




在关于机器学习的博客系列的第一部分中:
https://www.enterprisedb.com/blog/regression-analysis-postgresql-tensorflow-part-1-getting-started
我们研究了如何设置 PostgreSQL,以便我们可以在使用 pl/python3 过程语言的数据库服务器中使用TensorFlow(https://www.tensorflow.org/ )对我们的数据执行回归分析。我们还研究了 pl/python3 的一些基础知识,以此作为本系列和本系列第三部分内容的入门。
在这一部分,我们将研究数据预处理。为了保证我们的回归分析尽可能准确,我们首先需要对原始数据进行分析和理解。我们可以使用我们学到的知识从训练和验证数据集中删除异常值,以确保这些值不会扭曲结果。此外,我们需要查看数据中的列,以了解哪些与结果相关性强,哪些是松散甚至不相关的。这些列(或机器学习术语中的特征)可以从训练和验证数据中删除,以简化神经网络的工作并提高其准确性。
本文讨论的实验代码可以在Github上找到:
https://github.com/dpage/ml-experiments/blob/main/regression/pg-tf.sql
我们将专注于 tf_analysis() 函数。显示的示例基于对波士顿住房数据集的分析。
https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html
打开样板
tf_analysis() 函数以我们可能认为的样板代码开始;它是必需的,但不是特别有趣:
CREATE OR REPLACE FUNCTION public.tf_analyse(data_source_sql text,output_name text,output_path text)RETURNS voidLANGUAGE 'plpython3u'COST 100VOLATILE PARALLEL UNSAFEAS $BODY$import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom math import ceil# Pandas print optionspd.set_option('display.max_rows', None)pd.set_option('display.max_columns', None)pd.set_option('display.width', 1000)复制
第一部分是用于声明我们正在定义 pl/python3 函数的 SQL 代码。调用时需要三个文本参数:
data_source_sql:要执行以获取要分析的数据的 SQL。
output_name:分析名称,用于文件名等。
output_path:存储我们保存的文件的目录。请注意,运行 PostgreSQL 的用户帐户必须能够将文件写入此目录。
该函数不返回任何内容,因此被标记为返回类型为 void。我设置了一个任意的成本,并将其标记为 volatile(意味着它每次运行时可能有不同的输出,即使使用相同的参数调用),并将其标记为并行执行不安全。
该函数将被调用如下:
SELECT tf_analyse('SELECT * FROM housing','housing','/Users/shared/tf');复制
在 标记之后(在接近函数末尾的关闭标记之前)是 Python 代码。首先,我们导入一些我们需要的库和函数,然后我们设置一些显示输出时 Pandas 库使用的选项。
获取数据
现在我们可以开始实际工作了:
# Create the data setsrows = plpy.execute(data_source_sql)# Check we have enough rowsif len(rows) < 2:plpy.error('At least 2 data rows must be available for analysis. {} rows retrieved.'.format(len(rows)))columns = list(rows[0].keys())# Check we have enough columnsif len(columns) < 2:plpy.error('At least 2 data columns must be available for analysis. {} columns retrieved.'.format(len(columns)))# Create the dataframedata = pd.DataFrame.from_records(rows, columns = columns)# Setup the plot layoutplot_columns = 5plot_rows = ceil(len(columns) / plot_columns)# High level infoplpy.notice('{} Analysis\n {}=========\n'.format(output_name.capitalize(), '=' * len(output_name)))plpy.notice('Data\n ----\n')plpy.notice('Data shape: {}'.format(data.shape))plpy.notice('Data sample:\n{}\n'.format(data.head()))复制
我们首先执行传递给函数的 SQL 以获取原始数据集,然后检查我们是否有足够的行和列。在columns变量中创建了一个列名列表。
然后我们创建一个包含数据的 Pandas 数据框,并设置一些稍后将用于格式化我们将创建的图的变量。
最后,我们使用 Pandas 来显示我们正在分析的数据集的摘要。这将是Postgres 中的一组NOTICE,将由 psql 或 pgAdmin 显示(在查询工具的消息选项卡上)。输出如下所示:
NOTICE: Housing Analysis================NOTICE: Data----NOTICE: Data shape: (506, 14)NOTICE: Data sample:crim zn indus chas nox rm age dis rad tax ptratio b lstat medv0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 24.01 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 21.62 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 34.73 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 33.44 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33 36.2复制
异常值
下一步是识别数据集中的异常值。异常值是具有异常值的行;在训练神经网络时删除这些很重要,因为它们不符合规范会使构建准确模型变得更加困难。为了检测异常值,我们将查看数据的四分位距:https://en.wikipedia.org/wiki/Interquartile_range
即落在第 25 到第 75 个百分位数之外的值。在这一点上,我们只是简单地绘制数据以进行可视化,但是当我们进行训练时,我们会自动删除异常值。
# Outliersplpy.notice('Outliers\n --------\n')Q1 = data.quantile(0.25)Q3 = data.quantile(0.75)IQR = Q3 - Q1plpy.notice('Interquartile Range (IQR):\n{}\n'.format(IQR))plpy.notice('Outliers detected using IQR:\n{}\n'.format((data < (Q1 - 1.5 * IQR)) |(data > (Q3 + 1.5 * IQR))))plt.cla()fig, axs = plt.subplots(ncols=plot_columns, nrows=plot_rows, figsize=(20, 5 * plot_rows))index = 0axs = axs.flatten()for k,v in data.items():sns.boxplot(y=k, data=data, ax=axs[index])index += 1plt.tight_layout(pad=5, w_pad=0.5, h_pad=5.0)plt.suptitle('{} Outliers'.format(output_name.capitalize()))plt.savefig('{}/{}_outliers.png'.format(output_path, output_name))plpy.notice('Created: {}/{}_outliers.png\n'.format(output_path, output_name))复制
上面代码的第一部分将输出基于文本的异常值分析。首先,它将显示数据集中每一列的值的四分位范围,然后将输出与数据集中的行和列对应的表,对于异常值显示 True。例如:
NOTICE: Outliers--------NOTICE: Interquartile Range (IQR):crim 3.595038zn 12.500000indus 12.910000chas 0.000000nox 0.175000rm 0.738000age 49.050000dis 3.088250rad 20.000000tax 387.000000ptratio 2.800000b 20.847500lstat 10.005000medv 7.975000dtype: float64NOTICE: Outliers detected using IQR:crim zn indus chas nox rm age dis rad tax ptratio b lstat medv0 False False False False False False False False False False False False False False1 False False False False False False False False False False False False False False2 False False False False False False False False False False False False False False3 False False False False False False False False False False False False False False...18 False False False False False False False False False False False True False False19 False False False False False False False False False False False False False False...复制
代码的第二部分使用:
Matplotlib (https://matplotlib.org/ ) 和 Seaborn (https://seaborn.pydata.org/) 库在箱形图中绘制异常值。这将使用给定的名称保存到我们在函数调用中指定的目录中,例如 /Users/Shared/tf/housing_outliers.png:
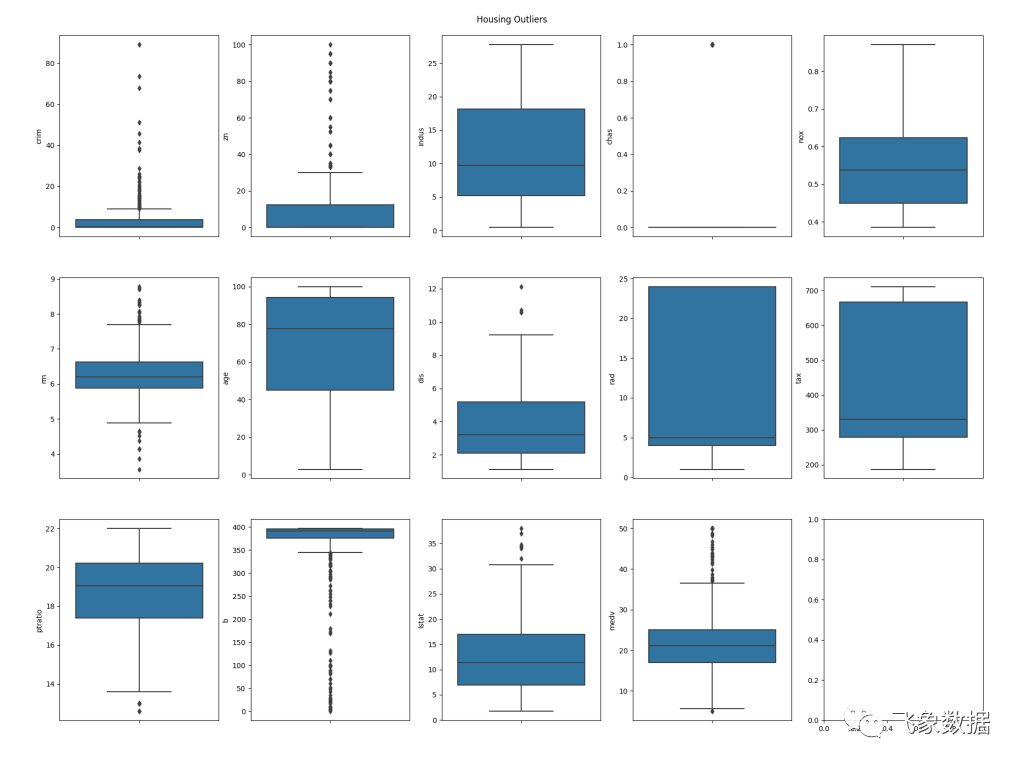
图中的蓝色框代表数据集中每一列四分位范围内的一组值,而点代表该范围之外的值,从而使它们从训练所在的行变成排除的候选内容。
分布
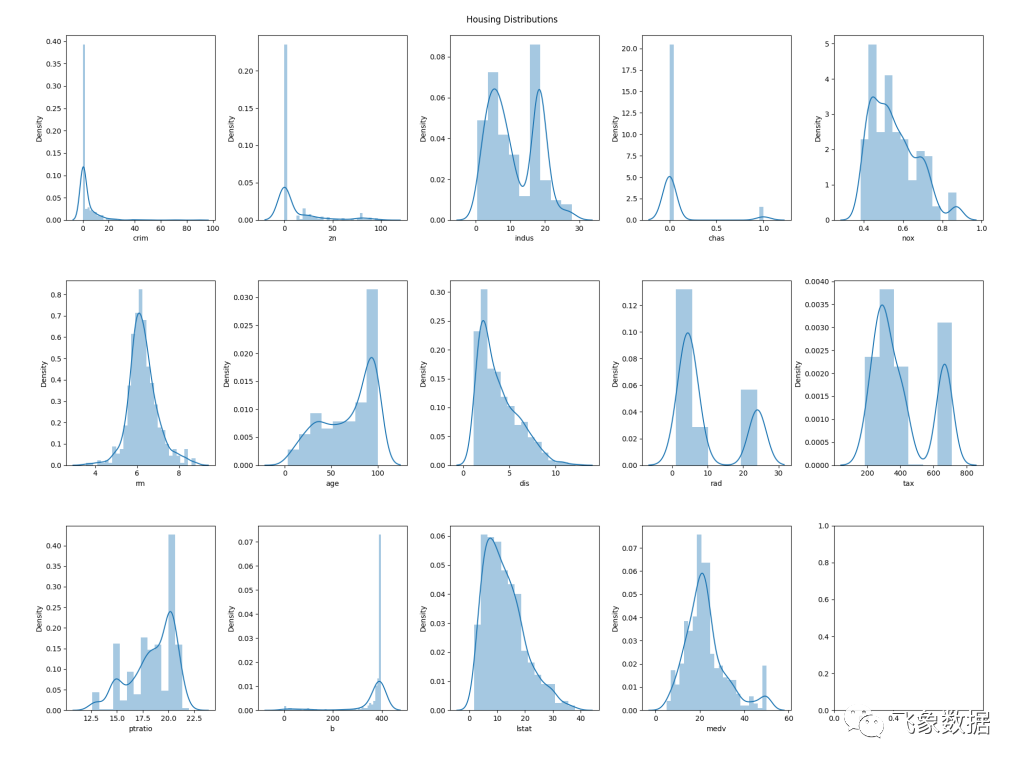
现在,我们将查看每列的值分布。这可能不会直接导致我们从用于构建模型的训练/验证集中消除数据,尽管在某些情况下可能会;例如,如果某个特定特征的分布非常窄,我们可能会选择完全排除它,因为它可能与输出无关。无论如何,这对于帮助理解数据的特征很有用。
与异常值一样,代码首先将基于文本的分析输出为 NOTICE(由 Pandas 很容易生成),然后生成图表以帮助可视化:
# Distributionsplpy.notice('Distributions\n -------------\n')plpy.notice('Summary:\n{}\n'.format(data.describe()))plt.cla()fig, axs = plt.subplots(ncols=plot_columns, nrows=plot_rows, figsize=(20, 5 * plot_rows))index = 0axs = axs.flatten()for k,v in data.items():sns.distplot(v, ax=axs[index])index += 1plt.tight_layout(pad=5, w_pad=0.5, h_pad=5.0)plt.suptitle('{} Distributions'.format(output_name.capitalize()))plt.savefig('{}/{}_distributions.png'.format(output_path, output_name))plpy.notice('Created: {}/{}_distributions.png\n'.format(output_path, output_name))复制
文本输出如下所示:
NOTICE: Distributions-------------NOTICE: Summary:crim zn indus chas nox rm age dis rad tax ptratio b lstat medvcount 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000mean 3.613524 11.363636 11.136779 0.069170 0.554695 6.284634 68.574901 3.795043 9.549407 408.237154 18.455534 356.674032 12.653063 22.532806std 8.601545 23.322453 6.860353 0.253994 0.115878 0.702617 28.148861 2.105710 8.707259 168.537116 2.164946 91.294864 7.141062 9.197104min 0.006320 0.000000 0.460000 0.000000 0.385000 3.561000 2.900000 1.129600 1.000000 187.000000 12.600000 0.320000 1.730000 5.00000025% 0.082045 0.000000 5.190000 0.000000 0.449000 5.885500 45.025000 2.100175 4.000000 279.000000 17.400000 375.377500 6.950000 17.02500050% 0.256510 0.000000 9.690000 0.000000 0.538000 6.208500 77.500000 3.207450 5.000000 330.000000 19.050000 391.440000 11.360000 21.20000075% 3.677083 12.500000 18.100000 0.000000 0.624000 6.623500 94.075000 5.188425 24.000000 666.000000 20.200000 396.225000 16.955000 25.000000max 88.976200 100.000000 27.740000 1.000000 0.871000 8.780000 100.000000 12.126500 24.000000 711.000000 22.000000 396.900000 37.970000 50.000000复制
图形表示如下所示:
相关性
虽然异常值检测用于确定应在训练前删除的数据行,但数据相关性可以向我们指示应考虑从训练和最终模型分析的数据中删除的列或特征,因为它们与输出无关. 在到目前为止所做的分析中,我们平等地考虑了数据集中的所有列或特征,但是,我们现在需要考虑哪些或哪些特征是我们的输入,哪些是输出。在此分析的情况下,所有列都是输入,除了 medv 列是输出,表示原始数据集中房屋的价值。
代码与前两个示例非常相似;Pandas 将直接从数据帧为我们生成基于文本的输出,而 Seaborn 和 Matplotlib 将生成图形输出:
# Correlationsplpy.notice('Correlations\n ------------\n')corr = data.corr()plpy.notice('Correlation data:\n{}\n'.format(corr))plt.cla()plt.figure(figsize=(20,20))sns.heatmap(data.corr().abs(), annot=True, cmap='Blues')plt.tight_layout(pad=5, w_pad=0.5, h_pad=5.0)plt.suptitle('{} Correlations'.format(output_name.capitalize()))plt.savefig('{}/{}_correlations.png'.format(output_path, output_name))plpy.notice('Created: {}/{}_correlations.png\n'.format(output_path, output_name))复制
文本输出如下:
NOTICE: Correlations------------NOTICE: Correlation data:crim zn indus chas nox rm age dis rad tax ptratio b lstat medvcrim 1.000000 -0.200469 0.406583 -0.055892 0.420972 -0.219247 0.352734 -0.379670 0.625505 0.582764 0.289946 -0.385064 0.455621 -0.388305zn -0.200469 1.000000 -0.533828 -0.042697 -0.516604 0.311991 -0.569537 0.664408 -0.311948 -0.314563 -0.391679 0.175520 -0.412995 0.360445indus 0.406583 -0.533828 1.000000 0.062938 0.763651 -0.391676 0.644779 -0.708027 0.595129 0.720760 0.383248 -0.356977 0.603800 -0.483725chas -0.055892 -0.042697 0.062938 1.000000 0.091203 0.091251 0.086518 -0.099176 -0.007368 -0.035587 -0.121515 0.048788 -0.053929 0.175260nox 0.420972 -0.516604 0.763651 0.091203 1.000000 -0.302188 0.731470 -0.769230 0.611441 0.668023 0.188933 -0.380051 0.590879 -0.427321rm -0.219247 0.311991 -0.391676 0.091251 -0.302188 1.000000 -0.240265 0.205246 -0.209847 -0.292048 -0.355501 0.128069 -0.613808 0.695360age 0.352734 -0.569537 0.644779 0.086518 0.731470 -0.240265 1.000000 -0.747881 0.456022 0.506456 0.261515 -0.273534 0.602339 -0.376955dis -0.379670 0.664408 -0.708027 -0.099176 -0.769230 0.205246 -0.747881 1.000000 -0.494588 -0.534432 -0.232471 0.291512 -0.496996 0.249929rad 0.625505 -0.311948 0.595129 -0.007368 0.611441 -0.209847 0.456022 -0.494588 1.000000 0.910228 0.464741 -0.444413 0.488676 -0.381626tax 0.582764 -0.314563 0.720760 -0.035587 0.668023 -0.292048 0.506456 -0.534432 0.910228 1.000000 0.460853 -0.441808 0.543993 -0.468536ptratio 0.289946 -0.391679 0.383248 -0.121515 0.188933 -0.355501 0.261515 -0.232471 0.464741 0.460853 1.000000 -0.177383 0.374044 -0.507787b -0.385064 0.175520 -0.356977 0.048788 -0.380051 0.128069 -0.273534 0.291512 -0.444413 -0.441808 -0.177383 1.000000 -0.366087 0.333461lstat 0.455621 -0.412995 0.603800 -0.053929 0.590879 -0.613808 0.602339 -0.496996 0.488676 0.543993 0.374044 -0.366087 1.000000 -0.737663medv -0.388305 0.360445 -0.483725 0.175260 -0.427321 0.695360 -0.376955 0.249929 -0.381626 -0.468536 -0.507787 0.333461 -0.737663 1.000000复制
数据显示在网格中,每个特征都有一行和一列。相交的单元格包含这两列的相关值。与同名的行和列相交的单元格的相关性正好为 1,因为两个轴都表示相同的一组值。我们主要对与输出值 medv 的相关性感兴趣。不幸的是,在文本输出中很难看到,但是彩色图形输出使它更容易:
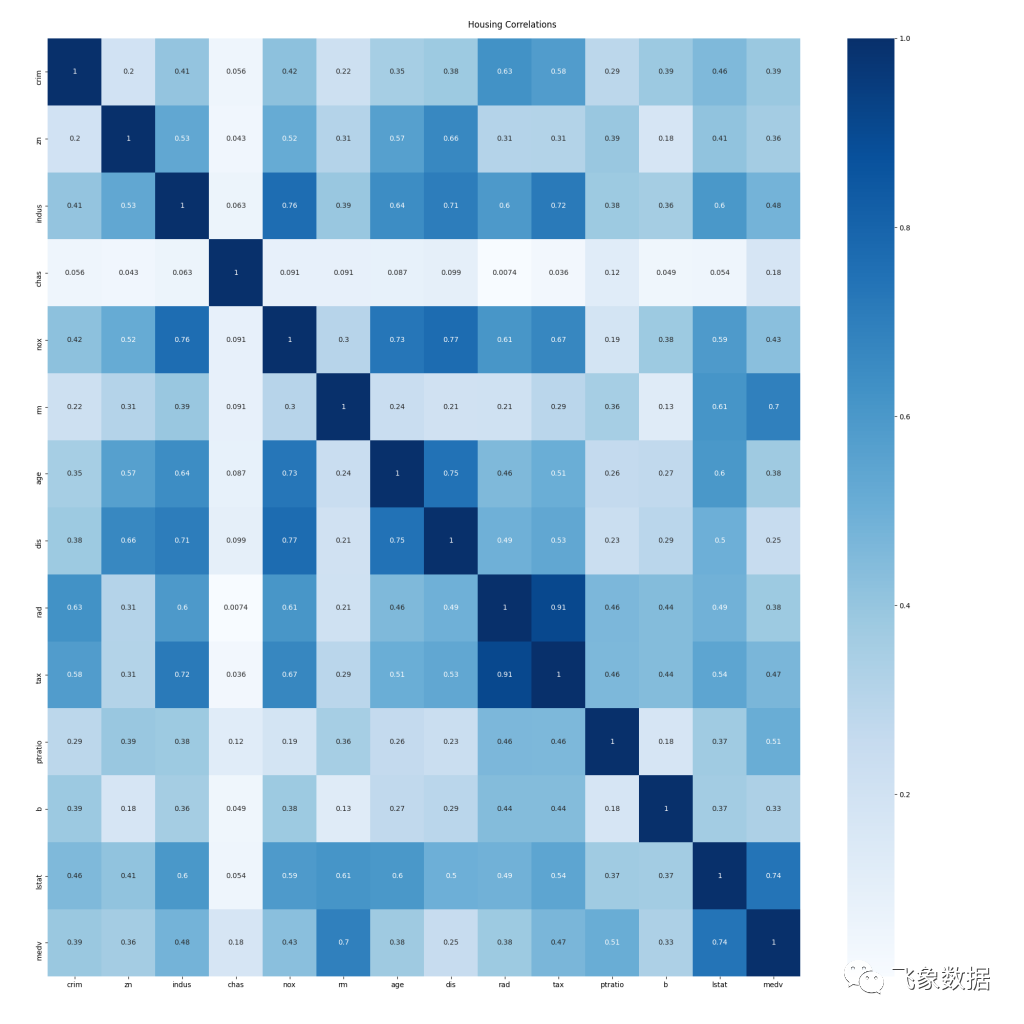
单元格越暗,两个值之间的相关性越强。应该考虑从训练/验证数据集中删除更弱相关的特征,当然,任何使用训练模型执行的后续分析。
关闭样板
有少量关闭样板来完成功能:
$BODY$;ALTER FUNCTION public.tf_analyse(text, text, text)OWNER TO postgres;COMMENT ON FUNCTION public.tf_analyse(text, text, text)IS 'Function to perform statistical analysis on an arbitrary data set.Parameters:* data_source_sql: An SQL query returning at least 2 rows and 2 columns of numeric data to analyse.* output_name: The name of the output to use in titles etc.* output_path: The path of a directory under which to save generated graphs. Must be writeable by the database server''s service account (usually postgres).';复制
在标记关闭Python代码块,和分号关闭CREATE FUNCTION语句。其余行将函数所有者设置为超级用户帐户并添加注释以用于文档目的,这始终是一种好习惯。
结论
在本博客迷你系列的第一部分中:
https://www.enterprisedb.com/blog/regression-analysis-postgresql-tensorflow-part-1-getting-started
我们研究了如何设置 PostgreSQL,以便我们可以使用 TensorFlow 从使用 pl/python3 过程语言的数据库服务器内对我们的数据执行回归分析。
在这一部分中,我们探索了一个 SQL 函数,该函数将对任意数据集执行各种类型的分析,以帮助我们理解数据并就如何训练神经网络对类似数据执行回归分析做出明智的决定。我们使用了 Pandas、Matplotlib 和 Seaborn Python 库来做到这一点。
在本系列的第三部分也是最后一部分中,我们将根据这里的发现构建一个数据集,并使用它来训练一个可用于回归分析的神经网络,所有这些都来自 PostgreSQL。敬请关注!




