





Resource Group 资源组管理介绍
Greenplum在资源管理方面,经历了从资源管理队列到资源管理组的一个升级变化。不同的数据库用户分属于不同的组别,而新的资源管理组可以将资源分配给不同的组别。资源管理组可针对每一个组别,单独设置其特定的CPU、内存和并发限制,这来达到控制不同级别资源的分配和使用的目的。
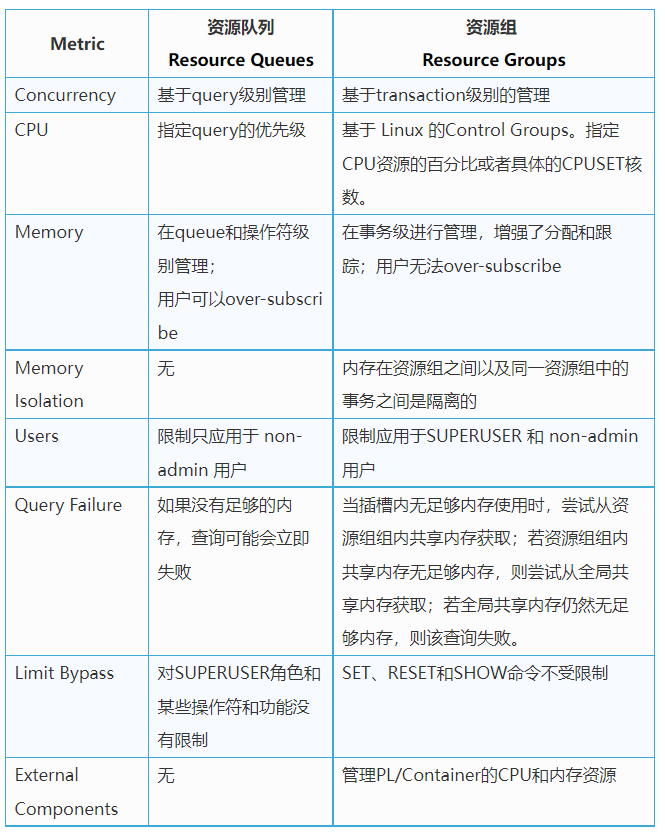
Resource Group 和 Resource Queue 的对比
资源组和资源队列的主要对比区别有下列表所示:

Resource Group 资源组管理
Greenplum 数据库支持两种类型的资源组:管理角色资源的组,以及管理外部组件(如PL/Container)资源的组。在管理角色资源的组中,对CPU的资源管理使用基于Linux的CGroup,对内存通过vmtracker来进行统计和跟踪。用户还可以使用资源组来管理外部组件(如PL/Container),其使用Linux CGroup来管理组件的总CPU和总内存资源。
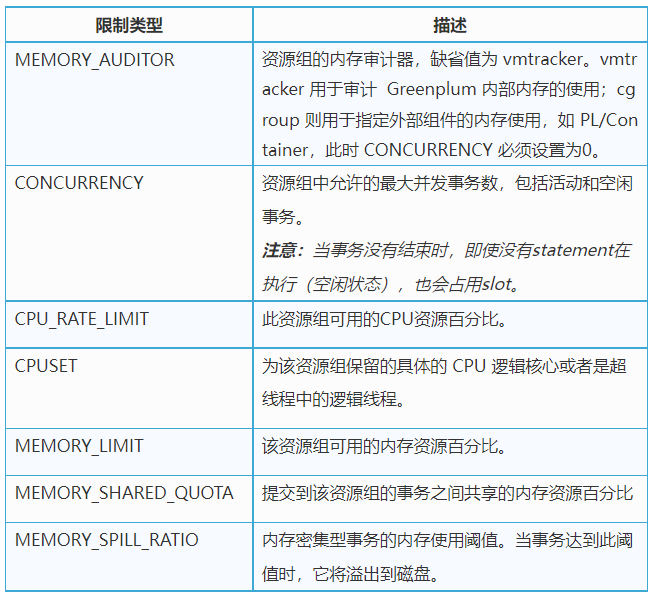
主要配置介绍
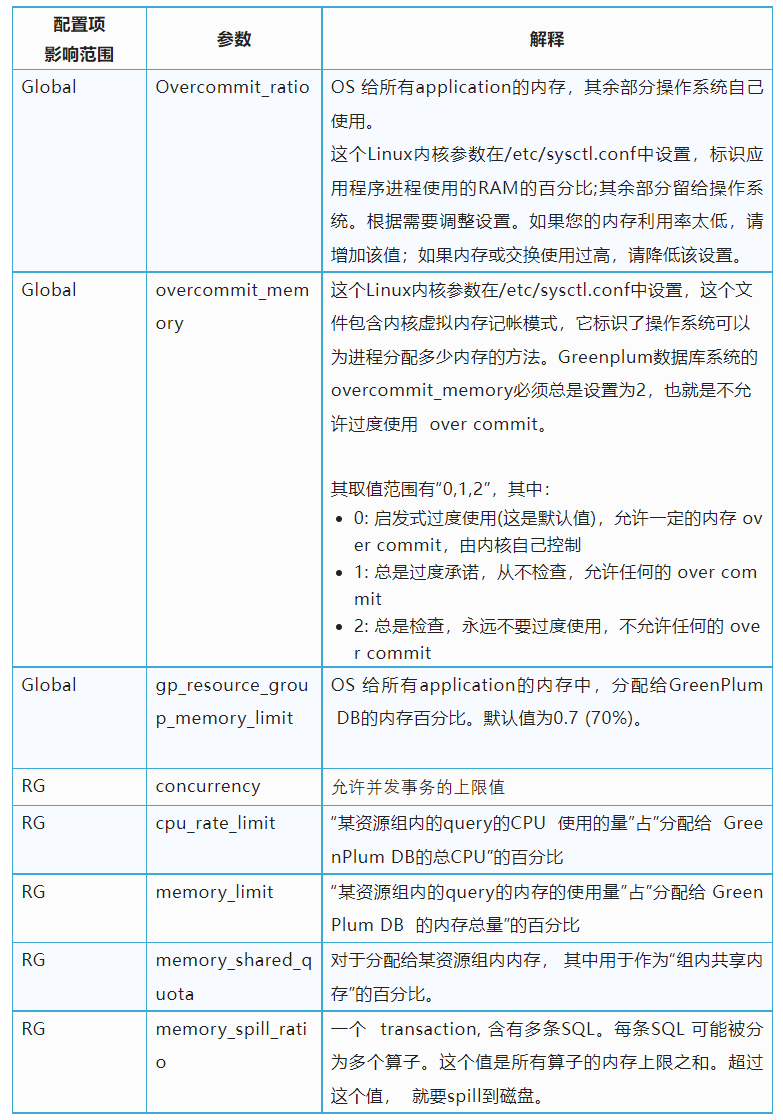
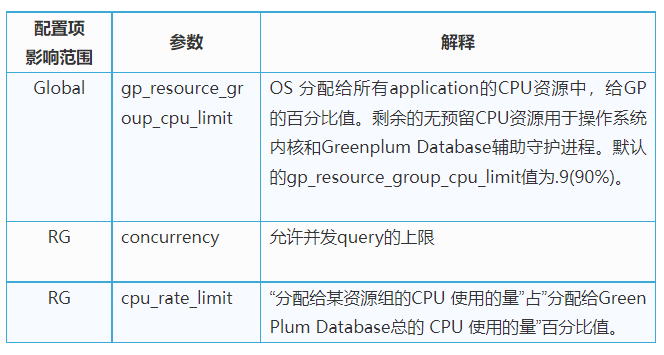
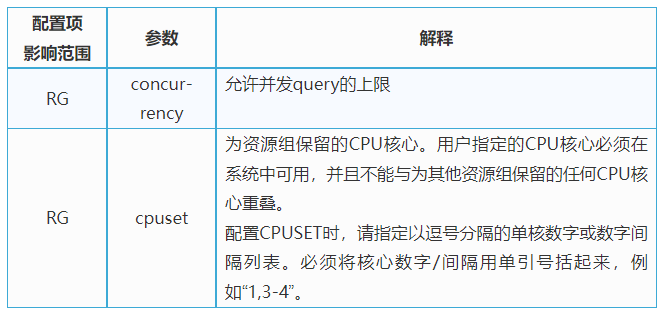
资源组的参数和限制如下所示:
注意: 不对SET,RESET和SHOW命令执行资源限制。
主要命令介绍
主要相关的创建命令有
1
●
启动资源组
将gp_resource_manager服务器配置参数设置为值"group":
i.gpconfig -s gp_resource_manager
ii.gpconfig -c gp_resource_manager -v "group"
重启Greenplum 数据库
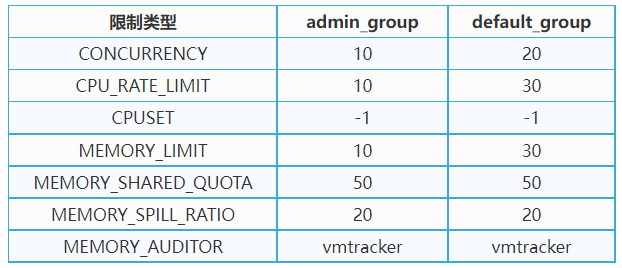
c. 启动资源组选项后,将默认创建2个资源组
i. admin_group和default_group:
ii. 例如:
2
●
创建一个资源组
=# create resource group rg_new with (concurrency=5, cpu_rate_limit=20, memory_limit=30, memory_shared_quota=20, memory_spill_ratio=30);
3
●
修改资源组的配置
=# alter resource group rg _group set memory_spill_ratio 50;
=# alter resource group admin_group set memory_limit 70;
4
●
将资源组绑定给某一个用户的 SQL
=# CREATE ROLE r1;
=# ALTER ROLE r1 RESOURCE GROUP rg_new;
5
●
删除一个资源组
事务并发限制介绍
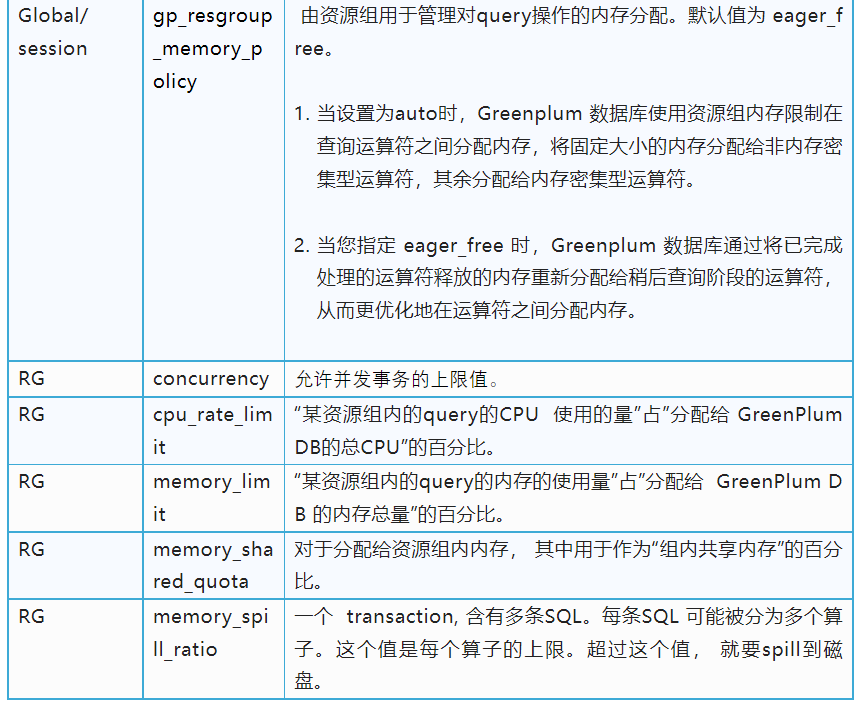
对事务并发限制,指的是资源组内允许的最大并发事务数。每个角色的资源组在逻辑上被划分为固定数量的槽位,也就是并发限制。Greenplum Database以相同的固定百分比为这些插槽分配内存资源。
内存管理介绍
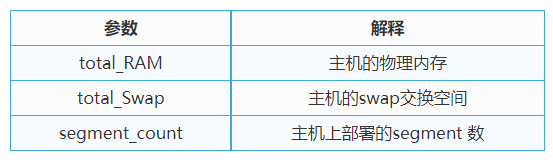
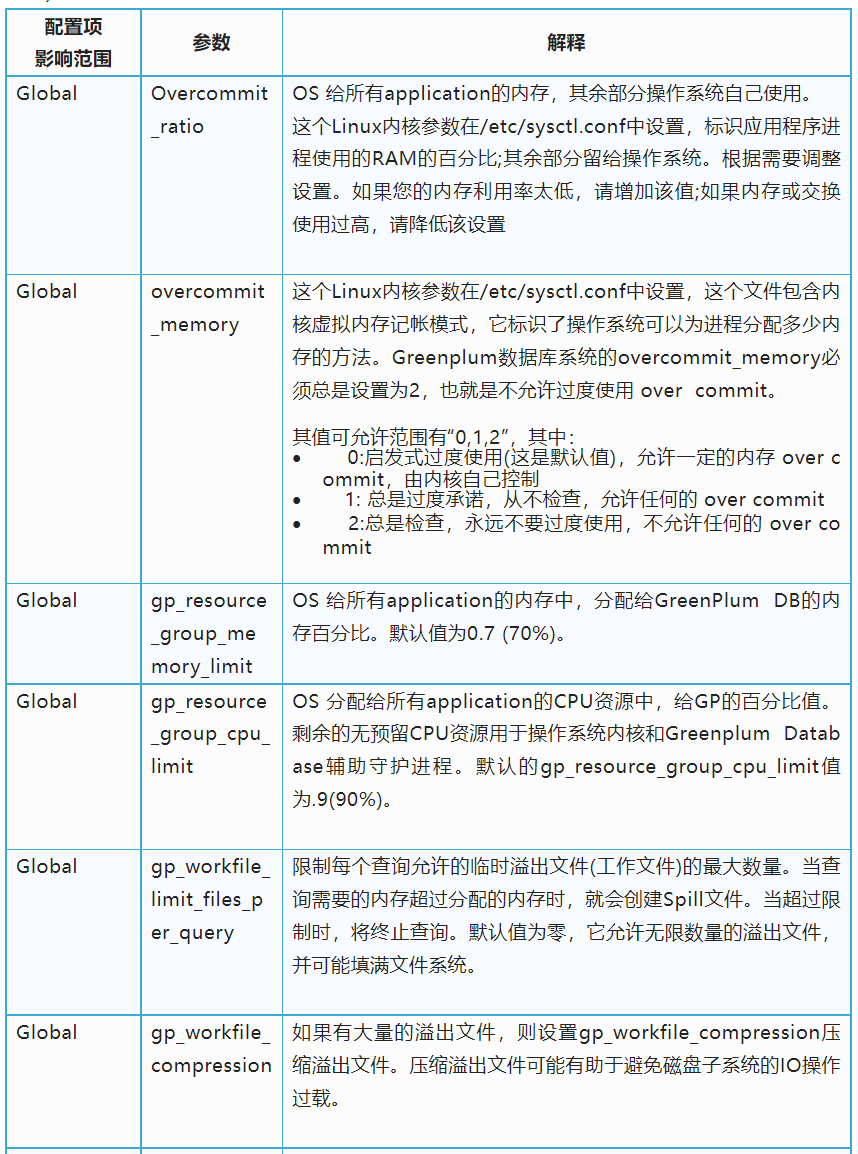
注意:SWAP是内存交换空间,或者叫虚拟内存,是从磁盘空间上开辟出来的一部分空间虚拟出来的。从运行速度和效率的角度考虑,如果客户的内存配置足够的情况下,不建议客户使用SWAP交换空间。但如果使用了SWAP, 需要知道此部分将参与内存管理分配的计算。
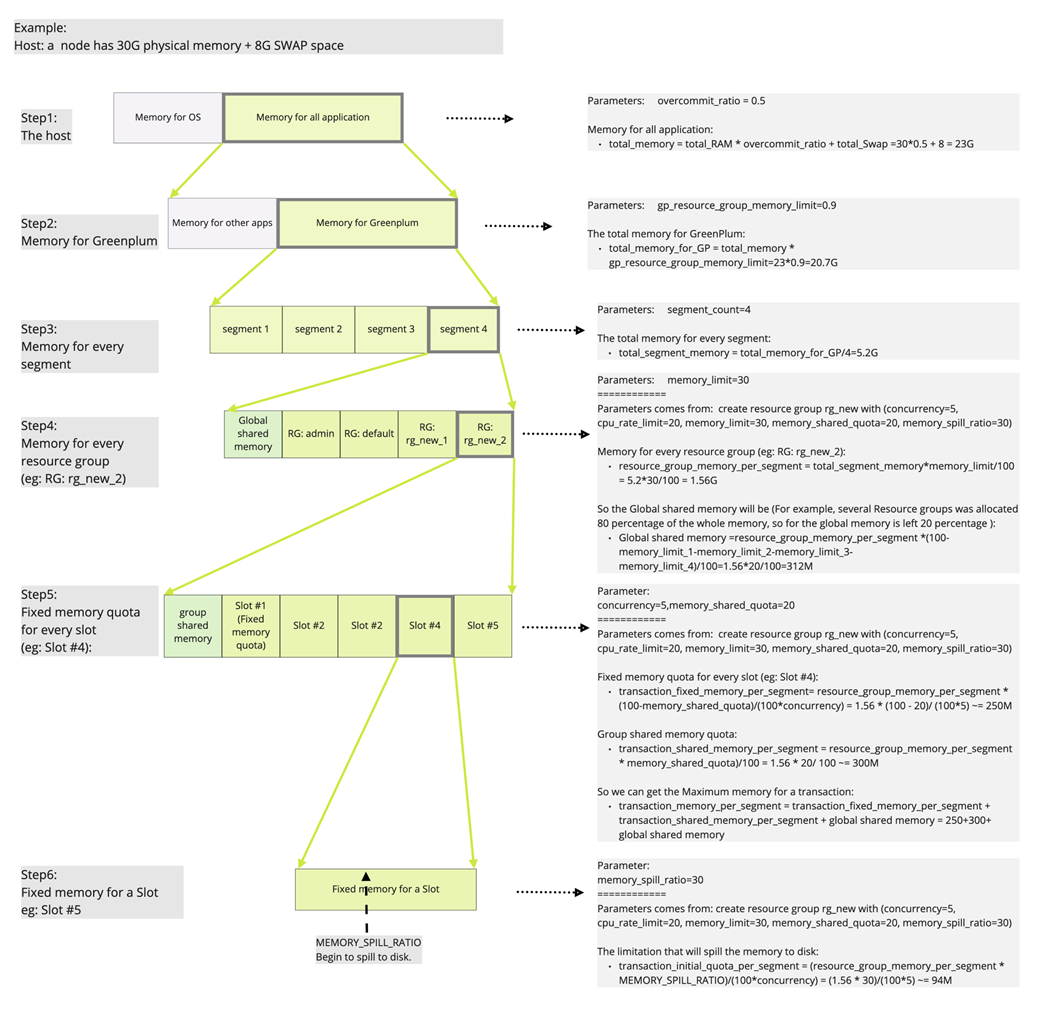
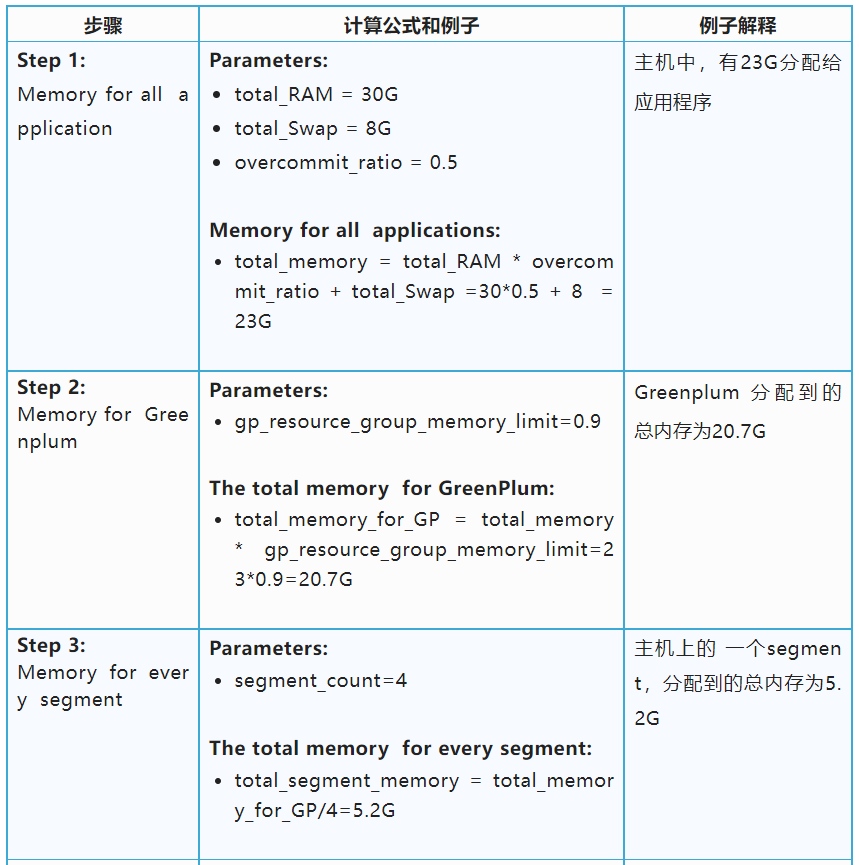



4. 上述“Step6 提到的内存溢出到磁盘”的操作,具体指什么呢?
举个例子,比如建立一张表,插入8000000行,数值的范围在1~1000000,对其进行排序操作。排序过程中,会产生大量的中间计算结果,会大量占用内存。比如,如果不加限制,这个query需要使用的主要内存量大概为200M以上。
如果设置的” 溢出到磁盘的上限”为125M, GP会在内存使用量达到125M之后,排序相关的中间结果溢出到磁盘存储,减少内存的占用量,最终query的使用量可能在128M左右。其中这3M(128M-125M=3M) 的使用,是无法溢出到磁盘部分的占用量。
如果设置的” 溢出到磁盘的上限”为3M, GP会在内存使用量达到3M之后,排序相关的中间结果溢出到磁盘存储,减少内存的占用量,最终query的使用量可能在6M左右。其中这3M(6M-3M=3M) 的使用,是无法溢出到磁盘部分的占用量。
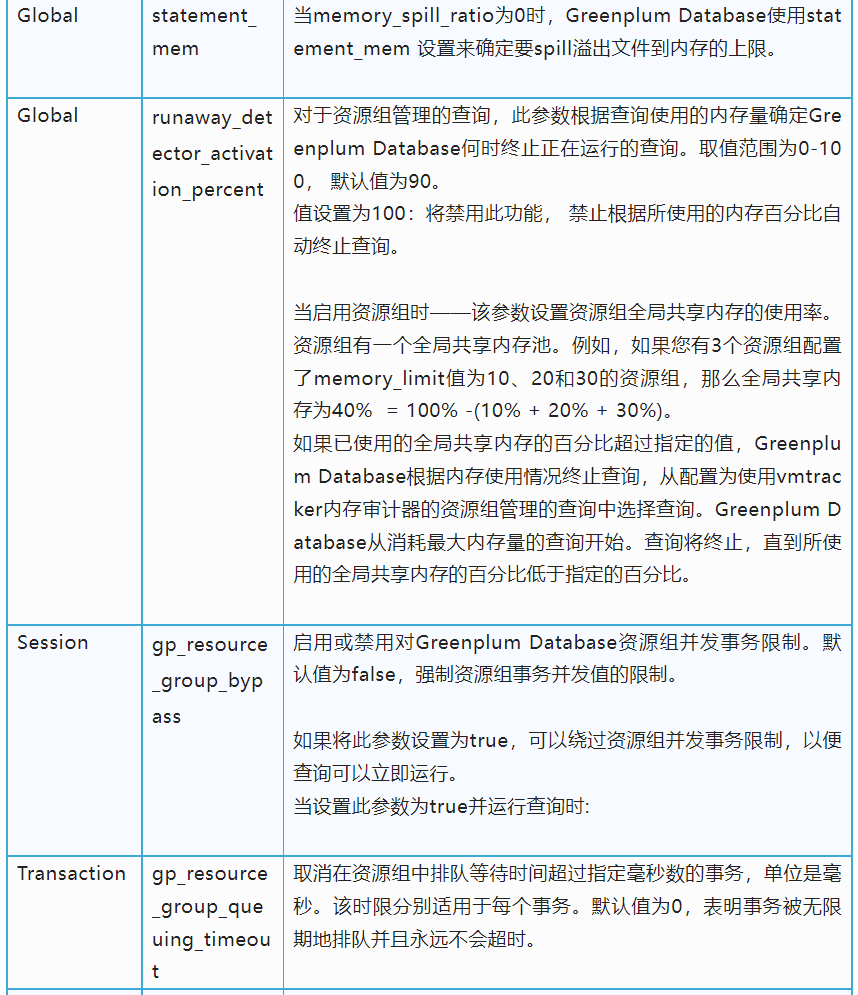
Query计划中的每个计划节点可分为两类: 内存密集型:像,排序,散列,物化… 非内存密集型:所有其他的,比如扫描,motion,.... 内存密集型plannode在执行时, 需要产生大量中间临时结果,可能需要外部存储,我们称之为溢出(到磁盘)。通过调整memory_spill_ratio来增加或减少来控制何时溢出。当memory_spill_ratio大于0时,它表示分配给查询操作符的资源组内存的百分比。 使用时请注意,如果并发性很高,即使将memory_spill_ratio设置为最大值100,这个内存数量也可能很小。当您将memory_spill_ratio设置为0时,Greenplum Database使用statement_mem设置来作为溢出到内存的上限值。 还有一个需要注意的问题是,当内存使用“超过溢出到磁盘上限值”之后,内存仍有可能增加。因为只有需要产生大量中间临时结果的操作类型受此控制,还有很多操作是无法溢出到磁盘上的,这些操作会继续占用内存。所以在配置时,仍需综合考虑。 因此,溢出到磁盘的上限 相关参数“memory_spill_ratio”的设置,会影响到内存的整体表现。在使用中,需要根据客户环境的真实情况进行调优。
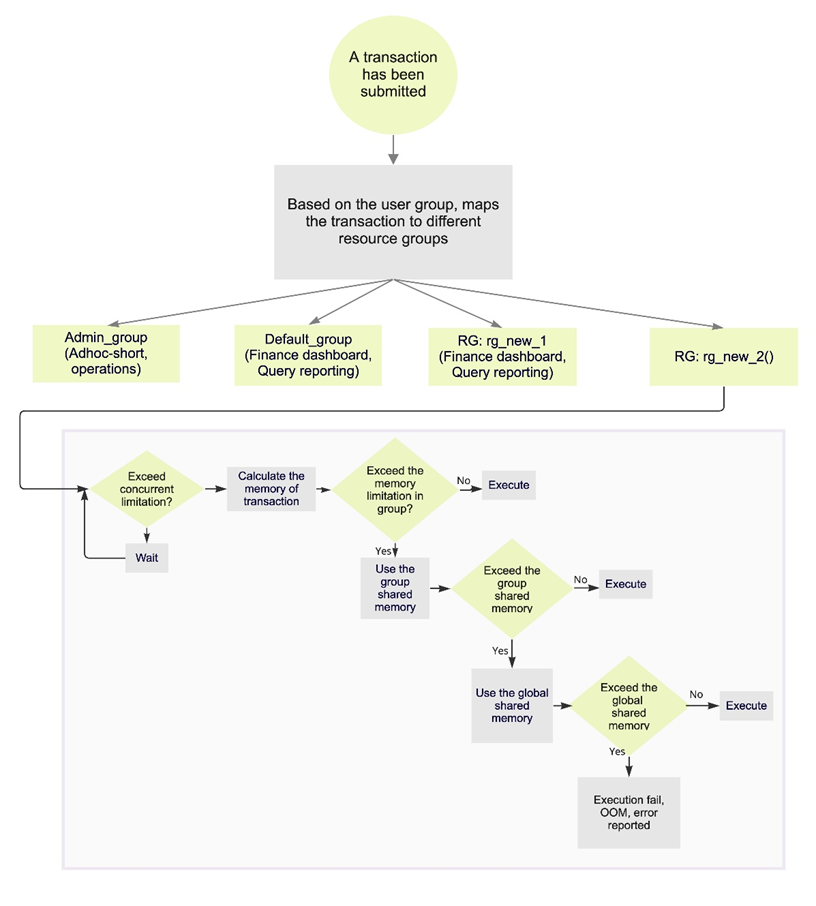
对于资源组管理的查询,此参数根据查询使用的内存量确定Greenplum Database何时终止正在运行的查询。 取值范围为0-100, 默认值为90。 如果值设置为100或者0:将禁用此功能, 禁止根据所使用的内存百分比自动终止查询。 当启用资源组时——该参数设置资源组全局共享内存的使用率。资源组有一个全局共享内存池。例如,如果您有3个资源组配置了memory_limit值为10、20和30的资源组,那么全局共享内存为40% = 100% -(10% + 20% + 30%)。 如果已使用的全局共享内存的百分比超过指定的值,Greenplum Database根据内存使用情况终止查询,从配置为使用vmtracker内存审计器的资源组管理的查询中选择查询。Greenplum Database从消耗最大内存量的查询开始。查询将终止,直到所使用的全局共享内存的百分比低于指定的百分比。
CPU管理介绍
在管理角色资源的组中,对CPU的资源管理使用基于Linux的CGroup。GreenPlum对CPU资源的分配有两种方式:
通过分配特定的CPU核给资源组 通过分配CPU资源的百分比给资源组

1
// 按资源百分比分配CPU资源
1. 对于按照 CPU资源百分比分配的模式,需要通过系统设置的参数有:
gp_resource_group_cpu_limit = 0.9
Parameters comes from: create resource group rg_new with (concurrency=5, cpu_rate_limit=20, memory_limit=30, memory_shared_quota=20, memory_spill_ratio=30)
可得出,此资源组分配得到的CPU资源:gp_resource_group_cpu_limit*cpu_rate_limit/100 = 0.9*20/100=0.18。
注意:一个资源组指定的 cpu_rate_limit 百分比的范围是1~100之间的整数值。在Greenplum数据库集群中定义的所有资源组指定的 cpu_rate_limit 之和不能超过100。
第一种是弹性模式 当 gp_resource_group_cpu_ceiling_enforcement设置为false(默认值)时,该模式激活。 它的弹性在于Greenplum Database可以将空闲的资源组的CPU资源分配给其他繁忙的资源组使用。当之前空闲的资源组需要CPU 资源时,CPU资源将被重新分配给该资源组。如果多个资源组都很忙,则根据CPU_RATE_LIMIT的比例分配,来分配空闲资源组的CPU资源。
例如,CPU_RATE_LIMIT为40的资源组与CPU_RATE_LIMIT为20的资源组相比,将分配两倍的额外CPU资源。第二种是上限模式 当 “gp_resource_group_cpu_ceiling_enforcement”设置为true时,该模式生效。 强制资源组使用的CPU资源不能超过定义的CPU_RATE_LIMIT值,避免使用CPU burst的弹性特性。
2
// 按核心数分配CPUSET资源
1. 可以在Greenplum数据库集群中同时使用这两种CPU资源分配模式。
举个例子:比如某台host 的CPU资源为32核, 其上面部署了4个segment。其上面的资源组的配置如下:
gp_resource_group_cpu_limit = 0.9=# postgres=# select * from gp_toolkit.gp_resgroup_config ;groupid | groupname | concurrency | cpu_rate_limit | memory_limit | memory_shared_quota | memory_spill_ratio | memory_auditor | cpuset ---------+---------------+-------------+----------------+--------------+---------------------+--------------------+----------------+--------6437 | default_group | 20 | 50 | 0 | 80 | 0 | vmtracker | -16438 | admin_group | 10 | -1 | 10 | 80 | 0 | vmtracker | 1-316388 | rg_new | 10 | 20 | 10 | 80 | 0 | vmtracker | -1(3 rows)复制
2. 从上面可以看出:
Host的CPU 资源的90%分配给GreenPlum Database。
其中资源组 admin_group 使用CPUSET, 分配的核为1-3。注意,为资源组配置CPUSET时,Greenplum数据库会禁用组的CPU_RATE_LIMIT并将值设置为-1。
其中资源组 default _group 使用的基于 CPU资源百分比分配的模式, cpu_rate_limit 分配比率为50%。
其中资源组 rg_new 使用的基于 CPU资源百分比分配的模式, cpu_rate_limit 分配比率为20%。
这个 CPU资源百分比分配的基数,指的是除去CPUSET分配出去的核之外的部分。对于CPUSET和CPU百分比混合配置的情况,此处仍需遵守这个限制:在Greenplum数据库集群中定义的所有资源组指定的 cpu_rate_limit 之和不能超过100。
3. 关于CPUSET 的使用注意事项:
当使用按照核心数CPUSET的模式,要避免浪费系统的CPU。
因为被指定为CPUSET 的core, 只能由这个资源组使用,其他资源组是无法使用的。所以,如果不能确认指定的core 能被充分使用时,使用 CPU资源百分比分配的模式会更加高效。
CPUSET中的核心0,有其特殊作用,所以尽可能少使用此编号:
因为系统会将CPU内核0分配给默认admin_group和default_group使用。在这种情况下,如果其他组也被分配了CPU核心0, 那这些资源组将与admin_group和default_group共享核心0。
如果进行物理节点替换后重新启动Greenplum数据库集群,并且新节点没有足够的内核来为所有CPUSET资源组提供服务,则会自动为这些组分配CPU核心0,以避免系统启动失败。
当使用按照核心数CPUSET的模式,请使用尽可能小的核心编号。
在场景“替换Greenplum数据库节点并且新节点的CPU核心数少于原始节点”时,或者场景“备份数据库希望在具有较少CPU核心的节点的群集上还原它”时,如果新节点找不到相应 CPUSET的核心数,将会失败。
监控命令和解释
1. 通过 “gp_resgroup_configgp_toolkit”系统视图来查看掌握资源的配置和状态。
查看资源组限制
=# SELECT * FROM gp_toolkit.gp_resgroup_config;
查看资源组查询状态和CPU/内存使用情况
=# SELECT * FROM gp_toolkit.gp_resgroup_status;
查看每个主机的资源组CPU/内存使用情况
=# SELECT * FROM gp_toolkit.gp_resgroup_status_per_host;
查看每个segment的资源组CPU/内存使用情况
=# SELECT * FROM gp_toolkit.gp_resgroup_status_per_segment;
查看分配给角色的资源组
=# SELECT rolname, rsgname FROM pg_roles, pg_resgroup
WHERE pg_roles.rolresgroup=pg_resgroup.oid;
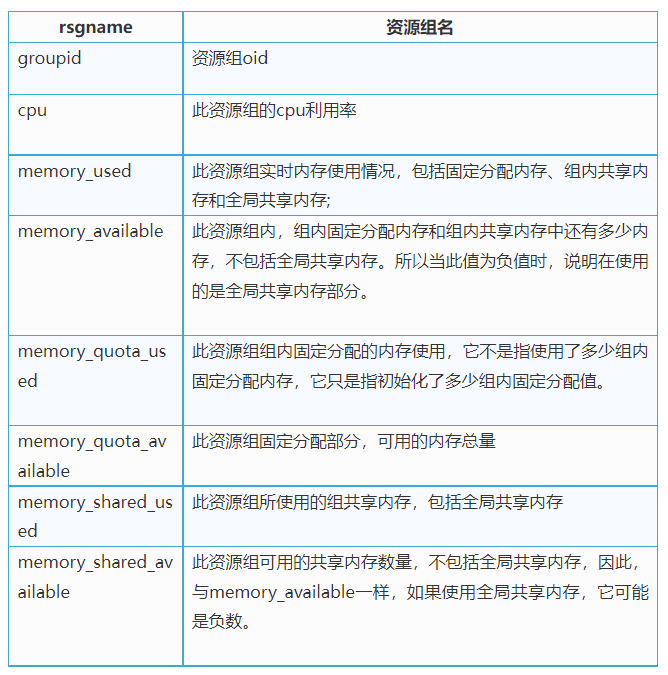
3. 有些参数的数值,会有负值出现,以此来表示是否使用到了共享内存。
举个例子:“memory_available”出现负值的情况:
下面是并发4个query,其并发设置上限为10。通过第一行可以看出, 对于资源组“admin_group”在“segment_id=2”上, memory_used=512, memory_available=-175, 说明其共使用了512M内存,其中全局共享内存占175M。memory_available=30, 表明其组内固定分配内存初始化时分配了30M (虽然,未必真正全部使用了)。memory_shared_used=488, memory_shared_available=-211, 说明其共享内存共使用了488M,其中全局共享使用了211M, 组内共享内存使用了377M(488-211=377)。
Query = 4, concurrency=10postgres=# select * from gp_toolkit.gp_resgroup_status_per_segment;rsgname | groupid | hostname | segment_id | cpu | memory_used | memory_available | memory_quota_used | memory_quota_available | memory_shared_used | memory_shared_available---------------+---------+----------+------------+-------+-------------+------------------+-------------------+------------------------+--------------------+-------------------------admin_group | 6438 | stable | 2 | 90.01 | 512 | -175 | 30 | 30 | 488 | -211default_group | 6437 | stable | -1 | 0.00 | 0 | 0 | 0 | 0 | 0 | 0default_group | 6437 | stable | 2 | 0.00 | 0 | 0 | 0 | 0 | 0 | 0admin_group | 6438 | stable | 0 | 90.01 | 512 | -175 | 30 | 30 | 488 | -211admin_group | 6438 | stable | 1 | 90.01 | 512 | -175 | 30 | 30 | 488 | -211default_group | 6437 | stable | 0 | 0.00 | 0 | 0 | 0 | 0 | 0 | 0admin_group | 6438 | stable | -1 | 90.97 | 18 | 319 | 30 | 30 | 0 | 277default_group | 6437 | stable | 1 | 0.00 | 0 | 0 | 0 | 0 | 0 | 0(8 rows)复制
调优参数
调参建议
1
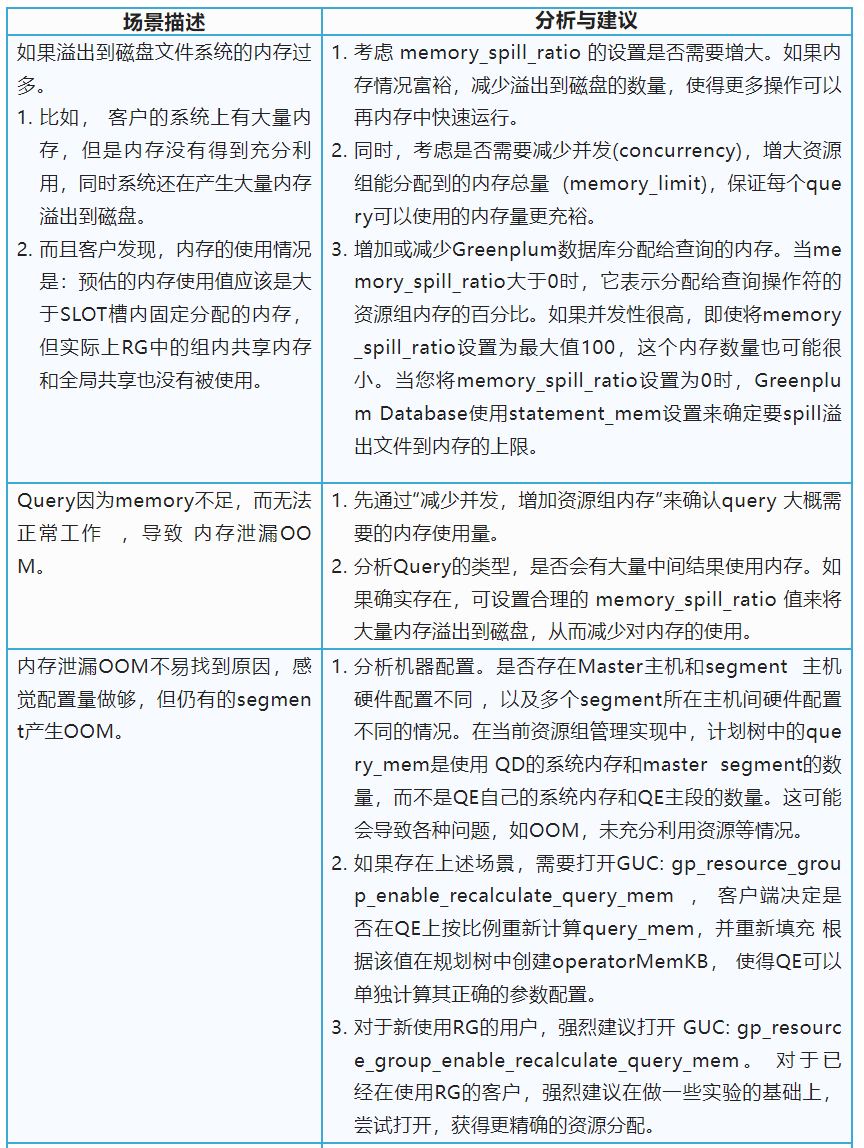
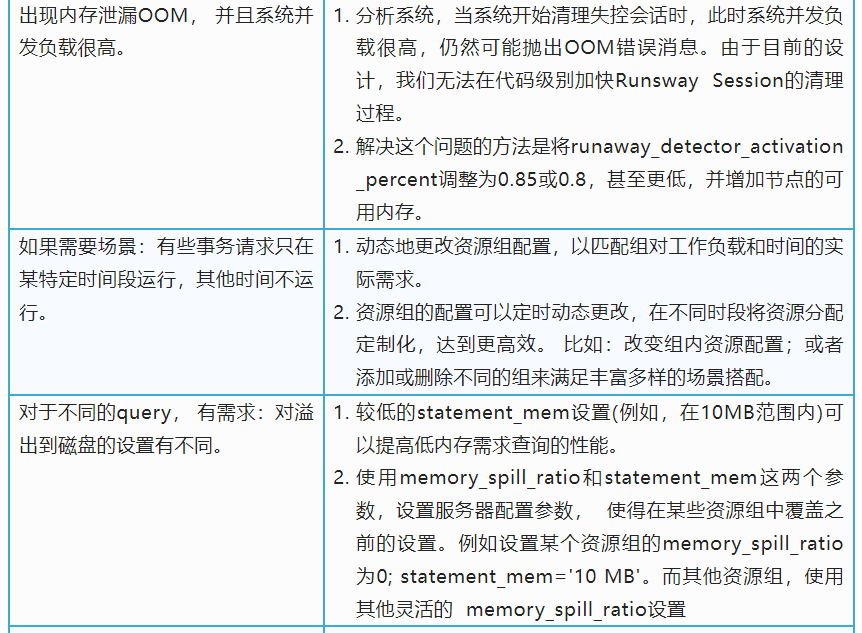
注意, 如果将memory_shared_quota设置为接近100: 这将导致固定分配内存部分几乎为0,而transaction_initial_quota_per_segment (开始溢出到磁盘的上限)可能太小,无法运行大多数查询。
2
注意,如果将memory_spill_ratio设置为非常大的值,这将导致很大的transaction_initial_quota_per_segment(开始溢出到磁盘的上限),许多查询可能使用过多的内存,耗尽插槽内存限制,或资源组内存限制,最终导致失败。
3
关于调优memory_shared_quota (组内共享内存):设置memory_shared_quota时,请考虑资源组的工作负载。如果几乎所有查询都需要类似的内存大小,那么memory_shared_quota可以小到0。如果您的资源组将支持带有小内存查询和大内存查询的混合工作负载,那么您可以将memory_shared_quota设置为相对较大的值,这样小内存查询就可以只使用固定部分内存运行,而大内存查询可以同时使用固定部分和组内共享部分。


作者简介
王雯

 来一波 “在看”、“分享”和 “赞” 吧!
来一波 “在看”、“分享”和 “赞” 吧!
