




第一章 故障概述
某日,客户反馈XX系统存在大量enq: TX - index contention阻塞,即:索引分裂问题。影响了系统正常的业务活动。在早高峰发现上述问题后,为了及时缓解业务应用,通过杀掉阻塞会话的方式,来解决了对应问题。在阻塞结束后,对XX系统出现的异常问题进行分析,以确定出现问题的根本原因。
数据库版本:ORACLE 11.2.0.4
经过分析,出现上述异常的根本原因是由于触发了ORACLE 11.2.0.4的BUG
Bug 24555417 - Sessions Waiting On ‘gc buffer busy acquire’=> { ‘gc cr request’ | ‘gc current request’ } With No Blocker (Doc ID 24555417.8)
MMON进程异常报错,在内存中留下了pin锁,此后节点2在插入数据时触发了的索引分裂,在索引分裂操作过程中通过GC获取源端节点1上的索引块时,和节点1内存的Pin锁冲突,导致节点2的索引分裂和gc buffer busy acquire等待长时间HANG住,从4点24开始一直持续到9点之后,直到后续运维人员KILL会话,把这个HANG的问题解决。
第二章 故障分析
2.1 故障现象
在业务高峰期8点左右出现大量enq: TX - index contention索引分裂等待事件。问题持续1一个多小时直到杀会话后解除。
查看问题时段的AWR报告:
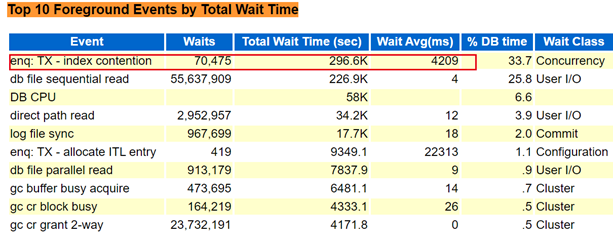
可以看到主要的问题是索引分裂现象。且平均延时非常高。查看索引分裂的对象分布:



对比了多个时段的报告分析,其中索引分裂的程度并不严重。根节点没有进行分裂,只是对分支节点进行,且分裂程度并不频繁。
这里就很奇怪,分裂量级并不严重,为何会出现如此大量的分裂问题甚至导致数据库HANG住呢?
分析历史的活动会话累计,可以追述故障起点在当日的4点23分左右就已出现。
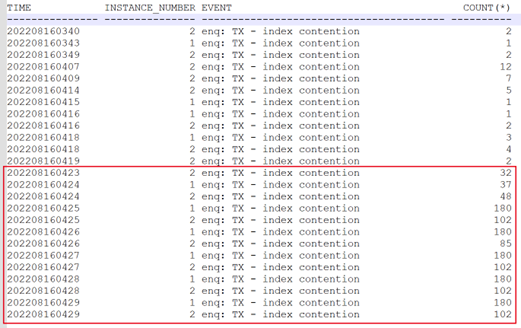
2.2 故障根源分析
分析对应时段的活动会话,可以看到主要在16日4点24分49秒时,出现大量的索引分裂及GC等待事件。

发生等待在同一个对象上面。

而这里索引分裂,伴随着大量GC等待,也是合理的。索引分裂过程中,如果内存块在另一节点,需要通过gc驱动索引块完成分裂动作。
查看相应事件的P1/P2:
select instance_number,
event,
p1,
p2,
count(*) cn,
max(to_char(sample_Time, 'yyyymmddhh24miss')) max_time,
min(to_char(sample_Time, 'yyyymmddhh24miss')) min_time
from dba_hist_active_sess_history
where sample_time >= to_date('202208160300', 'yyyymmddhh24mi')
and sample_time < to_date('202208161000', 'yyyymmddhh24mi')
and event = 'gc buffer busy acquire'
group by instance_number, event, p1, p2
having count(*) > 5
order by cn desc
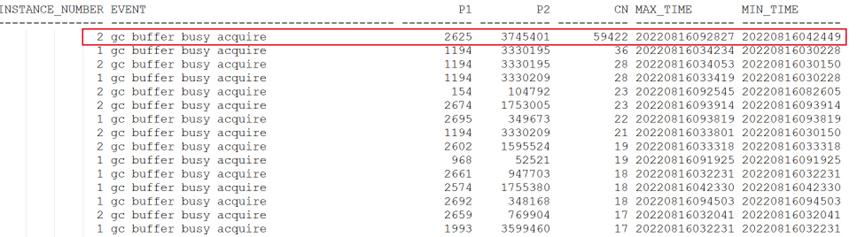
主要为2节点的gc buffer busy acquire事件,从4点一直持续到早上9点。且阻塞在同一个文件、块号上面。
问题时点主要在执行SQL: c6v5t48b4pj6x
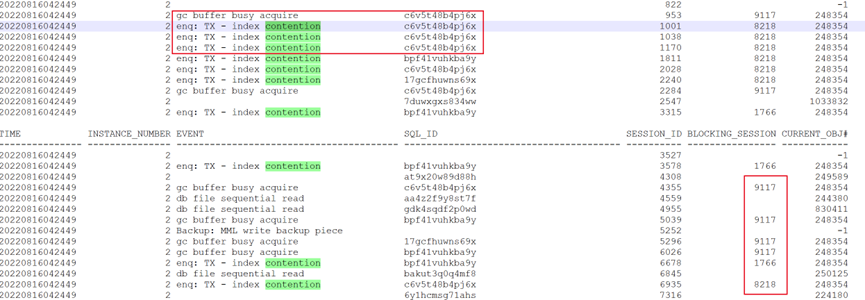
其对象也是在索引IDX_表名__FINISH_TIME上面。
查看阻塞链:
col lock_chain for a75
col EVENT_CHAIN for a50
col first_seen for a18
col last_seen for a18
col BLOCKING_HEADER for a10
with ash as (
select *
from gv$active_session_history
where sample_time>=to_date('2022-08-16 08:30:52','yyyy-mm-dd hh24:mi:ss')
and sample_time< to_date('2022-08-16 11:30:52','yyyy-mm-dd hh24:mi:ss')),
ash2 as (
select sample_time,inst_id,session_id,session_serial#,sql_id,sql_opname,
event,blocking_inst_id,blocking_session,blocking_session_serial#,
level lv,
connect_by_isleaf isleaf,
sys_connect_by_path(inst_id||'_'||session_id||'_'||session_serial#||':'||sql_id||':'||sql_opname,'->') lock_chain,
sys_connect_by_path(EVENT,',') EVENT_CHAIN ,
connect_by_root(inst_id||'_'||session_id||'_'||session_serial#) root_sess
from ash
--start with event like 'enq: TX - row lock contention%'
start with blocking_session is not null
connect by nocycle
prior blocking_inst_id=inst_id
and prior blocking_session=session_id
and prior blocking_session_serial#=session_serial#
and prior sample_id=sample_id)
select lock_chain lock_chain,
case when blocking_session is not null then blocking_inst_id||'_'||blocking_session||'_'||blocking_session_serial# else inst_id||'_'||session_id||'_'||session_serial# end blocking_header, EVENT_CHAIN,
count(*) cnt,
TO_CHAR(min(sample_time),'YYYYMMDD HH24:MI:ss') first_seen,
TO_CHAR(max(sample_time),'YYYYMMDD HH24:MI:ss') last_seen
from ash2
where isleaf=1
group by lock_chain,EVENT_CHAIN,case when blocking_session is not null then blocking_inst_id||'_'||blocking_session||'_'||blocking_session_serial# else inst_id||'_'||session_id||'_'||session_serial# end
having count(*)>1
order by first_seen, cnt desc;

最终的阻塞者是9117会话。且SQL: c6v5t48b4pj6x被8218所阻塞,8218又被9117阻塞。依次的等待事件是:索引分裂enq: TX - index contention、gc buffer busy acquire、gc current request。
继续查看该时点的阻塞者:

阻塞会话9117。

而9117会话等待事件为gc current request。该等待同样持续到早上才结束。

4点开始,持续到早上9点。且没有阻塞者。
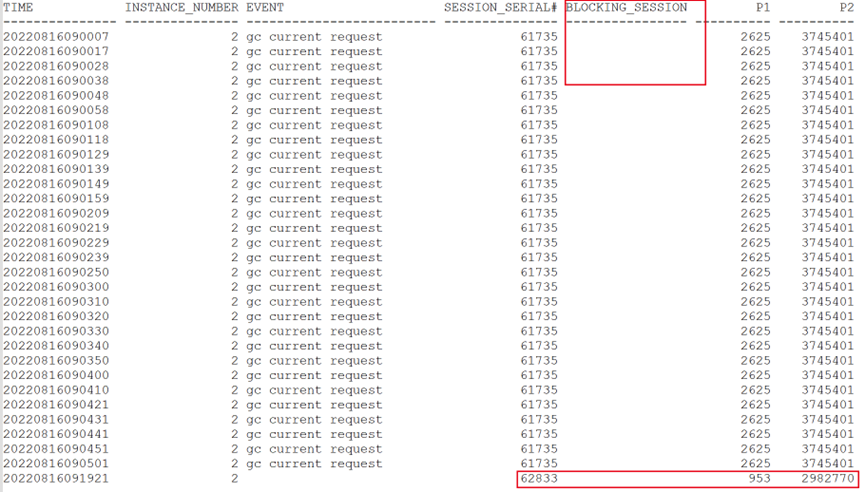
通过上述跟踪,源头SQL等待gc buffer busy acquire。被会话9117所阻塞,而阻塞者的等待事件为gc current request。且无阻塞者。
这种现象与ORACLE的一个BUG较为符合。

根据BUG描述,在11204版本会出现。
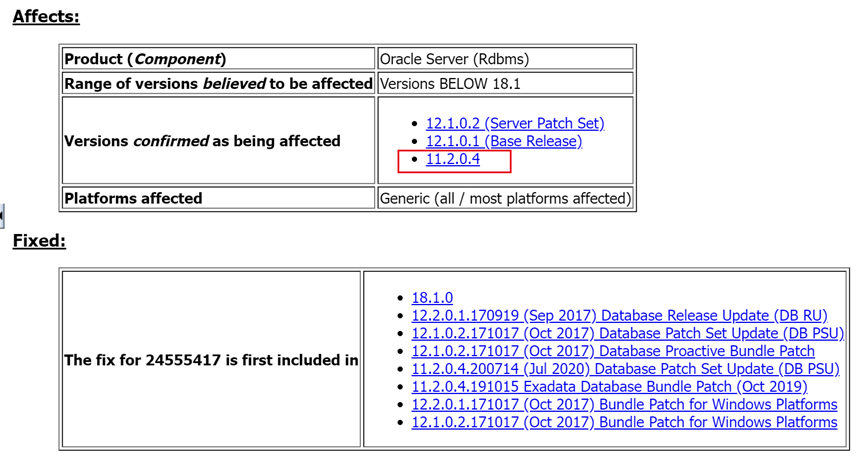
且MMON中会出现如下现象:

分析两节点的MMON日志:
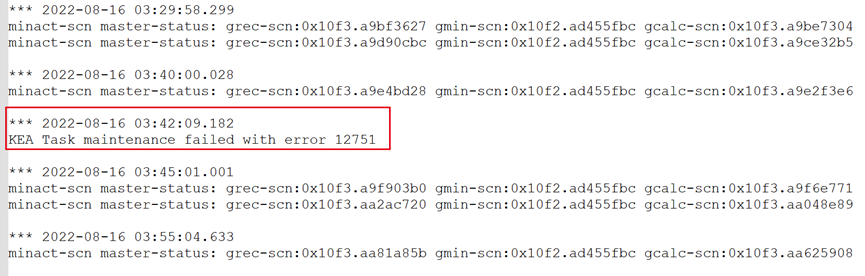
在1节点的MMON日志中,出现了对应的12751错误。进一步印证了我们前面的分析。
2.3 故障解决
问题是通过杀掉索引分裂相关的会话来解决的。
后续在发现会话长时间出现gc cr request 或gc current request等待时,根据p1和p2判断是否HANG在同一个数据块的读取过程中,并一直持续的现象后。可以检查mmon进程的trace,是否存在ORA-12751的报错。
如果上述现象均符合,证明确实触发了相应的BUG。
由于当前版本已是11g最新版,无法通过补丁方式解决,可参照MOS中的解决方案,快速kill mmon进程来解决。
第三章 解决方案及总结
明确了问题原因,下面分析解决方案:
-
通过kill mmon进程来解决:
后续在发现会话长时间出现gc cr request 或gc current request等待时,根据p1和p2判断是否HANG在同一个数据块的读取过程中,并一直持续的现象后。可以检查mmon进程的trace,是否存在ORA-12751的报错。
如果上述现象均符合,证明确实触发了相应的BUG。
由于当前版本已是11g最新版,无法通过补丁方式解决,可参照MOS中的解决方案,快速kill mmon进程来解决。 -
通过规范插入业务在同节点来降低GC等待的产生,从而降低触发BUG的概率。
经过了解,相应语句的大量插入在每日均有进行,且不区分节点。如能控制相应插入仅在同一节点进行,则对新插入的数据块不会产生如此多的GC类等待事件。也降低了触发该BUG的几率。
