




前言

今天在 stackexchange上看到了一个名为 Large IN的优化文章,这让我觉得很有意义。以前我们这里开发人员因为 in的值太多,导致 sql语句效率不高,一直没有修改。也是时候改了。
Large In的优化方法
什么叫Large In,意思是语句都中使用 in,然后列表中有大量的值。以前我们在 Oracle上遇到过这样的语句,最多有超过60000个值,直接运行语句中命中 Bug,因为 in中的 list使用了绑定变量,Oracle最多有65536个绑定变量。
现在我们来试一试 PostgreSQL,它是一个292 GB的表,以前的测试tps环境构建的。
pgbench=# select pg_size_pretty(pg_total_relation_size('pgbench_accounts'));
pg_size_pretty
----------------
292 GB
(1 row)
pgbench=# select pg_size_pretty(pg_total_relation_size('pgbench_branches'));
pg_size_pretty
----------------
6520 kB
(1 row)
pgbench=# \d pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
aid | bigint | | not null |
bid | integer | | |
abalance | integer | | |
filler | character(84) | | |
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
pgbench=# \d pgbench_branches
Table "public.pgbench_branches"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
bid | integer | | not null |
bbalance | integer | | |
filler | character(88) | | |
Indexes:
"pgbench_branches_pkey" PRIMARY KEY, btree (bid)复制
首先测试 in中有20个值的情况,通常我们语句的写法如下:
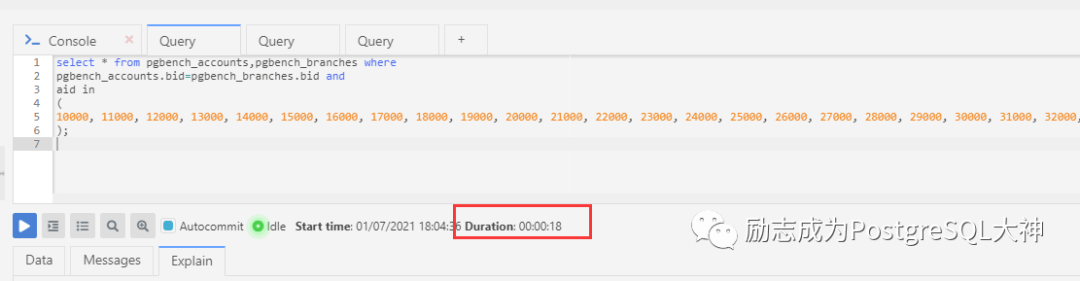
explain (analyze,buffers) select * from pgbench_accounts,pgbench_branches where
pgbench_accounts.bid=pgbench_branches.bid and
aid in
(
10000, 11000, 12000, 13000, 14000, 15000, 16000, 17000, 18000, 19000, 20000, 21000, 22000, 23000, 24000, 25000, 26000, 27000, 28000, 29000
);复制
经过多次执行,执行时间为0.203ms,速度很快。

对于in,我们默认会使用in-list来查找,如果你有大量数据,我们可以使用常量子查询或临时表。
首先尝试一下常量子查询。
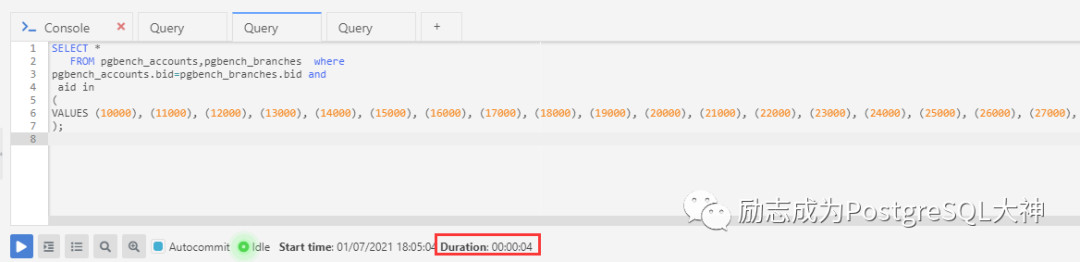
explain (analyze,buffers)
SELECT *
FROM pgbench_accounts,pgbench_branches where
pgbench_accounts.bid=pgbench_branches.bid and
aid in
(
VALUES (10000), (11000), (12000), (13000), (14000), (15000), (16000), (17000), (18000), (19000), (20000), (21000), (22000), (23000), (24000), (25000), (26000), (27000), (28000), (29000)
);复制

可以看到常量子查询执行效率并不占优势,我们再测试一下临时表。
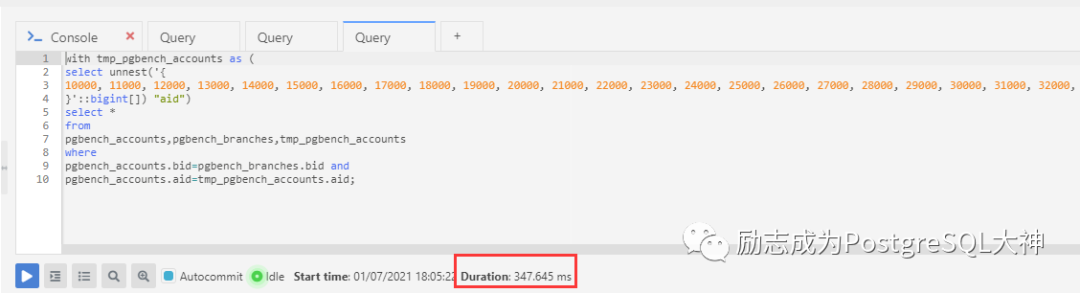
explain analyze
with tmp_pgbench_accounts as (
select unnest('{
10000, 11000, 12000, 13000, 14000, 15000, 16000, 17000, 18000, 19000, 20000, 21000, 22000, 23000, 24000, 25000, 26000, 27000, 28000, 29000
}'::bigint[]) "aid")
select *
from
pgbench_accounts,pgbench_branches,tmp_pgbench_accounts
where
pgbench_accounts.bid=pgbench_branches.bid and
pgbench_accounts.aid=tmp_pgbench_accounts.aid复制

临时表的速度是0.219ms,也没有优势。
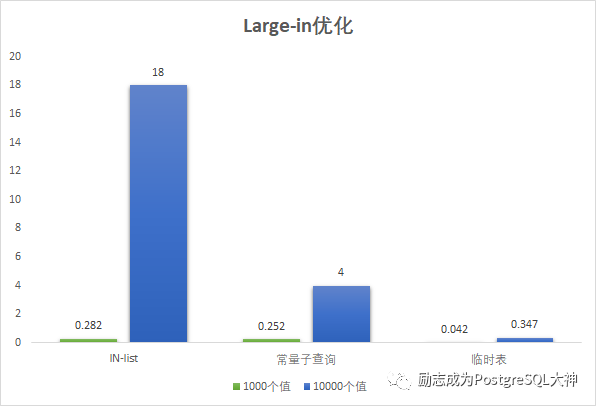
我们现在把in的值增多,直接测试1000,10000个值。因为有更多的代码,所以这里直接显示测试结果图,为了保证结果准确,我这里使用客户端多次运行。
客户端显示结果如下:
1000个值差距不明显,在达到10000值之后,IN-list需要18秒左右,常量子查询需要4秒,临时表只需要347 ms。临时表的效率是最高的。
后记
所以以前开发使用 in传递一堆值,如果传递太多的话,速度会很慢,会影响效率。因此遇到此类语句时,可以改造成临时表的写法。
参考文档
https://dba.stackexchange.com/questions/91247/optimizing-a-postgres-query-with-a-large-in/91539
文章转载自励志成为PostgreSQL大神,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
外国CTO也感兴趣的开源数据库项目——openHalo
小满未满、
1848次阅读
2025-04-21 16:58:09
3月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
381次阅读
2025-04-15 14:48:05
转发有奖 | PostgreSQL 16 PGCM高级认证课程直播班招生中!
墨天轮小教习
195次阅读
2025-04-14 15:58:34
中国PostgreSQL培训认证体系新增PGAI应用工程师方向
开源软件联盟PostgreSQL分会
189次阅读
2025-05-06 10:21:13
华象新闻 | PostgreSQL 18 Beta 1、17.5、16.9、15.13、14.18、13.21 发布
严少安
164次阅读
2025-05-09 11:34:10
PG生态赢得资本市场青睐:Databricks收购Neon,Supabase融资两亿美元,微软财报点名PG
老冯云数
149次阅读
2025-05-07 10:06:22
SQL 优化之 OR 子句改写
xiongcc
143次阅读
2025-04-21 00:08:06
告别老旧mysql_fdw,升级正当时
NickYoung
126次阅读
2025-04-29 11:15:18
PostgreSQL中文社区亮相于第八届数字中国峰会
PostgreSQL中文社区
114次阅读
2025-05-07 10:06:20
PostgreSQL的dblink扩展模块使用方法
szrsu
109次阅读
2025-04-24 17:39:30



