




本文作为Data Science Blogathon.的一部分发表。
介绍
Impala是一个面向Hadoop的开源原生分析数据库。Cloudera、Oracle、MapReduce和Amazon等供应商已经推出了Impala。如果你想学习Impala的所有知识,你来对地方了。
它使用传统的SQL知识快速处理大量数据。要学习Impala,您应该了解Apache Hadoop和HDFS命令的基础知识。学习Impala时,SQL基础知识是一个优势。
什么是Impala?
Impala是一个面向Hadoop的开源原生分析数据库。它是一个大规模并行处理(MPP)SQL查询引擎,处理存储在Hadoop集群中的大量数据。
与Apache Hadoop的其他SQL引擎(如Hive)相比,Impala提供了高性能和低延迟。
简单地说,我们可以说Impala是最强大的SQL引擎,它提供了访问存储在HDFS(Hadoop分布式文件系统)中的数据的最快方式。Impala是用Java和C++编写的。
ApacheImpala提高了Hadoop上的SQL查询性能,同时保持了熟悉的用户体验。我们可以使用ApacheImpala查询存储在HDFS或ApacheHBase中的数据。我们可以使用Impala执行实时操作,如选择、连接和聚合函数。
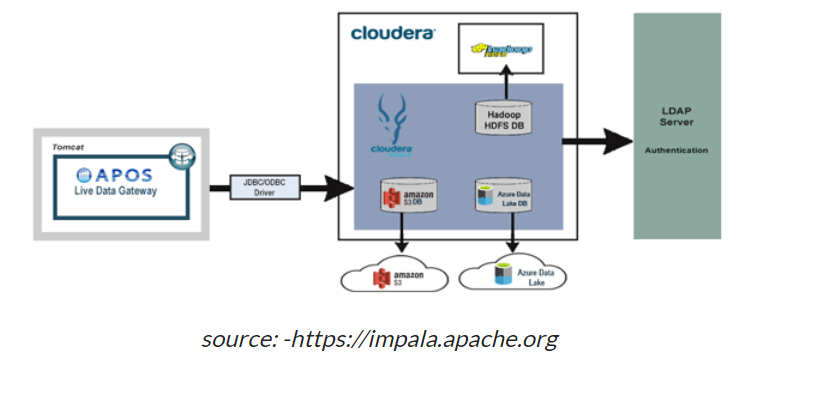
ApacheImpala使用与ApacheHive相同的配置单元查询语言(SQL)语法、元数据、用户界面和ODBC驱动程序,为面向批处理或实时查询提供了熟悉和统一的平台。
这允许Hive用户使用ApacheImpala,只需很少的安装开销。但是,Impala不支持所有SQL查询;可能会发生一些语法更改。Impala查询语言是Hive查询语言的一个子集,具有一些功能限制,如转换。
使用Apache Impala的原因
1.Apache Impala将Hadoop的灵活性和可伸缩性与传统分析数据库的SQL支持和多用户性能相结合,使用了HDFS、元存储、HBase、Sentry和YARN等组件。
2.使用Apache Impala,用户可以使用类似SQL的查询轻松与HDFS或HBase交互,比其他SQL引擎(如Apache Hive)更快。
3.ApacheImpala可以读取ApacheHadoop使用的几乎所有文件格式,如Parquet、RCFiand le和Avro。
4.此外,它使用与Apache Hive相同的SQL(Hive SQL)语法、元数据、用户界面和ODBC驱动程序,为面向批处理或实时查询提供了熟悉和统一的平台。
5.Impala也不是基于MapReduce算法,比如Apache Hive。
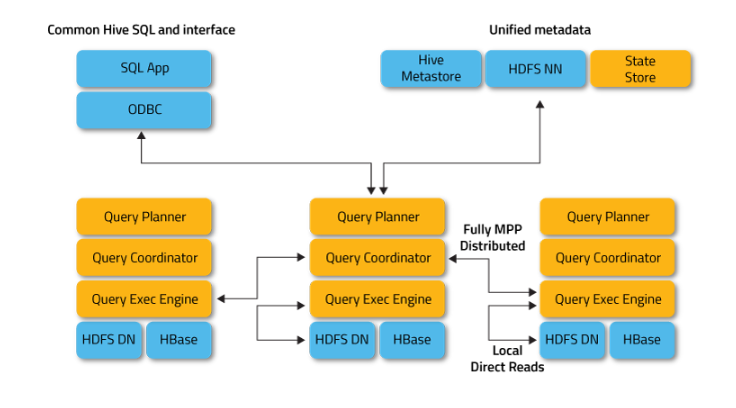
Apache Impala架构
上图显示了Impala建筑。Apache Impala在Apache Hadoop集群中运行多个系统。与传统的存储系统不同,ApacheImpala不依赖于其存储核心。
它与其存储引擎是分开的。Impala有三个核心组件:Impala守护进程(Impala)、Imp状态存储和Impala目录服务。
1.Impala Demon
Impala守护进程是Apache Impala的核心组件。impalad进程在物理上代表了它。Impala守护进程在安装了Impala的每台计算机上运行。Impala守护进程的主要功能是:
-
读取和写入数据文件。
-
接受从impala shell、JDBC、Hue或ODBC传递的查询。
-
Impala守护进程在整个Hadoop集群中并行查询和分配工作。
-
将正在进行的查询结果发送回中央协调器。
-
Impala守护进程不断与StateStore通信,以确认哪些守护进程正常并准备接受新工作。
-
Impala守护进程还可以随时从编目的守护进程(如下所述)接收广播消息
-
任何Impala守护进程都将创建、删除或修改任何类型的对象。
-
当Impala处理INSERT或LOAD DATA语句时。
为了实现impala,我们可以使用以下方法之一:
-
将HDFS和Impala放在一起,每个Impala守护进程应该与DataNode在同一主机上运行。
-
在计算集群中单独部署Impala,可以从HDFS、S3、ADL等远程读取数据。
2.ImpStateStore商店
ImpStateStore是检查集群中所有Impala守护进程的运行状况并将其结果持续传递给每个Impala后台进程的存储库。IMPStateStore由守护进程cal state stored物理表示。
我们只需要集群中一台主机上的状态存储存储存储进程。因此,如果任何Impala煽动者由于网络错误、硬件故障、软件问题或其他原因而脱机,Impala状态存储将通知所有其他Impala守护进程。
这确保了将来的查询不会向失败的Impala守护进程发送请求。
ImpStateStore对于Impala集群的正常运行并不总是至关重要的。如果在这种情况下StateStore没有运行,那么Impala守护进程也将像往常一样在它们之间运行和分配工作。
在这种情况下,当其他Impala守护进程失败时,集群将变得不那么健壮,元数据也将不那么一致。当Impala状态存储返回时,它将恢复与所有Impala守护进程的通信,并继续其监视和广播功能。
3.Impala目录服务
catalog服务是另一个Impala组件,它将来自Impala SQL命令的元数据更改传播到集群中的所有Impala守护进程。Impala catalog服务由名为catalog的守护进程物理表示。
我们只需要集群中一台主机上的编目进程。由于请求通过StateStore守护进程传递,因此最好在同一主机上运行有状态和编目进程。
当通过Apache Impala发布的命令对元数据进行更改时,Impala目录服务避免了发出刷新和无效元数据命令的需要。
当我们通过Apache配置单元创建表或加载数据时,必须在对Impala节点执行任何查询之前发出刷新或使元数据无效。
Apache Impala特性
Impala的主要特征是:
-
为内存数据处理提供支持;它可以访问或分析存储在Hadoop DataNodes上的数据,而无需任何数据移动。
-
通过使用Impala,我们可以使用类似SQL的查询来访问数据。
-
与其他SQL引擎(如Hive)相比,Apache Impala提供了对存储在Hadoop分布式文件系统中的数据的更快访问。
-
Impala帮助我们将数据存储在Hadoop HBase、HDFS和Amazon s3等存储系统中。
-
我们可以轻松地将Impala与商业智能工具集成,如Tableau、Micro strategy、P、Pentaho和Zoom data。
-
提供对各种文件格式的支持,如LZO、Avro、RCFile、序列文件和Parquet。
-
ApacheImpala使用ODBC驱动程序、用户界面元数据和SQL语法作为ApacheHive。
结论
简言之,我们可以说Impala是一个面向Hadoop的开源原生分析数据库。Impala是最强大的SQL引擎,提供对存储在HDFS(Hadoop分布式文件系统)中的数据的最快访问。
Impala使用与Apache配置单元相同的配置单元查询语言(SQL)语法、元数据、用户界面和ODBC驱动程序。与传统的存储系统不同,ApacheImpala不依赖于其存储核心。
它由三个核心组件组成:Impala守护进程、Impala状态存储和Impala目录。Impala外壳、Hue浏览器和JDBC/ODBC驱动程序是我们可以用来与ApacheImpala交互的三个查询处理接口。
-
Impala不支持所有SQL查询。可能会发生一些语法更改。Impala查询语言是Hive查询语言的一个子集,具有一些功能限制,如转换。
-
Apache Impala将Hadoop的灵活性和可伸缩性与传统分析数据库的SQL支持和多用户性能结合起来,使用了HDFS、元存储、HBase、Sentry和YARN等组件。
-
Impala是用Java和C++编写的。ApacheImpala提高了Hadoop上的SQL查询性能,同时保持了熟悉的用户体验。我们可以查询存储在HDFS或Apache HBase中的数据。
本文中显示的媒体并非Analytics Vidhya所有,由作者自行决定使用。
原文标题:Apache Impala- Features and Architecture
原文作者:Trupti Dekate
原文链接:https://www.analyticsvidhya.com/blog/2022/08/what-is-apache-impala-features-and-architecture/
