




直方图介绍:
为了防止列分布不均带来SQL查询的性能问题对oracle产生严重的影响,oracle引入了直方图,它是一个详细描述列数据分布的特殊的列统计信息,实际存放在HISTGRM基表中,可通过DBA_TAB_HISTOGRAMS、DBA_PART_HISTOGRAMS、DBA_SUBPART_HISTOGRAMS来分别查看列直方图信息。oracle只对常用的目标列收集直方图信息,oracle默认为不常用的列不需要收集直方图信息,SQL中的谓词条件会存在SYS.COL_USAGE基表中,在执行DBMS_STATS包时首先先查询SYS.COL_USAGE$基表,只收集基表中有信息的列的直方图信息。
oracle直方图实际上是通过bucket(桶)的方式分别从ENDPOINT NUMBER和ENDPOINT VALUE两个维度来描述目标列的数据分布。分别对应DBA_TAB_HISTOGRAMS、DBA_PART_HISTOGRAMS、DBA_SUBPART_HISTOGRAMS中的ENDPOINT_NUMBER/BUCKET_NUMBER和ENDOINT_VALUE字段。还可通过DBA_TAB_COL_STATISTICS、DBA_PART_COL_STATISTICS和DBA_SUBPART_COL_STATISTICS查询bucket总数。
ENDPOINT NUMBER是直方图中bucket的编号,由DBMS.STATS包中的METHOD_OPT参数中的size控制buckets的数量(默认为254),在oracle11g中规定该值不能大于254。
ENDPOINT VALUE是直方图bucket的结束点,CBO可通过该值来准确计算目标结果集在目标列中的selectivity。
通过以下实例可以明显看到直方图信息对统计信息的影响:
ID COUNT(*) ---------- ---------- 1 1 10 1000复制
我们可以发现REN_TEST已经出现了严重的列倾斜,不收集直方图收集统计信息,可以查看执行计划:
TEST@PROD1> select count(*) from ren_test where id=1; Execution Plan ---------------------------------------------------------- Plan hash value: 3666266488 ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 3 | 1 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 3 | | | |* 2 | INDEX RANGE SCAN| IND_ID | 501 | 1503 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=1) Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 422 bytes sent via SQL*Net to client 419 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed复制
可以看到此处的Cardinality为501,这明显是不对的,结果应为1,这个错误的执行计划产生的结果就是在列倾斜的情况下没有直方图信息CBO估算产生的,由于没有直方图信息,where条件ID列的selectivity是1/2,故该执行计划的Cardinality为501.
计算结果为:
TEST@PROD1> select round(1001*(1/2))from dual; ROUND(1001*(1/2)) ----------------- 501复制
收集直方图信息后再次查看执行计划,发现此时已经是一个实际的值了。
TEST@PROD1>exec dbms_stats.gather_table_stats('test','ren_test',estimate_percent=>100,method_opt=>'for all columns size 245'); TEST@PROD1> select count(*) from ren_test where id=1; Execution Plan ---------------------------------------------------------- Plan hash value: 3666266488 ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 3 | 1 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 3 | | | |* 2 | INDEX RANGE SCAN| IND_ID | 1 | 3 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=1) Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 422 bytes sent via SQL*Net to client 419 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed复制
直方图类型:
在oracle 12c之前oracle直方图类型为Frequency和Height Balanced两种类型(在oracle 12c中为了解决Height Balanced不准确引起的oracle性能问题而引入了Top-Frequency和Hybrid类型的直方图)。在oracle11g中如果目标列NUM_DISTINCT值的数量小于设定的Bucket的数量则使用Frequency类型直方图,若目标列distinct值的数量大于Bucket的数量则使用Height Balanced类型直方图。在oracle12c以后DBMS_STATS包的METHOD_OPT参数引入了AUTO_SAMPLE_SIZE参数(默认是TRUE),目标列NUM_DISTINCT大于设定的Bucket的数量时满足一定条件会自动转换成Top-Frequency或Hybrid类型的直方图。
①Frequency类型直方图
Frequency类型的直方图要求直方图的Bucket数量等于目标列NUM_DISTINCT值的数量,即每一个NUM_DISTINCT对应一个bucket,CBO在选择执行计划时只需直接扫描bucket就可很直观的找到目标值,但是在oracle11g中对于Bucket数量的限制为254,超过这个值或者NUM_DISTINCT大于收集直方图时设定的bucket数量就必须用height Balanced类型的直方图,这就是之前讨论的12c之前版本CBO的一个缺陷问题。但是这个问题在12c以后的版本中得到解决,12c新引入了Top-Frequency和Hybrid两种类型的直方图。
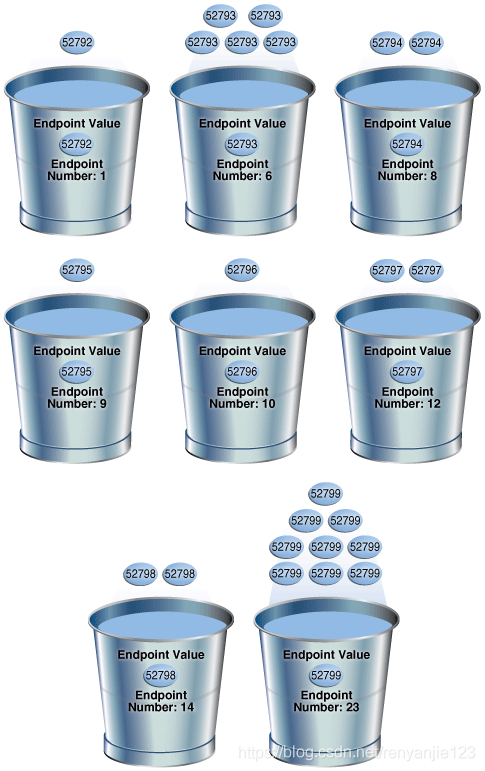
SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE FROM USER_HISTOGRAMS WHERE TABLE_NAME='COUNTRIES' AND COLUMN_NAME='COUNTRY_SUBREGION_ID'; ENDPOINT_NUMBER ENDPOINT_VALUE --------------- -------------- 1 52792 6 52793 8 52794 9 52795 10 52796 12 52797 14 52798 23 52799复制
frequency类型的直方图bucket和数据的存放方式如下图所示,由于frequency类型直方图要求NUM_DISTINCT<Bucket,所以为一比一存放。当select指定数据时,oracle会首先找到目标数据的ENDPOINT_VALUE和ENDPOINT_NUMBER,然后减去上一个ENDPOINT_NUMBER对应的ENDPOINT_VALUE,可以很精确的计算出分布不均数据的selectivity,选择正确的执行计划。但是由于frequency类型直方图特殊的要求(NUM_DISTINCT<254)故还存在一下的直方图类型。
通过以下实例也验证了之前讨论的结果,对于直方图会截取目标列的前32个字符(实际上是15个字符)转换成一个浮点数(ENDPOINT_ACTUAL_VALUE),在下面例子中Distinct values和number Buckets的值均为1,CBO默认name列值一样,产生的执行计划Cardinality也为4。
TEST@PROD1> create table t1(id number,name varchar2(50)); TEST@PROD1> insert into t1(name) values('0000000000000000000000000000000000000001'); TEST@PROD1> insert into t1(name) values('0000000000000000000000000000000000000002'); TEST@PROD1> insert into t1(name) values('0000000000000000000000000000000000000003'); TEST@PROD1> insert into t1(name) values('0000000000000000000000000000000000000003'); TEST@PROD1> commit; TEST@PROD1> select name,count(name) from t1 group by name; NAME COUNT(NAME) -------------------------------------------------- ----------- 0000000000000000000000000000000000000002 1 0000000000000000000000000000000000000003 2 0000000000000000000000000000000000000001 1 TEST@PROD1> exec dbms_stats.gather_table_stats('test','t1',estimate_percent=>100,method_opt=>'for columns name size auto'); TEST@PROD1> select owner,table_name,column_name,num_distinct,density,num_buckets,histogram from dba_tab_col_statistics where table_name='T1'; Table Column Distinct Number OWNER Name Name Values Density Buckets HISTOGRAM ------------------------------ --------------- ------------------------- ------------ ------- ------- --------------- TEST T1 NAME 1 0 1 FREQUENCY TEST T1 ID 0 0 0 NONE TEST@PROD1> select * from DBA_TAB_HISTOGRAMS where owner='TEST' and table_name='T1'; Table Column OWNER Name Name ENDPOINT_NUMBER ENDPOINT_VALUE ENDPOINT_ACTUAL_VALUE ------------------------------ --------------- ------------------------- --------------- -------------- -------------------------------- TEST T1 NAME 4 2.5021E+35 00000000000000000000000000000000 发现此时oracle认为这几个值是一样的,在进行查询的时候结果集为4。 此时的执行计划为: TEST@PROD1> select * from t1 where name='0000000000000000000000000000000000000003'; Execution Plan ---------------------------------------------------------- Plan hash value: 3617692013 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 4 | 164 | 3 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| T1 | 4 | 164 | 3 (0)| 00:00:01 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("NAME"='0000000000000000000000000000000000000003') Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size 590 bytes sent via SQL*Net to client 419 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2 rows processed复制
②Height Balanced类型直方图
在Height Balanced类型的直方图的selectivity和Cardinality的计算更为复杂,随着数据库版本不同也不同。
1>查询条件输入值是popular value:
Cardinality = NUM_ROWS * selectivity
selectivity = (Buckets_this_popular_value / Buckets_total) * Null_Adjust
Null_Adjust = (NUM_ROWS - NUM_NULLS) / NUM_ROWS
注:Buckets_this_popular_value:popular value所占bucket的数量。
Buckets_total:bucket的总数。
2>查询条件输入值nonpopular value:
A.oracle version <10.2.0.4(不含10.2.0.4,10.2.0.1)
Cardinality = NUM_ROWS * selectivity
selectivity = OldDensity * Null_Adjust
Null_Adjust = (NUM_ROWS - NUM_NULLS) / NUM_ROWS
OldDensity = SUM(NP.COUNT(i) * NP.COUNT(i)) / ((NUM_ROWS-NUM_NULLS) * SUM(NP.COUNT(i)))
注:OldDensity:CBO实际计算可选择率和结果集的Cardinality。
OldDensity:存储在DBA_TAB_STATISTICS、DBA_PART_TAB_STATISTICS、DBA_SUBPART_TAB_STATISTICS数据字典中的density字段。
NP.COUNT(i):每个nonpopular value在目标表中的记录数。
B.oracle version = 10.2.0.1
Cardinality = NUM_ROWS * selectivity
selectivity = OldDensity * Null_Adjust
Null_Adjust = (NUM_ROWS - NUM_NULLS) / NUM_ROWS
OldDensity = SUM(DV.COUNT(i) * DV.COUNT(i)) / ((NUM_ROWS-NUM_NULLS) * SUM(DV.COUNT(i)))
注:OldDensity:CBO实际计算可选择率和结果集的Cardinality。
OldDensity:存储在DBA_TAB_STATISTICS、DBA_PART_TAB_STATISTICS、DBA_SUBPART_TAB_STATISTICS数据字典中的density字段。
DV.COUNT(i):目标列的每个distinct值在目标中的记录数。
C.oracle version >10.2.0.4(含10.2.0.4)
Cardinality = NUM_ROWS * selectivity
selectivity = NewDensity * Null_Adjust
Null_Adjust = (NUM_ROWS - NUM_NULLS) / NUM_ROWS
NewDensity = (Buckets_total - Buckets_all_popular_value) / Buckets_total / (NDV-popular_values.COUNT)
OldDensity = SUM(NP.COUNT(i) * NP.COUNT(i)) / ((NUM_ROWS-NUM_NULLS) * SUM(NP.COUNT(i)))
DNV = NUM_DISTINCT
注:NewDensity:CBO实际计算可选择率和结果集的Cardinality。
OldDensity:存储在DBA_TAB_STATISTICS、DBA_PART_TAB_STATISTICS、DBA_SUBPART_TAB_STATISTICS数据字典中的density字段。
Buckets_all_popular_value :所有的 popular value所占用的bucket数量。
Buckets_total:bucket总数。
popular_values.COUNT:popular value的个数。
NP.COUNT(i):每个nonpopular value在目标表中的记录数。
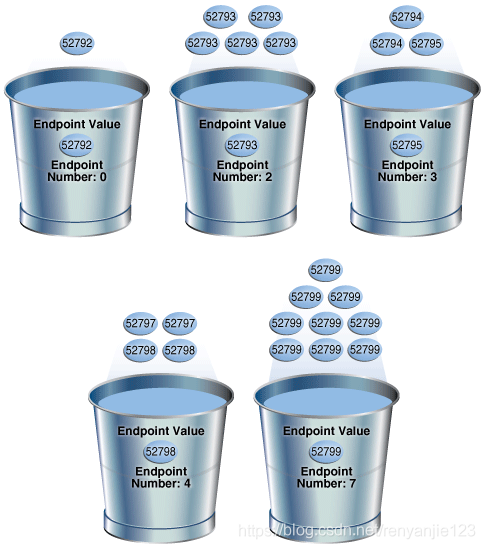
目标列中的popular_value:简单的说就是目标列出现频率较多的值,例如下图中的52793。nopopular_value:目标列出现频率低的值,例如下图中的52792。在Height Balanced类型的直方图中完全忽略了nopopular_value值,如下图,将nopopular_value和popular_value存放在一起,由于NUM_DISTINCT>Bucket所以height Balanced类型的直方图bucket和数据存放形式如下图所示,oracle会自动将数据随机存放(即存在一个popular_value值存在不同的bucket中),这样的存放会影响 CBO对bucket的计算和寻找,影响oracle的性能。
SELECT COUNT(country_subregion_id) AS NUM_OF_ROWS, country_subregion_id FROM countries GROUP BY country_subregion_id ORDER BY 2; NUM_OF_ROWS COUNTRY_SUBREGION_ID ----------- -------------------- 1 52792 5 52793 2 52794 1 52795 1 52796 2 52797 2 52798 9 52799 SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE FROM USER_HISTOGRAMS WHERE TABLE_NAME='COUNTRIES' AND COLUMN_NAME='COUNTRY_SUBREGION_ID'; ENDPOINT_NUMBER ENDPOINT_VALUE --------------- -------------- 0 52792 2 52793 3 52795 4 52798 7 52799复制
通过下面一个例子可以很明显的看到11g对frequency类型的直方图bucket的限制是254,若bucket个数超过这个值则直方图类型自动转换为Height Balanced类型。
TEST@PROD1> create table t2(id number);--插入一定数据出现列倾斜,并保证distinct为254 TEST@PROD1> select count(distinct id) from t2; COUNT(DISTINCTID) ----------------- 254 TEST@PROD1> exec dbms_stats.gather_table_stats('TEST','T2',method_opt=>'for columns id size auto' ,cascade=>true); 可以看到当前直方图distinct为254,bucket为254,类型为FREQUENCY。 TEST@PROD1> select owner,table_name,column_name,num_distinct,density,num_buckets,histogram from dba_tab_col_statistics where table_name='T2'; Table Column Distinct Number OWNER Name Name Values Density Buckets HISTOGRAM ------------------------------ --------------- ------------------------- ------------ ------- ------- --------------- TEST T2 ID 254 0 254 FREQUENCY 再插入一行: TEST@PROD1> insert into t2 values(255); TEST@PROD1> commit; TEST@PROD1> exec dbms_stats.gather_table_stats('TEST','T2',method_opt=>'for columns id size auto' ,cascade=>true); 可以看到insert 一行后distinct为255,大于254后直方图类型变为HEIGHT BALANCED。 TEST@PROD1> select owner,table_name,column_name,num_distinct,density,num_buckets,histogram from dba_tab_col_statistics where table_name='T2'; Table Column Distinct Number OWNER Name Name Values Density Buckets HISTOGRAM ------------------------------ --------------- ------------------------- ------------ ------- ------- --------------- TEST T2 ID 255 0 254 HEIGHT BALANCED复制
在oracle12c中引入了Top-Frequency和Hybrid类型的直方图:
③Top-Frequency类型的直方图:
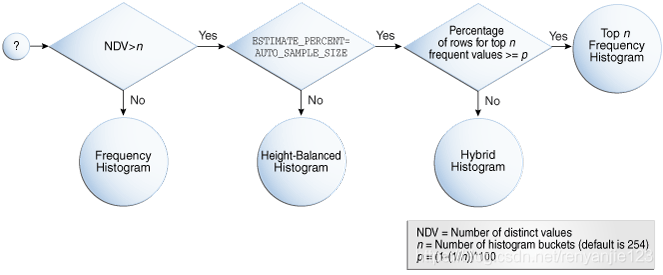
Top-Frequency类型的直方图会忽略统计上无关紧要的nopopular_values值,在oracle12c中用NDV(number for distinct values)代表NUM_DISTINCT,n代表收集直方图信息时指定的bucket数量(默认是254),p表示能否触发此类型直方图的一个阈值,在oracle12c以后的版本中,NUM_DISTINCT>n and ESTIMATE_PERCENT=AUTO_SAMPLE_SIZE and SELECT_NUM>=p时则会产生Top-Frequency类型的直方图。NUM_DISTINCT>n and ESTIMATE_PERCENT=AUTO_SAMPLE_SIZE and SELECT_NUM < p时产生Hybrid类型的直方图。
p=(1-(1/n))*100
SELECT_NUM=select_number/totol_number
在oracle12c以后默认ESTIMATE_PERCENT值为auto,当NUM_DISTINCT>n时只要满足SELECT_NUM>=p就可以使用Top-Frequency类型的直方图,即忽略部分无关紧要的nopopular_values使忽略后的NUM_DISTINCT=Bucket,忽略部分nopopular_value值的列实际值和bucket一对一存放。这种存放方式的直方图就是Top-Frequency直方图。
SELECT country_subregion_id, count(*) FROM sh.countries GROUP BY country_subregion_id ORDER BY 1; COUNTRY_SUBREGION_ID COUNT(*) -------------------- ---------- 52792 1 52793 5 52794 2 52795 1 --忽略次popular_values 52796 1 52797 2 52798 2 52799 9 SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE FROM USER_HISTOGRAMS WHERE TABLE_NAME='COUNTRIES' AND COLUMN_NAME='COUNTRY_SUBREGION_ID'; ENDPOINT_NUMBER ENDPOINT_VALUE --------------- -------------- 1 52792 6 52793 8 52794 9 52796 11 52797 13 52798 22 52799复制
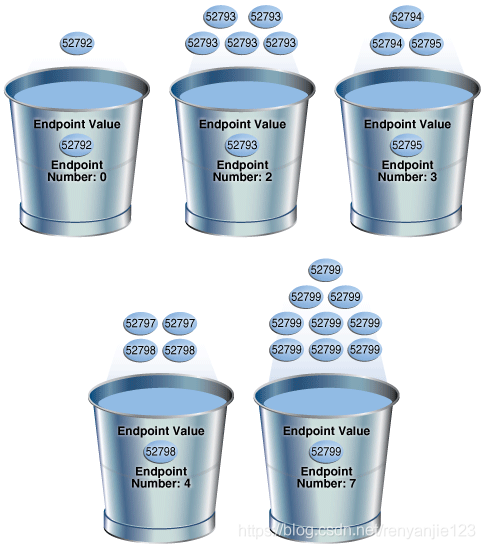
④Hybrid类型的直方图
Hybrid类型的直方图结合了Frequency和Height Balanced类型直方图的优点,Height Balanced类型的直方图允许一个值存在多个bucket中,这对CBO估算成本带来了误判,Hybrid利用端点重复计的方式防止了一个值存在多个bucket的可能性。端点重复计就是首先对目标值根据bucket数量进行初始排序,然后oracle优化器会找到桶的边界然后向前找到不同的值,如此反复将相同的值存放在同一个bucket中。这就是Hybrid类型的直方图
oracle中选择直方图的顺序如下,根据目标列的实际情况会自动选择不同类型的直方图(12c or later):
直方图收集方法:
①所有索引列自动收集直方图
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>‘HR’,TABNAME=>‘EMPLOYEES’,METHOD_OPT=>‘FOR ALL INDEXED COLUMNS SIZE AUTO’);
②指定列收集直方图
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>‘HR’,TABNAME=>‘EMPLOYEES’,METHOD_OPT=>‘FOR COLUMNS SIZE AUTO EMPLOYEE_ID SALARY’);
③指定列收集直方图,指定Bucket数量。
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>‘HR’,TABNAME=>‘EMPLOYEES’,METHOD_OPT=>‘FOR COLUMNS EMPLOYEE_ID SIZE 5 SALARY SIZE 10’);
④删除数据字典中某个表指定列上的直方图信息。
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>‘HR’,TABNAME=>‘EMPLOYEES’,METHOD_OPT=>'FOR COLUMNS EMPLOYEE_ID SIZE 1);
⑤删除数据字典中某个表的直方图信息
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>‘HR’,TABNAME=>‘EMPLOYEES’,METHOD_OPT=>'FOR ALL COLUMNS SIZE 1);
直方图对CBO的影响:
①直方图在shared cursor的影响
对于目标列收集直方图后,where中的谓词条件就被认为是一个“不安全”的谓词,这里“不安全”是指施加等值条件之后产生的执行计划不同,这一点我们能够理解,本来目标列分布不均匀才会收集直方图信息,那么不同的谓词会产生不同执行计划,相反如果选用主键列为目标列那么产生的执行计划一定是一样的,因为该列分布均匀不需要收集直方图信息。
此处“不安全”的谓词条件产生的副作用就是:当cursor_sharing值设置为similar后,本来是想使用绑定变量来替换where后面的具体值,只产生一个执行计划来提升效率,但是如果该列上有直方图信息就会导致每一个值都会产生一个child cursor,即硬解析。
通过以下实例可以明显看到直方图对cursor的影响,首先先看下不使用直方图和游标的结果。
TEST@PROD1> select id,name,count(id) from ren_test group by id,name; ID NAME COUNT(ID) ---------- ---------- ---------- 1 A 100 100 B 500 10 CAP 1000 TEST@PROD1> exec dbms_stats.gather_table_stats('test','ren_test',method_opt=>'for columns name size 1'); TEST@PROD1> show parameter cursor_sharing; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ cursor_sharing string EXACT TEST@PROD1> select /*+ cursor_sharding_exact_demo */ count(*) from ren_test where name='A'; COUNT(*) ---------- 100 TEST@PROD1> select /*+ cursor_sharding_exact_demo */ count(*) from ren_test where name='CAP'; COUNT(*) ---------- 1000 TEST@PROD1> select /*+ cursor_sharding_exact_demo */ count(*) from ren_test where name='B'; COUNT(*) ---------- 500 TEST@PROD1> select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select /*+ cursor_sharding_exact_demo */%'; SQL_TEXT SQL_ID VERSION_COUNT ---------------------------------------------------------------------------------------------------- ------------- ------------- select /*+ cursor_sharding_exact_demo */ count(*) from ren_test where name='CAP' 6y23fhj32s5pc 1 select /*+ cursor_sharding_exact_demo */ count(*) from ren_test where name='B' 8p8yjgrmvt9mz 1 select /*+ cursor_sharding_exact_demo */ count(*) from ren_test where name='A' 49rk5y1xnbsd8 1复制
通过以上验证可以看到在不使用直方图和游标的情况下三条select产生三个parent cursor,这很容易被理解,CBO认为这是三条不同的语句,的确在不使用绑定变量的情况下这的确是三条不一样的SQL,所以在生产中此类型的业务需求需使用绑定变量来降低性能消耗,下面使用cursor来看在有直方图的前提下的结果。
TEST@PROD1> exec dbms_stats.gather_table_stats('test','ren_test',method_opt=>'for columns name size auto',cascade=>true); PL/SQL procedure successfully completed. TEST@PROD1> select owner,table_name,column_name,num_distinct,density,num_buckets,histogram from dba_tab_col_statistics where table_name='REN_TEST'; OWNER TABLE_NAME COLUMN_NAME NUM_DISTINCT DENSITY NUM_BUCKETS HISTOGRAM ---------- ------------------------------ ------------------------------ ------------ ---------- ----------- --------------- TEST REN_TEST NAME 3 .0003125 3 FREQUENCY TEST REN_TEST ID 3 .333333333 1 NONE TEST@PROD1> alter system set cursor_sharing='SIMILAR'; System altered. TEST@PROD1> show parameter cursor_sharing; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ cursor_sharing string SIMILAR TEST@PROD1> select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name='A'; COUNT(*) ---------- 100 TEST@PROD1> select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name='CAP'; COUNT(*) ---------- 1000 TEST@PROD1> select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name='B'; COUNT(*) ---------- 500 TEST@PROD1> select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select /*+ cursor_sharding_similar_example */%'; SQL_TEXT SQL_ID VERSION_COUNT ---------------------------------------------------------------------------------------------------- ------------- ------------- select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name=:"SYS_B_0" 9wnd8qp7c931k 3 TEST@PROD1> select sql_text,sql_id,PLAN_HASH_VALUE,CHILD_NUMBER from v$sql where sql_text like 'select /*+ cursor_sharding_similar_example */%'; SQL_TEXT SQL_ID PLAN_HASH_VALUE CHILD_NUMBER ------------------------------------------------------------------------------------------ ------------- --------------- ------------ select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name=:"SYS_B_0" 9wnd8qp7c931k 2524500097 0 select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name=:"SYS_B_0" 9wnd8qp7c931k 2524500097 1 select /*+ cursor_sharding_similar_example */ count(*) from ren_test where name=:"SYS_B_0" 9wnd8qp7c931k 2524500097 2复制
由以上验证可发现已经使用了绑定变量,但是对应的VERSION_COUNT值为3,意味着一个parent cursor下有三个child cursor,这三条select全是硬解析,这是一个不正常的现象,正常情况下应只有一个child cursor,原因是name列上有了直方图信息,直方图会直接影响shared cursor能否被共享。
②直方图对selectivity的影响
直方图是oracle为了解决目标表列数据分布不均导致CBO选择执行计划不准确而引入的新特性,在目标列收集直方图之后会直接影响CBO估算selectivity和Cardinality,使CBO选择出贴近实际的执行计划。
使用注意事项:
①只对常用的出现列倾斜的目标列收集直方图信息,不常用的列不收集直方图信息。对于分布均匀的列收集会影响CBO选择正确的执行计划。
②根据上述讨论,直方图会影响shared cursor的共享使用,对于使用绑定变量的列不收集直方图信息。
③oracle自动收集统计信息作业中要注意对直方图信息的收集。
