




在POSTGRESQL 的使用中,找到缺失的索引这个问题在维护POSTGRESQL 是一个重要的工作,在商业数据库中都有一些语句或工具可以直接给出一些添加索引的建议来帮助DB 人员快速的识别和建立相关的索引。PostgreSQL 在这方面有没有什么成熟的方案或办法。
首先网络上大部分的方案基于的都是系统表,并通过系统表来判断是否有缺失索引的问题,这样的方法的好处是通过现有的系统表就可以找到相关的信息,但是缺点也显而易见
1、找不到对应的SQL
2、给不出相关的索引建立的建议
https://www.dbrnd.com/2015/10/postgresql-script-to-find-a-missing-indexes-of-the-schema/
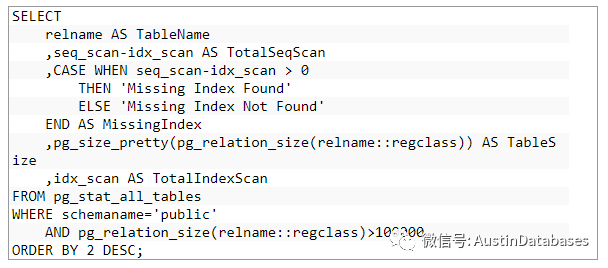
上面给出的语句就是大概率从网上搜到的语句和信息,首选我们先不说它能不能运行,我们先分析一下它大概的率的想法出发点是什么。pg_stat_all_tables表是 pg_stat_user_tables 和 pg_stat_sys_tables 两个表合成的统计表,其中包含如下的核心信息
表顺序扫描的次数,通过索引扫描这个表的次数以及通过索引进行定位查找的次数,以及表中的活跃行和死行的数量,和表是否被分析和被进行vacuum操作以及最后一次进行autovacuum操作的时间等等,和这张表在分析,vacuum,autovacuum 等次数。
上面的语句从语句的逻辑上进行分析,主要的逻辑就是如果表的查询中出现了不走索引的扫描的并且这样的情况高于搜索引的情况,则就判定为缺少索引。显然这样的逻辑是站不住脚的。
判断一个表是否缺少索引,需要有以下条件
1、表的行数的问题,表的行数应该超过一定的数量级,才能被判断需要走索引,或者有可能走索引,上面对于行的判断是没有的。
2、查询中一个表除了行数,还有查询的条件的问题,如果一个查询语句根本就没有条件,那么必然会产生全表扫描的问题,基于这个问题那么和缺少索引显然是无关的。
3、索引失效的问题,导致查询无法走索引,所以这个问题产生也和缺少索引无关
所以POSTGRESQL 中查询一个数据库表缺少索引的条件如果单从上面的表中获取,是不完全的。基于这个问题有两个方案
1、猜测法,通过完善上面的语句来猜测一个数据库的表可能缺少索引 ,当然这里可以通过完善相关的查询条件,来尽量定位的准确。
2、通过pg_qualstats + pg_stat_statements来完成更精确的查询缺失索引的定位并可以产生索引添加建议。
关于问题 2 之前是写过,如果需要可以从文字的最末尾,找到相关的连接。
所以问题2 的答案已经有了,那么就剩下如果我不想安装pg_qualstats 怎么来满足我猜测的工作的需求。
那么我们就先集中精力搞搞,第一个猜测的方案,实际上无论是国外的专家,还是国内的大云厂商都给这方面有一些建议,都挺好,这边在这些的基础上继续工作让准确性更高一些,也修复一些语句的问题。
1、先确认这个表中是否有索引,什么样的索引,索引的数量等先进行第一轮的判断
drop table index_missing;
CREATE TEMPORARY TABLE index_missing
(id serial primary key,
table_name varchar(200),
index_count smallint
);
hemaname in ('postgres_air') group by relname)
insert into index_missing (table_name,index_count) select pt.relname,it.countd
FROM pg_stat_all_tables pt
left join index_table as it on pt.relname = it.relname
where pt.schemaname in ('postgres_air');
select
id,
table_name,
index_count,
case
when index_count is null then 'no index there waring'
when index_count > 6 then 'please care abount the index numbers'
else 'OK'
end as comments
from index_missing复制
上面这段逻辑主要是
1、建立一个临时表,通过往临时表中插入分析的数据做中间结果
2、通过pg_stat_all_indexes 表来发现哪些表有从来没有建立过索引,那些表建立索引的数量。
3、最后将临时表和我们的pg_stat_all_tables 表的混合分析后的结果展示,给出一些提示性的语言展示。
下面是展示后的结果,这里大家可以根据自己的想法来调整,如schemaname, 和一些提示的数量上下限,这里就不过多介入了。
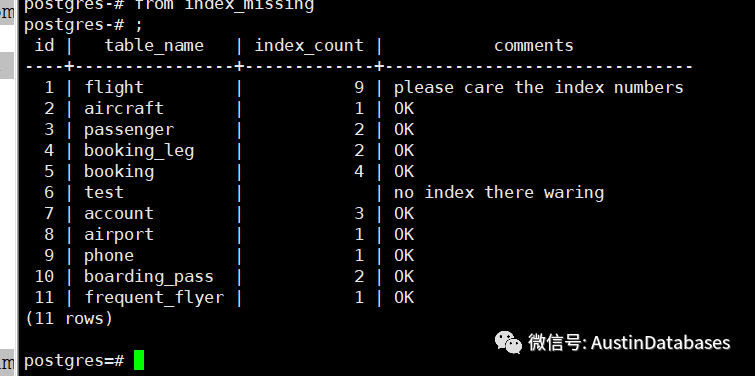
目的1 一个表到底有没有索引,索引的数量是否靠谱,这点上面的SQL 已经帮助完成了。
下面继续完成,针对一些大表的索引是否可能存在缺陷的问题进行解决。
首先我们先确认什么是大表,行数多的,我们认为一般是大表,另外查询次数多的我们也认为是“大表”。所以基于以上两个部分,我们可以设计出一个,小型的分析语句。
drop table analyze_table;
CREATE TEMPORARY TABLE analyze_table
(id serial primary key,
table_name varchar(200),
seq_scan int,
idx_scan int,
idx_tup_fetch int,
seq_tup_read int
);
insert into analyze_table (
table_name,
seq_scan ,
idx_scan ,
idx_tup_fetch ,
seq_tup_read
)select
relname,
seq_scan,
idx_scan,
idx_tup_fetch,
seq_tup_read
from pg_stat_user_tables as pt
where n_live_tup > 500000
and schemaname in ('postgres_air');
with analyze_table_result as
( select
table_name,
seq_scan,
idx_scan,
seq_tup_read,
idx_tup_fetch,
CASE
WHEN (seq_scan - idx_scan) < 100
THEN 'It is ok, I think that'::text
WHEN (seq_scan - idx_scan) >= 100 AND (seq_scan - idx_scan) < 1500
THEN 'please take care about'::text
WHEN (seq_scan - idx_scan) >= 1500
THEN 'please check it now'::text
ELSE NULL::text
END AS missing_index_comments
from analyze_table
)
select * from analyze_table_result;复制
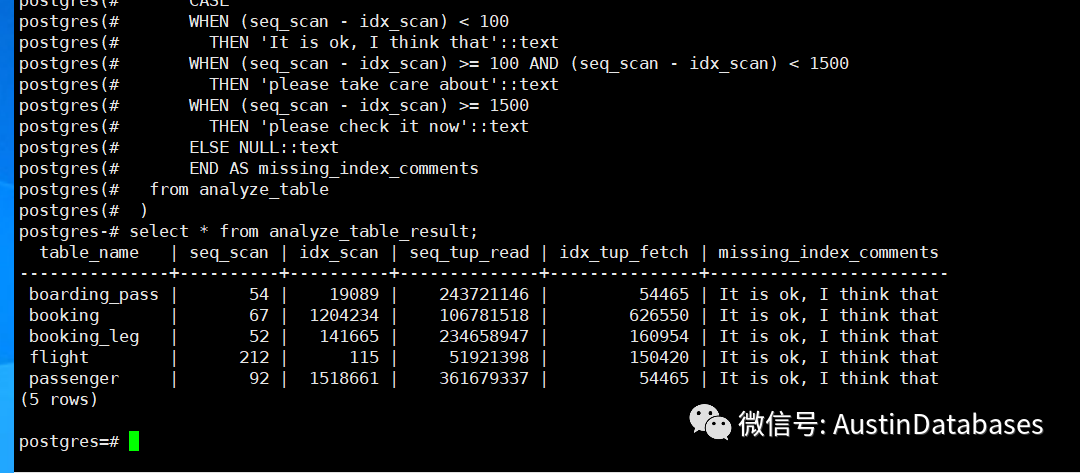
上面这段逻辑的实际上就是通过顺序扫描的次数与索引扫描的次数相比较通过不同的差异的数字来评判你的表到底是否缺不缺索引。实际上可以调整的位置主要集中在经验的部分,到底seq_scan 和 idx_scan 之间的差距多少,应该值得注意。上面的主要逻辑是,排除掉50万以下行的表,并且针对全表扫描和索引扫描的对比,来分析表是否缺不缺索引。
实际上,除此以外,我们还应该分析如下部分
1、表中是否有主键
2、表中是否有唯一索引
3、表中的索引大小
另外还有一个主要注意的就是索引的利用率,一个索引建立后是有相关的消耗的,我们希望的是索引建立后被使用,而不是不被使用。
下面的这个SQL 就是通过读取索引的使用的次数来分析当前的索引是否有利用率,如果数字很低,则说明索引得利用率不高,但是这也不能证明这个索引不应该被建立,如一个不经常使用了OLAP 的语句,但是在这里如果不建立相关的索引,这个语句将会引起十分严重的问题,所以需要建立。
SELECT
idstat.relname AS TABLE_NAME,
indexrelname AS index_name,
idstat.idx_scan AS index_scans_count,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size,
tabstat.idx_scan AS table_reads_index_count,
tabstat.seq_scan AS table_reads_seq_count,
tabstat.seq_scan + tabstat.idx_scan AS table_reads_count,
n_tup_upd + n_tup_ins + n_tup_del AS table_writes_count,
pg_size_pretty(pg_relation_size(idstat.relid)) AS table_size
FROM
pg_stat_user_indexes AS idstat
JOIN
pg_indexes
ON
indexrelname = indexname
AND
idstat.schemaname = pg_indexes.schemaname
JOIN
pg_stat_user_tables AS tabstat
ON
idstat.relid = tabstat.relid
WHERE
indexdef !~* 'unique'
ORDER BY
idstat.idx_scan DESC,
pg_relation_size(indexrelid) DESC;
``复制
到此为止针对索引的一些工作我们大致梳理了一下,同时对更精确命中MISSING INDEX 的工作大家可以看下方的提到了另一个方式。
同时这里还有一个放方式就是index_adviser ,这里就不在详述了。
如何自动找到缺失的索引
https://mp.weixin.qq.com/s?__biz=Mzg4NDA0NTEwNA==&mid=2247488921&idx=1&sn=16c5116fece5b1e77c10e29480232dc9&chksm=cfbf71c6f8c8f8d0732d6aca3169977611a2ad6f9f8180f1c542f3c7696bd4e17a09791fb921&token=507603249&lang=zh_CN#rd




