




EXPLAIN ANALYZE
是 PostgreSQL 中优化 SQL 语句的关键。本文并不试图解释它的所有内容。相反,我想给你一个简短的介绍,解释要寻找什么,并向你展示一些有用的工具来可视化输出。
怎么调用EXPLAIN ANALYZE?
如果您有一条执行很慢的 SQL 语句,您想知道发生了什么以及如何优化它。在 SQL 中,很难看出引擎是如何花费时间的,因为它不是一种过程语言,而是一种声明性语言:你描述的是你想要得到的结果,而不是如何计算它。该EXPLAIN命令向您显示优化器生成的执行计划。这很有帮助,但通常您需要更多信息。
EXPLAIN
您可以通过在括号中添加选项来获取此类附加信息。
最重要的EXPLAIN选项
ANALYZE
: 使用这个关键字,EXPLAIN
不仅显示计划和 PostgreSQL 的估计,而且还执行查询(所以要小心UPDATE
andDELETE
!)并显示每个步骤的实际执行时间和行数。这对于分析 SQL 性能是必不可少的。BUFFERS
: 这个关键字只能和ANALYZE
一起使用,它显示了每一步读、写和脏读有多少个8kB-blocks 。你总是想要这个。VERBOSE
:如果您指定此选项,则EXPLAIN
显示执行计划中每个步骤的所有输出表达式。这通常只是杂乱无章,没有它你会更好,但如果执行器将时间花在经常执行的、昂贵的函数上,它会很有用。SETTINGS
:此选项从 v12 开始存在,包括所有与输出中的默认值不同的性能相关参数。WAL
:在v13中引入,该选项显示数据修改语句所产生的WAL使用情况。您只能与ANALYZE
一起使用。这总是有用的信息!
通常,最好的调用方式EXPLAIN
是:
EXPLAIN (ANALYZE, BUFFERS) /* SQL statement */;复制
包括您是否使用 v12 或更高版本以及从 v13 开始的数据修改语句。
如果您使用的是v12或更高版本,请包括SETTINGS
,以及WAL
v13上的数据修改语句。
设置track_io_timing = on
来获取有关 I/O 性能的数据是非常有价值的。
警告和限制
您不能EXPLAIN
用于所有类型的语句:它仅支持SELECT
, INSERT
, UPDATE
, DELETE
, EXECUTE
(准备好的语句)CREATE TABLE ... AS
和DECLARE
(游标)。
请注意,这EXPLAIN ANALYZE
会显着增加查询执行时间的开销,因此不必担心语句花费的时间更长。
查询执行时间总是存在一定的变化,因为在第一次执行期间数据可能不在缓存中。这就是为什么重复EXPLAIN ANALYZE
几次并查看结果是否改变是有价值的。
从EXPLAIN ANALYZE信息中得到什么?
一些信息显示在执行计划的每个节点上,一些显示在页脚中。
EXPLAIN没有选项
EXPLAIN
计划为您提供估计成本、估计行数和平均结果行的估计大小。估计查询成本的单位是人为的(1 是在顺序扫描期间读取 8kB 页面的成本)。有两个成本值:启动成本(返回第一行的成本)和总成本(返回所有行的成本)。
EXPLAIN SELECT count(*) FROM c WHERE pid = 1 AND cid > 200;QUERY PLAN------------------------------------------------------------Aggregate (cost=219.50..219.51 rows=1 width=8)-> Seq Scan on c (cost=0.00..195.00 rows=9800 width=0)Filter: ((cid > 200) AND (pid = 1))(3 rows)复制
ANALYZE选项的输出
ANALYZE
为您提供第二个括号,其中包含实际执行时间(以毫秒为单位)、实际行数和显示该节点执行频率的循环计数。它还显示过滤器已删除的行数。
EXPLAIN (ANALYZE) SELECT count(*) FROM c WHERE pid = 1 AND cid > 200;QUERY PLAN---------------------------------------------------------------------------------------------------------Aggregate (cost=219.50..219.51 rows=1 width=8) (actual time=4.286..4.287 rows=1 loops=1)-> Seq Scan on c (cost=0.00..195.00 rows=9800 width=0) (actual time=0.063..2.955 rows=9800 loops=1)Filter: ((cid > 200) AND (pid = 1))Rows Removed by Filter: 200Planning Time: 0.162 msExecution Time: 4.340 ms(6 rows)复制
在页脚中,您可以看到 PostgreSQL 计划和执行查询所用的时间。您可以使用 SUMMARY OFF隐藏该信息。
BUFFERS选项的输出
此选项显示每个节点在缓存(hit)中找到的数据块数量、必须从磁盘读取的数据块数量、写入的数据块数量以及被脏读的数据块数量。在最新版本中,如果页脚在缓存中没有找到所有数据,则页脚包含与优化器所做工作相同的信息。
如果track_io_timing = on
,您将获得所有 I/O 操作的时序信息。
EXPLAIN (ANALYZE, BUFFERS) SELECT count(*) FROM c WHERE pid = 1 AND cid > 200;QUERY PLAN---------------------------------------------------------------------------------------------------------Aggregate (cost=219.50..219.51 rows=1 width=8) (actual time=2.808..2.809 rows=1 loops=1)Buffers: shared read=45I/O Timings: read=0.380-> Seq Scan on c (cost=0.00..195.00 rows=9800 width=0) (actual time=0.083..1.950 rows=9800 loops=1)Filter: ((cid > 200) AND (pid = 1))Rows Removed by Filter: 200Buffers: shared read=45I/O Timings: read=0.380Planning:Buffers: shared hit=48 read=29I/O Timings: read=0.713Planning Time: 1.673 msExecution Time: 3.096 ms(13 rows)复制
如何读取EXPLAIN ANALYZE输出
你会发现,即使是简单的查询,你也会得到相当多的信息。要提取有意义的信息,你必须知道如何阅读。
首先,您必须了解 PostgreSQL 执行计划是由多个节点组成的树形结构。顶部节点(上图Aggregate
)位于顶部,下部节点缩进并以箭头 ( ->
) 开头。具有相同缩进的节点处于同一级别(例如,两个关系与一个连接相结合)。
PostgreSQL 执行一个自上而下的计划,也就是说,它首先为顶部节点生成第一个结果行。执行器“按需”处理下层节点,也就是说,它只从它们中获取尽可能多的结果行,以计算上层节点的下一个结果。这会影响您如何阅读“成本”和“时间”:上层节点的启动时间至少与下层节点的启动时间一样高,总时间也是如此。如果你想找到在一个节点上花费的净时间,你必须减去在较低节点上花费的时间。并行查询使这变得更加复杂。
最重要的是,您必须将成本和时间乘以“循环”的数量,以获得在节点中花费的总时间。
EXPLAIN ANALYZE输出要注意什么
查找花费大部分执行时间的节点。
找到估计行数与实际行数显着不同的最低节点。很多时候,这是性能不佳的原因,而其他地方的长执行时间只是基于错误估计的错误计划选择的结果。“明显不同”通常意味着 10 倍左右。
查找具有删除多行的筛选条件的长时间运行的顺序扫描。这些都是很好的索引候选。
解读EXPLAIN ANALYZE输出的工具
由于阅读较长的执行计划非常麻烦,因此有一些工具试图可视化这个“文本海洋”:
Depesz 的EXPLAIN ANALYZE可视化工具
这个工具可以在https://explain.depesz.com/找到。如果您将执行计划粘贴到文本区域并点击“提交”,您将获得如下输出:
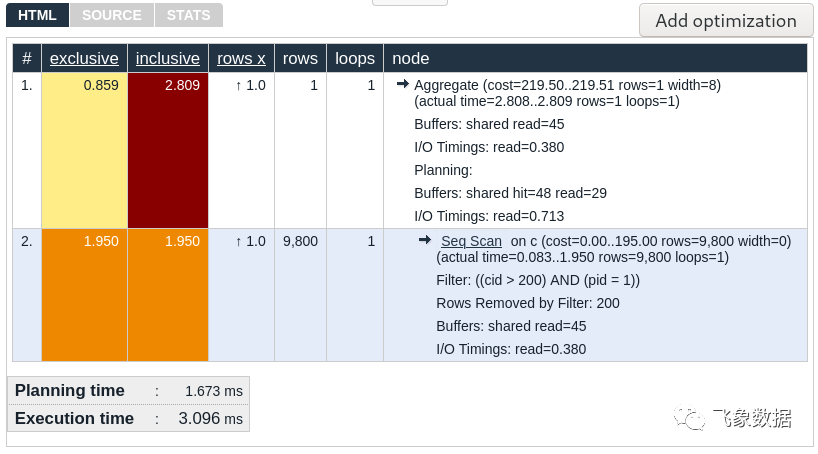
执行计划看起来与原版有些相似,但视觉上更令人愉悦。还有一些有用的附加功能:
计算并显示每个节点的总执行时间和净执行时间。这可以为您节省大量工作!时间最高的节点以红色背景突出显示,很容易发现。
在标题“rows x”下,您可以看到 PostgreSQL 高估或低估行数的因素。错误的估计以红色背景突出显示。
如果单击一个节点,它下面的所有内容都会被隐藏。这使您可以忽略冗长的执行计划中不感兴趣的部分,并专注于重要的部分。
如果您将鼠标悬停在一个节点上,它的所有直接子节点都会用星号突出显示。这使得在一个大的执行计划中很容易找到它们。
我特别喜欢这个工具的一点是,一旦你专注于一个有趣的节点,所有的原始EXPLAIN
文本都在那里供你查看。外观和感觉显然更“老派”和严肃,而且这个网站已经存在了很长时间。
Dalibo的EXPLAIN ANALYZE可视化工具
这个工具可以在https://explain.dalibo.com/找到。同样,您粘贴原始执行计划并点击“提交”。输出显示为树:
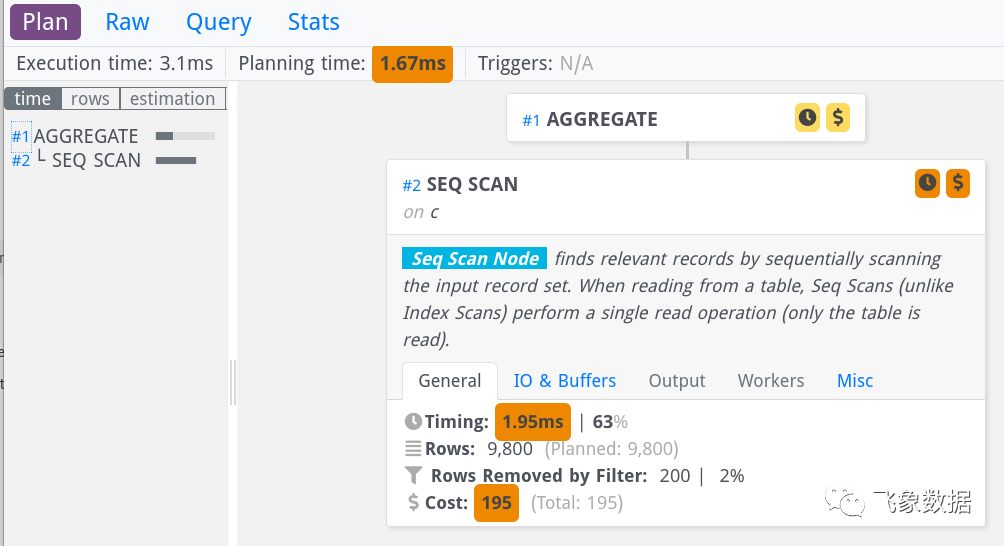
最初,显示隐藏了详细信息,但您可以通过单击一个节点来显示它们,就像我对上图中的第二个节点所做的那样。在左侧,您可以看到所有节点的小概览,从那里您可以跳转到右侧以获取详细信息。增值功能包括:
在左侧,您会看到代表相对净执行时间的条形图,让您可以专注于最昂贵的节点。
同样在左侧,您可以选择“估计”以查看 PostgreSQL 高估或低估每行的行数的程度。
最后,您可以单击“缓冲区”查看哪些节点使用了最多的 8kB 块。这是有用的信息,因为它显示节点的执行时间将取决于数据缓存的程度。
在右侧,您可以通过单击展开节点,并在多个选项卡中获取所有详细信息。
您可以通过单击隐藏在节点右下角的“十字准线”图标来折叠树中节点下的所有内容。
这个工具的好处是它使执行计划的树形结构清晰可见。外观和感觉是最新的。不利的一面是,它在某种程度上隐藏了详细信息,您必须了解在哪里搜索它。
结论
EXPLAIN (ANALYZE, BUFFERS)
(track_io_timing
打开情况下)将向您展示诊断 SQL 语句性能问题所需的一切。为了避免淹没在一堆文本的海洋中,您可以使用 Depesz 或 Dalibo 的可视化工具。两者都提供大致相同的功能。
在开始调优查询之前,您必须找到使用服务器大部分资源的查询。这是一篇描述如何做到这一点的文章。
