




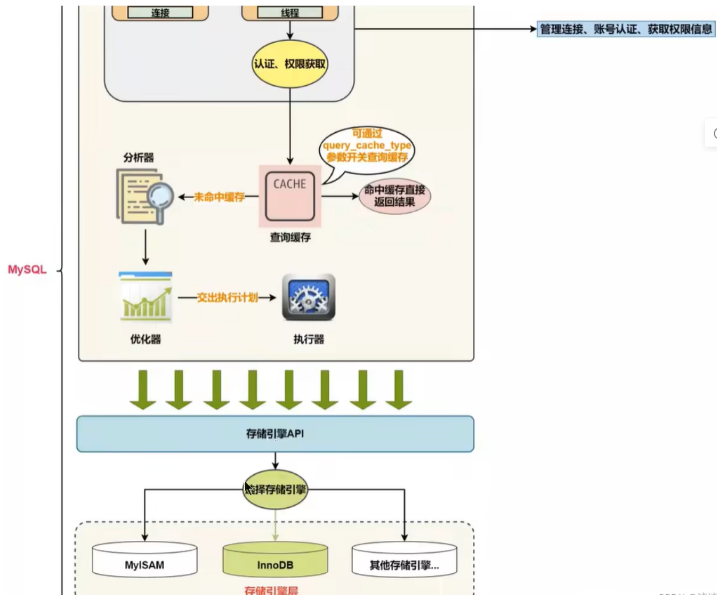
MySQL 中的 SQL执行流程
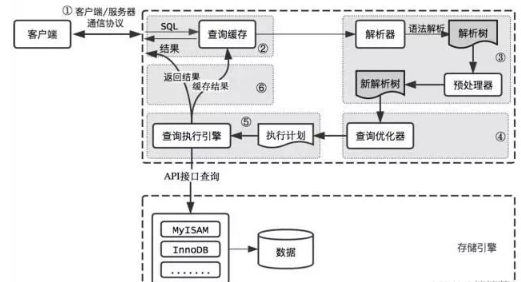
MySQL的查询流程:
1、查询缓存 :Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃了这个功能。
大多数情况查询缓存就是个鸡肋,为什么呢?
SELECT employee_id,last_name FROM employees WHERE employee_id = 101;
1
查询缓存是提前把查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。这就意味着查询匹配的鲁棒性大大降低,只有相同的查询操作才会命中查询缓存。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。因此 MySQL 的 查询缓存命中率不高 。
同时,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如 mysql 、information_schema、performance_schema 数据库中的表,那这个请求就不会被缓存。以某些系统函数举例,可能同样的函数的两次调用会产生不一样的结果,比如函数 NOW ,每次调用都会产生最新的当前时间,如果在一个查询请求中调用了这个函数,那即使查询请求的文本信息都一样,那不同时间的两次查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询的结果就是错误的!
此外,既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!对于更新压力大的数据库来说,查询缓存的命中率会非常低。
总之,因为查询缓存往往弊大于利,查询缓存的失效非常频繁。
一般建议大家在静态表里使用查询缓存,什么叫静态表呢?就是一般我们极少更新的表。比如,一个系统配置表、字典表,这张表上的查询才适合使用查询缓存。好在MysQL也提供了这种”按需使用”的方式。你可以将my.cnf参数query_cache_type设置成DEMAND,代表当sql语句中有SQL_CACHE关键词时才缓存。比如:
# query_cache_type有3个值,0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)
query_cache_type=2
这样对于默认的SQL语句都不使用查询缓存。而对于你确定要是使用查询缓存的语句,可以用SQL_CACHE显示指定,像下面这个语句一样:
select SQL_CACHE * from test where ID=5;
查看当前mysql实例是否开启缓存机制
# mysql5.7中:
mysql> show global variables like "%query_cache_type%";
# mysql8.0中
mysql> show global variables like "%query_cache_type%";
Empty set (0.02 sec)
监控查询缓存的命中率:
show status like '%Qcache%';
运行结果解析:
Qcache_free_blocks :表示查询缓存中还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片过多了,可能在一定的时间进行整理。
Qcache_free_memory :查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,DBA可以根据实际情况做出调整。
Qcache_hits :表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越理想。
Qcache_inserts:表示多少次未命中然后插入,意思是新来的sQL请求在缓存中未找到,不得不执行查询处理执行查询处理后把结果insert到查询缓存中。这样的情况的次数越多,表示查询缓存应用到的比较少,效果也就理想。当然系统刚启动后,查询缓存是空的,这很正常。
Qcache_lowmem_prunes :该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的调整缓存大小。
Qcache_not_cached :表示因为query_cache_type的设置而没有被缓存的查询数量。
Qcache_queries.in.cache :当前缓存中缓存的查诎数量。
Qcache_total_blocks :当前缓存的block数量。
2、解析器 :在解析器中对 SQL 语句进行语法分析、语义分析。
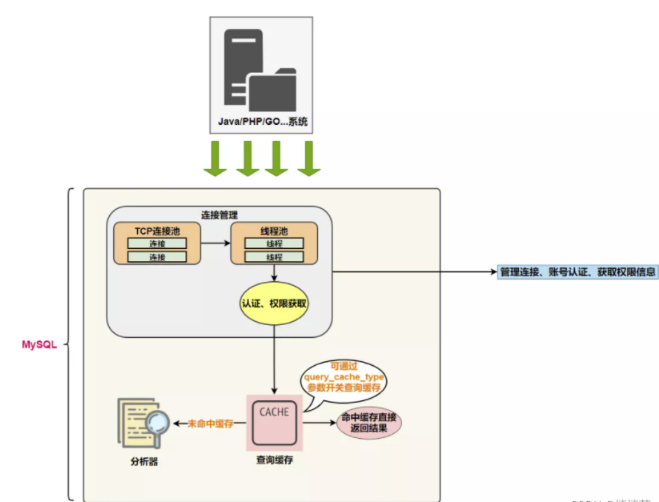
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL需要知道你要做什么,因此需要对SQL语句做解析。SQL语句的分析分为词法分析与语法分析。
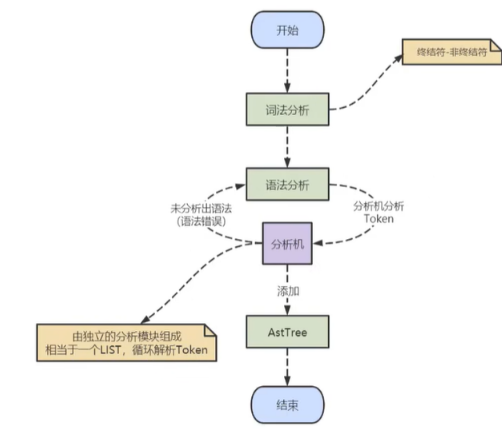
分析器先做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。 MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
接着,要做“语法分析”。根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句from写成了“rom”。
# 语句:
select * rom test where id=1;
# 错误:
ERROR 1064 (42800 ) : You have an error in your SQL syntax; check the manual that corresponds toyour MySQL server version for the right syntax to use near 'fro test where id=1' at line 1
如果SQL语句正确,则会生成一个语法树。
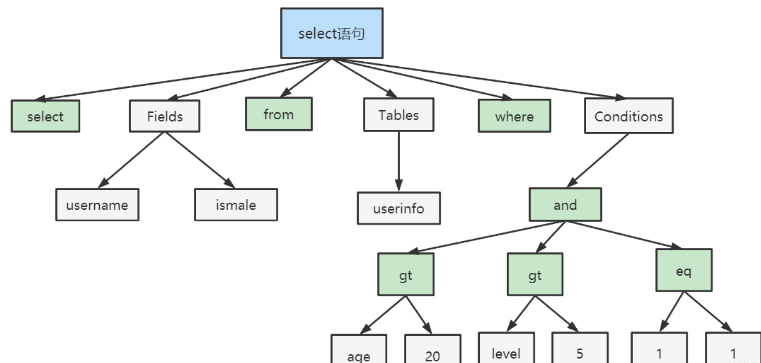
下面是SQL语法分析的过程步骤:
3、优化器 :在优化器中会确定 SQL 语句的执行路径,比如是根据全表检索,还是根据索引检索等。在查询优化器中,可以分为逻辑查询优化阶段和物理查询优化阶段。
select * from test1 join test2 using(ID) where test1.name='zhangwei' and test2.name='mysql高级课程';
1
# 方案1:可以先从表 test1 里面取出 name='zhangwei'的记录的 ID 值,再根据 ID 值关联到表 test2,再判断 test2 里面 name的值是否等于 'mysql高级课程'。
# 方案2:可以先从表 test2 里面取出 name='mysql高级课程' 的记录的 ID 值,再根据 ID 值关联到 test1,再判断 test1 里面 name的值是否等于 zhangwei。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
如果你还有一些疑问,比如优化器是怎么选择索引的,有没有可能选择错等。后面讲到索引我们再谈。
在查询优化器中,可以分为 逻辑查询 优化阶段和 物理查询 优化阶段。
逻辑查询优化:就是通过改变SQL语句的内容来使得SQL查询更高效,同时为物理查询优化提供更多的候选执行计划。通常采用的方式是对SQL语句进行等价交换,对查询进行 重写,而查询重写的数学基础就是关系代数。对条件表达式进行等价谓词重写、条件简化,对视图进行重写,对子查询进行优化,对连接语义进行了外连接消除、嵌套连接消除等。
物理查询优化:是基于关系代数进行的查询重写,而关系代数的每一步都对应着物理计算,这些物理计算往往存在多种算法,因此需要计算各种物理路径的代价,从中选择代价最小的作为执行计划。在这个阶段里,对于单表和多表连接的操作,需要高效地使用索引,提升查询效率。
4、执行器 :

在执行之前需要判断该用户是否 具备权限 。如果没有,就会返回权限错误。如果具备权限,就执行 SQL查询并返回结果。在 MySQL8.0 之前的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
select * from test where id=1;
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,调用存储引擎API对表进行的读写。存储引擎API只是抽象接口,下面还有个存储引擎层,具体实现还是要看表选择的存储引擎。
比如:表 test 中,ID 字段没有索引,那么执行器的执行流程是这样的:
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是1,如果不是则跳过,如果是则将这行存在结果集中;调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。对于有索引的表,执行的逻辑也差不多。
SQL 语句在 MySQL 中的流程是: SQL语句→查询缓存→解析器→优化器→执行器 。
4.2.2、MySQL8中SQL执行原理
确认profiling 是否开启
mysql> select @@profiling;
mysql> show variables like 'profiling';
profiling=0 代表关闭,我们需要把 profiling 打开,即设置为 1:
mysql> set profiling=1;
多次执行相同SQL查询
然后我们执行一个 SQL 查询(你可以执行任何一个 SQL 查询):
mysql> select * from employees;
查看profiles
查看当前会话所产生的所有 profiles:
mysql> show profiles; # 显示最近的几次查询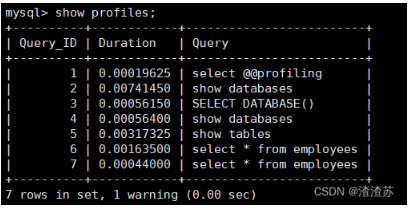
查看profile
显示执行计划,查看程序的执行步骤:
mysql> show profile;
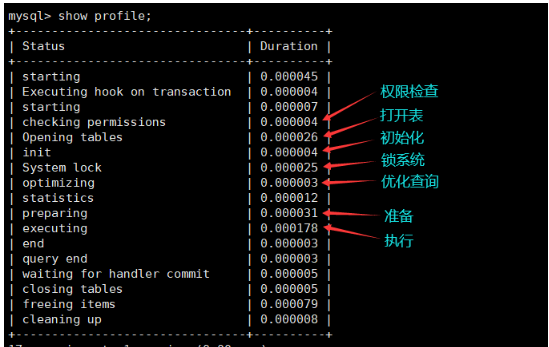
此外,还可以查询更丰富的内容:
Syntax:
SHOW PROFILE [type [ , type ] ... ]
[ FOR QUERY n ]
[LIMIT row_count [ OFFSET offset ] ]
type : {
ALL -- 显示所有参数的开销信息
BLOCK IO -- 显示IO的相关开销
CONTEXT SWITCHES -- 上下文切换相关开销
CPU -- 显示CPU相关开销信息
IPC -- 显示发送和接收相关开销信息
MEMORY -- 显示内存相关开销信息
PAGE FAULTS -- 显示页面错误相关开销信息
SOURCE -- 显示和Source_function, Source_file,Source_line相关的开销信息
SWAPS -- 显示交换次数相关的开销信息
}
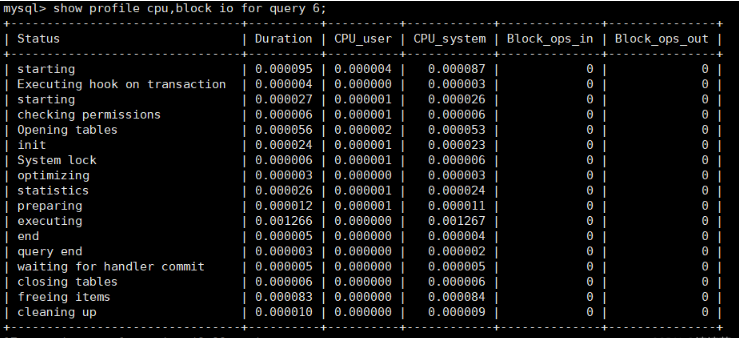
mysql> show profile cpu,block io for query 6;
4.2.3、MySQL5.7中SQL执行原理
上述操作在MySQL5.7中测试,发现前后两次相同的sql语句,执行的查询过程仍然是相同的。不是会使用缓存吗?这里我们需要 显式开启查询缓存模式 。在MySQL5.7中如下设置:
配置文件中开启查询缓存
在 /etc/my.cnf 中新增一行:
query_cache_type=1
1
重启mysql服务
systemctl restart mysqld
1
开启查询执行计划
由于重启过服务,需要重新执行如下指令,开启profiling。
mysql> set profiling=1;
1
执行语句两次:
mysql> select * from locations;
mysql> select * from locations;
1
2
查看profiles
查看profile
显示执行计划,查看程序的执行步骤:
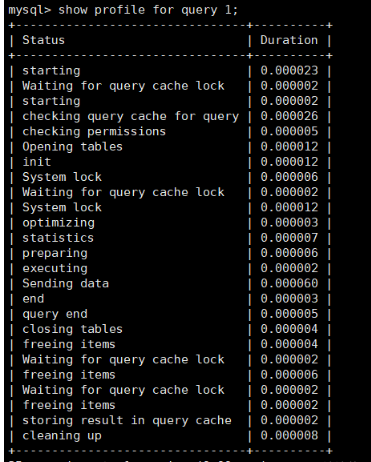
mysql> show profile for query 1;
mysql> show profile for query 2;
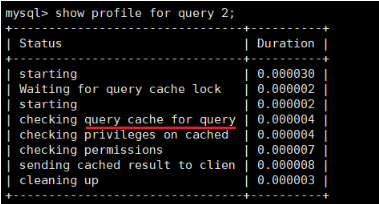
结论不言而喻。执行编号2时,比执行编号1时少了很多信息,从截图中可以看出查询语句直接从缓存中获取数据。
4.2.4、SQL语法顺序
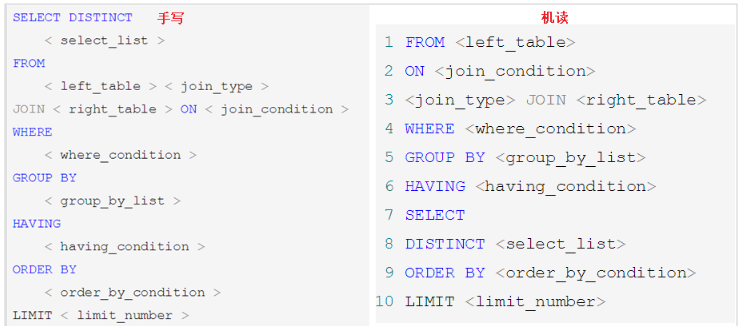
随着Mysql版本的更新换代,其优化器也在不断的升级,优化器会分析不同执行顺序产生的性能消耗不同而动态调整执行顺序。
需求:查询每个部门年龄高于20岁的人数且高于20岁人数不能少于2人,显示人数最多的第一名部门信息
下面是经常出现的查询顺序:
4.2.5、Oracle中的SQL执行流程(了解)
Oracle 中采用了 共享池 来判断 SQL 语句是否存在缓存和执行计划,通过这一步骤我们可以知道应该采用硬解析还是软解析。
我们先来看下 SQL 在 Oracle 中的执行过程:
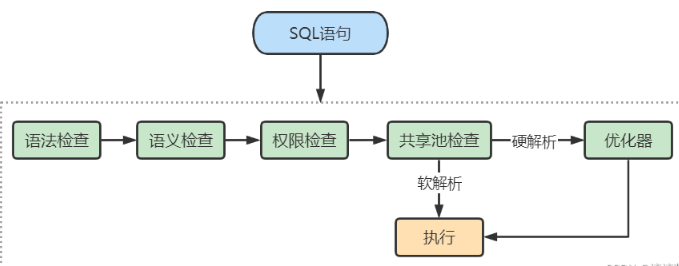
从上面这张图中可以看出,SQL 语句在 Oracle 中经历了以下的几个步骤。
1.语法检查:检查 SQL 拼写是否正确,如果不正确,Oracle 会报语法错误。
2.语义检查:检查 SQL 中的访问对象是否存在。比如我们在写 SELECT 语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证 SQL 语句没有错误。
3.权限检查:看用户是否具备访问该数据的权限。
4.共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存 SQL 语句和该语句的执行计划。Oracle 通过检查共享池是否存在 SQL 语句的执行计划,来判断进行软解析,还是硬解析。那软解析和硬解析又该怎么理解呢?
在共享池中,Oracle 首先对 SQL 语句进行 Hash 运算 ,然后根据 Hash 值在库缓存(Library Cache)中查找,如果 存在 SQL 语句的执行计划 ,就直接拿来执行,直接进入“执行器”的环节,这就是 软解析 。
如果没有找到 SQL 语句和执行计划,Oracle 就需要创建解析树进行解析,生成执行计划,进入“优化器”这个步骤,这就是 硬解析 。
5.优化器:优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
6.执行器:当有了解析树和执行计划之后,就知道了 SQL 该怎么被执行,这样就可以在执行器中执行语句了。
共享池是 Oracle 中的术语,包括了库缓存,数据字典缓冲区等。我们上面已经讲到了库缓存区,它主要缓存 SQL 语句和执行计划。而 数据字典缓冲区 存储的是 Oracle 中的对象定义,比如表、视图、索引等对象。当对 SQL 语句进行解析的时候,如果需要相关的数据,会从数据字典缓冲区中提取。
库缓存 这一个步骤,决定了 SQL 语句是否需要进行硬解析。为了提升 SQL 的执行效率,我们应该尽量避免硬解析,因为在 SQL 的执行过程中,创建解析树,生成执行计划是很消耗资源的。
你可能会问,如何避免硬解析,尽量使用软解析呢?在 Oracle 中, 绑定变量 是它的一大特色。绑定变量就是在 SQL 语句中使用变量,通过不同的变量取值来改变 SQL 的执行结果。这样做的好处是能 提升软解析的可能性 ,不足之处在于可能会导致生成的执行计划不够优化,因此是否需要绑定变量还需要视情况而定。
举个例子,我们可以使用下面的查询语句:
SQL> select * from player where player_id = 10001;
你也可以使用绑定变量,如:
SQL> select * from player where player_id = :player_id;
这两个查询语句的效率在 Oracle 中是完全不同的。如果你在查询 player_id = 10001 之后,还会查询10002、10003 之类的数据,那么每一次查询都会创建一个新的查询解析。而第二种方式使用了绑定变量,那么在第一次查询之后,在共享池中就会存在这类查询的执行计划,也就是软解析。
因此,我们可以通过使用绑定变量来减少硬解析,减少 Oracle 的解析工作量。但是这种方式也有缺点,使用动态 SQL 的方式,因为参数不同,会导致 SQL 的执行效率不同,同时 SQL 优化也会比较困难。
Oracle的架构图:
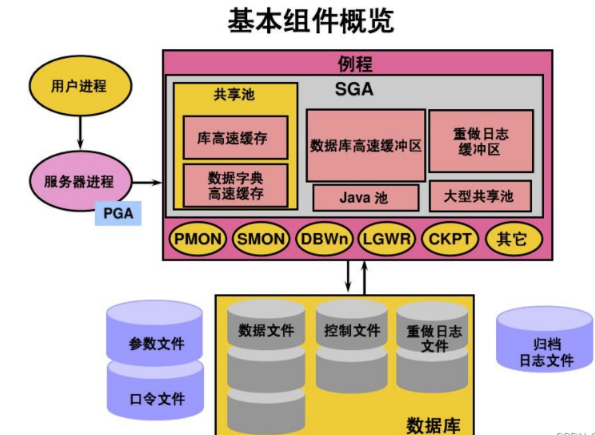
小结:
Oracle 和 MySQL 在进行 SQL 的查询上面有软件实现层面的差异。Oracle 提出了共享池的概念,通过共享池来判断是进行软解析,还是硬解析。
