




1. 整体架构介绍

1.1 Amazon DynamoDB 介绍
Amazon DynamoDB 是一个键-值和文档数据库,可利用水平扩展支持几乎任何大小的表。这使 DynamoDB 能够扩展到请求数超过 10 万亿条/天,峰值高于 2000 万条请求/秒,存储空间大于数 PB。交付具有一致的个位数毫秒性能、几乎无限的吞吐量和存储以及自动多区域复制的应用程序。通过静态加密、自动备份和恢复,以及高达 99.999% 可用性的 SLA 保证可靠性。
DynamoDB Accelerator (DAX) 是一个内存内缓存,通过支持您使用完全托管的内存中的缓存来大规模地为您的表提供快速读取性能。借助 DAX,您的 DynamoDB 表可实现高达 10 倍的性能提升(读取时间从数毫秒缩短到数微秒),甚至在每秒处理的请求数达到数百万的情况下也是如此。利用 DynamoDB Accelerator 可以实现微秒级延迟。
通常情况下,DAX 集群运行时,复制该集群中所有节点之间的数据(假定已预置多个节点)。考虑一个使用 DAX 成功执行 UpdateItem 的应用程序。此操作会导致使用新值修改主节点中的项目缓存。然后,该值复制到集群中的所有其他节点。此复制具有最终一致性,并且通常只需不到一秒即可完成。DAX 无法自行处理强一致性读取,因为它未紧密耦合到 DynamoDB。因此,任何从 DAX 后续读取必须为最终一致性读取。任何后续强一致性读取将传递到 DynamoDB。
1.2 典型的Flink 实时计算场景

使用HBASE作为维表的分布式存储库,底层存储依赖于HDFS,挂载Redis提高查询性能。Flink 实时双写维表数据到HBASE及Redis,并通过异步同步保证数据一致性。另一条实时计算流触发实时数据流于维表的计算,并将最终计算结果写入下游。整体上需要维护的组件较多,扩展及维护都需要投入资源。
本文实践内容旨在通过Amazon DynamoDB替换HBASE与Redis,提出一种基于无服务化数据库实时计算的架构。接下来将重点介绍Flink SQL 在Amazon DynamoDB Connector 的实现。
2. Flink SQL Connector实现
当前版本主要实现以下内容:
支持定义primary key ,Table Name ,代码hard code 到 AP_SOUTHEAST_1 区域;
支持Source/Sink,Source 暂时只实现了scan 模式。Sink 端支持了实时流式append写入,并支持kafka、S3等Stream/Batch数据源写入;
当前仅支持定义String类型数据格式
2.1 DynamoDB Flink SQL Connector 使用说明
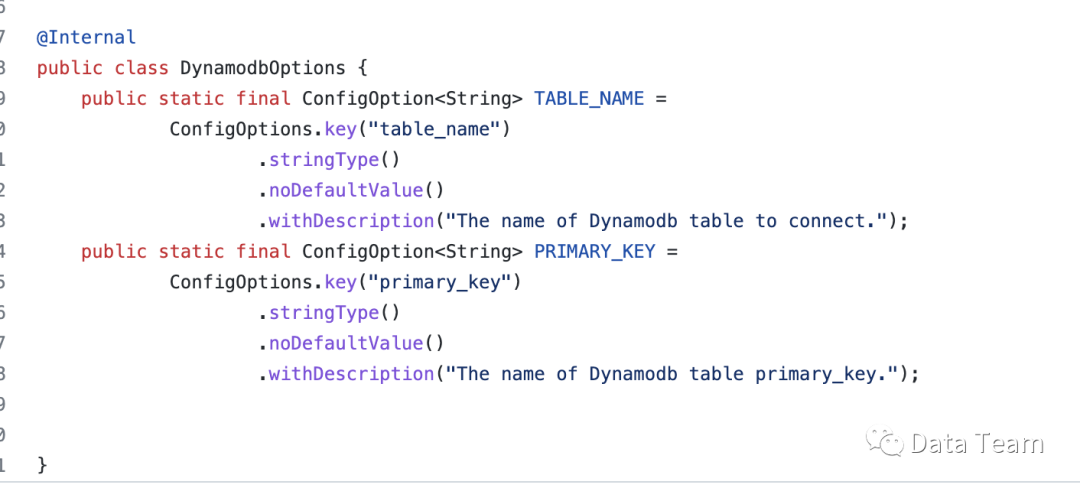
-- 创建表CREATE TABLE IF NOT EXISTS test_database.test_dynamodb_table(field1 STRING,field2 STRING,field3 STRING)WITH ('connector' = 'dynamodb-v2', -- 使用Amazon v2版本sdk'table_name' = 'tableName', -- 对应dynamodb 表名'primary_key' = 'primaryKey' -- 主键必须定义的partition key)-- 查询select * from test_database.test_dynamodb_table;-- 写入insert intotest_database.test_dynamodb_tableselect * fromtest_database_source.test_source_table
2.2 DynamoDB Flink SQL Connector 实现说明
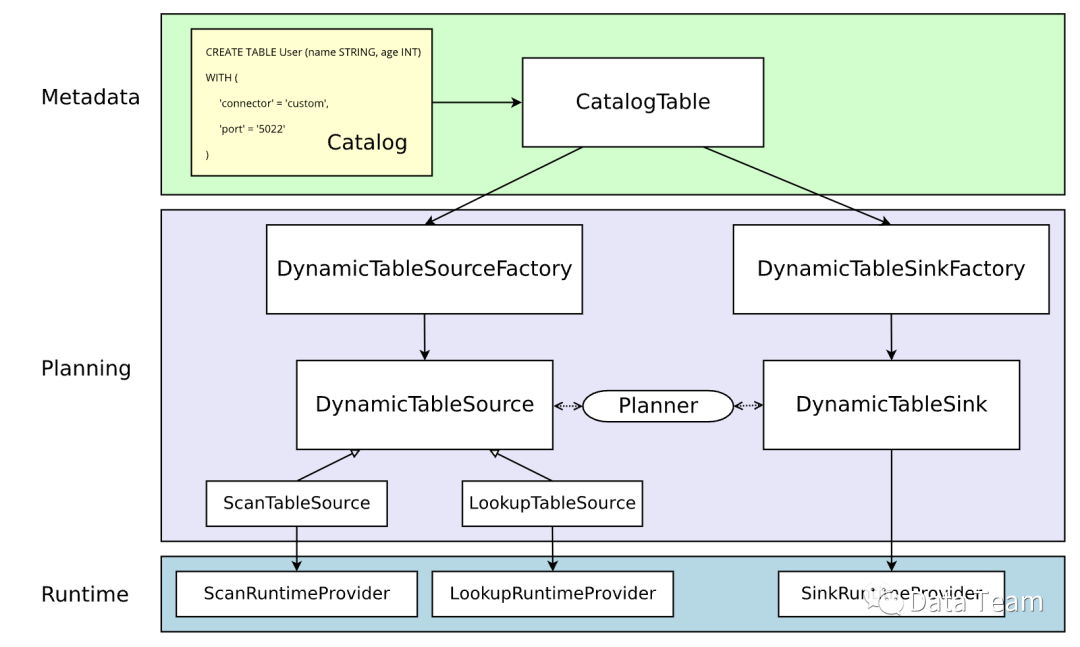
1. 项目整体结构

2. 继承实现Flink DynamicTableFactory

3. 定义DDL 接受参数
4. 实现Sink写数据

5. 实现Source读取数据

3. 后续待改进点
集成lookup 查询,异步缓存特性,优化查询性能;
支持Dynamodb 原生支持的多种字段type mapping;
支持设置参数定义aws region、读写并发设置、 DDL直接创建dynamodb表等功能;
对接flink metric 指标统计特性。
相关文档:
DynamoDB 数据一致性模型:https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/DAX.consistency.html
DyanmoDB 功能特性:https://aws.amazon.com/cn/dynamodb/features/#Performance_at_scale
分布式键值存储DynamoDB实现原理:https://draveness.me/dynamo/
分布式系统弱一致性模型和DynamoDB的设计思想:https://www.jianshu.com/p/4b6bc3b84cdc
flink-connector-dynamodb-1.13.2项目地址:https://github.com/DataTeamLab/flink-connector-dynamodb-1.13.2
