




介绍
在本文中,我们将继续讨论关于“数据科学”和“机器学习”的重要关键面试问题,这有助于清楚地了解这些技术,也有助于机器学习、人工智能和数据科学面试。
我们相信您已经学习了有监督和无监督算法的理论和实践知识。
因此,让我们在这里测试您的知识。
面试问题
1.监督学习和无监督学习的区别。
|
|
| 监督学习算法使用标记数据(目标列)进行训练。 | 无监督学习算法通过使用未标记的数据进行训练。 |
| 监督学习算法旨在训练模型在给定新数据时预测输出。 | 无监督学习算法旨在从未知数据集中找到隐藏的模式和有用的见解 |
| 输入数据与输出一起提供给模型。 | 仅向模型提供输入数据。 |
| 监督学习可以分为: 1.分类和 2.关联问题。 | 无监督学习可分为: 1. 聚类和 2. 关联问题。 |
2. 什么是线性回归?
线性回归通过寻找直线的最佳拟合来建立因变量 (Y) 和一个或多个自变量 (X) 之间的关系。
线性模型的方程是 Y = mX+C,
其中 m 是斜率,C 是截距。
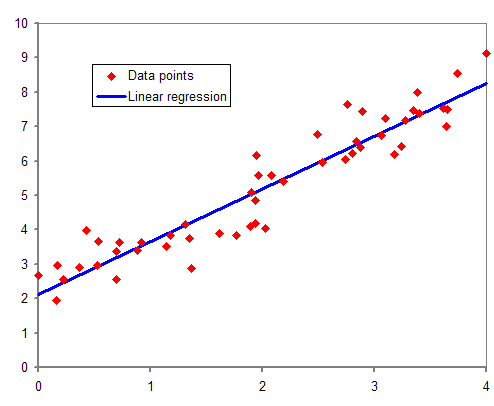
在上图中,我们看到的红点是“Y”关于 X 的分布。在现实生活中,没有一条直线贯穿所有数据点。因此,这里的目标是拟合直线的最佳拟合,以最小化预期值和实际值之间的误差。
回归指标
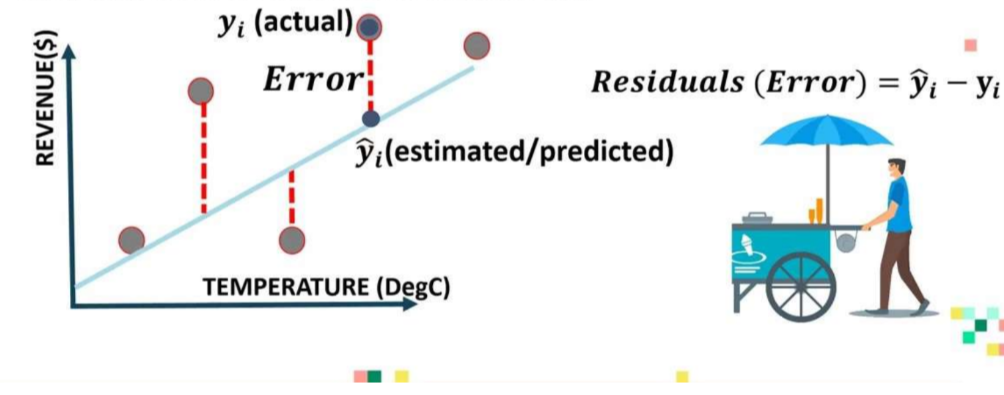
回归指标:

3. 解释回归模型中的错误:
1. 平均绝对误差 (MAE):
MAE 是通过计算模型预测值和真实(实际)值之间的绝对差来计算的。
MAE 是回归模型产生的平均误差幅度的度量:
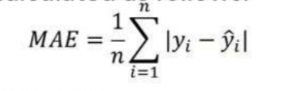
如果 MAE 为零,则表明模型预测是完美的。
2. 均方误差 (MSE):
MSE 与平均绝对误差 (MAE) 非常相似。在 MAE 中,不是使用绝对值,而是计算模型预测和训练数据集(真值)之间差异的平方。
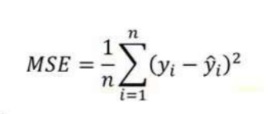
MSE 值通常大于 MAE,因为残差是平方的。在数据异常值的情况下,与 MAE 相比,MSE 将变得非常大。
在 MSE 中,由于误差是平方的,因此任何预测误差都会受到严重惩罚。
3.根均方误差(RMSE):
均方根误差 (RMSE) 表示残差的标准差(模型预测与真实值(训练数据)之间的差异
。RMSE 提供了对分散残差大小的估计。
与 MSE 相比,RMSE 可以很容易翻译,因为RMSE 单位类似于输出单位。
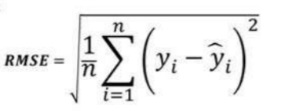
4. 平均百分比误差 (MPE):
平均百分比误差 (MPE) 有助于深入了解与负误差相比有多少正误差。
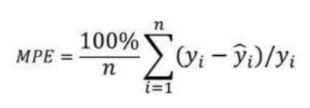
5. 平均绝对百分比误差 (MAPE):
平均绝对误差值的范围可以从零到无穷大,因此与训练数据相比,很难解释结果。
平均绝对百分比误差与 MAE 等效,但以百分比形式提供误差,因此克服了 MAE 的限制。
如果数据点值为零(因为涉及除法运算符),MAPE 可能会表现出一些限制。
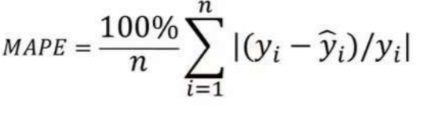
4. 什么是 R-Square,R-Square 究竟代表什么?
1. R-Square 表示因变量 (Y) 的方差已被自变量解释的比例。
2. R-Square 提供对拟合优度的洞察。
3. 最大 R-Square 值为 1。
4. 始终预测 y 的期望值而忽略输入特征的一致模型的 R-Square 评级为 0。
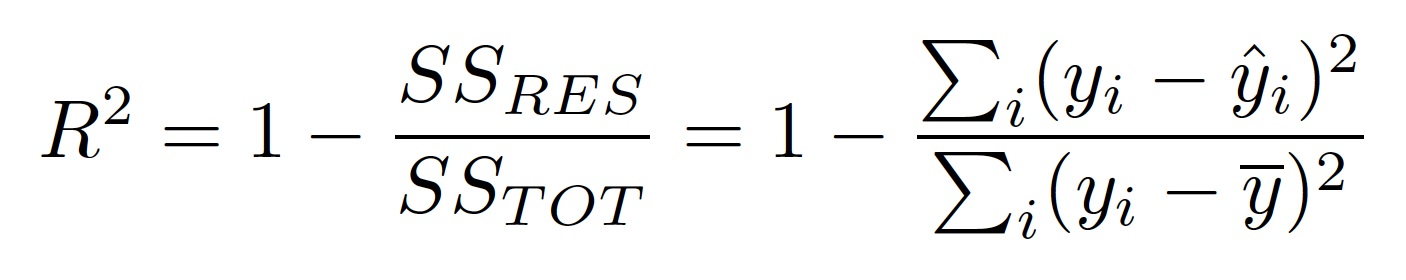
5. R-Square 和 Adjusted R-Square 有什么区别?
R-Square ( R² ) 解释了输入变量解释输出/预测变量变化的程度。
如果 R-Square 为 0.8,则意味着 80% 的输出变化由输入变量解释。所以简单来说,R-Squared 越高,输入变量解释的变化就越多,因此我们的模型就越好。
R 方的限制之一是它通过向模型中添加自变量来增加,即使它们与输出变量没有任何关系或与输出变量的关系非常小。
这就是调整后的 R 平方可以提供帮助的地方。如果我们尝试添加一个不会改进模型的自变量,调整后的 R 方会通过添加惩罚来克服这个问题。
如果将无用的预测变量添加到模型中,调整后的 R-Square 将会减少。
如果将有用的预测变量添加到模型中,调整后的 R-Square 将会增加。
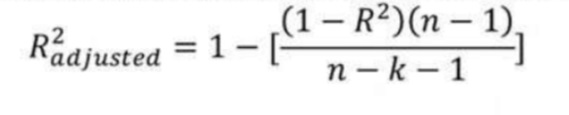
字母 k 表示自变量数,字母 n 表示样本数。
因此,如果您正在开发多个变量的线性回归模型。始终建议您使用调整后的 R-Squared 来判断模型的优劣。如果您只有一个输入变量 R-Square 和 Adjusted R-Square 将是相同的。
6. 线性回归的假设是什么?
线性回归是一种统计模型,它允许基于一个或多个自变量(表示为 X)的变化来解释因变量 y。它基于因变量和自变量之间的线性关系来做到这一点。
1. 线性/线性关系:自变量 X 和因变量 Y 之间存在线性关系。检测是否满足此假设的最简单方法是创建 X 与 Y 的散点图。这使您可以可视化是否这两个变量之间存在线性关系。
2. 独立性:线性回归的下一个假设是残差是独立的。在处理时间序列数据时最相关。理想情况下,我们不希望在连续残余之间存在模式。测试是否满足此假设的最简单方法是查看残差时间序列图,它是残差与时间的关系图。
3. 正态性:线性回归的下一个假设是残差是“正态分布的”。QQ 图是分位数图的缩写,是一种我们可以用来确定模型的残差是否服从正态分布的图。如果图上的点大致形成一条直线对角线,则满足正态性假设。
4. 等方差/同方差性:残差在每个 X 水平(自变量)处具有恒定方差。它被称为同方差性。将回归线拟合到一组数据后,您可以创建一个散点图,显示模型的拟合值与这些拟合值的残差。
7.回归和相关有什么区别?
相关性: 在实际情况下,相关性衡量两个变量之间关系的强度或程度。它没有捕捉因果关系。“相关性”用一个点来表示。
回归:衡量一个变量如何影响另一个变量。“回归”是关于模型拟合的。它试图捕捉因果关系并解释因果关系。“回归”由回归线表示。
8. 什么是异方差?如何检测它?
异方差是指残差的方差在一系列测量值上不相等的情况。运行回归分析时,“异方差”会导致残差(也称为误差项)分布不均。
9. 什么是线性回归中的截距?它的意义是什么?
截距是函数穿过 Y 轴的点。当所有 X = 0 时,截距是 Y 值的标准平均值。
10.什么是OLS?
OLS 代表普通最小二乘。线性回归算法的主要目标是通过最小化误差项来找到系数或估计值,从而使平方误差之和最小。此过程称为 OLS。
此方法通过最小化观察值和预测值之间的平方差之和来找到最佳拟合线,称为回归线。
11. 什么是多重共线性?
这是一种现象,其中两个或多个自变量(预测变量)彼此高度相关,使得一个变量可以在其他变量的帮助下线性预测。它决定了自变量之间的相互关系和关联。
多重共线性的原因:
1.假人使用不准确。
2. 由于可以从数据集中的另一个变量计算的变量。
检测多重共线性:
1. 通过使用相关系数。
2.借助方差膨胀因子(VIF)和特征值。
12. 什么是 VIF?你是怎么计算的?
VIF 代表方差膨胀因子,它决定了估计回归系数的方差由于变量之间存在共线性而增加了多少。它还计算特定回归模型中存在多少多重共线性。
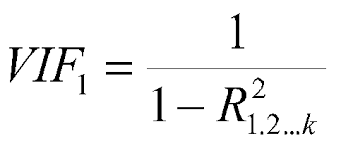
总是希望 VIF 值尽可能低。设置了阈值,这意味着任何大于阈值的自变量都必须删除。
13. 对于线性回归模型,我们如何解释 QQ 图?
QQ 图用于表示两个相互关联的分布的分位数的图形绘图。简单来说,QQ图就是用来检验误差的正态性的。
每当我们解释 QQ 图时,我们都应该关注对应于正态分布的 y=x 线。有时这也被称为统计中的 45 度线。
QQ图的用法:
1. 检查两个样本是否来自同一个总体。
2. 两个样本是否有相同的尾巴。
3. 两个样本是否具有相同的分布形状。
14. 为什么首选绝对误差而不是平方误差?
1. 从我们的模型进行预测时,绝对误差通常更接近我们想要的。但是,如果我们想惩罚那些导致误差最大值的预测。
2. 在数学方面,平方函数处处可微,而绝对误差在所有点处不可微,其导数未定义为 0。这使得平方误差比数学优化技术更可取。
3.我们使用均方根误差代替均方误差,使RMSE的单位和因变量相等,结果可解释。
15. 线性回归算法的缺点是什么?
1、线性假设:始终假设自变量(输入)和因变量(输出)之间存在线性关系。因此,我们无法借助线性回归来拟合复杂的问题。
2.异常值:对异常值高度敏感。
3. 多重共线性:受多重共线性影响。
16. 什么是正则化?解释它的类型?
正则化旨在通过以下方式解决一些常见的模型问题:
1. 最小化模型复杂度。
2. 惩罚损失函数。
3. 减少模型过拟合(增加更多偏差以减少模型方差)。
一般来说,我们一般可以解释,正则化是一种减少模型过拟合和方差的方法。为了这-
1. 它需要一些额外的偏见
2. 需要搜索最优惩罚超参数。
类型:
1. L2 正则化:岭回归
2. L1 正则化:LASSO 回归
3.结合L1和L2:弹性网络
L2 正则化:岭回归
岭回归通过应用惩罚项(减少权重和偏差)来克服过度拟合。
在 Ridge 中,回归斜率随着 ridge 回归惩罚项而减小,因此模型对自变量的变化变得不那么敏感。
最小二乘回归:最小值(残差平方和)
岭回归:最小值(残差平方和 + α .(斜率)²)
L1 正则化:LASSO 回归
套索回归类似于岭回归。它通过引入偏置项来工作,但不是平方斜率,而是将斜率的绝对(模量)值添加为“惩罚项”。
最小二乘回归:最小值(残差平方和)
岭回归:最小值(残差平方和 + α |斜率|)
弹性网:
弹性网络是一种流行的正则化线性回归类型,它结合了 L1 和 L2 惩罚项。
17. 机器学习中的分类算法是什么?
分类算法是一种监督学习技术,用于根据训练数据识别新观察的类别。在分类中,程序从给定的数据集或观察中学习,然后将新的观察分类为若干类或组,例如是或否。0 或 1。垃圾邮件或非垃圾邮件。类可以称为目标或类别。
1.二元分类器:如果分类问题只有两种可能的结果,则称为二元分类器。
示例:是或否、男性或女性、垃圾邮件或非垃圾邮件
2. 多类分类器:如果问题有两个以上的结果,则称为多类分类器。
示例农作物类型分类,音乐类型分类。
分类算法可以进一步分为主要的两类:
1. 线性模型:
1. 逻辑回归
2. 支持向量机。
2.非线性模型:
1. K-最近邻
2. 内核支持向量机
3.朴素贝叶斯
4.决策树分类
5. 随机森林分类。
18.你对混淆矩阵的理解是什么?解释?
1.混淆矩阵是一个N x N矩阵,用于评估分类模型的性能,其中N是目标类的数量。
2.混淆矩阵在机器学习模型的帮助下将实际目标值与预测值进行比较。
3. 也称为误差矩阵。
19.什么是AUC-ROC曲线?
1. ROC Curve 代表 Receiver Operating Characteristics Curve & AUC 代表 Area Under the Curve。
2. 该图显示了分类模型在不同阈值下的性能。
3. 为了可视化多类分类模型的性能,我们使用 AUC-ROC 曲线。
4. ROC 曲线以 FPR(假阳性率)为 X 轴,TPR(真阳性率)为 Y 轴绘制。
5. 如果 ROC-AUC = 1,完美分类器。
20.什么是逻辑回归?
逻辑回归是一种监督学习分类算法,用于预测目标变量的概率。
目标或依赖的性质是不可分割的,这意味着将只有两个可能的类别。
简而言之,因变量本质上是二进制的,数据编码为 1 或 0。
在逻辑回归中,我们不是拟合回归线,而是拟合“S”形逻辑函数,它预测两个最大值(0 或 1)。
例子:
1. 细胞是否癌变。
2. 学生将通过或失败。
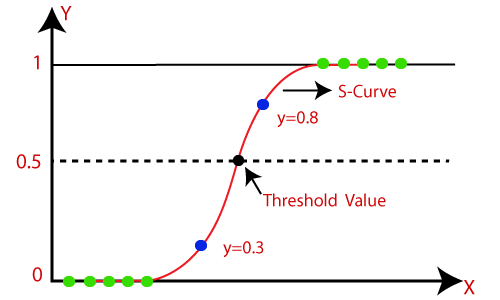
21.什么是Logistic函数或Sigmoid函数?
Sigmoid 函数是一种数学函数,用于将预测值映射到 0 和 1 的概率。
线性回归模型将预测值生成为从负无穷到正无穷的任意数字。但是我们知道概率可以在 0 到 1 之间。
为了克服这个问题,我们使用回归曲线,它使用 Sigmoid 函数将曲线的直线转换为 S 曲线,它总是会给出 0 到 1 之间的值1. S型曲线称为sigmoid或Logistic函数。功能。
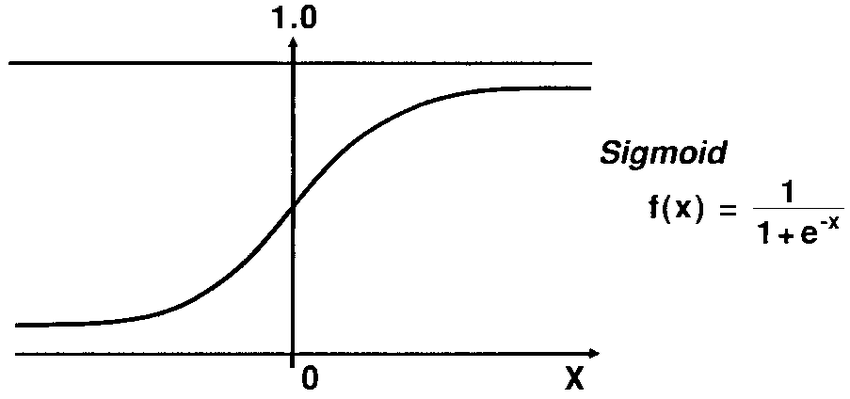
22. 解释逻辑回归中的假设:
1. 自变量之间没有或最小的多重共线性,因此预测变量不相关。
2. 结果的 Logit 和每个预测变量之间应该存在线性关系。
3. 通常需要大样本量。
4. 它假定观察之间没有依赖关系。
23. 线性回归和逻辑回归的比较。
| 线性回归 | 逻辑回归 |
| 线性回归用于使用给定的一组自变量来预测连续因变量。 | 逻辑回归用于使用给定的一组自变量来预测 0 和 1 形式的分类因变量。 |
| 它基于最小二乘估计方法。 | 它基于最大似然估计方法 |
| 这里不需要阈值。 | 这里需要阈值。 |
| 在线性回归中,要求因变量和自变量之间的关系必须是线性的。 | 因变量和自变量之间不需要具有线性关系。 |
| 在线性回归中,自变量之间存在共线性的可能性。 | 在逻辑回归中,自变量之间不应存在共线性。 |
面试问题的结论
感谢您的阅读。我希望你对出现在数据科学面试中充满信心。我希望你喜欢面试问题,并且能够测试你对数据科学和机器学习的了解。如果您有任何反馈或想分享您对这些评论的看法,请在下面的评论框中分享。
电子邮件:anurag8200@gmail.com
原文标题:Interview Questions to Test your Data Science Skills
原文作者:ANURAG SINGH CHOUDHARY
文章来源:https://www.analyticsvidhya.com/blog/2022/06/interview-questions-to-test-your-data-science-skills/
