排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
构建hudi数据湖集群环境
构建hudi数据湖集群环境
大数据研习社
2022-08-08
715
长按二维码关注
大数据领域必关注的公众号
1.
构建
hudi
数据湖集群环境
Hudi
数据湖相关组件依赖:
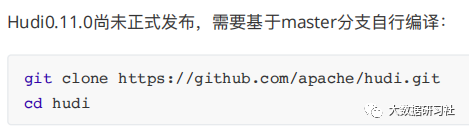
1.1 hudi
编译
1.
环境准备
2.
编译
(
1
)克隆源代码
(
2
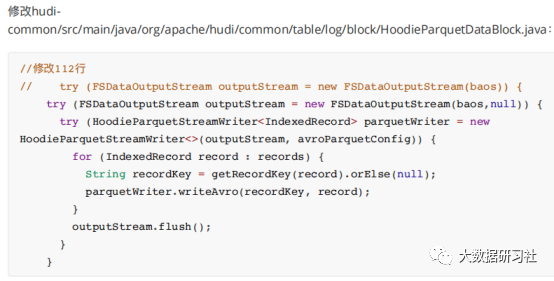
)适配
Hadoop
(
3
)编译
1.2
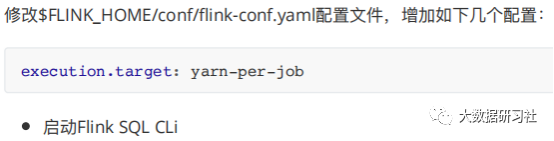
部署
Flink On YARN
1.
部署
Flink
2.Flink
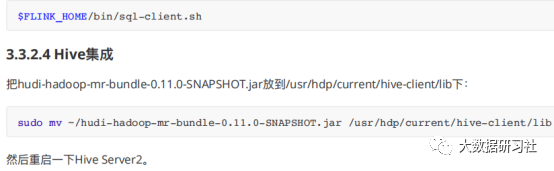
集成
hudi
3.
配置
Flink On YARN
1.3 hudi
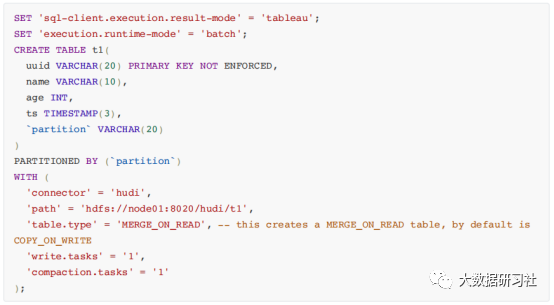
测试运行
1.
建
hudi
表
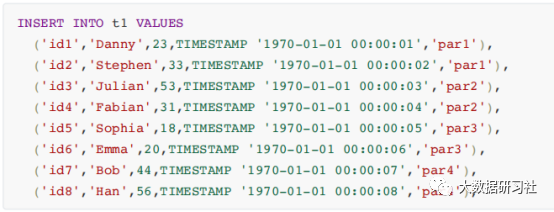
2.
插入数据
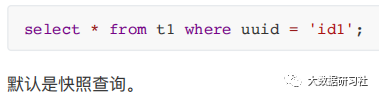
3.
快照查询
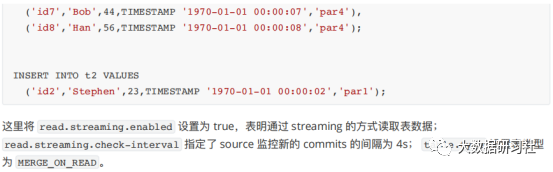
4.
更新数据
5.
流式查询
欢迎点赞 + 收藏 + 在看
素质三连
完
▼
往期精彩回顾
▼
程序员,如何避免内卷
Apache 架构师总结的 30 条架构原则
【全网首发】Hadoop 3.0分布式集群安装
大数据运维工程师经典面试题汇总(附带答案)
大数据面试130题
某集团大数据平台整体架构及实施方案完整目录
大数据凉凉了?Apache将一众大数据开源项目束之高阁!
实战企业数据湖,抢先数仓新玩法
Superset制作智慧数据大屏,看它就够了
Apache Flink 在快手的过去、现在和未来
华为云-基于Ambari构建大数据平台(上)
华为云-基于Ambari构建大数据平台(下)
【HBase调优】Hbase万亿级存储性能优化总结
【Python精华】100个Python练手小程序
【HBase企业应用开发】工作中自己总结的Hbase笔记,非常全面!
【剑指Offer】近50个常见算法面试题的Java实现代码
长按识别左侧二维码
关注领福利
领10本经典大数据书
hudi
大数据
apache
文章转载自
大数据研习社
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨