




在这个迷你系列博客的第一部分中,我们介绍了如何设置PostgreSQL,以便我们可以使用TensorFlow(https://www.tensorflow.org/)在数据库服务器中使用pl/python3过程语言对数据进行回归分析。https://www.enterprisedb.com/blog/regression-analysis-postgresql-tensorflow-part-1-getting-started,
在第二部分,我们了解了如何在训练神经网络之前理解和预处理数据。
https://www.enterprisedb.com/blog/regression-analysis-postgresql-tensorflow-part-2-data-pre-processing
在第三部分,我们将使用我们准备和优化的数据来训练一个网络,然后使用它来分析数据——所有这些都来自于一个PostgreSQL数据库!
拆分数据
当我们完成博客系列的最后一部分时,我们有一组数据,我们从中删除了具有异常值的行和与结果相关性较差的列。现在需要将该数据集拆分为训练、验证和测试数据集,每个数据集的结果(或输出特征)都将与输入特征分开。这是通过计算每个所需的行数,将输入和输出分割成单独的 Pandas 数据帧,然后相应地将它们逐行分割来实现的:
# Figure out how many rows to use for training, validation and testtest_rows = int((actual_rows/100) * test_pct)validation_rows = int(((actual_rows)/100) * validation_pct)training_rows = actual_rows - test_rows - validation_rows# Split the data into input and outputinput = data[columns[:-1]]output = data[columns[-1:]]# Split the input and output into training, validation and test setstraining_input = input[:training_rows]training_output = output[:training_rows]validation_input = input[training_rows:training_rows+validation_rows]validation_output = output[training_rows:training_rows+validation_rows]test_input = input[training_rows+validation_rows:]test_output = output[training_rows+validation_rows:]# Make a note of the largest result valuemax_z = max(output[output.columns[0]])复制
从代码中可以看出,三组数据中每一组的大小由 test_pct
和validation_pct
变量决定,这两个变量决定了每个初始数据集使用的百分比。这里没有硬性规定——事实上,在我的测试代码中,这些值都被传递到 pl/python3 函数中,因此它们可以很容易地被覆盖。我给他们两个默认值 10%。您几乎肯定希望训练数据集比其他数据集大得多。
创建模型
模型或神经网络是一组具有可训练参数的过滤器层 - 您可能认为是神经元。这个模型有多层的事实意味着我们正在执行深度学习。
# Define the modelmodel = tf.keras.Sequential()model.add(tf.keras.layers.Dense(units=units,input_shape=(len(columns) - 1,),activation = 'relu'))for units in structure:model.add(tf.keras.layers.Dense(units=units, activation = 'relu'))model.add(tf.keras.layers.Dense(units=1, activation='linear'))# Compile itmodel.compile(loss=tf.keras.losses.MeanSquaredError(),optimizer='adam')summary = []model.summary(print_fn=lambda x: summary.append(x))plpy.notice('Model architecture:\n{}'.format('\n'.join(summary)))复制
首先,我们创建一个空模型,并添加一个密集层,其中包含与我们在数据中具有输入特征的相同数量的过滤器。
为了测试不同的模型配置,我的 pl/python3 函数将一维整数数组作为参数。对于数组中的每个元素,将添加指定数量的过滤器的额外密集层。
要添加的最后一层是包含单个过滤器的密集层;对应于我们试图预测的单个标量结果值。当然,您可能想要预测多个值,在这种情况下,结果数据集和模型的最后一层会更宽。重要的是输入层的过滤器数量与输入特征的数量相匹配,输出层的过滤器数量与输出特征的数量相匹配。
您会注意到每一层都指定了一个激活函数。在将值传递到下一层之前,将激活函数应用于过滤器的输出。ReLU(整流线性单元)用于允许对非线性函数进行建模,输出层上的简单线性函数用于生成最终输出。
定义模型后,我们将对其进行编译以进行训练。我们指定用于衡量损失的指标(模型执行的好坏)和学习优化器。我更喜欢损失函数的均方误差(我经常将其转换为均方根损失来调试输出),并且 Adam 优化器运行良好,帮助网络在训练期间有效地为每个滤波器选择可调值。
最后,我输出了一个模型摘要,用于调试目的(注意输入层不是 TensorFlow 显示的):
NOTICE: Model architecture:Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param #=================================================================dense (Dense) (None, 13) 182_________________________________________________________________dense_1 (Dense) (None, 13) 182_________________________________________________________________dense_2 (Dense) (None, 1) 14=================================================================Total params: 378Trainable params: 378Non-trainable params: 0复制
训练模型
模型是在多个迭代或时代中训练的。在每个时期,调整滤波器的可调参数,目的是根据定义模型时选择的损失函数的输出实现最小损失。优化算法控制这些参数的调整方式,以使模型尽可能快地磨合到最佳配置。
训练过度拟合时需要注意的一个问题。当网络被训练太多次,并且有效地学习了数据而不是连接输入和输出的算法时,就会发生这种情况。当输入是它以前见过的输入时,这将使模型非常擅长产生正确的输出,但对于以前看不见的输入却很差。
您会记得我们将数据分成三组。我们将使用训练数据来训练模型,并在训练过程中使用验证数据对其进行验证。
# Save a checkpoint each time our loss metric improves.checkpoint = ModelCheckpoint('{}/{}.h5'.format(output_path, output_name),monitor='loss',save_best_only=True,mode='min')# Use early stoppingearly_stopping = EarlyStopping(patience=50)# Display outputlogger = LambdaCallback(on_epoch_end=lambda epoch,logs: plpy.notice('epoch: {}, training RMSE: {} ({}%), validation RMSE: {} ({}%)'.\format(epoch,sqrt(logs['loss']),round(100 / max_z * sqrt(logs['loss']), 5),sqrt(logs['val_loss']),round(100 / max_z * sqrt(logs['val_loss']), 5))))# Train it!history = model.fit(training_input,training_output,validation_data=(validation_input,validation_output),epochs=epochs,batch_size=50,callbacks=[logger, checkpoint, early_stopping])复制
首先,我们设置了三个回调函数:
检查点:这将在每个 epoch 之后保存模型,这将产生比之前所有 epoch 更好的结果。
early_stopping:这将在 50 个 epoch(耐力参数)后没有明显进展时停止训练,以防止过度拟合。
logger:通常 TensorFlow 会在每个 epoch 上向 stdout 输出一条状态消息。因为我们在 PostgreSQL 的 pl/python3 下运行,所以我们需要输出我们自己的作为 NOTICE。我们将输出 epoch 数、训练的平方根和验证损失(我们正在测量均方误差,因此平方根会将其转换回我们可以与实际输出进行比较的值),以及两者的百分比到原始数据中的最大输出值(max_z)。
一旦设置了回调,我们就可以在模型上执行 model.fit() 方法,将训练和验证数据、时期数、要处理的记录的批量大小和回调列表传递给它。输出将如下所示:
NOTICE: epoch: 0, training RMSE: 34.744217425799796 (95.9785%), validation RMSE: 66.97870901217416 (185.02406%)NOTICE: epoch: 1, training RMSE: 20.016233341165083 (55.29346%), validation RMSE: 86.36728608372935 (238.58366%)NOTICE: epoch: 2, training RMSE: 20.81612147077206 (57.5031%), validation RMSE: 74.53097811795274 (205.88668%)NOTICE: epoch: 3, training RMSE: 15.706952561354747 (43.38937%), validation RMSE: 50.19628950897417 (138.66378%)...NOTICE: epoch: 88, training RMSE: 4.051587516569147 (11.19223%), validation RMSE: 14.049098431858425 (38.80966%)NOTICE: epoch: 89, training RMSE: 4.043822798154733 (11.17078%), validation RMSE: 14.405585350211444 (39.79443%)NOTICE: epoch: 90, training RMSE: 4.039318438155652 (11.15834%), validation RMSE: 13.547520957602528 (37.42409%)NOTICE: epoch: 91, training RMSE: 4.0253103101067085 (11.11964%), validation RMSE: 14.17337045065995 (39.15296%)复制
即使最后一个 epoch 的错误率不是最好的,checkpoint 回调也会为我们保存最有效的模型。
我们可以很容易地绘制错误率与 epoch 的关系,以查看网络在训练时改进的速度:
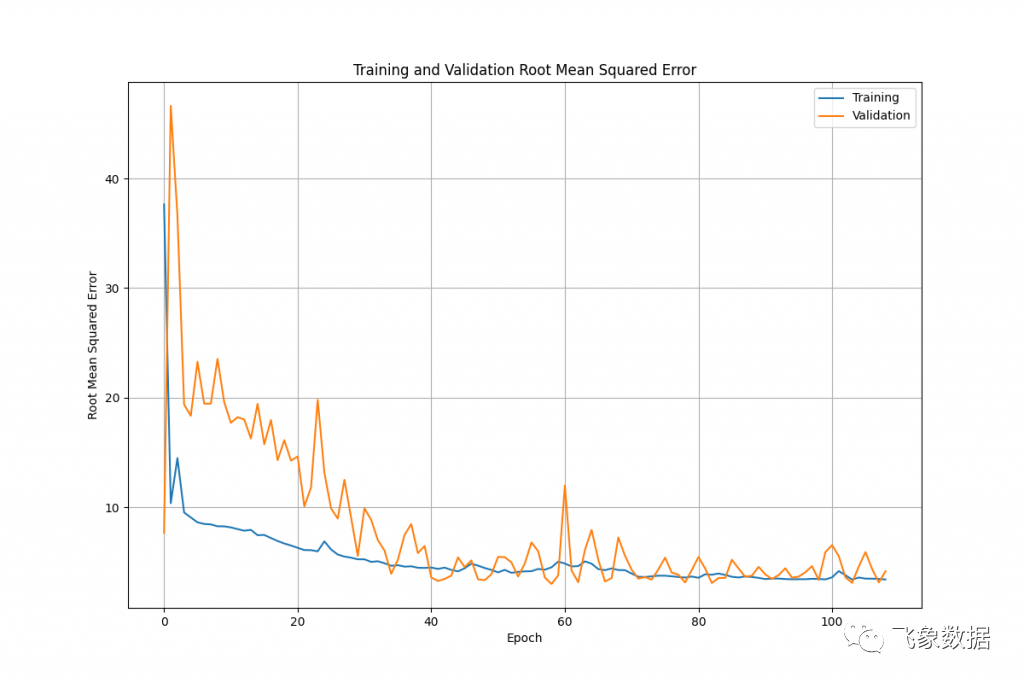
执行此操作的代码(使用 matplotlib)非常简单:
# Graph the resultstraining_loss = history.history['loss']validation_loss = history.history['val_loss']epochs_range = range(len(history.history['loss']))plt.figure(figsize=(12, 8))plt.grid(True)plt.plot(epochs_range,[x ** 0.5 for x in training_loss],label='Training')plt.plot(epochs_range,[x ** 0.5 for x in validation_loss],label='Validation')plt.xlabel('Epoch')plt.ylabel('Root Mean Squared Error')plt.legend(loc='upper right')plt.title('Training and Validation Root Mean Squared Error')plt.savefig('{}/{}_rmse.png'.format(output_path, output_name))plpy.notice('Created: {}/{}_rmse.png\n'.format(output_path,output_name))复制
我们首先从model.fit()方法返回的历史对象中获取每个 epoch 的训练和验证损失值。我们找出沿 X 轴绘制的时期范围,设置创建一个基本图,然后添加两个系列(平方根,因此我们可以将数字与实际数据进行比较)。最后,我们设置图例和标签等并保存图像。
此时,我们已经保存了一个模型,我们可以根据需要加载它以对新数据或假设数据进行分析。如果我们获得想要用来改进它的新数据,我们还可以在该模型的基础上重新训练。
您会记得,我们之前除了训练和验证数据集之外,还创建了一组测试数据。在这个阶段,我们可以使用 model.evaluate() 方法,将测试输入和输出特征传递给它,以便进一步测试模型。它将在测试模式和回波损耗和指标值下运行预测,以指示模型的执行情况。
执行分析
实际上,使用我们创建的模型来执行分析非常简单,可以很容易地封装到通用 pl/python3 函数中:
CREATE OR REPLACE FUNCTION public.tf_predict(input_values double precision[],model_path text)RETURNS double precision[]LANGUAGE 'plpython3u'COST 100VOLATILE PARALLEL UNSAFEAS $BODY$import tensorflow as tf# Reset everythingtf.keras.backend.clear_session()tf.random.set_seed(42)# Load the modelmodel = tf.keras.models.load_model(model_path)# Are we dealing with a single prediction, or a list of them?if not any(isinstance(sub, list) for sub in input_values):data = [input_values]else:data = input_values# Make the prediction(s)result = model.predict([data])[0]result = [ item for elem in result for item in elem]return result$BODY$;复制
首先,我们定义函数的 SQL 接口,传入一组输入特征,以及保存模型的路径。
在函数体内,我们导入 TensorFlow 库,然后确保一切都已重置。然后从给定的路径加载模型。
我们可以使用该函数一次进行一个或多个预测,方法是传入输入特征的一维数组或包含多组特征的二维数组。TensorFlow 需要一个二维数组(实际上是一个列表或类似对象,例如 Numpy 数组或 TensorFlow 张量),因此如果我们只传入一个一维数组,我们需要将其更改为包含单个列表的列表特点。否则,我们保持原样,因为 PostgreSQL 已经为我们将二维数组转换为一列列表。
然后使用model.predict()方法分析数据并进行预测,并返回一个 Numpy 的结果数组,我们将其转换为列表并返回给 PostgreSQL。该功能可以在下面看到:
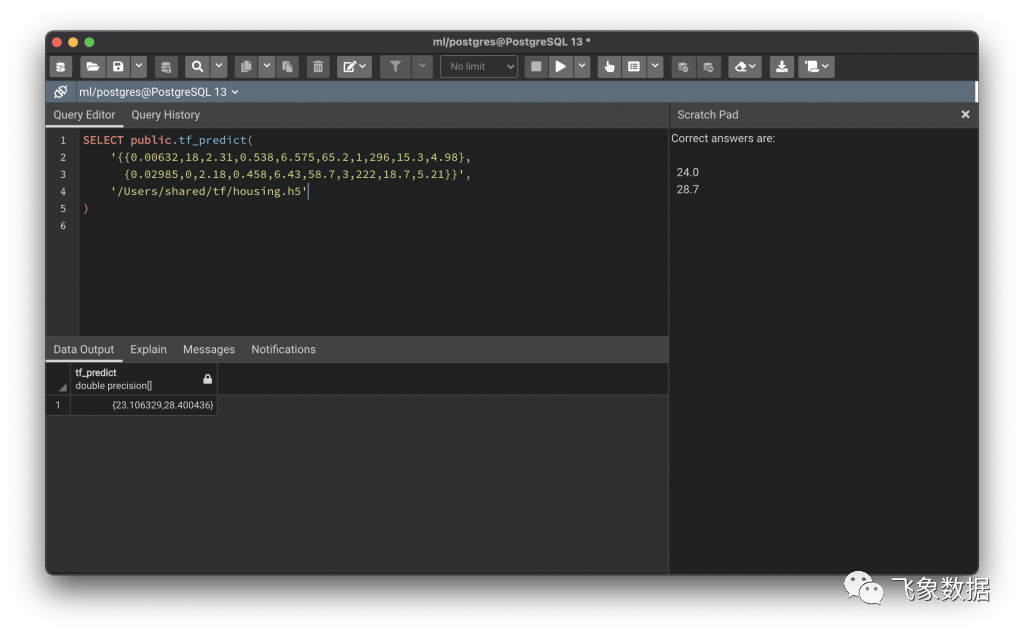
这个例子使用了我从 Boston Housing 数据集中随机选择的两行(因为我们知道它们的结果值应该是什么)。我删除了与medv列最松散相关的三列(chas、dis和b),然后训练了一个模型,除了输入和输出层外,还有四层 64 个过滤器,超过 5000 个 epoch(早期停止发生在 epoch 108)。
结论
在这个博客迷你系列中,我们探讨了如何设置 PostgreSQL 以便我们可以在我们的数据库中使用 TensorFlow,如何检查和优化数据以训练模型,以及如何执行训练并使用模型进行预测.
很容易看出,这里展示的技术提供了大量的可能性;将 TensorFlow 与 pl/python3 一起使用几乎只是一个示例,尽管它是一个非常强大且有趣的示例,但当然类似的代码可以与其他机器学习库(例如PyTorch https://pytorch.org/ )一起使用,或者实际上,任何其他可以使用的库用 PostgreSQL 中的数据做有趣的事情。
