




count如何执行?
有时候我们业务上的需求,需要统计某个业务场景有多少客户或者说表多少记录?那么程序员们肯定首先想到的肯定是
select count(*) from t;
那么这条语句到底是怎么执行的呢?这么操作就肯定不会引入问题么?随之数据量的增大,查询越来越慢真的不会有问题吗?
count 实现方式
count(*)
的实现,在MySql中区别于MyISAM引擎与InnoDB引擎的实现。
•MyISAM会把一个表的总行数记录在磁盘上,执行count(*)就将这个记录下的数字取出来,这效率可不是一般地高。但是每次做一次插入操作就记录一次数据,这每次的IO操作加起来还是蛮大的。•InnoDB执行count(*)就不是那么简单了,比较老实巴交一行一行地数。
但是要是这样呢?
select count(*) from t where xxx_id is not null;
这样就有了过滤条件了,有了过滤条件就需要参考索引值或者从主键找到该行,判断是否有数据再叠加。无论MyISAM和InnoDB都需要逐行计算。
InnoDB独有事务机制,InnoDB的索引组织表,索引包括主键索引与普通索引(非主键索引)。MySQL优化器会找到最小的树来遍历,在逻辑正确的前提下,减少扫描数据量,得出 count(xxx)
的值。
count 使用方式
目前流行的 count
使用方式,包括 count(*)
count(1)
count(字段)
count(主键id)
等。这里面不同的用法,性能也不一样。 基于innoDB引擎 count()
是一个聚合函数,对于返回的结果,上述所说,这是一个老实巴交的计算,如果 count
参数不是NULL,累计值 +1
否则不加,最后返回累计值。
•count(*)
不取值,按行累加。•count(1)
不取值,按行累加。•count(主键id)
遍历表取id的值,返回server层,再拿id的值去判断数据是否为空,不为空按行累加,但是主键不可能为空,所以优化器会优化掉。•count(字段)
若字段定义为not null,那就只需要遍历表,取字段,按行累加;否则若为null,则需要取值出来判断一下,不是null就累加。
所以效率,由上往下,逐个递减。
进阶分析
噢,对了,来个进阶版分析,最近遇到一个性能上的问题
先来看看这一段sql
select a.t_id as t_id, count(*) as cnt from a_trans_t a inner join b_trans_t b on a.t_id = b.t_id and a.r_id = b.r_id where a.t_id in (?) and a.r_id in (?) group by a.t_id;
这段SQL由三个关键信息, count(*)
inner join
group by
。上面讲了count(*),那么下面先来简要讲讲 inner join
与 group by
inner join
讲到join,先祭出一张韦恩图。
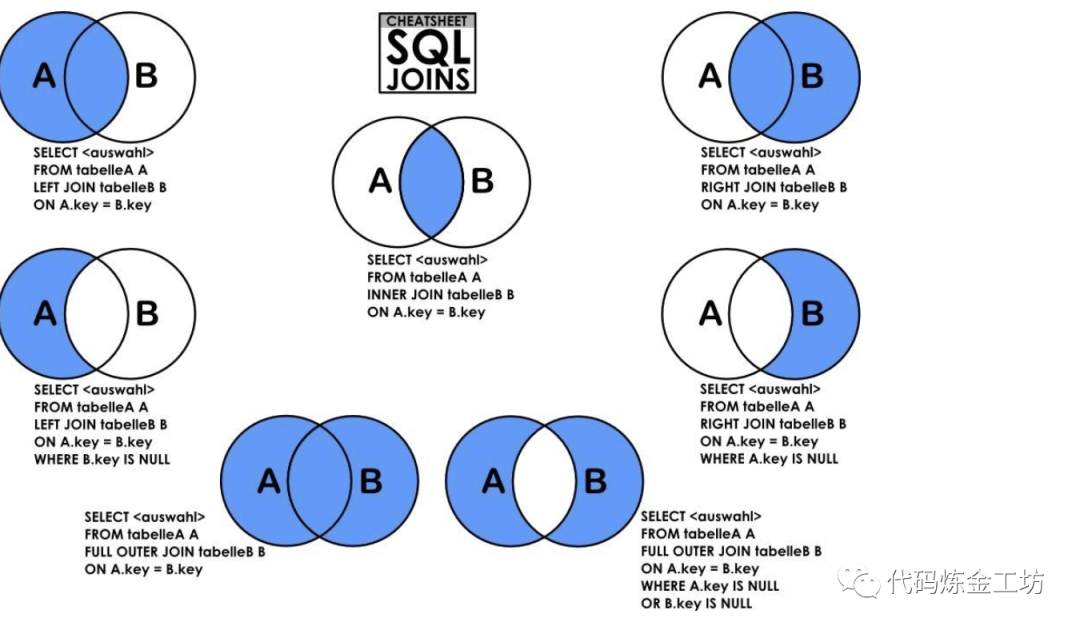
由图可知,这个inner join操作,是取A和B的交集。根据on条件获取两表的交集也就是临时表数据t1,根据t1的数据a表字段值 r_id
与 t_id
查询数据进行统计。那么根据这段SQL的目的,其实取交集也没问题,毕竟要统计两表交集中,在a表对应r_id
与 t_id
的数据量有多少。
group by
groub by
的作用,其实就是将数据,按照给定的字段值分组表示,并排序。根据上面的SQL语句,我们会发现,这个sql的目的,需要 group by
按照a表的t_id排序,那么如果根据交集查出来的数据存在于索引之中,那一切都好说,毕竟InnoDB的索引树的节点数据是按照一定顺序排序的。
a表存在800万数据,b表存在不到1万数据,而这个查询耗费的时间是25-34秒。这肯定被认定为慢查询了,到底怎么回事?先来看这个查询,这个 inner join
驱动表a,而a表存在800万数据,根据join复杂度计算公式(至于这个公式怎么来的,下回跟读者们讲讲)
T(n)=N+N*2*logM # N 驱动表数据N行 M被驱动表数据M行
驱动表走的是全表扫描,而被驱动表走的索引树搜索。也就是说这个SQL应该小表先行
SELECT a.t_id, count(a.t_id) AS cntFROM b_trans_t bINNER JOIN a_trans_t aON a.t_id = b.t_idAND a.r_id = b.r_idWHERE a.t_id IN (?)AND a.t_id IN (?)GROUP BY a.t_id
驱动表查询复杂度 用小表N驱动查询。
explain SQL
既然这个SQL遇到性能问题,那就Explain一下,发现了端倪。

哇,那么大一张表a,800多万数据的表,居然用了where 回表查询,而且explain出来的key,居然还是索引t_id。 那只能加联合索引拯救一下了,根据小表驱动先行的思想,查到表r_id与t_id存在一对多关联,所以建立了r_id字段在前的联合索引IX_r_id,t_id。 再explain一下

实践见真知:
修改大表在前SQL
select a.t_id as t_id, count(*) as cnt from a_trans_t a inner join b_trans_t b on a.t_id = b.t_id and a.r_id = b.r_id where a.t_id in (?) and a.r_id in (?) group by a.t_id;
查询耗时
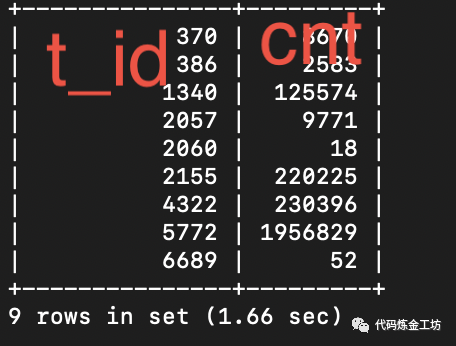
耗时1.66秒 修改小表驱动的SQL
SELECT a.t_id, count(a.t_id) AS cntFROM b_trans_t bINNER JOIN a_trans_t aON a.t_id = b.t_idAND a.r_id = b.r_idWHERE a.t_id IN (?)AND a.t_id IN (?)GROUP BY a.t_id

耗时0.9秒,秒回了!
带来的思考
码农不易!
参考资料:
•explain 详解[1]•group by执行简易原理[2]•极客时间Mysql实战45讲•count(*)这么慢,我该怎么办?•深入浅出索引上下•order by 是怎么工作的?•到底可不可以使用join?•都说InnoDB好,那还要不要使用Memory引擎
引用链接
[1]
explain 详解: https://www.jianshu.com/p/ea3fc71fdc45[2]
group by执行简易原理: https://www.cnblogs.com/newjiang/p/12841570.html
