




数据冷热分离
数据的存在价值,在于其被使用的程度,即被查询或更新的频率。在不同的业务系统中,人们对处于不同时期的数据有着不同的使用需求。比如,在网络流量行为分析系统中,客户会对最近一个月公司发生的安全事件和网络访问情况感兴趣,而很少关注几个月前的数据;在电商订单系统中,用户会经常访问最近三个月的订单,而更久远的数据则几乎不会去关注。针对这样一些业务场景,我们将数据按照时间纬度划分为二个阶段:Hot、Cold。

区分冷热数据的根本目的,在于控制成本。
为什么这么说?
因为通常情况下,为了支持热数据的操作特性,需要有较好的硬件配置,比如高性能CPU、大内存、SSD硬盘等等。随着时间的推移,系统里会积累越来越多的历史数据,如果依然采用高配置机器来存放这些使用频率非常低的数据,势必会带来非常高的成本。
目前比较常见的冷热分离方案是将冷热数据分离到两套不同的系统,这两套系统拥有不同的存储特性、访问方式等,从而在保证热数据访问性能的同时,将冷数据的成本降低下来。而随着冷热分离方案的普及,很多框架也开始考虑类似的事情,尝试在自己的体系下支持将数据进行冷热分离,避免两套系统带来的复杂性。我们姑且将这两种方案分别称为“冷热分离异构系统”和“冷热分离同构系统”。酬金项目建议使用冷热分离同构系统。
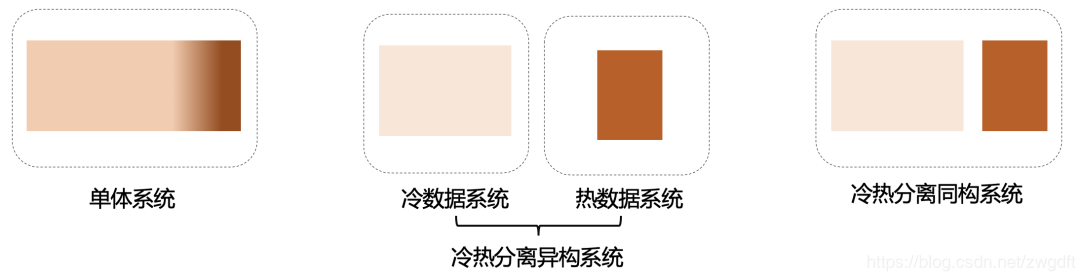

实践中,通常需要结合具体的业务,考虑下面几件事:
- 冷热数据存储的选型
- 确定冷热数据分割线
- 如何进行数据的迁移
冷热数据存储的选型
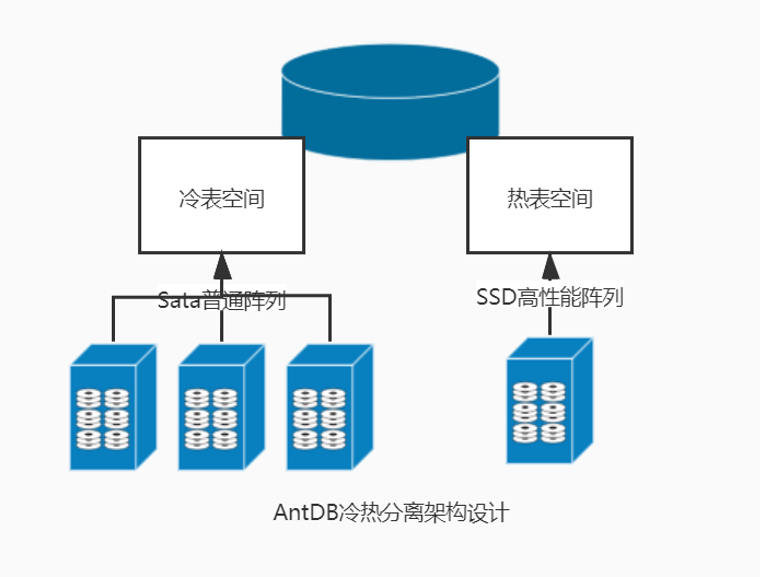
绝大部分场景,数据都可以分为“冷数据”和“热数据”。数据划分的原则,可以根据时间远近、热点/非热点数据等等。例如在以往项目中的实例,用户通常只访问一段时间之内的数据,例如近一周或一个月。如果数据不做划分,必然会导致一定程度上的性能、成本损耗。
在存储选型上,对于热数据存储,需要重点考虑读写的性能问题,诸如闪存、SSD等会成为首选;而对于冷数据存储,则重点关注低成本存储问题,通常会选择存储在低端磁盘阵列中。
确定冷热数据分割线
数据有冷热划分,那么就会有界限、生命周期。新的数据写入时,其属性是“热”的;当到达某个时间节点或预设阈值时,就需要把数据迁移到“冷”数据存储。
浙江移动酬金项目的冷热数据是按照时间推移来区分的,因此必然要敲定一个时间分割线,即多久以内的数据为热数据,这个值通常会结合业务与历史访问情况来综合考量。对于超过时间线的数据,会被迁移到冷数据中,迁移过程需要确保两点:
- 不能对热数据产生性能影响
- 不能影响数据查询
冷热数据标记
酬金业务的数据库模型中,大部分的表名都加上了月份,可以根据表名轻易标记冷热数据。根据酬金业务统计,95%以上的请求访问的是最近3个月的数据,因此热数据保留3个月的数据,其他的迁移到冷数据存储。
如何进行数据的迁移
冷热数据已经根据月份表做了标记,只需要将这部分月表迁移至冷数据存储。
AntDB支持表级别和表空间级别的数据迁移,数据迁移时采用直接将源表空间的数据文件硬拷贝至目标表空间的方式,相比传统的新建临时表/导出导入数据/新建索引或者流复制的模式(增量数据怎么处理?),AntDB的迁移效率要快的多。
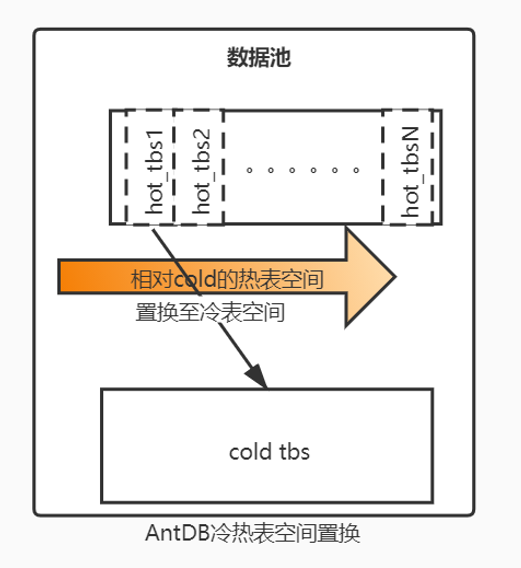
表级别数据迁移
标记为冷数据的月份表及索引迁至冷数据存储。标记单位:月份表
/*pg*/alter table test01 set TABLESPACE tbs2;
/*pg*/alter index test01_idx set TABLESPACE tbs2;
表空间级别数据迁移
标记为冷数据的热表空间内的所有月份表/索引一次性迁至冷数据存储。标记单位:表空间
/*pg*/alter table all in tablespace tbs1 owned by test set tablespace tbs2;
/*pg*/alter index all in tablespace tbs1 owned by test set tablespace tbs2;
2种迁移级别对比
表级别 | 表空间级别 | ||
热表空间数量 | 1个 | 至少3个 | |
表的生命周期 | 创建表 | 简单 常规方式创建即可 | 复杂 需要根据时间维度指定到某个热表空间 |
使用表 | 无区别 | 无区别 | |
迁移表 | 迁移步骤复杂,但比较灵活,可以多个表同时迁移。表迁移期间是独占锁,锁持有时间短。 | 迁移步骤简单,但表空间内的表只能串行迁移。 表空间迁移期间都是独占锁,锁持有时间较长。 整个表空间迁移完,才会释放独占锁。 | |
销毁表(热表空间) | 迁移完成后再销毁 | 迁移完成后再销毁 | |
迁移过程是否对热数据产生性能影响 | 在1个热表空间,底层绑定同一个物理卷,IO是共享的,有影响 | 多个热表空间,按照先进先出的原理循环使用,底层绑定不同的物理卷,IO是隔离的,无影响 | |
迁移周期 | 冷数据被标记后,可以指定按月为周期迁移,减少IO影响 | 冷数据和时间维度的表空间相关,至少按月为单位迁移,否则创建表将变得极其复杂。 | |
迁移过程是否影响数据查询 | 锁表时,不允许查询。锁表时间短。 | 锁表时,不允许查询。锁表时间较长。 | |
2种置换方式的技术难点对比 | 1.如何找出标记为冷数据的表。通过pg的系统视图根据表名的月份可以标记出来,但标记时比表空间置换要复杂。 2.如何解决IO影响 3.如何减少WAL日志 | 1.如何降低建表的复杂度 2.如何降低锁表的时间周期 3.虽然底层绑定不同的物理卷,但只有一个raid卡通道,虽然做了隔离,应该还是有IO影响,主机申请下来后,待验证该功能,再下结论。 4.如何减少WAL日志 | |
关于IO影响:迁移过程是有读有写的过程,从热数据的ssd读出来,往冷数据的普通盘写进去。根据经验,在一条由ssd+普通盘组成的IO读写链上,普通盘的顺序写速率如果在200MB/s左右,操作系统为了均衡服务器资源使用情况,此时ssd的读速率基本也保持在200M/s左右。而此时普通盘已经到瓶颈,但ssd远未达到瓶颈,还预留了大量带宽,且此时也只影响ssd的读的带宽。(此方案中,可以通过限制普通盘的写速率,来达到降低迁移ssd热数据时的IO影响,待验证)
测试数据/初步结论/改造点
alter table/index set tablespace的测试内容:
tbs1下面创建1张 13GB的表 进行迁移
表级别(多进程并行) | 表空间级别 | ||
性能 | 不记WAL(set unlogged) | 2s | 2s |
记WAL(set logged) | 8s | 8s | |
锁表时间(不记WAL) | 表1 | 2s | 2s |
锁表时间(记WAL) | 表1 | 8s | 8s |
tbs1下面创建3张 13GB的表 进行迁移
表级别(多进程并行) | 表空间级别 | ||
性能 | 不记WAL日志 | 2s | 6s |
记WAL日志 | 8s | 24s | |
锁表时间(不记WAL) | 表1 | 2s | 6s |
表2 | 2s | 6s | |
表3 | 2s | 6s | |
锁表时间(记WAL) | 表1 | 8s | 24s |
表2 | 8s | 24s | |
表3 | 8s | 24s | |
WAL日志量 | 3张13GB的表 | 39GB | 39GB |
3个2GB的主键索引 | 6GB | 6GB |
1.不管哪种方式,都要减少WAL日志
2.表空间置换,需要降低锁表时间 或者 降低锁级别,在迁移期间允许 select 查询
3.表置换,需要将alter table/index set tablespace 命令合并为一条,降低迁移复杂度
4.如何减少IO影响
分区置换(ATTACH/DETACH PARTITION) 和 表空间置换(SET TABLESPACE) 性能对比
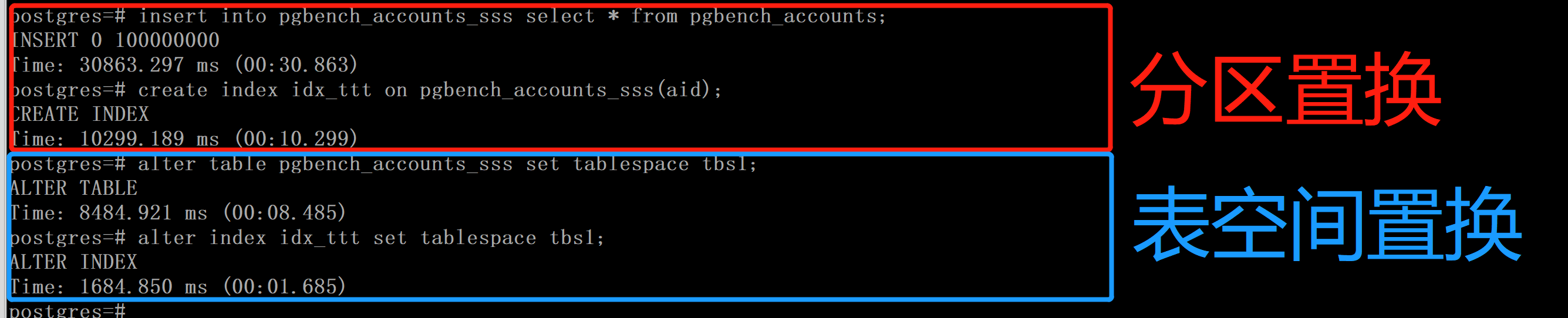
由于alter table/index set tablespace锁表时间太长,业务不太能接受,所以采用下述方案
最终的方案(最终的需求):
1、采用insert into select临时过渡表进行数据迁移
2、迁移表提供一个函数,迁移索引提供一个函数。再提供一个函数,封装前面2个函数,用户只需要提供表名,该函数即可以自动完成表及该表上所有索引的迁移。
