




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!


原理图:

主库配置
1. 配置postgresql.conf参数
使用命令找到postgre进程:
ps -ef | grep postgres
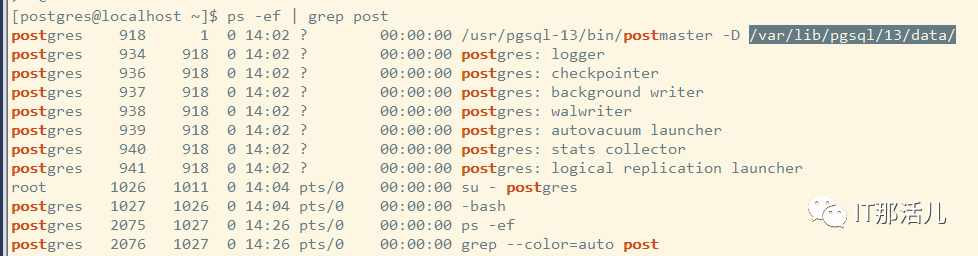
复制目录,cd进入:
cd /var/lib/pgsql/13/data/
vi postgresql.conf

修改下列参数:
wal_level = hot_standby
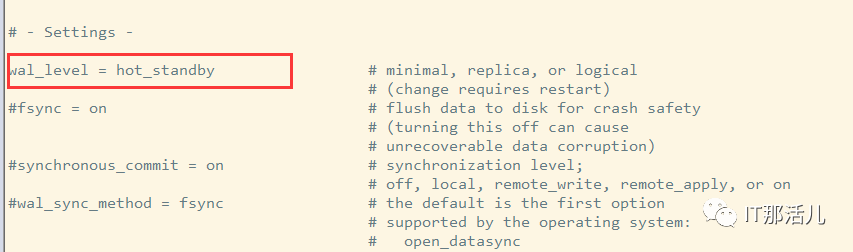
max_wal_senders = 5

hot_standby = on

2. 修改pg_hba.conf文件
Pg_hba.conf文件在postggresql.config同一目录下:
vi pg_hba.conf

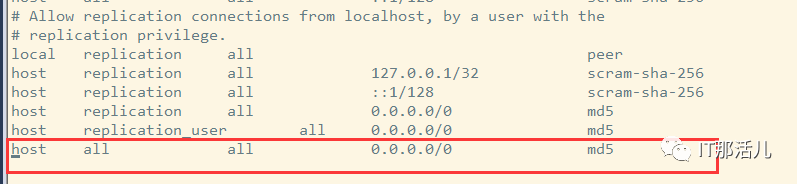
新增一行,允许复制用户访问主库:
host all all 0.0.0.0/0 md5
3. 新建replication_user用户
create user replication_user replication password '123456';
Master=>Slave1异步流复制配置
1. 在slave1的主机上执行 pg_basebackup
pg_basebackup -h 192.168.XX.132 -U replication_user -D var/lib/pgsql/13/data2/ -Xs -P -R

2. 执行命令后,主库的一些连接信息会自动写入写入备库postgresql.auto.conf文件,注释掉这些内容.
vi postgresql.auto.conf
#primary_conninfo = 'user=replication_user password=123456
channel_binding=prefer host=192.168.xx.132 port=5432
sslmode=prefer sslcompression=0
ssl_min_protocol_version=TLSv1.2 gssencmode=prefer
krbsrvname=postgres target_session_attrs=any'

3. 配置postgresql.conf参数
vi postgresql.conf
修改primary_conninfo参数为:
user=replication_user passfile=/var/lib/pgsql/.pgpass
host=192.168.XX.132 port=5432 application_name=slavedb1

4. 新增.pgpass密码文件
vi ~/.pgpass
#写入
192.168.XX.132:5432:replication:replication_user:123456
#修改权限
chmod 0600 ~/.pgpass
5. 开启slavedb1的postgres服务进程
/usr/pgsql-13/bin/pg_ctl -D /var/lib/pgsql/13/data2/ start

查看日志:

Slave1=>Slave2异步流复制配置
1. 在slave1的主机上执行 pg_basebackup基础备份与恢复。

2. 执行命令后,步骤同2.2,注释掉postgresql.auto.conf多出来的内容,配置postgresql.conf参数文件。
3. 配置postgresql.conf参数
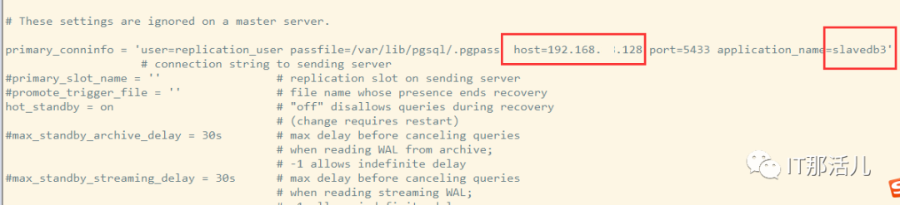
修改primary_conninfo参数为:
user=replication_user passfile=/var/lib/pgsql/.pgpass host=192.168.XX.128
port=5433 application_name=slavedb3
4. 新增.pgpass密码文件
vi ~/.pgpass
#写入
192.168.XX.128:5433:replication:replication_user:123456
#修改权限
chmod 0600 ~/.pgpass
5. 开启slavedb1的postgres服务进程
/usr/pgsql-13/bin/pg_ctl -D /var/lib/pgsql/13/data2/ start

查看日志:

查看级联复制状态
1. 主库查询
Select
pid,usename,application_name,client_addr,state,sync_state,sy
nc_priority from pg_stat_replication;

2. Slave1上查询
Select
pid,usename,application_name,client_addr,state,sync_state,sy
nc_priority from pg_stat_replication;

3. 验证数据
主库操作:
create table t_sr(id int4);
Insert into t_sr values(1);
Select * from t_sr;

Slave1上查询:
Select * from t_sr;
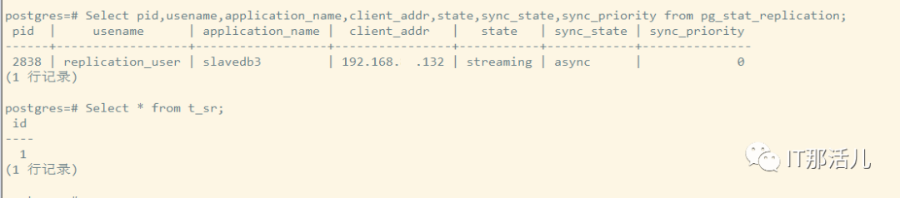
Slave3上查询:
Select * from t_sr;

总结:
PG级联流复制可以解决主库压力或跨机房的多份数据传输的问题,一般都会和repmgr工具搭配使用,来实现基于NAS共享存储的负载均衡策略。
由于篇幅限制,本次展示的部署步骤没有repmgr的内容,所以步骤跟mysql的级联复制差不多,都是从库套从库。但PostgreSQL 借助repmgr工具管理的级联数据复制有些不同,可以从PG的从库进行数据的CLONE 制作新的从节点,然后在将从节点连接到主库,并且PostgreSQL 中的复制是stream replication 而不是类似MYSQL 的逻辑复制。
关于repmgr工具的内容,以后有机会再行展示。

本文作者:吴航舟(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
