




1.测试环境
本文主要在mogdb 3.0.1版本下使用ptk安装3节点带CM集群管理软件的高可用环境下进行测试,文章从数据库实例,网络、主机方面的常见异常,共测试12个高可用场景。测试过程中较为详细记录了的测试的方法,过程和结论,供各位读者进行参考。
1.1数据库软硬件环境
| 主机名 | IP | az | dn | 角色-默认 | db版本 | CM版本 | 操作系统 |
|---|---|---|---|---|---|---|---|
| mogdbv3m1 | 192.168.5.30 | az1 | 6001 | 主库 | gsql ((MogDB 3.0.1 build 1a363ea9) compiled at 2022-08-05 17:31:04 commit 0 last mr ) | cm_ctl ( build d1f619ad) compiled at 2022-08-05 17:30:34 Release | CentOS Linux release 7.9.2009 (Core) |
| mogdbv3s1 | 192.168.5.31 | az1 | 6002 | 同步从 | gsql ((MogDB 3.0.1 build 1a363ea9) compiled at 2022-08-05 17:31:04 commit 0 last mr ) | cm_ctl ( build d1f619ad) compiled at 2022-08-05 17:30:34 Release | CentOS Linux release 7.9.2009 (Core) |
| mogdbv3s2 | 192.168.5.32 | az1 | 6003 | Potential从 | gsql ((MogDB 3.0.1 build 1a363ea9) compiled at 2022-08-05 17:31:04 commit 0 last mr ) | cm_ctl ( build d1f619ad) compiled at 2022-08-05 17:30:34 Release | CentOS Linux release 7.9.2009 (Core) |
1.2测试软件
压测主机
mogdb-single-v3b2:192.168.5.20
压力模拟工具,模拟压测期间的DML事务
benchmarksql-5.0-x86,参数如下:
db=postgres driver=org.postgresql.Driver #conn=jdbc:postgresql://1:26000/tpcc_db?prepareThreshold=1&batchMode=on&fetchsiz e=10&loggerLevel=offconn=jdbc:postgresql://192.168.5.30:26000,192.168.5.31:26000,192.168.5.32:26000/ tpcc_db?prepareThreshold=1&batchMode=on&fetchsize=10&loggerLevel=off&targetServerType=masteruser=tpcc_usr password=tpcc@123 warehouses=3 terminals=2 runMins=50 runTxnsPerTerminal=0 loadWorkers=50 limitTxnsPerMin=0 terminalWarehouseFixed=false newOrderWeight=45 paymentWeight=43 orderStatusWeight=4 deliveryWeight=4 stockLevelWeight=4`复制
jdbc模拟连接工具,模拟不间断连接数据库进行查询,代码如下:
import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; public class Test7CommitAndRollback { public static void main(String[] args) throws Exception{ Class.forName("org.opengauss.Driver"); Connection conn = DriverManager.getConnection("jdbc:opengauss://192.168.5.30:26000 ,192.168.5.31:26000,192.168.5.32:26000/tpcc_db?prepareThreshold=1&batchMode=on&fetchsize=10&loggerLevel=off&targetServerType=master", "tpcc_usr","tpcc@123"); conn.setAutoCommit(false); PreparedStatement stmt = null; //stmt = conn.prepareStatement("insert into tab_insert(data) values(?)"); //stmt.setString(1, "test commit"); //stmt.executeUpdate(); //查询 stmt = conn.prepareStatement("select * from bmsql_new_order order by random() limit 3;"); ResultSet rs =stmt.executeQuery(); while(rs.next()){ Integer d_id = (Integer) rs.getInt(1); Integer o_id = (Integer) rs.getInt(2); Integer w_id = (Integer) rs.getInt(3); System.out.println("d_id = "+d_id+", o_id = "+o_id+", w_id = "+w_id); } System.out.println("查询结果"); conn.close(); } }复制
* 数据库参数
2.测试场景
2.1主机问题
2.1.1 Potential从库主机宕机
测试目的:模拟Potential角色的从库主机硬件故障,出现宕机。
测试方法:选定一个Potential从库,直接关闭电源,观察业务情况。
预期结果:任意一个从库故障期间,主读写业务和另一个从库只读业务均正常,故障主机恢复后,宕机从库自动追平延迟。
测试过程和结论:
- 尚未进行测试正常环境。
HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: sender_pid : 2614 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 1/4027F300 sender_write_location : 1/4027F300 sender_flush_location : 1/4027F300 sender_replay_location : 1/4027F300 receiver_received_location : 1/4027EB30 receiver_write_location : 1/4027DFD8 receiver_flush_location : 1/4027DFD8 receiver_replay_location : 1/40269CD0 sync_percent : 99% sync_state : Sync sync_priority : 1 sync_most_available : On channel : 192.168.5.31:26001-->192.168.5.32:47642 sender_pid : 29676 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 1/4027F300 sender_write_location : 1/4027F300 sender_flush_location : 1/4027F300 sender_replay_location : 1/4027F300 receiver_received_location : 1/4027EB30 receiver_write_location : 1/4025B848 receiver_flush_location : 1/4025B848 receiver_replay_location : 1/38F9D560 sync_percent : 99% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.31:26001-->192.168.5.30:51958复制
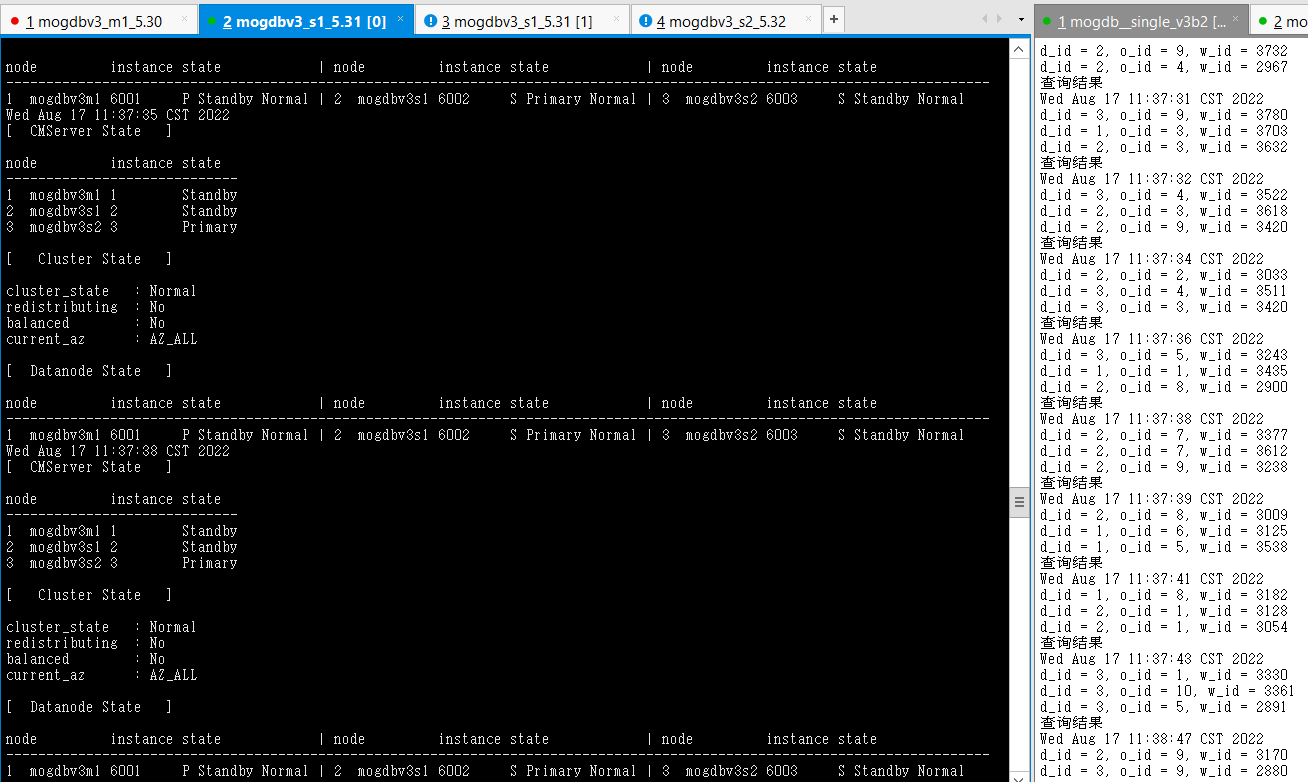
2. 关闭mogdbv3m1 为从库的node节点,查看数据库状态和业务中断情况,业务测试存在64s的等待,但并未发生连接报错。
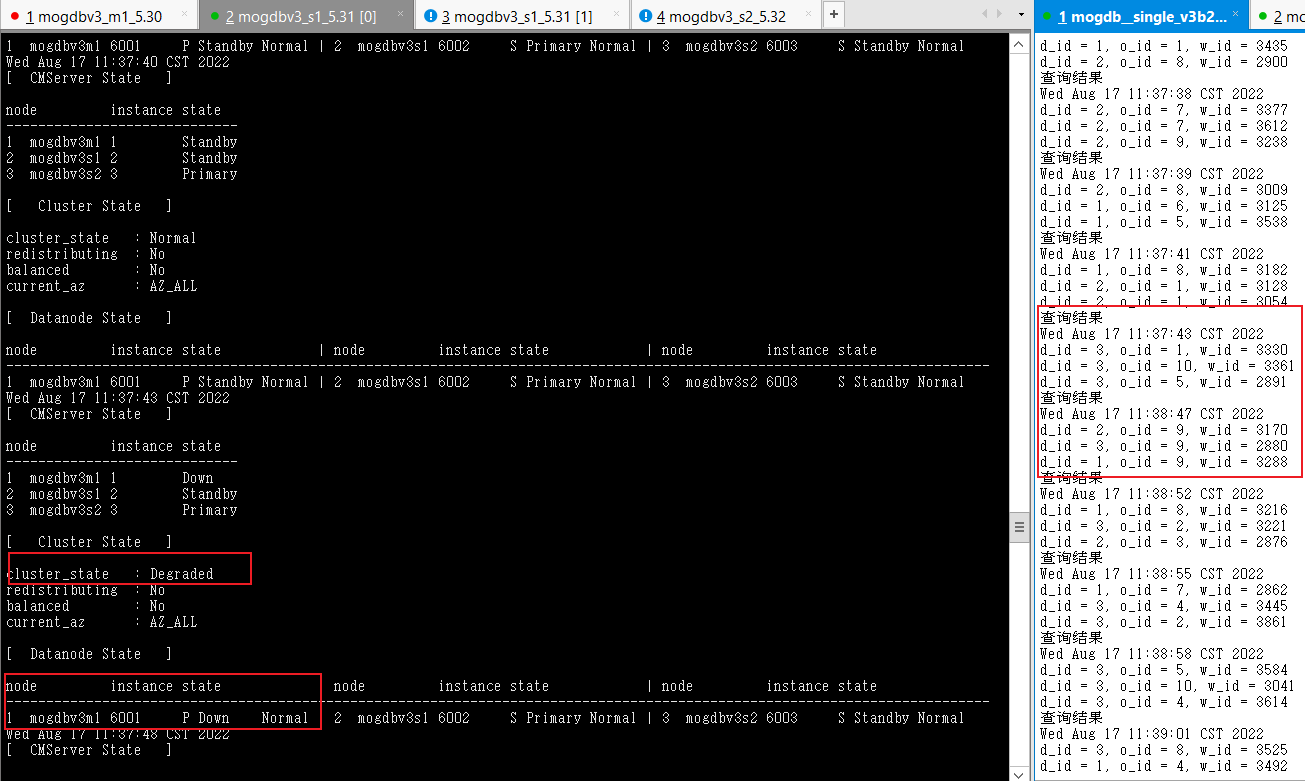
- 恢复宕机备库mogdbv3m1 ,恢复过程业务未出现等待。
- 结论:符合预期,但切换期间业务阻塞时间偏长。
2.1.2Sync从库主机宕机
测试目的:模拟Sync从库主机硬件故障,出现宕机。
测试方法:选定一个Sync从库,直接关闭电源,观察业务情况。
预期结果:任意一个从库故障期间,主库读写业务和另一个从库只读业务均正常,故障主机恢复后,宕机从库自动追平延迟
测试过程和结论:
- 切换前环境状态
[omm@mogdbv3s1 ~]$ gs_ctl query [2022-08-17 12:01:13.723][8405][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: sender_pid : 2614 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 1/6708EA60 sender_write_location : 1/6708EA60 sender_flush_location : 1/6708EA60 sender_replay_location : 1/6708EA60 receiver_received_location : 1/6708EA60 receiver_write_location : 1/6708EA60 receiver_flush_location : 1/6708EA60 receiver_replay_location : 1/6708EA60 sync_percent : 100% sync_state : Sync sync_priority : 1 sync_most_available : On channel : 192.168.5.31:26001-->192.168.5.32:47642 sender_pid : 6036 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 1/6708EA60 sender_write_location : 1/6708EA60 sender_flush_location : 1/6708EA60 sender_replay_location : 1/6708EA60 receiver_received_location : 1/6708EA60 receiver_write_location : 1/6708EA60 receiver_flush_location : 1/6708EA60 receiver_replay_location : 1/6708EA60 sync_percent : 100% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.31:26001-->192.168.5.30:58258复制
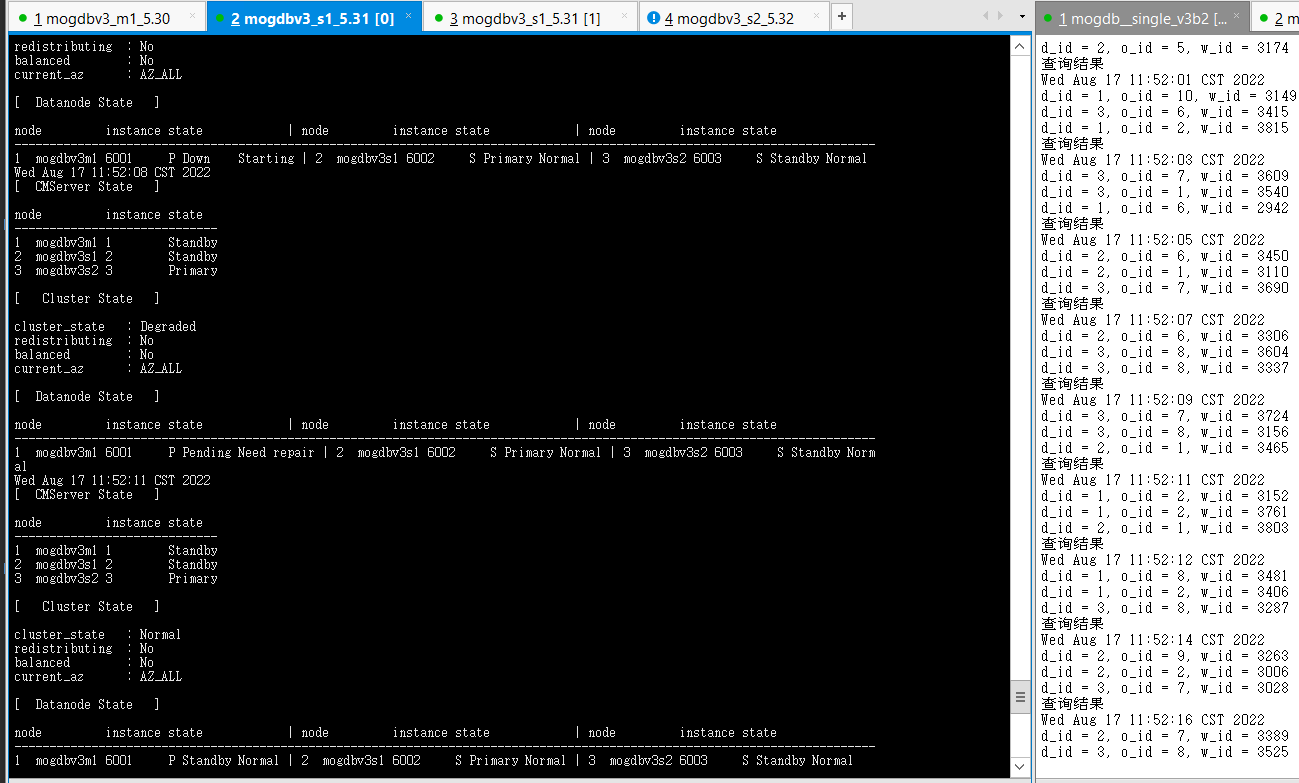
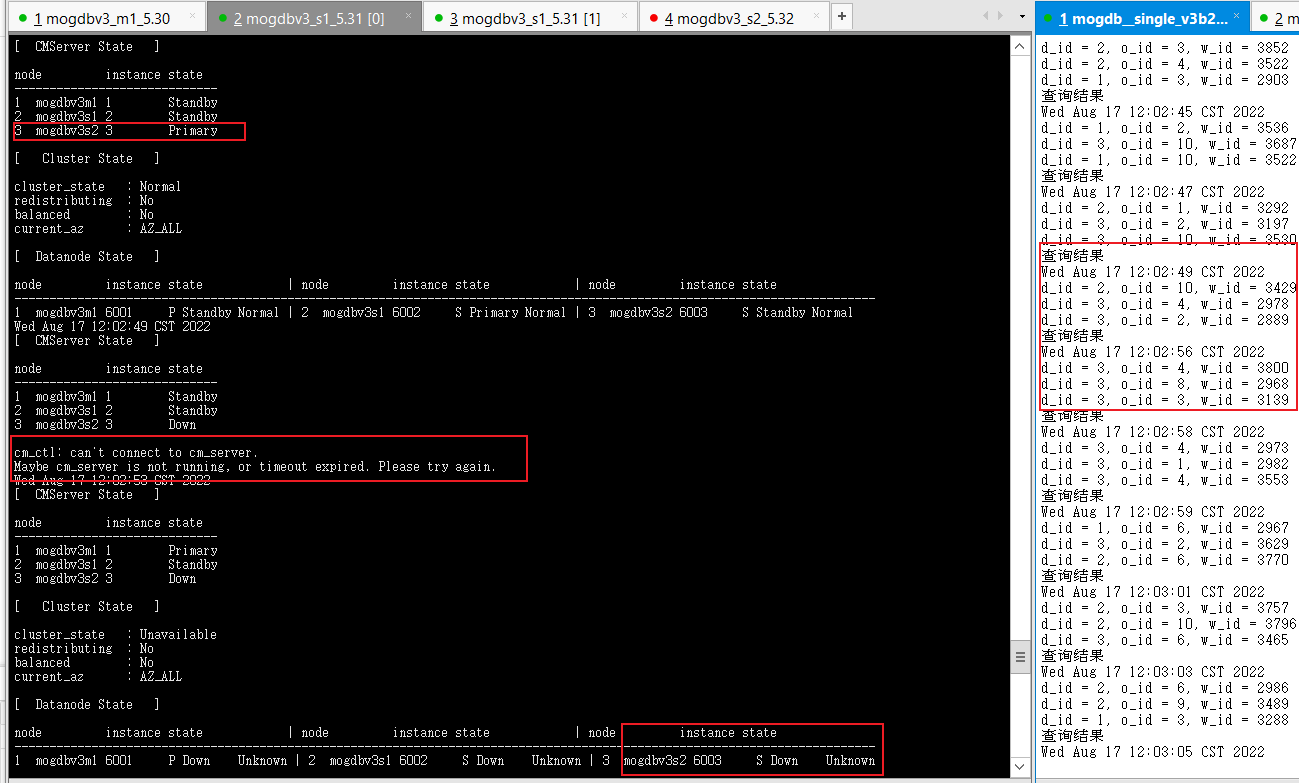
2. 关闭mogdbv3s2为从库的datanode节点,查看数据库状态和业务中断情况,测试业务jdbc连接存在5s左右的等待,但并未发生连接报错。由于cmserver主库也运行在该节点,测试触发切换cm命令持续2s左右不可用。
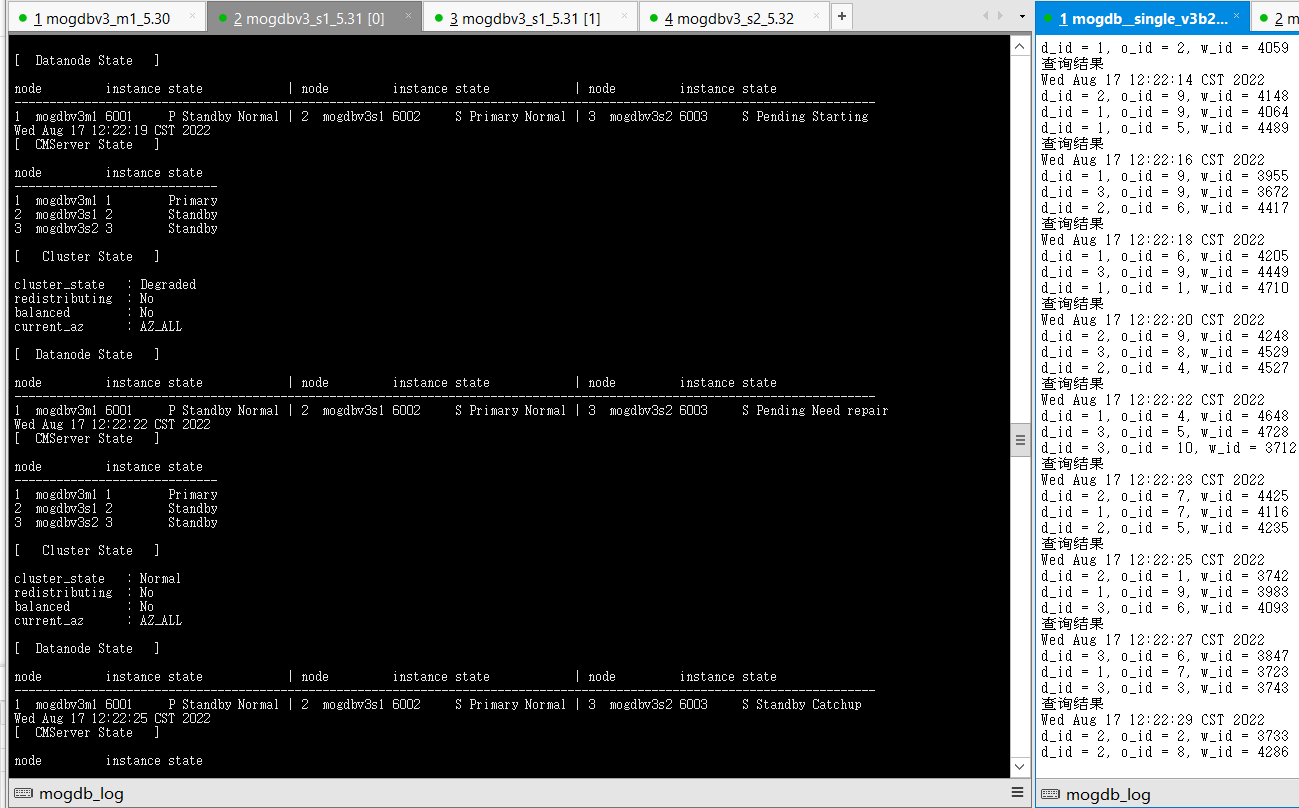
- 恢复宕机备库mogdbv3m1 ,恢复过程业务未出现等待。
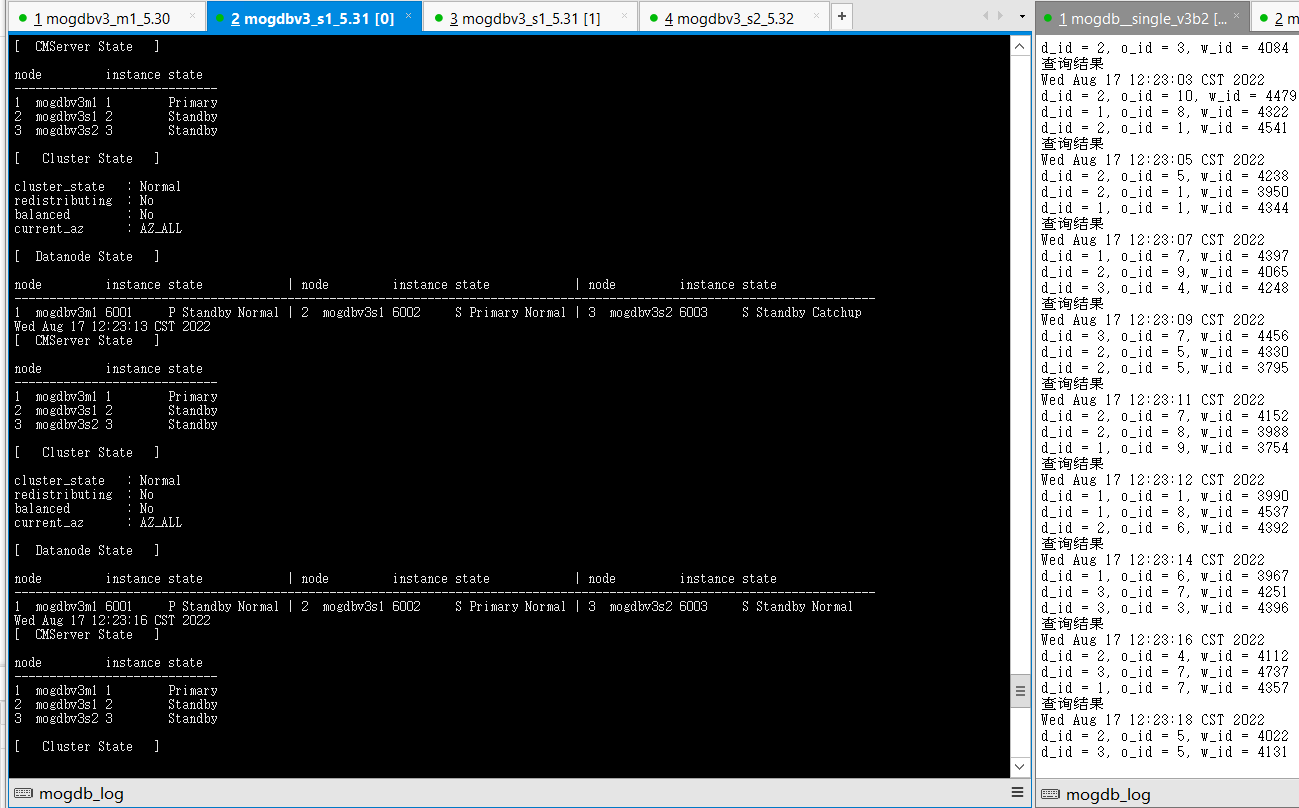
- 结论:符合预期。
2.1.3主库主机宕机
测试目的:模拟主库库主机硬件故障,出现宕机。
测试方法:直接关闭主库主机电源。
预期结果:主库主机宕机,业务中断若干秒后,在2个从库中选一台提升为新的主库,业务恢复正常,故障主机恢复后,宕机主库角色变为从库,并自动追平延迟。
测试过程和结论:
- 切换前环境状态
[omm@mogdbv3s1 ~]$ gs_ctl query [2022-08-17 13:24:27.061][30665][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: sender_pid : 14580 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 1/F86E1820 sender_write_location : 1/F86E1820 sender_flush_location : 1/F86E1820 sender_replay_location : 1/F86E1820 receiver_received_location : 1/F86E1820 receiver_write_location : 1/F86E1820 receiver_flush_location : 1/F86E1820 receiver_replay_location : 1/F86E1820 sync_percent : 100% sync_state : Sync sync_priority : 1 sync_most_available : On channel : 192.168.5.31:26001-->192.168.5.32:42666 sender_pid : 6036 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 1/F86E1820 sender_write_location : 1/F86E1820 sender_flush_location : 1/F86E1820 sender_replay_location : 1/F86E1820 receiver_received_location : 1/F86E1820 receiver_write_location : 1/F86D4690 receiver_flush_location : 1/F86D4690 receiver_replay_location : 1/F86B59F8 sync_percent : 99% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.31:26001-->192.168.5.30:58258复制
- 关闭mogdbv3s1为主库的node节点,查看数据库状态和业务中断情况,测试业务阻塞1分钟左右的,并产生连接报错,一分钟后新的主库产生,业务重连成功。
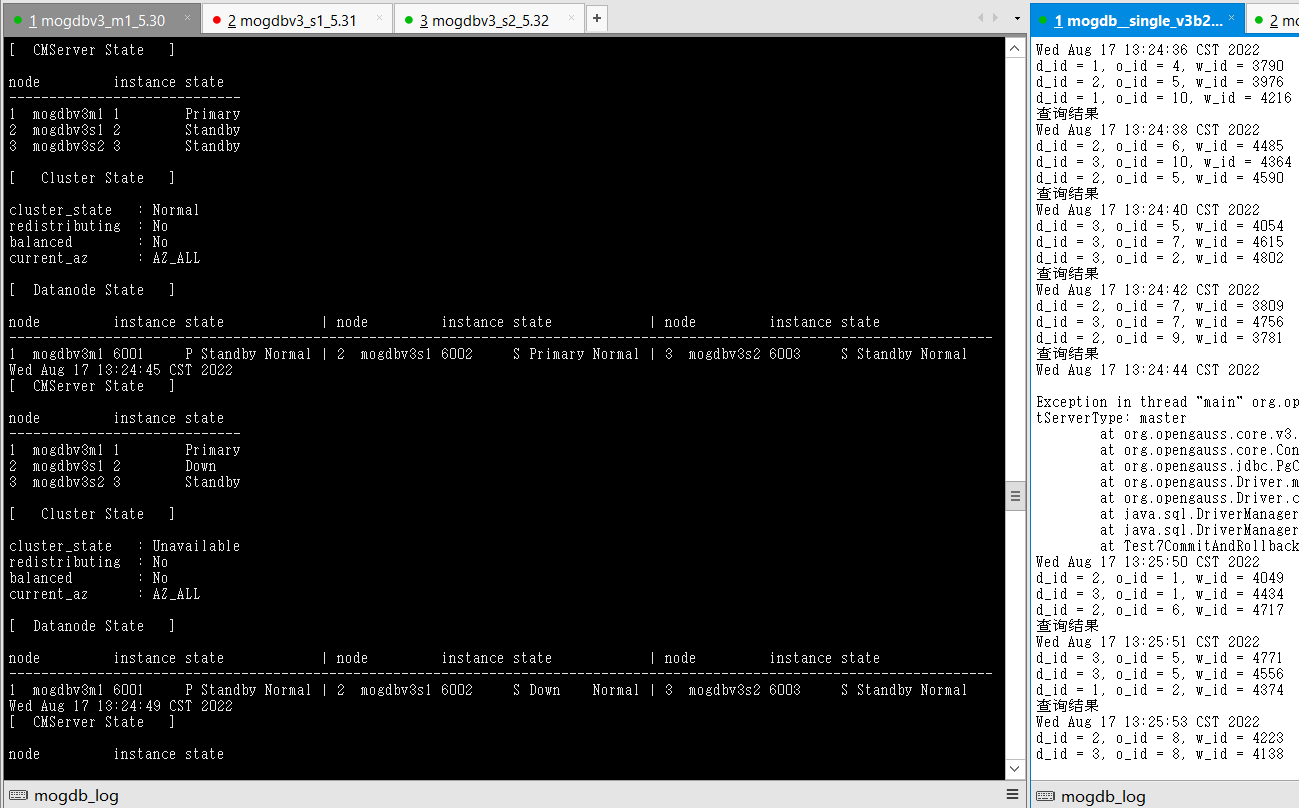
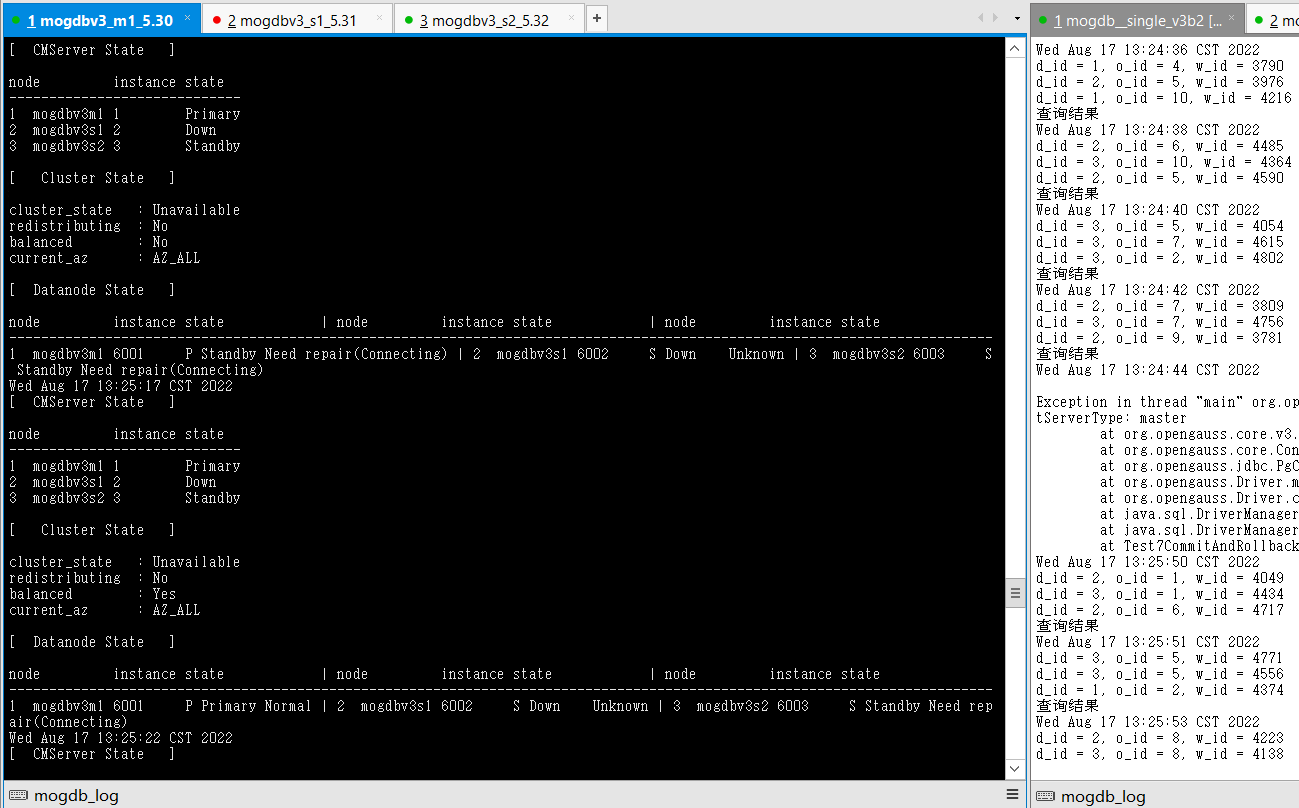
- 恢复宕机主库后自动和新主库追平,并成为备库。恢复期间测试业务未受影响。
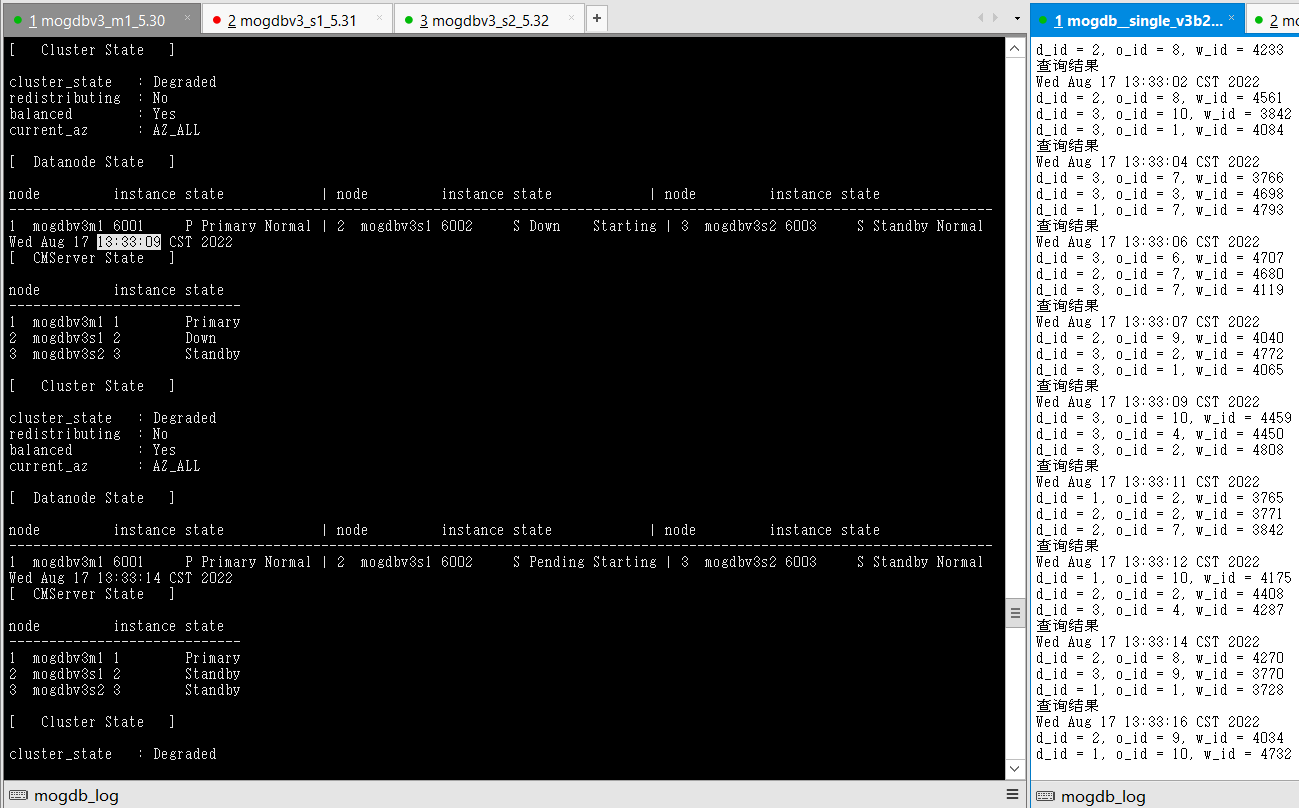
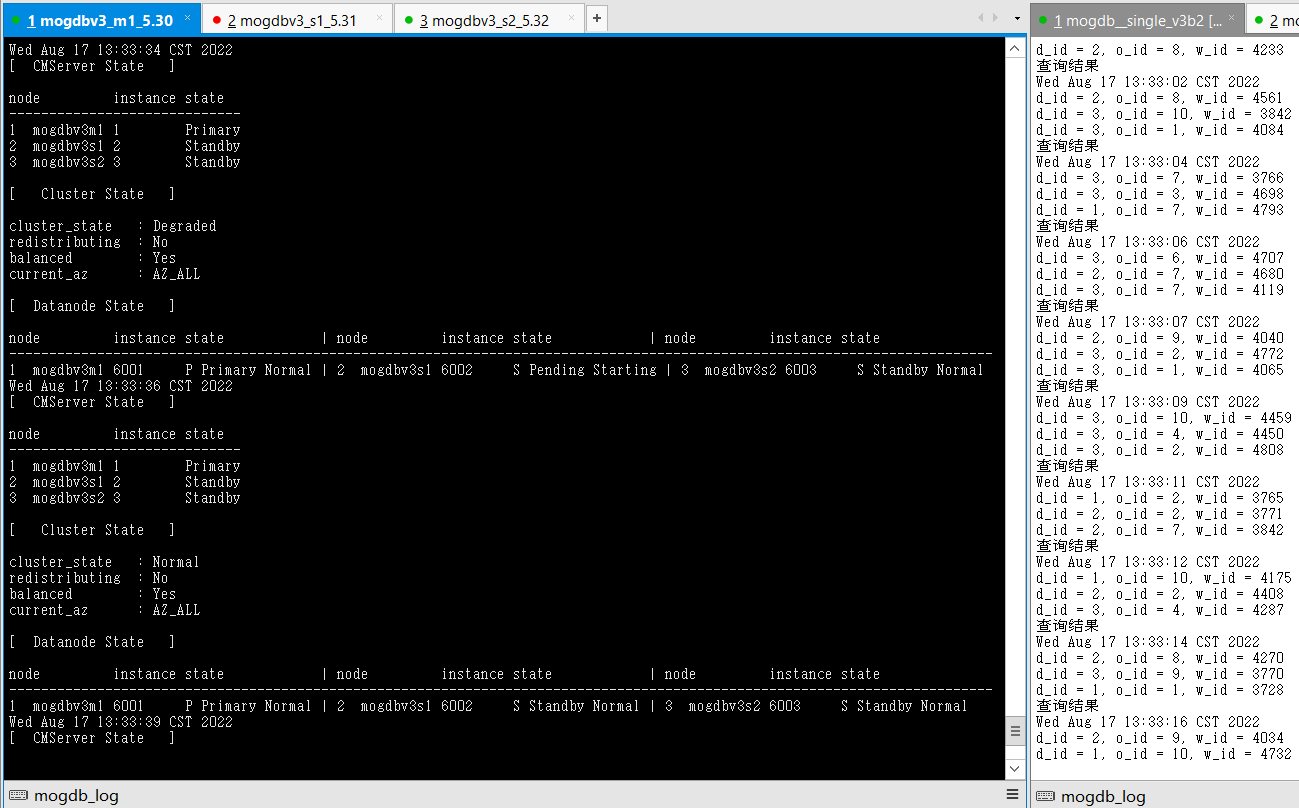
- 结论:符合预期,但切换过程业务阻塞时间较长。
2.1.4主库文件系统满
测试目的:模拟运行环境中的主库文件系统满。
测试方法:使用falloate命令创建文件,使mogdb软件和数据文件所在的目录,使用率100%。测试前需要设置CM的enable_transaction_read_only参数,执行_gs_guc set -Z cmserver -N all -I all -c "enable_transaction_read_only=off"降低CM对于此类异常的过度操作。
预期结果:主库无法写入导致数据异常宕库,在2个从库中选一台提升为新的主库,业务恢复正常。 故障主机恢复后,宕机主库角色变为从库,并自动追平延迟。
测试过程和结论:
- 正常状态
[omm@mogdbv3m1 ~]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.9G 0 7.9G 0% /dev tmpfs 7.9G 20K 7.9G 1% /dev/shm tmpfs 7.9G 8.9M 7.9G 1% /run tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup /dev/mapper/centos-root 92G 15G 77G 16% / /dev/sda1 1014M 137M 878M 14% /boot tmpfs 1.6G 0 1.6G 0% /run/user/0 tmpfs 1.6G 0 1.6G 0% /run/user/1000 [omm@mogdbv3m1 ~]$ echo $PGDATA /opt/mogdb/data [ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal复制
- 使用falloate命令填满mogdb家目录,主库由于无法写入宕库,mogdbv3s1节点升为主库。切换期间业务中断19s。cmserver 主节点由于也在该节点发生切换,导致cm命令中断4秒。
[omm@mogdbv3m1 ~]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.9G 0 7.9G 0% /dev tmpfs 7.9G 20K 7.9G 1% /dev/shm tmpfs 7.9G 8.9M 7.9G 1% /run tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup /dev/mapper/centos-root 92G 92G 900K 100% / /dev/sda1 1014M 137M 878M 14% /boot tmpfs 1.6G 0 1.6G 0% /run/user/0 tmpfs 1.6G 0 1.6G 0% /run/user/1000复制
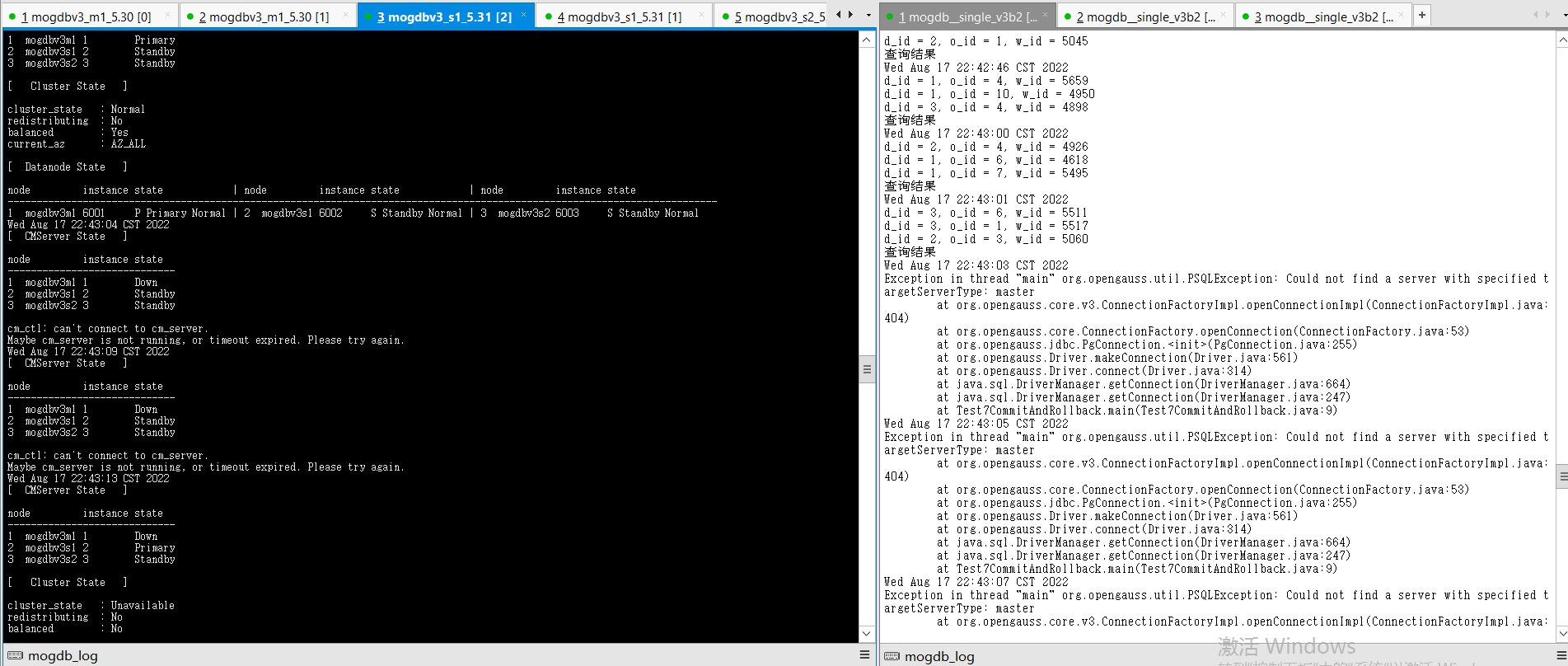
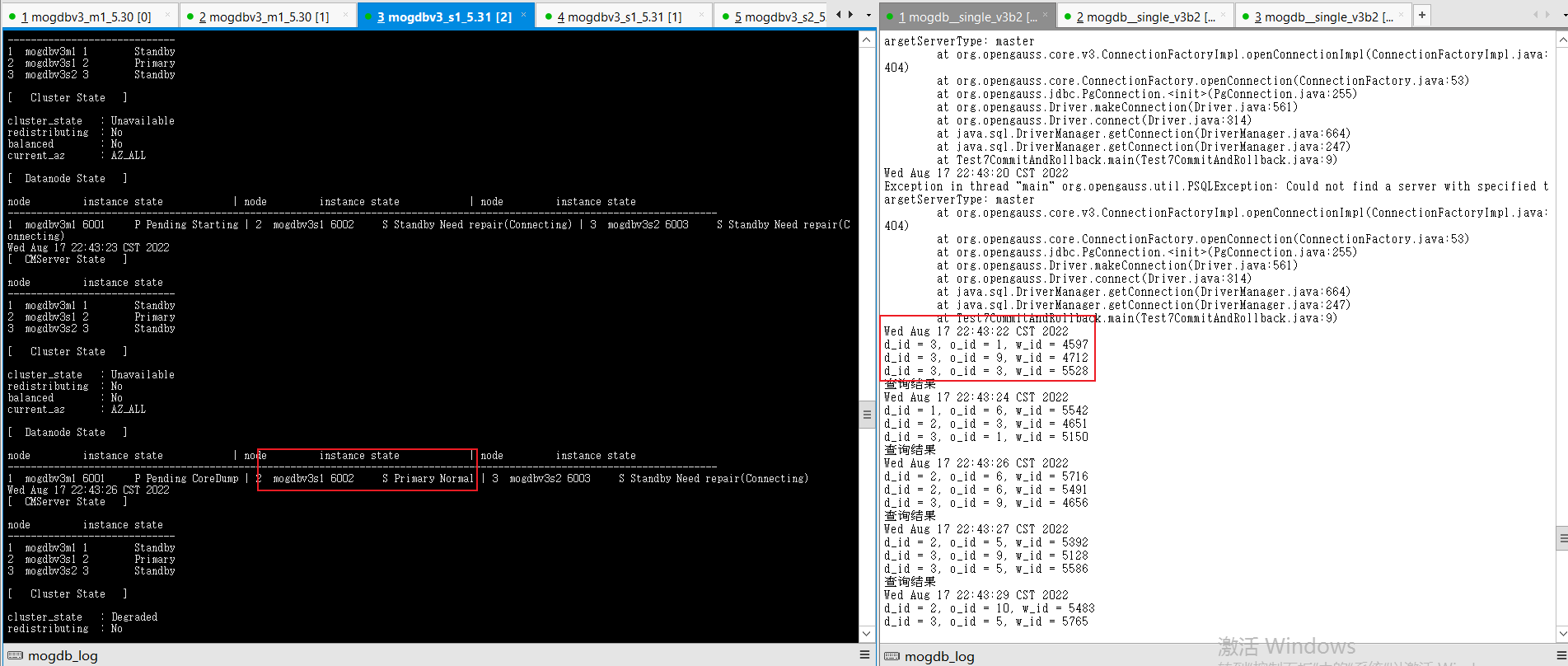
- 文件系统空间释放后,宕库节点自动启动,并重新进行build恢复正常状态,恢复期间业务不受影响。
- 结论:符合预期。
2.1.5从库文件系统满
测试方法:使用falloate命令创建文件,使某个从库mogdb软件和数据文件所在的目录,使用率100%。测试前需要设置CM的enable_transaction_read_only参数,执行_gs_guc set -Z cmserver -N all -I all -c "enable_transaction_read_only=off"降低CM对于此类异常的过度操作。
预期结果:从库无法写入导致数据库同步中断,并出现异常宕库,期间业务不受影响。故障节点从库恢复后,自动追平延迟。
测试过程和结论:
- 正常状态
[omm@mogdbv3s1 pg_xlog]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.9G 0 7.9G 0% /dev tmpfs 7.9G 20K 7.9G 1% /dev/shm tmpfs 7.9G 73M 7.8G 1% /run tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup /dev/mapper/centos-root 92G 25G 67G 27% / /dev/sda1 1014M 137M 878M 14% /boot tmpfs 1.6G 0 1.6G 0% /run/user/1000 tmpfs 1.6G 0 1.6G 0% /run/user/0 [omm@mogdbv3s1 pg_xlog]$ echo $PGDATA /opt/mogdb/data [omm@mogdbv3s1 pg_xlog]$ cm_ctl query -vC; [ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state------------------------------------------------------------------------------------------------------- --------------------1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal复制
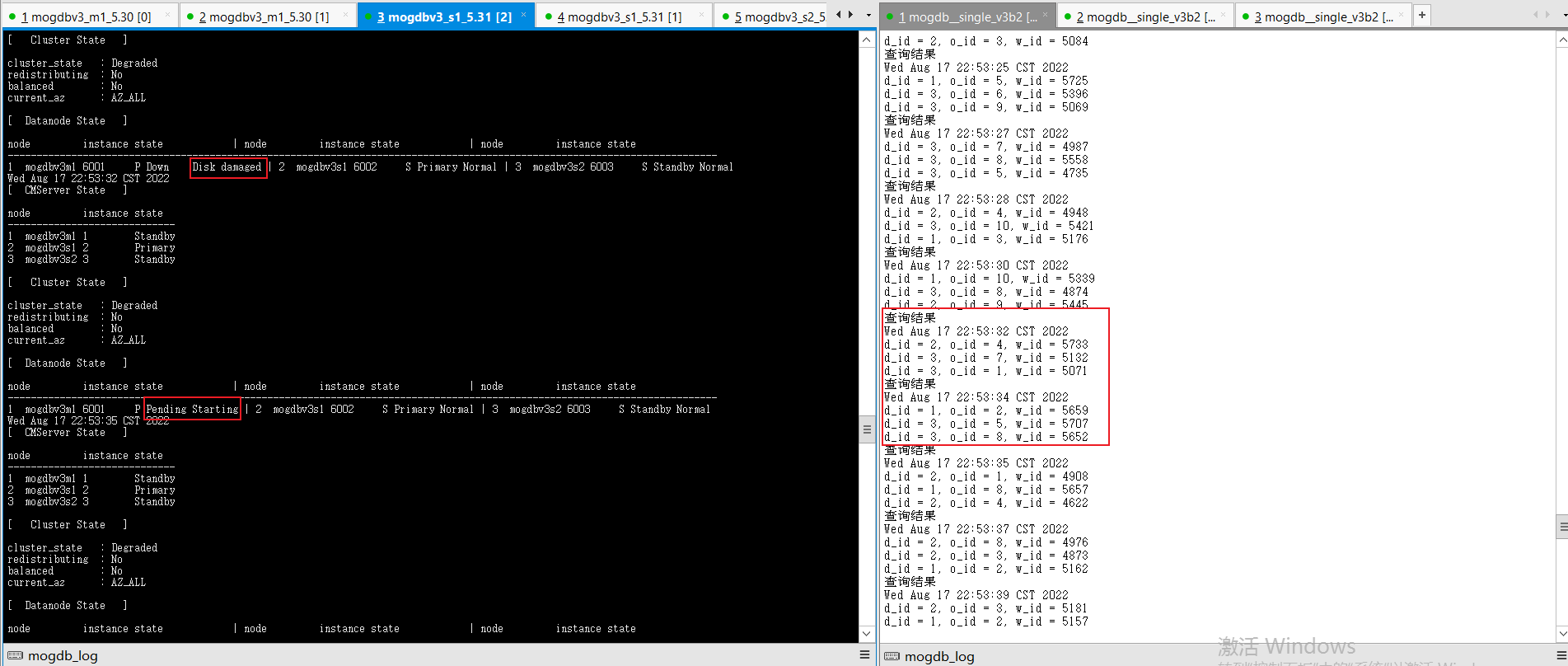
- 使用falloate命令填满mogdbv3s1节点mogdb家目录,从库由于由于无法写入宕库,宕库后CM尝试拉起数据库失败,从库状态变为 Standby Need repair(Connecting)最终显示为Disk damaged状态,期间业务未受影响。
[root@mogdbv3s1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.9G 0 7.9G 0% /dev tmpfs 7.9G 20K 7.9G 1% /dev/shm tmpfs 7.9G 73M 7.8G 1% /run tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup /dev/mapper/centos-root 92G 92G 428K 100% / /dev/sda1 1014M 137M 878M 14% /boot tmpfs 1.6G 0 1.6G 0% /run/user/1000 tmpfs 1.6G 0 1.6G 0% /run/user/0复制
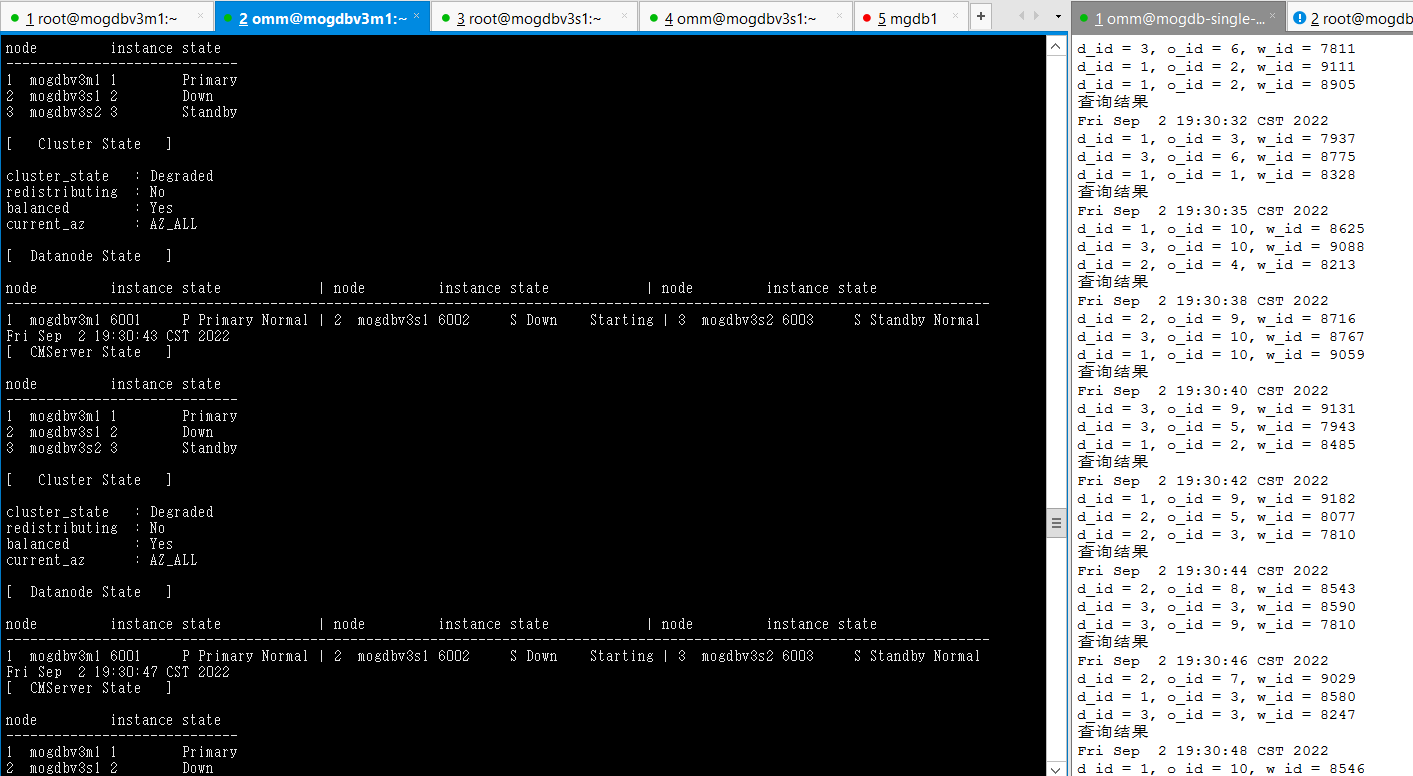
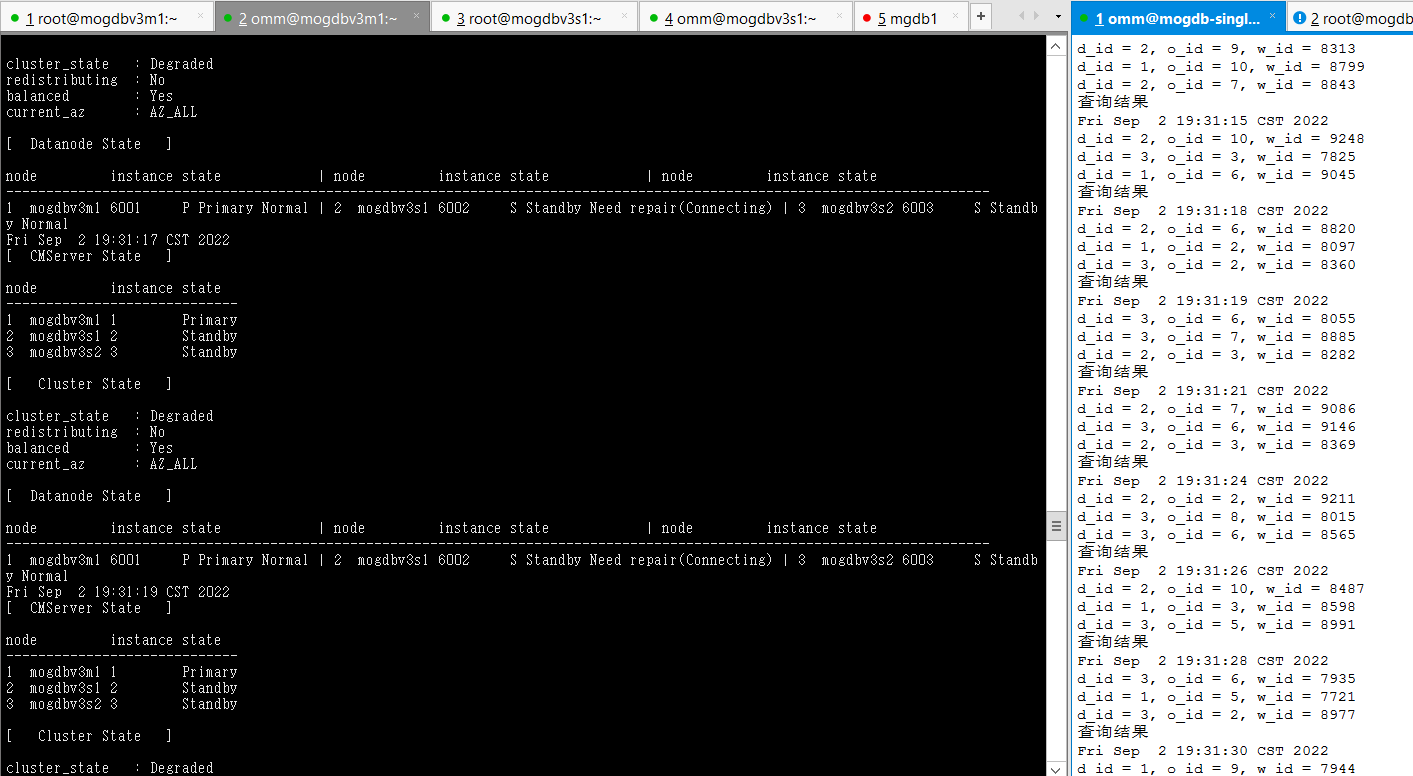
-
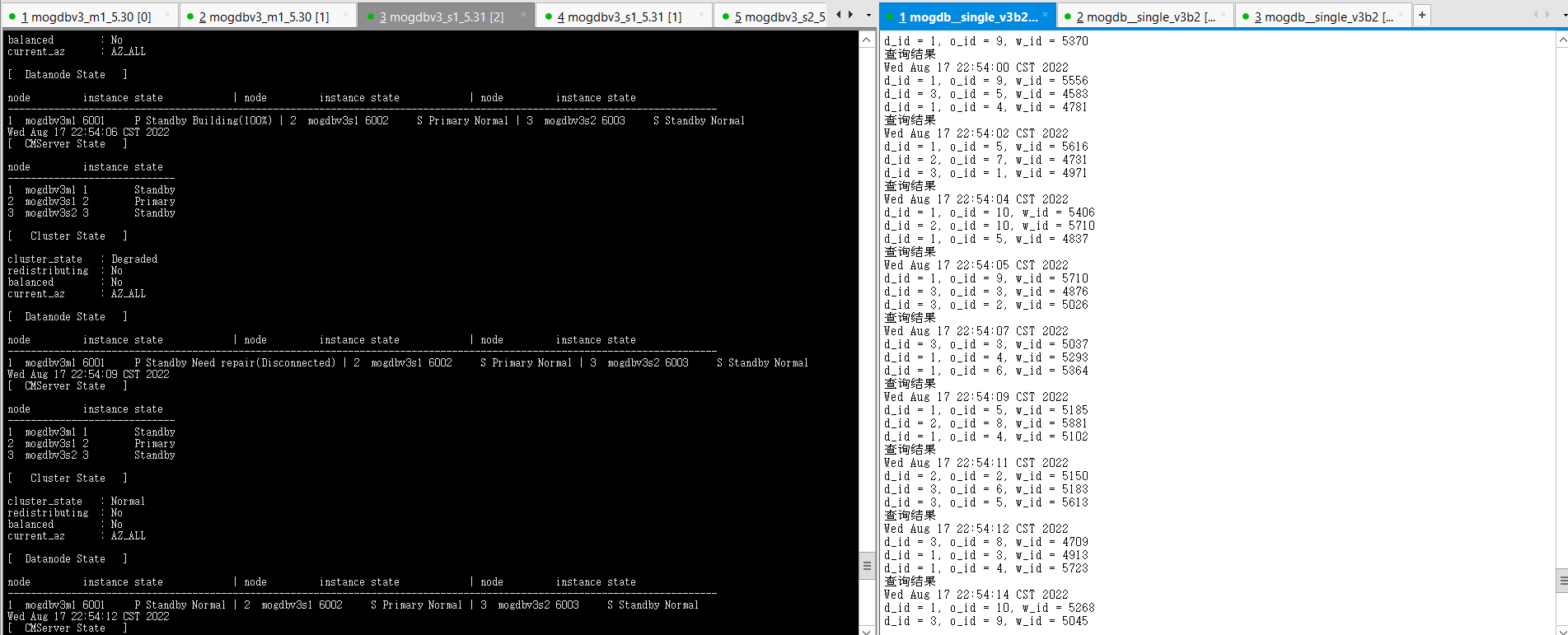
文件系统空间释放后,宕库节点自动启动,并进行Catchup恢复正常状态,恢复期间业务不受影响。
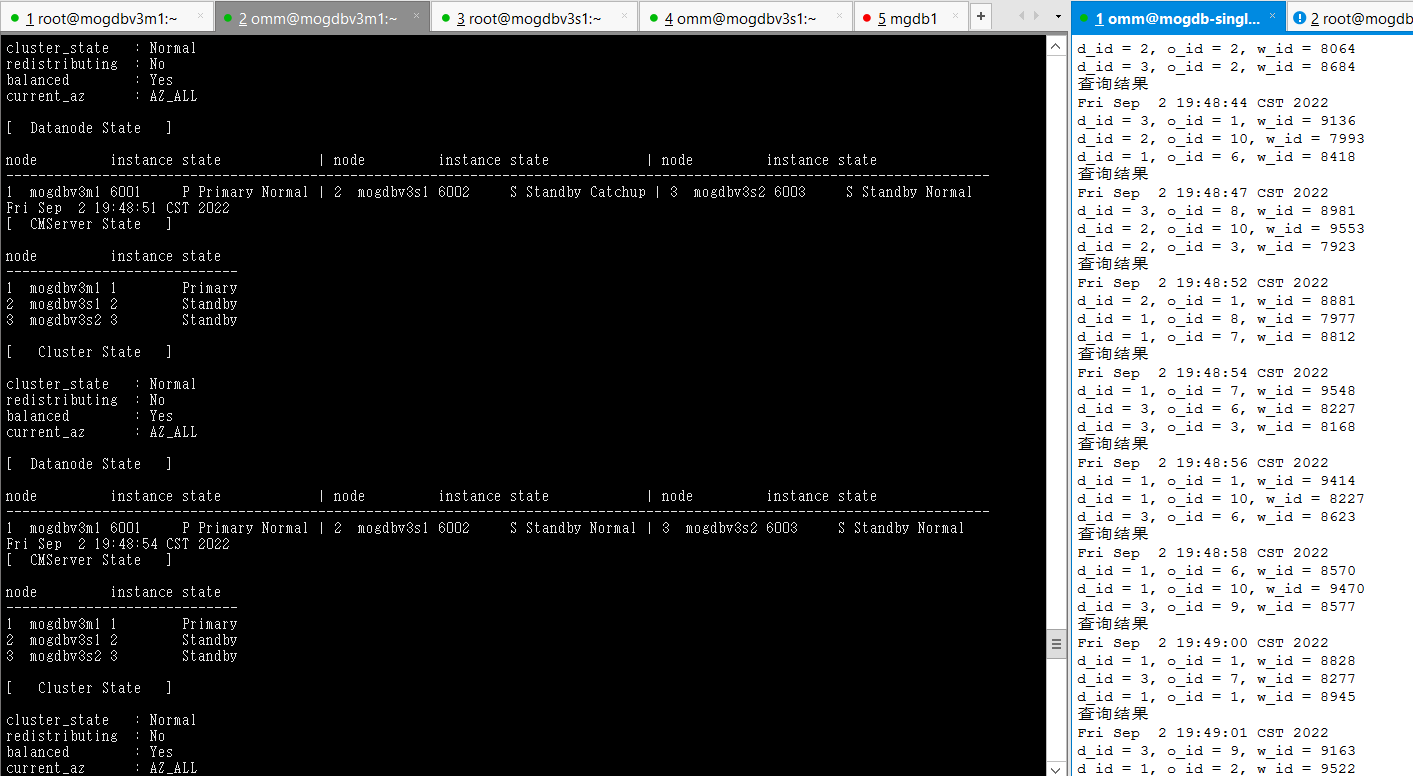
-
结论:符合预期。
2.1.6主库内存不足
测试目的:模拟主库主机内存不足。
测试方法:使用strees命令模拟主机物理内存和swap均降至0。
预期结果:主库随着内存使用率不断上升,性能逐渐下降,直至出现OOM后主库出现宕库,主库宕库后,在2个从库中选一台提升为新的主库。内存不足主机恢复后,宕库主库角色变为从库,并自动追平延迟。
测试过程和结论:
- 正常状态

[ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : No current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Standby Normal | 2 mogdbv3s1 6002 S Primary Normal | 3 mogdbv3s2 6003 S Standby Normal复制
- 在mogdbv3m1服务使用stress --vm 200 --vm-bytes 1280M --vm-hang 0 命令,尽快消耗该主机内存至0,一旦物理内存被消耗完,开始使用swap时数据库响应明显变慢,直至swap消耗完,主机出现OOM。CM检测到到该节点异常,CM状态显示数据库状态为down该过程耗时26s,mogdbv3s1进行角色转换为主库,业务恢复正常,该场景下整个切换过程耗时130s后,业务恢复正常。
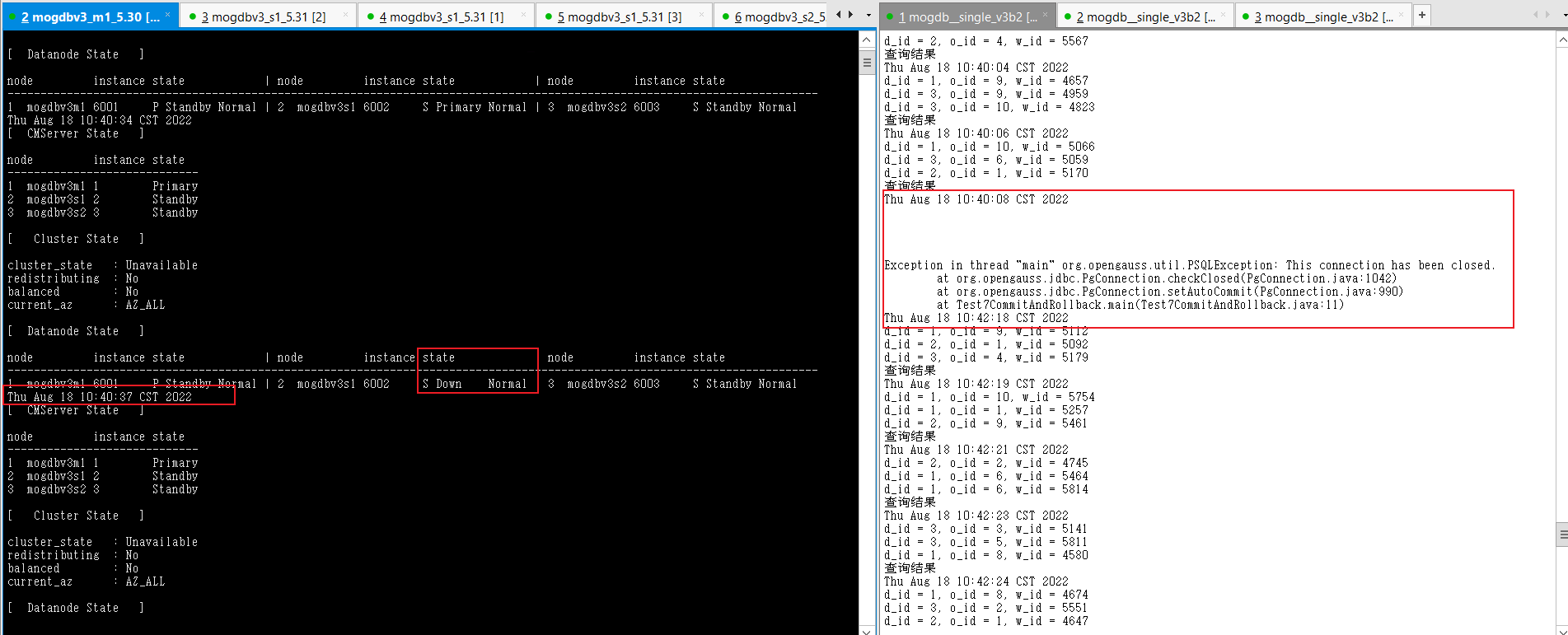
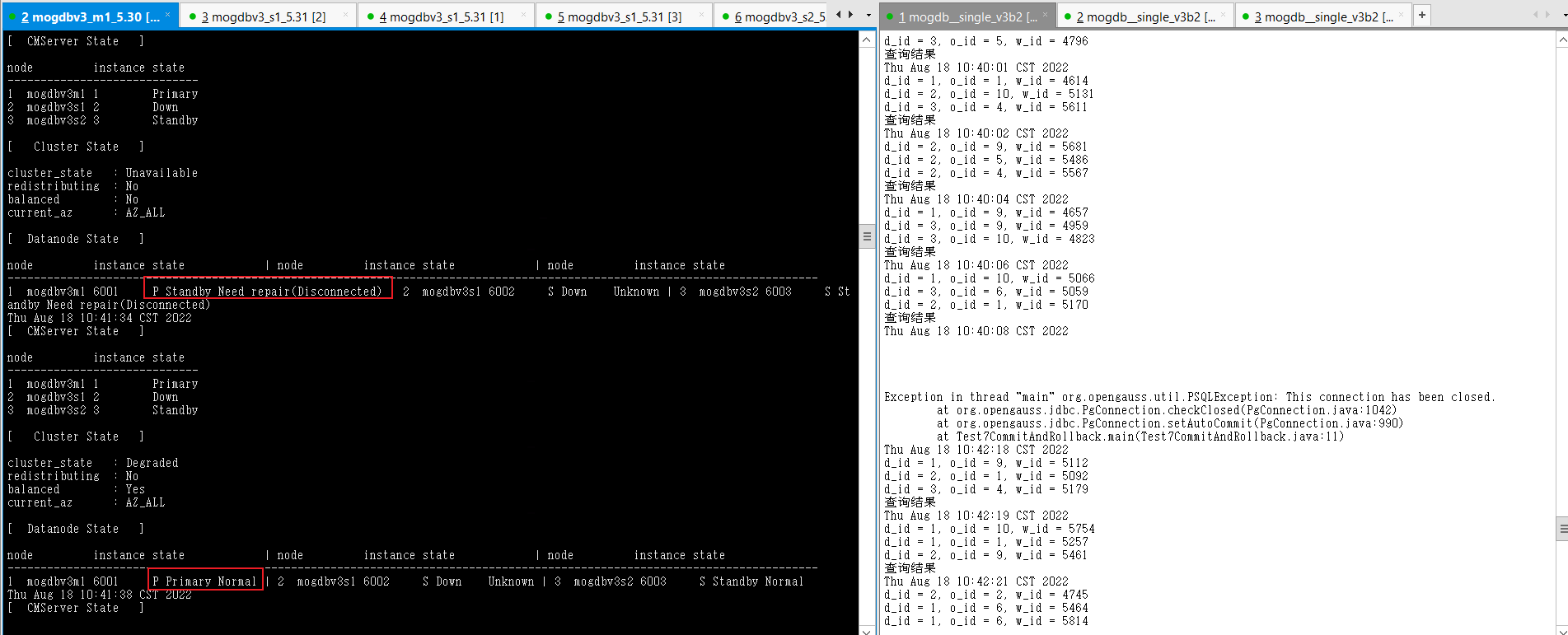
- mogdbv3s1主机操作系统触发oom后,消耗内存的进程被kill,物理内存恢复正常。CM检测到物理内存恢复正常后,自动拉起数据库,拉起后数据库角色变为备库,期间业务未受影响。
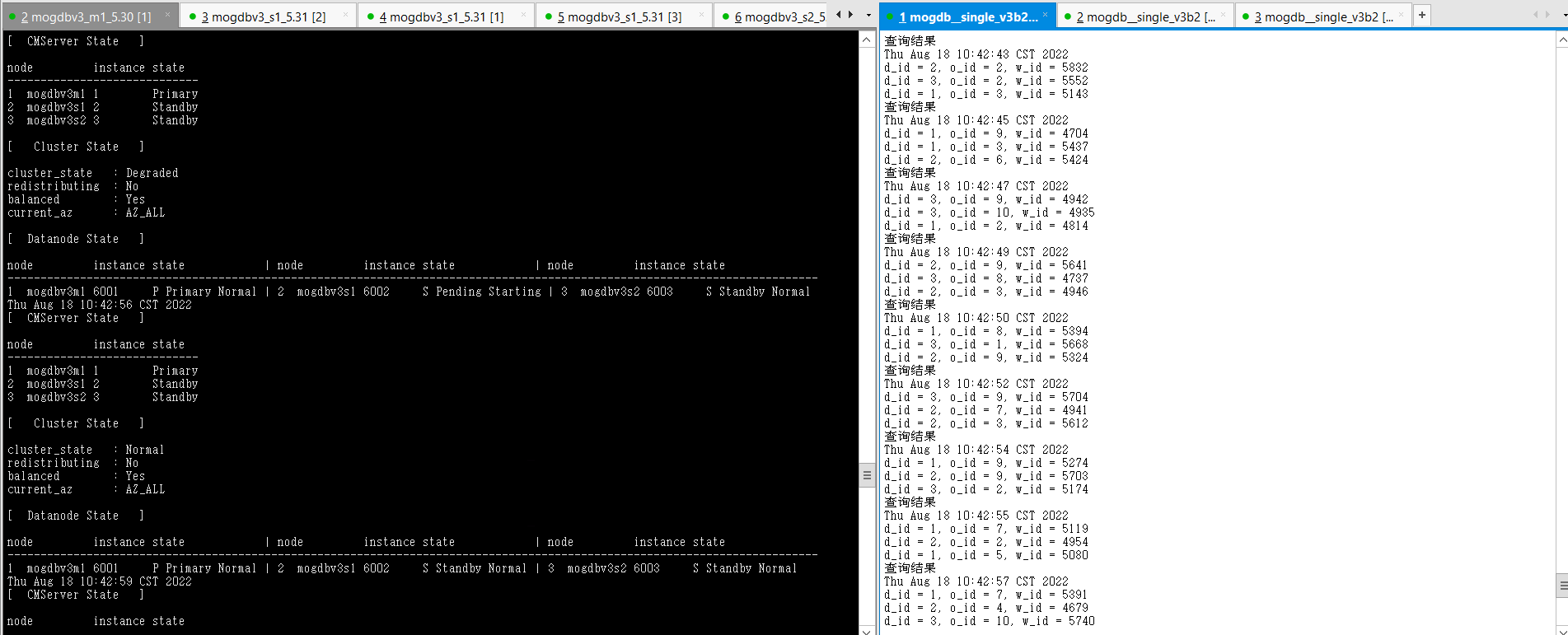
- 结论:符合预期,推荐业务类型为OLTP,物理内存充裕尽量减少SWAP分配或者关闭SWAP,当采用此种配置遇到内存不足时,问题节点可以尽快宕机,加速选主过程以使业务得以更快恢复。
2.2网络问题
2.2.1datanode和cmnode两个备之间网络异常。
测试目的: 测试DataNode两个从节点和CMServer Node两个从节点间网络中断场景。
测试方法:当DataNode和 CMServer Node所在的节点都为从环境,使用firewall隔离DataNode和CMServer Node 两个从节点之间的网络。CMServer Node从环境访问主环境正常。
预期结果:DataNode复制状态,数据库对外业务未受影响。CMServer有一个从节点instance状态变为down,
测试过程和结论:
- 正常状态,尚未开启防火墙。
node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal复制
-
配置好firewall规则,启动3个几点的firewall服务,mogdbv3s1和mogdbv3s2节点相互无法ping通。DataNode复制状态正常,CMServer Node各个节点状态未受影响
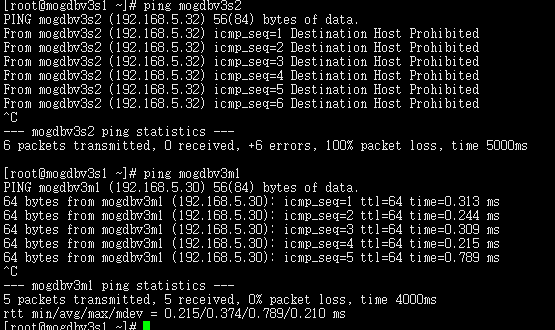
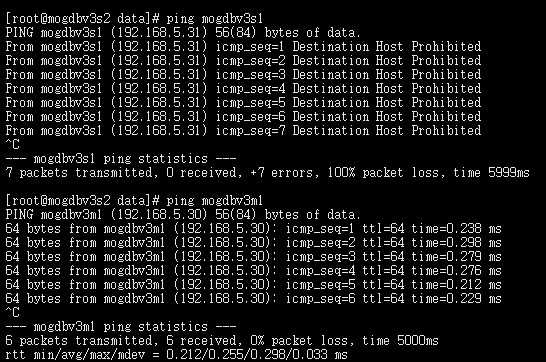
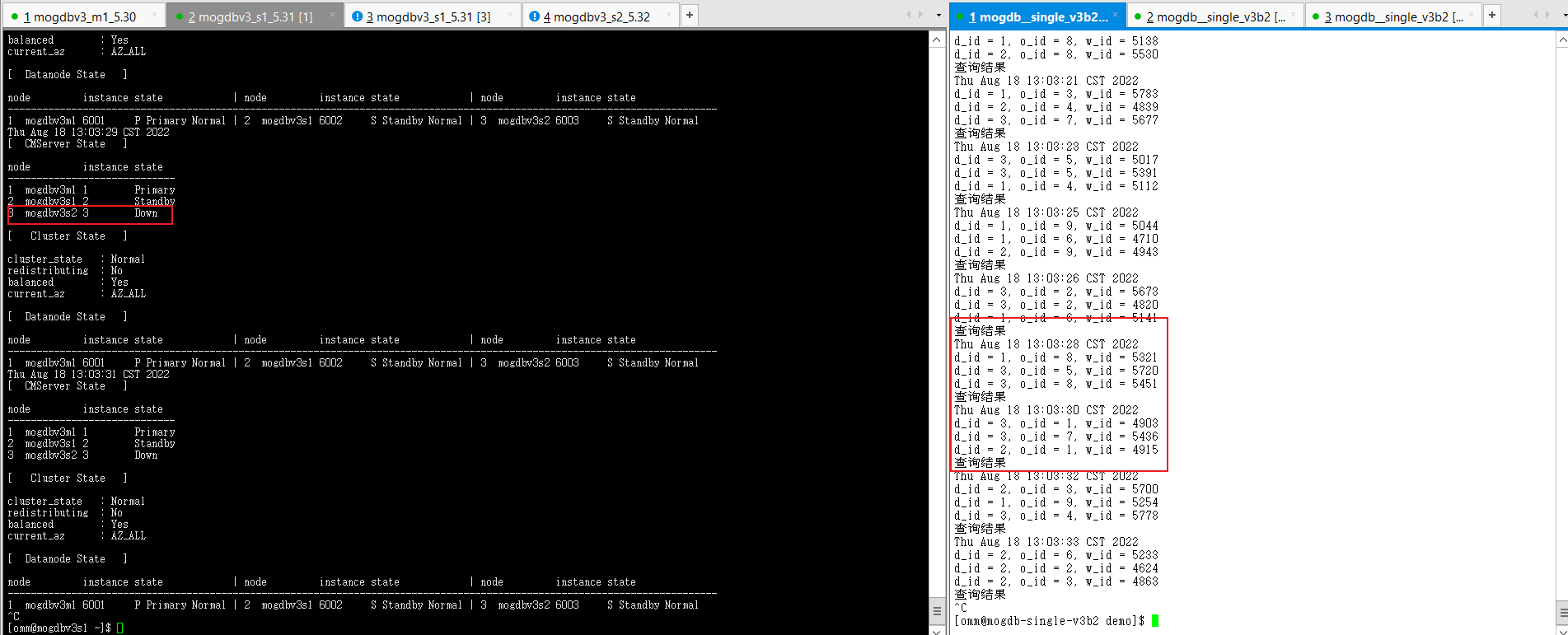
-
停止firewall服务后,mogdbv3s2下的cmserver instance 恢复正常。数据库业务未受影响。
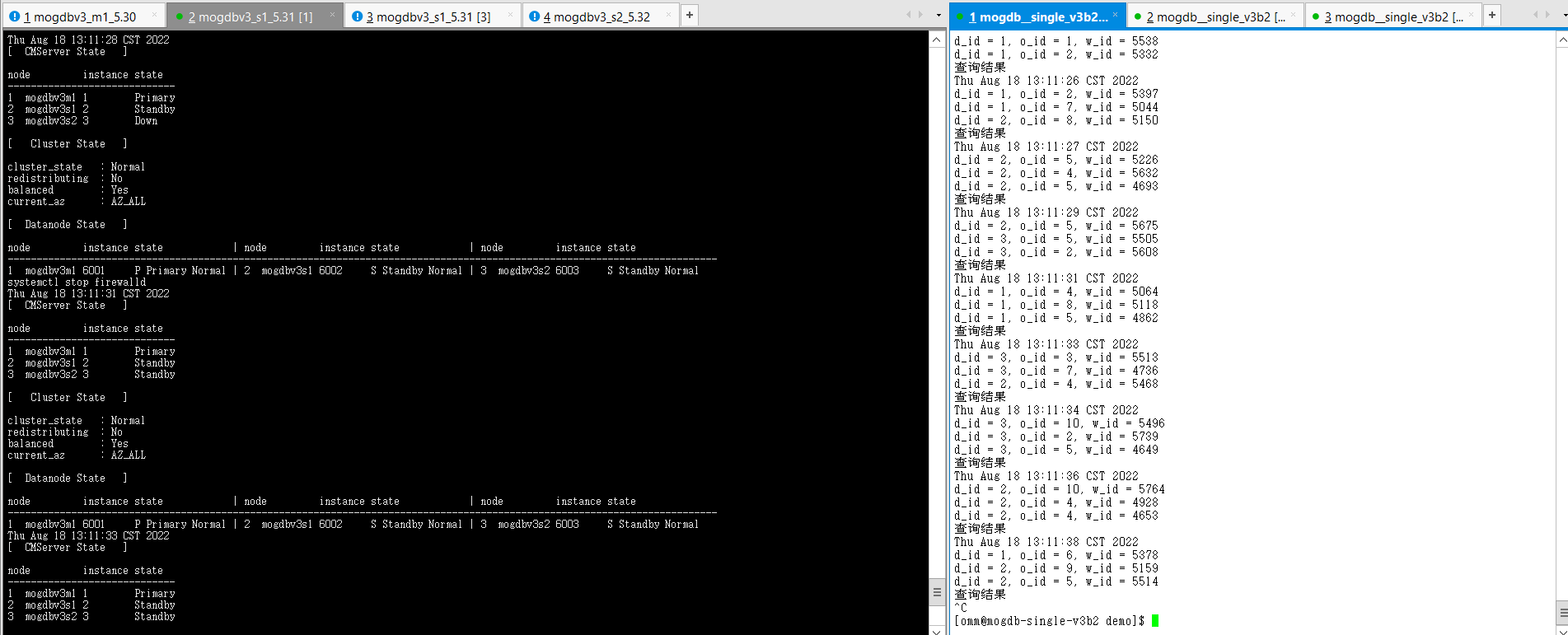
-
结论:符合预期
2.2.2一主一Potential从之间网络不通
测试目的: 测试DataNode主节点和Potential从节点,CMServer Node主节点和一个从节点之前网络中断场景。
测试方法:使用firewall隔离mogdbv3m1和mogdbv3s2之间的DataNode和CMServer Node网络。
预期结果:DataNode mogdbv3m1和mogdbv3s2之间复制中断,数据库对外业务未受影响。CMServer 有一个从节点instance状态变为down,
测试过程和结论:
- 测试前防火墙配置规则,尚未开启防火墙时集群同步状态。
[omm@mogdbv3m1 ~]$ gs_ctl query [2022-08-18 17:11:17.783][25525][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: sender_pid : 25003 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 2/B5889CD0 sender_write_location : 2/B5889CD0 sender_flush_location : 2/B5889CD0 sender_replay_location : 2/B5889CD0 receiver_received_location : 2/B5889CD0 receiver_write_location : 2/B5889CD0 receiver_flush_location : 2/B5889CD0 receiver_replay_location : 2/B5889CD0 sync_percent : 100% sync_state : Sync sync_priority : 1 sync_most_available : On channel : 192.168.5.30:26001-->192.168.5.31:53976 sender_pid : 25004 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 2/B5889CD0 sender_write_location : 2/B5889CD0 sender_flush_location : 2/B5889CD0 sender_replay_location : 2/B5889CD0 receiver_received_location : 2/B5889CD0 receiver_write_location : 2/B5889CD0 receiver_flush_location : 2/B5889CD0 receiver_replay_location : 2/B5889CD0 sync_percent : 100% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.30:26001-->192.168.5.32:41596` [ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal`复制
[root@mogdbv3m1 ~]# firewall-cmd --zone=drop --list-all drop (active) target: DROP icmp-block-inversion: no interfaces: sources: 192.168.5.32 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3m1 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: sources: 192.168.5.31 192.168.5.20 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:` [root@mogdbv3s1 ~]# firewall-cmd --zone=drop --list-all drop target: DROP icmp-block-inversion: no interfaces: sources: services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3s1 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: sources: 192.168.5.20 192.168.5.30 192.168.5.32 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:` [root@mogdbv3s2 ~]# firewall-cmd --zone=drop --list-all drop (active) target: DROP icmp-block-inversion: no interfaces: sources: 192.168.5.30 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3s2 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: ens192 sources: 192.168.5.20 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:`复制
- 启动3个节点已配置规则的firewall,DataNode主节点mogdbv3m1和Potential从节点mogdbv3s2之间网络中断,mogdbv3s2从库处于down状态,业务未受影响。各个CMServer Node状态均正常。
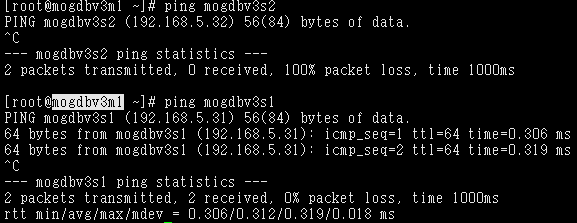
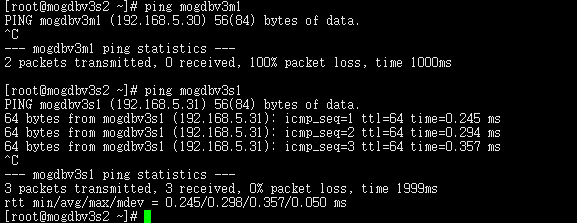

3. 关闭三个节点网络防火墙约2s后,mogdbv3s2节点的Potential从库开始自动恢复,期间业务未受影响。
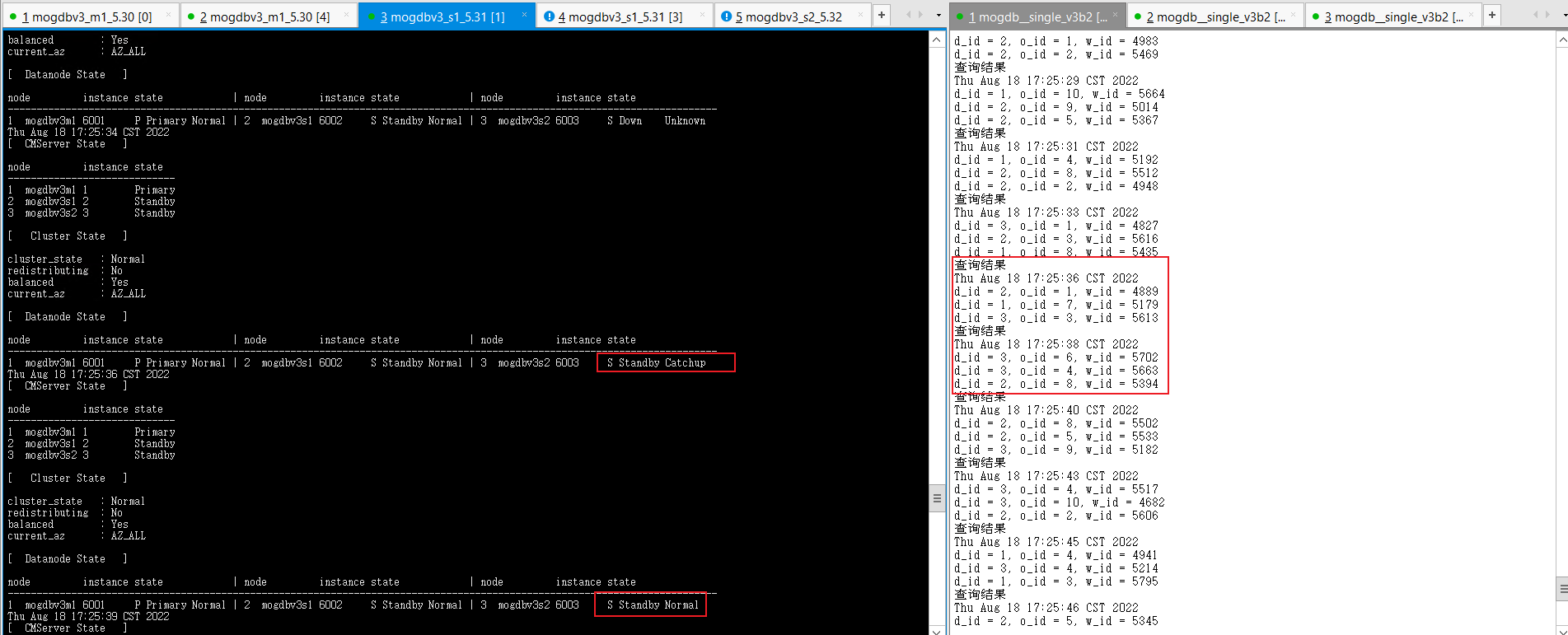
4. 结论:测试符合预期
2.2.3一主一Sync备库之间网络不通
测试目的: 测试DataNode主节点和Potential从节点,CMServer Node主节点和一个从节点之前网络中断场景。
测试方法:使用firewall隔离mogdbv3m1和mogdbv3s1之间的DataNode和CMServer Node网络。
预期结果:DataNode复制状态,数据库对外业务未受影响。CMServer 有一个从节点instance状态显示异常。
测试过程和结论:
- 测试前防火墙配置规则,尚未开启防火墙,集群的同步状态。
[root@mogdbv3s1 ~]# firewall-cmd --zone=drop --list-all drop (active) target: DROP icmp-block-inversion: no interfaces: sources: 192.168.5.30 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3s1 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: sources: 192.168.5.20 192.168.5.32 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:` [root@mogdbv3m1 ~]# firewall-cmd --zone=drop --list-all drop (active) target: DROP icmp-block-inversion: no interfaces: sources: 192.168.5.31 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3m1 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: sources: 192.168.5.20 192.168.5.32 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:复制
[omm@mogdbv3m1 ~]$ gs_ctl query [2022-08-19 08:07:19.773][31183][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: sender_pid : 7037 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 2/D3B021D8 sender_write_location : 2/D3B021D8 sender_flush_location : 2/D3B021D8 sender_replay_location : 2/D3B021D8 receiver_received_location : 2/D3B021D8 receiver_write_location : 2/D3B021D8 receiver_flush_location : 2/D3B021D8 receiver_replay_location : 2/D3B021D8 sync_percent : 100% sync_state : Sync sync_priority : 1 sync_most_available : On channel : 192.168.5.30:26001-->192.168.5.31:54904 sender_pid : 7039 local_role : Primary peer_role : Standby peer_state : Normal state : Streaming sender_sent_location : 2/D3B021D8 sender_write_location : 2/D3B021D8 sender_flush_location : 2/D3B021D8 sender_replay_location : 2/D3B021D8 receiver_received_location : 2/D3B021D8 receiver_write_location : 2/D3B021D8 receiver_flush_location : 2/D3B021D8 receiver_replay_location : 2/D3B00A10 sync_percent : 100% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.30:26001-->192.168.5.32:44410 Receiver info: No information [ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal`复制
-
启动3个节点已配置规则的firewall,DataNode主节点mogdbv3m1和Sync从节点mogdbv3s1之间网络中断,CM集群状态中显示mogdbv3s1从库处于down状态,期间业务未受影响。从mogdbv3s2观察各个CMServer Node状态均正常,但实际在mogdbv3s1执行cm_clt命令报无法连接cm_server错误。
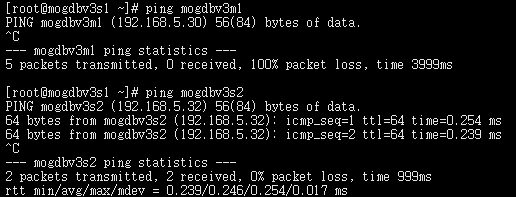

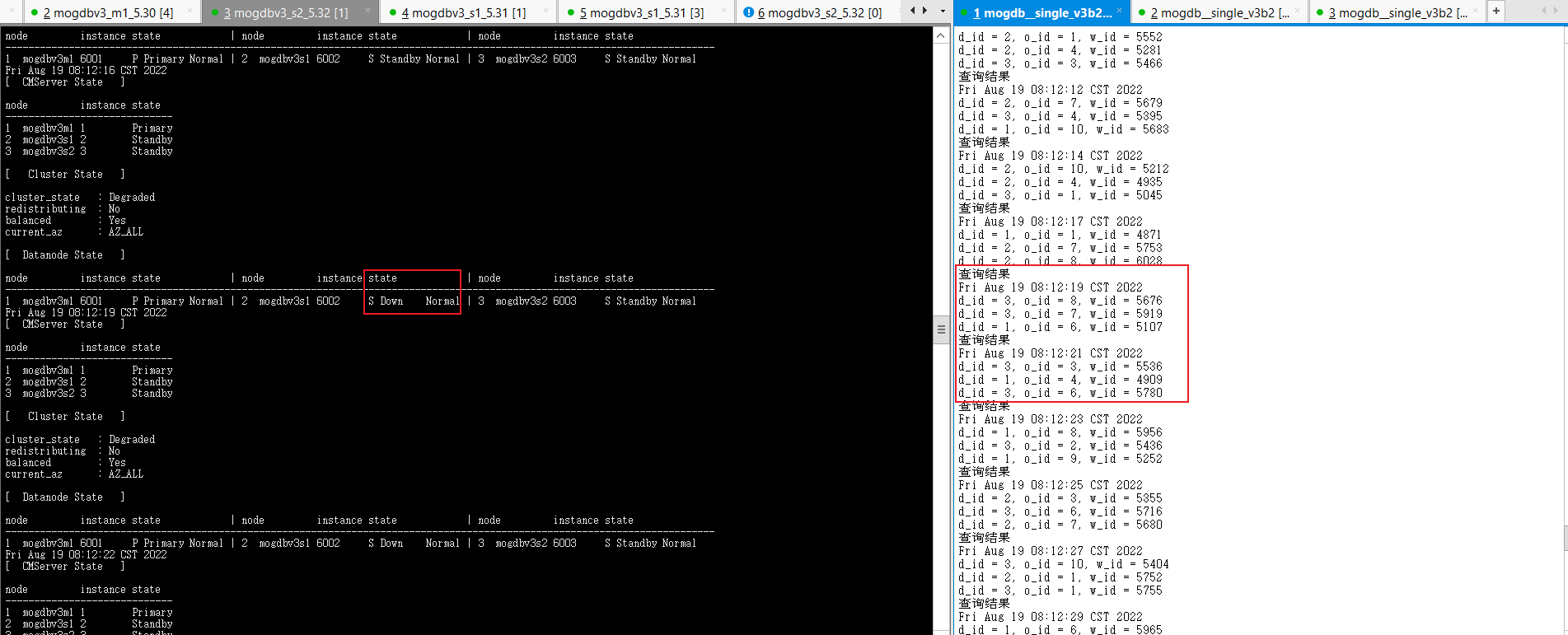
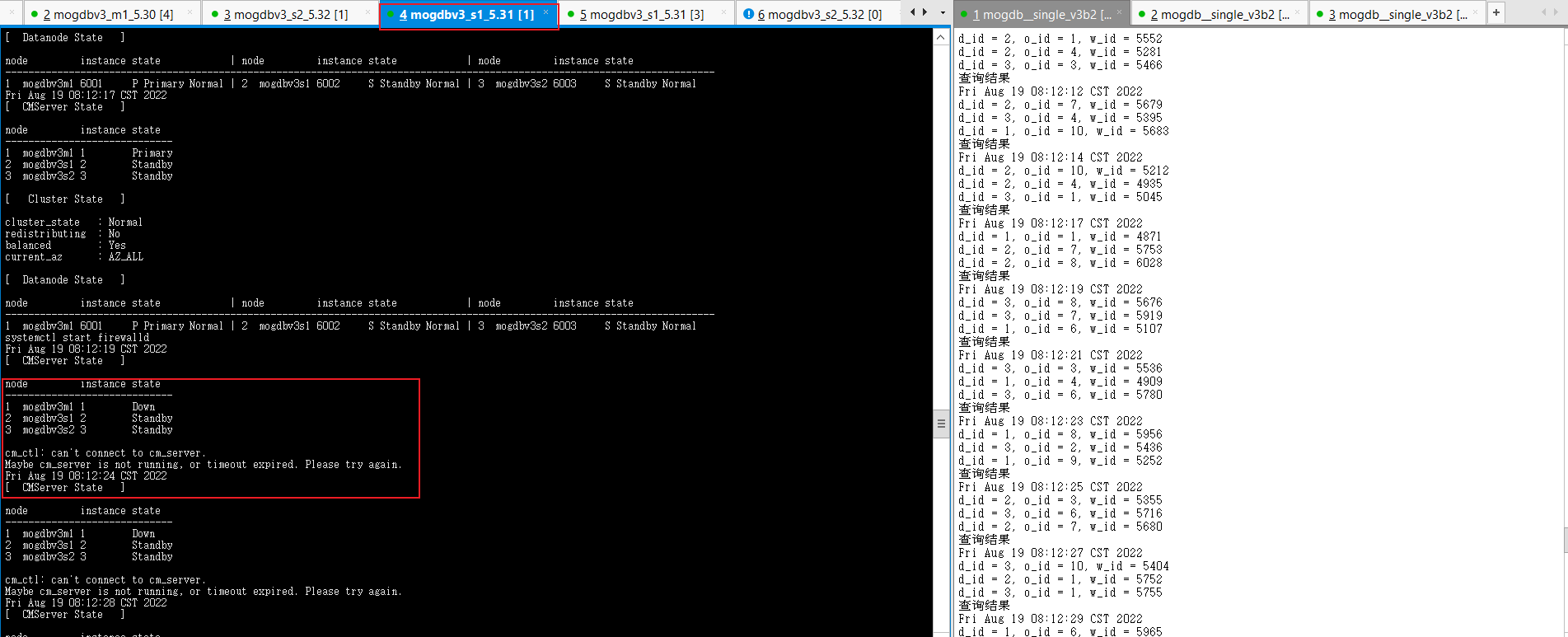
-
关闭三个节点网络防火墙约2s后,mogdbv3s1节点的Sync从库开始自动恢复,期间业务未受影响。
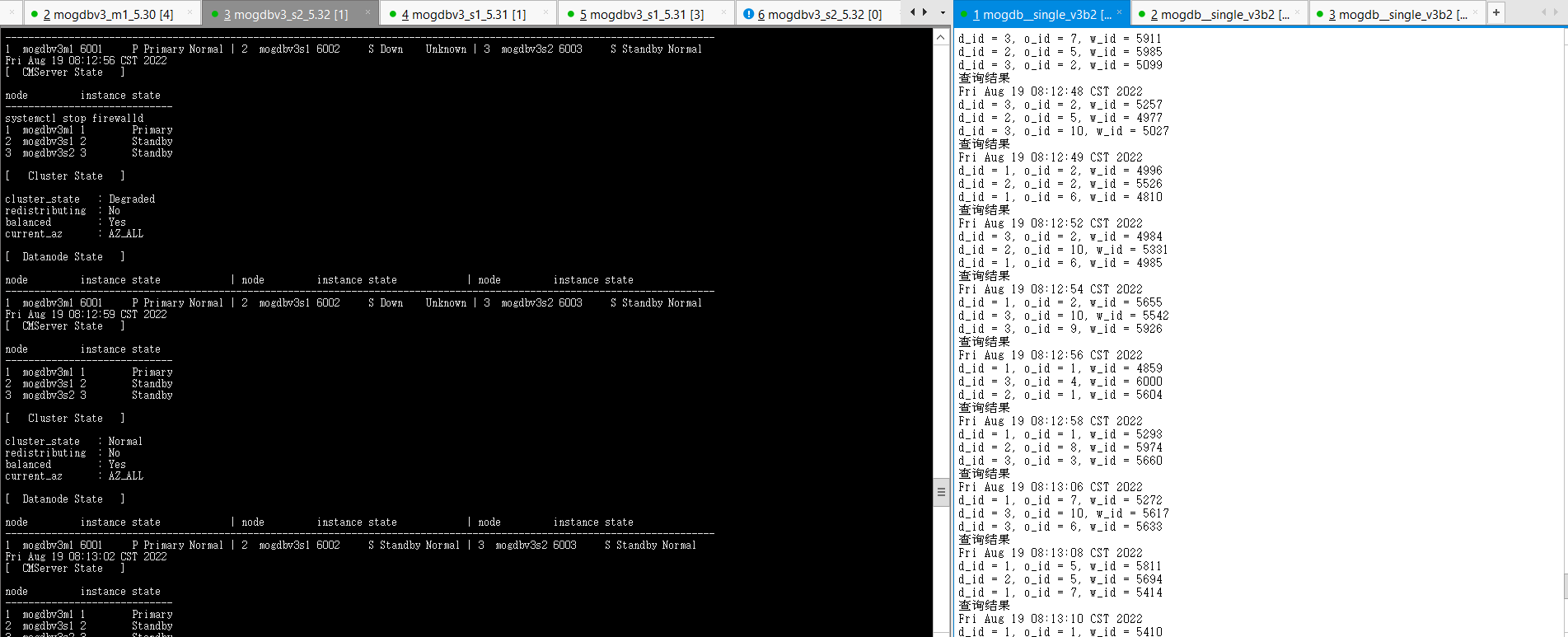
-
结论:符合预期。
2.2.5三台服务之间网络均不通
测试目的: 测试DataNode主节点、Potential从节点、Sync从节点相互之间的网络均不同,CMServer Node主节点和2个从节点相互之间网络中断场景。
测试方法:使用firewall隔离mogdbv3m1、mogdbv3s1、mogdbv3s2之间的DataNode和CMServer Node网络。
预期结果:DataNode复制状态异常,数据库对外业务未受影响。CMServer状态均异常,业务不受影响,
测试过程和结论:
- 测试前防火墙配置规则,尚未开启防火墙,集群同步状态。
[root@mogdbv3m1 ~]# firewall-cmd --zone=drop --list-all drop (active) target: DROP icmp-block-inversion: no interfaces: sources: 192.168.5.31 192.168.5.32 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3m1 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: sources: 192.168.5.20 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3s1 ~]# firewall-cmd --zone=drop --list-all drop (active) target: DROP icmp-block-inversion: no interfaces: sources: 192.168.5.30 192.168.5.32 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@mogdbv3s1 ~]# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT icmp-block-inversion: no interfaces: sources: 192.168.5.20 services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:`复制
[ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Primary 2 mogdbv3s1 2 Standby 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal复制
- 启动3个节点已配置规则的firewall,DataNode节点mogdbv3m1、从节点mogdbv3s1、mogdbv3s2之间网络中断,使用cm_clt检查集群运行情况,由于网络不通,无法获取对端2个节点的相关信息,只能显示自己节点的信息。在每个节点使用gs_ctl query检查数据库运行均正常,从库显示need repair。业务在启动防火墙期间运行正常,在启动防火墙瞬间有2s短暂阻塞。
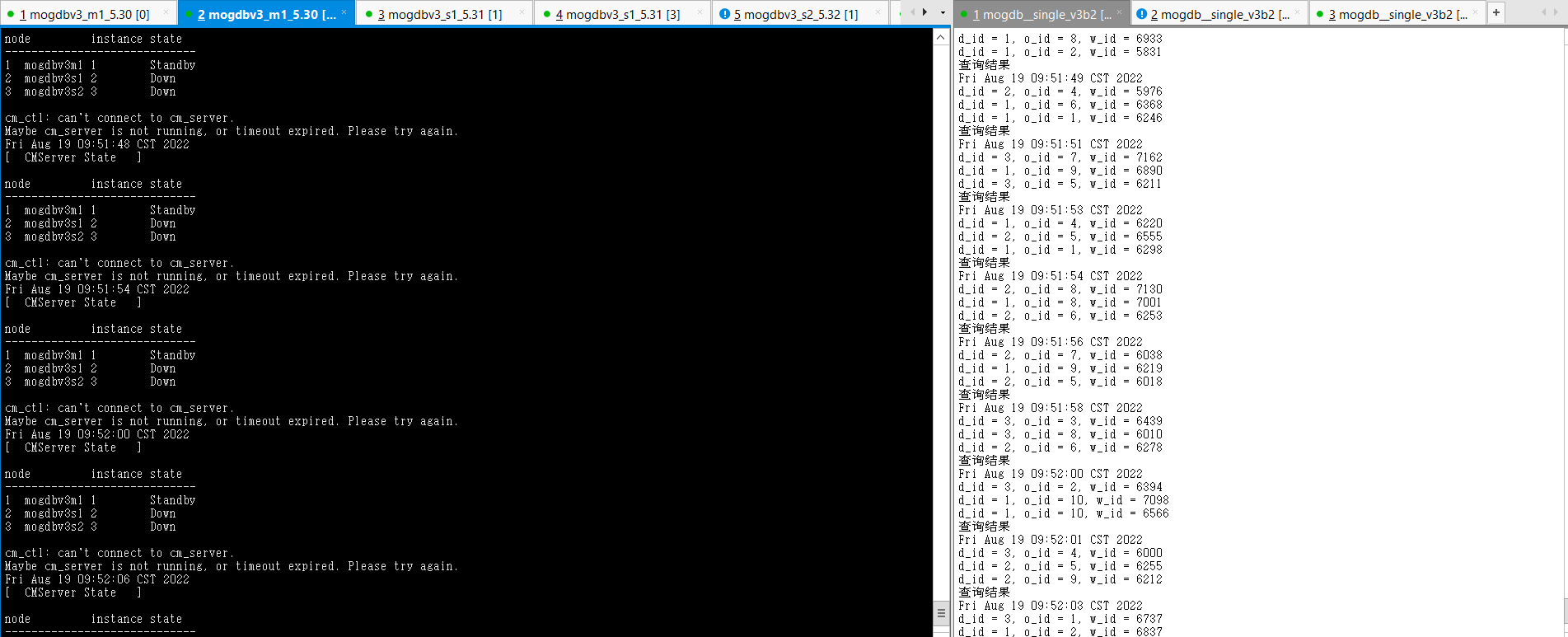
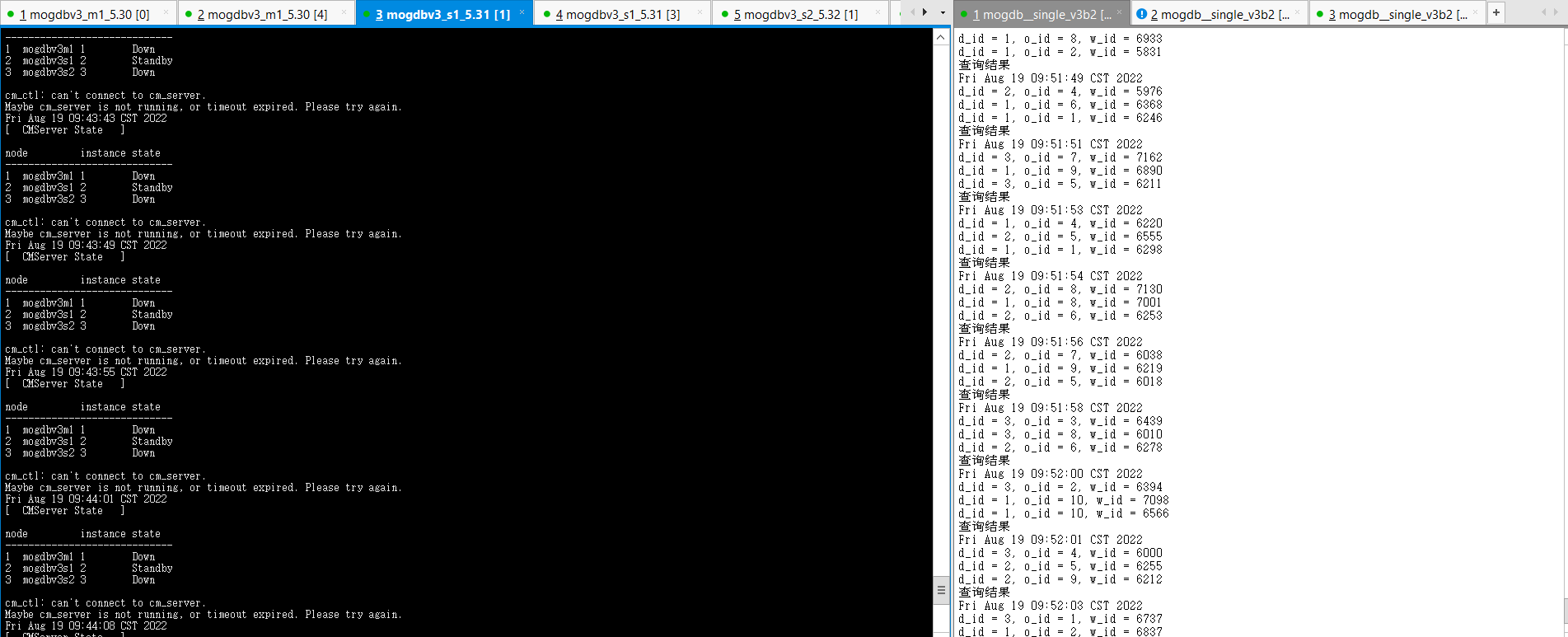
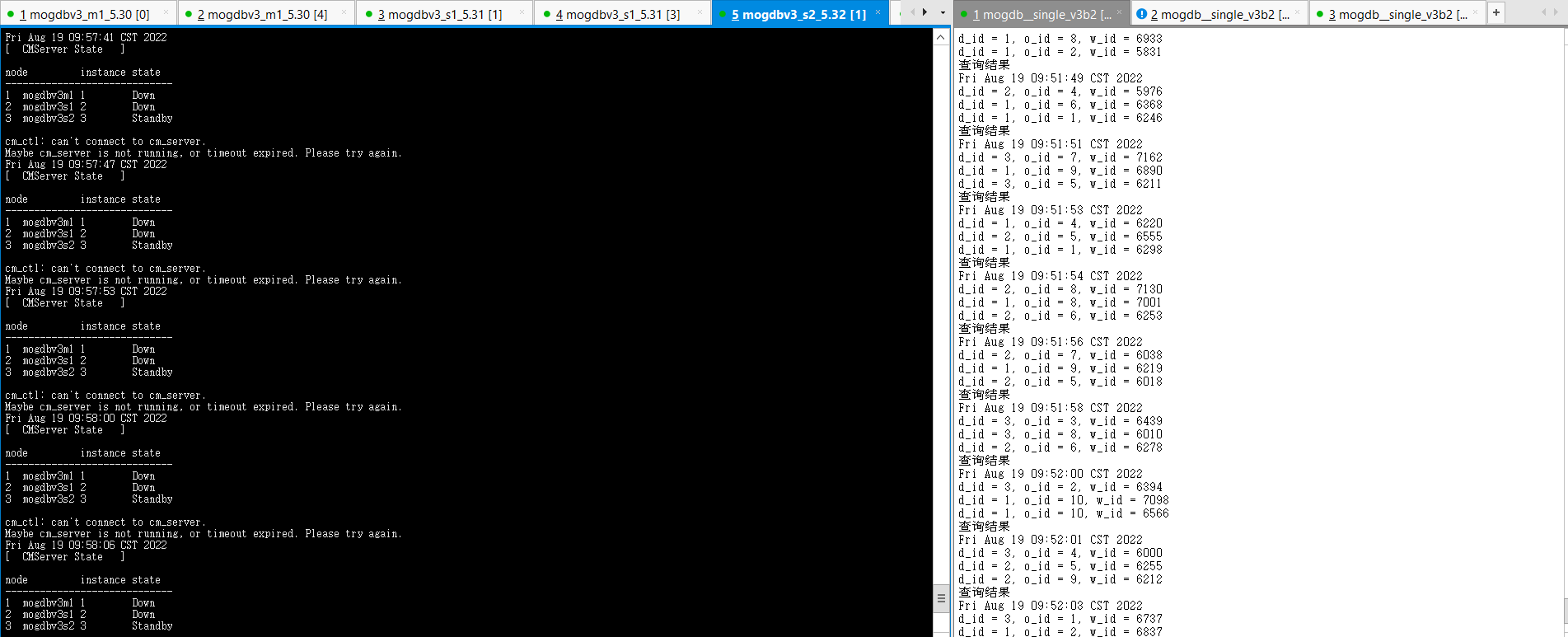
##mogdbv3m1 [omm@mogdbv3m1 ~]$ gs_ctl query [2022-08-19 09:57:22.351][17204][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: No information Receiver info: No information ##mogdbv3s1 [omm@mogdbv3s1 ~]$ gs_ctl query [2022-08-19 09:57:07.613][24975][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Standby static_connections : 2 db_state : Need repair detail_information : Disconnected Senders info: No information Receiver info: No information ##mogdbv3s2 [omm@mogdbv3s2 ~]$ gs_ctl query [2022-08-19 09:58:29.410][19052][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Standby static_connections : 2 db_state : Need repair detail_information : Disconnected Senders info: No information Receiver info: No information复制
- 关闭三个节点网络防火墙约48s后,各个节点cm server恢复正常,可以使用cm_ctl进行状态查询。mogdbv3s1、mogdbv3s2两个从节点开始进行catchup并自动恢复,期间业务未受影响。
[omm@mogdbv3m1 ~]$ gs_ctl query [2022-08-19 10:10:47.357][20858][][gs_ctl]: gs_ctl query ,datadir is /opt/mogdb/data HA state: local_role : Primary static_connections : 2 db_state : Normal detail_information : Normal Senders info: sender_pid : 20663 local_role : Primary peer_role : Standby peer_state : Catchup state : Catchup sender_sent_location : 3/38800000 sender_write_location : 5/DBC08A8 sender_flush_location : 5/DBC08A8 sender_replay_location : 5/DBC08A8 receiver_received_location : 3/37000000 receiver_write_location : 3/34000000 receiver_flush_location : 3/34000000 receiver_replay_location : 3/175C2948 sync_percent : 7% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.30:26001-->192.168.5.32:56034 sender_pid : 20664 local_role : Primary peer_role : Standby peer_state : Catchup state : Catchup sender_sent_location : 3/35800000 sender_write_location : 5/DBC08A8 sender_flush_location : 5/DBC08A8 sender_replay_location : 5/DBC08A8 receiver_received_location : 3/347FFFF9 receiver_write_location : 3/32000000 receiver_flush_location : 3/32000000 receiver_replay_location : 3/10D8BA40 sync_percent : 7% sync_state : Potential sync_priority : 1 sync_most_available : On channel : 192.168.5.30:26001-->192.168.5.31:37990 Receiver info: No information复制
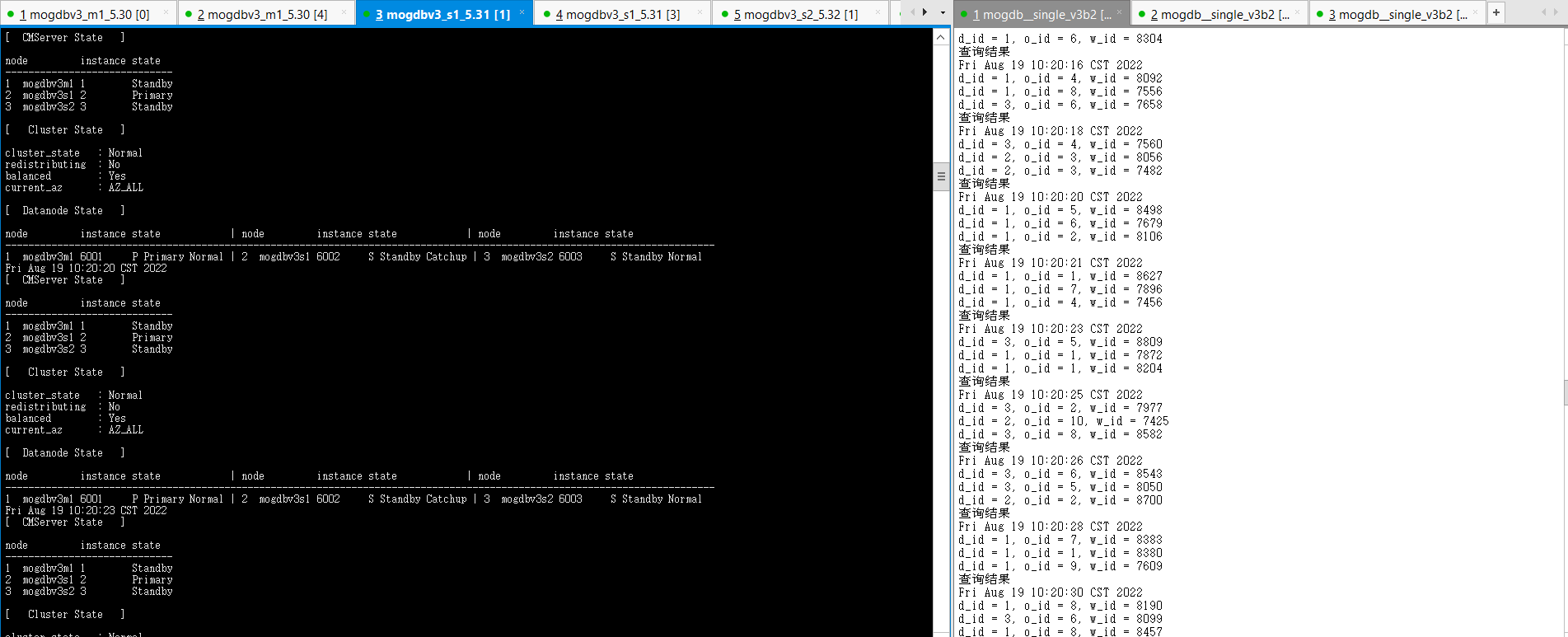
- 结论:复合预期。
2.3数据库问题
2.3.1实例崩溃
测试目的:测试主节点数据在运行期间遇到错误导致实例奔溃。
测试方法:使用kill -9 命令直接kiil掉mogdb进程
预期结果:主库宕库后,业务中断若干秒后,在2个从库中选一台提升为新的主库,业务恢复正常,CM立刻拉起被kill原主库,原主库角色角色变为从库,并自动追平延迟。
测试过程和结论:
- 测试前正常状态
[ CMServer State ] node instance state ----------------------------- 1 mogdbv3m1 1 Standby 2 mogdbv3s1 2 Primary 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal复制
-
使用kill -9 杀掉mogdbv3m1节点的mogdb进程,cm检测到主库宕机,选择mogdbv3s1同步从库提升为主库,业务中断8s。被kill掉的原有主库自动拉起后,降为备库。
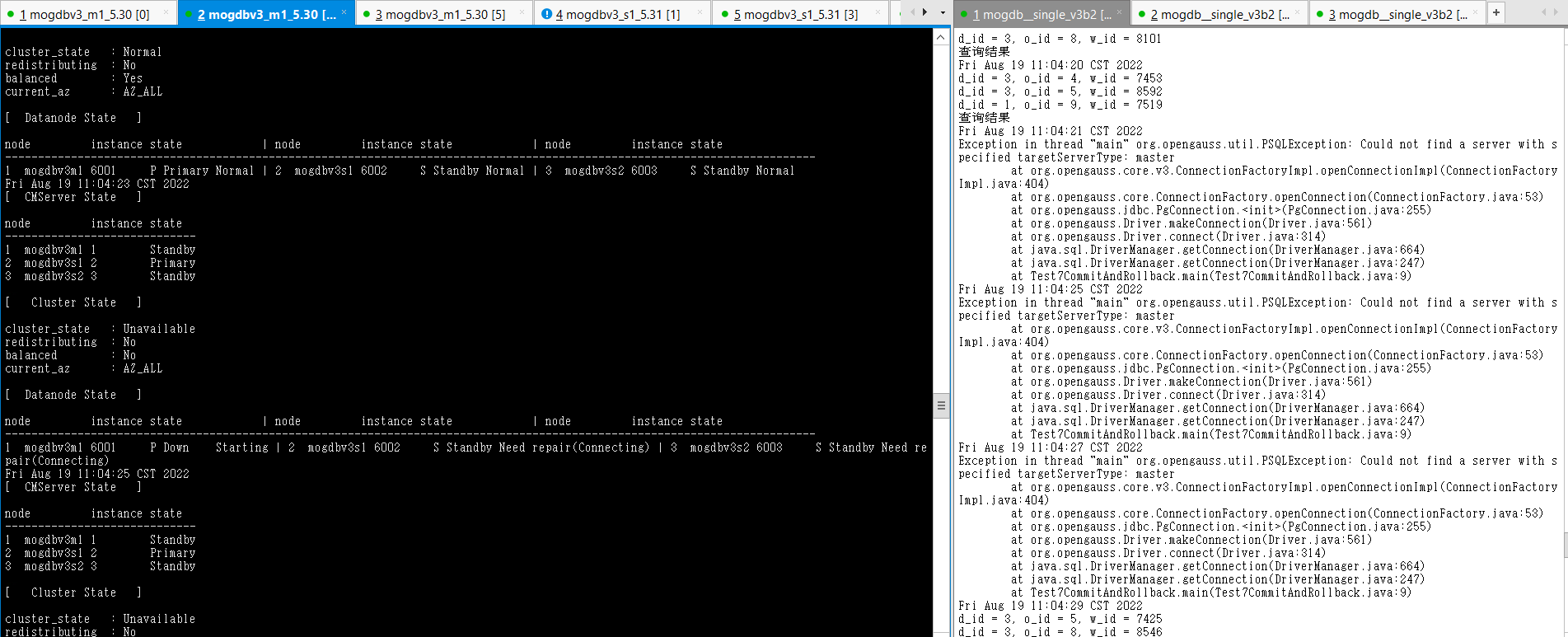
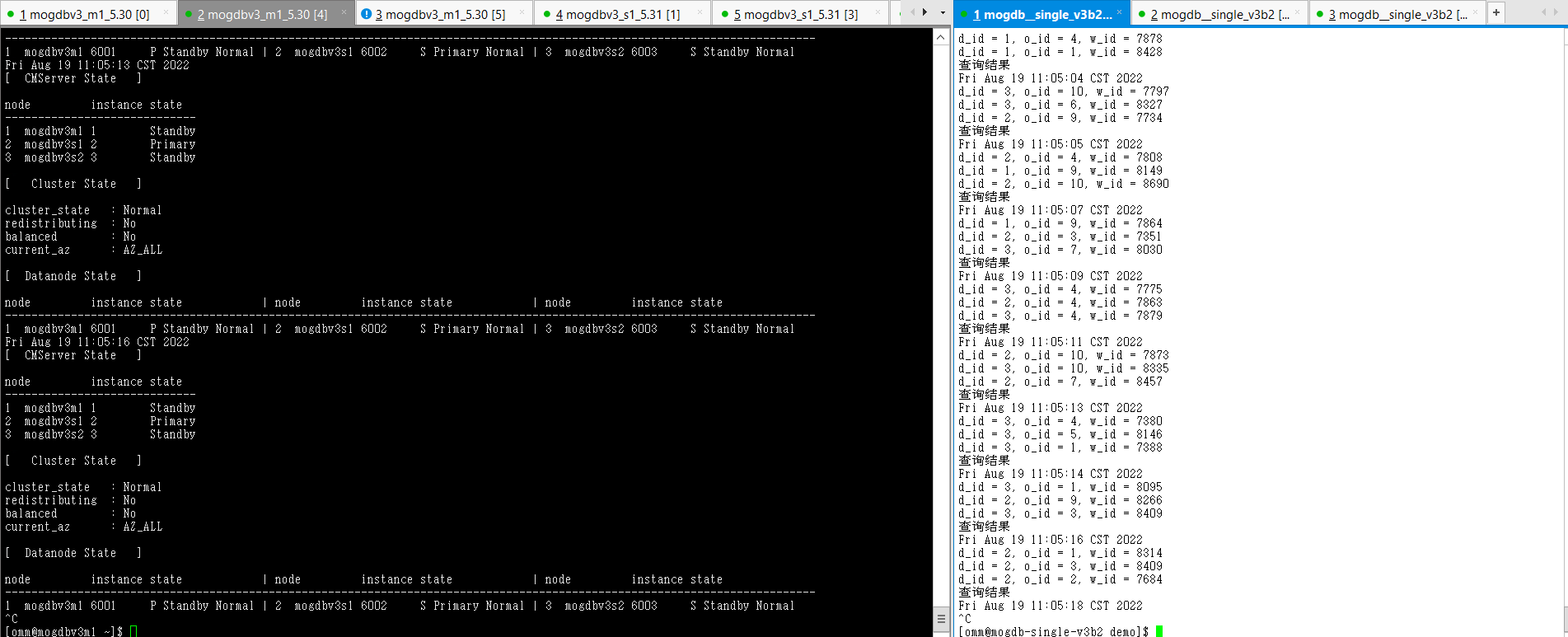
-
结论:符合预期
2.3.2文件被删除
测试目的:测试主库从库主机硬件故障,出现宕机。
测试方法:选择一个主库环境,对PGDATA目录下的base目录执行mv base base_bak模拟数据文件被删除。
预期结果:主库文件被删除后,业务中断若干秒后,在2个从库中选一台提升为新的主库,业务恢复正常。
测试过程和结论:
- 测试前正常状态
node instance state ----------------------------- 1 mogdbv3m1 1 Standby 2 mogdbv3s1 2 Primary 3 mogdbv3s2 3 Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node instance state | node instance state | node instance state --------------------------------------------------------------------------------------------------------------------------- 1 mogdbv3m1 6001 P Primary Normal | 2 mogdbv3s1 6002 S Standby Normal | 3 mogdbv3s2 6003 S Standby Normal复制
-
在mogdbv3m1节点PGDATA下,执行mv base base_bak模拟文件被删除,执行后业务立即报错出现异常,此时cm尚未检测到数据库异常,约在79s后cm完成新的主库提升,业务恢复正常。
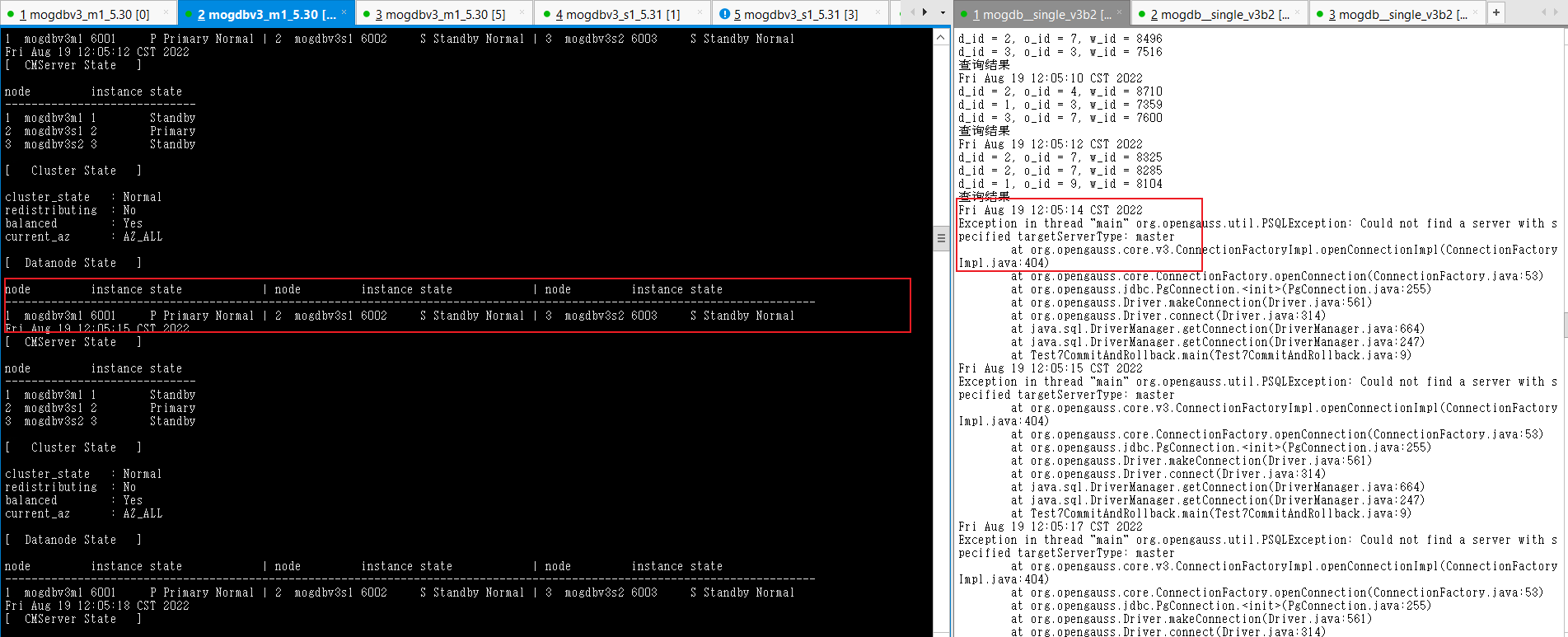
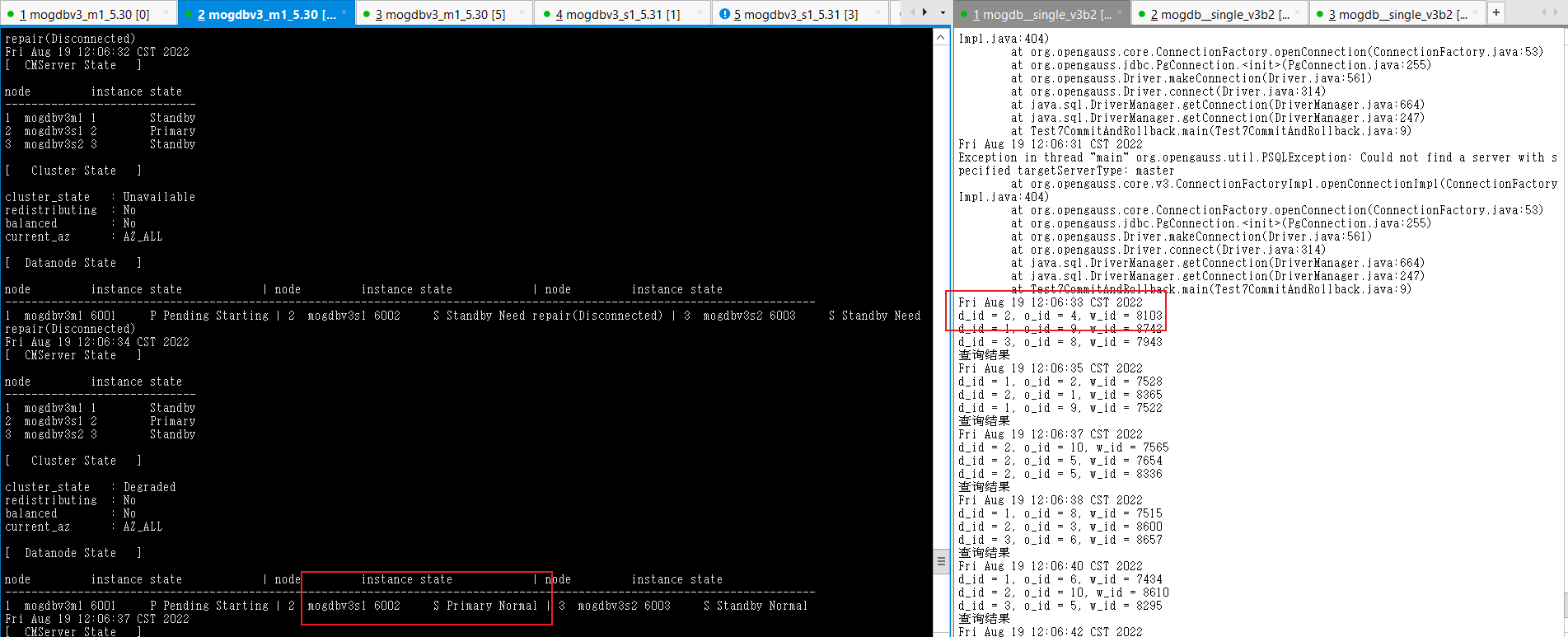
-
结论,过程符合预期,但是CM检测主节点文件删除异常过程触发新的选主操作较慢,导致业务中断时间较长。
