




前言

近来从Oracle割接了一套库到PG,遇到了序列的问题。

序列产生的值比当前序列的值小,这是肾么情况?
PG序列的设计理念不同
我在 google上搜索,发现这个问题的确存在。先在窗口 A中创建一个序列,然后将 cache设为20,第一次执行 sequence操作。下面显示100。
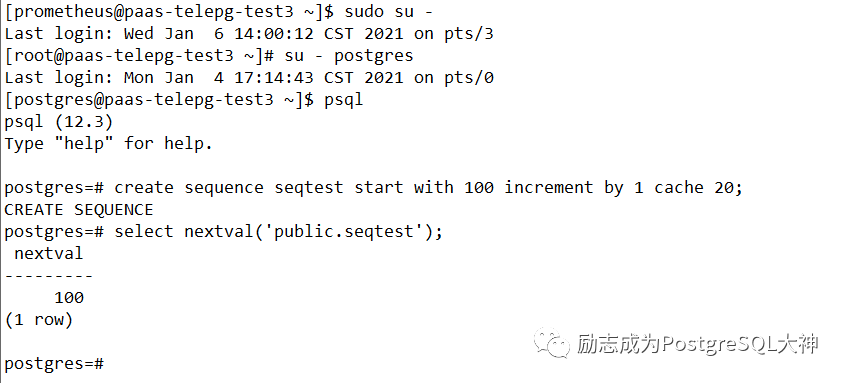
现在打开的 B窗口查询序列值。此处显示为120。

此时在返回A窗口,查询序列值。查询的结果是101。若按时间顺序排列,的确有比120更小的现象。

下一步,我们观察一下Oracle数据库。窗口A创建序列, cache设置为20。

接着再窗口B查询序列值。这里显示为2。

再一次返回窗口 A查询序列值,结果为3。

在 Oracle中, Session A和 Session B访问数据库对象来生成序列的下一个值,不同会话产生的序列号按照顺序排列。但在 PostgreSQL中,会话 A缓存100-119,而会话 B缓存120-139。所以 SessionB从120开始产生值。会话 A将从100-119个字符产生一个值。这就是说, PostgreSQL基于会话级别的缓存,并且序列值没有顺序排列,如果两个会话同时插入同一个表,那么会话B的值121可以在会话A的值102之前插入。这就导致了我们前面开发遇到的序列值小还在后面插入的问题。
那么,解决方案是什么呢?将序列的缓存修改为1。当缓存被修改为1后,将按顺序插入。在 PostgreSQL中也可以使用 SERIAL数据类型。但不知道是否会引发序列争用的问题。如果序列的 cache值很小,那么在 Oracle中同时执行大量并发插入操作时,肯定会导致 sequence争用问题。
双方还有一点区别。就是当数据库正常重启之后,Oracle的序列值仍然从最后一次使用的值获取。而PostgreSQL则会丢弃cache中缓存的值。直接从增加一个cache的开销然后开始。如下图所示:

当然这个是正常关机模式,如果是异常关机模式的情况,例如kill postgres主进程。
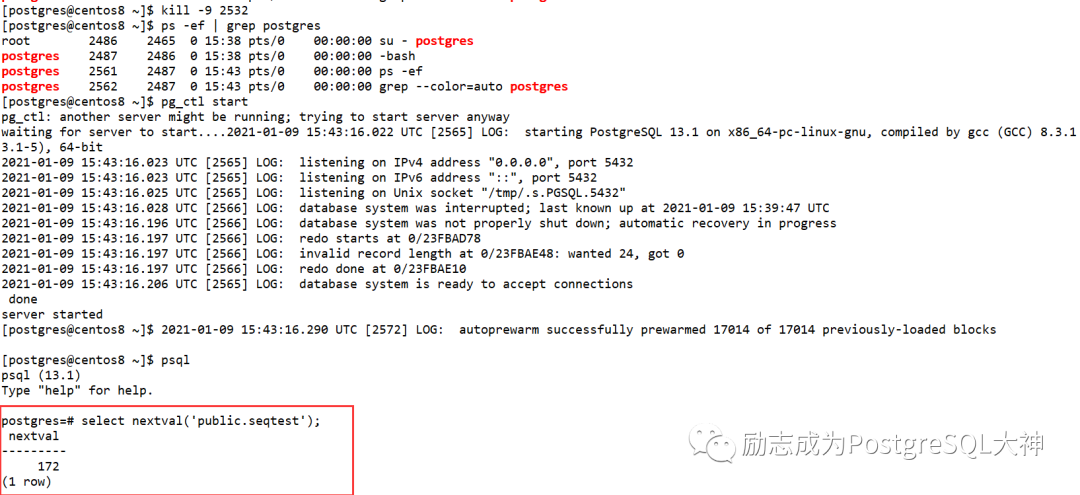
可以看到值从120变成了172,而不是140,这是因为它在sequence.c定义了异常关闭启动后会自动增加32。
crash we can lose (skip over) as many values as we pre-logged.
/*
* We don't want to log each fetching of a value from a sequence,
* so we pre-log a few fetches in advance. In the event of
* crash we can lose (skip over) as many values as we pre-logged.
*/
#define SEQ_LOG_VALS 32复制
后记
我们发现了Oracle和 PostgreSQL在序列使用上的差异。关于应用的问题,如果序列值和时间是挂钩的,那么 cache需要设置为1。对于是否会导致序列争用的问题,之后我将进行测试。
