




之前看过很多根因定位的论文,大多数都是基于PC算法+随机游走,而这些论文上的算法很难落地。去了解很多大厂的解决方案之后,发现他们基本上都是基于专家规则做分类。下面介绍一下华为opengauss的AI4DB中的慢SQL根因定位时如何实现的。根据他的这种方案,我们可以推广到系统根因定位、日志系统的根因定位等。
慢SQL一直是数据运维中的痛点问题,如何有效诊断慢SQL根因是当前一大难题,工具结合openGauss自身特点融合了现网DBA慢SQL诊断经验,该工具可以支持慢SQL根因15+,能同时按照可能性大小输出多个根因并提供针对性的建议。
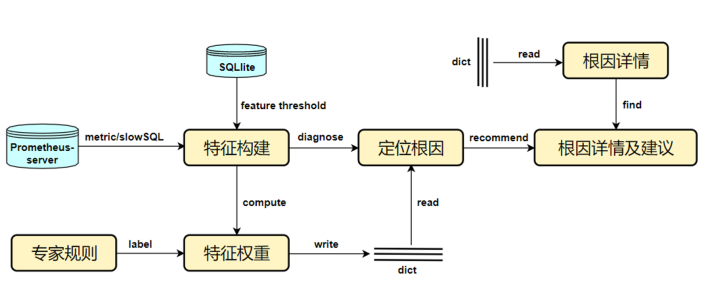
先来看一下数据流图:
参数配置
1:在misc/dbmind.config中设置detection_interval(检测的间隔),和last_detection_time(上次检测距离本次多久)。

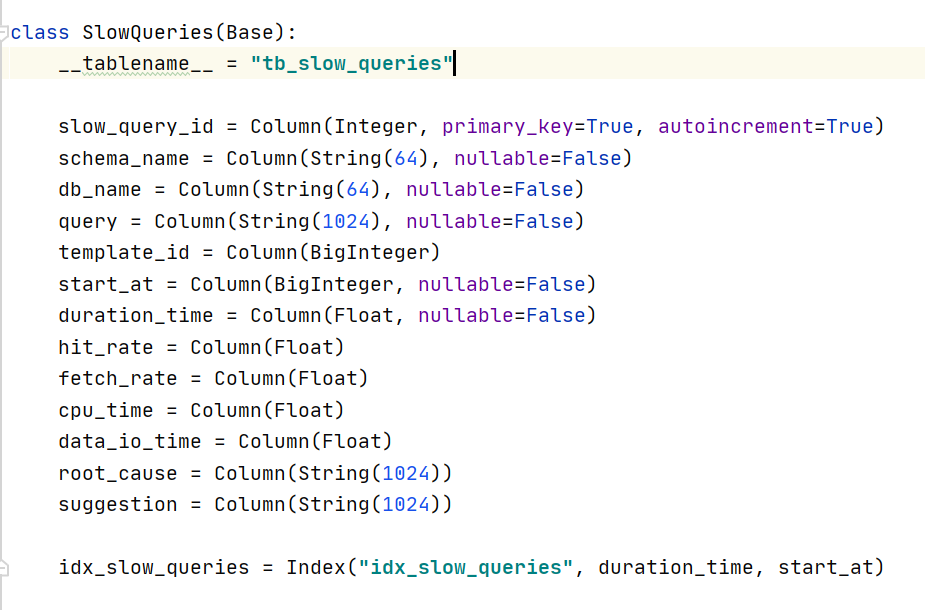
2:利用metadatabase/slow_queries.py在关系数据库中建立如下表,方便前端系统获取数据展示:
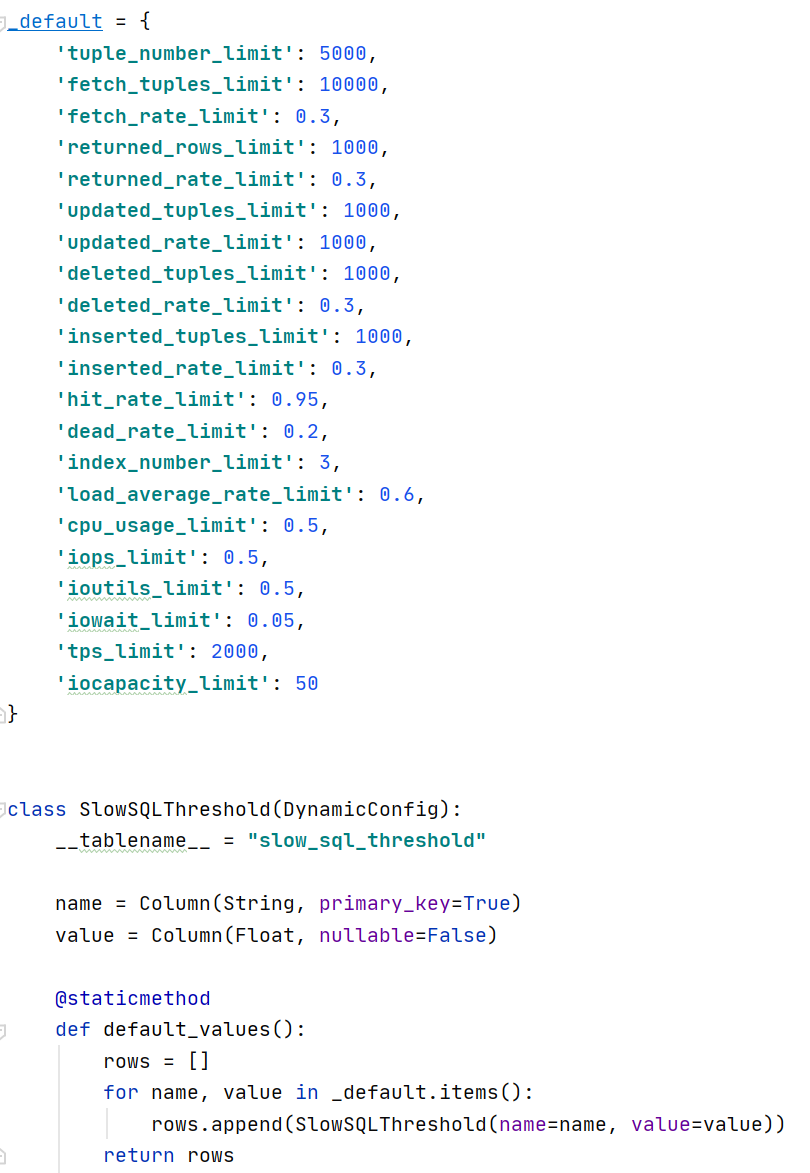
3:设置计算特征的阈值,也是在数据库建表,你也可以保存在文件中或固定的代码中:
4:模块启动时的其他参数

慢SQL和专家规则
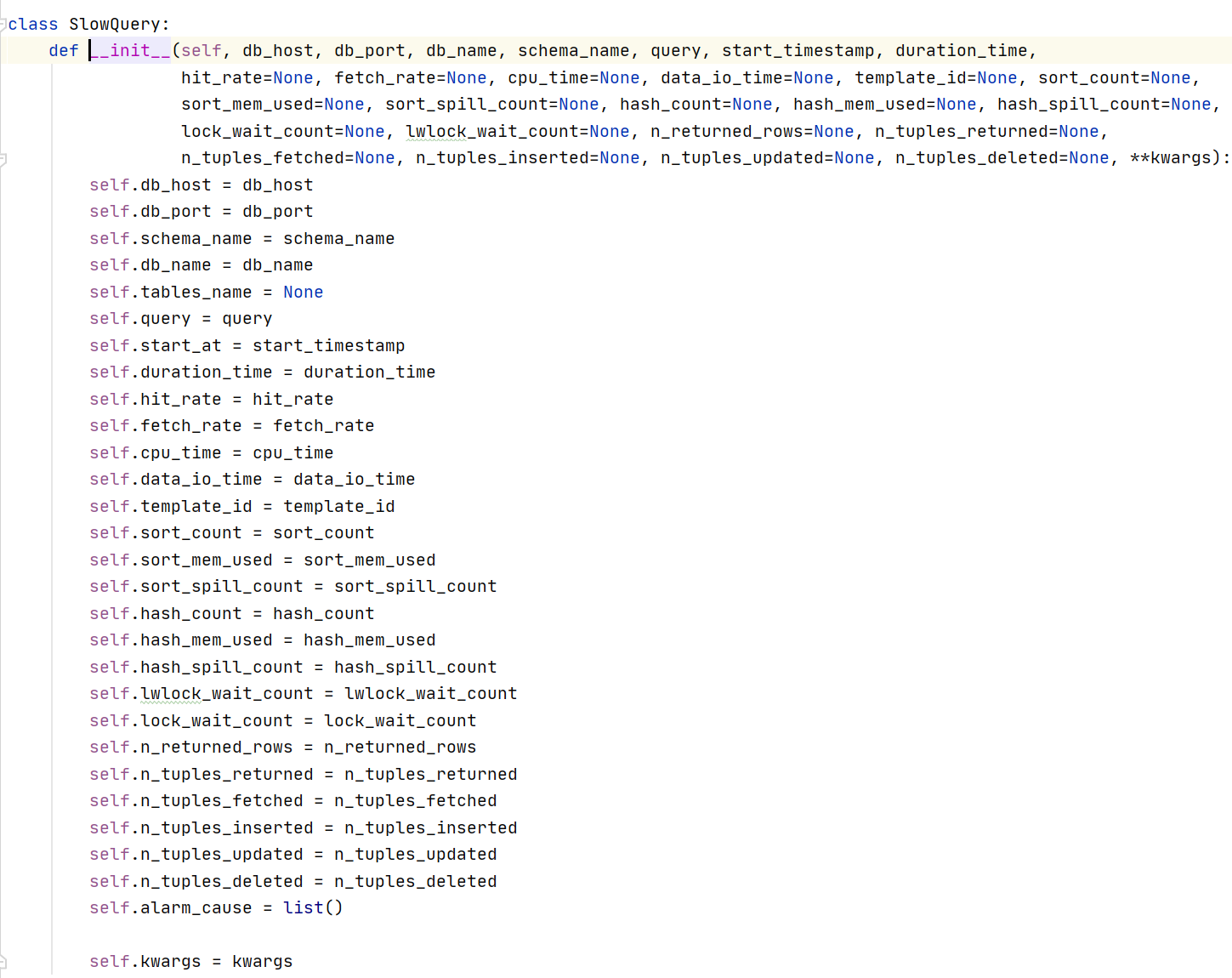
1:慢SQL类(common/types/misc.py)
2:根因类(common/types/root_cause.py)
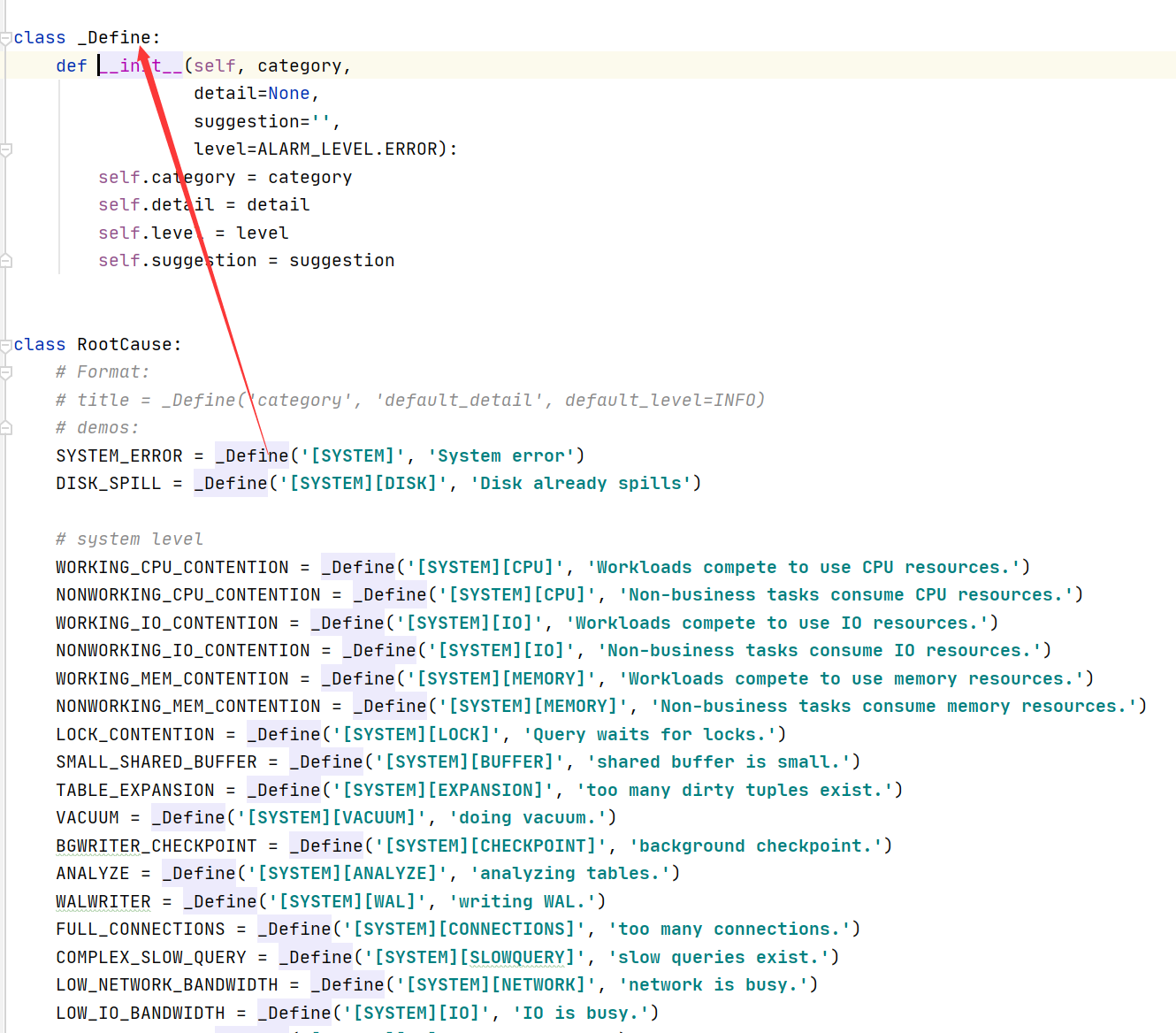
每个根因由四部分组成,分别是根因类别、根因细节、根因的建议、根因等级。
3:根因映射(slow_sql/featurelib/feature_mapping.py)
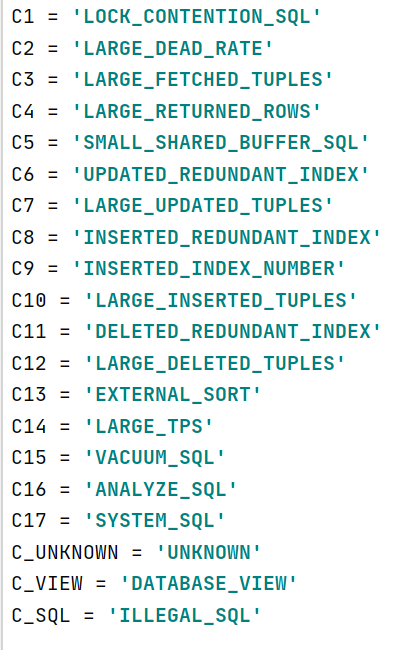
4:定义根因的规则(slow_sql/featurelib/features.py)
①:FEATURE_LIB[‘features’]

这是一个75*22的矩阵,行表示样本数可以是专家定义(针对一些根因,只需要一个特征被触发,前20个样本中大部分都是这样的)的也可以是历史慢SQL被打标签。列代表抽取出的慢SQL的特征。
②:FEATURE_LIB[‘labels’]

①中样本的标签,1到17对应于根因映射中分C1到C17,C1到C16只需要一个特征就能触发这些根因。
③:FEATURE_LIB[‘weight_matrix’]

这是一个17*22的矩阵,17代表根因数,22代表特征数,是由①中的features矩阵计算而来的,详细计算过程在slow_sql/featurelib/feature_model.py中的calculate_weight函数
定时任务
和趋势预测都是定时任务的脚本中app/timed_app.py
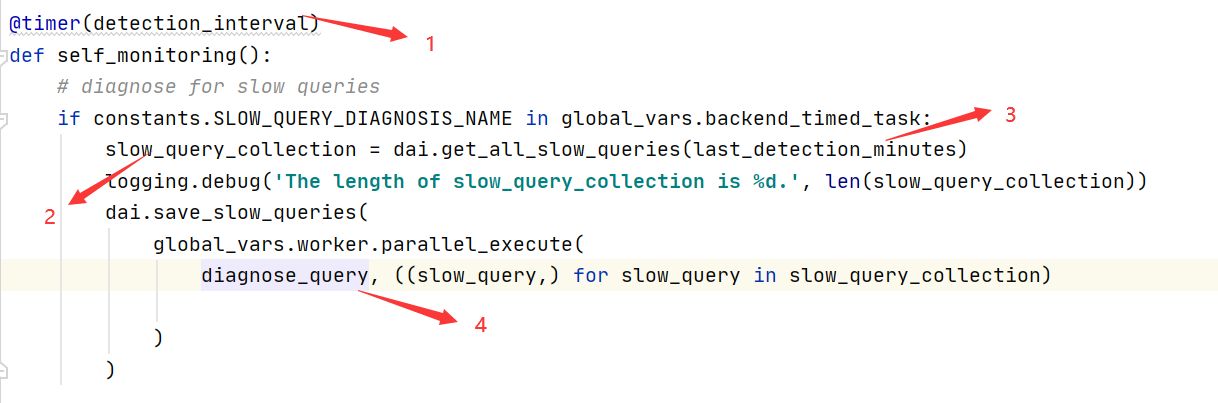
1:检测间隔
2:从prometheus获取最近时间(last_detection_time)的慢查询集合。
2:上次检测距离本次多久,last_detection_time转换为秒
3:慢查询诊断入口函数(并行检测)
模块入口
在app/diagnosis/query/init.py中(这个函数由上面的定时任务调用):
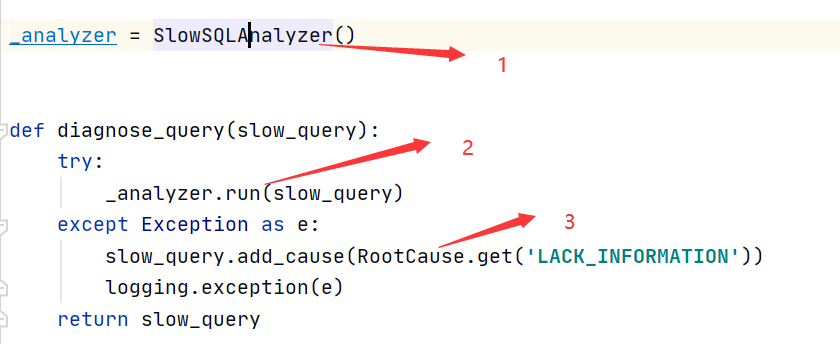
1:慢SQL诊断的核心类
2:入口函数,接下来我们会进入该函数进行详解
3:如果遇到异常,默认返回该根因
诊断的核心类SlowSQLAnalyzer
核心入口run()函数:
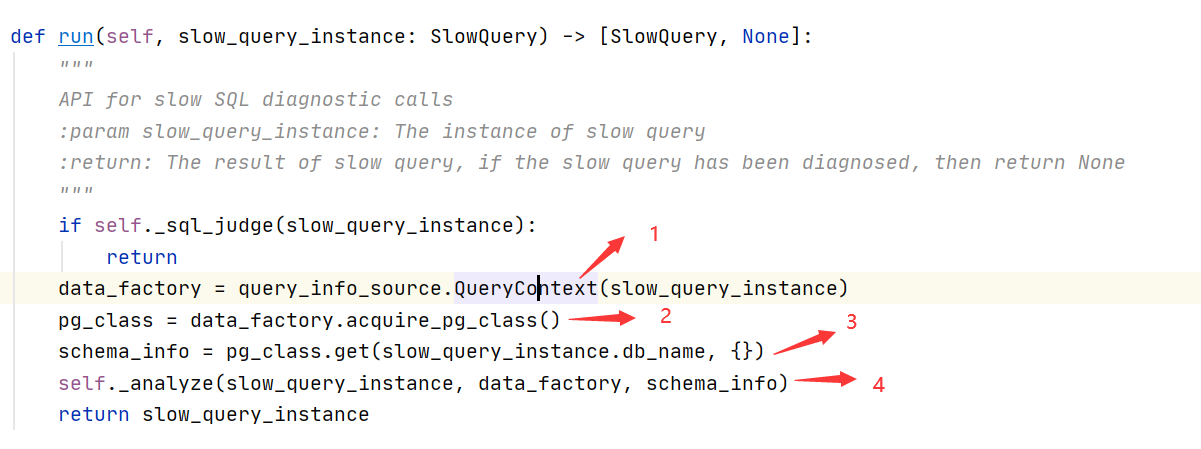
1:QueryContext是慢SQL对象的数据处理工厂类
2:从慢SQL获取数据库的相关信息:库、模式、表,以字典形式返回
3:从2返回的字典中获取schema信息,
4:诊断的核心函数,
核心函数_analyze():
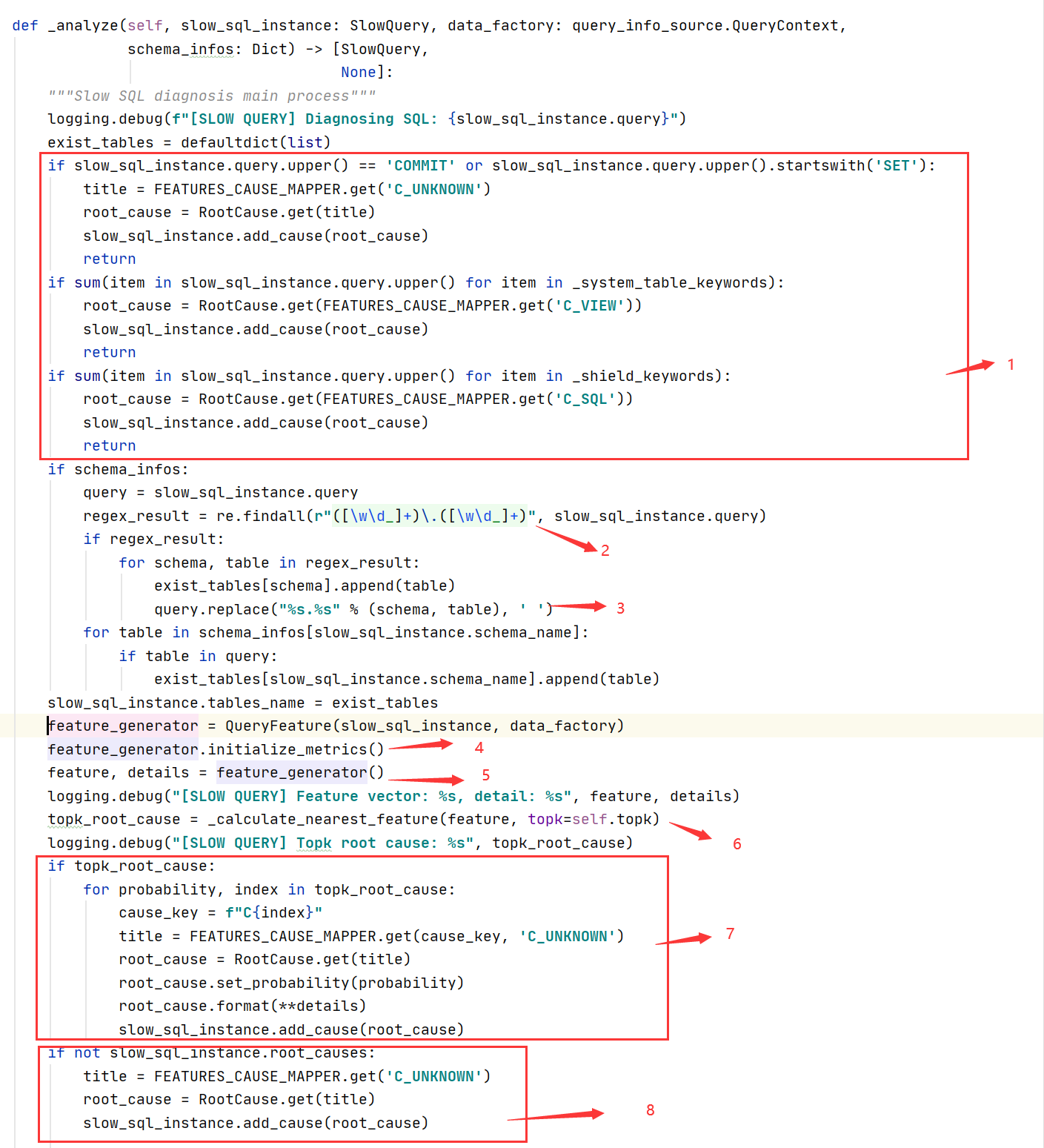
1:对一些特殊情况(commit或关键字)直接匹配指定的根因
2:正则找到所有SQL文本中所有schema.table,找到schmema和table
3:把所有的schema.table替换为空,是SQL文本成文SQL pattern
4:初始化各种类型的metrics(数据库、表结构、锁信息、系统信息)

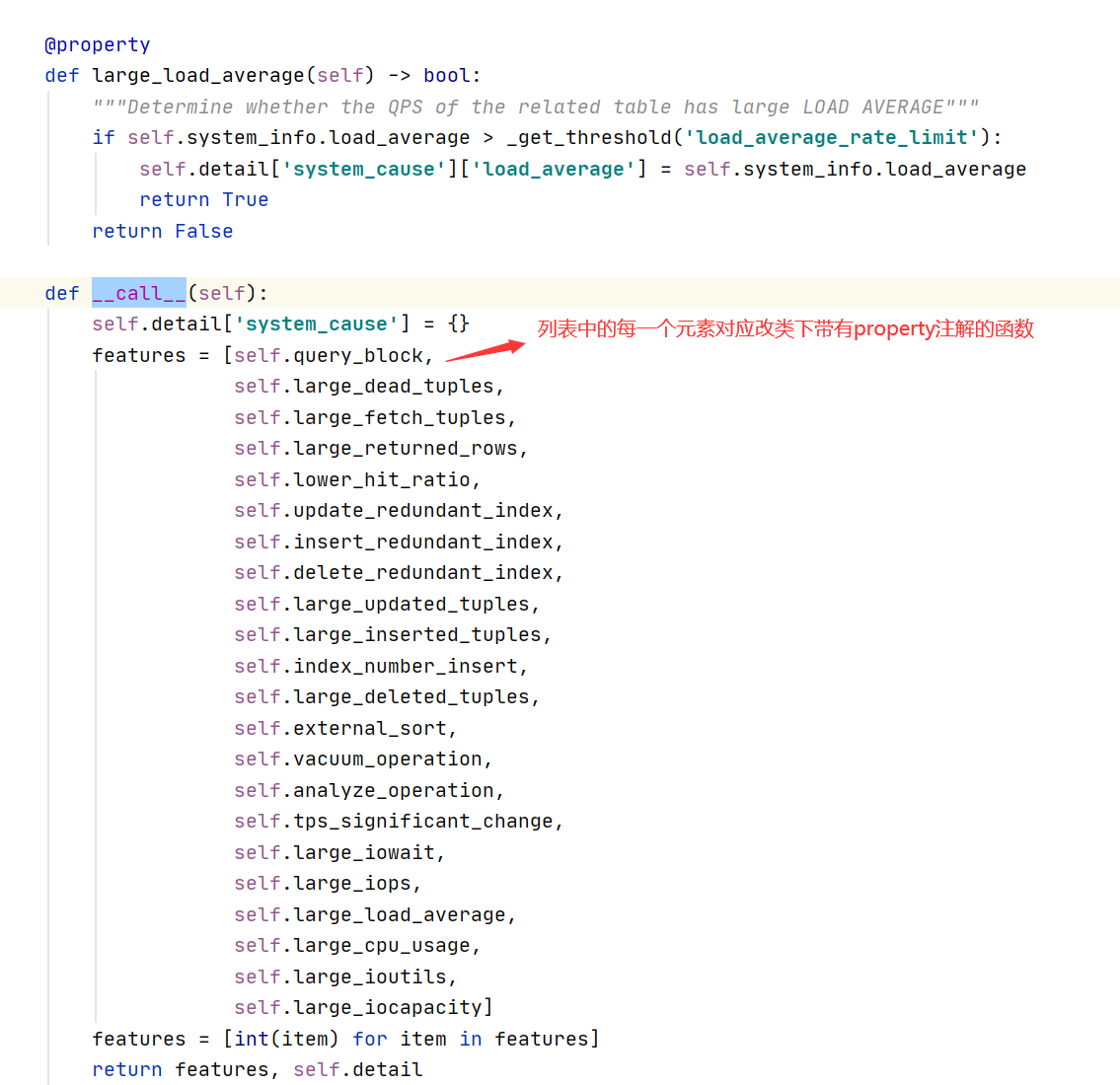
5:调用QueryFeature类的__call__函数,依次生成features列表中的每一个特征
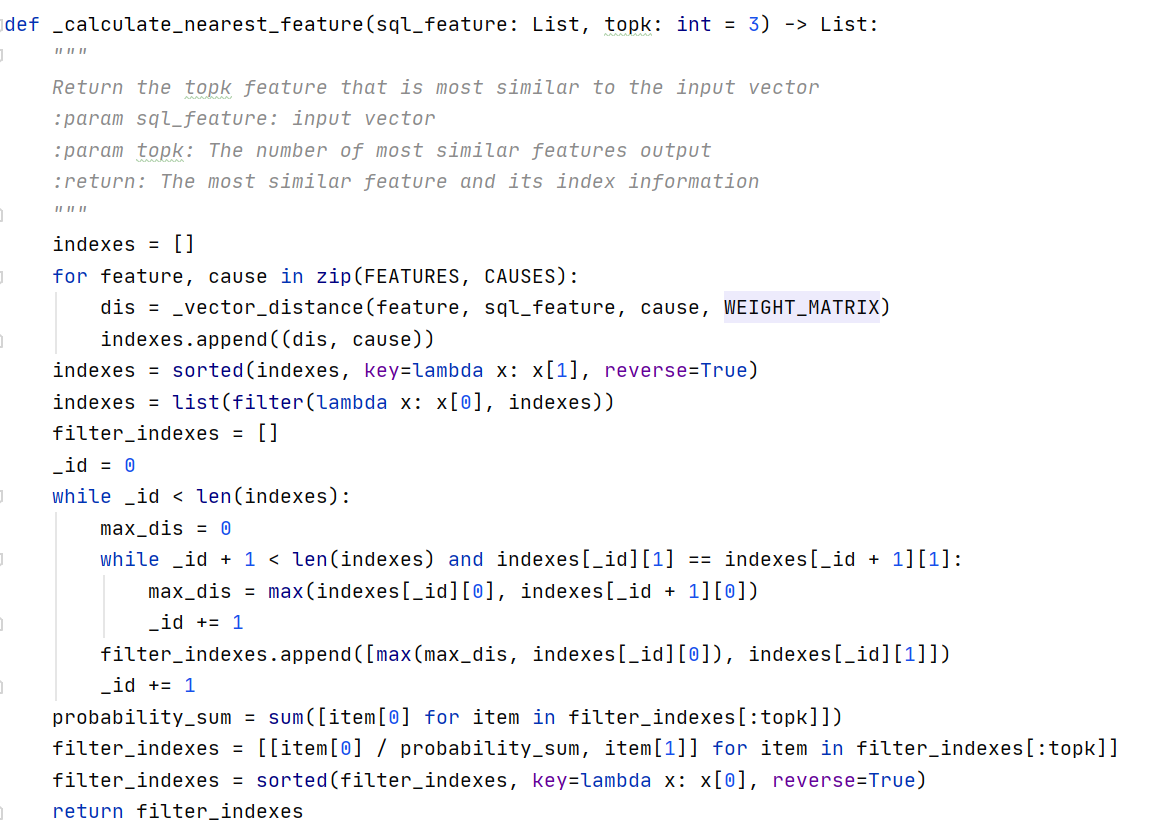
6:在第5步中生成的慢SQL根因和featurelib下的features.py下的权重矩阵计算距离,得到topk个最相似的根因
7:遍历根因封装到慢SQL对象的属性中
8:如果没有找到根因,以‘C_UNKNOW’根因返回
