




前言:
好记性不如烂笔头~
在2022/5/20的日子里,来回忆一下本周一的一个异常处理过程。
周一有套运行了很多年的DB系统,突然crash了,还导致Block Corruption
一,故障恢复
1. 突然接到应用保障电话,说XXX系统无法访问
第一时间登录服务器,查看listener/smon,监听正常,smon不见了,咦,DB被人关了?
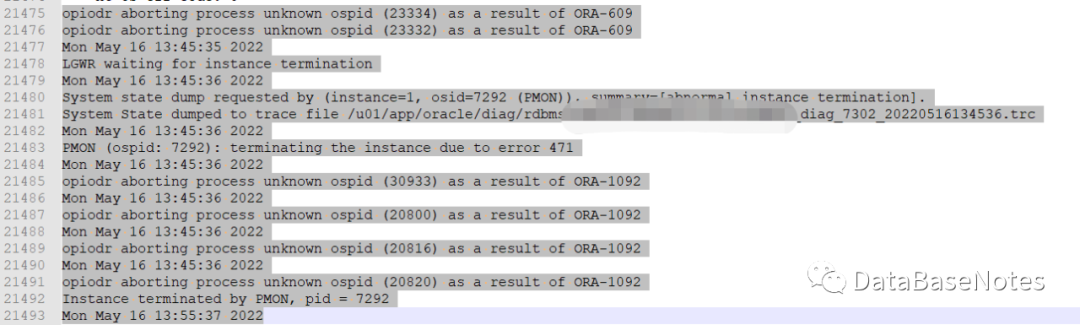
2. 查看alert
Mon May 16 13:45:35 2022
LGWR waiting for instance termination
Mon May 16 13:45:36 2022
System state dump requested by (instance=1, osid=7292 (PMON)), summary=[abnormal instance termination].
System State dumped to trace file u01/app/oracle/diag/rdbms/xxx/xxx/trace/xxx_diag_7302_20220516134536.trc
Mon May 16 13:45:36 2022
PMON (ospid: 7292): terminating the instance due to error 471
Mon May 16 13:45:36 2022
opiodr aborting process unknown ospid (30933) as a result of ORA-1092
Mon May 16 13:45:36 2022
opiodr aborting process unknown ospid (20800) as a result of ORA-1092
Mon May 16 13:45:36 2022
opiodr aborting process unknown ospid (20816) as a result of ORA-1092
Mon May 16 13:45:36 2022
opiodr aborting process unknown ospid (20820) as a result of ORA-1092
Instance terminated by PMON, pid = 7292
Mon May 16 13:55:37 2022
Starting ORACLE instance (normal)
************************ Large Pages Information *******************
Per process system memlock (soft) limit = 64 KB
3. 先拉起db 再说
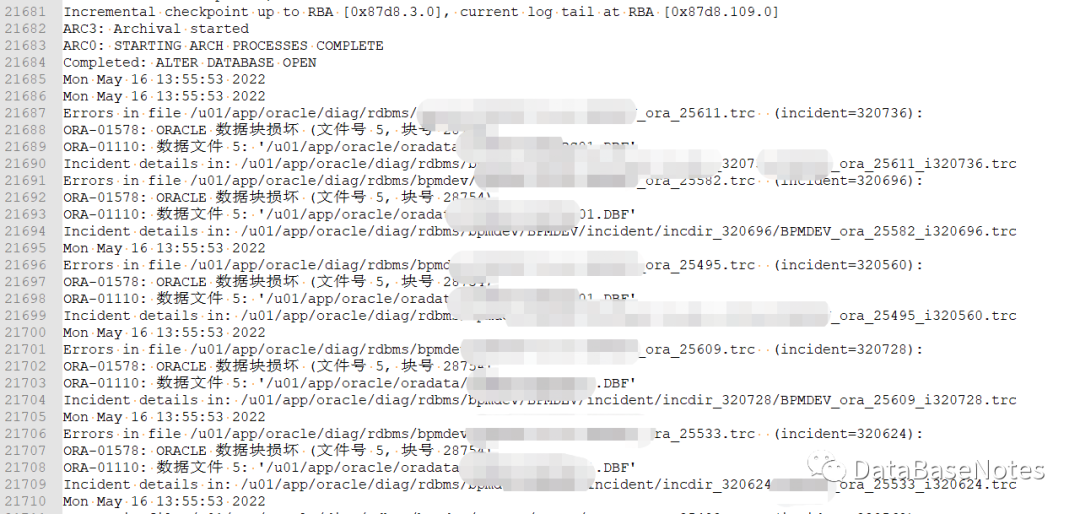
startup的时候,直接ORA-01578,,,
Mon May 16 13:55:55 2022
Errors in file /u01/app/oracle/diag/rdbms/xxx/xxxx/trace/xxx_ora_25599.trc (incident=320712):
ORA-01578: ORACLE 数据块损坏 (文件号 5, 块号 28754)
4. 赶紧跟应用沟通,数据库需要恢复
应用先暂停访问,DB修复优先。。。
5. 进一步排查异常数据块
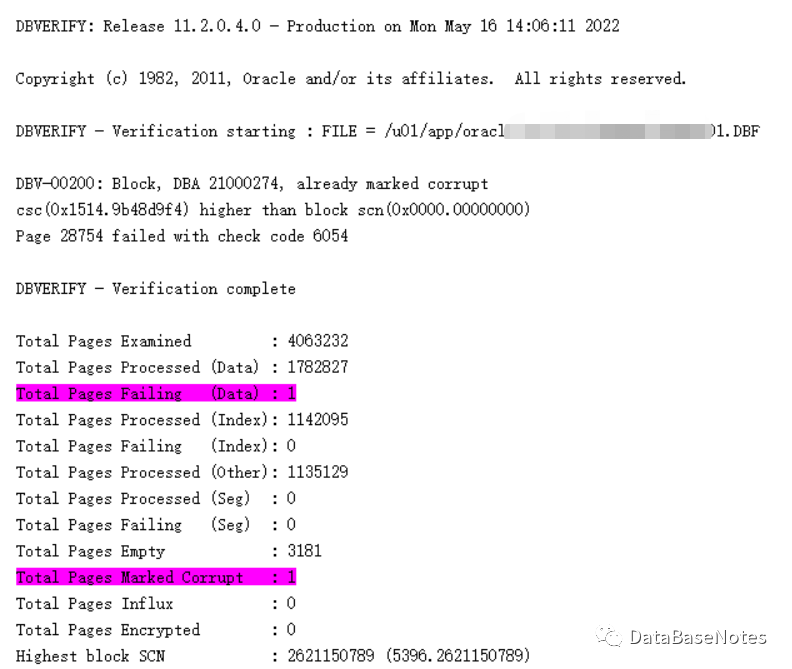
首先使用dbv来检查数据块,发现损失的是数据,有备份才不会丢失数据,没有备份,只能丢失数据了。。。
要是检查出来是index,那就好了。
PS: select * from v$database_block_corruption; 也可以查询出损坏的数据块,但是,无法判断是数据还是索引,所以,我个人倾向于用dbv检查。
dbv file=/u01/app/oracle/oradata/XXXX/XXXXX01.DBF blocksize=8192
6. 根据error信息检查损坏的对象
select tablespace_name,segment_type,owner,segment_name from dba_extents where file_id='&FILE#' and '&BLOCK#' between block_id and block_id+blocks-1;
这里的F指的是file#,B指的是block#
本次,ORA-01578: ORACLE 数据块损坏 (文件号 5, 块号 28754)
select tablespace_name,segment_type,owner,segment_name from dba_extents where file_id=5 and 28754 between block_id and block_id+blocks-1;

7.至此,已经得知具体损坏的数据表。
本套db 由于最近上NBU备份项目,本机RMAN已经停止备份。
NBU项目负责人还在摸索中。。。恢复时间不可知 555
如果有rman备份,执行blockrecover datafile xx block xx;就可以了。
可惜啊,唉
只能先屏蔽坏块,启库,让系统先恢复使用。

8,与应用负责人确认
此数据表部分数据丢失对系统无影响,我们可以后面nbu恢复备份后,把数据再补齐。
9. 临时针对table做exp/imp备份
export NLS_LANG=american_america.AL32UTF8
exp xxx/xxx file=dump.dmp tables=HRMRESOURCE
SQL> drop table xxx.HrmResource;
Table dropped.
SQL> commit;
Commit complete.
export NLS_LANG=american_america.AL32UTF8
imp xxx/xxxx file=dump.dmp tables=HRMRESOURCE
10. 启库,应用恢复正常访问
至此,应用已经恢复正常访问。
二、异常根因排查
11. 追查db crash原因
alert日志有一段,
PMON (ospid: 7292): terminating the instance due to error 471
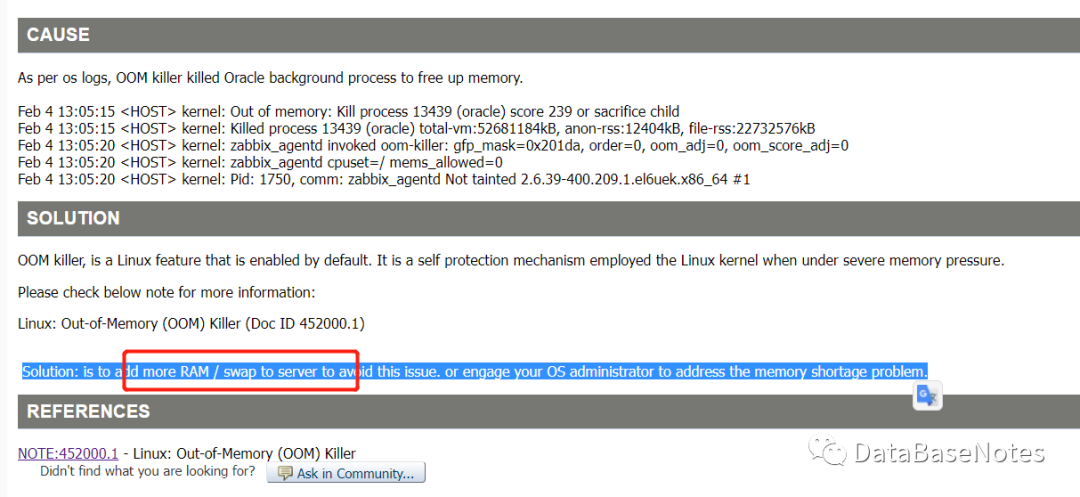
经查询mos文档
Terminating the Instance Due to Error 471 Out-Of-Memory(OOM) Killer Crashes Oracle Database (Doc ID 1622379.1)
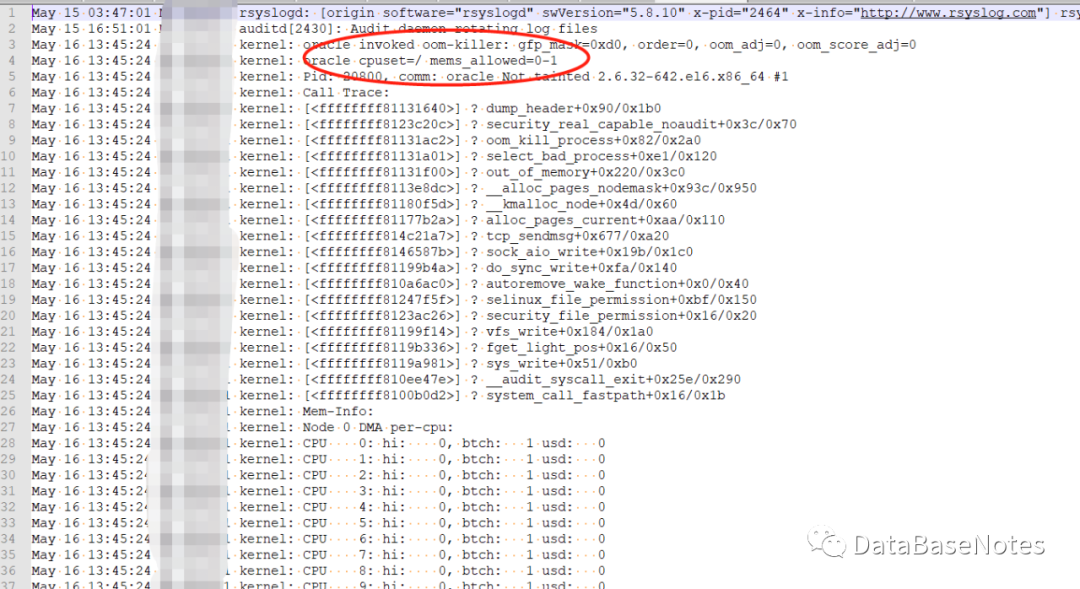
12. 检查/var/log/message
同样发现了OOM异常事件。
May 16 13:45:24 xxxxx kernel: oracle invoked oom-killer: gfp_mask=0xd0, order=0, oom_adj=0, oom_score_adj=0
May 16 13:45:24 xxxxx kernel: oracle cpuset=/ mems_allowed=0-1
May 16 13:45:24 xxxxx kernel: Pid: 20800, comm: oracle Not tainted 2.6.32-642.el6.x86_64 #1
May 16 13:45:24 xxxxx kernel: Call Trace:
May 16 13:45:24 xxxxx kernel: [<ffffffff81131640>] ? dump_header+0x90/0x1b0
May 16 13:45:24 xxxxx kernel: [<ffffffff8123c20c>] ? security_real_capable_noaudit+0x3c/0x70
May 16 13:45:24 xxxxx kernel: [<ffffffff81131ac2>] ? oom_kill_process+0x82/0x2a0
May 16 13:45:24 xxxxx kernel: [<ffffffff81131a01>] ? select_bad_process+0xe1/0x120
May 16 13:45:24 xxxxx kernel: [<ffffffff81131f00>] ? out_of_memory+0x220/0x3c0
May 16 13:45:24 xxxxx kernel: [<ffffffff8113e8dc>] ? __alloc_pages_nodemask+0x93c/0x950
May 16 13:45:24 xxxxx kernel: [<ffffffff81180f5d>] ? __kmalloc_node+0x4d/0x60
May 16 13:45:24 xxxxx kernel: [<ffffffff81177b2a>] ? alloc_pages_current+0xaa/0x110
May 16 13:45:24 xxxxx kernel: [<ffffffff814c21a7>] ? tcp_sendmsg+0x677/0xa20
May 16 13:45:24 xxxxx kernel: [<ffffffff8146587b>] ? sock_aio_write+0x19b/0x1c0
May 16 13:45:24 xxxxx kernel: [<ffffffff81199b4a>] ? do_sync_write+0xfa/0x140
13. 为什么突然OOM?
经咨询应用系统负责人,最近上了很多新应用,DB整体loading也很大,会话数也由原来的500左右,飙升到2000多。
抓取了一些TOP sql和近期AWR,这是后话,此处不做累赘叙述。。。
三、异常数据补录/恢复
14.接下来,来补录数据。
如果有rman备份,执行blockrecover datafile xx block xx;就可以了。
唉,唉,唉~
备份真的很很很重要啊!!!
备份真的很很很重要啊!!!
备份真的很很很重要啊!!!
15. NBU同事帮忙恢复到测试服务器
此处忽略过程。
据说rman也可以直接调用NBU备份文件恢复,由于对NBU不熟,后续研究一下,争取下次节约时间。。。更希望没有下次。
16. rowid简单介绍

第一部分6位表示:该行数据所在的数据对象的 data_object_id;
第二部分3位表示:该行数据所在的相对数据文件的id;
第三部分6位表示:该数据行所在的数据块的编号;
第四部分3位表示:该行数据的行的编号;
17. 读取数据块损坏(文件号 5, 块号 28754)的rowid
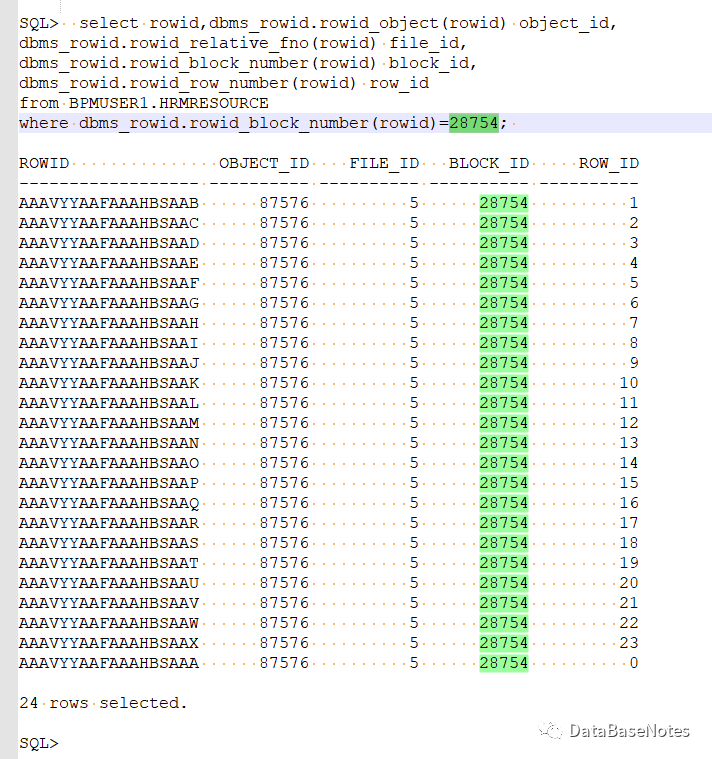
18. 根据rowid AAAVYYAAFAAAHBSAAB 查看数据块的原始数据
select * from XXX.HRMRESOURCE where rowid in (
select rowid from XXX.HRMRESOURCE where substr(rowid,0,6)='AAAVYY' and substr(rowid,7,3)='AAF' and substr(rowid,10,6)='AAAHBS');
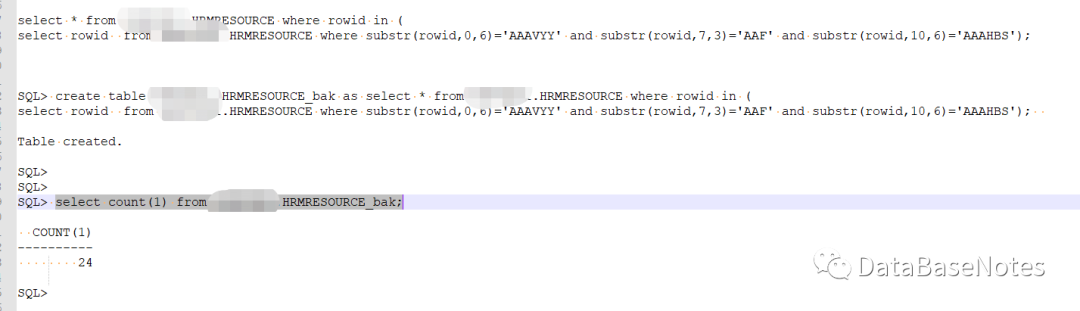
19. 备份数据块block数据
create table xxx.HRMRESOURCE_bak as select * from xxx.HRMRESOURCE where rowid in (
select rowid from xxxx.HRMRESOURCE where substr(rowid,0,6)='AAAVYY' and substr(rowid,7,3)='AAF' and substr(rowid,10,6)='AAAHBS');
select count(1) from xxxx.HRMRESOURCE_bak;
20. 导出备份的数据块,scp到生产db上,进行导入。让业务比对数据,检验。
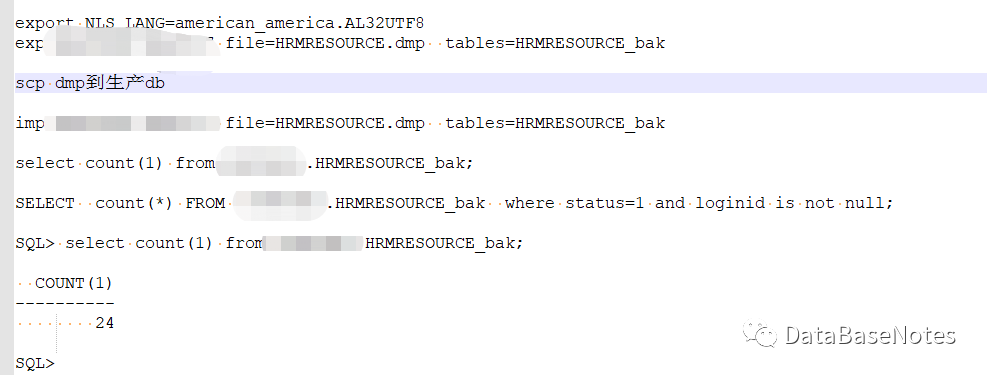
21.至此,数据恢复完成。
顺带复习了由rowid恢复数据。温故而知新,也挺好的~
坏块处理总结,
1.若效的rman备份则恢复语句如下:
----单block恢复
recover datafile 7 block 19846;
----多block恢复
recover corruption list; validate 检测后可用该语句进行恢复
2. 若仅数据泵备份,则从数据泵恢复该表数据到备份的状态。
impdp directory=dump dumpfile=xxx.dump SCHEMAS=xxx include=table:"\=\'tablename\'"
impdp directory=dump dumpfile=xxx.dump tables=xxx.tablename
3. 无备份,屏蔽掉坏块,拯救部分数据。exp备份表。
启用10231内部事件 alter system set events='10231 trace name context forever,level 10’;
关闭10231内部事件 alter system set events='10231 trace name context off’;



