




原文出处:4 Essential SQL Window Functions and Examples for a Data Scientist Interview in 2021
作者:Leon
译者:ACDU翻译组(@姚雷)
校对:ACDU翻译组(@帽子菌 @Finn)
介绍
在数据科学家岗位的面试中,窗口函数(WINDOW function) 是SQL函数家族中经常会被问到的主题。用窗口函数写一个正确的SQL查询对每个候选人来讲都很有挑战性,尤其是对那些SQL的初学者。
在本文中,我会根据面试的问题,问题模式和解决问题的基本策略向你展示一些典型的窗口函数,并提供一些示例的分步解决方案。
关于作者:Leon是硅谷FAANG(Facebook, Apple, Amazon, Netflix, 谷歌)公司的一位数据科学和机器学习领域的主管。在担任现在的职务之前,他在EdTech公司Chegg负责机器学习组织,并在amazon.com担任研究科学家,负责构建大规模机器学习系统。
大纲
我将把这篇文章分为4个章节:
- 在第一章节,我将通过常规聚合函数介绍一些基本的窗口函数,例如AVG, MIN/MAX, COUNT, SUM,来使你初步了解一些概念。
- 在第二章节,我将专注于排序相关的函数,例如ROW_NUMBER, RANK和RANK_DENSE。这些函数在分组生成排序方面极为有用,在进行数据科学家面试之前,你应该熟练使用它们。
- 在第三章节,我将讨论如何用NTILE函数生成统计信息(例如:百分位数,四分位数,中位数等),这是数据科学家的常见任务。
- 在最后一个章节,让我们专注于LAG和LEAD,如果你面试的角色需要处理时序数据,这是两个超级重要的的函数。
让我们开始吧!
章节1:基于常规聚合函数(AVG,MIN/MAX,COUNT,SUM)的窗口函数
窗口函数是一系列函数,这些函数在和当前行有关的多行数据上执行运算。
这相当于聚合函数所做的运算,但和常规聚合函数不同的是,窗口函数不会将分组的多行数据合并成一行 – 这些行都保留了自己的标识。
在后台,窗口函数实际上处理的不仅仅是查询结果的当前行。

本文所有的示例都基于 movie DVD rental business data 中的数据。在第一个示例中我们的目的是在相同的MPAA分级下,比较每个电影DVD的替换成本和平均成本。
SELECT title, rating, replacement_cost, AVG(replacement_cost) OVER(PARTITION BY rating) AS avg_cost FROM film;复制
对不在美国的读者解释一下,MPAA分级是一个电影分级系统,可根据电影的内容确定电影是否适合某些观众。比如,G表示适合所有年龄段的观众,同时PG-13表示包含不适合13岁以下儿童观看的内容。
在这里AVG函数没有GROUP BY 子句,但是SQL引擎如何知道哪些行需要计算平均值呢?答案是通过OVER() 工具里的PARTITION BY 子句,我们将根据一个特定的分级来计算平均值。
在最终的输出里,每一行包含相同分级下的平均成本,你可以分析这些数据,比如将替换成本除以平均成本,以对比相同评级下每部电影的相对支出。
本文中所有的表都可以在 SQLPad’s online SQL playground 中找到。如果你想提交本文提到的查询,尽管登录 sqlpad.io/playground 去尝试。
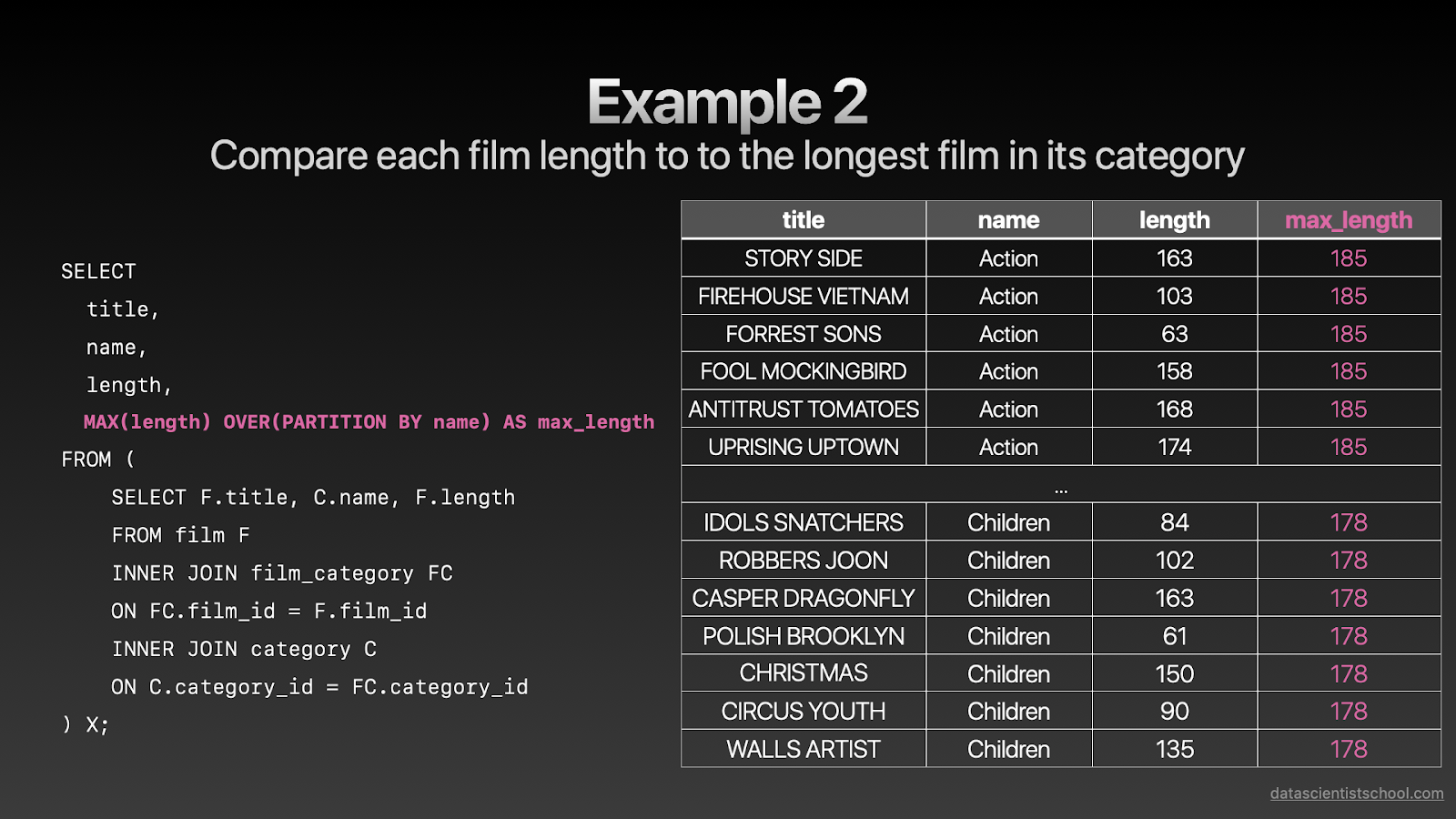
让我们来看另一个例子。在这个例子中,我要把每部电影的时长和同类型电影中最长的时长做对比。
SELECT title, name, length, MAX(length) OVER(PARTITION BY name) AS max_length FROM ( SELECT F.title, C.name, F.length FROM film F INNER JOIN film_category FC ON FC.film_id = F.film_id INNER JOIN category C ON C.category_id = FC.category_id ) X;复制
这和第一个例子很相似,不过我把MAX函数、OVER和PARTITION BY组合起来创建了一个窗口函数,这个窗口函数计算了每个电影类型的最长时长。
在第一行:Story Side(影片名称),时长163分钟,而动作类型电影的最长时长是185分钟。如果我对比每部影片的时长这个最长时长,我就可以了解在同类型影片中,这部电影的一个时长,这是一个非常有用的信息,因为不同类型电影的时长会有很大的不同。
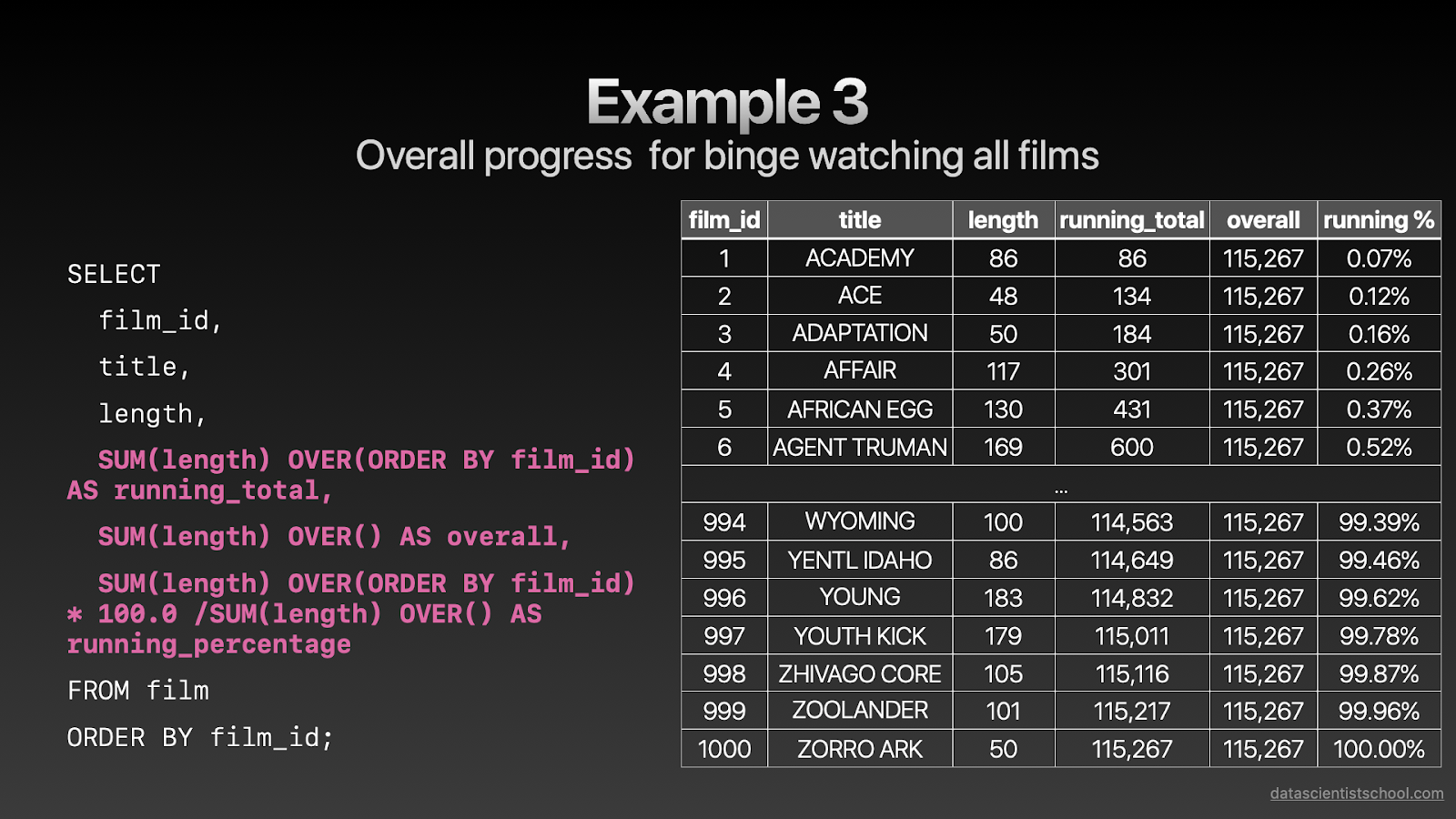
SELECT film_id, title, length, SUM(length) OVER(ORDER BY film_id) AS running_total, SUM(length) OVER() AS overall, SUM(length) OVER(ORDER BY film_id) * 100.0 /SUM(length) OVER() AS running_percentage FROM film ORDER BY film_id;复制
我们再来看这个例子。这个有一点复杂,我们将在窗口函数中计算一个运行中的求和运算。
假设在一个假期档,我想从id=1的电影开始,疯狂地看所有1000部电影。完成每一部电影后,我想知道我的观影进度是什么。我可以用SUM,和OVER去计算进行中的时间总和来得到我的整体进度。
注意这里没有PARTITION BY子句因为我没有把这些影片进行任何分类。我要计算不基于任何分组或分类的总体进度,我很有野心,是不是:)?
另一点需要注意的是如果我在OVER() 函数中不加任何内容,我实际上得到了所有电影类别的时长总和。你可以看到倒数第二个字段:他们有相同的值115267,但是当我加上ORDER BY子句,我得到了直到当前行的分钟数的总和(running_total字段)。
再一次,请随时登录sqlpad.io/playground去操作电影表直到你熟悉这些语法。
如果有兴趣去实践更多的窗口函数,这里有4个练习来加强你的学习效果。完成时间:大约30-45分钟。
- #58:每个电影的利润半分比
- #59:每部电影在同类型电影中的相对利润百分比
- #60:对比每部电影的租金和相同类型电影的平均租金
- #61:单个顾客的花费vs.每个店铺的平均顾客花费
章节2:ROW_NUMBER, RANK, DENSE_RANK
让我们看一下那些最重要的WINDOW函数:ROW_NUMBER和RANK。

SELECT F.film_id, F.title, F.length, ROW_NUMBER() OVER(ORDER BY length DESC) AS row_num FROM film F ORDER BY row_number;复制
这个例子的目的是为所有影片类型创建一个基于电影时长的排序索引。
如你所见,ROW_NUMBER函数为每行生成了一个从1开始的整数序列。
而且你可能注意到了那些时长相同的电影被分配了不同行号(如果出现排名相同的情况,它会在后台随机分配先后顺序),而且每一行有一个唯一编号。

SELECT F.film_id, F.title, F.length, C.name AS category, ROW_NUMBER() OVER(PARTITION BY C.name ORDER BY F.length DESC) row_num FROM film F INNER JOIN film_category FC ON FC.film_id = F.film_id INNER JOIN category C ON C.category_id = FC.category_id ORDER BY C.name, row_number;复制
让我们来看另一个例子,这次不是对比一部影片与所有类型其他影片的时长,而是在PARTITION BY的帮助下,为每一个影片类型排序。
ROW_NUMBER加上OVER和PARTITION BY 是高级SQL中经常使用的一个常规模式。掌握这个模式可以使你的日常数据处理工作轻松很多。
举个例子,想象你在一个电子商务公司工作,并且它一个全球的业务。你的老板让你发给他一份每个国家最好的销售人员的列表。你可以用ROW_NUMBER和PARTITION BY 轻松地生成这个列表。
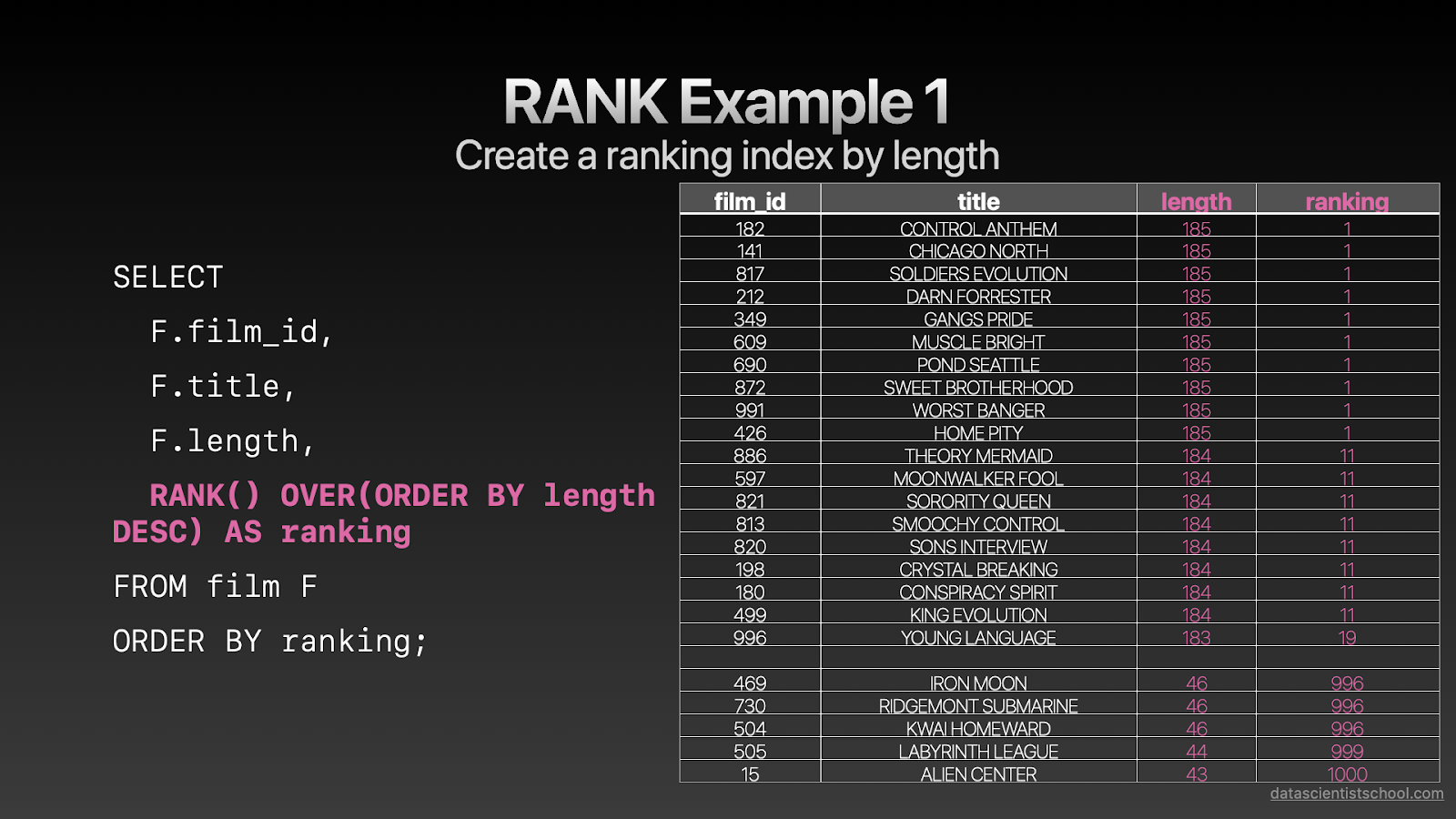
SELECT F.film_id, F.title, F.length, RANK() OVER(ORDER BY length DESC) AS ranking FROM film F ORDER BY ranking;复制
让我们来看RANK函数,这个函数和ROW_NUMBER函数非常相似。不同之处在于RANK为排名相同的情况分配相同的唯一值,并且基于当前行为止的总行数生成下一个值。注意从1跳到11的过程。
如果最后一行没有排名相同的情况,最大的排序号就是总行数(这个里我们有1000部影片)。
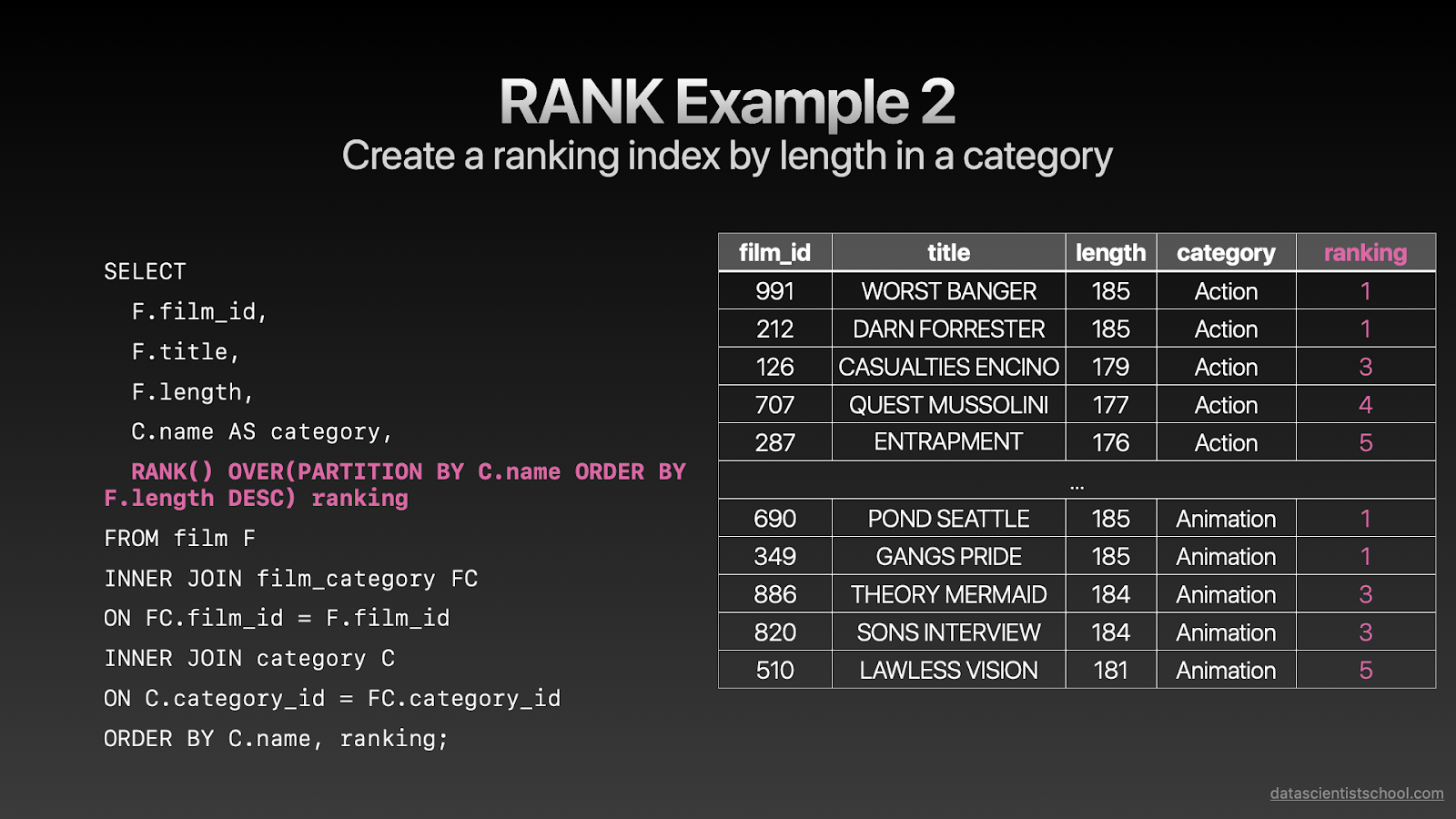
SELECT F.film_id, F.title, F.length, C.name AS category, RANK() OVER(PARTITION BY C.name ORDER BY F.length DESC) ranking FROM film F INNER JOIN film_category FC ON FC.film_id = F.film_id INNER JOIN category C ON C.category_id = FC.category_id ORDER BY C.name, ranking;复制
相似地,我们也可以用PARTITION BY在分组内生成排序。
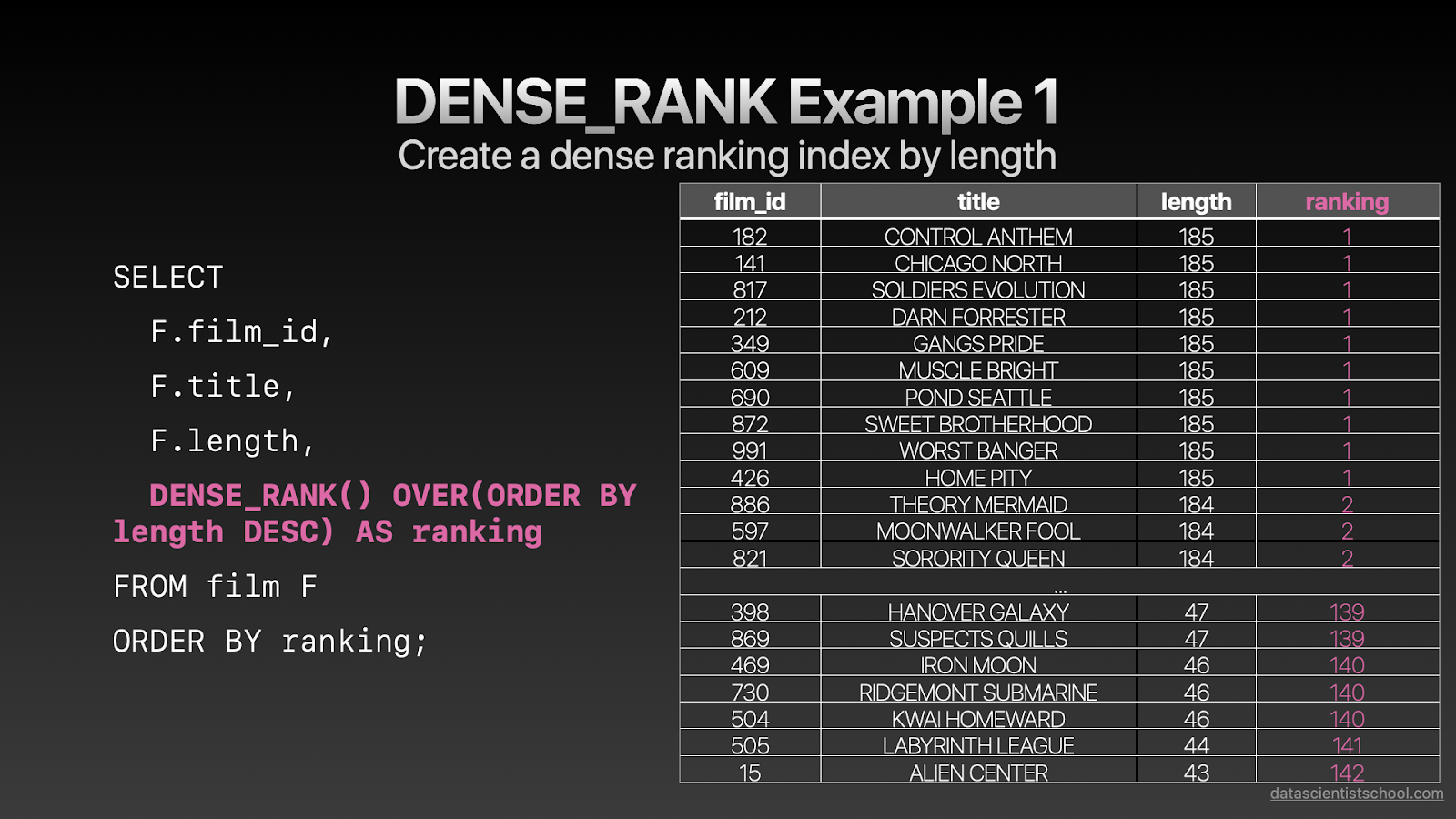
SELECT F.film_id, F.title, F.length, DENSE_RANK() OVER(ORDER BY length DESC) AS ranking FROM film F ORDER BY ranking;复制
我想展示给你的最后一个函数是DENSE_RANK。这个函数和RANK非常相似,只是处理排名相同情况的方式不同。它会使用连续的值生成下一个值,而不是制造一个间隔。
如你所见对于前两行,两个电影都有值1,下一个dense_rank值为2,而不是3。
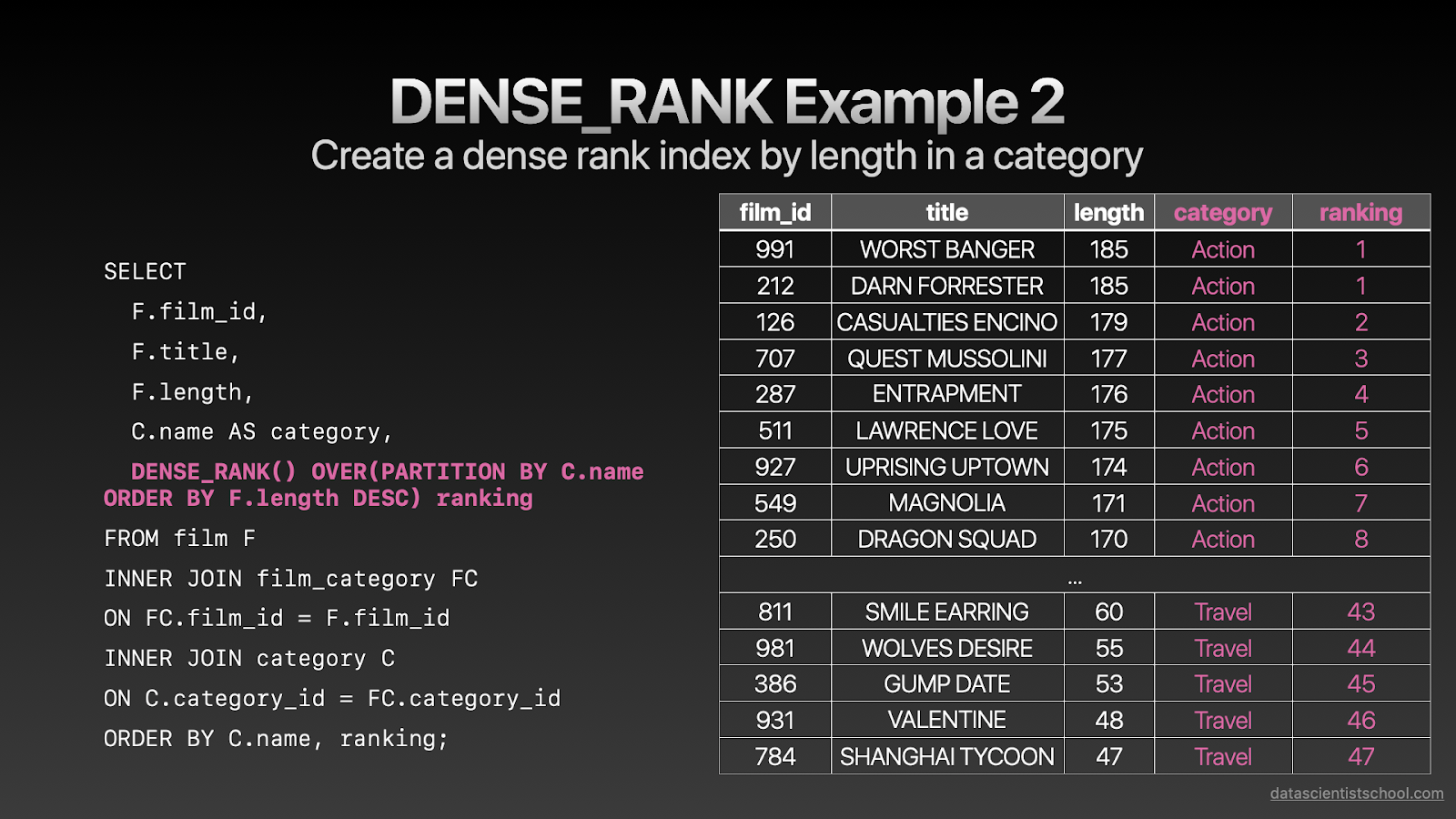
SELECT F.film_id, F.title, F.length, C.name AS category, DENSE_RANK() OVER(PARTITION BY C.name ORDER BY F.length DESC) ranking FROM film F INNER JOIN film_category FC ON FC.film_id = F.film_id INNER JOIN category C ON C.category_id = FC.category_id ORDER BY C.name, ranking;复制
相似地,如果我们组合PARTITION BY和DENSE_RANK,我们能得到一个类型内的连续排名,dense_rank的最大值是一个分区内所有唯一值的总数。
总的来说,ROW_NUMBER,RANK和DENSE_RANK,是生成排名的三个非常有用的函数。作为数据科学家,我经常使用ROW_NUMBER,并且当处理排名相同情况时偶尔使用RANK(很少)。
练习时间到了,我准备了3个练习来帮助理解。完成时间:大约30-45分钟。
- #62:同类型中最短的电影
- #63:同一店铺排名前5的顾客
- #64:同类型中排前两名的电影
章节3:NTILE
在这一节,我将向你展示如何使用NTILE创建统计信息。
NTILE是一个非常有用的函数,尤其对于数据分析专家。例如,作为数据科学家,你可能需要在日常工作中创建可靠的统计数据,例如四分位数,五分位数,中位数等,而NTILE使得生成这些数字非常容易。NTILE接受一个存储桶数的参数,然后根据OVER函数中行的划分和排序方式,尽可能平均地创建此存储桶数。
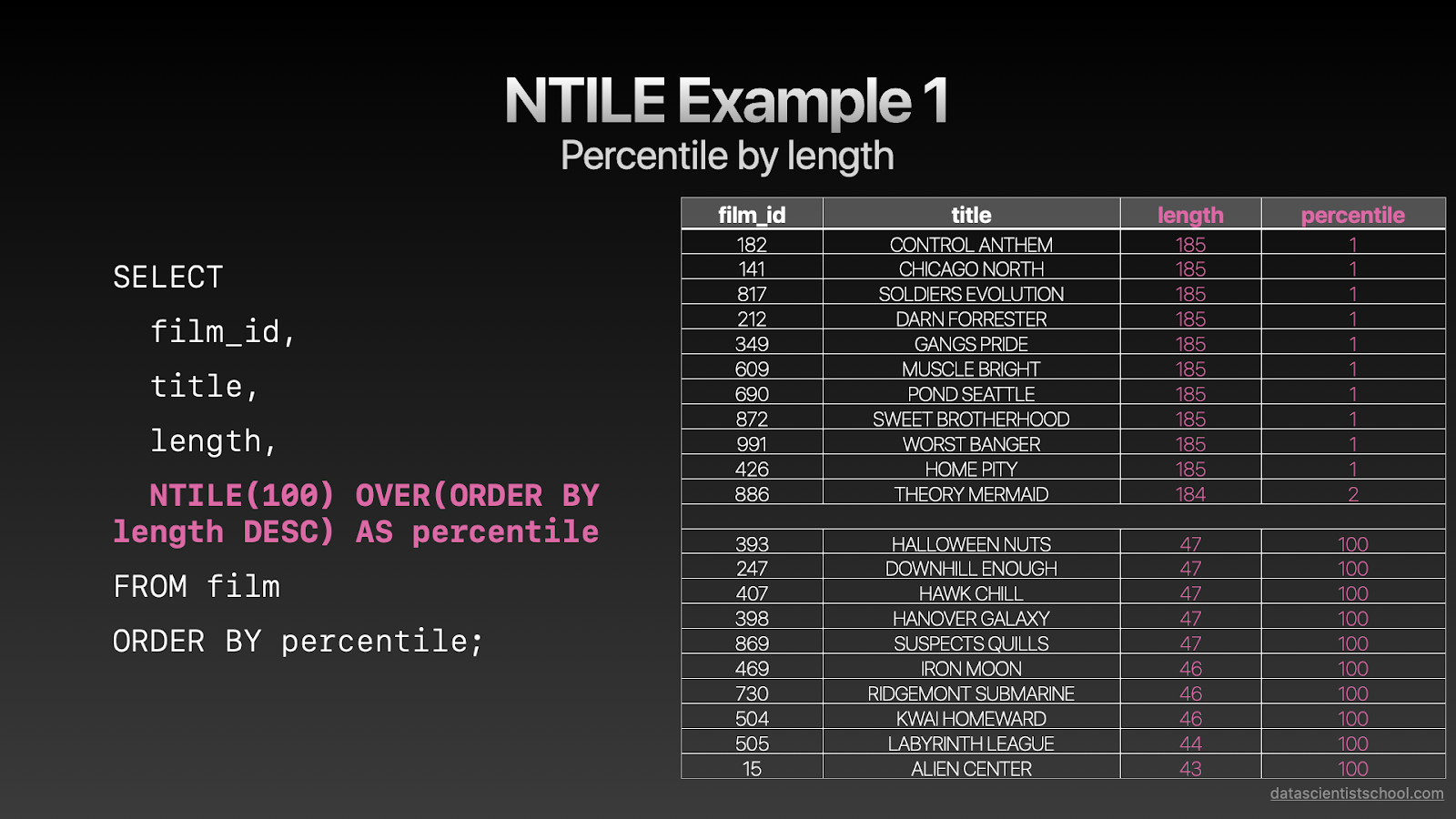
SELECT film_id, title, length, NTILE(100) OVER(ORDER BY length DESC) AS percentile FROM film ORDER BY percentile;复制
让我们看一下示例1,其中我们创建了100个存储桶,并按照其长度递减的顺序排列了所有电影。 因此,最长的桶将分配给存储桶1,最短的桶将分配给存储桶100。
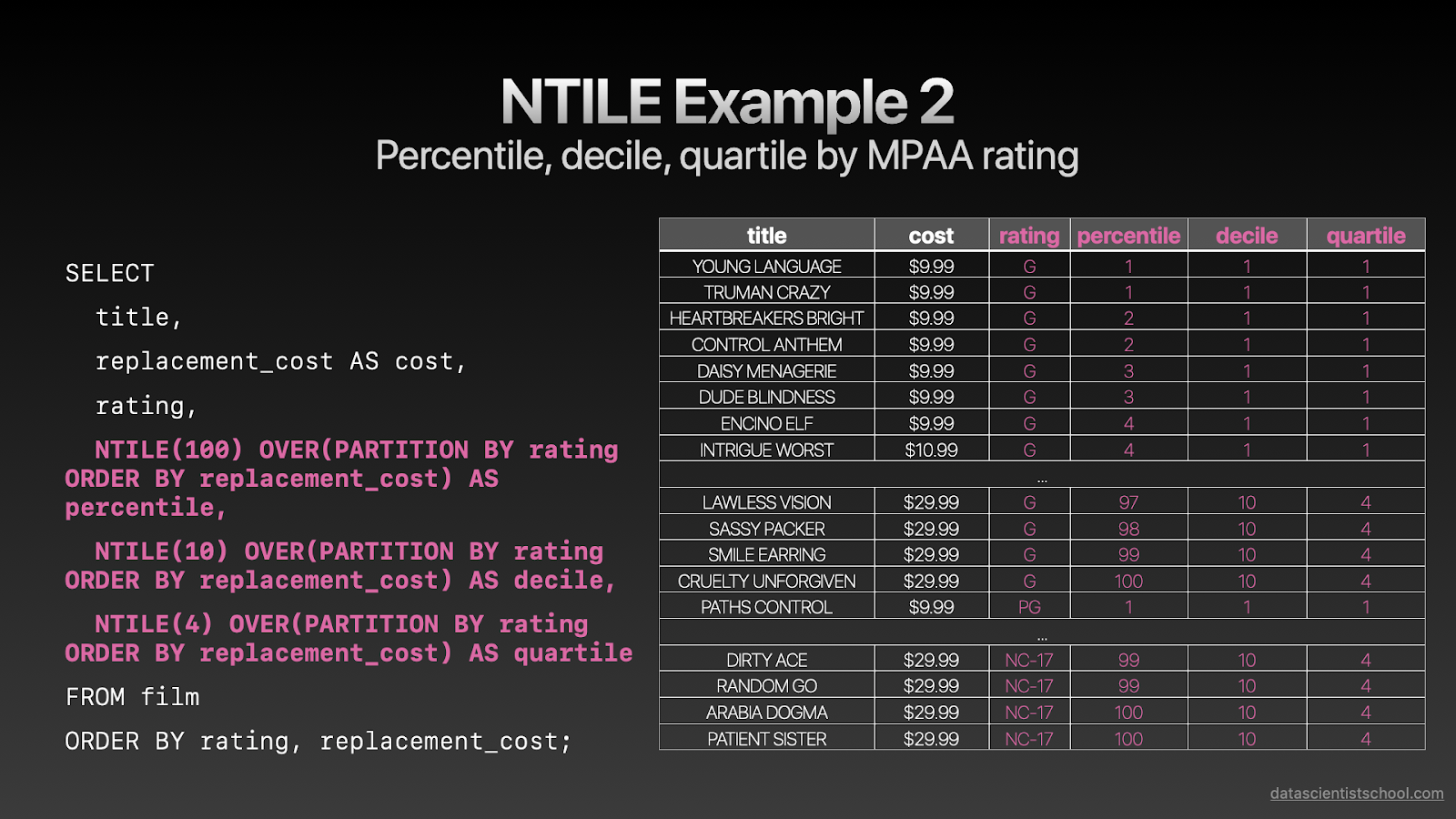
在第二个示例中,我们创建了更多统计信息,例如DECILES(10个存储桶)和QUARTILES(4个存储桶),并且还按MPAA等级对它们进行了划分,因此这些统计信息与每个唯一的MPAA等级相关。
NTILE是非常简单的窗口函数,对于你作为数据科学家的日常工作非常有用。 让我们做一些练习,以帮助你记住其语法,并在本讲座中加强学习。
一些有趣的练习。完成时间:大约30-45分钟:
- #65:电影收入百分比
- #66:按收入分类的电影百分位
- #67:按租金计算的四分位水桶
章节4:LAG,Lead
在最后一节中,我将带领你了解两个窗口函数:LAG和LEAD,它们对于处理与时间相关的数据极为有用。
LAG和LEAD之间的主要区别是LAG从“前几行”获取数据,而LEAD相反,后者从“后几行”获取数据。
例如,我们可以使用这两个函数之一来比较逐月增长。作为数据分析专家,你很有可能处理与时间有关的数据,如果你能够有效地使用LAG或LEAD,那么你将是一位非常有生产力的数据科学家。
它们的语法与其他窗口函数非常相似。让我给你展示几个示例,而不是只关注语法的格式。

WITH daily_revenue AS ( SELECT DATE(payment_ts) date, SUM(amount) revenue FROM payment WHERE DATE(payment_ts) >= '2020–05–24' AND DATE(payment_ts) <= '2020–05–31' GROUP BY DATE(payment_ts) ) SELECT date, revenue, LAG(revenue, 1) OVER (ORDER BY date) prev_day_sales, revenue *1.0/LAG(revenue,1) OVER (ORDER BY date) AS dod FROM daily_revenue ORDER BY date;复制
- 第一步,我们使用CTE(通用表格表达式)创建了每日电影租赁收入。
- 第二步,我们使用LAG函数将前一天的收入附加到当天。
- 请注意,最后两列的第一行为空,这仅仅是因为5月24日的数据是第一行,所以没有前一天。
- 我们还指定了偏移量,即1,因此我们获取下一行。如果将此数字更改为2,我们比较的就是当天和前天的每日租赁收入。
- 最后,我们将当天的收入除以前一天的收入,这样就可以创建我们的每日收入增长率。
WITH daily_revenue AS ( SELECT DATE(payment_ts) date, SUM(amount) revenue FROM payment WHERE DATE(payment_ts) >= '2020–05–24' AND DATE(payment_ts) <= '2020–05–31' GROUP BY DATE(payment_ts) ) SELECT date, revenue, LAG(revenue, 2) OVER (ORDER BY date) prev_day_sales, revenue *1.0/LAG(revenue,2) OVER (ORDER BY date) AS dod FROM daily_revenue ORDER BY date;复制
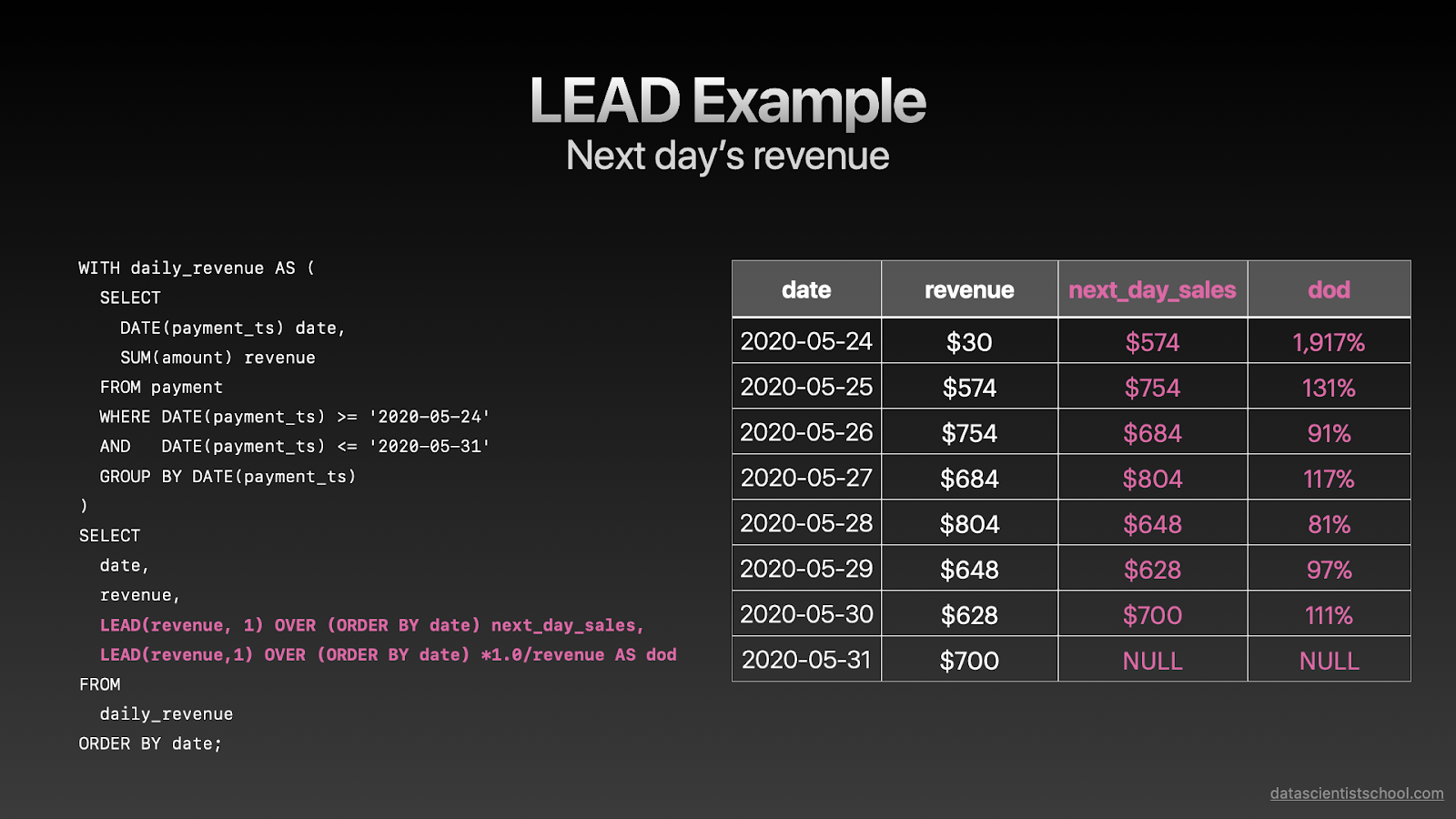
让我们来看另一个例子。 它与前一个非常相似,但是我们没有使用前一天的收入,而是使用LEAD函数(偏移量为1)来获取第二天的电影租赁收入。
然后,我们将第二天的收入除以当日的收入,以获取每日的增长率。
在本节中,你可以尝试以下2个练习,以帮助你熟悉语法。完成时间:大约45分钟-1小时。
- #68:第一笔租金与第二笔租金的差额
- #69:满意客户数量
总结
干的漂亮,如果你仔细阅读了所有示例,你就已经见过了大多数常见的窗口函数/模式。恭喜你!
窗口函数是SQL家族的一个工具,在数据科学家工作面试中经常被问到。编写无错误的窗口函数查询可能非常具有挑战性。真正掌握这些函数需要花费时间和练习,这就是我创建sqlpad.io的原因,在这里你可以练习80个SQL面试问题的列表,请随时尝试。

评论

 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 1 1
0 点赞 1 1