题 1:节点重新启动,但是日志文件未显示任何错误或原因。
问题 2:节点重新启动,该节点是由于丢失网络心跳而被逐出。
问题 3:在出现存储问题后节点重新启动。
问题 4:asm 或数据库实例被挂起或驱逐后节点重新启动。
问题 5:CRS 自动重启,但是节点没有重新启动
References
3.7. RAC 升级方面建议
升级注意事项
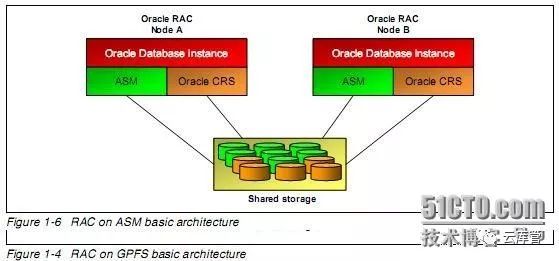
3.1. RAC 架构概述
参看ORACLE RAC 管理员手册 《第一章 简介》
|
保持 RAC 群集环境稳定当前必须要做的 11 件事 [ID 1525819.1] |
修改时间:2013-2-16 类型:BULLETIN状态:PUBLISHED优先级:1 |
|
In this Document
Purpose |
Scope |
Details |
1. 在您的环境中应用最新的 Patchset Update (PSU) |
2. 确保 UDP 缓冲区大小合适 |
3. 在所有版本 10.2 和 11.1 集群上将 DIAGWAIT 的值设置为 13 |
4. 在 Linux 环境中实施 HugePage |
5. 实施 OS Watcher 和(或) Cluster Health Monitor |
6. 按照最佳实践配置 OS 设置 |
7. 确保在 AIX 平台上应用合适的 APARS 以避免出现过量分页/交换问题 |
8. 应用 NUMA 补丁 |
9. 增加 Windows 非交互式 Desktop Heap |
10. 运行 RACcheck 实用程序 |
11. 使用 slewing 选项实施 NTP |
References |
Applies to:
Oracle Database - EnterpriseEdition - Version 10.2.0.1 to 11.2.0.2 [Release 10.2 to 11.2]
Information in this document applies to any platform.
Purpose
许多 RAC 不稳定的问题皆可归因于没有实施一个其实很短的最佳实践和(或)配置列表。本文档旨在提供一种简单的方法,找出这些常被遗漏的最佳实践和(或)配置问题的列表,以期可以防止这些问题引起的系统不稳定。
Scope
本文章适用于所有 RAC 实施过程。
Details
1. 在您的环境中应用最新的 Patchset Update (PSU)
适用平台:所有平台
原因: 10.2.0.4 及更高版本中引入了Patchset Updates (也称为 PSU),主要是为了改进 CPU 修补策略。PSU 按季度推出,其中包括最新的 CPU,另外它们也包含其它对保持您的环境稳定性非常重要的修正。如果要进行全新安装,应始终应用最新的 PSU 作为您的基线。对于现有安装,一个必须实施的策略就是定期和持续的应用最新的PSU 。许多提交给 Oracle Support 并被确认为属于 bug 的问题都是已知 bug,其中许多 bug 已在最新的 PSU 得到修正。请注意,在 Windows 上,会更经常推出累积型的补丁包,但是在季度 PSU 版本期间发行的 Windows bundle patch 中包含了最新的 PSU 修正程序。
更多信息:有关 PSU 的更多信息,请参阅以下文档:
Document 854428.1 Intro to Patch Set Updates (PSU)
Document 1082394.1 11.2.0.X Grid Infrastructure PSU Known Issues
Document 756671.1 Oracle Recommended Patches -- Oracle Database
Document 161549.1 Oracle Database, Networking and Grid Agent Patches forMicrosoft Platforms
2. 确保 UDP 缓冲区大小合适
适用平台:Windows 除外的所有平台
原因: 私网可以说是 RAC 数据库的命脉。但是,如果未向 UDP 分配合适的缓冲空间用以发送和接收缓冲,则私网的性能将大幅降低。这将会导致您的集群出现稳定性问题。
更多信息:有关正确调整 UDP 缓冲区的更多信息,请参考以下文档:
Document 181489.1 Tuning Inter-Instance Performance in RAC and OPS
Document 563566.1 gc lost blocks diagnostics
注意: Windows 集群对 Cache fusion 通信使用 TCP,因此,UDP 缓冲区设置不适用于 Windows。
3. 在所有版本 10.2 和 11.1 集群上将 DIAGWAIT 的值设置为 13
适用平台:Windows 除外的所有平台
原因: 在 10gR2 (10.2.x) 和11gR1 (11.1.x) 中,OPROCD 守护进程的默认容差仅设置为 500 毫秒(0.5 秒)。对于非常繁忙的系统,此容差可能过小,因此负载繁重的系统可能会出现错误重启的情况。将 diagwait 设置更改为 13 后,OPROCD 的容差变成 10,000 毫秒(10 秒),为繁忙的系统提供了更长容差,可避免出现错误重启的情况。另外,如果出现节点重启的情况,设置diagwait 能够提供更多的时间将诊断信息刷新到跟踪文件中,以供进一步诊断使用。此更改不能包含在补丁集中,因为必须关闭整个集群才能实施。但是,我们仍然强烈建议在所有 10gR2 和 11gR1 群集上将此值更改为 13。对于新实施的集群,应在安装后立即进行此更改。对于现有的安装,应当安排停机时间,以尽快进行此项更改。可通过以下命令确认当前设置:
#$CLUSTERWARE_HOME\bin\crsctl get css diagwait
注意:此设置不适用于 Windows 环境,也不适用于 11gR2 版本(11.2.0.1 和更高版本)。
更多信息:有关 DIAGWAIT 的更多信息,请参考以下文档中的内容:
Document 559365.1 Using Diagwait as a diagnostic to get more information fordiagnosing Oracle Clusterware Node evictions
Document 567730.1 Changes in Oracle Clusterware on Linux with the 10.2.0.4Patchset
4. 在 Linux 环境中实施 HugePage
适用平台: 所有 LINUX 64 位平台
原因: 在 Linux 环境中实施 HugePage 能够极大地提高内核性能。对于内存较大的系统,效果尤其明显。一般而言,所有 RAM 大于 12GB 的系统都适合使用 Hugepage。系统中的 RAM 越大,系统启用 Hugepage 后获得的好处也越大。这是因为内核为映射和维护内存页表所要做的工作量会随着系统内存的增大而增加。启用 Hugepage 能够显著地降低内核要管理的页面数,而且能提高系统的效率。经验表明,如果未启用 Hugepage,内核挤占关键的 Oracle Clusterware 或 Real Application Clusters 守护进程的情况会很常见,而这会导致实例或节点驱逐出现。
注意:在 Linux 平台上,11g Automatic Memory Management (AMM) 与HugePage 不兼容。最佳实践是禁用 AMM,以支持HugePage。有关 Linux 上的 AMM 和 HugePage 的更多信息,请参阅Document 749851.1
更多信息:Document 361323.1 HugePages on Linux: What It Is... and What It Is Not...
Document 401749.1 Shell Script to Calculate Values Recommended LinuxHugePages HugeTLB Configuration
5. 实施 OS Watcher 和(或) Cluster Health Monitor
适用平台: 所有平台
原因: 虽然 OS Watcher 和Cluster Health Monitor 与稳定性并不直接相关,但是,对于确定 OS 状态和分析导致节点或实例驱逐的许多问题的潜在根本原因方面,它们却是非常好用的工具。如果在第一次发生某个问题后就有合适的数据可用于诊断这个问题,则可缩短确定根本原因的时间,而且能防止以后出现停机。大部分类似的第三方数据收集工具的收集间隔时间都比较长(如 5 分钟或更长),而且(或者)它们很难被解释,或收集到的数据不正确。OSWatcher 是一款非常简单的小型工具,每 30 秒钟(默认)收集一次 OS 的基本信息。Cluster Health Monitor 虽然不适用于所有平台,但它能够更精细地实时收集数据,可以补充 OS Watcher 的不足之处。应当在所有集群节点上全天候运行这两个实用程序或其中一个,有助于更快地诊断和调试问题。
更多信息:
Document 301137.1 OS Watcher User Guide
Document 1328466.1 Cluster Health Monitor (CHM) FAQ
Document 580513.1 How To Start OSWatcher Black Box Every System Boot(Linux specific)
6. 按照最佳实践配置 OS 设置
(请参阅 Oracle IBM 针对系统稳定性进行内存优化而联合编写的白皮书)
适用平台: 所有 AIX 版本
原因: Oracle Real Application Clusters on IBM AIX Bestpractices in memory tuning and configuring for system stability(Oracle Real Application Clusters on IBM AIX 针对系统稳定性进行内存优化和配置的最佳实践)白皮书是这两大供应商根据共同的经验进行联合测试与合并最佳实践后的精华。经验表明,如果遵照本白皮书的建议,可以解决 RAC/AIX 集群中的大多数稳定性问题。AIX 版本 6.1 已将其中的多数建议作为默认值包含在内,但仍应在所有 AIX RAC 群集上确认这些设置,不论哪个 OS 或 Oracle 版本。
更多信息:
白皮书下载地址: http://www.oracle.com/technetwork/database/clusterware/overview/rac-aix-system-stability-131022.pdfDocument 811293.1 RAC Assurance Support Team: RAC Starter Kit and BestPractices (AIX)
7. 确保在 AIX 平台上应用合适的 APARS 以避免出现过量分页/交换问题
适用平台: 所有 AIX 版本
原因: 经验表明,这是很常见的会影响 AIX 环境的问题。鉴于此问题的性质,任何易受此问题影响的用户应该都有过系统完全挂起的经历。在非 RAC 环境中,此问题会导致系统挂起,直到进行手动干预为止。而在 RAC 环境中,此问题会由于节点无法响应导致出现节点驱逐的情况。
更多信息: 有关此问题的更多信息,请参考 Document 1088076.1 Paging Space Growth May Occur Unexpectedly on AIXSystems With 64K (medium) Pages Enabled
注意: 该文章中列出的 APAR 版本和编号特定于给定的Technology Level (TL)。您需要应用的实际 APAR 或修正程序编号将取决于您使用的 AIX (Technology Level,TL)。请与 IBM 联系,确认是否已进行此项修正,如果尚未进行,确认需要哪种 TL 或 APAR 才能进行此项特定的修正。
8. 应用 NUMA 补丁
适用平台: 所有平台
原因: 从 10.2.0.4 和11.1.0.7 RDBMS 补丁集开始,可在支持 NUMA 的平台(取决于 OS 和硬件)上进行 NUMA 优化。在(支持 NUMA 的系统中的)RDBMS 代码中应用 NUMA 会触发一些导致数据库性能降低和不稳定的 bug。与 10.2.0.4 和 11.1.0.7 中的 NUMA 优化相关的症状/问题相关的完整列表,请见 Document 759565.1。如果要运行 10.2.0.4 或 11.1.0.7 补丁集,Oracle 强烈建议将 Patch 8199533应用于系统,以预先解决这些 NUMA 相关的问题。
9. 增加 Windows 非交互式 Desktop Heap
适用平台:Windows 平台
原因: 现已发现,Windows 集群上的非交互式 Desktop Heap 的默认大小不够。这会导致出现应用程序连接问题和集群总体不稳定(挂起和/或崩溃)的问题。要有效地解决此问题,建议将非交互式 Desktop Heap增加到 1MB。如果没有 Microsoft 参与,不应超过建议的 1MB。
更多信息: 关于如何对非交互式 Desktop Heap进行上述调整的说明,请见 Document 744125.1.
10. 运行 RACcheck 实用程序
适用平台: Linux(x86 和 x86_64)、Solaris SPARC 和 AIX(使用 bash shell)
原因: RACcheck 是一款 RAC 配置审核工具,主要用于审核 Real Application Clusters (RAC)、OracleClusterware (CRS)、Automatic Storage Management (ASM) 和 Grid Infrastructure (GI) 环境中各个重要的配置设置。此实用程序用于验证由 RAC Assurance 开发和支持团队维护的 RAC 和 Oracle Clusterware 最佳实践和初学者指南文章(请参阅Document 810394.1)系列定义的最佳实践和成功因素。我们强烈建议在 RACcheck 支持的平台上运行 RAC 的客户使用此工具识别会影响集群稳定性的潜在配置问题。
更多信息: 有关 RACcheck 的更多信息和下载此实用程序的链接请参见 Document 1268927.1.
11. 使用 slewing 选项实施 NTP
适用平台: 所有 Linux 和 Unix 平台。
原因: 如果没有 slewing 选项,在时间差异超过特定(取决于平台)阈值时,NTP 将向前或向后调整系统时钟。大幅度向后调整时间会导致 Clusterware 以为错过了签到,从而发生节点驱逐的情况。出于此原因,我们强烈建议将 NTP 配置调整为 slewing time (加快或减慢)时钟时间以同步时间,以防止此类驱逐情况的发生。有关如何在您的平台上实施 NTP 时间调整的更多信息,请参考平台特定的 RAC 与 Oracle Clusterware 最佳实践和初学者指南文档(见下文)。
更多信息:
Document 811306.1 RAC and Oracle Clusterware Best Practices and StarterKit (Linux)
Document 811280.1 RAC and Oracle Clusterware Best Practices and StarterKit (Solaris)
Document 811271.1 RAC and Oracle Clusterware Best Practices and StarterKit (Windows)
Document 811293.1 RAC and Oracle Clusterware Best Practices and StarterKit (AIX)
Document 811303.1 RAC and Oracle Clusterware Best Practices and StarterKit (HP-UX)
3.3 RAC 日常运维管理的内容
参看ORACLE RAC 管理员手册
3.4. RACcheck 工具的使用
Oracle RACcheck 设计为一款 RAC 配置审核工
您是否听说过 HA_CHECK - 高可用性检查? | |||||
您是否知道 Oracle RACcheck 实用程序现在也包括高可用性检查了?请继续阅读以了解这将如何帮助您在问题发生之前避免潜在问题。 Oracle 最初将 Oracle RACcheck 设计为一款 RAC 配置审核工具,用于审查 Real Application Clusters (RAC) 环境中的重要配置设置。随着时间的推移,Oracle RACcheck 进行了增强,如今已涵盖了更多的环境,例如单实例(非 RAC)数据库和 Exadata。该工具的最近增强是针对主数据库和备用数据库的高可用性 (HA) 检查并且包括 Data Guard、corruption、flashback 和 RMAN 等诸多方面:
这些是 RACcheck 工具中的第一个高可用性检查集,并且在将来会添加更多。 如果您有
请在 My Oracle Support Community 中有关高可用性检查的讨论(英文)中与我们交流。 让我们看一下,如何使用 RACcheck 执行高可用性检查以及如何分析和解释所生成的输出报告。 在要求执行高可用性检查的情况下启动 RACcheck
RACcheck 将检测服务器上的所有实例并允许选择是针对所有数据库还是仅针对特定数据库运行检查。数据库列表将包括在服务器上运行的任何备用数据库。 一旦检查完成,RACcheck 将创建一个html格式的报告和包括所有这些 html 文件的一个 zip 文件。在调查问题时,可以通过 My Oracle Support 将该 zip 文件上载到服务请求。有关生成的 RACCheck 报告文件的示例,请参考下面的屏幕截图: 分析报告 可以通过 “VIEW” 链接获得有关每个项的详细信息。
有用参考
另外,请加入 Database Community来与 Oracle 专家和遍布全球的用户讨论有关高可用性检查的主题或任何其他高可用性主题。 |
3.5. RAC 补丁管理方面建议
安装注意事项
建议在安装 Oracle RAC 软件时使用本地文件系统,以允许使用滚动补丁升级,并避免出现单一故障点和其他故障。其它有关信息,请参见 Oracle Real Application Clusters Environment白皮书。请注意,不支持将 11gR2 Grid Infrastructure 安装到集群文件系统上,请参见 Oracle Grid Infrastructure Installation Guide 11g Release 2 (11.2) for Linux的 2.5.4 部分。
使用 cluvfy(集群验证实用程序)检查集群先决条件。在安装 Oracle 软件前,以及安装期间的所有阶段使用 cluvfy。安装 11gR2 之前的版本时,务必下载最新版本的 cluvfy OTN。 Document 339939.1和 Document 316817.1中包含了有关本主题的更多相关信息。
在执行 11gR2 之前的安装时,建议在执行任何 RDBMS 或 ASM 主目录安装前应用补丁程序将 Clusterware 主目录升级到所需的级别。例如,在安装 10.2.0.1 RDBMS 前,先安装 Clusterware 10.2.0.1 并使用补丁程序升级到 10.2.0.4。
在 11gR2 之前的环境中,出于维护和可用性的考虑(如独立补丁程序和升级),将 ASM安装到单独的ORACLE_HOME 。为轻松升级到 11gR2,ASM 软件所有者应与 Clusterware 软件所有者相同。
从 11gR2 开始,所有补丁程序集都是可完全安装的版本。例如,要安装 11.2.0.2(11gR2 Patchset 1),可直接安装 11.2.0.2,无需先安装 11.2.0.1 再应用补丁程序升级到 11.2.0.2。对于 11gR2 Grid Infrastructure,所有补丁程序集升级都是 out-of-place 的。对于 11gR2 RDBMS,您可以执行 out-of-place 或 in-place升级,但建议使用 out-of-place 升级方法。更多信息,请参考 Document 1189783.1.
如果安装 Oracle Clusterware的用户属于多个操作系统用户组,安装程序将在集群的所有节点上安装Oracle Clusterware,并将软件的组所有权设置为安装用户的当前活动组或主要组所有。因此,确保文件 etc/group 中列出的第一个组是当前活动组,或使用以下命令行选项调用 Oracle Clusterware 安装,以强制安装程序在对所有文件设置组所有权时使用正确的组:runInstaller s_usergroup=current_active_group (Bug 4433140)
补丁安装注意事项
本部分旨在为新实施和现有实施制定积极的修补策略。对于新实施,强烈建议您在开始测试时,对您的平台应用最新的可用 Patchset 和适用的 Patch Set Update (PSU)。如果由于内部延迟或第三方应用认证或由于其他限制导致无法使用最新版本的 RDBMS,则仍建议 CRS 主目录和ASM(或 Grid Infrastructure)主目录的patch级别比 RDBMS 主目录高。作为最佳实践(有一些例外,请参见下面参考部分中的文档),Oracle Support 建议遵循以下说明:
Clusterware(或 Grid Infrastructure)的补丁程序级别或版本必须高于或等同于 RDBMS 主目录的补丁程序级别或版本(比较到版本号的第四位)。对于 11.2 之前的版本,Clusterware 的补丁程序级别或版本必须高于或等同于 ASM 和 RDBMS 主目录的补丁程序级别或版本(比较到版本号的第四位)。
在应用补丁前,使用 opatch 检查ASM 或 Clusterware 主目录文件系统上的可用空间,并使用 Document 550522.1估计需要多少空间,以及如果应用补丁期间出现文件系统被填满的情况时该如何处理。
Document 557934.1提供了在 11gR2 之前的版本中给 Oracle Clusterware 应用补丁的基本概述,并介绍了 Oracle Clusterware 的组件是如何通过应用补丁获得更新的。
如果要通过补丁程序将 Grid Infrastructure 从 11.2.0.1 升级到 11.2.0.2,请务必参考 Document 1312225.1 - "Things to Consider Before Upgrading to Grid Infrastructure 11.2.0.2" be reviewed。本文档介绍了所有必须遵守的先决条件和过程,以确保成功升级到 11.2.0.2。
制定积极的修补策略,对最新的已知问题防患于未然。应用最新的Patch Set Update(请参见 Document 850471.1中的介绍),并了解最新的推荐补丁(请参见 Document 756671.1中的介绍)。制定定期(如按季度)维护窗口的计划,以应用最新推荐的 PSU 和补丁程序。
3.6. RAC 常见问题解答
最常见的 5 个导致节点重新启动、驱逐或 CRS 意外重启的问题 [ID 1524455.1]
In this Document
Purpose |
Scope |
Details |
问题 1:节点重新启动,但是日志文件未显示任何错误或原因。 |
问题 2:节点重新启动,该节点是由于丢失网络心跳而被逐出。 |
问题 3:在出现存储问题后节点重新启动。 |
问题 4:asm 或数据库实例被挂起或驱逐后节点重新启动。 |
问题 5:CRS 自动重启,但是节点没有重新启动 |
References |
Applies to:
Oracle Database -Enterprise Edition - Version 10.1.0.2 to 11.2.0.3 [Release 10.1 to 11.2]
Information in this document applies to any platform.
Purpose
本文章简要概述了导致节点重新启动或者 CRS 意外重启的几个最常见问题
Scope
有节点重新启动问题的所有用户
Details
问题 1:节点重新启动,但是日志文件未显示任何错误或原因。
原因: 如果节点重新启动是由于某个 Oracle 进程,但是日志文件没有显示任何错误,则故障位置为 oprocd、cssdmonitor 和 cssdagent 进程。当节点挂起一段时间或者一个或多个关键 CRS 进程无法被调度获得 CPU 时,会发生这种情况。因为那些进程都以实时优先级运行,所以问题可能是因为内存耗尽或者可用内存低,而不是因为 CPU 耗尽。也可能是由于内核交换页的工作量繁重或者正忙于扫描内存以标识要释放的页。也可能存在 OS 调度问题。
解决方案:
1) 如果 CRS 版本为 11.1 或者更低,请将 diagwait 设置为 13。
2) 如果平台为 AIX,请参照文章 811293.1(RAC and OracleClusterware Best Practices and Starter Kit (AIX))中所建议的方法优化 AIXVM 参数。
3) 如果平台为Linux,请设置Hugepage 并将内核参数vm.min_free_kbytes 设置为保留“512MB”,将swappiness 设置为100。请注意,使用 Hugepage 时无法设置 memory_target。
4) 检查是否有大量内存分配给了操作系统的 IO 缓冲区高速缓存。与 OS 供应商联系,建议一些方法来减少 IO 缓冲区高速缓存量,或者增加从 IO 缓冲区高速缓存回收内存的比率。
5) 增加内存量。
问题 2:节点重新启动,该节点是由于丢失网络心跳而被逐出。
这是因为丢失网络心跳或 发生了脑裂。在双节点环境中,节点 2 的重复重新启动通常意味着节点 2 由于 脑裂 而被驱逐。在节点重新启动前,ocssd.log 会显示丢失网络心跳或一条脑裂消息。
原因:节点之间通过私网互连的网络通信失败。故障可能是单向或者双向的。
解决方案:修复网络问题。确保交换机和 NIC 卡等所有网络组件都正常运行。确保 ssh 能通过私网互连工作。请注意,网络通常在节点重新启动后可以恢复正常。
注意: 如果您使用了巨帧(Jumbo Frame),请参考文章341788.1 (Recommendation for the RealApplication Cluster Interconnect and Jumbo Frames)。如果交换机的巨帧设置与集群私网NIC卡的MTU(巨帧)设置不同,会出现网络问题,并导致节点驱逐或CRS无法启动。有时,如果您使用的交换机和NIC卡来自不同的厂商,它们对巨帧的支持也可能不同。
问题 3:在出现存储问题后节点重新启动。
ocssd.log 文件显示节点因为无法访问大部分 voting disks 而重新启动。
原因:CRS 必须能够访问大部分 voting disks 。如果 CRS 无法正常访问大部分 voting disks ,则 CRS 无法确保群集的一致性,所以 CRS 重新启动节点。
解决方案:修复 voting disks 的问题。确保用户 oracle 或 grid,或者CRS 或 GI HOME 的拥有者可以使用和访问voting disks 。如果 voting disks 未在 ASM 中,请使用 "dd if= of=/dev/null bs=1024count=10240" 测试可访问性。
问题 4:asm 或数据库实例被挂起或驱逐后节点重新启动。
正常运行节点的 ocssd.log 显示一个 member kill 请求升级到了 node kill 请求。
原因:从版本 11.1 开始,如果无法在数据库级别驱逐数据库或 asm 实例,则意味 CRS 将介入来尝试终止问题实例,这被称之为 member kill 请求。如果 CRS 无法终止该问题实例,则 CRS 会重新启动节点,因为 meber kill 请求被升级到了 node kill 请求。
解决方案:查找无法在数据库级别驱逐 asm 或数据库实例(lmon、lmd 和 lms 发起的驱逐)的原因。一个常见原因是实例正处于挂起状态,对远程实例的终止请求无法响应。另一个原因是无法终止多个实例进程中的某个进程。如进程处于不可中断的 IO 闲置状态就属于这样一个例子。
问题 5:CRS 自动重启,但是节点没有重新启动
原因:从版本 11.2.0.2 开始,如果 CRS 由于此处列出的任何原因而需要重新启动节点,CRS 会在重新启动节点之前尝试先对自身进行重启。仅当它无法成功重启自身时,CRS 才重新启动节点来强制对自身进行重启。
解决方案:检查此处列出的哪个节点重新启动原因适用,并按照针对该原因列出的解决方案进行操作。
References
NOTE:341788.1 - Recommendation for the Real Application ClusterInterconnect and Jumbo Frames
NOTE:1050693.1 - Troubleshooting 11.2 Clusterware Node Evictions(Reboots)
NOTE:265769.1 - Troubleshooting 10g and 11.1 Clusterware Reboots
NOTE:452326.1 - Linux Kernel Lowmem Pressure Issues and KernelStructures
NOTE:811293.1 - RAC and Oracle Clusterware Best Practices and StarterKit (AIX)
3.7. RAC 升级方面建议
升级注意事项
本部分实际上分为 2 个子部分。第一部分介绍 Clusterware、ASM 和Grid Infrastructure 升级,第二部分介绍 RDBMS 升级。
Clusterware、ASM 和 Grid Infrastructure 升级注意事项
从 Oracle Clusterware 和 Oracle ASM 到 Grid Infrastructure 的升级应始终是 out-of-place 的。在 11g release 2 (11.2) 中,无法以 in-place 的方式将 Oracle Clusterware 和 Oracle ASM 升级。
如果现有 Oracle Clusterware 主目录是共享主目录,请注意,您可以对 Oracle Grid Infrastructure 使用非共享主目录。
在开始升级 Grid Infrastructure 或升级到 Grid Infrastructure 前,务必参考以下文档(取决于目标版本):
Document 1312225.1 - Things to Consider Before Upgrading to Grid Infrastructure 11.2.0.2
Document 1363369.1 - Things to Consider Before Upgrading to 11.2.0.3 Grid Infrastructure/ASM
下面列出了上述文档的一些要点(详细信息请参考文档):
验证现有 Clusterware 和 ASM(或 Grid Infrastructure)配置是否正常
确保将所有必须的补丁程序应用于升级前的 Clusterware/ASM/Grid Infrastructure 主目录,例如:
如果要从 GI 11.2.0.1 升级到 11.2.0.2,在尝试升级前,必须将 Patch 9706490应用于 GI 11.2.0.1 主目录。
如要升级到 11.2.0.2,请验证集群私网上的多播功能。
在执行 rootupgrade.sh(或 root.sh)前,将 11.2.0.2 升级到最新的 GI PSU,详细说明请参考 Document 1312225.1。
如要升级到 11.2.0.3,请使用 RACcheck 的升级准备情况评估功能帮助执行升级前要求计划和升级后验证。有关其他详细信息,请参考 Document 1457357.1 RACcheck 11.2.0.3 Upgrade Readiness Assessment for additional details。
要将 10gR2 Clusterware 升级到 11g,根据 Oracle Upgrade Guide 11gR1 http://download.oracle.com/docs/cd/B28359_01/server.111/b28300/upgrade.htm#BABCEGBC所述,最低必须从版本 10.2.0.3 开始,11gR2 GI 平台特定的文档中也介绍了类似的内容。该文档介绍了以下内容:
注意: Oracle 新添加了先决条件检查操作,以确保 Oracle Clusterware 10.2.0.x 版本为 10.2.0.3(或更高版)后,才能尝试将其升级到 Oracle Clusterware 11g release 1 (11.1)。如果此检查失败,系统将指导您将 Oracle Clusterware 补丁程序集 10.2.0.3.0 或更高版应用于现有版本,然后才能进行升级。所有其他升级路径和新的安装不会受这些先决条件检查操作的影响。
如果可能,可以对 Oracle Clusterware (CRS) 使用滚动升级,请参考 Document 338706.1。如需详细的升级帮助,请参考与您的版本对应的“升级指南”: Document 466181.1 10g Upgrade Companion 和 Document 601807.1 Oracle 11gR1 Upgrade Companion。 对于 11gR2,Clusterware 自身的升级是滚动升级(所有节点上的旧版本的程序必须处于运行状态);对于 ASM 11.1 和更高版本,ASM 升级也是滚动升级。ASM 11.1 之前的版本不是滚动升级。
如果计划在 11gR2 Grid Infrastrucutre 环境中运行 11gR2 之前的数据库,请查看 Document 948456.1 : Pre 11.2 Database Issues in 11gR2 Grid Infrastructure Environment。
对于 11.2.0.2 之前的数据库,11.2.0.2 HAIP 功能将不提供 NIC 冗余或负载均衡,如果计划在 11.2.0.2 Grid Infrastructure 上运行 11.2.0.2 之前的数据库,必须使用第三方 NIC 冗余解决方案,与 11.2.0.2 之前版本中的操作相同。
RDBMS 升级注意事项
请您务必查看与您的目标版本对应的“升级指南”:
Oracle 11gR2 Upgrade Companion Document 785351.1
Oracle 11gR1 Upgrade Companion Document 601807.1
查看与您的目标版本对应的“数据库升级指南”:
Oracle Database Upgrade Guide 11g Release 2 (11.2)Oracle Database Upgrade Guide 11g Release 1 (11.1)
升级到 11gR2 时,务必查看 Best Practices for Upgrading to Oracle Database 11g Release 2(升级到 Oracle Database 11g Release 2 的最佳实践)。
如要升级到 11.2.0.3,请使用 RACcheck 的升级准备情况评估功能帮助执行升级前要求计划和升级后验证。有关其他详细信息,请参见 Document 1457357.1 RACcheck 11.2.0.3 Upgrade Readiness Assessment for additional details.
如果在决定使用哪种方法将数据库升级到 11gR2 时需要帮助,请查看 Upgrade Methods for Upgrading to Oracle Database 11g Release 2(升级到 Oracle Database 11g Release 2 的升级方法)白皮书。
在将 Oracle Database 10g 升级到 11g 时,请查看:
http://www.oracle.com/technetwork/database/bi-datawarehousing/twp-sql-plan-management-11gr2-133099.pdf
对于希望在升级数据库时将停机时间缩到最短的用户,可以考虑使用 logical standby 做过渡,请参考 Document 949322.1 : Oracle11gData Guard: Database Rolling Upgrade Shell Script

